利用LSTM網絡和課程關聯分類的推薦模型
2019-08-12 02:11:14王素琴吳子銳
計算機與生活 2019年8期
王素琴,吳子銳
華北電力大學 控制與計算機工程學院,北京 102206
1 引言
隨著互聯網以及移動互聯網技術的迅速發展,在線學習方式已經得到了人們的廣泛認可。在線學習網站在為用戶提供豐富課程資源的同時,信息過載問題日益凸顯,海量的學習資源常常讓用戶無所適從。推薦系統能夠幫助用戶快速發現所需要的課程,是緩解信息過載問題的最有效方法之一[1]。
在線學習網站目前主要采用傳統的協同過濾算法[2-3]為用戶推薦課程,但存在冷啟動[4]和數據稀疏性等問題。近年來,深度學習技術發展迅速,并率先在圖像處理、自然語言處理和語音識別等領域取得突破性進展[5-6],為推薦系統帶來了新的思路。與協同過濾算法相比,多層神經網絡可以更好地應對數據的稀疏性特征。其中,長短時記憶(long short-term memory,LSTM)網絡擅長處理時間序列數據,當用戶行為模式具有明顯的時序性特點時,采用LSTM網絡能夠更準確地預測用戶未來的行為。用戶選擇新的課程時要考慮的因素與網絡購物差異較大,用戶購買商品通常出于個人偏好[7],但選擇新的課程時,往往與其學過的課程有關,即用戶所學習的課程具有一定的時序性。根據這一特性,本文將LSTM網絡應用于在線課程的推薦,根據用戶已學習的課程序列預測其將要學習的課程。
本文第2章介紹相關工作;第3章給出相關概念;第4章介紹課程推薦模型;第5章提出基于頻繁模式譜聚類的課程關聯分類模型;第6章給出在線課程推薦算法;第7章基于在線學習網站數據集進行實驗結果驗證和分析;第8章對全文工作進行總結。
2 相關工作
2.1 協同過濾算法及其應用
協同過濾算法是根據用戶群體興趣的相似性進行推薦的技術,分為基于用戶的協同過濾推薦(userbased collaborative filtering,UCF)和基于項目的協同過濾推薦(item-based collaborative filtering,ICF)。由于在線學習網站中用戶的數量通常遠多于課程的數量,使得計算用戶相似度矩陣的代價遠遠高于計算課程相似度矩陣的代價,因此針對該問題采用基于項目的協同過濾推薦算法效率更高。
馮亞麗等人[8]綜合應用UCF和ICF算法進行遠程培訓中的個性化學習資源的智能推薦,經實際應用測試表明效果良好。李浩君等人[9]提出了基于多維特征差異的個性化學習資源推薦算法,針對推薦模型的多目標優化特征,將協同過濾算法和粒子群算法相結合,實驗結果證明該算法準確率較好。
2.2 基于深度學習的推薦算法及其應用
深度學習技術能將數據的屬性或者特征進行提取并抽象為更高層的表示。最早應用于推薦系統的深度學習技術是受限玻爾茲曼機[10](restricted Boltzmann machine,RBM),Hinton等人使用RBM對表格數據建模,并提出了一種對比散度算法來提高RBM的訓練效率。實驗結果表明,該方法在Netflix數據集(包含超過1億用戶的評分數據)上表現出色。微軟公司的研究人員Song等人[11]在WWW2015會議上提出了一個面向新聞和桌面應用的基于內容的推薦模型,采用深層神經網絡(deep neural networks,DNN)進行用戶信息的提取。
循環神經網絡(recurrent neural network,RNN)主要用于處理序列數據。Netflix研究員Hidasi[12]提出了一個基于會話的循環神經網絡推薦系統,將會話記錄中的用戶點擊項序列信息作為輸入數據,在用戶點擊流數據量龐大且數據稀疏性高(即大部分用戶點擊量往往集中在少量的數據項)的情況下,RNN網絡取得了不錯的推薦結果。Okura等人[13]采用RNN從用戶的歷史行為列表中學習用戶的偏好,最后利用用戶與新聞之間的關聯性為用戶推薦新聞。斯坦福大學Liu等人[14]比較了十種不同結構的RNN網絡對用戶評論信息進行處理后的推薦效果,在此基礎上提出了一種適合于推薦的雙向RNN結構。
2.3 基于LSTM的推薦算法及應用
LSTM網絡針對RNN的隱藏層單元進行改進,具備長時記憶功能。通常來說,RNN能夠解決的問題LSTM都能夠處理并且效果更好。目前LSTM網絡主要應用于自然語言處理、語音識別和圖像理解。Graves等人[15]最早將LSTM網絡應用于單詞預測方面的研究,經過英語和法語語言庫的訓練后,單詞預測正確率比標準RNN高出8%。Li等人[16]提出了一種基于LSTM網絡的推特推文標簽推薦系統,首先使用skip-gram模型生成詞匯表,然后應用CNN(convolutional neural networks,CNN)將文章中的每一個句子生成為句子向量,最后利用句子向量訓練LSTM網絡。實驗結果表明,與標準RNN以及GRU(gated recurrent unit)相比,基于LSTM的推薦模型取得了更好的效果。
多項研究結果表明LSTM網絡適合于對具有時序性的信息流進行建模,并且在序列的時間跨度較大的情況下LSTM的性能優于RNN。
3 相關概念
3.1 RNN網絡結構
循環神經網絡RNN是一種時間遞歸網絡,可以看作是同一個神經網絡結構在時間軸上循環多次得到的結果。與其他深層神經網絡相比,RNN的結構特點決定了它更擅長處理序列數據。
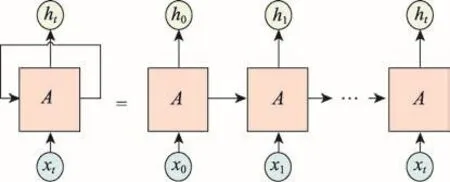
Fig.1 Network structure of RNN圖1 RNN網絡結構
RNN的網絡結構如圖1所示,其中A為RNN隱藏層處理單元,xt為當前時刻的輸入值,ht為當前時刻隱藏層的輸出值。從圖中可以看出,ht是由當前輸入值xt和上一時刻輸出值ht-1共同決定,而ht又會影響下一時刻的輸出,即每個輸出值不僅與當前的輸入值有關還與之前時刻的輸出值有關。
理論上RNN可以處理任意長度的時間序列數據,但是在實際應用中發現,在RNN訓練過程中會產生梯度消失和梯度爆炸的問題。Pascanu等人[17]通過詳細的數學推導解釋了這一現象產生的原因,即傳統的RNN模型在訓練時傾向于按照序列結尾處的權值正確方向進行更新。由于隔得越遠的輸入序列,對權值能夠正確變化的影響越小,因此網絡輸入偏向于新信息的輸入而不具備長期記憶功能。
3.2 LSTM網絡結構
LSTM解決了RNN訓練神經網絡過程中梯度消失和梯度爆炸問題,能夠保留更久以前的信息。LSTM的網絡結構與RNN大體接近,但是隱藏層的結構更為復雜,如圖2所示。
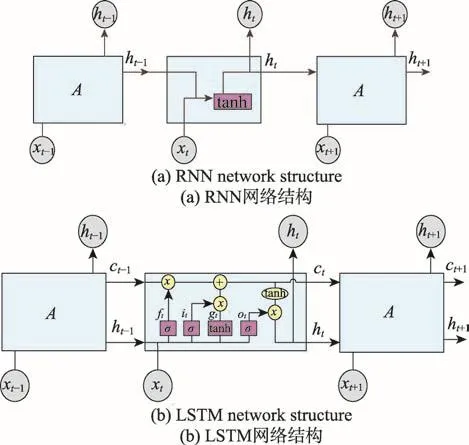
Fig.2 Comparison of RNN and LSTM network structures圖2 RNN和LSTM網絡結構比較
圖2 中,t時刻的輸入信息包括當前的輸入值xt以及上一時刻的輸出值ht-1。LSTM處理單元主要由輸入門(用it表示)、遺忘門(用ft表示)、輸出門(用ot表示)組成。
輸入門it主要用于控制當前時刻信息的流入量,見式(1)。
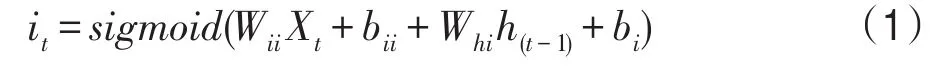
遺忘門ft用于控制上一時刻累積的歷史信息ct-1的流入量,見式(2)。
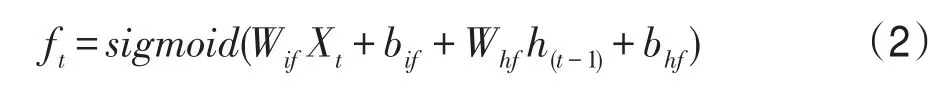
輸出門ot主要用于控制當前時刻信息的流出量,見式(3)。

gt代表當前時刻信息的更新值,它由上一時刻的輸出值ht-1和當前時刻的輸入值xt所決定,見式(4)。
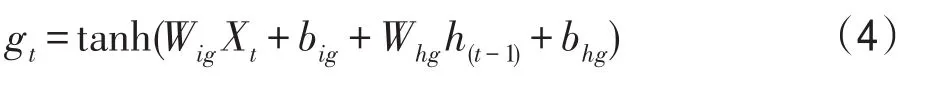
ct表示隱藏層單元攜帶的信息,類似于細胞的狀態。它由輸入門和遺忘門控制,每一時刻都在更新,并直接決定當前的輸出。ht是由輸出門ot對ct進行篩選后得到的輸出結果,見式(5)、式(6)。

以上公式詳細地推導了輸入信息在LSTM隱藏層的處理過程。LSTM通過輸入門、遺忘門和輸出門三個門的作用來調控信息的流向以及篩選信息,從而解決了信息的長時記憶問題[18-20]。
4 基于LSTM網絡的在線課程推薦模型
4.1 在線課程推薦模型的框架
基于LSTM的在線課程推薦模型按照功能劃分為輸入部分、處理部分和輸出部分,如圖3所示。
輸入部分將用戶的原始學習記錄轉化為LSTM網絡計算時所需要的數據形式,即每個用戶已學課程的向量表示。
處理部分是通過LSTM網絡處理輸入數據,得到輸出結果。需要確定LSTM網絡的結構,包括網絡層數、時間步長以及各層之間的連接設置。本文以課程的數量作為特征值的數量,相應地也就定義了輸入數據和輸出數據的維度,即輸入層和輸出層神經元的數量。用戶的課程學習序列長度決定了每次計算時的時間步長,將最大時間步長定義為用戶學習的課程序列的最大值,同時在讀取每個用戶學習序列時,需要指定相應的序列長度。這樣整個LSTM網絡模型的結構就確定了。Softmax層是將LSTM處理層輸出向量的值映射到(0,1)區間內。
輸出部分取Softmax層處理結果的最后一個維度得到最終推薦的課程向量。
4.2 課程向量表示及輸入數據預處理
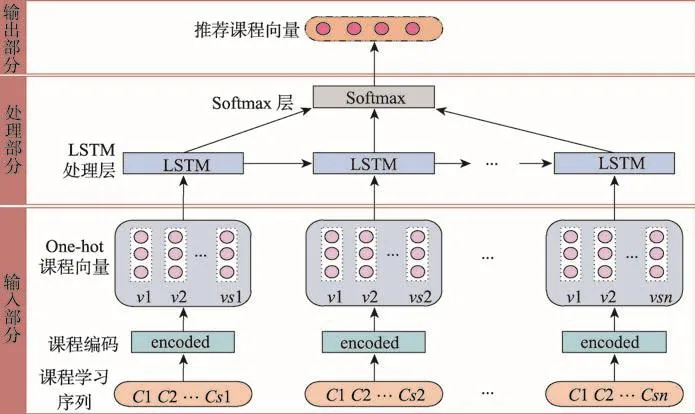
Fig.3 Framework of online course recommendation model圖3 在線課程推薦模型框架
神經網絡在計算前通常需要對輸入數據進行歸一化處理,將數據限制在一定范圍內,以保證模型能夠迅速收斂。本文采用One-Hot編碼對輸入數據進行歸一化處理。One-Hot編碼采用二進制向量形式,因此需要將課程映射為整數值,即每一門課程對應一個課程id,再將課程id表示為二進制向量,向量中下標為id號的元素值標記為1,其他元素都是0,例如{0,0,0,1,0…0}表示課程id為4的課程。對輸入數據進行預處理的過程如圖4所示。
首先讀取數據庫中用戶原始學習記錄,并轉化為用戶-課程序列的格式,最后將課程序列中每一門課程用向量表示。
其中將用戶課程序列用向量表示的方法如圖5所示。
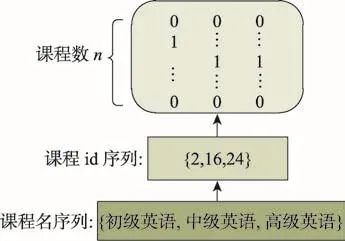
Fig.5 Data normalization diagram圖5 數據歸一化處理示意圖
4.3 模型輸出和推薦結果
將樣本中每個用戶的課程學習序列輸入到模型中,經過LSTM網絡處理后,再通過Softmax層映射得到最終的推薦結果,如圖6所示。
輸出結果是向量形式,每個元素的下標代表相應的課程id,每個元素的值表示用戶學習該課程的概率。向量中最大元素的下標即為推薦給用戶的課程id,是用戶接下來最有可能學習的課程。
4.4 模型輸出和推薦結果
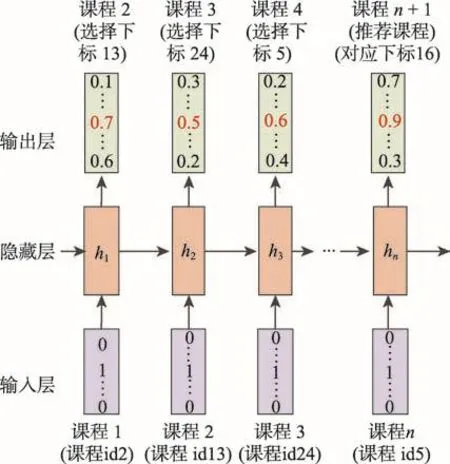
Fig.6 Input and output of model圖6 模型輸入輸出示意圖
訓練神經網絡時,使用損失函數(loss function)來評估模型的預測值與實際值不一致的程度。損失函數的值越小,模型的性能越好。交叉熵損失函數適用于多分類和預測問題。根據在線課程推薦的特點,本文選用交叉熵損失函數作為LSTM網絡的損失函數,其計算方法如式(7)所示。
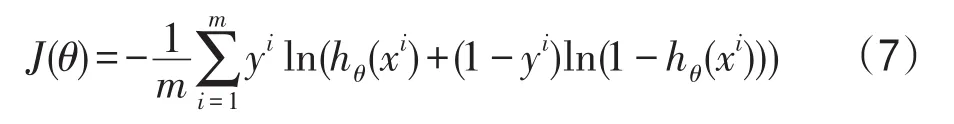
式中,m表示樣本大小,xi表示第i組輸入值,yi表示第i組輸入值對應的實際值,hθ表示模型中的權值參數,hθ(xi)表示模型的輸出值。
交叉熵損失函數有兩個重要的性質:
(1)非負性:J(θ)的值始終大于0,優化函數的目標是將函數值減小。
(2)模型的輸出值hθ(xi)與實際值yi偏差越小,J(θ)的值越小。當神經網絡的輸出值接近于實際值時,J(θ)的值接近于0。
以上兩個性質說明了交叉熵損失函數從數學的角度上看,適合用來評估模型的性能。當選擇sigmoid函數作為激活函數時,權值的更新速度與誤差大小相關,避免了反向傳播損失值收斂速度慢這一問題[21]。
4.5 Adam優化算法
在訓練神經網絡時,需要使用優化算法來調整網絡的權值參數,減小損失函數的值,使模型的性能得到優化。常用的優化算法有SGD算法、Adagrad算法和Adam算法等。SGD算法在每次迭代時計算最小batch的梯度,然后更新參數,缺點是選擇合適的學習速率比較困難,且容易陷入局部最優解。Adagrad算法對學習速率進行了約束,但仍依賴人工設置全局的學習速率,有時對梯度的調節過大。Adam(adaptive moment estimation)算法適用于大數據和高維度的空間,對內存的需求較小,因此本文采用Adam算法作為優化算法。
Adam算法能夠根據損失函數對每個參數的梯度的一階矩估計和二階矩估計動態調整針對于每個參數的學習速率。Adam是基于梯度下降的方法,但是每次迭代參數的學習步長都有一個確定的范圍,不會因為較大的梯度導致過大的學習步長,參數更新比較穩定。Adam的每一步迭代過程如下:
(1)從訓練集中隨機抽取一批樣本{x1,x2,…,xm}以及相應的輸出yi。
(2)計算梯度和誤差,更新一階動量s和二階動量r,再根據s和r以及梯度計算參數更新量。
與其他自適應學習率算法相比,Adam算法收斂速度更快,學習效果更有效,能夠解決其他優化算法中存在的問題,如學習率消失、收斂過慢或是高方差的參數更新導致損失函數波動較大等[22]。
5 基于頻繁模式譜聚類的課程關聯分類模型
5.1 關于課程分類的討論
上文的課程推薦算法是基于課程之間的時序性而提出的,因此將課程按照時序相關性進行分類后推薦的準確率會更高。目前,在線學習網站課程的分類由人工進行,一般只是單純地依據課程內容上的相似性,對課程學習的時序相關性考慮不多。同時,由于在線課程更新頻繁,人工維護課程分類的工作量較大。如果能夠根據大量用戶的學習記錄發現課程之間的時序相關性,再依據時序相關性對課程進行自動分類,必將進一步提高推薦算法的準確性。這里的課程分類不是通常意義上的課程聚類,聚類是根據課程的特征值計算課程間的“距離”,反映的是課程的相似性,而這里的課程分類考慮的是課程的時序相關性。本文采用GSP(generalized sequential pattern mining algorithm)算法和譜聚類算法對課程進行分類。
5.2 GSP算法和課程關系建立
首先使用GSP算法從用戶課程學習記錄數據庫中挖掘出不同課程之間的關聯關系,為下一步的聚類決策提供支持。GSP算法是一種常用的序列模式挖掘算法[23],屬于Apriori類算法。它能夠從用戶對課程的學習行為中,發現常見的學習模式,挖掘出課程之間時序上的聯系。
首先應用GSP算法挖掘出數據庫中所有超過最小支持度閾值的頻繁項集。對課程序列α支持度的定義見式(8)。
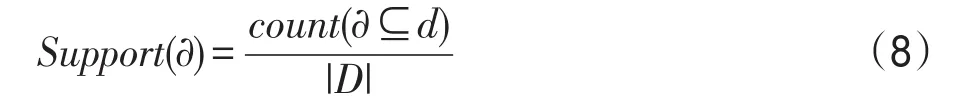
式中,count(α?d)表示數據庫中包含課程序列α的用戶課程序列d的個數,|D|表示數據庫大小,即序列總數。最小支持度閾值Supmin是人為設定的。
再對頻繁項集進行連接操作,設有兩個序列s1和s2,若s1去掉第一項和s2去掉最后一項剩下的序列相同,便可進行連接操作。通過連接操作自下而上地進行迭代產生更長的高階頻繁序列。
算法的實現流程如下所示:
(1)輸入用戶-課程數據庫D,支持度閾值Supmin。
(2)掃描數據庫,產生長度為1的頻繁序列的集合,即種子集L1。
(3)對頻繁序列進行連接,刪掉不滿足支持度閾值的序列,直到沒有新的候選集產生時,結束。
(4)輸出頻繁模式L,支持度列表count。
GSP算法挖掘出的頻繁序列數量隨著序列長度的增加呈現指數級遞減。較長的頻繁序列數量稀少,無法用于課程的分類。因此根據GSP算法挖掘出的長度為2的頻繁序列,建立課程關聯矩陣W。W是一個對稱矩陣,其中Wij表示課程i與課程j的關聯度,設定Wii=0。對于頻繁模式 <i,j>,對應的支持度為a(a<1),那么Wij=Wji=a。
5.3 譜聚類算法和課程關聯分類
GSP算法得到的關聯矩陣只能提供兩個課程間的相關程度,需要利用譜聚類算法[24]進一步根據課程關聯關系的強弱對所有課程做出合理的簇劃分。譜聚類算法是在傳統聚類算法的基礎上結合了圖譜理論而演化出的算法,后來在聚類中得到了廣泛的應用。其基本原理是:對于一個圖G,通常需要用點的集合V和邊的集合E來進行描述,記作G(V,E)。V為樣本集中的所有點(v1,v2,…,vn),對于圖中的點,定義Wij為點vi和vj之間的權重。譜聚類算法簡單地說就是通過對所有數據點組成的圖進行切圖,讓切圖后不同子圖點之間的權重較低,子圖內點之間的權重盡可能得高,從而達到聚類的目的。而最優的切圖方式,則可以通過對無向圖鄰接矩陣進行數學變化得到[25]。
本文將各個課程當作頂點,課程數為n,課程間的關聯度Wij看成帶權重的邊。算法流程如下:
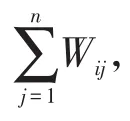
(2)求出L前k個較小特征值對應的特征向量,構造N×K維特征向量矩陣M,其中N為全部課程數,K為指定特征數。將全部課程投影到k維空間,M的每一行表示每門課程對應的k個特征。
(3)將每一行作為一個樣本點,對N個樣本點進行K-means聚類,最終得到每個課程的分類結果。
6 基于課程關聯分類和LSTM網絡的課程推薦流程
(1)利用GSP算法從用戶課程學習記錄表中挖掘出頻繁序列,并根據支持度建立課程關聯矩陣。
(2)應用譜聚類算法在課程關聯矩陣的基礎上對所有課程分類。
(3)數據歸一化,通過one-hot編碼將課程序列轉化為課程向量集合。
(4)按類別將課程向量輸入推薦模型,得到輸出結果。
(5)通過交叉熵損失函數,將模型的輸出結果與實際值比較,計算偏差值。
(6)偏差值反向傳播,應用Adam優化算法更新模型中每一層神經元的權值參數,達到調整偏差值的目的,直到滿足指定的條件,否則重復(3)、(4)、(5)步驟。
(7)推薦模型訓練結束后,載入測試數據,得到模型的輸出值,獲取推薦結果。
7 實驗結果及分析
7.1 實驗數據集
實驗數據集來自于某在線教學網站的實際運行數據,用戶數13 680人,課程總數737門,主要是計算機類相關課程。數據包括用戶的學習記錄和評分記錄,時間跨度從2014年5月到2017年7月,記錄總條數共148 170條。其中訓練集占80%,約11.8萬條記錄,測試集占20%,約3萬條記錄。首先將數據簡化為三元組(用戶id,學習時間,課程id)。
7.2 評估指標
算法的評價指標是準確率(Precision),是指在推薦給用戶的所有課程中用戶實際學習的課程所占的比例,見式(9)。
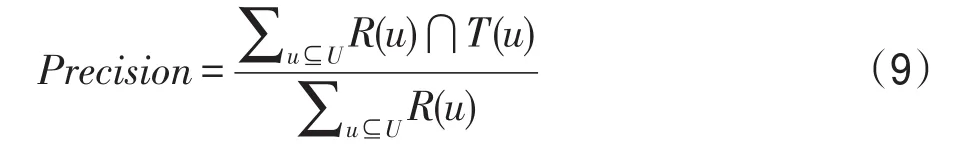
式中,T(u)表示用戶u實際學習的所有課程,R(u)表示推薦給用戶u的所有課程。準確率越高,表示推薦的課程越符合用戶的期望。
7.3 實驗結果
輸入測試集中用戶已學習的課程序列,經模型處理后輸出一個課程序列,取最后一門課程作為用戶推薦課程,并與用戶實際學習的課程相比,判斷推薦結果是否準確。
7.3.1 人工分類和頻繁模式譜聚類下推薦結果對比
將全部課程人工劃分為前端開發、后端開發、數據庫應用、軟件測試、UI設計、移動端開發六大類,并相應地將數據集拆分為六個子集。
表1記載了網站人工分類下應用基于LSTM推薦算法的推薦結果。
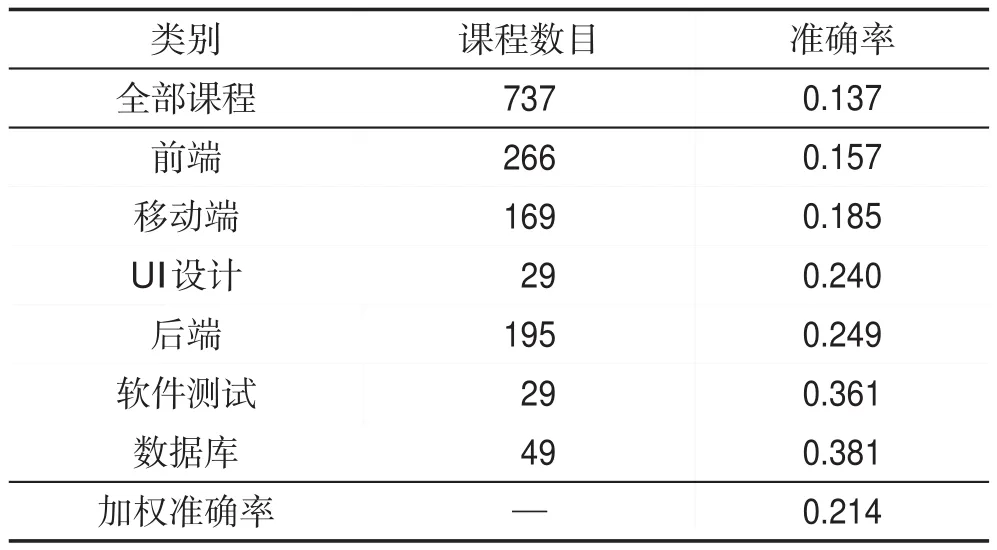
Table 1 Recommend results based on artificial classification of websites表1 基于網站人工分類下的推薦結果
從表格中可以看出,分類后各個類別下的推薦結果普遍好于全部課程下的推薦結果。
采用頻繁模式譜聚類算法進行課程的自動分類,得到六個課程類別,相應的推薦結果如表2所示。
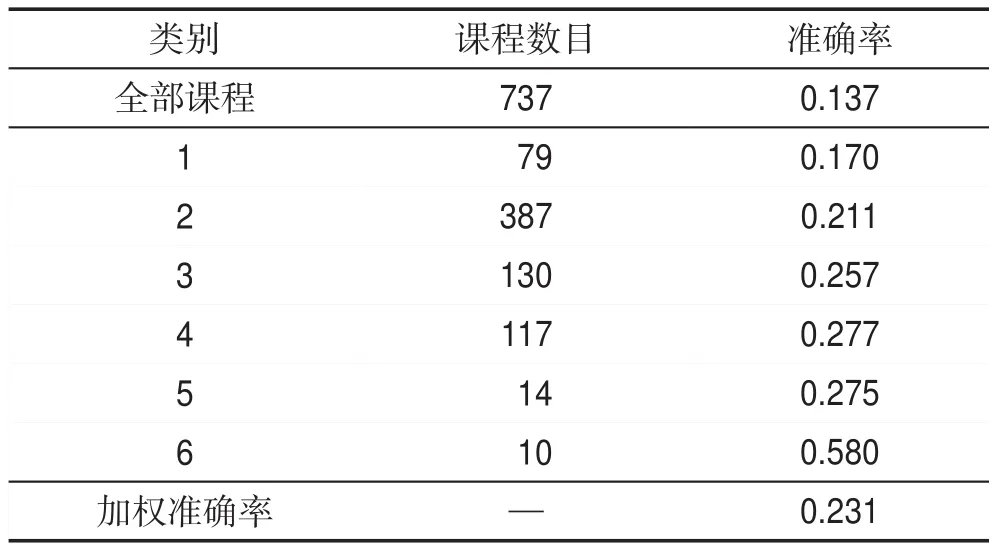
Table 2 Recommended results based on spectral clustering表2 譜聚類下的推薦結果
與表1人工分類推薦結果對比,推薦算法在譜聚類劃分的大多數類別下比人工分類的表現更好,加權的準確率提高了1.7%。
7.3.2 與協同過濾推薦算法對比
本文算法與UCF和ICF算法在相同數據集下的推薦結果準確率比較如表3所示。
除了全部課程類別外,本文算法的準確率指標均遠遠高于ICF和UCF算法。與協同過濾算法相比,本文算法更適合于時序依賴性較強的課程的推薦。另外,ICF比UCF更適合于在線教學網站中用戶數量遠大于課程數量情況下的推薦工作。
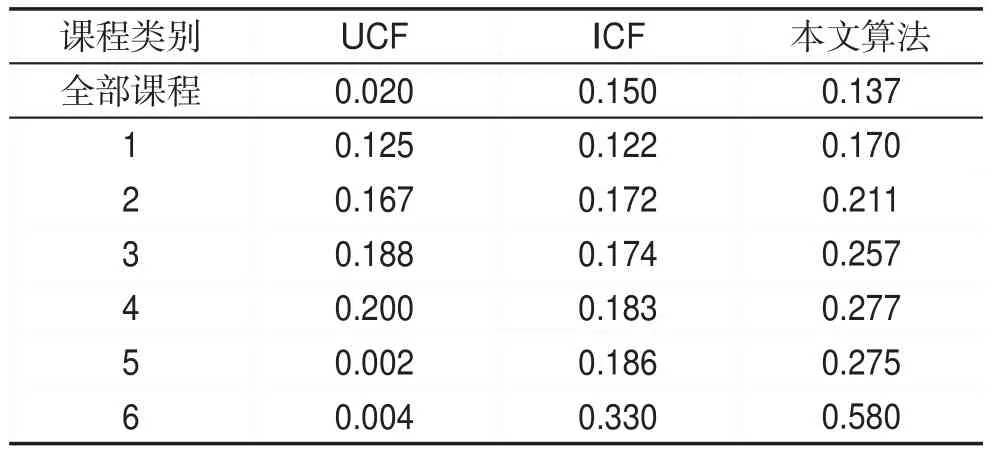
Table 3 Precision comparison between this algorithm and collaborative filtering recommendation algorithm表3 本文算法與協同過濾推薦算法準確率的對比
7.3.3 與基于RNN的推薦算法對比
基于RNN網絡的推薦算法與本文算法在相同訓練周期下(設定為100)推薦結果的準確率比較如表4所示。
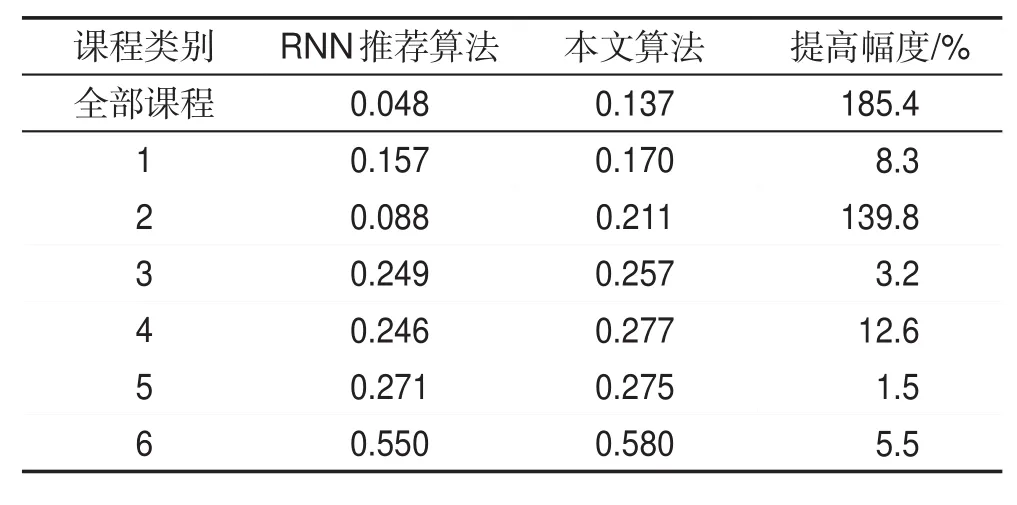
Table 4 Precision comparison between this algorithm and recommendation algorithm based on RNN表4 本文算法與基于RNN的推薦算法準確率的對比
實驗結果表明,一方面,兩個算法在不同類別課程上表現的差異性是相似的,在課程之間聯系比較緊密的課程類別上算法的表現更好,反之則算法的表現稍差;另一方面,在每一個課程類別上本文算法的推薦效果都優于RNN推薦算法,在用戶課程學習序列普遍較長的情況下兩者表現差距更大,出現這種現象的原因是LSTM網絡具備長時記憶功能,能夠很好地利用關系緊密的序列信息。
8 總結
本文結合了LSTM網絡的特性和在線課程學習的特點,提出將LSTM網絡應用于在線課程推薦算法,并應用GSP算法和譜聚類算法對全部課程進行分類,使每一類別下的課程聯系更加緊密。實驗結果表明,自動分類方法提高了課程推薦的準確率。與傳統的協同過濾算法相比,對于同類課程的推薦本文算法準確率有大幅度提升;與RNN推薦算法相比,本文算法在各個類別的課程數據集上準確率均有明顯提升,在用戶課程學習序列普遍較長的情況下,兩者表現差距更大,體現了LSTM網絡具備長時記憶的優勢。實驗結果表明,本文算法具有準確率高,所推薦課程與用戶已學課程密切相關的優點。
本文算法存在的不足主要是推薦列表的長度過短。本文算法推薦課程時取的是LSTM網絡輸出序列的最后一個維度,對應的是出現概率最大的課程,因此推薦列表的長度只有1,在實際推薦系統中,往往需要更多的推薦結果,在后續改進時,可選擇出現概率大的多門課程進行Top-N推薦。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
