領域資訊的個性化建構抽取建模研究*
2019-08-12 02:11:10任斌斌謝振平
計算機與生活 2019年8期
任斌斌,謝振平+,劉 淵
1.江南大學 數字媒體學院,江蘇 無錫 214122
2.江蘇省媒體設計與軟件技術重點實驗室(江南大學),江蘇 無錫 214122
1 引言
隨著網絡媒體的飛速發展,人類進入信息爆炸時代,“信息過載”[1]使得用戶獲取信息時往往會被動地接受一部分不感興趣的信息。而網絡資訊是當前互聯網中信息的重要組成部分,具有較強的時效性,用戶主動去查找感興趣的資訊既耗時又費力,因此個性化資訊服務[2]正成為一種趨勢。
個性化資訊服務以智能代理[3]為基礎,用戶偏好為主導,結合用戶的閱讀習慣,定期地獲取資訊并向用戶做相關推送。現有主要研究包括信息抽取、用戶需求描述、語義理解[4]、情感分析[5]等。目前人工神經網絡[6]在這一方面表現較為出色,但其需要大量的訓練數據致使系統的效率偏低。此外,用戶獲取資訊具有較強的選擇性,如何在數量巨大的資訊中篩選最符合用戶需求的信息,對提升個性化資訊服務的效率和質量有重要意義。
人的學習是個體基于現有知識、經驗生成建構理解的過程。用戶在閱讀資訊時發揮主動性,使得自身知識建構也在不斷變化。用戶利用自身已掌握的知識,結合當下獲取的知識,不斷完善自身知識建構,這是建構主義理論[7-8]的基本思想。為此,本文結合建構主義理論,提出一種平衡組合游走策略,對用戶閱讀資訊、獲取知識的過程進行建模分析,旨在模擬用戶網絡閱讀中認知的建構過程,為個性化資訊服務提供新技術手段。
本文組織結構如下:第2章給出相關網頁抽取技術;第3章對個性化抽取建模進行詳細闡述和分析;第4章以健康領域資訊為對象,進行相關實驗研究;第5章對本文進行總結。
2 相關工作
快速準確地獲取符合用戶需求的網頁是個性化爬取的核心。主題爬蟲[9]是當前個性化爬取主要的工具之一,由主題的描述、主題相關度度量和爬行策略構成。其中主題是對用戶需求的具體描述,主題描述的正確性和相關度度量直接影響網頁抽取的準確性,爬行策略則影響抽取的效率。
文獻[10]中提出自學習主題的爬取算法,執行時用戶僅需輸入一組關鍵詞,以此作為判斷是否爬取網頁的依據。爬取的網頁處理后作為經驗保存形成知識庫,后續的爬取依據知識庫進行,以此循環迭代更新知識庫。文獻[11]中提出基于“經驗樹”的“二次爬行”策略。“二次爬行”考慮后續的爬取受歷史爬取的影響,分別對歷史網頁鏈接和內容進行分析,將二者的相關度作為爬取“經驗”,存儲到“經驗樹”中作為后續爬取的參考,減少因相關度判別導致的誤判。文獻[12-13]中提出結合超文本敏感標題搜索(hyperlink-induced topic search,HITS)算法提取高質量的背景知識,利用概念背景圖來描述用戶需求,并依據背景圖估計鏈接的相關性,有效提升了準確率和召回率。文獻[14]中提出基于概率模型的主題爬蟲并引入網頁質量評價指標和歷史評價指標,較好地解決了“隧道穿越”和“主題漂移”[15]的問題。
上述對于用戶在網頁瀏覽過程中的動態性、選擇性建模還較少考慮,文中借鑒建構主義學習理論思想,考慮用戶在資訊閱讀過程中的動態選擇性特點,研究提出一種新的平衡組合游走建構認知資訊抽取模型。
3 模型框架
真實用戶獲取網絡資訊時具有一定的目的性,本文將這種“目的”描述為用戶興趣。理想的模型應能夠準確描述用戶需求并反映興趣與自身知識作用關系,遂提出平衡組合游走建構認知模型,模擬用戶閱讀資訊和認知的建構過程。首先考慮模型的基本框架,其由數據抽取模塊和用戶資訊建構模塊兩部分組成,設計如圖1所示。
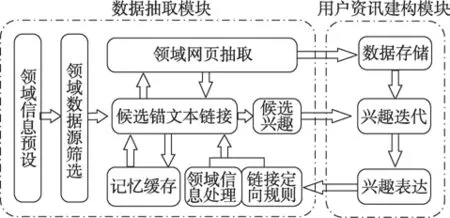
Fig.1 Personalized information extraction modeling framework圖1 個性化資訊抽取模型框架
3.1 相關概念
概念1(興趣點)興趣作為用戶需求的描述,一般具有多樣性,不同興趣點構成興趣,形如:
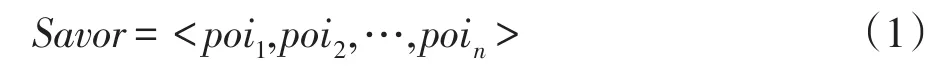
其中,Savor為包含不同興趣點的興趣,poi為相應的興趣點。為便于描述,文中的興趣點用相關關鍵詞詞頻表示,候選興趣點用文章內的top-k關鍵詞詞頻表示。
概念2(經驗性)用戶閱讀網絡資訊是一個自我學習的過程,興趣的經驗性反映了自身建構的相關性和歷史性。用戶的行為具有主觀能動性,在閱讀資訊增加自身知識儲備的同時,其對事物的認識也在不斷變化,因此相鄰時刻用戶的興趣理論上具有一定的繼承,與之對應的是用戶的經驗,即不同興趣之間相同興趣點的二元一致性:
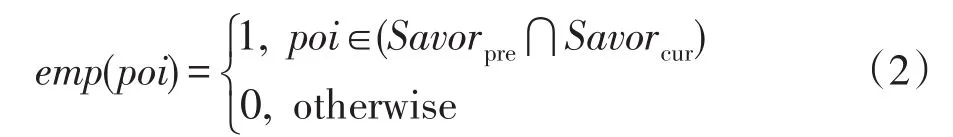
概念3(新穎性)用戶在閱讀資訊時,獲取的新知識也常影響自身的需求,故前后時刻的興趣一般存在一些區別。新穎性可以反映未來時刻用戶認知建構的可能,以當前文章關鍵詞作為候選興趣點,新穎性表現為候選興趣點未出現在前一刻興趣的情況,即候選興趣點與前一刻興趣點的文本差異性:
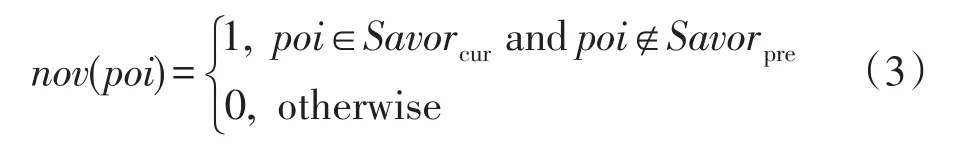
3.2 數據抽取模塊
領域資訊抽取考慮預先確定目標領域信息,并對相應的領域數據源進行甄別和篩選。數據抽取模塊依據相應的領域信息對數據源進行網頁抽取,具體包括領域網頁抽取和頁面分析。頁面分析主要包括鏈接分析和領域文本分析;對于鏈接分析,采用規則提取頁面內的鏈接過濾無關鏈接,并將錨文本(anchor text,At)和鏈接以鍵值對形式保存。領域文本分析是對于包含領域文章內容的網頁,通過分析頁面結構提取文本內容并做主題特征項抽取[16]。為便于表示和計算,采用關鍵詞作為文本特征詞。關鍵詞提取部分包括文本分詞、去除停用詞和統計詞頻,結果以鍵值對保存:
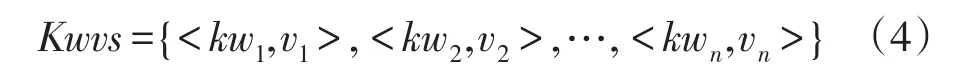
式中,kw表示相應的關鍵詞,v表示與之對應的詞頻,通過計算關鍵詞相關度判斷框架中的鏈接與用戶興趣的相關性,確定下一個瀏覽的頁面。由于用戶對過目的事物具有短暫記憶能力,故將未訪問的鏈接作為緩存暫時保留,并通過迭代算法生成下一時刻的興趣。如果當前頁面內沒有符合需求的鏈接,用戶則可以通過回憶近期瀏覽的網頁,從中選取某條相關的鏈接并訪問,如此循環,直至達到終止條件。
3.3 用戶資訊建構模塊
用戶閱讀資訊既是學習豐富知識的過程,也是建構、不斷完善自身系統的過程。用戶資訊建構模塊負責對用戶的認知進行表達與更迭,并對獲取的數據進行存儲。結合空間向量模型對用戶興趣進行建模[17],給予不同興趣點各自權重以表示其受感興趣程度,形式如下:
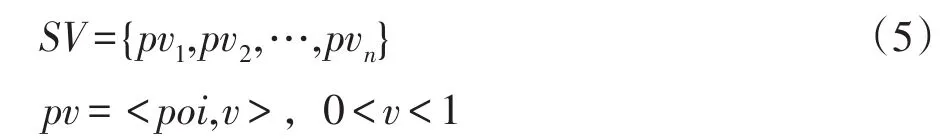
其中,poi為興趣點,對應興趣為Savor=<poi1,poi2,…,poin>。v表示受感興趣程度,對應向量為vector=<v1,v2,…,vn>,v∈(0,1)。用戶感興趣則v必不為0,本文考慮用戶興趣的多樣性(興趣數大于1),故v值小于1。使用當前網頁提取的top-k關鍵詞作為候選興趣點,結合式(4)構建候選興趣SVcur。
本文個性化資訊抽取結合建構主義理論,充分考慮用戶主觀性,獲取符合其興趣的領域信息。通常用戶瀏覽資訊后獲取了一定的信息,自身的知識建構一般會改變,因此產生的興趣也會區別于前一刻。
興趣點更新。依據興趣的經驗性,興趣點更新是針對前后興趣具有的相同部分。對公共項的權重用以下公式進行更新:
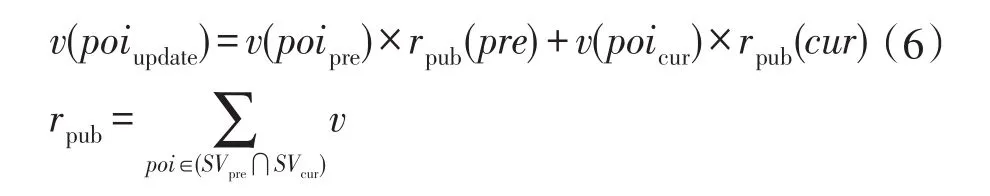
其中,rpub為各興趣對應公共項的權重和,v(poipre)和v(poicur)分別為對應公共項的權重,v(poiupdate)為更新后的公有興趣點的權重,故更新后的興趣pvupdate=<poipub,v(poiupdate)>。約定SVpre?SVcur=?時,用戶興趣與當前頁面產生的候選興趣點無相關性,此時用戶興趣不更新。
興趣點增加。上文所述興趣點的新穎性可以反映未來時刻用戶認知建構的可能,故新穎性是興趣點增加的重要依據。本文考慮使用關鍵詞權重作為興趣點,增加的興趣點為候選興趣點的若干項,作為增加的項,其必不包含在初始興趣內,即二者差集:
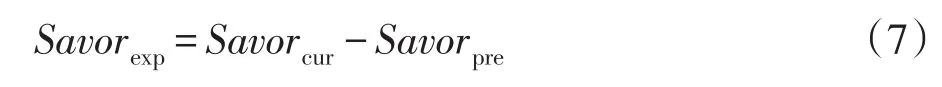
其中,Savorcur為當前候選興趣集合,Savorpre為當前興趣集合,對應權重計算如下:
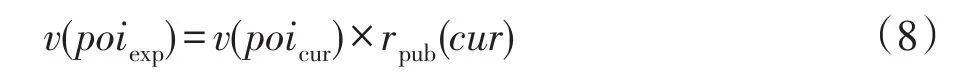
故增加的興趣pvexp=<poiexp,v(poiexp)>。
興趣點刪除。興趣點刪除一定程度上也屬于興趣點更新。雖然本文考慮興趣多樣性,但并不意味著興趣點越多越好,合適的興趣量才能模擬真實用戶的認知建構過程,故對興趣點根據權重作top-k選擇,權重過低的興趣點被刪除。
經過相應的更新、增加和刪除,迭代后的興趣應為:
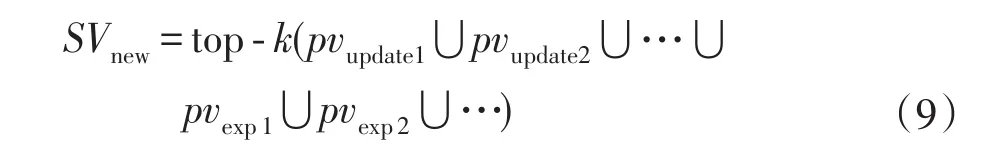
具體算法如下:
算法1興趣建構迭代算法
輸入:初始興趣SVpre,候選興趣SVcur。
輸出:迭代興趣SVnew。
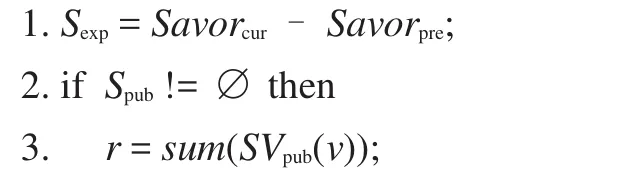
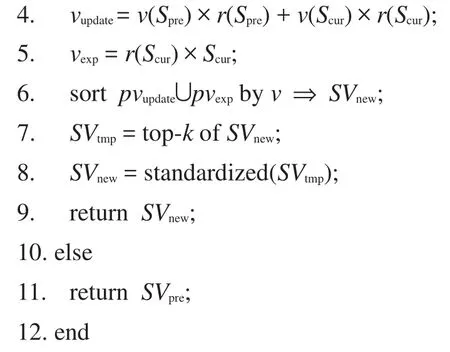
算法中步驟1獲取當前可擴展興趣點,步驟3計算當前興趣和候選興趣各自的權重因子r,步驟4~5根據對應的r對初始興趣SVpre內興趣點的權值進行更新,并計算可擴展興趣點的權重,步驟6~9對更新的興趣點和擴展的興趣點求并集,根據權值進行排序取top-k項作為迭代后的興趣,標準化并返回。
3.4 模型實現
現實中用戶通過點擊網頁鏈接來閱讀網頁,點擊的順序即瀏覽網頁的順序。不同的閱讀順序對用戶認知建構影響不同,最終自身的信息儲備也不同。一般來說用戶閱讀習慣存在差異性,因此考慮不同點擊序列下,用戶興趣的建構情況。
可能有用戶偏向于“最優優先”策略,即在當前頁面內選出最感興趣的資訊進行閱讀。由于每次只能選出一個最優鏈接,并不斷深入獲取網頁,形式上類似于深度優先策略。
另有可能用戶偏向于在當前頁面內選出自己感興趣的網頁,在后臺中全部打開后依次閱讀,形式上則類似于廣度優先策略。
還有部分用戶善于主動發現和獲取知識,在瀏覽網頁時,通過不斷回憶閱讀歷程,結合當前的認知,溫故知新,以獲取新的網頁。從此類用戶學習行為方式出發,本文提出平衡組合游走策略。
平衡是指瀏覽網頁時對網頁鏈接的平衡選擇,其本質上是深度優先與廣度優先的平衡組合[18]。通常依據當前搜索需求計算分析候選網頁的跳轉概率,以做出局部最優選擇。本文方法結合人類的閱讀習慣,融入建構游走策略,圖2簡略描述了組合游走策略與常規策略的差異。圖(a)示例了網站網頁間的鏈接情況,其中各節點表示若干網頁,相鄰的網頁節點間存在互鏈接;圖(b)描述的深度優先策略下,網頁的獲取序列為ABCDEFGHIJ;圖(c)描述的廣度優先策略下的序列為ABEHCDFGIJ;圖(d)描述平衡組合策略下的序列為ABDEGHCJ,其中ABD、EG、HJ為常規網頁瀏覽路徑,DE、GH為組合策略下的瀏覽路徑,HCJ為游走策略下的瀏覽路徑。路徑HC表示,雖然網頁C在最初的瀏覽過程中由于低相關性而被“忽略”,但隨著興趣的更迭,用戶逐漸發現網頁C符合自身當前的需求,遂“回憶”并瀏覽該網頁。同理,路徑CJ也是如此。
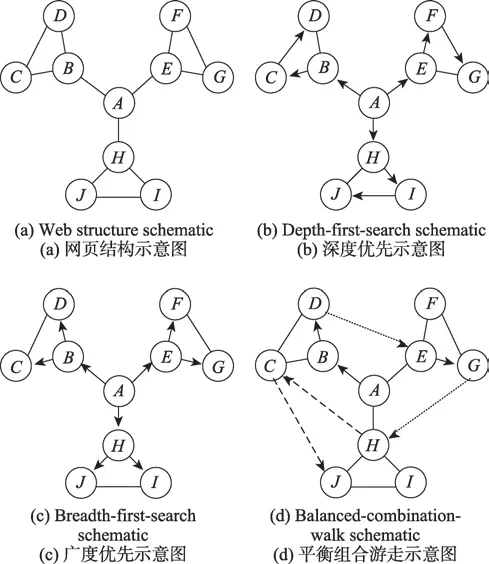
Fig.2 Comparison of different strategies圖2 不同策略對比
另一方面,人腦的短暫記憶能力,使得對近期瀏覽的網頁有較強的記憶,模仿提出網頁層次優先級(pagelevelpriority)和鏈接新鮮度(linkfreshness,LF)。網頁層次優先級是描述最近瀏覽網頁的順序,其數值上越大表示越近的瀏覽。鏈接新鮮度反映鏈接出現的時間度量,其數值上等于對應的網頁優先級。考慮到網頁間形成的有向圖的連通性,低新鮮度的鏈接可能會出現在高優先級的網頁內,約定此時的鏈接新鮮度為最大的網頁優先級,即:
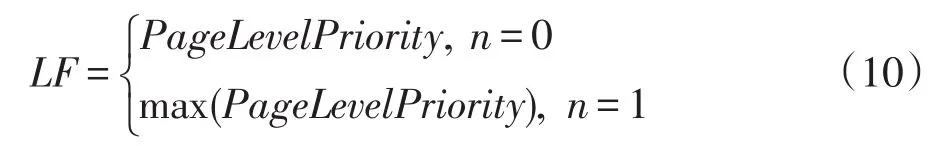
其中,n表示鏈接是否出現在當前頁面內。鏈接新鮮度可以區別于不同歷史時刻的鏈接記錄,可以反映用戶對該鏈接的記憶程度。用戶在閱讀新的網頁時,原先網頁的優先級和新鮮度分別遞減。此外,考慮用戶瀏覽當前頁面,興趣不發生改變的情況,依據本文策略,通過回憶近期瀏覽的頁面確定新的訪問鏈接。
基于上文闡述,對平衡組合游走策略進行具體描述。用網頁鏈接池來容納候選鏈接,包括網頁抽取模塊獲取的當前頁面內的鏈接及與模塊中存儲的近期保存但未訪問的部分鏈接(即模塊中的緩存鏈接),經過相應的計算得到下一訪問鏈接。結合考慮興趣點的新穎性與經驗性平衡要求,設計引入如下公式進行鏈接重定向計算:
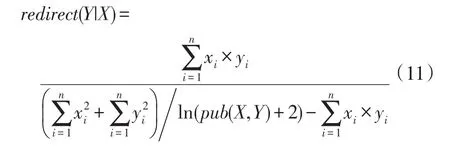
式中,pub(X,Y)=|{xi×yi|xi×yi≠0}|,其中|X|=|Y|。
算法2鏈接選擇算法
輸入:錨文本鏈接URLs_At,用戶興趣SV。
輸出:重定向錨文本鏈接

算法中第1行表示初始化序列,第3~4行分別對錨文本分詞去除停用詞、計算關鍵詞詞頻,第5~7行將兩組關鍵詞詞頻向量化,按照式(11)計算頁面跳轉概率,并獲取跳轉概率最大的錨文本和鏈接。
3.5 分析討論
本文考慮以關鍵詞輔助實現用戶興趣建模,何時建構以及如何建構是影響興趣的重要因素。對于如何建構興趣,前文已詳細介紹。考慮實際情況中不同用戶主動性與思維活躍性的差異,提出建構間隔(construction interval,CI)作為興趣建構的時間效率描述,其數值上等于兩次興趣迭代間的網頁爬取數。建構間隔較短,表明用戶思維活躍,獲取信息的能力較強。
互聯網的實質是一個龐大的分布式網絡數據庫[19],其中部分網站具有較強的領域性,爬取這些網站的網頁實際上是遍歷網頁組成的有向圖。遍歷的方式影響網站的爬取效率,對于用戶而言,閱讀網頁的次序則影響其獲取知識的效率。通常網頁節點的出度較大,即外鏈數目較多,考慮模擬用戶閱讀網絡資訊,提出平衡組合游走建構認知抽取模型。模型的關鍵問題在于如何平衡地選擇網頁鏈接,考慮網站的爬取深度,提出鏈接新鮮度(LF)作為衡量鏈接在時間上被選擇的可能。由于用戶短暫記憶能力,較新鮮的鏈接被選擇的可能較大,故將鏈接新鮮度作為鏈接選擇的標準之一。鏈接新鮮度影響網頁的爬取范圍,合理的鏈接新鮮度對爬取效率應有一定的提升。
個性化數據抽取模型中,復雜度主要考慮鏈接選擇部分和興趣迭代部分,其中讀取緩存的復雜度為O(M),鏈接選擇和興趣迭代部分分別對鏈接重定向值和興趣權重采用快速排序,因此鏈接選擇部分時間復雜度為O(M+NlbN),興趣迭代部分時間復雜度為O(NlbN)。考慮本文采用局部抓取,僅獲取網站中部分感興趣的網頁,時間復雜度是可以接受的。
平衡組合游走的策略區別于常規的爬取策略,更加接近于人類的閱讀選擇習慣。該策略不追求全局爬取,僅獲取自身感興趣的部分,獲取網頁的同時能夠根據已獲取的信息對自身認知進行建構更新,符合建構主義思想。
(4)最后一公里問題突出。物資集聚于外圍,無法分發到災民手中。最后一公里問題凸顯。物資投送需要多元化,可以考慮配備救災摩托車,用于運送必要的生活用品和輕型救災裝備。
4 實驗研究
4.1 實驗方案
本文考慮以食品健康資訊為實驗對象,對平衡組合游走建構認知模型進行性能分析。實驗素材方面以食品伙伴網(http://news.foodmate.net)的食品資訊中心作為資訊抽取數據源,預爬取10 000個資訊網頁作分析,以Jieba(https://github.com/fxsjy/jieba)作為分詞工具對網頁中提取的領域文本進行分詞、去除停用詞并統計詞頻。
為對比研究平衡組合游走策略的性能,以深度優先和廣度優先策略作為參照。對于用戶的興趣建構,選取權重最高的top-k興趣點作為更新后的興趣,k值暫考慮10,分析模型中不同參數CI和LF下的爬取效率以及用戶興趣建構情況。區別于現有考慮爬取精度的全局爬取方法,本文從模擬用戶閱讀的角度出發實現抽取部分網頁,故不與現有方法對比。
4.2 評價指標
網頁爬取效率f是指獲取的網頁的相對覆蓋度。通常某一資訊網站內包含大量資訊,由于其中部分資訊描述相似主題,因此網站內的主題數相對于資訊數是較少的,可以認為網頁爬取效率為已獲取的主題數與網站總主題數的百分比:

其中,topiccur為當前已獲取的主題數,topictotal為網站內包含主題的總數,由于本文使用關鍵詞詞頻作為文章的主題,隨著獲取的主題數不斷增加,爬取效率f用以下式子近似表示:
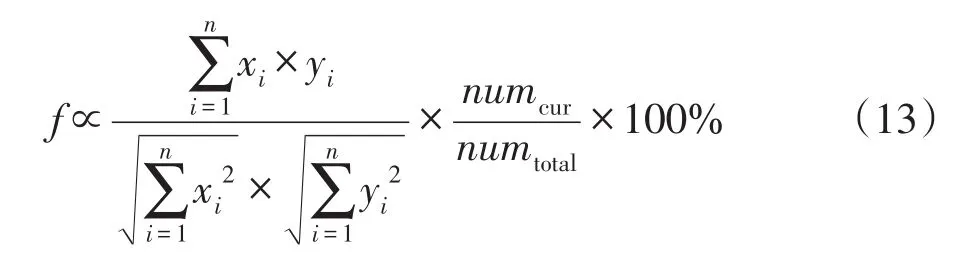
式中,x、y分別為對應關鍵詞的權重,numcur為當前已獲取文本關鍵詞數,numtotal為網站中所有頁面文本關鍵詞總數。
為描述用戶興趣的建構過程中的變化情況,考慮用相鄰時刻興趣的歐氏距離作為其語義距離:
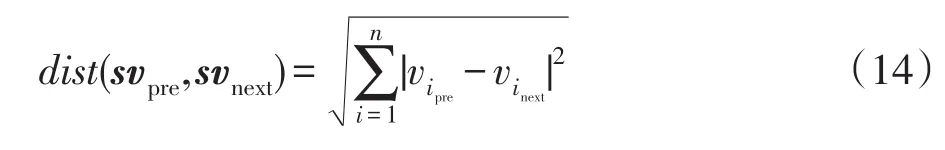
4.3 實驗結果與分析
平衡組合游走的個性化爬取模型需要初始設定的參數有建構間隔CI和鏈接新鮮度LF。建構間隔描述興趣迭代更新的頻次,適當的建構間隔會較符合用戶興趣的建構歷程。鏈接新鮮度描述鏈接被保存的歷史性,鑒于用戶有限的記憶能力,新鮮度較低的鏈接一般會選擇性丟棄。
首先分析無參數下的抓取性能,考慮平衡策略與深度優先和廣度優先策略的抓取效率。深度優先和廣度優先暫不考慮鏈接新鮮度的情況,設定用戶的初始興趣為“<奶粉,0.4><國內,0.3><市場,0.2><配方,0.1>”,假設此時興趣建構間隔為1,圖3反映了三種方法抓取效率的具體情況。
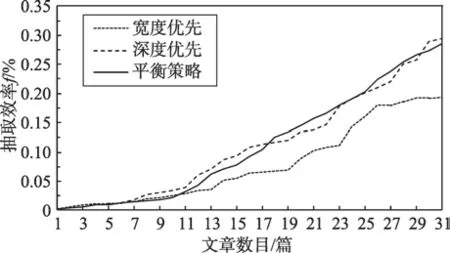
Fig.3 Information extraction efficiency using DFS,BFS and balanced strategies圖3 深度優先、廣度優先、平衡策略下資訊抽取效率
由圖3可知,深度優先的抓取效率總體上高于廣度優先策略。通常網頁中同一版塊內資訊的主題具有一定的相似性,深度優先策略可能較容易穿越不同版塊,獲取更多的主題,爬取效率優于廣度優先策略。平衡策略在抓取初期效率稍低于深度優先策略,但隨著抓取時間的增加,以及考慮興趣的建構更迭,后續獲取的主題數逐漸增多,爬取效率也較高。
進一步分析不同參數下,平衡組合游走策略的性能。前文考慮用戶自身短暫性記憶能力,提出鏈接新鮮度以反映鏈接在記憶層面被選擇的可能,故不同鏈接新鮮度下,網頁的瀏覽路徑有差異。此外,依據不同歷史記憶所產生的瀏覽網頁順序也會有所不同,而用戶的主題信息認知建構方式也會存在個性差異,本文模型中考慮以建構間隔(CI)反映個體認知建構的能力。考慮這兩點,對不同參數下的性能作分析。
圖4反映了在本文平衡策略下,不同鏈接新鮮度(LF)和不同興趣建構間隔(CI)下的爬取情況。可以看出,在爬取初期,不同參數下的爬取效率較相近,但隨著興趣的不斷迭代,爬取效率差距較為明顯。在鏈接新鮮度相同時,興趣建構間隔較短,網頁的爬取效率相對較高,即用戶思維較活躍時,能夠較高效地瀏覽網頁。可見,LF=-3,CI=1時,模型的爬取效率最高。這一結果反映了歷史記憶對獲取網頁信息的作用,在思維活躍時,丟棄新鮮度較低的網頁可以加速用戶瀏覽網頁的速度,提高建構學習的效率。
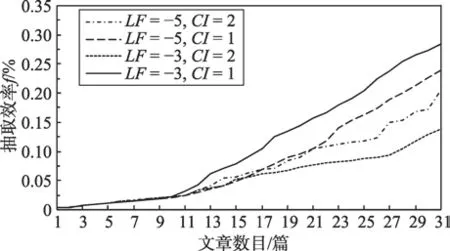
Fig.4 Web page extraction efficiency of balanced strategies with different LF and CI圖4 不同LF和CI下平衡策略的網頁抽取效率
表1進一步示例地給出了LF=-3、CI=1時平衡策略下用戶興趣的變化情況。如表中所示,在爬取前5篇資訊時,用戶的興趣主要在“奶粉”“配方”“嬰幼兒”等之間浮動。隨著后續興趣的不斷變化,最終用戶的興趣轉移到“食品”等其他興趣點上。
進一步可知,興趣的語義距離可反映興趣變化發展情況。圖5給出了LF=-3,CI=1時代表性模擬仿真的興趣變化距離情況。可以看出,用戶的興趣大多數情況下雖有不同程度變化,但相對較為穩定。
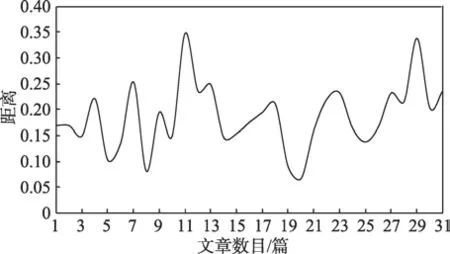
Fig.5 User's interest distance whenLF=-3andCI=1圖5 LF=-3,CI=1時用戶的興趣距離

Table 1 Some interest samples generated by balanced constructivist strategy withLF=-3andCI=1表1 LF=-3和CI=1時平衡建構算法產生的興趣示例
4.4 真實用戶模擬實驗
為進一步分析模型性能,邀請了部分同學進行了仿真實驗。實驗中先告訴實驗者本文的需求,即用戶的預設興趣,以指導他們獲取符合需求的網頁。模擬了LF=-3時,用戶獲取網頁的情況,表2列出了LF=-3時實驗者與算法模擬獲取網頁后部分興趣點變化情況。
表2較為直觀地反映人類用戶興趣的變化與算法模擬用戶興趣建構的情況。人類用戶自身主觀性較強,最終定位到感興趣的“鴨血粉絲”上,而依據規則的模型最終興趣點定位在“白酒”上。
圖6反映了LF=-3時真實用戶和本文框架中三種策略獲取資訊的情況。從圖中可以看到三種策略在資訊獲取初期效率相當。隨著獲取資訊的量不斷增加,用戶獲取資訊的效率明顯高于文中三種策略。后續的資訊抽取中,廣度優先策略效率最低,深度優先策略效率提升緩慢,平衡策略下抽取效率穩步提升,有逼近真實用戶的趨勢,這顯示本文提出的平衡策略更接近用戶的網絡閱讀行為,也一定程度上表明了平衡建構認知建模的合理性。
4.5 應用實施
考慮將本文方法應用于一個知識服務平臺,以更好地提供個性化領域資訊的服務性能。相應地,平臺架構如圖7所示。
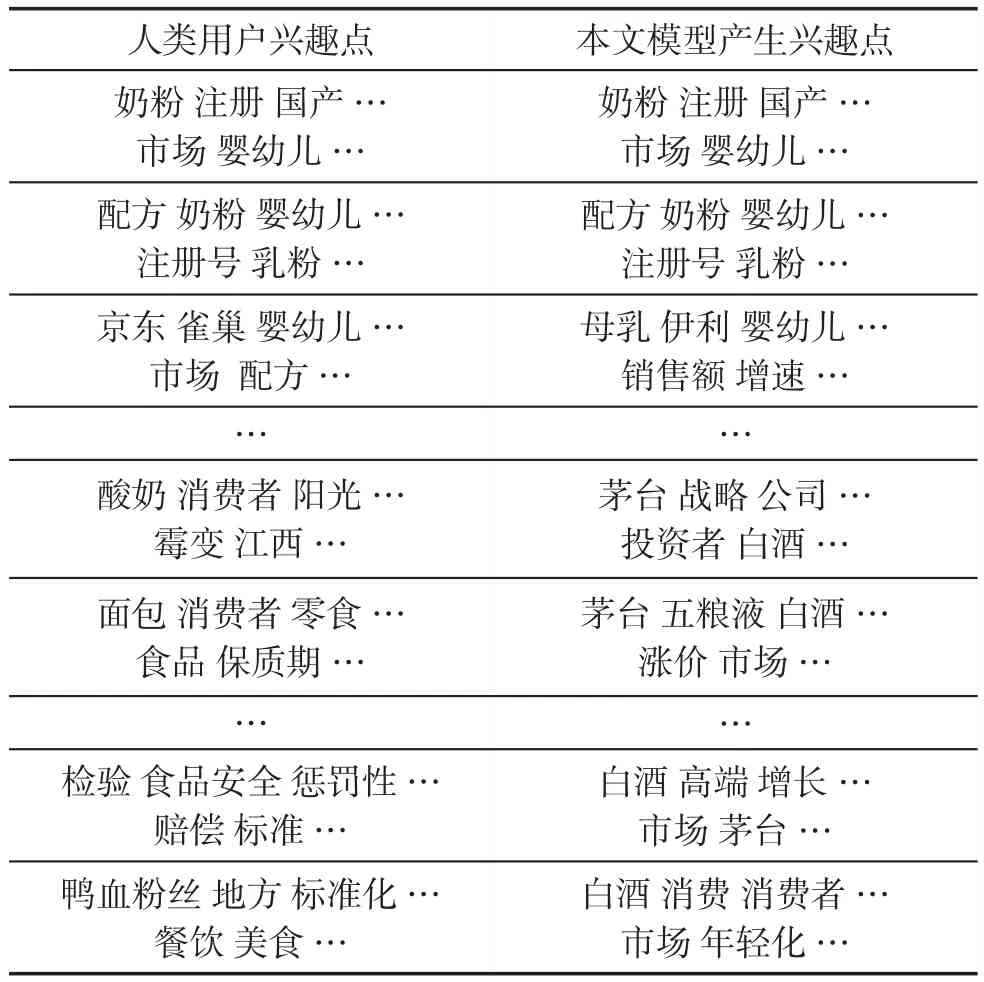
Table 2 Interest samples simulated by human user and model of this paper表2 人類用戶與本文模型產生興趣點對比
圖7描述了該平臺中個性化資訊服務的運用策略,圖中虛線方框部分即本文提出的框架模型,為個性化資訊服務提供業務支撐。項目部署中涉及的語料主要包括兩個來源:一方面是人工預先篩選的外部語料庫,具體包括專業網絡資料庫和領域資訊庫等;另一方面則是平臺附帶的檢索庫,二者協同為用戶提供資訊服務。平臺根據用戶知識建構系統提供的用戶特征信息,實現對外部語料庫的抽取,同時補充豐富本地檢索庫,降低后續服務的開銷。
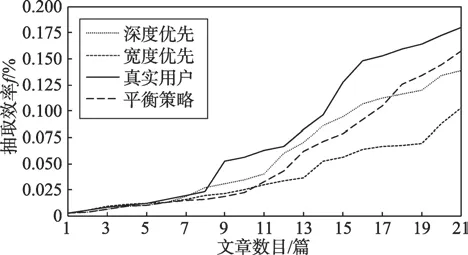
Fig.6 Comparison of efficiency between real users and method of this paper圖6 真實用戶和本文策略的效率對比
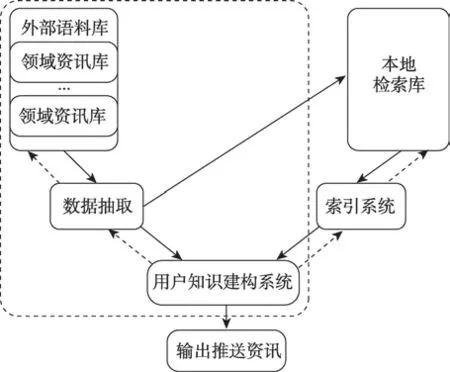
Fig.7 Framework of recommended application system圖7 建議的應用平臺架構
在用戶知識建構系統中,可使用關鍵詞詞頻描述用戶興趣需求,若系統經過用戶信息采樣后得出當前用戶的興趣為“<蛋白質,0.5><奶粉,0.5>”,其若干次讀取資訊后,興趣經過建構更新變為“<奶粉,0.362 496><嬰幼兒,0.161 392>…<人之初,0.047 253><雀巢,0.042 557>”,由最初感興趣的“蛋白質”和“奶粉”擴展到“嬰幼兒”等領域相關的術語乃至部分品牌,體現興趣的經驗性與新穎性。同時平臺依據本文平衡組合游走策略,抽取領域資訊并進行推送。
5 結束語
為提升領域個性化資訊服務質量,結合建構主義學習理論思想,提出了平衡組合游走建構認知的個性化領域資訊抽取模型,模擬用戶網絡閱讀的行為。
文中的理論和實驗結果表明,平衡組合游走策略相對于深度優先和廣度優先策略,更加接近人類的資訊閱讀過程,同時客觀反映了個體知識建構過程。在實際應用中,閱讀資訊的語義認知描述值得進一步深入研究,以盡可能模仿人類用戶閱讀行為。
猜你喜歡
阿來研究(2021年1期)2021-07-31 07:38:26
新世紀智能(高一語文)(2020年9期)2021-01-04 00:42:46
甘肅教育(2020年14期)2020-09-11 07:57:42
幼兒教育·父母孩子版(2016年12期)2017-05-24 13:11:53
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
新課程研究(2016年21期)2016-02-28 19:28:33
時代英語·高二(2015年1期)2015-03-16 00:08:11
創業家(2015年5期)2015-02-27 07:53:25
