基于NIRS技術和PCA-SVM算法快速鑒別國產和進口啤酒花
2019-08-08 01:38:04郭云香李曉瑾王果平蔣益萍辛海量賈曉光
藥學實踐雜志 2019年4期
關鍵詞:模型
郭云香,陳 龍, 李曉瑾,王果平, 蔣益萍 ,辛海量, 賈曉光
(1 新疆醫科大學 中醫學院,新疆 烏魯木齊 830011;2 新疆維吾爾自治區中藥民族藥研究所,國家中醫藥管理局新疆中藥民族藥資源重點實驗室,新疆 烏魯木齊 830002;3 海軍軍醫大學藥學院生藥學教研室,上海 200433;4 襄陽市中心醫院 湖北文理學院附屬醫院,湖北 襄陽 441021;5 湖北中醫藥大學 中藥資源和中藥復方教育部重點實驗室,湖北 武漢 430065)
啤酒花HumuluslupulusL.為桑科葎草屬啤酒花的干燥雌性球穗狀花序,不僅是釀造啤酒的重要添加原料[1]。在我國還作為民族藥使用。被收錄于《新疆藥用植物志》《內蒙古植物藥志》《寧夏中藥志》《哈薩克藥物志》《四川中藥志》等,具有止咳化痰、健胃、消食、鎮靜、利尿的功效,為藥食兩用的新疆特色資源植物[2]。在歐洲,啤酒花提取物用于緩解更年期的潮熱不適以及絕經后骨質疏松癥[3]。傳統啤酒花生藥的鑒別方法有顯微鑒定、理化鑒定[4]及非線性化學指紋圖譜[5-6]等,但這些方法都存在實驗復雜、檢測時間過長等缺點。近紅外漫反射光譜技術(NIR)其無損、快速、準確的優點能夠反映樣品的綜合信息,在植物藥[7]、動物藥[8]和礦物藥[9]中均有涉及,能反映分子中C-H、N-H、O-H基團基頻振動的倍頻吸收與合頻吸收。本研究將運用近紅外漫反射光譜(NIRS)技術,將主成分分析(PCA)和支持向量機(SVM)等化學計量學算法相結合,建立快速無損的PCA-SVM識別模型,用于國產和進口啤酒花的快速鑒別。
1 儀器與材料
1.1 儀器
MPA傅里葉變換近紅外光譜儀(德國布魯克光學儀器公司,配備固體積分球漫反射附件),OPUS 7.5 采集和處理軟件(德國布魯克光學儀器公司),MATLAB R2014b軟件(美國Math Works公司)。
1.2 樣品
2017年采集的國內外不同地方的啤酒花樣品均經第二軍醫大學藥學院生藥教研室辛海量副教授鑒定,并密封存放于干燥陰涼處,詳細采集信息見表1。

表1 啤酒花樣品產地來源及采集時間

(續表1)
2 方法與結果
2.1 近紅外光譜采集
共計56批樣品,分別取2g置于樣品瓶中,采用積分球漫反射測試模式掃描NIR光譜。光譜掃描范圍4 000~12 500 cm-1,掃描次數32次,儀器分辨率為8 cm-1。每個樣品重復掃描3次,取平均值作為該樣品的分析光譜。所有樣品NIR光譜見圖1。
2.2 樣本集劃分及類別標簽值設定
將56批樣品按2:1比例隨機分為校正集和測試集2個子集,校正集訓練模型,并以內部交叉驗證法驗證模型性能,測試集對所建模型進行預測能力評價。采用矢量歸一化法(VN)、一階導數(FD)、二階導數(SD)對樣品進行光譜預處理,運用PCA-SVM算法,以 RBF(高斯徑向基核函數)為核函數,分別采用網格搜索優化法、遺傳算法(GA)、粒子群算法(PSO)并結合五折交叉驗證法進行建模,并以五折交叉驗證準確率為指標,對SVM模型參數組合(c,g)進行尋優,用尋優所確定的最佳參數建立PCA-SVM模型,并用所建模型對校正集和測試集樣品進行預測,計算預測準確率。具體分集信息見表1。
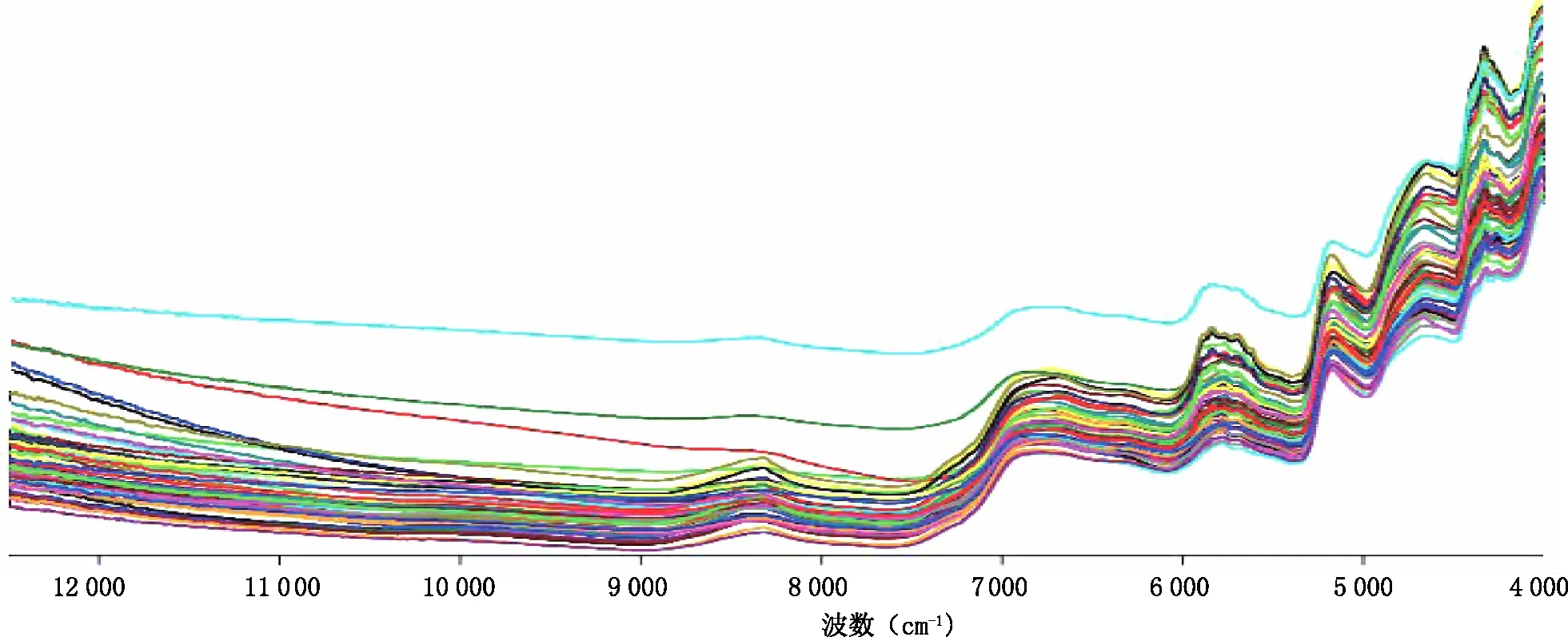
圖1 56份啤酒花樣品的近紅外原始光譜疊加圖
2.3 PCA降維及光譜預處理
2.3.1PCA降維
PCA是一種將原來多個具有一定相關性的眾多指標,重新組合成一組新的互相無關的綜合指標的統計分析方法[11]。運用PCA方法對近紅外光譜數據特征提取和壓縮,對多維數據進行降維,去除輸入隨機向量之間的相關性,突出原始數據中的隱含特性,可消除眾多信息共存中相互重疊的信息部分。選擇特征值較大的幾個主成分作為特征變量進行模式識別[12]。
在OPUS軟件中,將校正集樣本初始建模譜段的原始光譜數據,進行PCA降維處理,提取前兩個主成分,利用各樣品的第一主成分(PC1)和第二主成分(PC2)得分值繪制平面散點圖(圖2)。
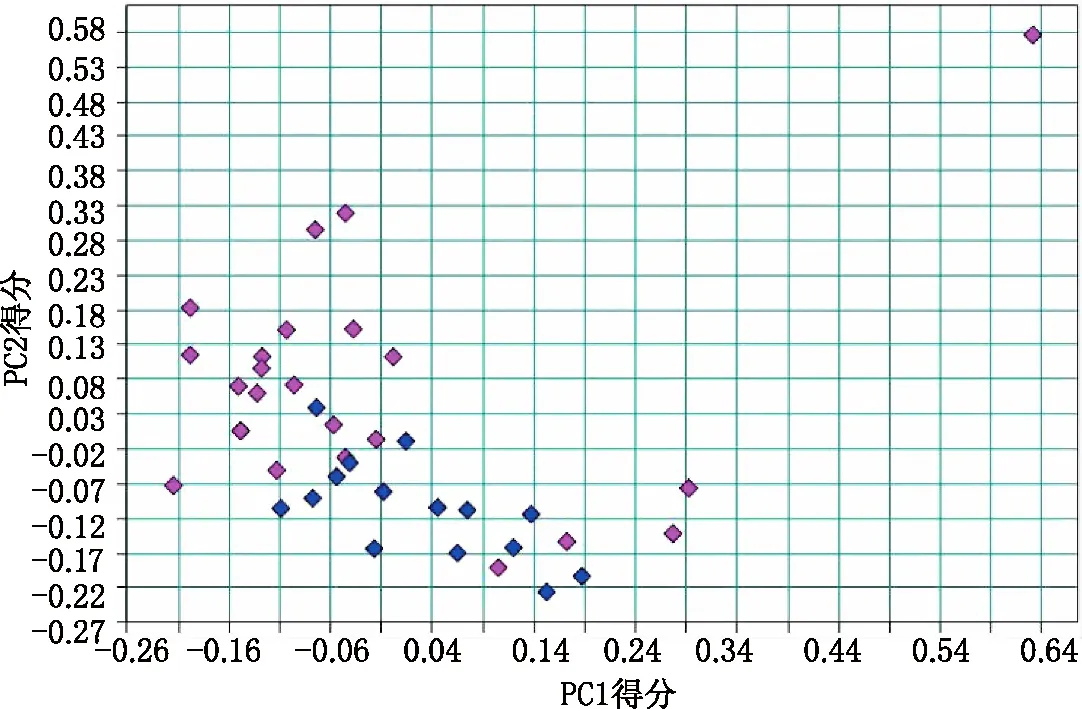
圖2 第一主成分(PC1)和第二主成分(PC2)得分平面散點圖 進口:藍色;國產:紅色
2.3.2光譜預處理
在用近紅外漫反射儀進行光譜信息采集時,得到的樣品信息包括除自身信息外的無關信息,例如由于儀器、樣品粒徑大小、裝樣量、重復測量次數等引起的基線不平、噪音干擾,為了得到可靠的信息,需要對光譜進行預處理以消除干擾,建立更可靠的模型。采用光譜預處理方法有矢量歸一化法(VN)、一階導數法(FD)、二階導數法(SD)建立定性模型,并以模型效果確定最佳預處理方法。
為確定最佳的光譜預處理方法,提取有效的主成分。利用Matlab R2014b軟件,在訓練集樣品的9 000~4 100 cm-1譜段,分別對VN,FD或SD預處理后的光譜進行PCA降維,并提取不同預處理條件下的前兩個主成分,利用各樣品的第一主成分(PC1)和第二主成分(PC2)得分值繪制平面散點圖(圖3)。
由圖3可知,校正樣品經VN、FD、SD預處理后可見鑒別趨勢,但VN、SD預處理后部分同類別樣品分布較近,易混淆。而校正集樣品的光譜經FD預處理后,其主成分得分的散點圖上,同類樣品彼此靠近,異類樣品彼此分離,相比于其他預處理方法,其分類效果最佳,故確定FD為最佳光譜預處理方法。光譜在9 000~4 100cm-1譜段的光譜經FD預處理后,消除了基線漂移,同時光譜峰差異得到顯著放大,更有利于進行品種鑒別。
2.4 特征譜段篩選
在9 000~4 100 cm-1譜段中還包括水的特征吸收7 500~6 500 cm-1,5 400~5 000 cm-1。此外還有尚不明確的干擾信息,因此,為簡化模型,消除干擾,提高模型穩定性,對建模譜段進行篩選。在不降低模型鑒別能力的情況下,盡可能縮小建模譜段的范圍。
由圖4,在排除水分的干擾后,初始建模譜段可被分為3部分:9 000~7 500 cm-1,6 500~5 400 cm-1,5 000~4 100 cm-1,故將上述SD預處理后的三個譜段,分別進行PCA降維,提取前兩個主成分,繪制主成分得分散點圖(圖5)。由圖5可見6 500~5 400 cm-1譜段效果最佳,該譜段條件佳,PCA得分散點圖上,同類樣品點相對集中,異類樣品點能較好分離。但3批樣品出現類別混亂。尚需進一步的優化。
因此,選取6 500~5 400 cm-1譜段,以FD為最佳預處理方法進行光譜預處理,以PCA提取主成分,獲得各樣品光譜的主成分得分,作為SVM模型的輸入變量,建立國產和進口啤酒花的近紅外光譜PCA-SVM定性分析模型。

圖3 光譜預處理VN、FD、SD散點圖 A.矢量歸一化法散點圖;B.一階導數法散點圖;C.二階導數法散點圖
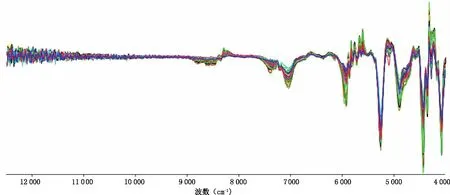
圖4 啤酒花樣品的一階導數NIRS
2.5 SVM建模
2.5.1SVM算法
SVM算法[13]是一種基于統計學理論的新的機器學習方法,SVM通過尋求結構化風險最小來提高學習機泛化能力,實現經驗風險和置信范圍的最小化,達到在統計樣本量較少的情況下,獲得良好統計規律的目的。在解決小樣本、非線性、高維數據時具有很大優勢,在很大程度上能夠克服“過學習”和“維數災難”等問題。SVM常用核函數有多項式、Sigmoid感知核和高斯徑向基核(RBF)。其中,RBF核函數[14]是應用最廣泛的核函數,適用于低緯、高維、小樣本或大樣本等情況,是較為理想的分類依據函數。
2.5.2內部參數優化
在RBF為核函數的SVM算法中有2個重要的參數:懲罰因子c和核函數參數g,不同參數所建立的模型的預測能力不同,故參數優化的方法在建模過程中有著很大的影響。網格搜索法(GS)是SVM問題上應用最為普遍的參數尋優算法,它是將參數(c,g)在一定的空間范圍中劃分成網格,從網格中全部的點中找到最優參數[15]。此外,遺傳算法(GA)和粒子群算法(PSO)是近年來迅猛發展起來的智能算法,GA算法是借鑒生物界自然選擇和遺傳機制,利用選擇、交換和突變等算法的操作,隨著不斷的遺傳迭代,保留目標數據較優的變量,最終達到最優結果的一種方法[16]。PSO算法模擬鳥群飛行覓食的行為,通過鳥之間的集體協作使群體達到最優目的。在PSO算法系統中,每個備選解被稱為一個粒子,多個粒子共存、合作尋優,每個粒子根據其自身的經驗和相鄰粒子群的最佳經驗在問題空間中向更好的位置飛行,搜索最優解[17]。
基于上述原理,本文使用了RBF核函數建立國產和進口啤酒花的SVM模式分類模型。模型以FD預處理的樣品光譜(6500-5400cm-1)經PCA提取的前兩個主成分得分為SVM輸入變量,以各類樣品的類別標簽值為輸出,分別采用網格搜索優化法、GA、PSO并結合五折交叉驗證法,以五折交叉驗證準確率為指標,對SVM模型參數組合(c,g)進行尋優,用尋優所確定的最佳參數建立PCA-SVM模型,并用所建模型對校正集和測試集樣品進行預測,計算預測準確率。綜合考慮五折交叉驗證準確率、校正集預測準確率和測試集預測準確率,對PCA-SVM模型進行評價。不同尋優方法的尋優過程見圖6所示,所得參數建立的SVM模型效果見表2。
綜合對比上述預測準確率,準確率越高,模型越好,據此判斷最佳SVM模型。由表2,不同尋優方法下,兩個主成分所建PCA-SVM模型的效果一致。但PSO尋優所確定的c值偏大而g值偏小,該選優方法不合適。對比網格搜索法和GA尋優過程,發現GA尋優操作更為復雜,且具有一定隨機性,故確定網格搜索法為最佳。依據網格尋優結果,確定最佳c和g值均為1,利用前2個主成分得分值建立的PCA-SVM模型對校正集和測試集預測準確率均較高(>85%)。但考察主成分累計貢獻率變化(圖7),前兩個主成分累計貢獻率為91.70%(<95%),2個主成分包含原光譜數據的信息量有限,是否為最佳建模主成分數尚不明確,故對主成分數進行優選,進一步提高PCA-SVM模型性能。

圖5 不同建模波段的一階導數PCA得分散點圖 A.9 000~7 500 cm-1;B.6 500~5 400 cm-1;C.5 000~4 100 cm-1
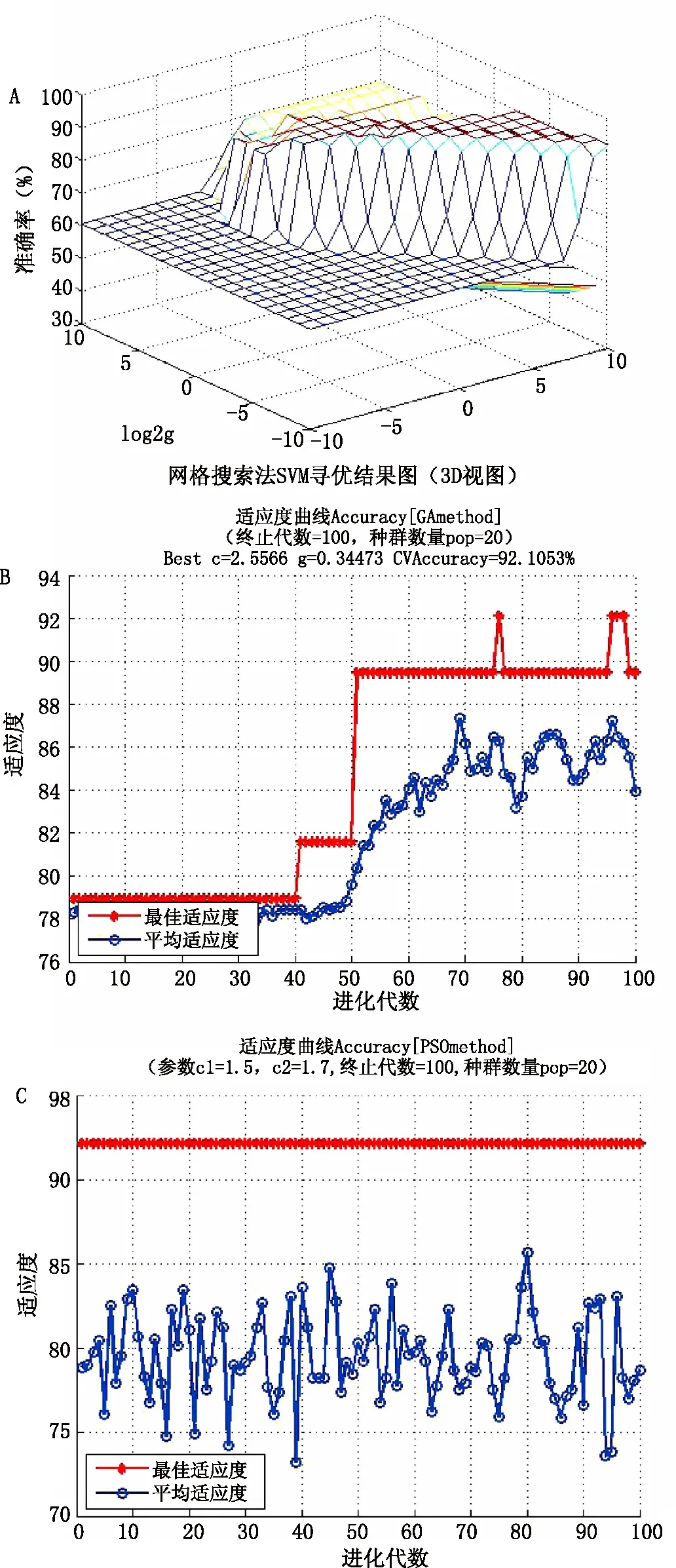
圖6 SVM內部參數尋優過程圖 A.網格搜索優化法;B.遺傳算法;C.粒子群優化算法

尋優算法主成分數cg準確率/%五折交叉驗證校正集測試集網格21192.1192.11(35/38)88.89(16/18)GA22.55660.344792.1192.11(35/38)88.89(16/18)PSO2778.68770.00192.1192.11(35/38)88.89(16/18)
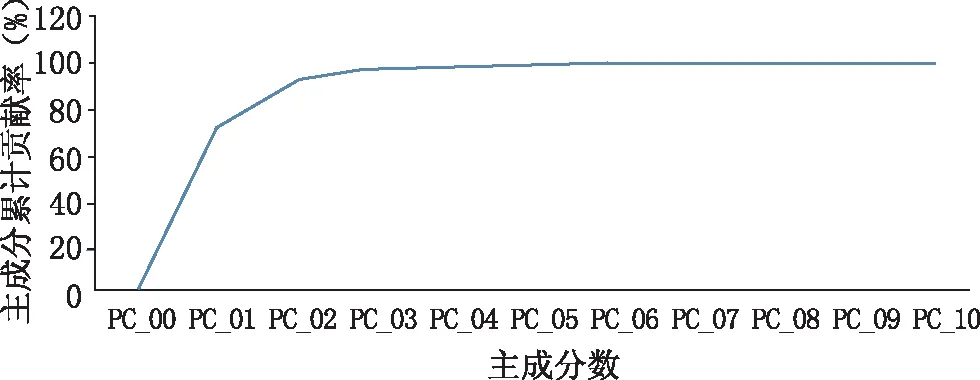
圖7 主成分累計貢獻變化圖
2.5.3主成分數進一步優選
經原始光譜(9 000~4 100 cm-1)FD預處理、PCA降維得到前2個主成分,并提取特征譜段數據(6 500~5 400 cm-1)進行SVM建模,前2個是否為必要或最佳主成分尚不明確,且對原始光譜數據信息的代表性不強,故需對主成分數進行優選。在前2個主成分的基礎上,增加建模的主成分個數,將PCA提取前3、4、5、6、7、8、9、10個主成分,以防數據丟失。但主成分數增加會使模型穩定性減低,故需對建模的主成分數進行篩選。根據上述SVM算法建模及尋優過程依次建立8個PCA-SVM分類模型,由圖7可得,前10個主成分累計貢獻率達99.74%,前10個主成分的貢獻率相對較大,對原數據的代表性較強,故本研究在這前10個主成分中進行篩選,依次建立不同主成分數的PCA-SVM模型,并對比建模效果見表3。
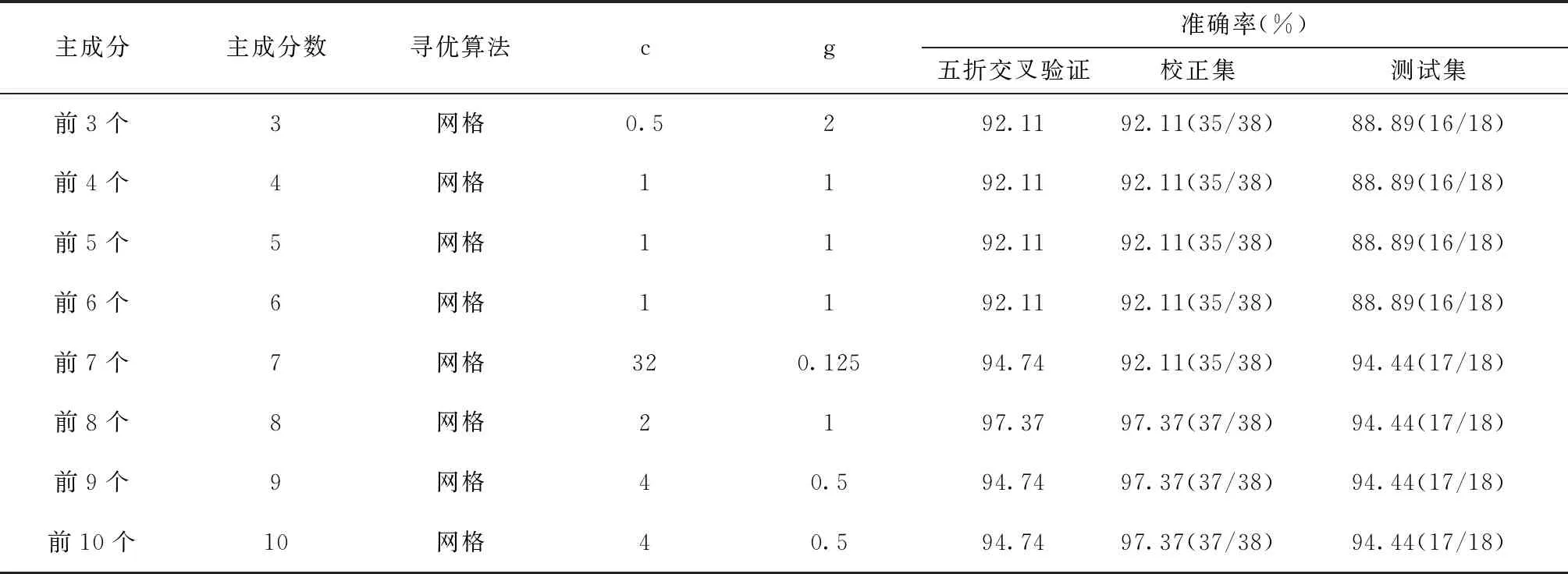
表3 不同主成分數的PCA-SVM模型的建模參數及驗證、評價效果
由表2和表3可知:隨主成分數的增加,校正集和測試集預測準確率均增加,其中當主成分數為8時,校正集預測準確率達到最大,其后保持穩定;當主成分數為7時,測試集預測準確率達到最大,并保持穩定。此外,五折交叉驗證準確率先增大,后減小,當主成分數為8時,五折交叉驗證準確率最大。故確定啤酒花樣品最佳主成分數為8。即以PCA提取的前8個主成分得分為PCA-SVM的輸入變量。
2.6 SVM評價
綜上所述,在6 500~54 00 cm-1建模譜段,確定最佳光譜預處理方法為一階導數法(FD),FD預處理光譜PCA降維后,確定最佳主成分前8個主成分(PC1,PC2,...,PC8)。經網格搜索法確定最佳SVM建模參數組為:c=2,g=1,所建PCA-SVM模型對校正集和測試集樣品預測正確率均分別為97.37%和97.44%,預測準確率高。模型五折交叉驗證準確率亦達97.37%,模型性能最佳。該模型對校正集和測試集預測結果見圖8。
通過圖8可以看出,在尋優過程中發現,網格搜索算法尋優原理簡單,具有可重復性,而PSO算法和GA尋優的智能算法,其運算過程具有一定的隨機性,對復雜問題的解決能力更強。建立光譜數據經FD預處理后進行降維,使得建模復雜度相對簡化,且不同樣品的趨向度不一致,故確定最優內部尋優方法為網格搜索算法。以網格搜索算法確定的模型8對訓練集和測試集樣品的預測可知,校正集的第9個樣品PJH-14預測錯誤,測試集的第17個樣品PJH-51預測錯誤,可能樣品的基數過小,可達標原始光譜的絕大多數信息。
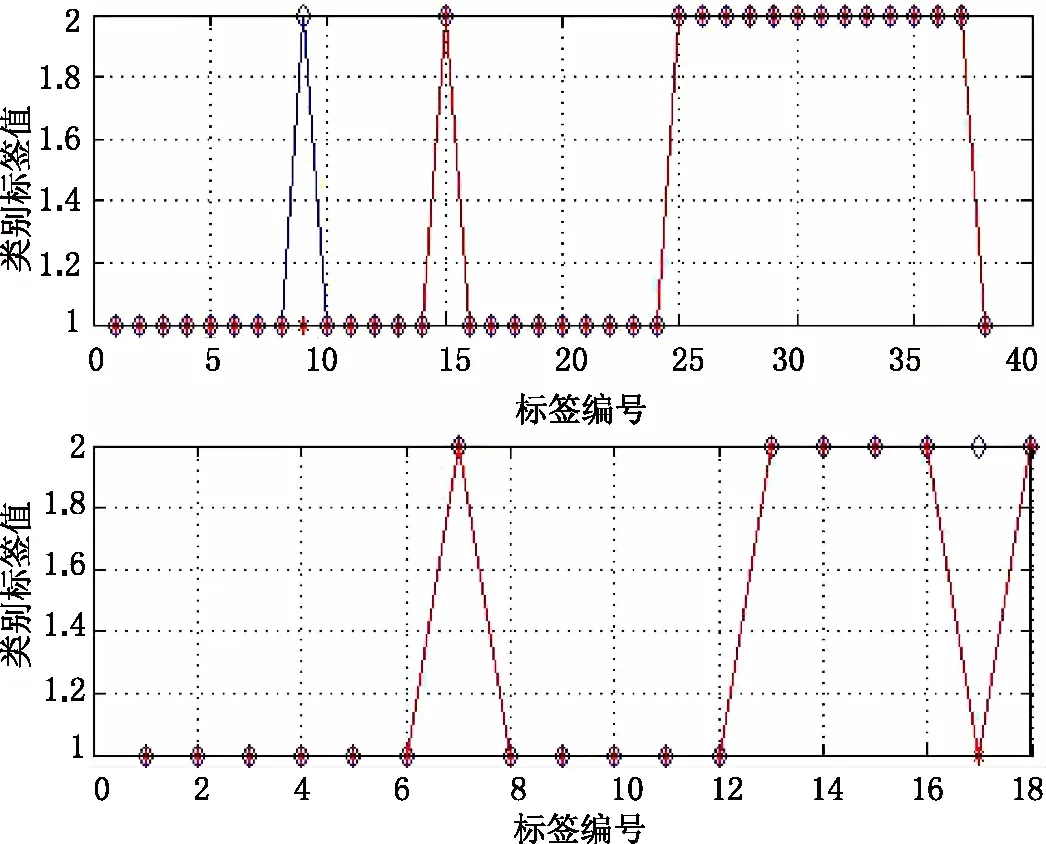
圖8 模型8對樣品的預測效果 A.預測集;B.校正集
3 討論
本實驗通過收集國產和進口啤酒花樣品,在收集的56個樣品中,有21個進口啤酒花,35個國產啤酒花,利用NIRS光譜,建立了啤酒花中藥材的PCA-SVM模式識別模型,該模型對預測集和校正集樣品的預測準確率高。模型五折交叉驗證準確率亦達97.37%,模型性能最佳。可用于啤酒花樣品的快速鑒別。建模過程中,本文采用光譜PCA降維所得的主成分得分平面散點圖,對光譜預處理主成分進行優選,根據樣品的趨勢,確定樣品的最佳預處理方法。然后對SVM的內部參數進行GA算法、PSO算法尋優,建立PCA-SVM算法,快速鑒別啤酒花樣品。
本文首次將NIRS技術應用于啤酒花中藥材的鑒別,證明了其具有可能性,為啤酒花的鑒別提供了新的方法。但由于樣本量及產地的限制,本文在對啤酒花樣品進行模型五折交叉驗證中校正集第9個樣品PJH-14預測錯誤,測試集第17個樣品PJH-51預測錯誤。后期需對樣品量和產地、品種進行擴增,對模型進行完善。使該方法可以快速鑒別啤酒花,提高測試正確率和準確率。該方法也可用于其他中藥材的鑒別,例如礦物類和樹脂類中藥材[18-19]。本研究方法較新,收集樣品量大,建立方法具有一定的應用和推廣價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
