基于孤立森林模型的企業用水異常檢測研究
2019-06-30 00:26:46巫朝星
企業科技與發展 2019年11期
巫朝星


【摘 要】文章基于企業用水量,提出一種結合業務規則和無監督算法的企業用水異常檢測方法。首先基于業務經驗的凝練規則,將數據集分為含有顯著異常的部分和含有潛在異常的部分。然后針對含有顯著異常的部分,通過分類規則判定異常類型;針對含有潛在異常的部分,則利用孤立森林算法進行異常檢測,并對異常進行聚類,判定異常類型。在企業用水量數據集上的實驗結果表明,該方法能夠找出存在異常的企業并把握異常的模式。
【關鍵詞】公共安全;異常檢測;孤立森林
【中圖分類號】TP311.13 【文獻標識碼】A 【文章編號】1674-0688(2019)11-0061-03
0 引言
異常檢測是一種數據挖掘技術,是指在從數據集中找出其行為不同于預期的過程[1],已經被應用于眾多領域,如金融、醫療和圖像處理等[2]。如今,這項技術也被一些電力公司和自來水公司所采用,主要目的是降低公司運營成本。如自來水公司會對城市水管網區用水進行監測,尋找其中的異常模式,這為公司實施科學化運行管理提供重要依據[3-5];電力公司檢測異常用電模式降低非技術性損失,如監測用戶竊電和欺詐行為,降低公司運營成本[6-9]。在公共安全部門,異常檢測尚未得到廣泛應用。企業用水量作為企業日常資源消耗的數據之一,一定程度上反映了企業運營的基本狀況,如企業生產的規模和狀態。對企業用水量的監測可以了解企業的生產運作狀態,若能及時發現生產運作狀態異常企業,對于保護公共財產和維護社會安全有十分重要的意義。然而,各種規模的企業和海量的用水數據為監測帶來了挑戰,且人工監測和頻繁的現場探測消耗大量人力、物力,成本較高。因此,公共安全部門亟需一套行之有效、基于海量數據的異常企業檢測方案,為部門管理決策提供支持。
目前,常見的異常檢測方法主要有基于統計分布的方法[10]、基于距離的方法[11]、基于密度的方法[12]、基于聚類的方法[13]和基于樹的方法[14]5種。本文從公共安全部門視角出發,針對企業每月的用水量,提出了一套結合業務規則和無監督算法的異常檢測方案,并對檢測出來的異常進行分類和聚類分析,為公共安全部門的管理決策提供建議。考慮到每種異常檢測的算法都有難以解決的異常模式,本文在異常檢測開始階段結合了基于業務經驗的規則,將數據集分為含有顯著異常的部分和含有潛在異常的部分。綜合考量算法的假設與數據集的匹配度和算法的復雜度,從上文提到的5種經典的異常檢測方法中,選擇iForest作為異常檢測算法。針對含有顯著異常的部分,通過規則判定異常的類型。針對含有潛在異常的部分,則利用iForest進行異常檢測,并對異常進行聚類分析,找出異常的模式。最后針對不同類型的異常,給出對應的管理建議。
本文提出的方案作用體現在以下3個方面:一是有助于自動排查存在隱患的企業,縮小需現場檢查企業的范圍,降低人力、物力成本;二是通過挖掘企業異常背后的原因,為加強和優化管理提供依據;三是有助于加強對嫌疑企業的威懾力,降低企業異常行為的發生率。
1 企業異常檢測的流程
1.1 數據預處理
本文的原始數據共計13 838家企業的每月用水總量。通過業務規則,發現不含用水值為0的企業分為一類,共6 128個企業,該類企業中仍存在潛在的異常。表1描述的是含有潛在異常的6 128家企業平均用水量的分類情況。然后對數據進行對數處理,取對數主要是為了消除不同規模企業之間用水量大小的差異。最后對數據做一階差分,消除隨機趨勢,將每月之間用水量的波動作為企業是否異常的特征。至此,原始數據的預處理工作全部完成。
1.2 孤立森林算法
孤立森林算法[13]是一種無監督的異常檢測方法,該算法主要通過從訓練數據集中隨機選取一個特征,在該特征的最大值與最小值之間隨機選取一個分裂點,小于分裂點的進入左側分支,大于或等于分裂點的進入右側分支;不斷重復上述過程直到只剩一個樣本或相同樣本(無法繼續分裂)或達到樹的深度限制。路徑長度h(x)指樣本點x從根節點到外部節點所經過的二叉樹的邊數,異常樣本通常路徑長度較小,而正常樣本路徑長度較大。以同樣的方式構建包含多棵孤立樹的孤立森林,異常事件即可基于路徑長度被檢測出來。數據異常的程度可以通過異常分值判斷S(x,n)。定義如下:
式(1)中,n為樣本個數,H(i)為諧波次數,c(n)為二叉搜索樹的平均路徑長度。
式(2)中,E(h(x))是樣本點x在孤立森林中所有孤立樹的路徑長度的平均值。當異常分值s(x,n)越小,則其異常程度越高,是異常點的可能性越大。
1.3 異常值聚類分析
為了更好地探究異常及其背后的原因,本文利用K-means算法對檢測出來的異常值進行聚類,并利用手肘法對合適的K值進行確定。K-means聚類算法[15]是一種迭代重定位方法,主要有兩個步驟:第一步是依據最近鄰原則將數據點分配到距離最近的簇中心點;第二步重新計算簇中心點。如此反復,直到指定的收斂條件,聚類結束。K-means算法流程如圖1所示。
2 實驗結果與分析
對于含有顯著異常的數據集,可以根據0值出現的情況進行分類,本實驗分類規則如下:①用水量數據全為0值的企業分為一類,記為I;②用水量數據和0值依次交替出現分為一類,記為II;③其他出現0值的情況分為一類,記為III。
通過表1可知,第I、II和III類異常分別包含298、4 456和2 956家企業。其中,第II類異常企業數量最多,也就是用水量數據和0值依次交替出現的情況,導致該異常出現的情況可能是抄表員2個月才進行一次抄表造成,公共安全部門應該及時提醒有關的自來水公司加強對相關人員的監督和管理,使企業用水量數據能夠準確及時地記錄;除此之外,還存在相當一部分第III類異常企業,即企業用水量序列中前部、中部或尾部出現幾個0值的情況。類似這樣從有用水量到無用水量或者從無用水量到有用水量的情況,有可能是企業從生產到停產或者從停產到生產的過程,這對一個正常運營的企業來說是比較罕見的。政府需要及時了解企業運營狀況,查清停產和生產狀態頻繁切換的原因,將該類企業列入觀察名單;最后一種數量最少的異常就是第I類異常,該類異常中的企業用水量全部為0值,該情況可能是企業已經停止運營或者已經倒閉,公共安全部門需做好核實。
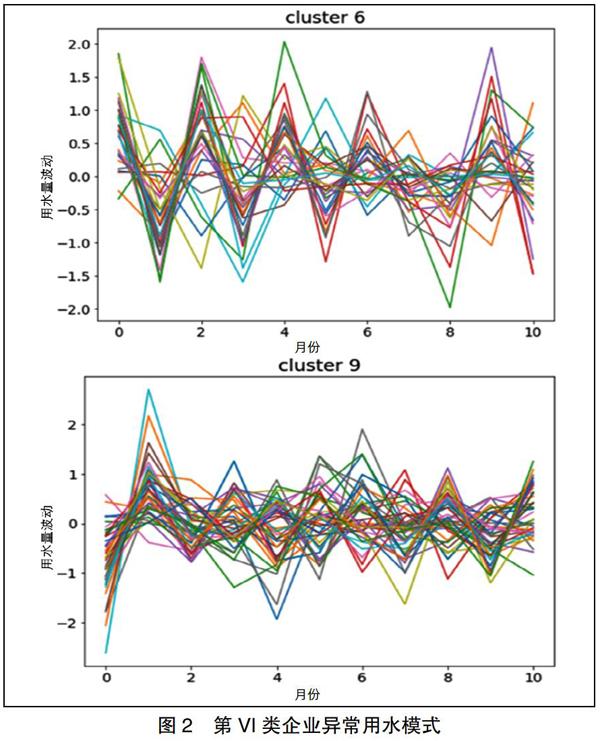
圖2給出了某種類別的企業用水模式,從中可以發現用水量沒有一致的模式,但至少在某個月的用水量波動較大。
綜上所述,通過算法分析,可以觀察到用水量存在大幅度連續波動的規律。在第VI類異常中,存在某些月份用水量發生較大波動。因此,公共安全部門要特別關注此類用水量具有大幅度波動的企業,可以進行現場實地排查,調查造成用水量波動巨大的具體原因。
3 結論
本文基于企業每月的用水量數據,提出了一套結合業務規則和無監督算法的異常檢測方法。針對含有顯著異常的部分,通過算法規則發現了3種異常模式。針對含有潛在異常的部分,利用孤立森林方法進行異常檢測,并對異常進行聚類找到3種異常模式。在檢測出的6種異常模式中,第I類異常可能是企業已經停止運營或者已經倒閉,公共安全部門需及時對企業狀況進行核實;第II類異常出現的原因可能是抄表員2個月才進行一次抄表,公共安全部門應及時提醒相關的自來水公司加強對相關人員的監督和管理,使企業用水量數據能夠準確及時地記錄;第III類異常可能是企業從生產到停產或者從停產到生產的過程;第IV和第V類異常中企業用水量存在顯著的連續大幅度波動,而第VI類異常中企業至少存在某一個特定月份用水量波動。
參 考 文 獻
[1]Han J,KamberM,Pei J.Data Mining:Concepts and Techniques Third Edition[M].Elsevier Pte Led,2012.
[2]Chandola V,Banerjee A,Kumar V.Anomaly dete-ction:A survey[J].ACM Computing Surveys,2009,41(3):51-58.
[3]黃琛,李文婷,張旭,等,城市供水管網片區用水異常模式識別[J].云南大學學報(自然科學版),2018(5):879-885.
[4]Mounce R,Khan A,Wood AS,et al.Sensor-fusion of hydraulic data for burst detection and location in a treated water distribution system[J].Information Fusion,2003,4(3):217-229.
[5]Mounce R,Boxall J B,Mexhell J.Development and verification of an online artificial intelligence system for detection of bursts and other abnormal flows[J].Journal of Water Resources Planning and Management,2010,136(3):309-318.
[6]莊池杰,張斌,胡軍,等.基于無監督學習的電力用戶異常用電模式檢測[J].中國電機工程學報,2016,36(2):379-387.
[7]León C,Biscarri F,Monedero I,et al.Variability and trend-based generalized rule induction model to NTL detection in power companies[J].IEEE Transactions on Power Systems,2011,26(4):1798-1807.
[8]Fontugne R,Tremblay N,Borgnat P,et al.Mining anomalous electricity consumption using ensemble empirical mode decomposition[C].//2013 IEEE International Conference on Acoustics,Speech and Si-gnal Processing(ICASSP).Vancouver,BC:IEEE,2013.
[9]NagiJ,Yap K S,Tiong S K,et al.Improving SVM-based nontechnical loss detection in power utility using the fuzzy inference system[J].IEEE Transac-tions on Power Delivery,2011,26(2):1284-1285.
[10]GoldsteinM.,DengelA.Histogram-based Outlier Score(HBOS):A fast Unsupervised Anomaly Detection Algorithm[C].In:Wolfl S,editor. KI-2012:Poster and Demo Track,2012.
[11]E M Knorr,R T Ng.A unified notion of outliers:properties and computation[C].In:Proceedings of the 3rd ACM international conference on knowledge discovery and data mining(KDD),Newport Beach,1997.
[12]BreunigM M.LOF:identifying density-based local outliers[J].2000,29(2):93-104.
[13]Ester M,Kriegel HP,Sander J,et al.Adensity-based algorithm for discovering clusters in large spatial databases[C].In:Proceedings of KDD' 96,Portland OR,USA,1996:226-231.
[14]Liu F T,Kai M T,Zhou Z H.Isolation-Based an-omaly detection[M].ACM,2012.
[15]王建仁,馬鑫,段剛龍.改進的K-means聚類k值選擇算法[J].計算機工程與應用,2019(8):27-33.
