一種基于聯合學習的家庭日常工具功用性部件檢測算法
2019-06-11 06:42:54吳培良隰曉珺楊霄孔令富侯增廣
自動化學報 2019年5期
吳培良 隰曉珺 楊霄 孔令富 侯增廣
縱觀人類文明史,社會每一次進步幾乎都與使用工具息息相關;在人的成長過程中,學習使用工具也是其必備的能力之一.在機器智能研究領域,機器人的發展始終都在學習人類智能和技能,目前機器人可在一定程度上模擬人類的感知能力[1],而借鑒人類認知方式,使機器人具備工具及其組成部件的功能用途(功用性,Affordance)認知能力,對機器人從感知到認知的主動智能提升具有重要意義[2].
目前,機器人主要通過讀取語義標簽方式被動獲取物品功用性等語義,基于學習的功用性主動認知方法研究剛剛出現.特別是近年來隨著RGB-D傳感器(如Kinect)的出現,3D數據的獲取更加方便快捷,極大地推動了功用性檢測領域的研究.Lenz等學習工具中可供機器人抓取的部位[3],Kjellstrom等通過學習人手操作來分類所用工具[4],Grabner等通過3D數據檢測出可供坐的曲面[5],文獻[6]將工具功用性看做相互關聯的整體,通過馬爾科夫隨機場建模工具與人的操作,文獻[7]運用結構隨機森林(Structured random forest,SRF)和超像素分層匹配追蹤(SHMP)方法檢測家庭常見工具的7種功用性部件(grasp、cut、scoop、contain、pound、support和wrap-grasp),上述方法均提取彩色圖像或深度圖像中的特征加以建模,但沒有考慮圖像塊間的空間上下文信息.文獻[8]考慮部件間的空間結構,針對目標輪廓進行幾何特征稀疏表示與分級檢測.Redmon等提出采用卷積神經網絡(Convolutional neural network,CNN)識別工具[9],文獻[10]研究多模特征深度學習與融合方法,以實現最優抓取判別,Myers通過雙流卷積神經網絡(Two-stream CNN),將幾何特征與材質信息相結合用于功用性檢測[11],Nguyen等以端到端的方式利用深度特征訓練CNN,并通過CNN中的編解碼裝置保證標簽平滑性[12].但上述深度學習方法均需較高的硬件配置(GPU環境).文獻[13]僅利用結構隨機森林(SRF)訓練功用性部件檢測模型,基本實現了無GPU配置下的實時檢測.Thogersen等通過聯合隨機森林與條件隨機場(Conditional random field,CRF)實現室內各功能區的分割[14],其中CRF的引入有效地整合了空間上下文以描述區域關聯性,但文獻[14]缺少對特征有效性的判別而文獻[13]僅依靠經驗選取關鍵特征,兩者均可通過采用更加通用的特征編碼方法來提升信息的有效性.
稀疏編碼已成功應用于圖像表示和模式識別等諸多領域,通過將普通稠密特征轉化為稀疏表達形式從而使學習任務得到簡化,使模型復雜度得到降低[15].顯著性計算領域的研究結果表明,對CRF和稀疏編碼的聯合學習比兩種方法順序處理性能更好[16].借鑒該理論,本文針對功用性檢測問題,整合CRF刻畫空間上下文能力和稀疏編碼特征約簡的優點,綜合考慮兩者間的耦合關系,設計其聯合條件概率表示與解耦策略,繼而給出了基于聯合學習的算法實現.
1 問題描述與分析
本文研究深度圖像中工具部件功用性檢測問題,即給定一幅深度圖像,試圖得知其中是否存在某類待檢測功用性部件.針對此問題,提出了功用性部件字典的概念,并將稀疏編碼用于工具部件功用性特征表示.此外,顯著性計算和目標跟蹤等研究均表明,如果一個局部塊表現了很強的目標特性,那么其附近的塊也可能含有相似的性能[16?17],遵循這一法則,針對該功用性字典在描述空間上下文方面的不足,引入條件隨機場(CRF)來表征這種空間臨域關系,從而構建出一個自上而下的基于圖像塊稀疏編碼的CRF模型.但分析可知,在該模型中CRF構建和稀疏編碼是互相耦合的兩個子問題:一方面,CRF中節點存儲圖像塊的特征稀疏向量,CRF權重向量的優化將導致特征字典的更新;另一方面,各圖像塊的特征稀疏向量則被用于計算和優化CRF的權重向量.
綜合上述分析,針對不同功用性部件分別訓練模型,將該部件功用性區域視為目標區域,其他區域視為背景區域,深度結合CRF與稀疏編碼,將稀疏向量作為潛變量構建CRF,與此同時,通過CRF的調制更新字典.
2 公式化表示
本文針對深度圖像展開功用性部件特征提取,并針對不同功用性部件分別設置與深度圖同尺度的二值標簽文件.深度圖中,假設某局部圖像塊特征向量x∈Rp,p為特征維度,若在該圖像塊中存在某功用性部件,則令該部件二值標簽文件中對應位置處的標簽y=1;否則,令y=?1[18].則可從圖像不同位置采樣m個圖像塊構建特征集X={x1,x2,···,xm}作為觀測值,對應標簽集合Y={y1,y2,···,ym}記錄目標存在與否.構建字典D∈Rp×k用于存儲從訓練樣本學習得到的最具判別性的k個深度特征單詞{d1,d2,···,dk},并引入潛變量si∈Rk作為圖像塊特征xi的稀疏表示,即有xi=Dsi.此稀疏表示可進一步公式化為如下最優化問題:
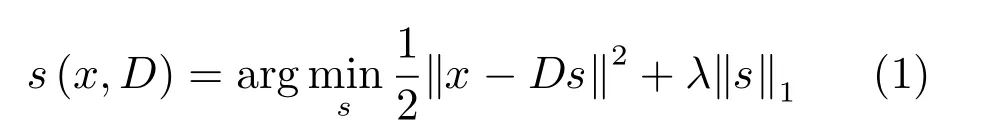
其中,λ為控制稀疏性的參數.令S(X,D)=[s(x1,D),···,s(xm,D)]表示所有塊的潛變量,可知S(X,D)為關于字典D的函數,且同時包含了字典和圖像塊特征集信息.
考慮到采樣塊空間連接特性,本文創建四連接圖G=hv,εi,其中v表示節點集合,ε表示邊集合,鑒于v中節點只與其周圍四鄰接節點存在條件概率關系,而與其他節點無關.本文以S(X,D)作為節點信息,則可知在S(X,D)條件下,圖G具有Markov性[16],即可用如下的條件概率作為CRF公式:
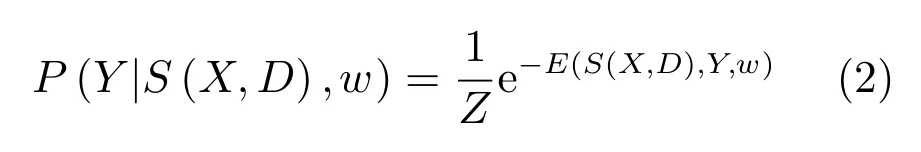
其中,Z為配分函數,E(S(X,D),Y,w)為能量函數,其可分解為節點能量項與邊能量項[19?20].對于每一個節點i∈v,該節點能量由稀疏編碼的總貢獻計算得到,即,其中w1∈Rk是權重向量.對于每一條邊(i,j)∈ε,若只考慮數據間的平滑性,則有ψ(yi,yj,w2)=w2⊕(yi,yj),其中w2表示標簽平滑性的權重,⊕表示異或運算.
因此,隨機能量場可詳寫為:
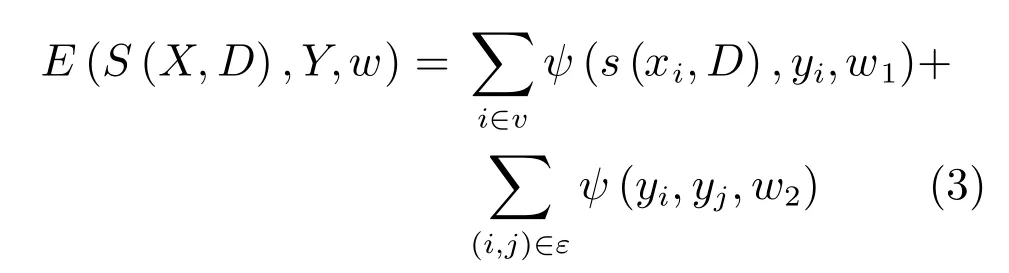
其中,w=[w1;w2].
由前面式(2)可知,學習CRF權重w與字典D為兩個相互耦合的子問題.給出CRF權重w,式(2)的模型可以看作是CRF監督下的字典學習;給出字典D,則可看作是基于稀疏編碼的CRF調制.在此模型中,通過求解下面的邊緣概率來計算節點i∈v的目標概率[21]:
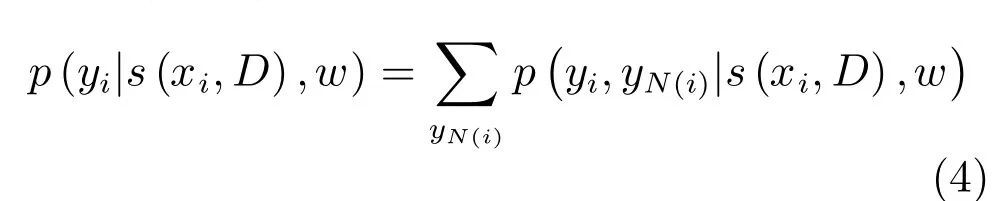
其中,N(i)表示圖像上結點i的鄰居節點.若定義圖像塊i中目標存在的概率為:
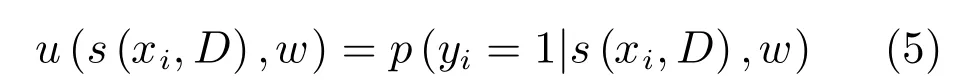
則最終圖像中存在某種功用性部件的概率圖為:
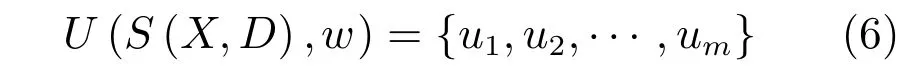
3 模型優化與解耦求解
假設由N幅深度圖構成的訓練樣本集為, 其對應標簽為ψ=,本文旨在學習CRF參數和字典來獲得訓練樣本的最大聯合似然估計:
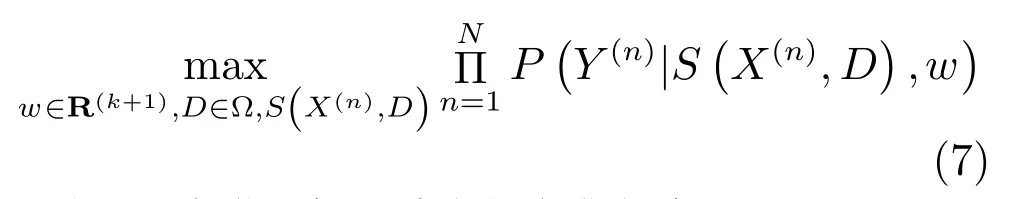
其中,?為滿足如下約束的字典集合:
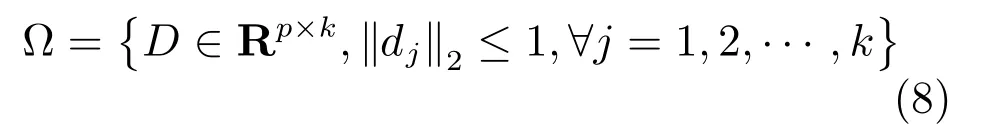
3.1 模型優化
對于上節式(7),考慮到從有限的訓練樣本學習大量參數較為困難,參考Max-margin CRF學習方法[22],我們將似然最大化轉化為不等式約束優化問題以追求最優的w和D,則對于所有YY(n),n=1,2,···,N,有:
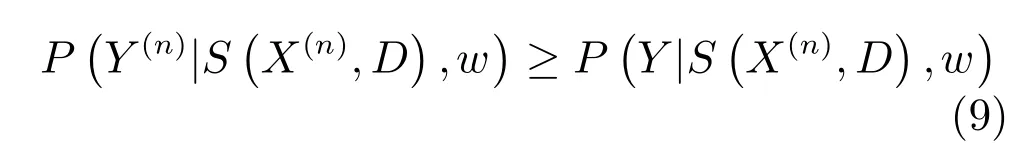
在此約束優化的條件下可將兩邊的配分函數Z去掉,表示為能量項的形式:
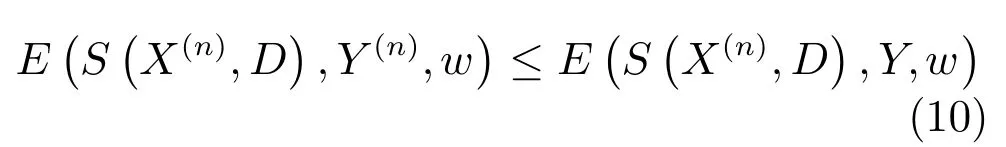
若試圖使實際的能量ESX(n),D,Y(n),w比任意E?S?X(n),D¢,Y,w¢都小[23],則可令:
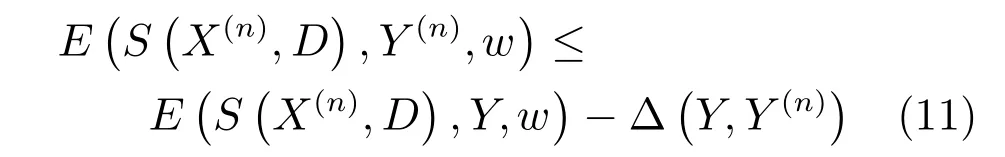
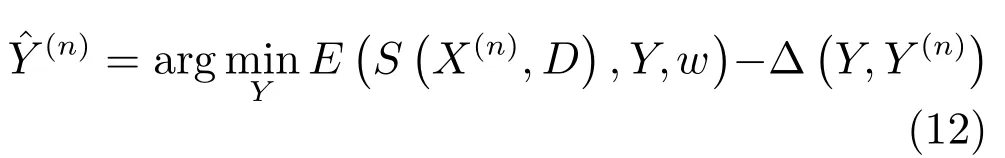
因此,對式(7)中權值w和字典D的學習可通過最小化如下目標損失函數來實現:
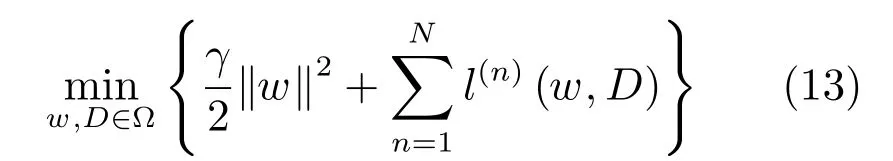
3.2 CRF權重求解
本文采用Adam 算法[24]來優化式(13)中的目標損失函數,從中解耦出CRF并計算其權重.當潛變量S(X,D)己知時,式 (3)中能量函數E(Y,S(X,D),w)對權值w是線性的,則可進一步表示為:
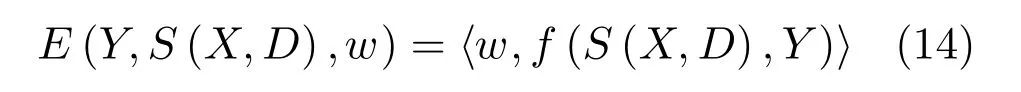
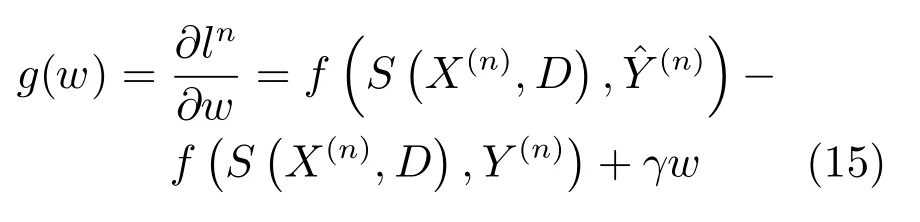
對式(15)采用Adam算法加以求解.若第t次迭代的梯度值記為g(n)(w(t?1)),有偏的第一時刻向量記為m(t),有偏的第二時刻向量記為v(t),則有:

式中,β1,β2分別為某接近1的固定參數.對上式進行偏差校正,令
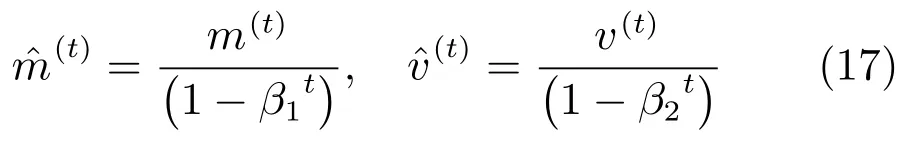
則在第t次迭代后的CRF權重更新公式如下:
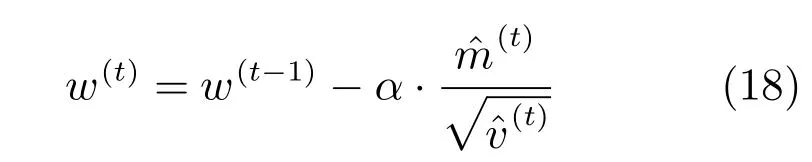
式中,α為固定參數,其與聯合構成可自適應動態調整的學習率函數.
3.3 字典求解
對于字典D,本文使用鏈式法則[25]來計算ln對D的微分:
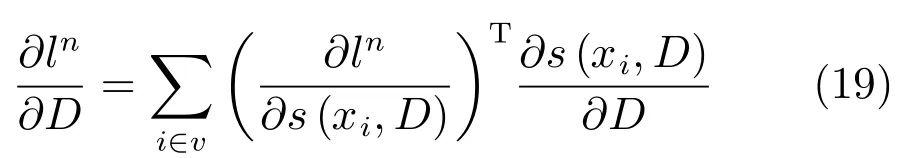
建立式(1)的不動點方程:
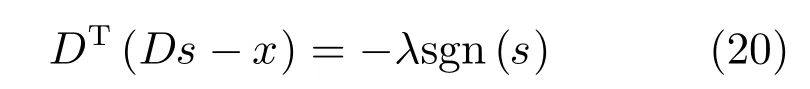
其中 sgn(s)以逐點的方式表示s的符號,且sgn(0)=0.式(20)兩端分別對D求導得:
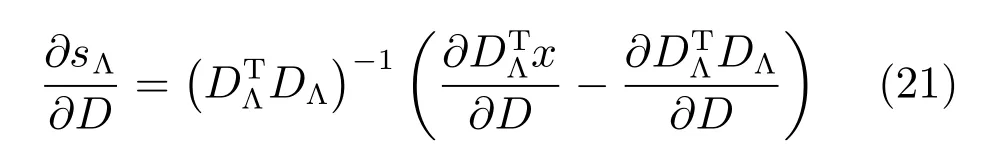
其中,Λ表示s的非零編碼索引集,表示零編碼索引集.為每個s引入一個輔助變量z來簡化式(19):

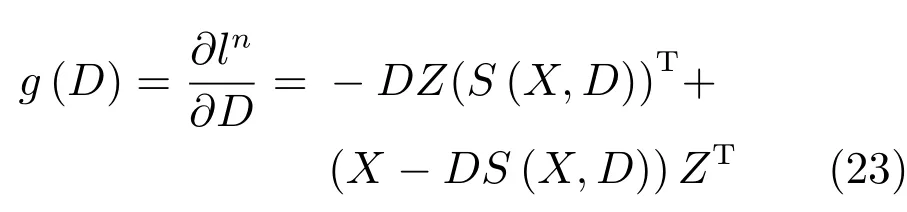
此處,同樣采用Adam算法進行字典的求解,求解過程與上節相同.
4 算法實現
4.1 幾何特征表示與提取
本文所用特征有高斯曲率(Gaussian curvatures)、方向梯度直方圖(Oriented gradient histograms)、梯度幅值(Gradient magnitude)、平均曲率(Mean curvatures)、形狀指數(Shape index)、曲度(Curvedness)和表面法向量(Surface normals)[7].其中方向梯度直方圖為4維特征向量,表面法向量為3維特征向量,其他特征均為1維向量.將這些特征進行歸一化后組合,得到表征某圖像塊的工具功用性部件的12維特征向量.上述特征均在家庭日常工具1/4下采樣的深度圖上計算得到,并經由稀疏編碼后作為表征某工具功用性部件的特征向量.
此外,考慮到方向梯度直方圖、梯度幅值、平均曲率、形狀指數和曲度在功用性部件邊緣快速檢測時的重要作用,借鑒文獻[13]中的功用性部件邊緣表示方法,并將這些特征用結構隨機森林(SRF)進行組織和功用性部件邊緣建模,受篇幅所限,具體算法不再贅述.
4.2 基于聯合學習的模型構建算法
在對CRF和稀疏編碼耦合分析與求解基礎上,采用聯合學習的方法分別對每類功用性部件構建模型,該模型包括了最宜于表征該功用性部件的字典原子及CRF權重向量.下面給出模型構建的完整算法.
算法1. 基于聯合學習的模型構建算法
輸入.χ(訓練圖像集),ψ(真實標簽集),D(0)(初始字典);
w(0)(初始CRF權重),λ(在式(1)中),T(循環次數);
γ(在式(13)中)
輸出.
1 fort=1,···,Tdo
2 /*依次訓練樣本集合(χ,ψ)*/
3 forn=1,···,Ndo/*N為χ中深度圖像的數量*/
4 通過式(1)評估潛變量s(xi,D),?i∈V;
6 采用Adam算法通過式(18)更新CRF權重w(t);
7 為s(xi,D)找到有效集Λi,?i∈V;
8 通過式(22)計算輔助變量zi;
9 采用Adam算法更新字典D(t);
10 通過式(8)在?上對D(t)進行正則化;
11 end for
12 end for
4.3 功用性部件在線檢測
通過前面的離線建模階段,得到了最具判別性的特征字典和CRF權重向量.在線檢測過程中,利用工具部件功用性邊緣檢測器計算功用性的外接矩形區域,在此區域內以特征稀疏表示作為圖像節點信息,在聯合CRF圖模型與稀疏編碼的基礎上利用置信度傳播算法完成圖像的語義分割,至此得到每個圖像塊屬于目標的概率,進而產生目標功用性概率圖U={u1,u2,···,um},其中,概率大于某一閾值的區域即為目標區域,反之則為背景區域.
5 實驗及結果分析
5.1 實驗數據集
為驗證本文理論推導和算法實現的正確性,使用文獻 [7]中的數據集檢測并分類其中的家庭工具功用性部件,該數據集中包括廚房、園藝和工作間共17類105種家庭日常工具的 RGB-D 信息,涵蓋了 grasp、wrapgrasp、cut、scoop、contain、pound、support 共7種功用性.圖1給出了數據集內的部分工具示例,圖2給出了示例工具所具有的功用性部件,可以直觀看出,每類工具都可視為若干功用性部件的集合,而同一功用性部件則可能出現在不同工具中.

圖1 RGB-D數據集中部分工具Fig.1 Tools in RGB-D data set
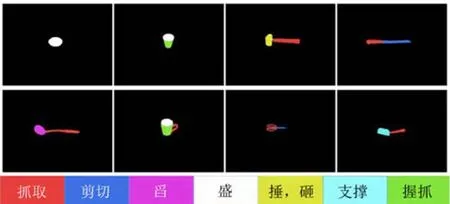
圖2 工具目標部件功用性區域Fig.2 Target affordance parts in tools
針對某種功用性部件,在數據集中選取包含該功用性部件的各類工具的不同角度Depth圖像以及已標記該功用性部件的二值標簽文件作為訓練樣本.從功用性角度出發,圖3直觀地給出了包含功用性部件“盛(Contain)”的工具及其對應的二值標簽.

圖3 包含功用性部件“盛(Contain)”的工具及其對應的二值標簽Fig.3 Tools containing affordance of“contain” and the corresponding labels in binaryzation
5.2 實驗條件與配置
將深度圖像1/4下采樣后作為訓練樣本,其中每個像素視為一個圖像塊.訓練過程中,收集所有塊的幾何特征,并使用K-means算法初始化字典D(0).基于字典計算特征稀疏表示,并將其作為潛變量與對應標簽進行訓練得到一個線性SVM(Support vector machine),利用此SVM初始化CRF結點能量權重,并將邊能量權重設置為1.所有模型訓練3個周期,訓練得到表征該功用性部件的字典與CRF權重向量.基于該模型進行功用性部件檢測和定位,產生目標功用性存在的概率圖,將概率值大于等于0.5的圖像塊認定為目標塊,將概率值小于0.5的塊認定為背景塊.本文算法運行于Windows 7操作系統,雙核3.20GHz CPU,內存為8GB.
5.3 實驗結果及分析
本文依次構建上文提到的4種功用性contain、scoop、support與wrap-grasp的部件檢測模型.僅使用文獻[15]的稀疏編碼并分別采用SIFT(Scale invariant feature transform)特征和深度特征得到的檢測結果如圖4(c)和圖4(d)所示,使用文獻[16]的聯合學習方法并分別采用SIFT特征和深度特征得到的檢測結果如圖4(e)和圖4(f)所示,采用深度特征并使用文獻[7]方法和文獻[13]方法得到的檢測結果如圖4(g)和圖4(h)所示,使用本文方法的檢測結果如圖4(i)所示.通過對比可以直觀看出,相較于SIFT特征,深度特征能夠更加有效地表征工具的功用性部件,且相較于僅采用稀疏編碼方法、SRF方法以及傳統的CRF與稀疏編碼結合的方法,本文通過對多類深度特征進行稀疏編碼,同時采用CRF表征特征空間關系,使得檢測效果獲得了不同程度的提升.
為了進一步定量評定本文方法的性能,圖5給出了采用不同特征及不同方法所得到的精度召回率曲線.可以看出,采用SIFT特征表征功用性部件時,其精度和召回率普遍低于采用深度特征表征功用性部件.本文算法采用深度特征及性能更優的Adam優化算法,對4種功用性部件的檢測效果普遍都較好,總體性能優于現有方法.
為了評判不同算法的效率,表1給出了本文方法與其他已有方法的用時對比.實驗過程中,文獻[7]方法需先將深度數據做較為費時的平滑預處理,再提取深度特征并交由訓練好的SRF模型進行功用性判別;文獻[13]中采用功用性部件邊緣檢測器快速定位目標區域,有效提升了檢測效率;文獻[15?16]方法本用于處理SIFT特征和顯著性檢測,但針對功用性部件建模深度特征較SIFT特征更具優勢,在Depth圖像中多類深度特征的提取速度稍慢于在RGB圖像中SIFT特征.本文從Depth圖像中提取多類深度特征,采用功用性部件邊緣檢測器快速定位目標區域,加之采用能夠快速收斂的Adam算法,因此取得了較為理想的檢測效率.

圖4 本文方法與其他方法的檢測結果對比圖((a)為單一場景下的待檢測工具圖,由上到下分別為碗(bowl)、杯子(cup)、勺子(ladle)、鏟子(turner);(b)為待檢測目標功用性部件的真實值圖,由上到下分別為盛(contain)、握抓(wrap-grasp)、舀(scoop)、支撐(support);(c)SIFT+文獻[15]方法檢測結果;(d)深度特征+文獻[15]方法檢測結果;(e)SIFT+文獻[16]方法檢測結果;(f)深度特征+文獻[16]方法檢測結果;(g)深度特征+文獻[7]方法檢測結果;(h)深度特征+文獻[13]方法檢測結果;(i)本文方法檢測結果)Fig.4 Comparison of detection results between our method and others((a)Tools in a single scene,from the top to the bottom:bowl,cup,ladle and turner;(b)Ground truth of object affordances,from the top to the bottom:contain、wrap-grasp、scoop、support;(c)Detection result with SIFT+Paper[15];(d)Detection result with Depth+Paper[15];(e)Detection result with SIFT+Paper[16];(f)Detection result with Depth+Paper[16];(g)Detection result with Depth+Paper[7];(h)Detection result with Depth+Paper[13];(i)Detection result with our method)

表1 本文方法與其他方法的效率對比(秒)Table 1 Comparison of efficiency between our method and others(s)
此外,需要說明的是,深度學習方法已被用于功用性部件的學習和檢測,并取得了與本文相當的識別準確率,但該類方法的運行均需GPU支持,如文獻[9]的CNN方法運行于NVIDIA Tesla K20 GPU環境下,文獻[12]的CNN方法運行于NVIDIA Titan X GPU環境下,兩者的識別速度均達到毫秒級,但在普通配置的CPU上無法運行.文獻[3]的SAE(Sparse auto-encoder)方法雖可運行于CPU環境,但算法運行耗時較長(如功用性部件grasp的檢測用時約幾十分鐘),無法滿足服務機器人任務的實時性要求.
6 結論
機器人與人的共融,將成為下一代機器人的本質特征.事實上,功用性語義頻繁出現在人們的日常思維和交互中,功用性認知也已成為了人機和諧共融的必然要求.本文利用工具的多類深度特征,結合稀疏編碼與CRF優勢訓練家庭日常工具功用性部件的檢測模型,通過與利用SIFT特征表示圖像信息和傳統聯合CRF與稀疏編碼訓練模型的算法進行比較,由精度召回率曲線可知本文模型對工具部件的目標功用性檢測效果良好,為機器人工具功能認知及后續人機共融和自然交互奠定基礎.
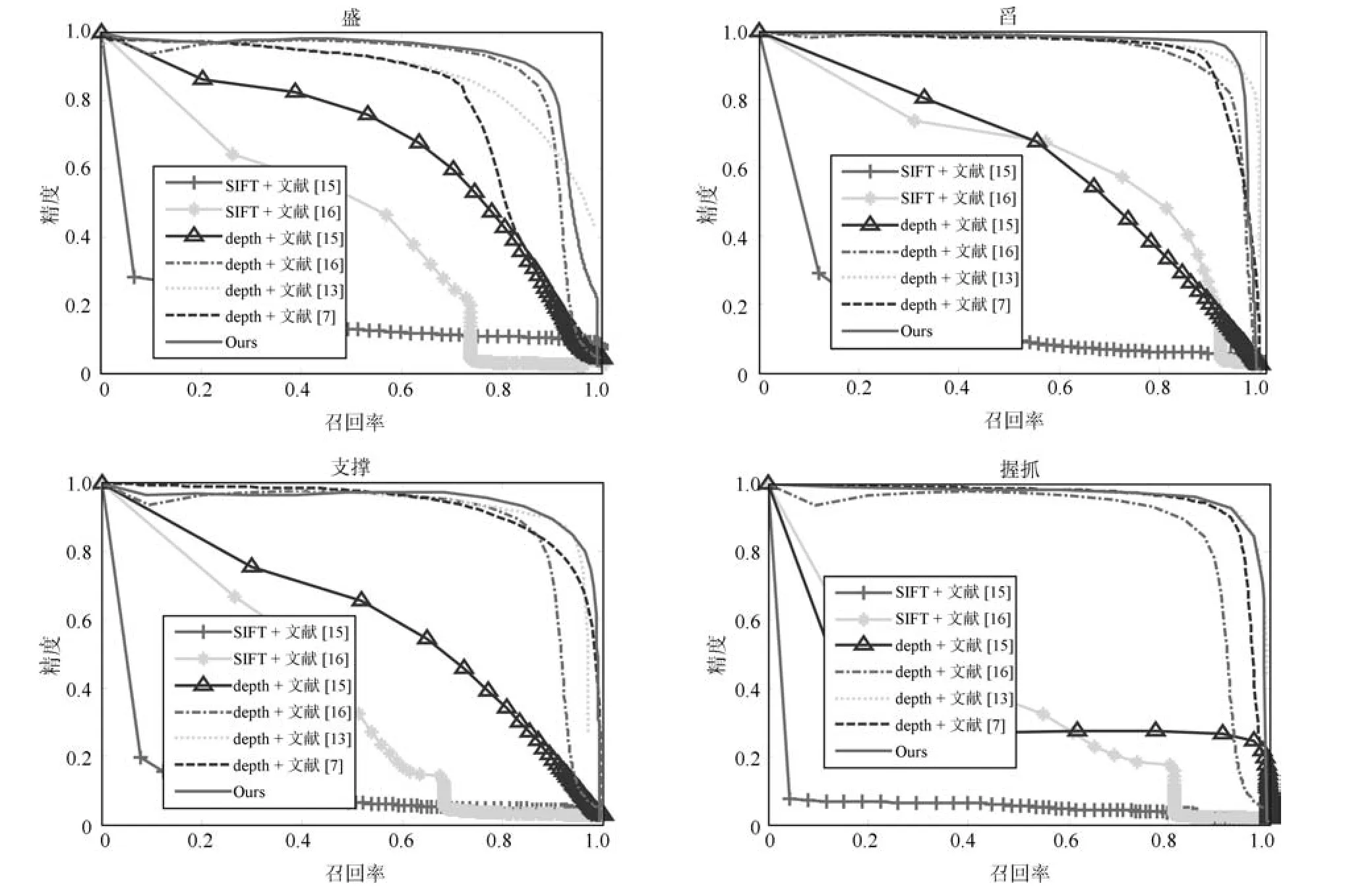
圖5 本文方法與其他方法的精度召回率曲線對比Fig.5 Comparison of precision recall curves between our method and others
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
