基于行人屬性先驗分布的行人再識別
2019-06-11 06:42:46吳彥丞陳鴻昶李邵梅高超
自動化學報 2019年5期
關鍵詞:實驗
吳彥丞 陳鴻昶 李邵梅 高超
近年來,隨著監控設備在公共場所的普及,行人再識別技術越來越受到人們的重視.行人再識別是利用計算機視覺技術判斷圖像或者視頻序列中是否存在特定行人的技術.但是由于光照、遮擋、行人姿態等問題,同一行人在不同場景中的外觀呈現出較大差異,這給行人再識別研究帶來了巨大挑戰.為了有效應對這些挑戰,廣大研究者提出了很多解決方法.
1 相關研究
目前的行人再識別算法大體可分為三類,分別是特征表示學習、距離度量學習和基于深度學習的方法.特征表示學習方法利用視覺特征對行人建立一個具有魯棒性和區分性的表示,然后根據傳統的相似性度量算法(歐氏距離等)來計算行人之間的相似度.文獻[1]在提取出行人前景的基礎上,利用行人區域的對稱性和非對稱性將前景劃分成不同的區域,對于每個區域,提取帶權重的顏色直方圖等特征描述它們.文獻[2]對于提取出的顏色直方圖特征,使用PCA(Principle component analysis)對其進行降維.文獻[3]結合方向、顏色、熵等多種特征,分級識別行人.雖然特征表示學習的思想較為直接簡單,易于解決小規模數據集的行人再識別問題,但是在光照、視角、姿態變化較大的情況下,特征表示學習方法的效果很差.
距離度量學習是一種利用測度學習算法得出兩張行人圖像的相似度度量函數,使相關的行人圖像對的相似度盡可能高,不相關的行人圖像對的相似度盡可能低的方法.代表性的距離度量學習算法有文獻[4],其中將行人再識別問題轉化為距離學習問題,提出了一種基于概率相對距離的行人匹配模型.文獻[5]在不同的特征子空間中利用不同的核函數對距離進行度量.文獻[6]基于馬爾科夫模型對行人之間的距離進行度量.在大規模數據集下,距離度量學習計算開銷過大,計算效率過低,容易陷入局部最小值,準確率不高.
深度學習近年來在計算機視覺中得到了廣泛的應用,因此不少學者研究并提出了基于深度學習的行人再識別算法.文獻[7]最先將深度學習應用于行人再識別領域,使用卷積神經網絡提取行人的特征.隨后不斷研究對其進行改進.文獻[8]提出將LSTM(Long short-term memory)模型結合進卷積神經網絡中,提高了網絡對時序特征的提取能力.文獻[9]將注意力模型結合進CNN(Convolutional neural network)網絡中,提升了模型的特征提取能力.基于深度學習的行人再識別近年來成為該領域的主流方法,相對于傳統方法,具有識別精度高,魯棒性好的優點.
上述方法有個共同的特點,就是它們僅僅考慮了行人圖片的標簽信息,也就是只使用了行人ID這個標記信息,并沒有采用行人的屬性信息.為此,近年來,隨著帶屬性標簽行人數據庫的出現,有研究人員提出了基于屬性的行人再識別方法,比如文獻[10?11]使用行人屬性進行行人再識別,達到了很好的識別效果.由于基于屬性學習的方法具有更符合人類的搜索習慣,能應用于零樣本學習等優點,因此當前這類方法成為該領域的研究熱點.其中,文獻[10]主要針對監控場景下行人屬性的識別做出了改進,主要提出了兩個行人屬性識別網絡DeepSAR和DeepMAR,前者對每個屬性進行單獨預測,后者聯合多屬性同時預測,在預測每個屬性時,考慮到屬性內正負樣本不均衡的情況,利用數據先驗分布對屬性預測的權值進行調整,從而提高了行人屬性的識別效果.文獻[11]提出一種聯合識別行人屬性和行人ID的神經網絡模型,大幅度提高了行人再識別的準確率,作者首先對大規模行人再識別數據集Market 1501[12]和DukeMTMC[13]進行了行人屬性的標注,然后基于這些標注圖片,設計實現了APR(Attribute-person recognition)神經網絡,該網絡對輸入圖片同時進行行人屬性和行人ID的提取與識別,將識別結果與圖片標注標簽進行比對,比對結果作為反向傳播的依據,訓練得到網絡,從網絡中提取出代表行人的向量,進行距離度量計算,得到再識別的結果.該網絡充分利用了行人的ID信息和屬性信息,相對于已有方法,有效提高了行人再識別的精度.本文在APR的基礎上,進一步進行了三個方面的改進,首先,網絡結構上的改進,在網絡中添加了一層全連接層.根據文獻[14]的研究,全連接層可以提高網絡在微調后的判別能力,保證源模型表示能力的遷移;然后,針對數據集中屬性類之間的數量不均衡問題,在損失函數中對各屬性的損失基于其包含的樣本數量進行了歸一化處理,提高網絡對不平衡數據的處理能力;最后,針對數據集中各屬性正負樣本的數量不均衡問題,利用數據中各屬性分布的先驗知識,通過數量占比來調整各屬性在損失層中的權重.測試結果表明,本文算法在公共實驗數據集上的實驗效果優于目前主流的行人再識別算法,尤其是首位匹配率(Rank-1),相對于APR網絡,也是有了較大幅度的提升.
本文其余章節的組織安排如下.第1節介紹本文提出的用于提取行人屬性和ID的行人再識別網絡結構;第2節介紹本文提出的運用數據先驗知識的損失函數設計原理及實現;第3節介紹本文算法在公共數據集上的實驗結果及分析;第4節總結全文以及展望.
2 用于提取行人屬性和ID的行人再識別網絡結構設計
在本節中,主要介紹用于提取行人屬性和ID的行人再識別網絡結構和算法流程.為了提取到高魯棒性的行人屬性特征描述子,基于數據分布的先驗知識,本文對APR網絡進行了大幅度改進,具體網絡結構見圖1.主要分兩個部分介紹改進后的網絡:基礎網絡部分,行人特征向量度量部分.下面詳細介紹這兩個方面的內容.
2.1 模型架構
本文的基礎網絡主要由兩個部分組成,以全連接層FC0為界線,前半部分為殘差網絡(Resnet[15]),后半部分為行人屬性和ID特征分類網絡.首先介紹前半部分,在計算機視覺里,特征的等級隨著網絡深度的加深而變高.研究表明,網絡的深度是實現好效果的重要因素,然而太深的網絡在訓練中會存在梯度彌散和爆炸的障礙,導致無法收斂.Resnet的提出,解決了多達100層的深度神經網絡訓練的問題,它通過學習殘差函數,實現恒等映射,從而在不引入額外參數和計算復雜度的情況下,避免了網絡的退化.本文網絡采用的是Resnet-50網絡,即具有50層深度的網絡,該網絡主要由卷積層(Convolution layer)、池化層(Pooling layer)和殘差塊組成.

圖1 網絡結構示意圖Fig.1 Schematic diagram of network structure
卷積層主要用于對圖像或者上一層的特征圖(Feature map)作卷積運算,并使用神經元激活函數計算卷積后的輸出.卷積操作可以表示為:

其中,xi為第i層輸入圖像或特征圖,yj為第j層輸出特征圖,ki,j是連接第i層輸入圖像與第j層輸入圖像的卷積核,bj是第j層輸出圖像的偏置,?是卷積運算符,f(x)是神經元激活函數.
池化層主要對卷積層的輸出作下采樣,其目的是減小特征圖尺寸大小,增強特征提取對旋轉和形變的魯棒性.一般使用平均值池化和最大值池化兩種方式,設輸入特征圖矩陣F,子采樣池化域的大小為c×c,偏置為b,池化過程移動步長為c.則平均值池化和最大值池化的算法表達式分別為:
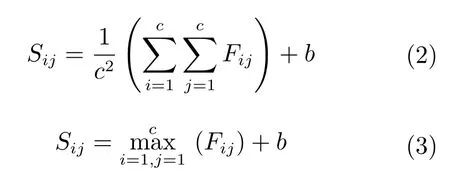
殘差塊是整個網絡的核心部分,基本思想是在一個淺層網絡基礎上疊加一個恒等映射(Identity mappings),并學習殘差函數,從而使得網絡不退化而且性能更好.殘差塊共有兩層,計算表達式如下:
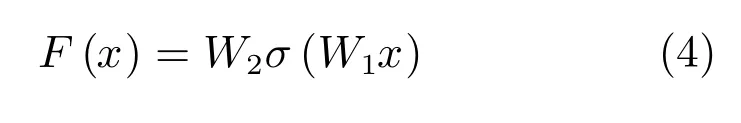
其中, 表示非線性函數Relu,W1和W2表示兩個卷積層的參數矩陣.
最后通過一個捷徑(Shortcut)與恒等映射相加,再通過一個Relu函數,獲得輸出y.
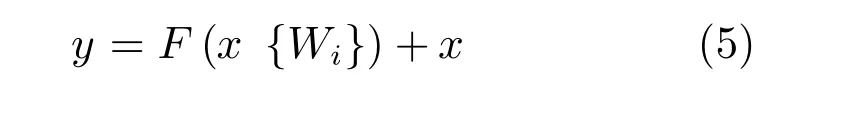
網絡的后半部分為行人屬性和ID特征分類網絡,主要用于提取行人的屬性特征和行人ID特征,由全連接層(Fully connected layers,FC)、Softmax層和損失層(Loss layers)組成.本文網絡架構相較于APR網絡最大的改進之處就是添加了FC0層,根據文獻[14]的研究,FC0層的主要作用是在模型表示能力遷移過程中充當“防火墻”的作用.具體來講,本實驗是基于ImageNet上預訓練得到的模型進行微調( fine tuning)得到最后的訓練結果的,則ImageNet可視為源域(Source domain).針對微調,若目標域(Target domain)中的圖像與源域中圖像差異巨大,如本文的實驗中,使用的是行人數據集,相比ImageNet,目標域圖像不是各種物體的圖像,而是行人圖像,差異巨大.在這種情況下,不含全連接層的網絡微調后的結果要差于含全連接層的網絡.因此,在源域與目標域差異較大的情況下,添加FC0層,可保證模型表示能力的遷移.
圖1中全連接層FC1-G和FCID主要起到分類器的作用,對于每一個全連接層來說,它的參數由節點權重矩陣W、偏置b以及激活函數f構成,可以表示為:
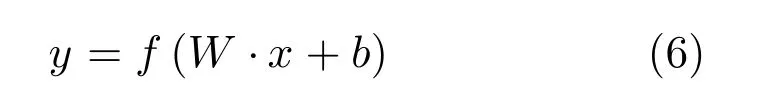
其中,x,y分別為輸入、輸出數據.
而Softmax層主要在全連接層的基礎上,進行分類結果的概率計算.可以表示為:
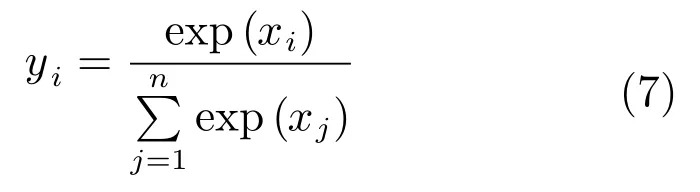
其中,xi為Softmax層第i個節點的值,yi為第i個輸出值,n為Softmax層節點的個數.
Loss層采用交叉信息熵損失(Cross-entropy loss)計算方式,可以表示為:
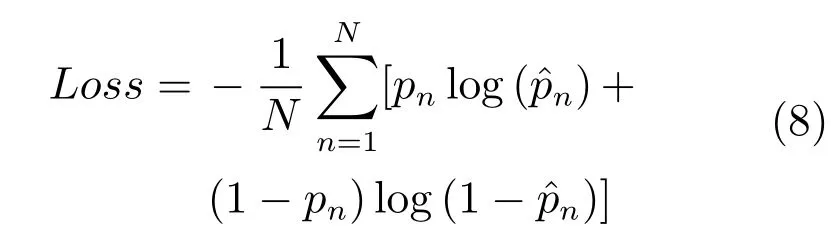
2.2 行人特征向量度量部分
本文從網絡中的FC0層中提取出2048維的特征向量,用于表示行人特征,采用交叉視角的二次判別分析法(Cross-view quadratic discriminant analysis,XQDA)[16]進行向量之間距離的度量,該方法是在KISSME算法和貝葉斯方法基礎上提出的.該方法用高斯模型分別擬合類內和類間樣本特征的差值分布.根據兩個高斯分布的對數似然比推導出馬氏距離.
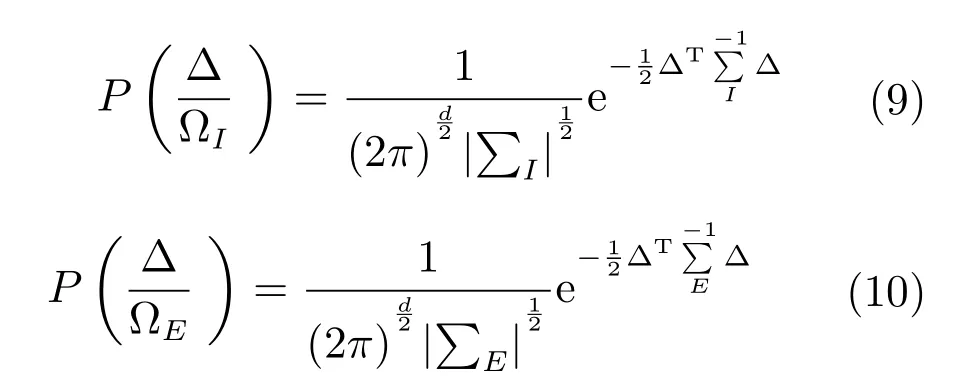
上述兩式取根號相除,得到對數似然比為:
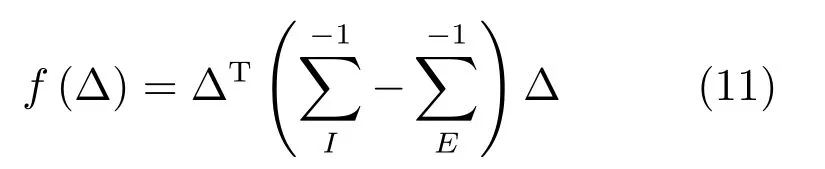
則兩個樣本之間的距離為:
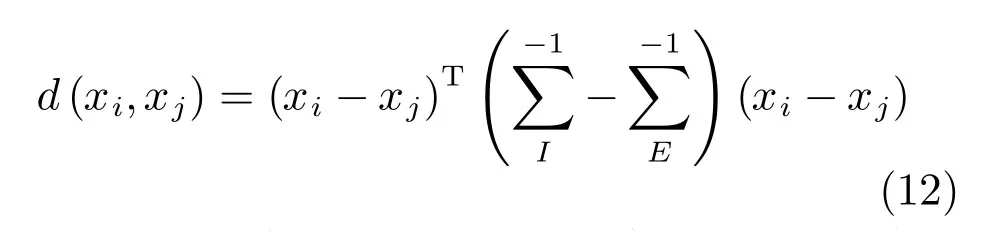
最后對所有的樣本之間的距離進行排序,選取距離最小的樣本作為識別結果.
3 基于數據分布先驗的損失函數設計
第1節從整體上介紹了本文提出的行人再識別網絡,本節主要介紹網絡中損失層計算的改進之處.本文主要利用數據先驗分布,對第1節提出的式(8)進行進一步的闡述和改進,為了便于問題描述,做出如下假設.
假設訓練數據集中(以Market 1501數據集為例,見表1)包含N張行人圖片,分別屬于M個不同的行人,每張圖片標注了G類屬性,包括性別,頭發長短,是否帶包,上衣顏色等屬性,對于每一類屬性,其中包含了Kg種屬性,以上衣顏色為例,其中包含黑色,白色,黃色等多種屬性.將數據集用集合方式描述如下:
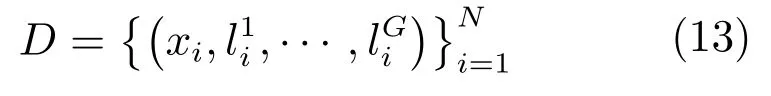
其中,xi為第i張行人圖片,行人的第g類屬性可以用向量表示,每類屬性中的第k種屬性都是二值向量表示,即如果行人存在該屬性,則,反之則
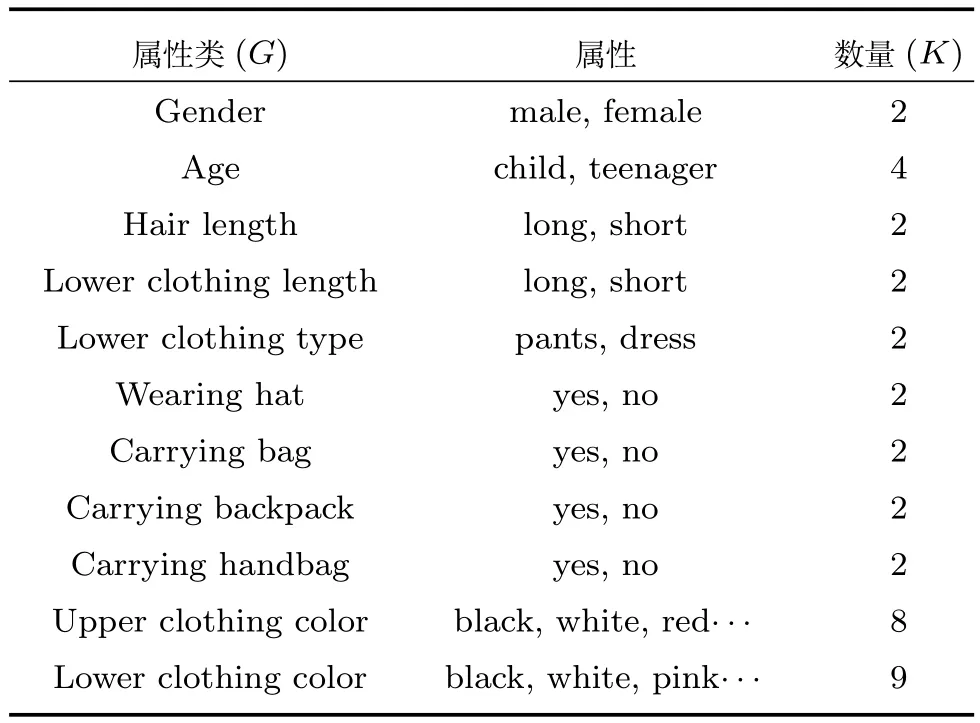
表1 Market 1501數據集中的屬性類別Table 1 The attribute category of Market 1501 dataset
APR網絡中的損失函數包括兩部分,一部分是屬性識別的損失函數,一部分是行人ID識別的損失函數.可以用下式進行計算:
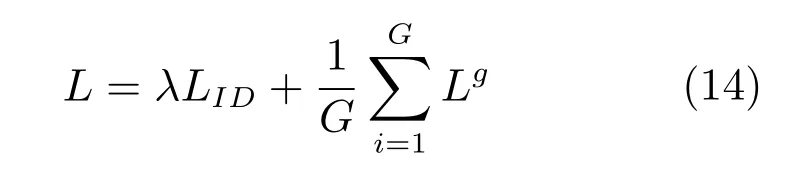
其中,LID表示行人ID識別的損失函數,Lg表示各類屬性識別的損失函數,λ為參數,用于調節兩者的權重.
行人ID識別的損失函數具體形式為:
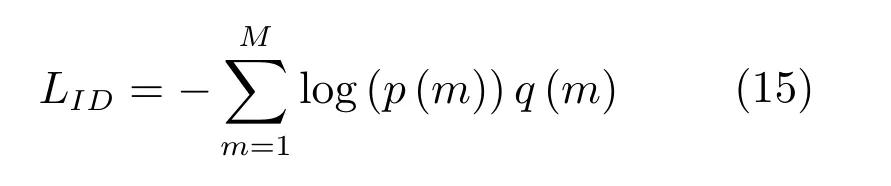
其中,p(m)表示第i個樣本屬于第m類行人的概率,由FCID層后的Softmax層計算得到;如果假設y為標注的正確行人類別,則q(y)=1,當m 6=y時,q(m)=0.
行人屬性識別的損失函數具體形式為:

其中,p(k)表示第i個樣本屬于第g類屬性中第k種屬性的概率值,由FC1?G各層后的Sofxmax層計算得到.
在APR網絡的基礎上,本文主要對基于屬性識別的損失函數,就是式(16)進行了改進.這部分改進包括兩方面:1)基于屬性樣本數量對損失函數進行歸一化;2)基于各屬性中正負樣本數量的占比對不同的屬性賦予不同的權重.下面在第3.1節和第3.2節分別進行介紹.
3.1 基于屬性樣本數量的損失函數歸一化
對通用的行人數據集統計發現,屬性間存在的樣本數量不平衡現象,這極大得影響了行人再識別的識別準確性.以Market 1501數據集為例,表2中統計了數據集中行人各屬性的數量.從表2可以看出,年齡是青年,穿短袖上衣,短褲等屬性的樣本數量較多,分別為569,712,641個樣本.攜帶手提包,帽子,穿粉色下衣等屬性的樣本數量很少,分別只有86,20,2個樣本.針對各屬性樣本數據不平衡的情況,本文在損失層的計算中,對各屬性的損失,基于其所包含的樣本數量進行了歸一化處理.最終,損失層改寫為下式:
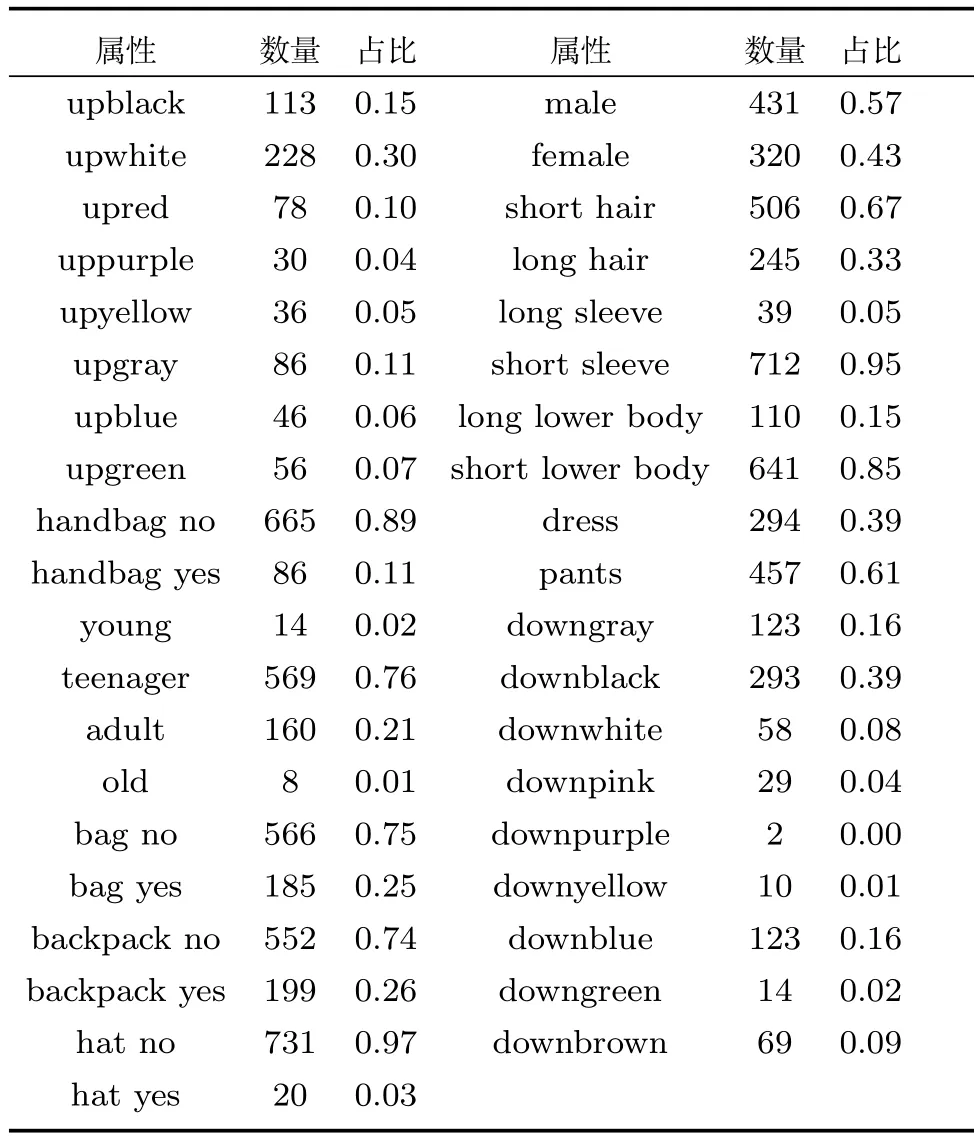
表2 Market 1501數據集中行人屬性訓練樣本數量及占比Table 2 Statistics of Market 1501 dataset
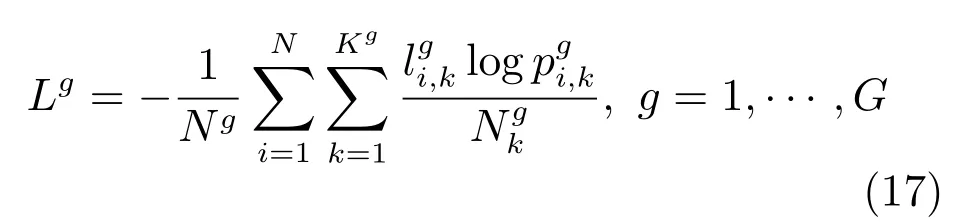
其中,Ng表示第g類屬性的訓練樣本數量,表示第g類屬性中第k種屬性的訓練樣本數量,概率值是FC1?G各層的輸出經由Softmax層計算而得的,表示第i個樣本屬于第g類屬性中第k種屬性的概率值.
Softmax層的計算方式如下:
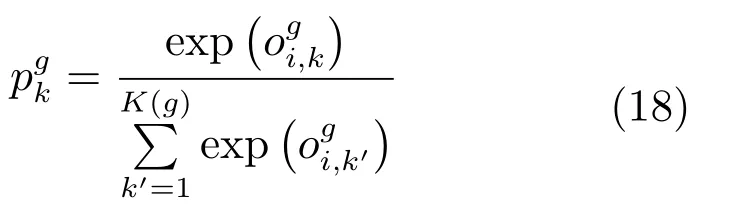
對于行人類別來說,每個行人的樣本數量大致相同,基本不存在數據不平衡問題,則不需要進行歸一化操作.假設FCID層的輸出為z=[z1,z2,···,zM]∈RM,同理可得,第i個樣本屬于第m類行人的概率為:
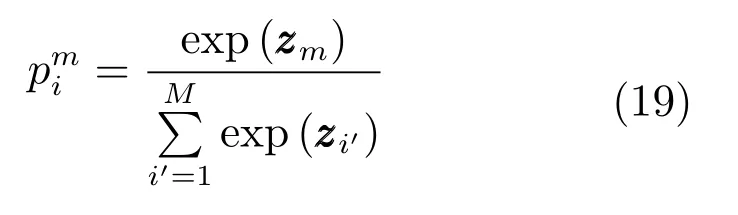
則可以將式(15)改寫成如下損失函數:

對于整個網絡來說,不能只計算屬性或者行人類別的損失函數,這會導致訓練無法收斂.所以網絡采用聯合損失函數的方式,將兩者結合起來,作為網絡整體的損失函數,聯合方式可以用下式表示:
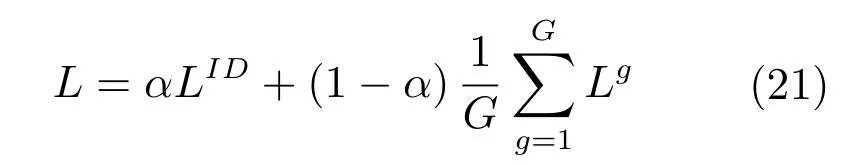
其中,0≤α≤1,該參數用于調節兩個損失層在網絡中的權重,通過實驗得到最佳值.在整個訓練過程中,通過反向傳播和梯度下降來計算網絡參數.
3.2 基于屬性正負樣本權重調整的損失函數設計
行人再識別數據庫中,不僅存在屬性間樣本數量不平衡的問題,也存在屬性內正負樣本數據不平衡問題.在選取的三個實驗數據集中,行人屬性內的正負樣本數據不平衡的現象也非常嚴重.以Market 1501數據集為例,從表2中可以看出,比如在是否戴帽子這個屬性類中,戴帽子的占較少數,沒有帽子的占大多數,占比為0.03/0.97.在上衣長短這個屬性中,也是正負樣本比例不均,長袖的只占0.05.在這種情況下,正樣本在在識別過程中起到的影響過小,不能很好地反應行人屬性真實情況,影響識別的效果.為了解決正負樣本不平衡的情況,參照文獻[10]的方法,本文在第3.1節提出的損失層計算基礎上,利用數據先驗分布知識,基于各屬性中正負樣本占比,對屬性識別的損失函數通過引入權重的方式進行了調整,將式(17)改寫為下式:
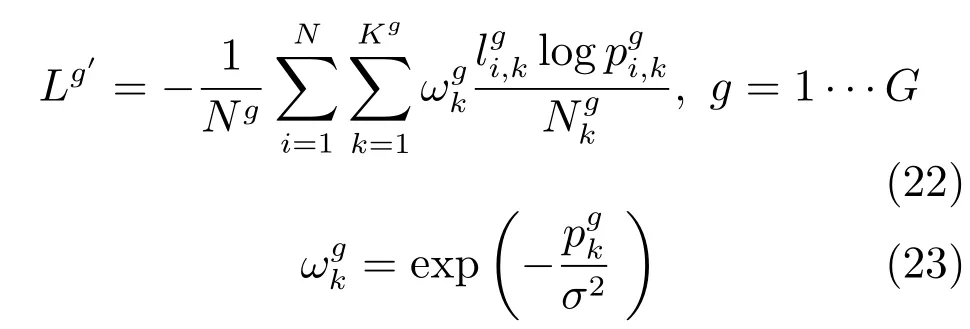
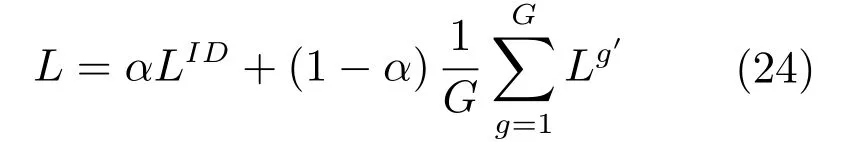
4 實驗結果與分析
本節首先介紹實驗中使用的測試數據和算法性能的評測準則,其次介紹本文算法中的一些相關參數設置和選取實驗,然后在不同公開實驗數據集上測試對各行人屬性的識別結果,最后介紹本文算法在不同公共實驗數據集上與已有的行人再識別算法的性能比較.本文所有的實驗是基于深度學習框架Matconvnet實現的,實驗平臺是配備64GB內存的Intel Core i7處理器和24GB顯存的Nvidia TITAN X顯卡的GPU工作站.
4.1 數據集和評價指標
本文主要基于三個具有行人屬性標注的行人再識別數據集進行實驗,分別是Market 1501、DukeMTMC數據集和PETA數據集,其中的一些行人圖片例子見圖2.

圖2 數據集行人圖片舉例Fig.2 Example of dataset pedestrian picture
Market 1501數據集是由6個攝像機拍攝采集生成的大規模行人再識別數據集,包含32668張行人圖片和3368張查詢集圖片,共有1501個不同ID的行人,對每個行人標注了27種行人屬性.其中751個不同ID的行人作為訓練集,750個不同ID的行人作為測試集.在本文實驗中,使用其中的651個ID的行人作為訓練集,剩下的100個ID的行人作為驗證集,用于確定參數.
DukeMTMC數據集是由8個攝像機采集,包含34183張行人圖片和2228張查詢集圖片,共有1812個不同ID的行人,其中1404個不同ID的行人出現在不同攝像機拍攝視野中,剩余的408個不同ID的行人是一些誤導圖片,對每個行人標注了23種行人屬性.根據數據集本身的劃分,其中702個不同ID的行人用于訓練,剩余的702個不同ID的行人用于測試.
PETA數據集是由19000張行人圖片組成,圖片分辨率分布在17×39到169×365之間.這些行人圖片共包含8705個不同ID的行人,每張行人圖片標注了61個二值行人屬性和4個多值行人屬性.在本文實驗中,隨機選取其中的9500張行人圖片作為訓練集,1900張行人圖片作為驗證集,7600張行人圖片作為測試集,按照經典的數據集使用方式,只選取其中標注數量最多的35個行人屬性作為識別目標.
為了與已有算法公正比較,實驗中,采用先前工作普遍采用的評價框架.將數據集事先劃分為訓練集和測試集,其中測試集由查詢集和行人圖像庫兩部分組成.當給定一個行人再識別算法,衡量該算法在行人圖像庫中搜索待查詢行人的能力來評測此算法的性能.已有的行人再識別算法大部分采用累積匹配特性(Cumulative match characteristic,CMC)曲線評價算法性能,給定一個查詢集和行人圖像庫,累積匹配特征曲線描述的是在行人圖像庫中搜索待查詢的行人,前r個搜索結果中找到待查詢人的比率.首位匹配率(r=1)很重要,因為它表示的是系統真正的識別能力.另外,同時采用平均準確率(Mean average precision,mAP)評價算法性能,平均準確率是對準確率和召回率的全面反映,計算平均準確率時,將準確率和召回率作為橫縱坐標,繪制曲線,曲線包圍的面積就是平均準確率的值,該值最大時,表示系統的準確率和召回率達到了最優.
4.2 網絡參數與結構設置
本網絡參數設置是在文獻[11]的基礎上微調而得的,訓練過程中設置批尺寸(Batch size)大小為64,epochs為55,學習率初始值為0.001,在最后5個epochs中,調整為0.0001.各參數的微調過程具體見圖3.
參數α.如圖3(a)所示,其中曲線代表了式(24)中的參數對準確率的影響,當α取不同值時,網絡的行人再識別準確率也隨之發生變化.基于Market 1501數據集,當網絡不使用行人屬性標簽信息時(即α=1時),首位匹配率是72.36%.當網絡僅考慮行人屬性標簽信息時(即α=0時),首位匹配率是76.81%.當0.1≤α≤0.9時,也就是同時考慮屬性和ID標簽信息時,首位匹配率要普遍高于單獨考慮這兩者,在α=0.7時,首位匹配率達到最大值86.90%.基于DukeMTMC數據集,當α=1時,首位匹配率是60.34%.當α=0時,首位匹配率是62.16%.在α=0.7時,首位匹配率達到最大值72.83%.基于PETA數據集,當α=1時,首位匹配率是70.13%.當α=0時,首位匹配率是65.24%.在α=0.6時,首位匹配率達到最大值76.37%.綜上考慮,實驗中取α=0.7.

圖3 網絡參數及結果對比Fig.3 Comparison of network parameters and results
迭代次數.如圖3(b)所示,其中曲線代表了當網絡迭代不同次數時,網絡的首位匹配率變化情況.每迭代1000次測試一次網絡性能,隨著迭代次數達到8000次左右,網絡性能基本穩定,所以將網絡的epochs設置為55.
屬性選取.圖3(c)表示了Market 1501數據集去除不同屬性后,網絡的再識別準確率.有些行人屬性容易產生誤檢和漏檢,從而對行人再識別帶來負效應,所以考慮從數據集標注的行人屬性中,剔除一些具有負效應的屬性.以所有屬性參與訓練得到的準確率作為基準,每次去除一類屬性,得到識別準確率,與基準進行對比,其中橫坐標為去除的屬性.圖3(d)表示了DukeMTMC數據集的實驗結果.可以發現,在Market 1501數據集中,不使用是否有帽子這個行人屬性,再識別的準確率反而得到了提升,主要因為帽子這個屬性漏檢的概率較大,所以本文實驗中不使用該屬性.而在DukeMTMC數據集的測試結果表明,減少任一行人屬性后,行人再識別的識別效果都會降低,所以使用所有的屬性.
全連接層FC0.如圖3(e)所示,其中曲線代表了網絡是否添加全連接層FC0對網絡準確率的影響.圖中實線的趨勢線代表添加了完整本文算法結果,虛線的趨勢線代表去除全連接層的本文算法,可以發現,添加了全連接層后,本文提出的訓練網絡更加的穩定,能更快的迭代到穩定值,并且提升了算法在三個數據集上的首位匹配率.與本文算法完整算法相比,去除全連接層后,在Market 1501、DukeMTMC和PETA數據集上的首位匹配率分別下降了0.89%,0.76%和1.31%.可以看出,全連接層的添加對于本文算法的識別效果具有較大的提升作用.添加全連接層能夠較明顯改善識別效果的原因主要有如下兩點:1)根據文獻[13]的研究,全連接層可以提高網絡在微調后的判別能力,使得網絡在這三個常用數據集上的判別能力得到提升;2)本文采用的是殘差網絡,不包含全連接層,所以在添加了全連接層后,豐富了網絡結構,從而提高特征提取能力,進而提升了網絡的識別效果.鑒于以上兩點,本文采用添加了全連接層FC0的網絡.
數據集間交叉識別.如圖3(f)所示,其中實線代表了根據各自數據集的先驗分布訓練得到的網絡進行數據集內識別結果(例:用數據集Market 3中的訓練集訓練得到的網絡,對數據集Market 1501中的測試集進行測試),虛線表示基于三個數據集的先驗分布訓練的網絡進行數據集間交叉識別的結果(例:用數據集DukeMTMC和PETA中的訓練集分別訓練得到的網絡,對數據集Market 1501中的測試集分別進行測試分別記為Market-D和Market-P,后面的命名規則相同,需要說明的是,當待測數據集中含有訓練數據集中沒有的屬性時,從待測數據集的訓練集中選取含有特殊屬性的樣本,對訓練集進行擴充以后再進行訓練.);實驗結果表明,數據集間交叉識別的性能相對于數據集內識別的性能是有輕微下降.對于數據集Market 1501來說,利用數據集DukeMTMC和PETA中的訓練集訓練得到的網絡,在該數據集上測試得到的首位匹配率相比于數據集內識別結果,分別下降了0.82%和1.13%;對于數據集DukeMTMC來說,利用數據集Market 1501和PETA中的訓練集訓練得到的網絡,在該數據集上測試得到的首位準確率相比于數據集內識別結果,分別下降了0.67%和1.38%;對于數據集PETA來說,利用數據集Market 1501和DukeMTMC中的訓練集訓練得到的網絡,在該數據集上測試得到首位匹配率相比于數據集內識別結果,分別下降了1.54%和1.78%.這主要是因為PETA中屬性分布相對于Market 1501和DukeMTMC有較大的差異.但是相對于不考慮數據先驗分布的APR網絡,數據集間交叉識別的性能還是有所提升,在Market 1501,DukeMTMC和PETA數據集上,首位匹配率分別至少提升了1.48%,0.76%,2.61%.所以,在實際應用中,在對待檢測數據集屬性分布不可知的情況下,可以直接采用基于已有的數據集訓練的網絡實現行人再識別工作.

表3 Market 1501數據集各屬性識別準確率(%)Table 3 Accuracy rate of each attribute recognition of Market 1501 dataset(%)
4.3 各屬性的識別精度
本文基于三個通用行人屬性數據集,分別進行了行人屬性的識別實驗,識別準確率如表3~表5所示.同樣地,選取APR網絡的實驗結果作為對比,其中APR網絡在PETA數據集上的結果是基于APR文獻源代碼復現得到.
首先,從整體來看,在這三個數據集上,本文的識別準確率相較于APR網絡都有了較大的提升,平均準確率分別提升了0.99%、2.03%和3.83%,就各屬性來說,識別準確率也都提升了0.12%~7.29%不等.這表示本文提出的網絡相較于APR網絡在行人屬性識別上具有更好的性能.
其次,從一些具有強數據不平衡的屬性來看,以Market 1501數據集為例,其中是否有包這個屬性,識別準確率提高了7.29%,提升程度比較大,對于一些數據平衡的數據,比如性別這個屬性,識別準確率只提高了0.28%.這表明本文提出的基于數據先驗分布知識的權值調整策略,對行人屬性的提升具有明顯的效果,尤其是具有強數據不平衡的屬性,提升效果更為明顯.

表4 DukeMTMC數據集各屬性識別準確率(%)Table 4 Accuracy rate of each attribute recognition of DukeMTMC dataset(%)

表5 PETA數據集各屬性識別準確率(%)Table 5 Accuracy rate of each attribute recognition of PETA dataset(%)
最后,如圖4所示,列舉了兩個行人屬性識別結果的例子,本文的網絡會對行人所有的屬性進行預測并打分,可以發現,左邊行人的屬性預測全部正確,而右邊行人的下衣種類和是否帶手提包兩個屬性識別錯誤.

圖4 行人屬性識別結果舉例Fig.4 Example of the result of pedestrian attributes
4.4 行人再識別結果
本文基于三個通用行人屬性數據集,進行了行人再識別實驗,實驗結果如表6~表8所示.表中“*”表示原文獻中沒有公布相關數據,本文使用其源碼復現得到.其中“–”表示沒有該項實驗結果.
4.4.1 Market 1501數據集
首先,針對本文提出的三個改進點分別做了對比實驗,在表6中分別以“本文–FC0”,“本文–歸一化”,“本文 –權重”代表基于APR 網絡單獨添加這三處改進得到實驗結果,“本文–歸一化+權重”代表同時添加這兩項改進得到的實驗結果.可以發現,相對于APR網絡,這4處改進在首位匹配率上都得到了提升,分別提升了1.08%、0.63%、1.38%、2.02%,其中添加了全連接層和改變權重對實驗效果的提升比較明顯,對數據進行歸一化也有一定提升.相應的平均準確率也有0.44%、0.15%、0.56%、0.79% 的提升,這說明三處改進對于提高行人再識別結果都有較大作用,而且聯合歸一化和占比權重調整兩處改進,得到了較單獨改進更好的實驗效果,說明兩處改進之間具有互補之處.
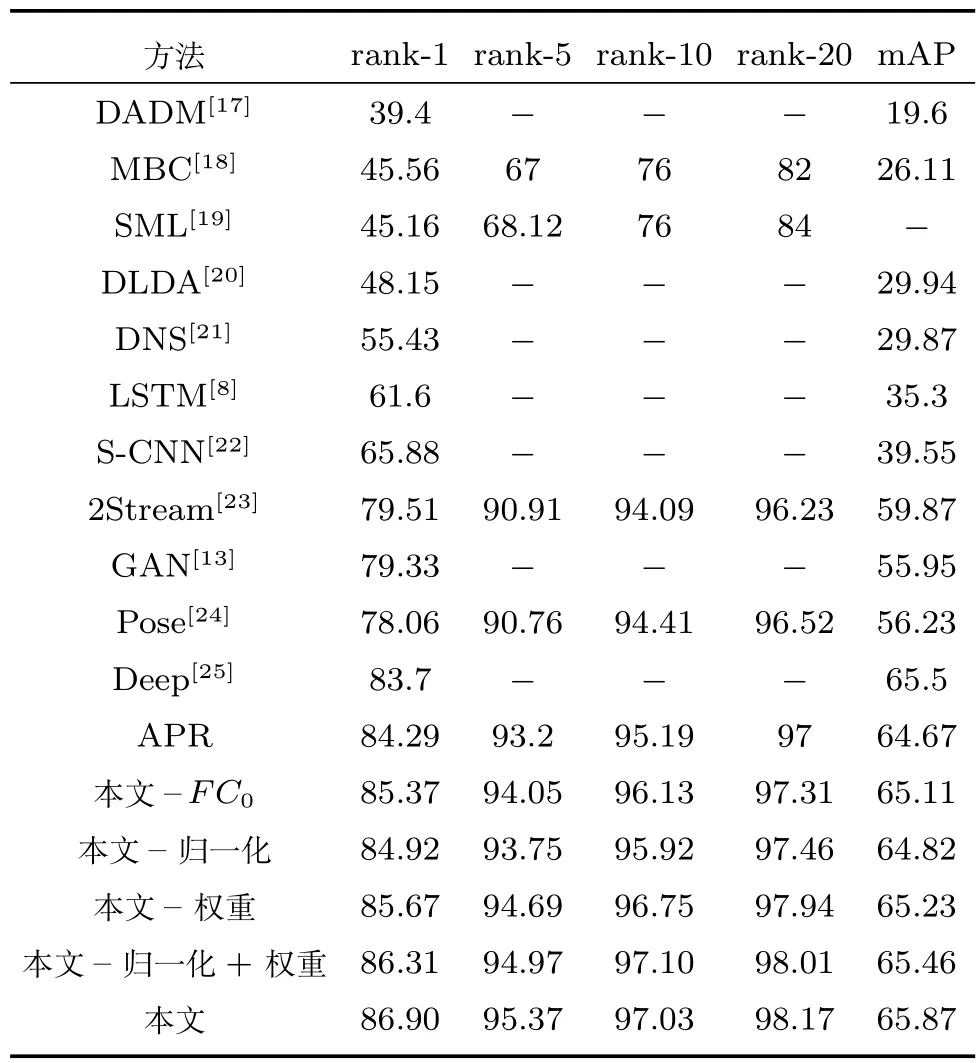
表6 Market 1501數據集行人再識別結果Table 6 Re-id results of the Market 1501 dataset
其次,在Market 1501數據集,本文選取了DADM、MBC等經典方法進行對比.可以發現,傳統方法的首位匹配率普遍不是很高,一般在50%以下.在使用深度學習方法以后,準確率得到了一個巨大的提升,而APR網絡更是達到了84.29%的首位匹配率和64.67%的平均準確率.本文在APR網絡的基礎上,進一步提高了識別的準確率,達到了86.90%的首位匹配率和65.87%的平均準確率,第5,10,20匹配率也有相應的提升.
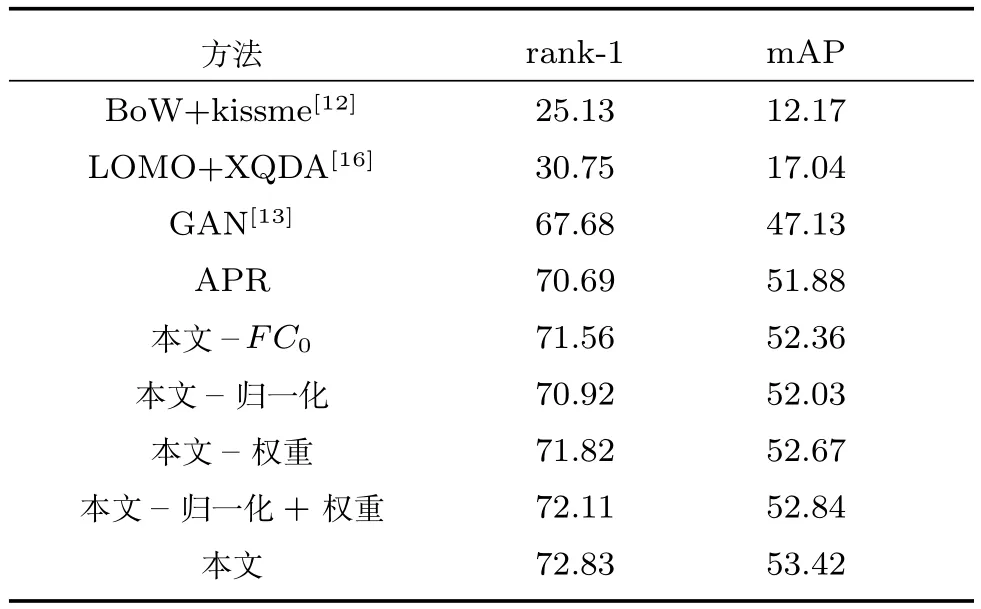
表7 DukeMTMC數據集行人再識別結果Table 7 Re-id results of the DukeMTMC dataset
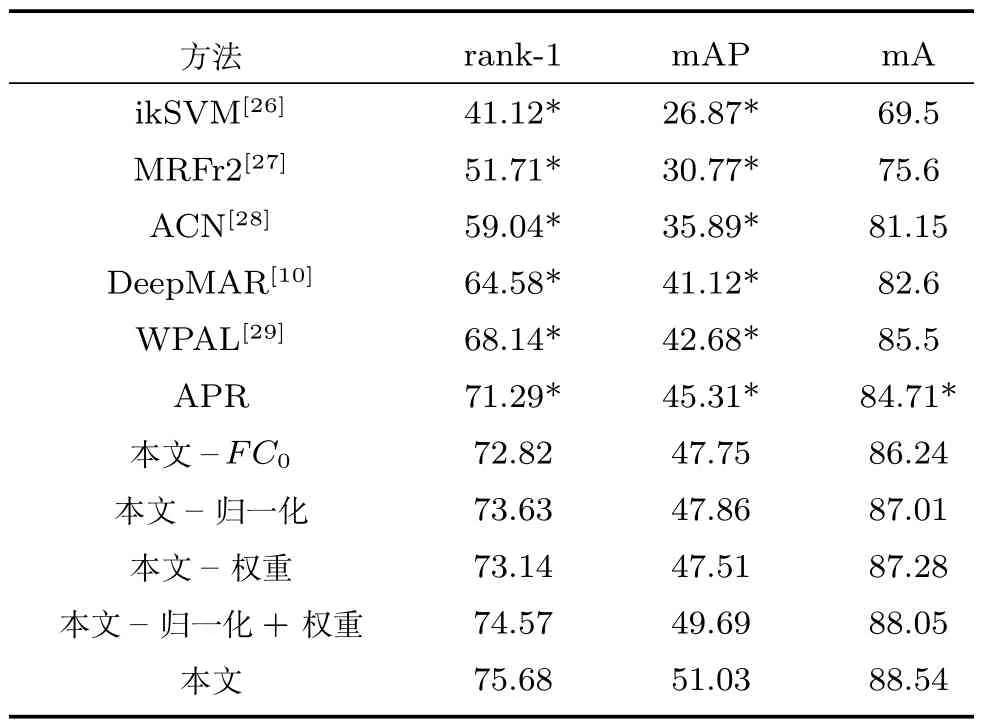
表8 PETA數據集行人再識別結果Table 8 Re-id results of the PETA dataset
4.4.2 DukeMTMC數據集
同樣的,針對本文提出的三個改進點分別做了對比實驗.從表7中可以發現,相對于APR網絡,這四處改進在首位匹配率上都得到了提升,分別提升了0.87%,0.26%,1.13%,1.42%,類似于Market 1501數據集的實驗結果,添加全連接層和改變權重對實驗效果的提升比較明顯,相應的平均準確率也有0.48%,0.25%,0.79%,0.96%的提升,這說明對于該數據集,這三處改進也有較好的實驗效果.
其次,針對DukeMTMC數據集,由于使用該數據集的評測方法與Market 1501數據集不盡相同,從中選取了BoW、LOMO等經典方法進行對比.可以發現,這兩種傳統方法的效果不是很好.對抗學習達到了67.68%的首位匹配率.APR網絡在該數據集達到了70.69%的首位匹配率和51.88%的平均準確率.本文在APR網絡的基礎上,在該數據集上達到了72.83%的首位匹配率和53.42%的平均準確率.由于這幾個方法沒有提供第5、10、20匹配率,所以在此不作對比.
4.4.3 PETA數據集
與前兩個數據集相同,針對本文提出的三個改進點分別做了對比實驗.從表8中可以發現,相對于APR網絡,在這4處改進中分別提升了 1.53%、2.34%、1.85%、3.28%,類似于前兩者的實驗結果,添加全連接層和改變權重對實驗效果的提升比較明顯,相應的平均準確率也有1.53%、2.30%、2.57%、3.34% 的提升,由于該數據集各屬性之間數量差異較大,且屬性內正負樣本不平衡嚴重,所以本文方法在此數據集上有較大提升.
其次,針對PETA數據集,很多方法是比較各屬性的平均準確率(Mean accuracy,mA),而不是比較rank-1和mAP的值,所以本文一方面進行了mA的比較,可以發現,本文達到了88.54%的屬性平均準確率,較傳統方法有了大幅度提升,相對于APR網絡也是有3.83%的提升.另一方面,本文通過對文獻源代碼進行復現,得到rank-1和mAP的值,可以發現,本文相對于APR網絡和經典算法,也是有較大的提升,達到了75.68%的首位匹配率和51.03%的平均準確率.
綜上可以得出,本文提出的網絡相對于一些經典方法,在首位匹配率和平均準確率上都有很大的優勢,相較于APR網絡也有較大的提升,表明本文提出的基于數據先驗知識的行人再識別網絡,對于行人再識別效果提升是有效的.如圖5所示的行人再識別結果的兩個例子,可以發現,雖然存在一些誤識,但是總體識別效果已經達到較高的程度.

圖5 行人再識別結果舉例Fig.5 Example of the re-id result
5 結語
隨著深度學習技術的發展和帶屬性標注行人數據集的出現,近年來基于行人屬性的行人再識別有效提升了識別精度.在已有研究基礎上,本文基于行人屬性中的數據先驗分布知識設計了新的用于行人屬性識別和再識別的深度神經網絡.實驗結果驗證了本文方法的有效性.但依舊沒有充分挖掘數據集的內在信息,實驗效果還可進一步提高.后續工作將進一步研究如何在網絡設計中融入屬性之間的相關性和異質性.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
