基于多隱層Gibbs采樣的深度信念網絡訓練方法
2019-06-11 06:42:50史科陸陽劉廣亮畢翔王輝
自動化學報 2019年5期
史科 陸陽 劉廣亮 畢翔 王輝
在機器學習領域里,最重要也是最困難的莫過于特征的提取,抓住事物區分度強的特征也就抓住了事物的本質.在此基礎上,分類器的性能會得到極大的提高.但長期以來如何進行特征提取一直是個棘手的問題,不同領域的數據涉及到不同的提取方法,需要大量的領域知識作為支撐.另一方面,一直以來各種深度神經網絡模型都困擾在如何找到有效的訓練方法.傳統的反向傳播算法在多隱層神經網絡上存在著梯度消失的問題,使得深度網絡的性能甚至還不如淺層網絡[1].這兩個關鍵問題在2006年Hinton提出的文獻[2]中得到了很大程度上的解決.在文獻[2]中提出的多層限制玻爾茲曼機(Restrict Boltzmann machine,RBM)堆疊降維的方法,在無監督的情況下實現了自動化的特征學習,實驗表明效果比傳統的PCA方法要好得多.在此基礎上增加分類器就構成了深度信念網絡模型(Deep belief network,DBN).作為一種生成模型,DBN有著重要的研究價值.相對于判別式模型,生成模型可以反向生成研究對象的實例,可以直觀地觀察出生成對象的各種特征,為進一步的研究提供可能.在隨后的大量研究中,DBN被廣泛應用到了圖像識別[3?4]、語音識別[5]、自然語言處理[6]、控制[7]等多個領域,并取得了很好的效果.
針對DBN訓練方法的研究一直是一個熱點[8?9].Goh等[10]提出了一種有監督的預訓練方法,提高了DBN的精度.李飛等[11]從Gibbs采樣的次數入手,提出了動態的采樣方法,喬俊飛等[12]將自適應學習率引入到對比散度(Contrastive divergence,CD)算法中,提高了算法收斂速度.典型的DBN的訓練分為2個階段[13],分別是逐層預訓練和整體精調.在逐層預訓練階段,從網絡最底層的RBM開始,自底向上逐層使用無監督的貪婪方法來使得每層RBM的損失誤差最小.然后在整體精調階段使用有監督的學習方法,針對有標簽的數據使用梯度下降進行整體權值修正.實驗表明此種方法是有效的,很好地解決了一直以來深度網絡無法有效訓練的難題.逐層預訓練將網絡的權重調整到一個“合適”的初始位置,如果不進行逐層預訓練而直接進行整體精調,則網絡很難收斂,在逐層預訓練的基礎上進行整體精調可以確保網絡能夠收斂到很好的位置上.在此基礎上,網絡權重的初始位置有沒有進一步改進的可能,從而獲得更好的網絡性能呢?DBN的逐層預訓練是在堆疊著的每個RBM內進行多步Gibbs采樣來逼近數據的真實分布的,采樣在RBM的可視層和隱藏層之間迭代進行.本文在此基礎上,提出了一種兩階段的無監督預訓練方法,在已有預訓練的基礎上引入多隱層Gibbs采樣預訓練方法,將多個RBM 組合成一個整體概率模型進行預訓練,使得Gibbs采樣在多個RBM中進行,從而獲得更“合適”的網絡權值初始位置.在MNIST、ShapeSet和Cifar10數據集上的實驗表明,此種方法比傳統的深度信念網絡訓練方法可以獲得更好的分類效果,在包含(1300,1300,1300,1300)四層隱層的DBN上使用固定學習率的實驗,相對于傳統方法的可以將MNIST的錯誤率從1.25%降低到1.09%.
本文先介紹了受限玻爾茲曼機和深度信念網絡模型,然后提出了改進后的算法,最后在MNIST、ShapeSet和Cifar10數據集上驗證并討論了實驗結果.
1 受限玻爾茲曼機模型
DBN的預訓練是通過受限玻爾茲曼機的訓練進行的,所以我們先描述RBM模型.RBM是一個無向圖模型,它可以被看做是一個二部圖(Bipartite graph),兩個部分分別是可視層v和隱層h,層間結點全連接,層內結點不連接,如圖1所示.可視層接收數據輸入,兩層間的連接權值用W表示,W∈Rn×m.可視層的偏置用a表示,a∈Rn,隱層的偏置用bb表示,b∈Rm.RBM的隱層可以理解為模型中尚未被觀測到的部分,可視層可以理解為可以觀測到的部分,它們的節點狀態一般是二進制的,取值1或0.
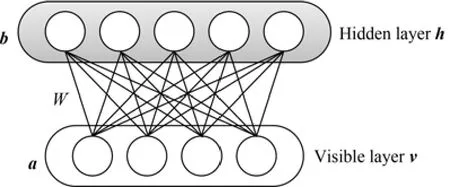
圖1 RBM模型Fig.1 Restricted Boltzmann machine
RBM是能量模型系統,它通過能量來表示系統當前的狀態,能量定義為[2]:

其中,n表示可視層的節點數目,m表示隱藏層節點數目,就表示可視層i節點到隱層j節點的權值大小.使用θ={W,a,b}表示系統所有參數的集合.
給定了能量定義,就可以在此基礎上定義系統整體的概率分布[2]:

其中,分母部分稱之為歸一化因子或配分函數(Partition function),使得系統概率取值在[0,1]范圍內,一般用表示.
RBM的結構決定了隱層和可見層是相互條件獨立的,于是可以得到條件概率分布[14]:
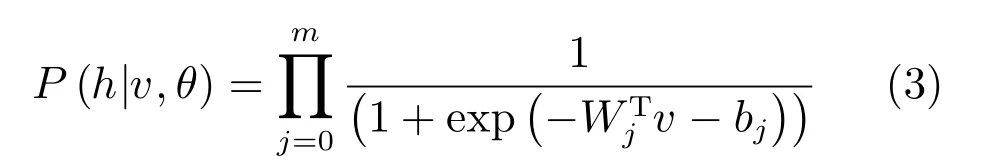
以及
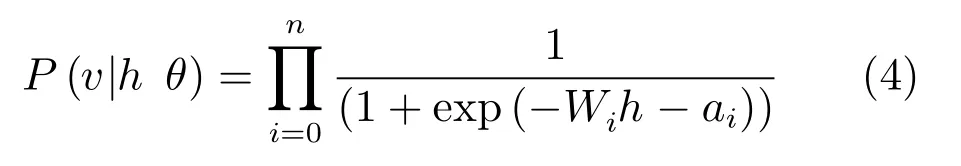
RBM的訓練就是依據訓練樣本來估計模型的參數,使得此模型的推斷數據盡可能地接近真實數據.由式(2)可得邊緣概率分布,通過使用最大似然的方法來估計,對其對數求導數有[1]:
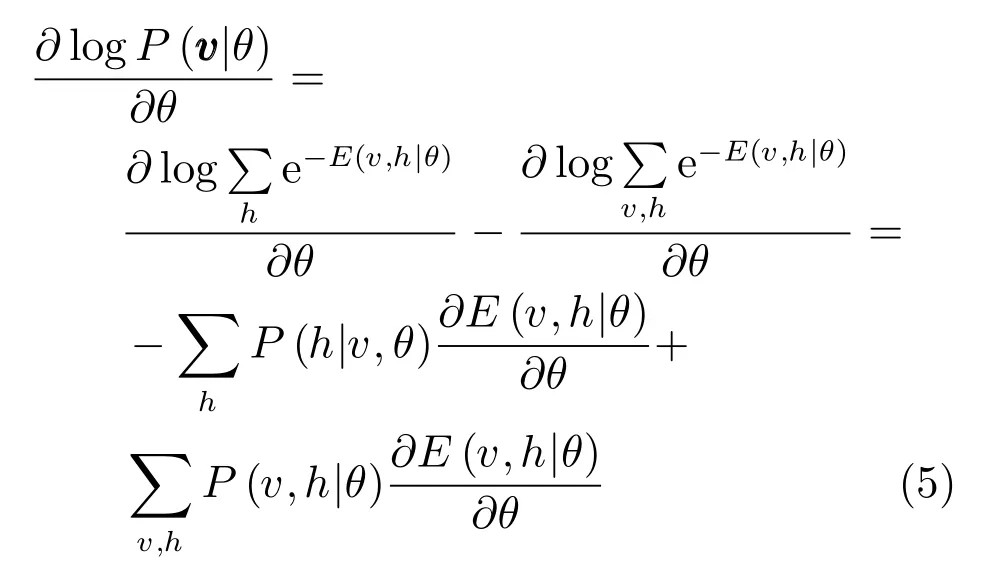
對于訓練樣本,使用 “data”表示分布P(h|v,θ), 使用 “model”表示分布P(v,h|θ). 其中,使用表示關于分布p的數學期望.因為,聯合式(1)的導數,式(5)可表示為[1]:
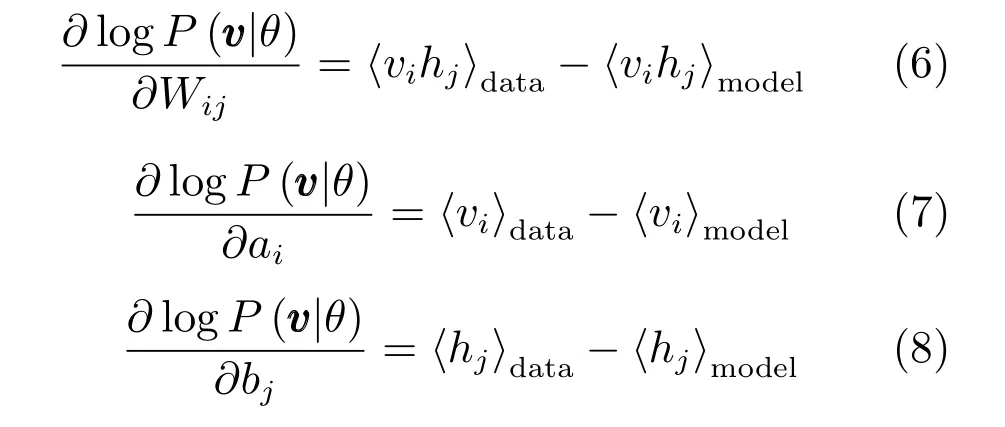
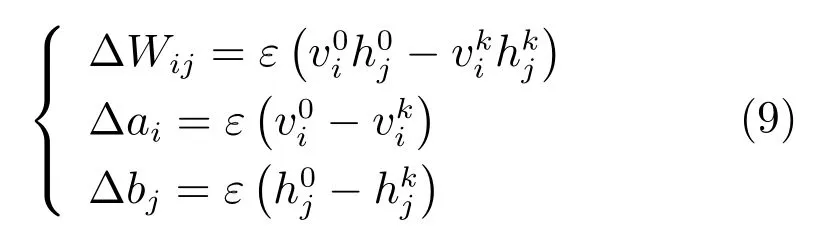
其中,ε為學習率.
2 深度信念網絡
多個玻爾茲曼機堆疊后,就形成了深度信念網絡[13].通常可以在最上層再增加一層邏輯回歸(Logistic regression)層來作為有監督學習分類器.DBN模型示意圖見圖2.

圖2 DBN模型Fig.2 Deep belief networks
Hinton在文獻[13]中提出了深度信念網絡的訓練方法,分為逐層預訓練和整體精調兩個階段.在逐層預訓練階段,從網絡最底層的RBM開始,自底向上逐層使用無監督的貪婪方法來使得每層RBM的損失誤差最小.在此過程中相鄰的RBM兩兩連接,下層RBM的輸出傳遞到上一層RBM作為輸入,最底層的輸入為訓練數據,最頂層的輸出傳遞給分類器.在整體精調階段使用有監督的學習方法,將所有隱層的權值看做一個整體,使用梯度下降的方法針對有標簽的數據進行權值修正.第一階段的學習過程提高了在構造模型下訓練數據的似然概率的變分下限,是無監督的,不需要標簽信息.如果不進行第一階段的逐層預訓練,直接使用隨機初始化的參數直接進行梯度下降法則很容易導致訓練失敗,模型容易陷入局部極值點[1].通過RBM的逐層訓練,深度網絡每層的參數都已處于一個比較好的位置上,在此前提下進行全局性的梯度下降可以精調整個模型的精度,獲得更好的結果.
3 多隱層Gibbs采樣預訓練
作為生成模型的DBN,在向下的生成方向上,不僅是最底層的可視層,整個網絡的每一層都是為了使得重構數據的分布和真實數據的分布盡可能地接近.如圖3所示,表示DBN的隱層.傳統的逐層訓練算法,針對組合的RBM,是其可視層,是其隱層,Gibbs采樣是在這兩層之間迭代的,使得此RBM 參數Wm+1收斂,以更好地接近層輸入的分布.采樣先從層的輸入開始向上構建層,概率為再在此基礎上反向重構出層的數據,概率為Salakhutdinov等在文獻[16]中指出,在DBN中如果每層RBM都被正確地初始化(可以通過逐層預訓練保證),則反向的P(hm+1|hm+2,Wm+2)是比P(hm+1| hm,Wm+1)更好的hm+1上的后驗分布.反向的概率P(hm+1| hm+2,Wm+2)是由高層多個隱層計算得到,包含了比低層更抽象更豐富的信息.在此基礎上我們使用P(hm+1|hm+2,Wm+2)來代替P(hm+1| hm,Wm+1)以獲得更好的近似.

圖3 針對hm+1的采樣Fig.3 Sampling for hm+1
于是針對hm+1, hm組合的RBM,hm層的對數似然梯度為考慮到

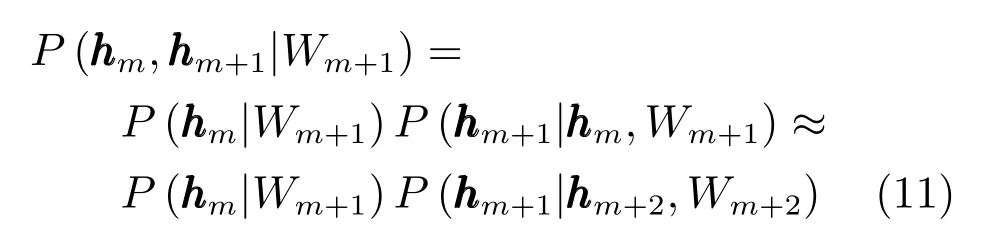
以及能量對于Wm+1的梯度,所以式(10)的第二部分為

同理,式(10)的第一部分為
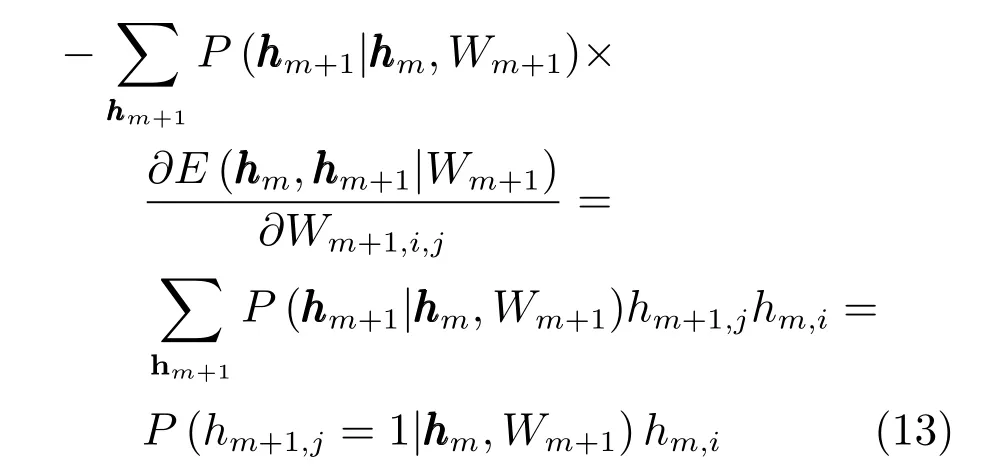
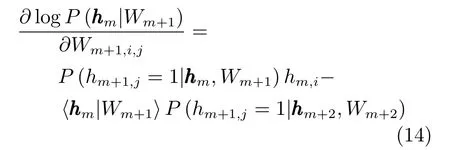
條件概率為

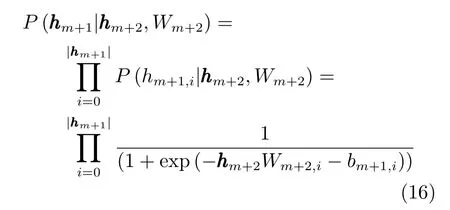
對于bm和bm+1的梯度可以通過類似的方法推導,使用之前的記號,可以得到類似式(6)~(8)的結論.

Gibbs采樣是一種馬爾科夫蒙特卡羅(Markov chain Monte Carlo,MCMC)方法,可以利用已有數據來推斷丟失的數據.對于從到的多隱層Gibbs采樣是在這n?m+1個隱層上進行的.信號先從層開始向上使用式(15)傳播,到達最上層層后開始使用(16)反向傳播,等到信號回退到層后使用采樣值來估計,隨后向下采樣估計,再使用式(17)~(19)來更新網絡參數.注意到我們僅更新,層相關權重,而將高層權重固定,以保持模型的穩定,所以本質上還是一種逐層訓練方法.在迭代時要注意從底向上逐層進行.如前兩節所述,現有的DBN預訓練是針對每層的RBM使用Gibbs采樣來逼近模型的真實分布,使得每層RBM和其真實分布的差異減小,但DBN的推斷過程是將所有的RBM 層看做一個整體進行的,通過引入多隱層Gibbs采樣可以在逐層逼近的基礎上進一步在局部模型上逼近真實分布.
多隱層的選擇和組合方式有多種可能,本文通過實驗討論了以下4種類型的組合方式:兩兩不嵌套組合(Non-nested)、兩兩嵌套組合(Nested)、增量不嵌套組合(Incremental non-nested)和增量嵌套組合(Incremental nested).以4隱層的DBN舉例,假設4個隱層分別為,那么兩兩不嵌套組合的RBM序列為;兩兩嵌套組合的RBM為;不嵌套增量組合的序列為嵌套增量組合的序列為
綜上所述,基于多隱層Gibbs采樣的DBN模型算法整體描述如下:
步驟1.無監督的逐層預訓練.對于DBN中的RBM層進行逐層貪婪預訓練.令XXX為最底層RBM的輸入.自底向上,對于第i層RBM,計算隱層節點概率并交替采樣,具體如下.
步驟1.1.進行K次Gibbs采樣.使用式(3)計算概率分布,然后從分布中抽取再使用式(4)計算并從中抽取
步驟1.2.以下式和(9)來更新參數
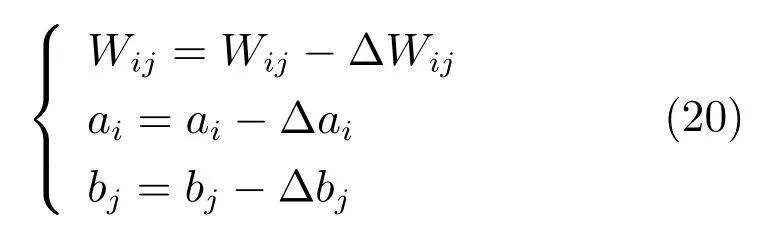
步驟2.無監督的多隱層預訓練.自底向上組合多隱層,對于每個RBM組合,執行以下步驟進行多隱層預訓練.
步驟2.1.依據式(15)向上計算每層概率分布并抽取出hi,j∈{0,1},直到頂層.
步驟2.2. 依據式(16)計算反向概率,每計算一層同時抽取,直到底層.
步驟 2.3.使用式(17)~(19)計算梯度,并更新權重.
步驟3.有監督的全局精調.步驟如下.
步驟3.1.對于所有的RBM層,自底向上傳遞信號.第i層的輸出作為第i+1層的輸入.
步驟3.2. 將最上層RBM的輸出和樣本標簽Y傳遞給分類器,使用梯度遞減更新所有的參數.
4 實驗與分析
實驗部分使用MNIST手寫數字數據集、合成的數據集ShapeSet以及真實物體圖像數據集Cifar10來測試本文的模型.MNIST數據集包含70000張人類手寫數字的圖片,每張圖片包含一個0~9的手寫數字,被分割成28×28的黑白兩色點陣.數據集分為兩部分,一部分是包含60000張圖片的測試用數據,一部分是剩下的10000張用于測試.每張圖片都有對應的標簽數據,表明正確的數字是什么.MNIST數據集是一個廣泛使用的評估機器學習算法的數據庫,其中包含的手寫數字信息來自于不同的書寫方式,且數據集沒有經過任何拉伸轉換等幾何上的處理.在本文實驗中,也沒有進行任何額外的預處理,相當于沒有任何領域知識的介入.ShapeSet是一個人工生成的數據集,每個樣本可以包含任意多個平行四邊形、三角形或圓形的圖像,圖像之間可以互相疊加遮擋,且有任意的前景和背景色.在本文的實驗中,設置每個樣本的大小為32×32,限制樣本中出現的圖形數為1或2,兩個圖形之間的遮擋率為不超過50%.Cifar10數據集包含60000張32×32大小,有RGB三原色信息的彩色圖片,共有10類物體,每個類別6000張.
在DBN的最上層,增加了一層邏輯回歸層來預測類別,使用Softmax激活函數,用預測值和真實類別值之間的負對數似然函數來計算損失.通常情況下動態的學習率會取得更好的結果,學習率一般隨著訓練次數的增加而逐漸減小,以防止模型錯過最小值.在本文的實驗中,目的是驗證新的算法相對傳統算法的有效性,沒有去討論模型在實驗數據集上所能達到的最優結果,所以使用了常數的學習率.無論是DBN還是改進后的算法,在訓練的第一階段,也就是逐層訓練時使用的學習率都是0.01,在最后一個階段整體精調時使用的學習率是0.1,改進后的算法的第二階段使用0.01的學習率.在所有實驗的整體精調階段和本文提出的算法的第二階段,都使用了“早停”(Early stop)的技術,來防止模型過擬合.為了加速算法,本文使用了小批量(Mini-batch)的方法來把數據批量提交給GPU計算.文獻[17]中,Vincent等給出了Mini-batch的數量設置建議,通常情況下每個小Batch包含的樣例數目應等于類別的數量,在本文的實驗中設置為10.逐層訓練階段循環Epoch數設置為100,整體精調階段設置為1000,改進的算法的第二階段設置為100.
本文使用Python ver.3.5.2語言在Theano ver.0.8庫的基礎上實現了基本的DBN算法以及提出的改進算法.在一臺Xeno E3-1230V3,8GB內存,Ubuntu16.10 64位的系統上,通過GeForce GTX1070 GPU加速來運行實驗程序.
4.1 4隱層,不同RBM嵌套組合方式
在本組實驗中,使用了784×N×N×N×N×10的網絡結構.包含了4層相同節點數的隱層.N的取值從100遞增到3000.針對不同的方法,在MNIST數據集上做了5組實驗,實驗結果如圖4.
可以看到對于4隱層的深度信念網絡,使用兩兩嵌套組合,方式訓練的錯誤率最低,無論是全局最低值還是整體平均值.在1300×1300×1300×1300隱層的結構下,達到最好的錯誤率1.09%,比傳統的DBN在同樣結構時的1.25%要降低0.16%.在整組實驗中使用兩兩嵌套組合方式的錯誤率普遍要好于其他方式.當隱層節點數逐漸增加到大于200以后時,兩兩嵌套組合的方法要普遍好于傳統方法的DBN.兩兩嵌套組合方式最小錯誤率1.09%比傳統方法的最好結果1.15%(1500隱層結點時)要低0.06%,且在更少的隱層節點下取得,這表明兩兩嵌套組合方式能夠比傳統方法更早更好地找到數據的特征.同時因為是深層層間全連接網絡,1300隱層節點的網絡要比1500節點的網絡少大約1/4的層間參數,相應的計算量要少得多,分類的速度會更快.

圖4 MNIST數據集上4隱層模型錯誤率對比Fig.4 The error rate of 4 hidden layers model on MNIST
不嵌套組合的方法在隱層節點低于1500時和傳統的DBN接近,大于1500時比DBN要好,但普遍比兩兩嵌套組合方式要差.
增量不嵌套和增量嵌套的組合方式表現出了較大的波動性,錯誤率圍繞傳統DBN上下擺動.相對于不遞增的組合方式,它們對數據進行了更多輪的學習,也消耗了更多的運算時間,出現這樣現象的原因可能是因為組合了超過3層的隱層,從而導致出現了梯度消失或激增的情況,導致了網絡性能的不穩定[18].
4.2 3隱層,2RBM組合交叉實驗
為了進一步驗證模型有效性,在本組實驗中,改變了網絡的深度,使用了784×N×N×N×10的網絡結構,隱層為三層.同樣的,為了方便考察算法性能,設置了同樣的節點數,都為N.N的取值設定為從100到4000.如果對于3隱層從底向上編號為,增量嵌套的訓練序列是嵌套組合的訓練序列是最終的MNIST數據集上實驗結果如圖5.
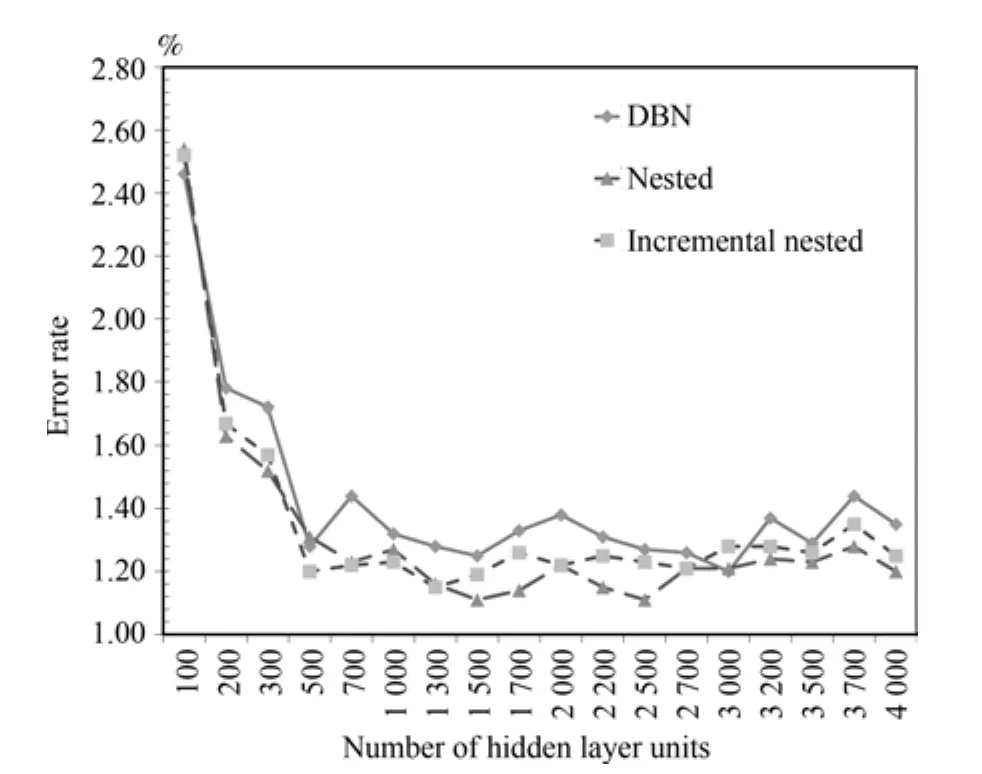
圖5 MNIST數據集上3隱層模型錯誤率對比Fig.5 The error rate of 3 hidden layers model on MNIST
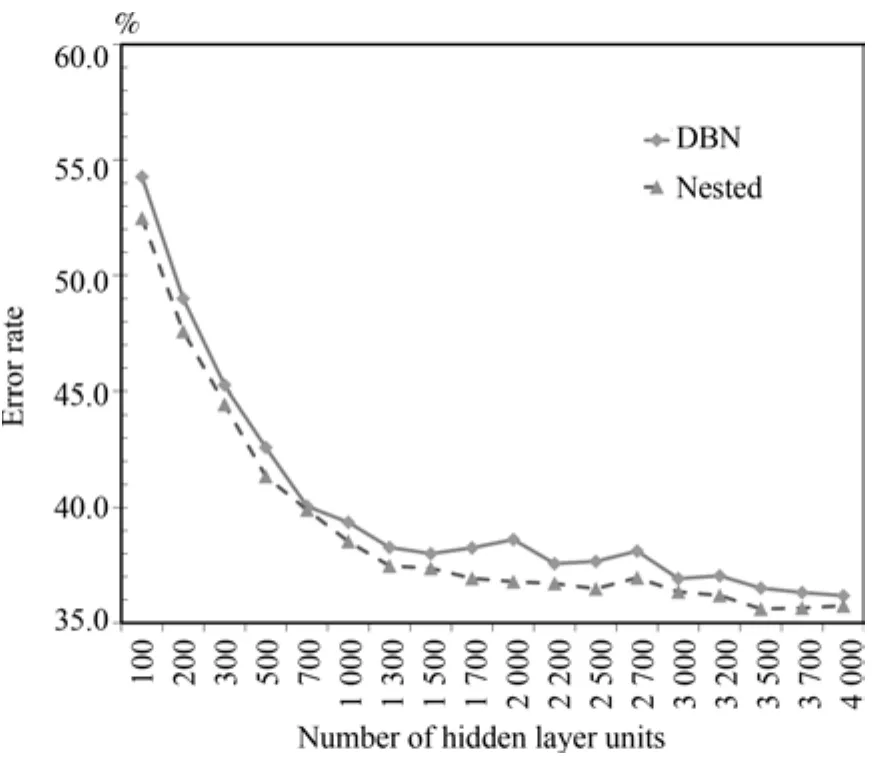
圖6 ShapeSet數據集上3隱層模型錯誤率對比Fig.6 The error rate of 3 hidden layers model on ShapeSet

圖7 Cifar10數據集上3隱層模型錯誤率對比Fig.7 The error rate of 3 hidden layers model on Cifar10
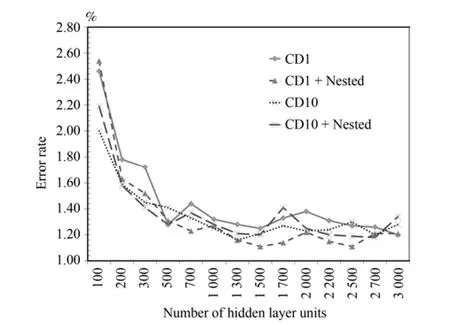
圖8 3隱層模型CD1、CD10錯誤率對比Fig.8 The error rate comparison with CD1 and CD10 on 3 hidden layers model
最好的錯誤率同時出現在兩兩嵌套組合算法隱層為1500節點和2500節點時,都為1.11%,對應的傳統的DBN算法錯誤率為1.25%和1.27%,分別降低了0.14%和0.16%.在其他節點數的情況下,從200開始改進后的算法錯誤率都要普遍優于傳統算法.相對于4隱層的結果,3隱層下增量嵌套組合的穩定性要更好,雖然不如嵌套組合的效果,但也普遍優于傳統算法.
4.3 ShapeSet數據集和Cifar10數據集
為了進一步驗證算法的有效性,在ShapeSet和Cifar10數據集上針對兩兩嵌套組合算法和傳統的DBN算法再次做了比較.實驗結果如圖6和圖7.ShapeSet數據集上錯誤率普遍比傳統方法低2個百分點.Cifar10數據集上從1000結點規模后普遍比傳統方法要低3個百分點.類似的結論再次驗證本文提出的算法相對于傳統DBN算法的有效性,兩兩嵌套組合算法在各種隱層節點數量的模型上普遍獲得了更低的錯誤率.
4.4 其他方法的比較
上述實驗是在傳統的DBN方法的基礎上增加一輪無監督的組合訓練得到的.傳統的DBN在逐層預訓練階段使用的是基于對比散度(CD)的采樣方法,實驗表明CD-1,也就是Gibbs鏈迭代1次后的采樣效果就已經很好了.Tieleman等[19?20]在傳統的 DBN 上提出了一種改進的對比散度方法,稱之為Persistent contrastive divergence(PCD)算法.實驗表明PCD要優于傳統的基于CD-1采樣的DBN算法,和10次交替采樣的CD-10接近.在本文之前實驗中的對比算法就是使用CD-1的DBN算法為基準.在CD-1的基礎上增加組合訓練可以改進模型的精度,那么在使用PCD或CD-10來逐層預訓練的基礎上能否進一步的改進模型精度呢?在MNIST數據集3隱層的模型上CD-1和CD-10的對比實驗結果見圖8,4隱層上的CD-1和CD-10以及PCD的對比結果見圖9和圖10.
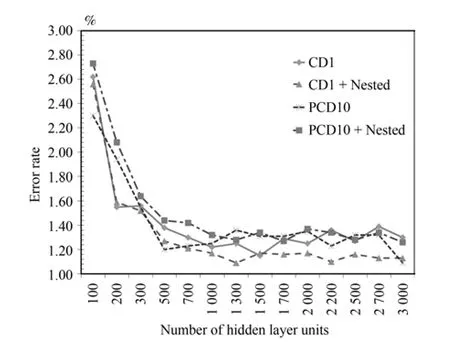
圖10 4隱層模型CD1、PCD錯誤率對比Fig.10 The error rate comparison with CD1 and PCD on 4 hidden layers model
可以看到,在3隱層的網絡上,CD-10的基礎上再次進行RBM嵌套組合預訓練并不能顯著提高模型精度.最好的結果仍然是在CD-1+嵌套組合預訓練的情況下.
在4隱層的網絡上的結論類似,最好的結果還是在CD-1的基礎上進行嵌套組合預訓練.CD-10和PCD-10的情況下,模型錯誤率圍繞CD-1波動,在CD-10或PCD的基礎上增加一輪組合預訓練并不能顯著地提高系統的精度.
4.5 時間消耗和算法效率
本文在新增的多隱層Gibbs采樣預訓練中使用了“早停”機制,在訓練中一旦檢測到模型的代價值增加就會提前終止訓練.實際中在大部分的情況下只需額外訓練很少的輪數就會滿足終止條件,實際消耗的時間非常少.幾種算法的實際訓練時間對比見圖11.可以看到本文的算法相對于CD-1時間略微增加,遠少于CD-10和PCD算法.
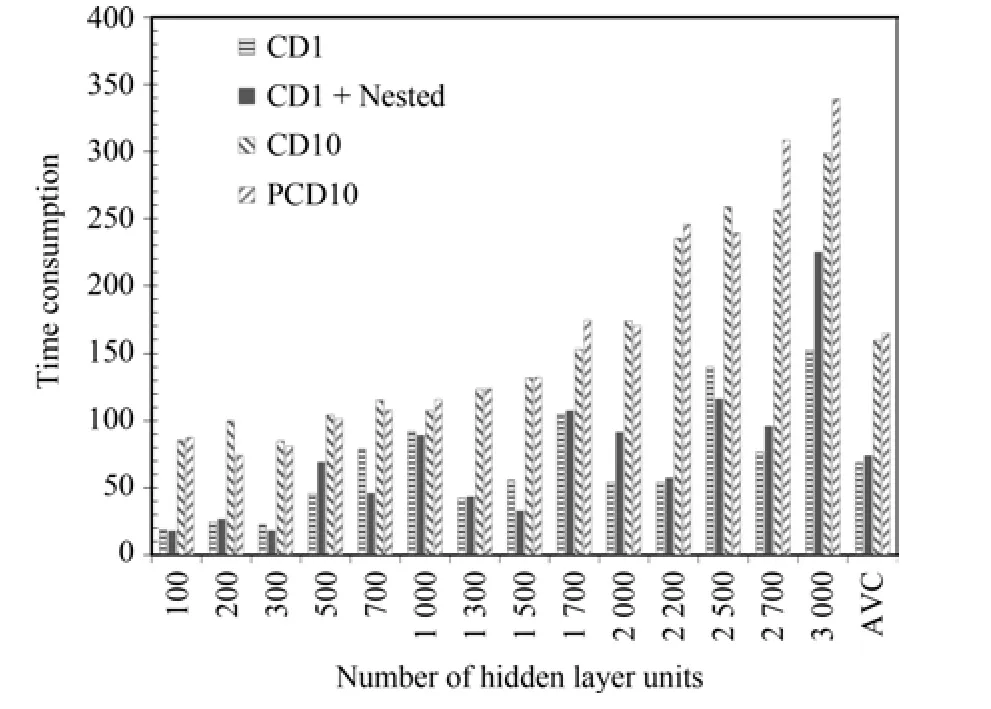
圖11 4隱層模型上各種算法訓練耗時對比Fig.11 The training time consumption comparison on 4 hidden layers model
上述實驗表明,本文方法能夠在更小模型規模上實現比傳統DBN更好的分類效果.為了量化比較,使用算法效率(Algorithm efficiency,AE)來度量識別速度、錯誤率和模型規模之間的關系.AE定義為負的算法識別時間和錯誤率的乘積:

在4隱層上的算法效率對比見圖12.可以看出本文方法相比傳統的方法有著更高的算法效率.
5 總結和展望
理論分析和實驗表明在傳統的DBN訓練方法的基礎上,增加一輪基于多隱層的Gibbs采樣無監督預訓練,對于提高深度信念網絡的精度是有效的,可以為進一步的有監督全局精調提供更好的初始化.對比多種隱層的組合方式,本文發現兩兩嵌套組合相鄰的RBM進行訓練的效果最好.此種訓練方法在原有無監督逐層訓練的基礎上進一步地提高了模型訓練數據似然概率的變分下限,相對于傳統的使用CD或PCD的兩階段訓練方法可以將錯誤率進一步降低,同時也有著更高的算法效率.

圖12 4隱層模型上各種算法效率對比Fig.12 AE comparison on 4 hidden layers model
無監督的預訓練不需要樣本標簽,堆疊基本組件逐層預訓練也是眾多深度學習模型[17,21?22]的一種通用的學習框架.現有的深度網絡還有以其他組件為基本元素組合而成的,如深度降噪自編碼網絡[23],其使用自動編碼器來代替限制玻爾茲曼機,組合基本組件混合訓練的思想在理論上也可以推廣到這些結構上,是否有效也還有待進一步的實驗證明.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
