融合高低層多特征的顯著性檢測算法
2019-05-29 07:03:26孫君頂李海華
液晶與顯示 2019年4期
孫君頂, 張 毅, 李海華
(1.河南理工大學 計算機科學與技術學院, 焦作 454000;2. 河南理工大學 物理與電子信息學院, 焦作 454000)
1 引 言
圖像顯著性檢測是計算機視覺研究中非常重要的方向,利用顯著性檢測提取目標圖像的顯著圖,這對分析目標圖像不同區域的顯著程度至關重要,是圖像處理的基礎。目前,圖像顯著性檢測廣泛應用于目標定位檢測[1]、圖像分割[2]、視頻壓縮等領域。根據人類視覺機制,目前圖像顯著性檢測算法主要分為自頂向下和自底向上的檢測算法,自底向上的檢測算法不依賴于預定義的任務或先驗知識,而是基于目標圖像本身的屬性(顏色、邊緣稀疏等)特征整合圖像顯著性,而自頂向下的顯著性檢測算法主要依靠任務或知識驅動進行先驗顯著性線索檢測,其由于高層知識或任務的參加,檢測算法較為復雜,檢測時間較慢。在自底向上的檢測算法中大多采用單一或組合的顯著性特征線索表征顯著目標,比如文獻[3]提出了一種基于區域對比度的方法來對全局顯著性進行建模檢測;文獻[4]提出了一種多尺度超像素顯著性檢測算法,利用局部對比度、圖像完整性和中心偏差3個線索進行圖像區域顯著性度量;文獻[5]根據局部區域背景-主體-背景的相鄰顏色差值進行邊緣化,提出了一種自適應閾值分割與局部背景線索結合的顯著性檢測算法;文獻[6]結合局部及全局特征提出了一種顯著性檢測算法;文獻[7]綜合利用邊界、全局和局部信息來提取多種顯著性特征,并在隨機場下進行融合以實現顯著區域的檢測;文獻[8]綜合考慮超像素區塊局部對比度、全局對比度以及空間分布關系來計算每個區塊的顯著值,利用融合結果來檢測圖像;文獻[9]提出了一種應用局部和全局特征對比的顯著性檢測模型,通過計算顏色和紋理特征的局部對比度得到局部顯著圖,利用全局、空間分布特性得到全局顯著圖;文獻[10]在高層特征上重新定義了背景先驗特征和中心先驗特征,在低層特征上使用全局對比度和局部對比度,得到了高質量的顯著圖。
上述這些算法都是結合高層或底層幾種特征來融合得到顯著圖,并且多采用線性融合策略。而單一或同類幾種顯著特征無法全面表達圖像顯著性,顯著檢測精度普遍不高,針對于此,本文提出了一種融合高低層多種特征的顯著性檢測算法。
2 底層顯著性特征
2.1 邊界稀疏性特征
邊緣是圖像屬性與另一屬性交界,是圖像特征變化的集中區域,也是圖像背景與邊緣信息連通性最為緊密的地方。圖像邊界在圖像顯著性計算中起著至關重要的作用。設檢測圖像邊界區域為字典D=[d1,d2,...dn]∈Rm×n含有n個基礎信號,每個信號是m維。稀疏系數χ∈Rn可通過求解L1范數最小化問題:
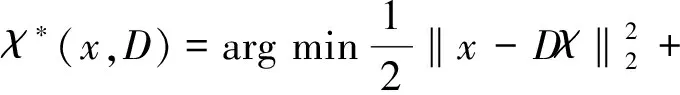
(1)
上式中‖·‖1表示L1范數,λ1為正則化系數。所以x≈x′=Dχ*,其中x′是x的近似表示。
若使用該邊界區域字典D進行重建時誤差較小則該區域屬于背景區域的可能性大,反之亦然。重建系數χi計算如下:
(2)
則邊界稀疏重建誤差εi計算如下:
(3)
根據文獻[11]可知,圖像顯著空間遵循一定的規律,距離圖像中心越近越能引起觀察者的注意,基于此利用分割區域與圖像中心點間距離來提取顯著特征Tcenter(i):
(4)
(5)
μ=(0.5,0.5)表示圖像中心的二維坐標,參數k為位置控制系數,c(i)表示分割區域Ri所有像素坐標中心,Lp表示像素p的空間二維坐標,Ui表示分割區域Ri所有像素個數。
結合以上邊界稀疏重建誤差εi和圖像先驗中心理論,則邊界稀疏性特征Ti(1):
Ti(1)=εi·Tcenter(i),
(6)
2.2 全局對比度特征
幾乎所有顯著性檢測算法都會利用不同的顏色體系計算顏色對比度,主要利用RGB或Lab兩種顏色體系。文獻[12]提出了一種利用RGB、Lab兩種顏色體系與區域分割相結合的全局對比度特征提取方法。本文借鑒該方法對圖像的分割結果{R1,R2,...,RNum}進行區域對比度特征計算:
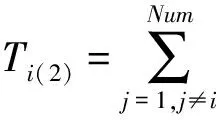
(7)
ψ(Ri,Rj)=‖Averlab(Ri)-Averlab(Rj)‖+
η‖AverRGB(Ri)-AverRGB(Rj)‖,
(8)
其中:?(Ri,Rj)表示分割區域Ri,Rj間的空間幾何距離,ψ(Ri,Rj)表示分割區域Ri,Rj間的空間顏色距離,Averlab(·)和AverRGB(·)為計算平均顏色函數,pf表示像素p的顏色向量。參數η為控制顏色體系RGB、Lab在計算全局對比特征中的比重,本文將η設置為0.5。基于全局對比度特性得到的圖像顯著性特征圖如圖1所示。

圖1 基于全局對比度的顯著性特征圖Fig.1 Saliency feature map based on global contrast
2.3 顏色空間分布特征
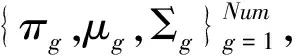
(10)
這里設置高斯混合模型中分量值g最大值為6,本文采用文獻[13]中同樣方法對高斯混合模型進行初始化,并使用EM算法訓練高斯混合模型中的各參數。將高斯混合模型中第g過分割區域的水平方差Dx(g)定義如下:
(11)
(12)
(13)
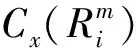
(14)
則第g個高斯成分整體空間的分布方差Dxy(g)定義如下:
Dxy(g)=Dx(g)+Dy(g),
(15)
下面需要對公式(11)、(14)和(15) 3種方差進行歸一化,計算如下:
(16)
通過上式可以看出分布方差大的區域顏色空間分布較為廣泛,顯著目標存在的可能性較小,分布方差小的區域顏色空間分布較為集中,顯著目標存在的可能性較大。設置區域顏色空間分布控制權值δ,水平、垂直、綜合區域顏色空間分布顯著性特征計算如下:
(17)
(18)
(19)

圖2 基于顏色空間分布的圖像顯著圖Fig.2 Image saliency map based on color spatial distribution
2.4 超像素差異性特征
超像素分割(Simple Linear Iterative Clustering)是一種簡單的、方便的分割方法,是圖像處理過程中重要的技術手段[14]。本文基于超像素級來計算目標圖像的差異性特征。
超像素差異性表現為超像素i在位置和顏色空間中相對于其他超像素分割的差別。d(i,j)表示超像素i與超像素j在位置和顏色空間中的距離:
(20)
上式中dc(i,j)表示超像素i與超像素j在Lab顏色空間歸一化距離,dp(i,j)表示超像素i與超像素j的中心距離,β為調解參數,取值為2。計算全局的超像素差異性:
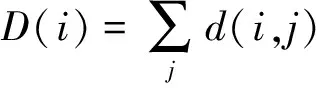
(21)
超像素差異性定義為:
(22)
上式中σu為高斯密度標準差。基于超像素差異性特征得到的顯著性特征圖如圖3所示。

圖3 基于像素差異的圖像顯著圖Fig.3 Image saliency map based on pixel difference
3 高層先驗特征及其融合
3.1 背景先驗顯著
利用超像素分割算法對目標圖像進行超像素分割,通過粗選背景集、精選背景集和顯著值計算3步得到背景先驗顯著圖。
3.1.1 粗選背景集
從左至右、從上至下對目標圖像進行掃描,取目標圖像周邊一圈20個像素作為邊界區域背景混合區B0,背景混合區橫縱坐標范圍:
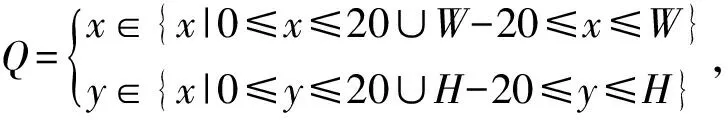
(23)
上式中W、H表示目標圖像的寬和高,將這些邊界定義為粗選背景集B0={pi|pi∈Q}。
3.1.2 精選背景集
由于顯著目標不一定居于目標圖像的中心,有可能接近于邊界區域,為了進一步突出顯著性目標,要對粗選背景集做進一步篩選,計算粗選背景集各超像素pi的Tboundary(i):
(24)
(25)
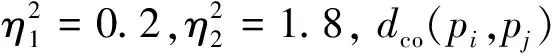
3.1.3 計算顯著值
對目標圖像中的每個超像素pi在背景超像素集B下計算顯著值:
(26)
(27)
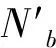
3.2 中心先驗顯著
一般拍攝者都希望將所拍攝的目標放在圖像的中心區域,但實際并非都如此,若直接將目標圖像的中心作為顯著目標的中心會導致顯著性目標檢測出現偏差。本文將前節得到的背景先驗顯著圖中的質心作為顯著目標的中心,提出一種新的中心先驗顯著方法。本方法將越靠近顯著目標中心的超像素設置越高的顯著值,對所有超像素顯著值使用高斯分布求解中心先驗。超像素pi中心顯著值計算如下:
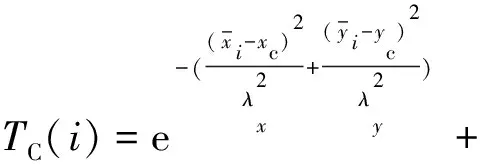
(28)
(29)
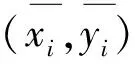
3.3 不同顯著特征融合
文章分別求出4種低層顯著特征值和2種高層先驗特征值。但某些性質相似的分割區域在不同求取方法下得到的顯著特征值差異較大,為了降低各顯著特征在融合時的差異,需對不同顯著特征進行歸一化處理。
首先將Ti(1)、Ti(2)、Ti(3)、Ti(4)、TB(i)、TC(i)這6幅顯著圖統一歸一化到區間[0,1]內,利用最大類間方差法(Ostu)對得到的6幅顯著圖所有顯著值進行閾值求解,得到類間差異最大的閾值T′,對于第m個顯著圖中的像素(x,y),當其顯著值TN(x,y)在6幅顯著圖中均大于類間差異閾值T′時,表示像素(x,y)確處于顯著區域,融合采用線性策略;反之,則表示像素(x,y)并不處于顯著區域,融合采用非采用線性策略。設像素(x,y)最終的顯著值為T(x,y),則:
(30)
(31)
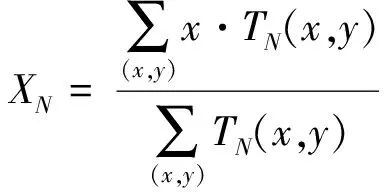
(32)
公式(31)中γN為非線性融合時的融合系數,其表示第N個顯著特征圖中水平和垂直方向標準差加權之和,公式(32)分別為第N個顯著特征圖中橫縱坐標在水平和垂直方向上的加權平均值。
4 仿真實驗及結果分析
4.1 實驗環境與評價
為驗證本文所提算法的性能,將本文算法與AC算法[15]、CA算法[16]、LC算法[17]、HC算法[18]、GC算法[3]、SF算法[19]、文獻[20]、文獻[6]進行顯著性檢測實驗。上述對比算法中LC、HC、GC、SF是基于全局特征對比類型,AC和CA屬于局部特征對比類型,文獻[6]和[20]屬于多特征融合類型算法。本文從主觀視覺和定量對比兩方面分析實驗結果。
實驗硬件環境為Intel(R) Core(TM) i7-7700U@3.6GHz,RAM:8GB,軟件編程環境為:Windows 7操作系統,Visual Studio 2013 開發工具,使用C++進行編程實現。實驗在MSRA-1000[22]、SED[23]和SOD[24]3個國際公開的顯著性檢測數據集上進行。
本文采用PR曲線(查全率-查準率曲線)、平均絕對誤差(MAE,Mean Absolute Error)、F-measure值和AUC值(Area Under the ROC Curve)等4種評價指標對各顯著性檢測算法進行定量分析。
4.1.1 PR曲線
查全率(Recall)和查準率(Precision)被廣泛應用于顯著性檢測算法的結果評價中。經顯著性檢測算法得到顯著圖T(x,y),采用固定閾值將其轉化成二值圖像M(x,y),利用二值圖像M(x,y)和人工標記G(x,y)計算查全率R和查準率P,查全率R和查準率P計算公式如下:
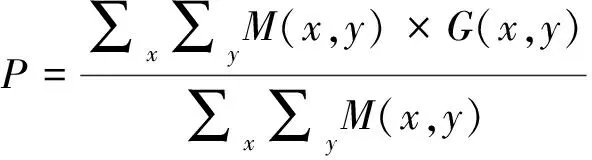
(33)
PR曲線是以固定閾值轉化后的二值圖像計算得到查全率R和查準率P,并以此畫出曲線,如果曲線起始高,后期曲線越平穩檢測算法越好。
4.1.2 F-measure值
F-measure值就是查全率R和查準率P的加權調和平均,本文采用文獻[21]提出的動態閾值二值化顯著圖T(x,y),動態閾值ψ及F-measure計算如下:
(34)
(35)
上式中參數β2一般取值為0.3。數據集中的F-measure值為數據集中每幅目標圖像的平均值,其值是對查全率R和查準率P的綜合,越大越好。
4.1.3 AUC值
AUC被定義為ROC曲線下的面積,是一種度量分類模型好壞的標準。又由于ROC曲線一般都處于y=x的上方,所以AUC的取值范圍一般在0.5~1之間。通俗的說AUC值越大顯著性檢測的正確率越高。
4.1.4 MAE值
KMAE是算法得出的顯著圖與人工標記間的平均絕對誤差,計算公式如下:
(36)
通過上式可知KMAE值描述的就是顯著圖與人工標注的相似程度,其值越小越好。
4.1 主觀視覺對比
本文選取的3個數據集可分成兩組,MSRA-1000和SED數據集為一組主要包括單個顯著性目標,目標邊緣清晰、語義明確,顯著性識別相對較易;另一組SOD數據集顯著目標紛雜,目前顯著性檢測算法對此數據集的檢測效果與前兩種數據集相比較差。首先將本文算法與其他8種算法在MSRA-1000數據集上進行顯著性檢測,MSRA-1000數據集含有1 000幅自然圖像,是現階段圖像顯著性檢測的默認數據庫,人工標記的分割結果由文獻[21]提供,檢測結果如圖4所示。

圖4 各種算法在MSRA-1000數據集上的實驗結果Fig.4 Comparison of the indicators of the algorithms on MSRA-1000 data set
通過對比以上檢測結果看出:各顯著性檢測算法都能大概檢測出目標圖像的顯著性目標,CA算法總體較差,顯著性目標檢測結果邊緣較為模糊;LC、AC、GC、SF等算法或多或少在顯著性目標檢測時會將背景信息誤檢測為顯著目標區域;文獻[21]在檢測背景與目標顏色差別較大的目標檢測圖(如第1、2、4、5、6、8幅圖)時能準確地檢測出顯著目標,但對于背景與目標顏色差別較小的目標圖像,顯著性檢測效果稍差;文獻[6]能大部分檢測出目標圖像的顯著性目標,但在處理顏色空間對比度較高的背景區域時有時會誤凸顯,這是由于算法雖然融合了多種顯著特征,但其只注重于底層特征的融合,對于高層先驗信息并沒有有效融合;本文顯著性檢測結果與人工標注的重合度比較高,不僅能有效的將圖像中的顯著性目標檢測出來,還能與人眼的視覺注意點吻合。各算法在SOD數據集上的顯著性檢測結果如圖5所示。
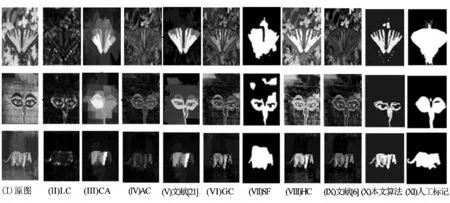
圖5 各種算法在SOD數據集上的實驗結果Fig.5 Experimental results of various algorithms on SOD datasets
LC算法顯著性檢測結果較差,在抑制背景的同時,目標也被抑制了;SF算法雖然能將背景抑制徹底,但是目標輪廓提取較寬泛;CA算法能基本檢測到顯著目標,但是在目標和背景相似的顯著區域檢測效果不佳;AC、GC、HC、文獻[20]和文獻[6]都能基本檢測出顯著性目標,但在背景和目標相近的顏色區域,算法或多或少將背景信息誤檢測成目標;本文算法能在復雜背景下較好的檢測出顯著性目標,邊界輪廓基本清晰。
4.2 定量指標評價分析
視覺對比因觀察者的感官而有差別,不能作為評價顯著性檢測算法好壞的唯一標準。為了定性的比較各顯著性檢測算法的檢測效果,將本文算法與其他顯著性檢測算法進行定量計算。
4.2.1 不同算法在MSRA數據集上的性能
將不同顯著性算法在單個顯著性目標數據集MSRA上進行定量計算,圖6為各算法4種評價指標對比結果,(a)為PR曲線,(b)為F-measure值,(c)為MAE值,(d)為AUC值。
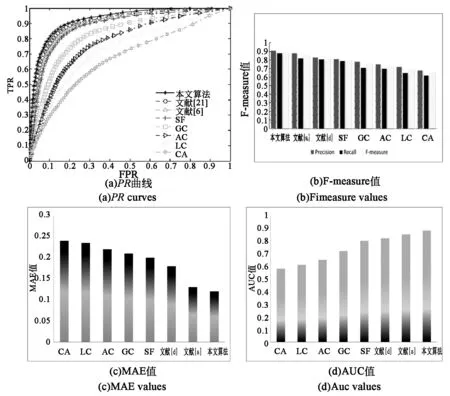
圖6 各算法在MSRA-1000數據集上的指標對比Fig.6 Comparison of the indicators of the algorithms on MSRA-1000 data set
從圖6各評價指標的對比中可以看出,對于單個顯著性目標MSRA數據集,各顯著性檢測算法檢測效果普遍較好,指標評價情況與圖5視覺顯著性檢測結果一致。與效果較好的文獻[20]相比,查全率、查準率至少提高了3.4%。
4.2.2 不同算法在SOD數據集上的性能
將不同顯著性算法SOD數據集上進行定量計算,圖7為各算法4種評價指標對比結果。
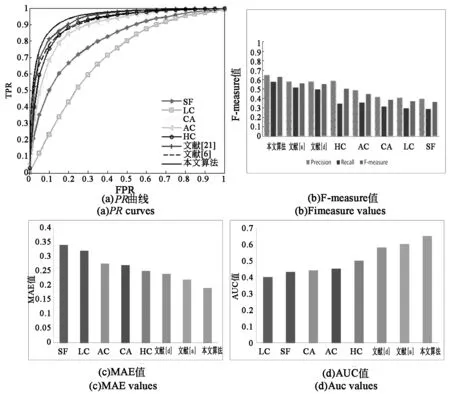
圖7 各算法在SOD數據集上的指標對比Fig.7 Comparison of indicators of algorithms on SOD data set
從圖7各評價指標的對比中可以看出,對于識別圖像比較復雜的SOD數據集,各顯著性檢測算法檢測效果普遍較差,但本文算法融合了多種顯著特征,總體上較其他算法有較大的提高,查準率為65%,相較于在其他算法至少提高了12%,這與視覺顯著性檢測結果也是基本一致的。
綜合兩個數據集上的定量指標對比,我們可以看出本文算法無論對邊緣清晰、顏色分明的單目標數據集還是對顏色相近、目標難辨的復雜數據集都能有較好的顯著性識別結果,這是由于算法融合了底層和高層顯著特征,針對差異較大的顯著特征值,為了降低各顯著特征在融合時的差異,本文采用線性和非線性融合策略,確保顯著目標識別的精確。
4.2.3 時間復雜度對比
將各算法在MSRA-1000數據集上運行,硬件環境如前節所述,各算法的平均運行時間如表1所示。
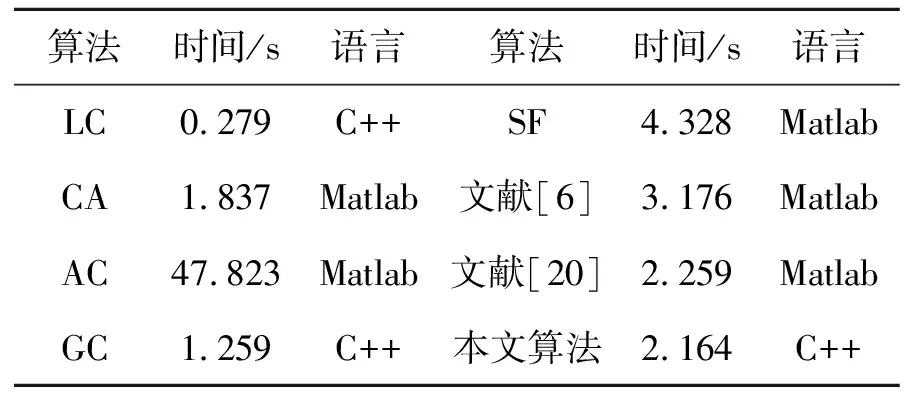
表1 各算法平均運行時間Tab.1 Average running time of each algorithm
由于是多特征融合進行顯著特征提取,使得本算法的計算開銷相對較大,相對比文獻[6]、文獻[20]、AC、SF等算法,本文的計算運行時間較短,但與LC、CA、GC算法相比,運行時間略長,針對于此,后期可以通過并行計算策略降低運行時間。
5 結 論
針對單一或同類幾種顯著特征無法全面表達圖像顯著性,顯著檢測精度不高等問題,本文提出了一種融合高低層多種特征的顯著性檢測算法。算法利用類間差異閾值以線性和非線性策略融合2種高層先驗特征4種低層圖像特征,從而獲得高質量的目標圖像顯著圖。通過實驗對比可以得出本文算法在有效抑制背景信息的同時所得顯著圖像視覺感知更好。但算法運行所需時間稍長。利用并行策略進一步降低運行時間是本文下一步的研究重點。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
河南科技(2014年23期)2014-02-27 14:19:15
