基于多品牌產品擴散模型的智能手機銷量仿真預測
2019-05-16 08:22:26劉夢莉
計算機應用與軟件 2019年5期
喬 健 劉夢莉 王 攀
(西北工業大學管理學院 陜西 西安 710072)
0 引 言
智能手機已成為消費者不可或缺的耐用消費品,其市場巨大、品牌眾多、競爭十分激烈。企業必須具備強大的創新和銷量預測能力,才可能長久立于不敗之地。產品擴散模型是用于預測產品銷量的理想工具,包括單產品和多產品擴散模型兩類,后者又分為多代和多品牌產品擴散模型。智能手機具有多種品牌競爭擴散的特點,所以非常適合用多品牌產品擴散模型進行銷量預測。
多品牌產品擴散模型分為宏觀和微觀模型兩種。學者們已提出多種宏觀模型,用于分析廣告策略[1-3]、定價策略[4]、產品替代[2]、重復購買[5]、入市時間和市場占有形式[5-6]等因素對多品牌產品擴散過程的影響。宏觀模型一般由一組微分方程構成,形式簡潔且便于理論分析,但也存在一定的局限。首先,模型中變量不易過多,模型結構也不易太復雜,否則,求解和分析都可能受阻。由于這些原因,現有的宏觀模型大多都是針對只有兩、三家廠商參與的寡頭壟斷市場上的多品牌產品擴散情形。智能手機市場是一種參與廠商眾多的完全競爭市場,因此,難以用宏觀模型描述這種市場上眾多品牌產品的擴散問題。其次,最近的研究表明[7],不同的消費者網絡結構對擴散過程的影響有顯著差異,而宏觀模型無法反映網絡結構對擴散過程造成的影響。
基于Agent的微觀模型正好彌補了宏觀模型的上述不足[8],成為近年來多品牌產品擴散模型的研究熱點。例如,Schramm等[9]提出基于消費者和品牌兩種Agent的模型,消費者Agent的品牌選擇決策受其自身屬性、品牌屬性和鄰居行為的影響;Kim等[10]及李英和胡劍[11]在他們的模型中設計了基于產品信息、屬性權重和社會影響的多屬性模糊評價方法,用于分析技術學習率和政府補貼對傳統和新能源汽車擴散過程的影響[11];Stummer等[12]在所提出的模型中引入了重復購買機制;Jiang等[13]在所構建的模型中考慮了創新程度、品牌印象、感知效用和電子口碑等因素的影響。經仔細梳理后我們發現,微觀模型的研究在以下三方面還有待深入:第一,大多數現有模型僅用于多品牌產品擴散問題的理論探討,未見到可準確預測多品牌產品銷量走勢的模型報道。第二,購物網站上的線上評論已成為影響消費者購買決策的重要因素,而我們發現,現有模型還未考慮線上評論對多品牌產品競爭與擴散過程的影響。第三,在產品、消費者及其所處社會環境三方面,存在眾多影響消費者購買決策的重要因素。模糊推理又是一種能集成眾多因素建模行為決策的理想技術,然而,我們至今尚未見到一例在產品擴散模型中應用此技術的有關報道。
基于以上分析,本文首先綜合來自產品、消費者及其所處社會環境中的重要影響因素,提出一種將多Agent理論與模糊推理技術相結合的多品牌產品擴散模型,然后基于四種品牌智能手機的真實銷量數據做仿真實驗,檢驗該模型的多品牌產品銷量預測能力。本文的研究在理論上和方法上均是一種創新。
1 消費者Agent模型
本文依據多Agent理論將每個消費者定義為一個Agent,每個Agent擁有若干種屬性、狀態和行為。
1.1 屬 性
消費者Agent共有月收入水平I、產品需求D、質量權重wQ、性能權重wF和品牌知名度權重wB等五種屬性。其中,wQ、wF和wB為[0,1]內的常數,并且wQ+wF+wB=1;我們將I定義為:
It+1=(1+k)It
(1)
其中,t表示仿真時刻,It=0~N(μI,σI),k為[0,1]內的常數;我們將D定義為:
Dt+1=Dt+1/TUC
(2)
當t=0時,Dt=0為[0,1]內的隨機數,TUC代表消費者Agent的平均產品更新周期。
1.2 狀 態
對于每種產品,消費者Agent共有潛在購買者和購買者兩種狀態,即消費者Agent沒有購買某產品時,它關于該產品的狀態是潛在購買者,否則,它關于該產品的狀態是購買者。某產品的潛在購買者購買該產品后,它關于該產品的狀態就轉變成了購買者。
1.3 決策行為
消費者Agent共有產品購買和評論發表兩種決策行為。
(1) 產品購買決策 當一個消費者Agent的D達到事先設定的閾值DT時,那些已上市產品列表中該消費者Agent沒買過的產品將成為它的候選產品。該消費者Agent先通過模糊推理機計算對各候選產品的購買意愿W,再以輪盤賭方式從所有W大于事先設定的閾值WT的候選產品中選擇并購買一個產品。如果沒有滿足W>WT的候選產品,則取消本次購買計劃。消費者Agent采用圖1所示的兩級模糊推理機計算對各候選產品的購買意愿。

圖1 輸入和輸出變量的隸屬函數
一級模糊推理機有兩個輸入變量:一個是消費者Agent的I和該產品的價格P的比值R=I/P,用來衡量消費者對產品價格的接受程度,該值越大表示接受程度越高;另一個是消費者Agent對該產品價值的整體評估:
V=wQQ+wFF+wBB
(3)
式中:Q、F和B分別表示產品的質量、性能和品牌知名度,值域均為[0,1]。一級模糊推理機的輸出變量是消費者Agent對于該產品的效用估計U,值域為[0,1]。
二級模糊推理機共有三個輸入變量,分別是一級模糊推理機的輸出變量U、外界對消費者Agent的影響ICN和消費者Agent上一次購買該品牌產品的經驗E。二級模糊推理機的輸出變量是消費者Agent的W。ICN由線上口碑(又稱線上評論)對消費者Agent的影響IC和鄰居中的購買者對消費者Agent的影響IN組成,計算公式為:
ICN=αIC+(1-α)IN
(4)
式中:α∈[0,1]為常數,用于調節IC和IN在ICN中所占的比重。
消費者Agent購買產品后,可能對所購產品做出好評、中評或差評。我們假設,好評和差評對其他消費者Agent的產品購買決策分別產生正面和負面影響,中評不產生影響。據此,我們設計如下公式計算線上評論的影響:
IC=(β/η)(C+-ηC-)/(C++C-)
(5)
式中:C+和C-分別代表好評和差評的數量;η是一個大于1的常數因子,表示差評的影響大于好評的程度;β是一個分段函數,用于描述一種事實,即在線評論對消費者Agent的產品購買決策的影響隨著評論數量的增加而增加。當評論數量足夠多時影響程度的變化可以忽略。據此,我們定義β如下:
(6)
式中:C0表示中評的數量,閾值CT是一個代表評論數量級的常量。
IN體現從眾行為對消費者Agent的產品購買決策的影響,用下式計算:
IN=γNA/N
(7)
式中:系數γ∈[0,1]用于反映消費者Agent的從眾程度,該系數的取值因消費者Agent而異;N和NA分別代表消費者Agent在社交網絡中的鄰居總數和已購買該品牌產品的鄰居數。
E用來表達消費者Agent對上一次購買該品牌產品的滿意程度,值域為[-1,1]。E越大,表明消費者Agent對上次的購買經歷越滿意,越愿意再次購買該品牌的產品。我們認為,消費者對所購產品的滿意度主要受他或她對該產品的效用估計的影響。效用估計越高的產品,購買者滿意度高的可能性也越大。據此,我們分兩步估算E的值:
第一步,依次在[-1,x-]、[x-,0]、[0,x+]和[x+,1]區間內各生成一個隨機數e1、e2、e3和e4,在[0,1]內生成兩個隨機數r1和r2。
第二步,按以下規則給E賦值:當r1<1-U時,若r2<1-U,則E=e1,否則E=e2;當r1≥1-U時,若r2<1-U,則E=e3,否則E=e4。
兩級模糊推理機的所有輸入和輸出變量的模糊集及其相應的論域見表1。其中,變量E的模糊集中的L、M和H取值的含義依次為差、中、好,其他變量的模糊集中的L、SL、M、SH和H取值的含義依次為低、較低、中、較高、高。
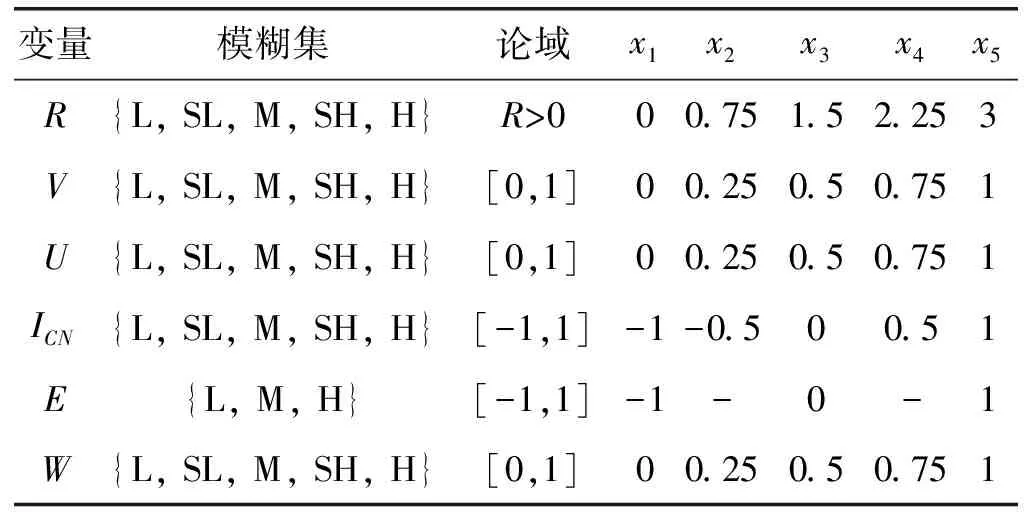
表1 輸入和輸出變量的模糊集、論域及隸屬函數的橫坐標
隸屬函數的形式如圖2所示,其中,橫坐標刻度x1、x2、x3、x4、x5的值見表1。

圖2 輸入和輸出變量的隸屬函數
一級模糊推理機的模糊規則如表2所示。為節省篇幅,這里省略了二級模糊推理機的模糊規則。本文采用Mamdini的推理合成方法[14]進行模糊推理,采用重心法進行解模糊運算。

表2 一級模糊推理機的模糊規則
(2) 評論發表決策 研究表明,購買者發表評論的愿望與滿意度之間呈現一種U型的函數關系,即滿意或不滿意的程度越高,發表評論的愿望越強烈。已有研究和生活經驗均表明,使那些最滿意或最不滿意的購買者中,只有部分人愿意發表評論。據此,我們用1、0和-1分別表示好評、中評和差評,并設計評論發表決策規則如下:消費者Agent購買某產品后,將以概率p=λ|E|發表評論,其中λ∈[0,1]為常數,用于控制購買者中發表評論者的比例。根據對消費者的社會調查,我們提出以下規定,當E
2 多品牌產品擴散模型
該模型模擬了多品牌產品在消費者網絡中的競爭與擴散過程。研究表明,由消費者構成的在線社交網絡一般都有顯著的無標度特性。所以,我們依據BA模型[15]構建消費者Agent社交網絡,并在該網絡上模擬產品的擴散過程。首先設定BA模型的參數m0和m的取值,并按照該模型的演化規則構建一個規模為S的消費者Agent社交網絡。然后,令仿真時刻t=0,并開始仿真。每一仿真時刻完成以下操作:(1) 檢查待入市產品列表,將所有到達入市時間的產品移入已入市產品列表。(2) 檢查已入市產品列表,將所有到達退市時間的產品從該表刪除。(3) 每個消費者Agent更新其I和D的值,并根據最新的D進行產品購買決策,購買了產品的則更新其狀態并進行評論發表決策。(4) 令t=t+1。如果t未達到仿真終止時刻T,則按BA模型的演化規則向消費者Agent社交網絡中增加ΔS個新消費者Agent,否則結束仿真。
3 模型的實現與運行
在Repast Simphony仿真平臺上,我們用Java編程實現了上述多品牌產品擴散模型的仿真程序。
在該程序中,我們根據消費者Agent模型定義了一個消費者Agent類,它由若干屬性變量、狀態變量和決策方法組成。還根據擴散模型定義了一個由品牌ID、價格、質量、性能、品牌知名度、入市時間和用戶評價等屬性變量組成的產品類,以及List類型的全局變量待入市產品列表BrandList1和已入市產品列表BrandList2。
在程序初始化階段,基于產品類創建全部待模擬的產品對象,并添加到BrandList1中。選擇Repast Simphony提供的ContextJungNetwork類作為Agent的空間環境。基于消費者Agent類創建S個消費者Agent,再根據BA模型建立以消費者Agent為節點、以Agent之間的相鄰關系為邊的消費者Agent網絡。
程序完成初始化后,將仿真步置為0,并開始仿真迭代。每個仿真步要完成的任務均放在由Repast Simphony提供的空方法step()中。本文中,這些任務主要指:更新消費者Agent的收入和需求;更新待入市產品列表和已入市產品列表;消費者Agent進行產品購買決策和評論發表決策;輸出各品牌產品當前銷量;向網絡中增加ΔS個新的消費者Agent。
每執行完一次step()方法,由Repast Simphony的Schedule調度機制負責推進仿真步。當仿真步數到達預設總步數時,仿真迭代將結束。
Repast Simphony既是一個編程環境,又是一個運行環境。本文所有的仿真實驗都是在該環境中運行我們編寫的多品牌產品擴散仿真程序完成的。
4 仿真實驗
本文通過仿真實驗預測了1998年-2012年間四種品牌智能手機的銷量走勢。
四個品牌智能手機的真實銷量見表3,擴散過程大致分三個階段。1998年-2000年,APPLE手機還未上市,NOKIA、MOTOROLA和SAMSUNG手機的價差并不是很大,但是,NOKIA手機的質量、性能和品牌知名度明顯更高,加之消費者收入增長帶來的市場潛量的增加,使其銷量增速明顯快于MOTOROLA和SAMSUNG手機。2001年-2006年,APPLE手機仍然未上市,SAMSUNG手機的質量和性能明顯提高,導致NOKIA手機的增速明顯放緩。消費者收入的不斷增長和手機功能的不斷增強促使市場潛量加速擴大,從而引起NOKIA、MOTOROLA和SAMSUNG手機在后期加速增長。2007年-2012年,APPLE手機上市并以出色的質量和性能開始搶奪高端市場,SAMSUNG手機繼續以很高的性價比與APPLE手機一道,分別加速占領中低端和高端市場。2008年,運行安卓系統的手機上市。與安卓和IOS相比,塞班系統的性能明顯處于下風。上述原因導致NOKIA手機的銷量從2009年開始出現下滑,并于2011年被SAMSUNG手機超越。而MOTOROLA手機從2007年開始,就因缺乏創新而導致銷量快速下滑。

表3 四種智能手機銷量的真實值、預測值及其相對差

續表3
根據上述對四種品牌智能手機的真實銷量的分析,我們設定模型參數如下:
由于個體差異性的原因,消費者的wQ、wF、wB、DT、WT和γ,通常都是彼此不同的。
一般而言,產品的質量、性能和品牌知名度在消費者心目中的重要程度也不同。對部分消費者的調查表明,大部分被調查者傾向于認為wF>wQ>wB,并且關于三者占比的觀點也趨同。因此,我們認為,假設wQ~N(0.4,0.04)、wF~N(0.5,0.05)和wB~N(0.1,0.02)較符合實際。為此,針對每個消費者Agent,先按上述分布產生3個隨機數分別賦予該Agent的wF、wQ和wB,再進行歸一化,使wQ+wF+wB=1。
需求/購買意愿的值域為[0,1],0表示沒有需求/購買意愿,1表示需求/購買意愿的上限,即最大需求/最大購買意愿。我們認為,需求/購買意愿超過上限的一半時,內心活動轉化為實際行動較合理。所以,針對每個消費者Agent,在[0.5,1]內生成2個隨機數,分別賦予該Agent的DT和WT。
調查表明,消費者的從眾程度也有差異,而且沒有規律。據此,針對每個消費者Agent,在[0,1]內生成1個隨機數,賦予該Agent的γ。
其余模型參數的設置如表4所示。為節省篇幅,全部產品參數均在此未列。
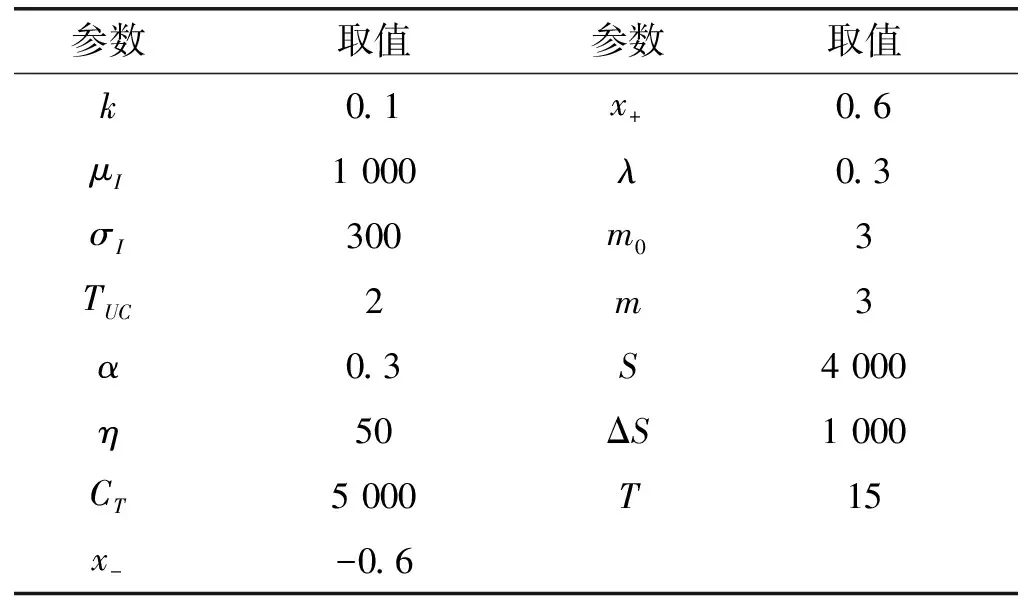
表4 30次仿真實驗中部分模型參數的設置
可以看到,上述部分模型參數的初值是隨機產生的,目的是為了使模型更符合實際。為消除預測結果的隨機誤差,我們先進行30次仿真實驗,再平均全部實驗結果得出預測值。表4所示為四種品牌智能手機銷量的真實值(百萬部)、預測值(百萬部)及其相對差(%)。可以看出,在所有年份里,預測值的相對差均小于10%,說明預測效果是令人滿意的。
我們又采用誤差平均絕對百分比(MAPE)、平均絕對誤差(MAD)、均方根誤差(RMSE)和R方(R2)等4個指標檢驗了預測值的精確度,檢驗結果如表5所示。MAPE考慮了絕對誤差與真實值的比率,值越小精確度越高;R2的值域為[0,1],越接近1表明預測效果越好。該表顯示,所有MAD和RMSE均小于10,所有MAPE均小于0.05,所有R2均大于0.99,可見本文模型的預測精度確實不錯。表3和表5的結果說明,本文建立的多品牌產品擴散模型可以較好地預測四種品牌智能手機的銷量走勢。由于表4中的模型參數是通過試錯法人工設定的,所以目前的預測結果并非模型所能達到的最優值。如果設計優化算法自動找出模型參數的最優組合,預計將進一步顯著提高預測的準確性。
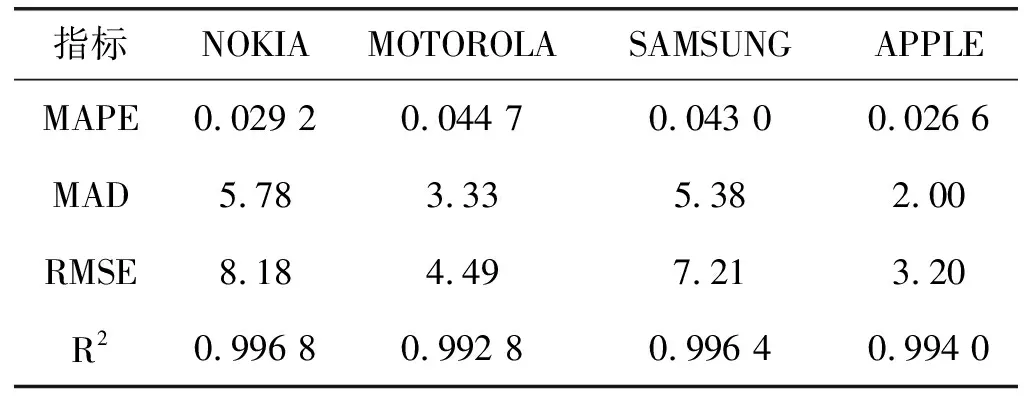
表5 預測值的精確度
5 結 語
智能手機具有多品牌競爭擴散的特點。而目前,我們尚未見到具備強大銷量預測能力的多品牌產品擴散模型出現。消費者的購買決策受產品、消費者及其所處社會環境中眾多因素的影響,找到能將這些因素有機結合的一套建模理論和方法,以確保所構建的模型能準確刻畫消費者的決策邏輯及其對產品競爭與擴散過程的影響邏輯,是構建具備強大銷量預測能力的多品牌產品擴散模型的關鍵。本文運用多Agent理論和模糊推理技術,綜合產品、消費者和社會環境中的重要因素所構建的多品牌產品擴散模型,被大量實驗證明能較好地預測多品牌智能手機的銷量走勢。本文的研究不僅豐富和發展了創新擴散理論,而且還可為相關企業的產品營銷提供決策參考。
猜你喜歡
紅領巾·萌芽(2022年9期)2022-11-24 05:55:58
今日農業(2020年20期)2020-12-15 15:53:19
英語文摘(2020年5期)2020-09-21 09:26:30
趣味(語文)(2018年8期)2018-11-15 08:53:00
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
發明與創新(2016年16期)2016-08-21 13:56:16
發明與創新(2016年21期)2016-05-17 03:57:29
Coco薇(2015年1期)2015-08-13 02:23:50
小說月刊(2014年4期)2014-04-23 08:52:21
玩具(2009年10期)2009-11-04 02:33:14
