大數據在移動出行中的應用
2019-04-04 02:45:40
福建質量管理 2019年7期
(山東工藝美術學院公共課教學部 山東 濟南 250000)
引言
“分享經濟”是通過大數據技術以及互聯網技術進行資源配合,整和重構資源所誕生的一種全新商業模式,降低了消費者的購買成本和提高了生產效率。隨著分享經濟的興起,將會使商業和社會帶來翻天覆地的變化。從15年滴滴打車與快的打車的合并,再到16年滴滴收購Uber,移動出行巨頭——滴滴出行,為人們的城市交通出行帶來了巨大的變化。滴滴出行作為移動互聯網背景下“分享經濟”的領軍人物,它利用GPS、移動互聯網、大數據等技術,充分利用了閑置的交通資源,使出行更加高效便捷,解決了緊張的交通資源,節約了人們等車的時間,使人們的出行方式由普通的打車變為了現在利用互聯網智慧出行,推動了互聯網和傳統產業的創新融合。
移動出行平臺發揮了“分享經濟”的低成本優勢,它們通過運營管理,有效地解決了信息不對稱,通過技術手段,連接了車主和乘客,并且對每個人都有信用記錄,在交易平臺上給出一個清晰透明的價格,使服務順利達成,原本閑置的資源被利用起來,釋放了分享經濟的低成本優勢。
近年來,隨著通訊技術的發展和空間定位的普及和應用,我國大多數車上都安設了GPS系統,通過GPS的定位功能,產生了大量車輛連續性的時間和空間的軌跡數據,這些數據獲取的成本低,覆蓋范圍廣,擁有動態特性,使得這些數據成為研究人們出行的新數據來源。
一、中國移動出行應用分析
(一)移動出行應用市場分類
目前,我國移動出行應用主要有專車、打車、拼車和租車四種類型,這使人們出行選擇多種多樣,也滿足了各個年齡階段、各個地域以及各個階層的需求,表1顯示了四種移動出行的代表應用及其主要特點。
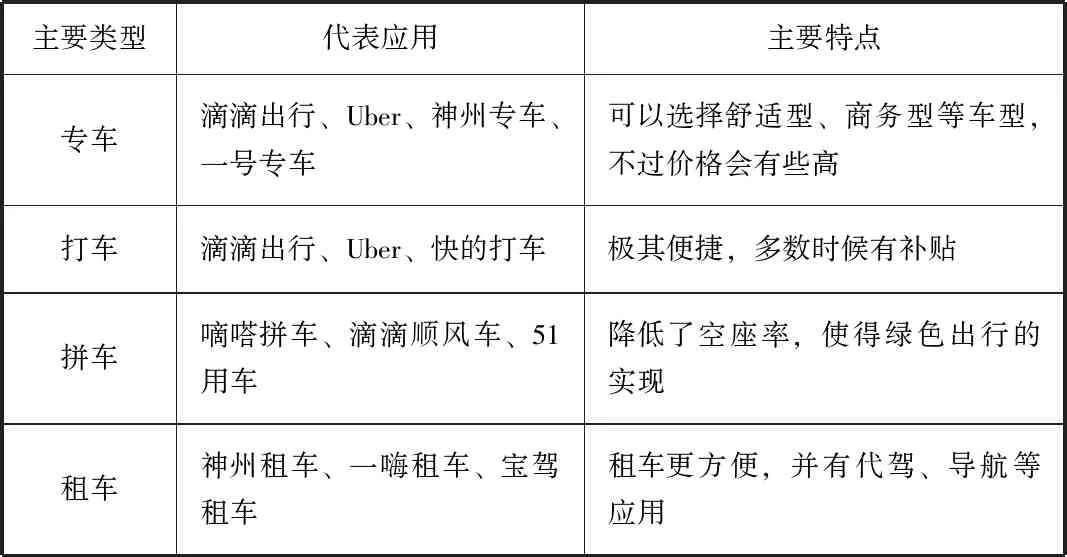
表1 移動出行市場主流軟件及其特點
2016年下半年移動出行應用排名如圖1所示,滴滴出行的市場份額和用戶活躍度遠高于其他應用,其原當然離不開各大公司背后強大的資金支持以及技術支持。而更主要的是,滴滴出行與快的打車合并后,又收購了Uber中國,其業務拓展速度非常之快,占據了中國超過75%的市場用戶。而其經常采取的補貼戰略,更是吸引了一大批消費者。
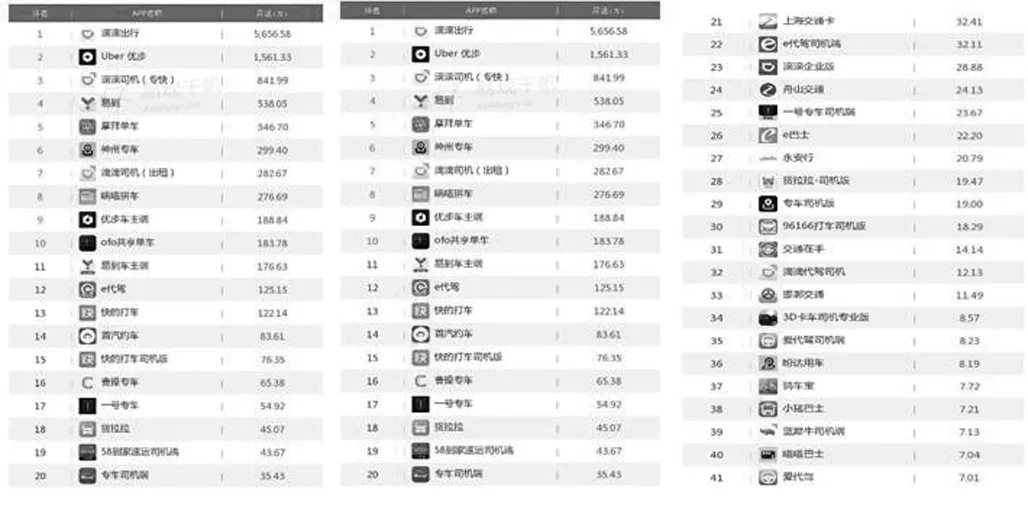
圖1 移動出行領域榜單

圖2 各專車應用的活躍用戶量及啟動次數
從圖2中可以看出,滴滴出行APP占據了絕大部分市場份額,活躍用戶數量以及啟動次數遠遠高于其他幾個專車應用。從圖3中可以看出,在日均活躍用戶量、日均啟動次數和日均使用時長上看,占據領先地位的是Uber和神州專車。
(二)用戶行為分析
用戶選擇出行軟件的時候,往往考慮以下幾個因素:首先,在價格方面,用軟件打車的價格是否合理,是否比打普通出租車要便宜。其次,是否能及時到達自己所在的地點。因此商家為了留住顧客,經常采取一些補貼優惠政策,使價格方面盡量讓人們接受,甚至用白菜價吸引那些潛在的客戶,再利用其便捷的優點,使潛在客戶發展為長期客戶。隨著注冊的車主越來越多,打車也越來越便捷,打車的人也變得越來越多。因此打車的效率和速度就提高了。
如圖3顯示的人均行為,我們可以得出人均啟動次數和人均使用時長最多的是滴滴出行,其次是Uber和神州專車。

圖3 人均行為分析圖
(三)用戶構成分析
移動出行類應用的主要用戶主要集中在20-30歲以下的青年人士,這些年輕人對互聯網接觸了解的較多,并且樂于嘗試新型的出行方式。而41歲以上的人群只占了10%的份額。
從使用的領域來看,一線城市的市場份額占據了50%以上,這與一線城市人群有較高的收入水平有關系,他們的出行頻次也比較高。而隨著年齡的遞增,收入檔次的提高,移動出行用戶數量逐漸減少,其原因主要有以下兩點:一是我國高收入者占總人口的比重較小;二是高收入者一般有自己的汽車。隨著移動出行應用的普及,將會有更多的年輕人進入這個市場,也會逐步有中年人士放棄自己開車而選擇專車和拼車,這將是綠色出行,實現節約能源的第一步。
二、大數據挖掘理論綜述
近年來,在我們生活在互聯網海洋的每時每刻,都會產生海量的數據。而面對這些海量的數據,人們的肉眼和手工方法很難去處理這些數據并發現其中的價值,在這些數據的海洋中,人們急切需要更有效的方法來處理這些數據來獲得有用的知識。數據挖掘正是在這種強烈需求的背景下應運而生的,為我們從大量數據中提煉出有價值的只是提供了可行有效地方法。
(一)大數據挖掘技術的概念
數據挖掘結合了多個領域的技術,如人工智能、概率學、數據庫技術、機器學習等。數據挖掘是在不完全的數據信息中,去除噪聲、重復數據、不一致數據,發現那些對人們有價值的信息。數據挖掘技術還可以用于預測信息,發現數據之間的規律,推測出將來可能的行為。
數據挖掘也往往用來解決商業的實際問題,首先從商業角度理解問題,將這些問題轉化為數據,對這些數據進行建模,然后對模型進行評估,最后發布模型得出目標結果。
(二)大數據挖掘的過程
數據挖掘的整個行程是為了發現在最初的數據中,所隱含著的對我們有價值的信息,所以在進行數據挖掘前,我們首先要知道,我們要解決的問題是什么以及想達到什么樣的目的。只有這樣將問題和目的結合起來才能得到我們想要的結果。數據挖掘的過程分為以下幾個階段:數據預處理、數據挖掘和模型最終效果的評估。
1.大數據預處理
我們剛開始收集的原始數據往往具有復雜和多樣等特性,為了將這些最初的數據轉化為我們最終需要的數據,我們要對數據進行一些處理,使原本不完整的數據變得完整,使數據變得一致起來。我們要對數據進行清洗來消除數據的噪聲和重復的觀測值。數據預處理過程又分為以下四個子階段:
數據清理:數據清理包括消除數據的噪聲、填補那些遺缺的數據,使數據變得平滑起來。車輛軌跡數據存在的主要問題是軌跡點經緯度坐標越界和異常的軌跡點,需要對這些異常數據進行處理。
數據合成:數據合成是將各不相同的數據在某些特征上讓它們有機的集中起來。
數據選擇和分析:是指在大量的數據中取出一些相關數據,在不損失有效信息的情況下,對數據的范圍進行合理的選擇,以減少不必要的時間浪費。
數據變換:是指通過離散化、平滑處理以及標準規則化處理等方法,將數據變化成適合進行數據挖掘的形式。
其中對GPS測數據的數據剔除方法我們可以使用萊茵達準則法和羅曼洛夫斯基準則,這種GPS載波相位差分技術的運用,極大地降低了如衛星相關誤差及電離層折射延遲、對流層折射延遲等主要誤差源的影響。為了盡可能可靠地提高GPS定位的精度,必須對測量數據進行粗差剔除。
(1)萊茵達準則
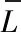
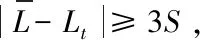
(2)羅曼洛夫斯基準則
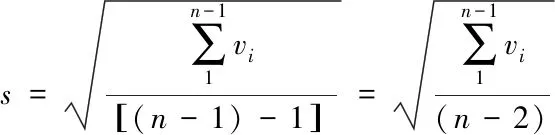
2.大數據挖掘
數據挖掘是為了在初始不規則的數據中發現對我們有用的信息,數據挖掘的模式有兩種,其中一種是描述性模型,用特征化分析、聚類分析、關聯分析等方法描述數據的一般特征,再用數學統計模型對隱含在這些數據中的信息進行解釋;另一種是預測性模式,通過分類、孤立點分析、回歸等方法,在預測和推斷這些數據。
3.模型最終效果的評估
在數據挖掘階段之后,挖掘到的數據是需要我們進行分析的,要用恰當的評價標準來衡量結果的正確與否。
(三)數據挖掘的方法任務及分析
數據挖掘有兩種方法類型,一種是統計型的,常用的方法包括聚類分析和相關性分析,這種類型旨在發現數據中藏匿的一般規律。另一種類型是機器學習類型,它通過大量的數據樣本得到模型,然后對未知的樣本進行預測。本論文使用的是第二種類型,通過乘客和司機的出行數據,對乘客和司機的歷史行為進行分析。這種結合了概率學、人工智能、數據庫等技術的綜合性方法,減少了只在單個分析方法中的缺點和不足,將多重分析方法的優勢結合起來,更好的分析數據得出結論。下面介紹四種數據挖掘任務。
1.預測建模
預測建模有回歸建模形式和分類建模形式,它們通過提取數據的普通模式來預測未來的變化趨勢。回歸建模的函數模型是連續的,可以用線性回歸的方式來解決許多問題,而通過變換,我們也可以將許多非線性問題轉化為線性問題來解決。分類建模是預測離散的數值。這兩種建模形式都是預測問題。分類和回歸預測的經典方法有決策樹、貝葉斯、支持向量機、人工神經網絡、組合學習方法和K鄰域。
2.關聯分析
關聯分析方法是為了發現數據集中的關聯性和相關性。但是,在海量的數據中要發現它們的聯系要耗費大量的時間和資源,同時,發現的這些相關性也會有偶然的情況和錯誤的情況,為了解決這兩個問題,在關聯分析中,要使用規則的支持度和置信度,使得去除那些偶然出現的規則,得到最可靠的信息。利用關聯分析的算法主要有FP-growth和Apriori等。
3.聚類分析
聚類分析是一種沒有監督的方法,它通過合理劃分那些未標注的樣本,對不同類別使用顯式或隱式的方法進行描述,層次方法、劃分方法、基于網絡的方法等都是聚類分析的主要方法。
4.異常檢測
異常檢測的目的是為了發現那些特征明顯不同于其他數據的對象,從而避免將正常的觀測對象標記為異常數值。異常檢測在公共損失檢測、網絡攻擊、疾病的不尋常模式、醫療處理等方面都有重要作用。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
Coco薇(2016年2期)2016-03-22 02:42:52
信息通信技術(2015年6期)2015-12-26 01:16:46
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電子設計工程(2014年18期)2014-02-27 12:00:13
