樸素貝葉斯算法的綜述
2019-04-03 11:19:48山東省濟(jì)寧育才中學(xué)王華宇
數(shù)學(xué)大世界 2019年4期
山東省濟(jì)寧育才中學(xué) 王華宇
在當(dāng)今這個(gè)信息技術(shù)高速發(fā)展的時(shí)代,人們對(duì)信息處理的方式越來(lái)越多樣化、智能化,像人工檢索這種耗時(shí)耗力的方法已經(jīng)逐漸跟不上時(shí)代發(fā)展的潮流了,而迅速快捷、對(duì)人力要求甚微的人工智能正在一步步發(fā)展起來(lái),這對(duì)于我們?cè)诖罅繑?shù)據(jù)中尋找、篩選對(duì)自己有用的信息是有極大的幫助的。而作為人工智能的一個(gè)分支,樸素貝葉斯算法在統(tǒng)計(jì)學(xué)中具有與決策樹、神經(jīng)網(wǎng)絡(luò)相媲美的應(yīng)用前景,因此,如果做好樸素貝葉斯算法的應(yīng)用,將其應(yīng)用于信息篩選,必將產(chǎn)生極大的作用。
一、樸素貝葉斯算法的原理
樸素貝葉斯算法是基于貝葉斯定理與特征條件獨(dú)立假設(shè)的分類方法。即假設(shè)給定對(duì)象的各個(gè)屬性之間相互獨(dú)立,因此在計(jì)算概率時(shí)可利用公式:
之后通過(guò)計(jì)算給定對(duì)象的先驗(yàn)概率,利用貝葉斯定理:
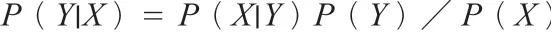
計(jì)算其后驗(yàn)概率,即該對(duì)象屬于某一類的概率,再比較各后驗(yàn)概率的大小,最后確定給定對(duì)象屬于的類別。
樸素貝葉斯算法的具體描述(這里應(yīng)用了極大似然估計(jì)):
假設(shè)給定一數(shù)據(jù)集X ={x1,x2,x3…xn},每個(gè)x 含有m 個(gè)屬性,記為c1,c2,c3,…,cm。每個(gè)x 一一對(duì)應(yīng)一個(gè)Y ={y1,y2,y3,…,yn}通過(guò)給出數(shù)據(jù)可以計(jì)算先驗(yàn)概率P(Y);此時(shí)給出一個(gè)已知各屬性,未知其映射yi的量Xi(c1i,c2i,c3i,…,cmi),分別計(jì)算y1,y2,y3,…,yn后驗(yàn)概率P(Y|Xi),比較各后驗(yàn)概率大小,取最大值P(Y|Xi)max,則其對(duì)應(yīng)的yi即為Xi所對(duì)應(yīng)的Y。
二、樸素貝葉斯算法的缺點(diǎn)分析
由于未知對(duì)象屬性具有的不確定性,因此可能出現(xiàn)未知對(duì)象某一屬性在原始對(duì)象中沒有對(duì)應(yīng)屬性的情況,在該種情況下,在計(jì)算先驗(yàn)概率時(shí)會(huì)出現(xiàn)概率等于零的情況,這樣就會(huì)對(duì)最終結(jié)果產(chǎn)生一定的影響,使結(jié)論與實(shí)際情況產(chǎn)生偏差。為了避免這種誤差的出現(xiàn),我們?cè)跇O大似然估計(jì)方法的基礎(chǔ)上可以采用貝葉斯估計(jì),即:
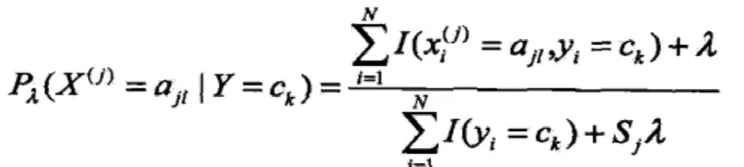
J =1,2,3…,n;l =1,2,…,Sj;k =1,2,…,K。
式中,xi(j)是第i 個(gè)樣本的第J 個(gè)屬性;ajl是第j 個(gè)屬性可能取的第l 個(gè)值;I 為指示函數(shù)。
同樣,先驗(yàn)概率的貝葉斯估計(jì)是:
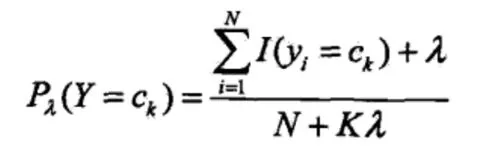
式中,λ ≥0,相當(dāng)于在對(duì)未知對(duì)象相應(yīng)屬性求取頻數(shù)時(shí)賦予一個(gè)正數(shù)λ >0,這就是貝葉斯估計(jì)。當(dāng)λ=0 時(shí),就是極大似然估計(jì)。對(duì)于λ,我們常取1,這時(shí)稱為拉普拉斯平滑。這樣我們就避免了上文所提到的可能出現(xiàn)的誤差。
三、關(guān)于樸素貝葉斯算法應(yīng)用的思考
通過(guò)以上對(duì)樸素貝葉斯算法原理及具體過(guò)程的分析可以了解到:樸素貝葉斯算法對(duì)于已知部分?jǐn)?shù)據(jù)并可求出數(shù)據(jù)各屬性對(duì)應(yīng)映射Y 的先驗(yàn)概率的情況下,求一未知對(duì)象Xi相應(yīng)的對(duì)應(yīng)映射Yi的問(wèn)題具有得天獨(dú)厚的優(yōu)勢(shì):1.由于前提條件中進(jìn)行了條件獨(dú)立性假設(shè),因此可以將計(jì)算變得簡(jiǎn)單;2.雖然進(jìn)行了較強(qiáng)的條件獨(dú)立性假設(shè),但對(duì)于結(jié)果準(zhǔn)確性的影響不大。
因此,如果可以將樸素貝葉斯算法與人工智能相結(jié)合,便可以在數(shù)據(jù)篩選中起到重要作用,比如日常生活中我們經(jīng)常遇到的垃圾郵件,就可以利用樸素貝葉斯算法,具體方法如下:
首先隨機(jī)選取等量的正常郵件和垃圾郵件,選取合適的多個(gè)屬性,并利用統(tǒng)計(jì)學(xué)方法分別對(duì)兩類郵件的各個(gè)屬性的數(shù)據(jù)進(jìn)行統(tǒng)計(jì)、分析,計(jì)算出“正常郵件”和“垃圾郵件”的先驗(yàn)概率,然后對(duì)于給定一已知各屬性數(shù)據(jù)、未知類型的郵件,根據(jù)其各屬性數(shù)據(jù)分別求出“正常郵件”和“垃圾郵件”的后驗(yàn)概率,比較其大小,取最大值,將其對(duì)應(yīng)的郵件類型標(biāo)記給上述給定郵件,若為垃圾郵件,則被系統(tǒng)自動(dòng)刪除;若為正常郵件,則由系統(tǒng)保留。當(dāng)然,以上的計(jì)算過(guò)程、取最大值過(guò)程以及判斷標(biāo)記處理過(guò)程都是利用人工智能來(lái)完成的,這就實(shí)現(xiàn)了對(duì)樸素貝葉斯算法的應(yīng)用,于是就可以準(zhǔn)確、簡(jiǎn)便、高效地篩選出垃圾郵件并將其刪除,從而提高了信息利用的效率。
本文主要講述了樸素貝葉斯算法的基本原理、具體描述、應(yīng)用的思考以及實(shí)例的分析操作。通過(guò)本文我們了解到樸素貝葉斯算法的應(yīng)用在數(shù)據(jù)篩選和分類過(guò)程中的應(yīng)用前景,但是樸素貝葉斯算法同時(shí)存在著一些問(wèn)題,例如先驗(yàn)概率可能為零的情況,這里我們可以利用貝葉斯估計(jì)來(lái)代替極大似然估計(jì),從而解決這一問(wèn)題。我相信,在對(duì)樸素貝葉斯算法的不斷發(fā)展和完善的過(guò)程中,一定可以發(fā)揮其更大的應(yīng)用潛力,為大數(shù)據(jù)時(shí)代的人類做出更大的貢獻(xiàn)。
