機器學習算法在網絡入侵檢測系統中的應用
2019-04-04 07:05:38普華迅光北京科技有限公司
數學大世界 2019年4期
普華迅光北京科技有限公司 楊 寧
一、基于機器學習算法的網絡入侵檢測系統
以機器學習為基礎的入侵檢測系統的組成主要是:模塊的捕捉、處理數據以及機器學習,其中系統運行的核心便是機器學習這一模塊。監測以及驗證網絡工作的狀態的模塊是網絡數據捕捉,該模塊的主要功能便是截獲處在傳輸控制協議模型中各個協議層次上的數據,而實現網絡入侵監測的基礎也在于此。該部分主要利用數據包的嗅探來實現其功能。數據的預先處理部分是對網絡數據包中的數據進行更進一步的分析處理,其中包括解碼數據包的數據,以實現重復數據以及錯誤數據的過濾,并將該過程所產生的特征值作為機器學習部分的輸入值輸入。入侵檢測系統的核心便是機器學習,通過針對性的實現,以保證其功能的實現。基于機器學算法的入侵檢測系統如圖1 所示。

圖1 入侵檢測系統結構
機器學習理論自提出以來,尤其是近些年來,機器學習這一技術發展勢頭正猛。該理論常用到的技術主要是人工神經網絡技術、決策樹、貝葉斯以及規則性學習和遺傳算法等等。機器學習在入侵檢測系統中的應用,用到更多的主要是領域和經驗知識,在系統中主要采用的技術有遺傳算法、決策樹和神經網絡以及貝葉斯這四種。
二、基于機器學習算法的網絡入侵檢測技術支持
1.決策樹
該算法主要是通過將實例從根節處排列到該樹上的某一個節點來分類,所謂葉子的節點便是所用到的實例的分類。而樹上各個節點則規定了各個特征的測試,而且每個節點后續的分支都與該特征的可能值一一對應。分類實例這種方法的起點是該樹的節點,通過該節點指定屬性的測試,接著根據給定的具體屬性值移動,然后在這個過程中以新的節點為根重復上述操作。Quinlan 在1986 年發明了ID3 算法,該算法在決策樹方法中堪稱最為經典的一種算法。不過因為這種算法解決的問題有一定的局限性,僅僅能夠做到離散型數據問題的解決,這遠遠達不到解決入侵檢測問題的程度。不過在1993 年,Quinlan所提出的C4.5 算法對于這種算法來講是一種延續,該算法不僅僅涵蓋了ID3 算法的各種優點,即解決離散型數據的問題,還能夠等價劃分數據屬性的取值集合。在對被劃分在一個類別里的屬性進行判斷之后,走向同一分支。在完成決策樹的構造之后,把各種入侵情況列出,可省略合理的葉節點。將決策樹寫成諸如“if…then”等語句則是決策樹的規則化處理。因為占到入侵數據大部分的是離散值,這便有助于其決策樹的構造,接著可以通過屬性的比對實現入侵行為的準確判斷。
2.貝葉斯理論
該理論的原理是通過概率進行推理,而貝葉斯理論對于機器學習來講至關重要,這一理論給許多假設的置信程度提供了可行的方法,是許多算法學習的基礎。這種理論的算法是通過變量之間的概率關系而建立的模型,也就是說該算法能夠解決入侵檢測系統中許多難以確定的問題。貝葉斯網絡能夠統計異常的檢測,研究人員應尤其注意該方法在入侵檢測中的應用。貝葉斯分類是極為高效的一種機器學習算法,其會將極有可能入侵的行為列入序列,而且還能根據已知序列檢測疑似入侵序列。貝葉斯是一種高效的處理龐大數據的方法,該方法能將確定入侵的事件檢測出來,還能夠將有潛在入侵風險的事件檢測出來,而且能夠學習以及鑒別新的入侵行為,通過概率進行分類,而不是簡單歸類。
3.神經網絡
所謂神經網絡,是通過人腦的模擬加工、處理存儲信息的機制而制定出的一種智能化的處理技術。其組成單位是大量簡單單元。這些簡單的處理單元會互相連接形成復雜的網絡結構。函數的映射權值決定著神經元的輸入輸出過程。一般神經網絡的處理過程主要是神經網絡模型的建立以及訓練、去除冗雜的網絡等階段。入侵檢測系統這一網絡的應用能夠通過大量簡單單位的組合連接實現全職的學習修改,能夠在一組數據輸入之后,實現數據輸出的預測。
該神經網絡的學習算法有誤差補償的原則,在神經網絡輸出的結果出現差錯時,能夠通過閾值以及權重的調整實現誤差的補償。神經網絡的基本結構由節點的學習算法以及拓撲結構組成。系統能夠通過神經系統的學習算法記住合法用戶的基本特點,以便于在用戶輸入時根據其特征進行分類辨別,如果出現系統未記錄的用戶的行為,則會認定該行為為異常行為。比如合法用戶可以通過留下自己的特征(如:指紋、簽名)使用系統,如果入侵者使用用戶信息登錄時,系統會通過指紋的比對查找入侵者。因為用戶在登錄時,其行為特征不易記憶,為了避免用戶忘記自己行為數據的尷尬,神經網絡會將用戶行為轉變成輸入變量,通過神經網絡的輸出,能夠找出輸出和輸入之間的關系,以實現用戶身份的認定。不過該神經網絡系統也存在著諸如系統結構不穩定、學習時間過久等弊端。
4.遺傳算法
該方法也被稱為基因算法,是基于自然選擇的優化搜索方法。該方法的思想基礎是達爾文的進化論和孟德爾的遺傳學說。這種算法會把待解決的方法編碼為基因,而編碼數列被稱為染色體。這種算法的執行過程為編碼、構造適應的函數以及隨機選擇變異或者交叉的方式產生新的解決方法。在最有個體的適應度不再繼續上升時,算法結束。否則則用辨析、選擇等得到的新個體取代最初的個體,再進行循環操作。
三、基于機器學習算法的網絡入侵檢測模型
以機器學習為基礎的入侵檢測示意圖如圖2 所示:
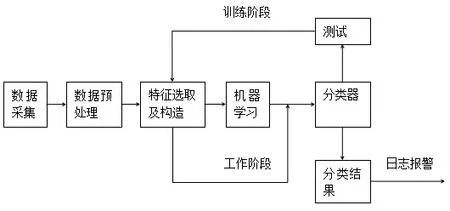
圖2 以機器學習為基礎的入侵檢測系統的指示框架
首先是對已收集的網絡上的調查數據進行預分析處理,根據網絡數據的特征進行選取,以助于將有著正常和非正常區分開來的重要信息特點送進學習機器里進行規范化的學習,而分類機器便是學習輸出機。接著通過數據集的測試對分類機器進行評估測試,以得到入侵檢測系統各個性能指標,在各項規定的指標都滿足的情況下,入侵檢測系統則可以運行。如果入侵檢測系統不符合指標要求,那么則應重新進行部分計算以及特征選取,直至各項性能指標滿足要求。
在采集數據以及預處理數據時,要注意對網絡狀態的監視與驗證,并且取每個協議層的數據進行進一步的分析處理,以便得到所需的特征值。在選取特征以及模塊構造過程中,也就是將選取的模塊構造以及特征值和特征值進行比對分析,如果行為被判斷為入侵性行為,那么就將該行為輸入分類機器里去,否則將其送入機器學習模塊進行處理,再進一步判斷其是否有入侵性行為,接著再對結果處理。所謂機器學習這一部分是通過系統的訓練提高機器的學習能力,以便應付入侵,在這一模塊的訓練之后,其檢測能力會得到一定程度的提升,對于不正常的攻擊,其判斷也會更精確。
入侵檢測這種技術是一種計算機主動出擊來使自己免受傷害的網絡安全技術,隨著計算機以及網絡的進步,這一系統的缺陷更加彰顯。筆者在這里針對其不足之處,創造性地提出了機器學習理論的應用。盡管現在以機器學習為基礎的入侵檢測系統的研究已獲得了不少進展,但是在很多地方還是存在著較多問題亟待解決。基于上述闡述,以機器學習為基礎的入侵檢測系統通過及時更新知識儲備、進一步提升系統的適應能力以及自主學習能力來應付復雜狀況,不過每種機器學習方法都有著自己的不足之處,為了保證入侵檢測系統性能的進一步提高,可以通過將多種機器學習方式整合的方法,保證各種機器學習都能夠充分發揮自己的所長,使入侵檢測系統的功能更加完善。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
