基于多源域深度遷移學習的液晶面板缺陷檢測
2019-04-02 07:59:08
福建質量管理 2019年6期
(重慶郵電大學通信與信息工程學院 重慶 400065) (重慶郵電大學電子信息與網絡工程研究院 重慶 400065)
引言
液晶面板的缺陷檢測是保證液晶面板質量的重要的一環。液晶面板種類多樣,其缺陷種類繁多,如何高效的進行液晶面板的缺陷檢測已經成為了熱門的研究課題。
目前在液晶面板缺陷檢測方面主要有兩種技術思路,以機器視覺與機器學習為代表的手動提取特征的方法和利用深度神經網絡自動提取特征的深度卷積神經網絡的方式。但他們在液晶面板缺陷的檢測問題中均遇到了瓶頸,一是液晶面板缺陷的不規則性、隨機性及其與背景差異性低等特性導致手工提取特征的方法作用甚微,檢測效果達不到工業生產的要求[1];二是由于各類缺陷數據集的采集、標記和制作需要耗費大量的人力物力,導致數據集從質量和數量上均出現數據貧瘠現象,從而使得基于深度卷積神經網絡的缺陷檢測系統出現訓練數據匱乏、模型泛化能力不足和模型穩定性差等問題。因此必須解決在缺陷檢測問題中所面臨的數據貧瘠問題。在缺陷檢測領域中,現有的高質量數據集匱乏并且分散在并沒有打通的各個項目當中,大多數缺陷檢測任務所能利用的數據比較單一,標簽標記的水平也參差不齊。
另一方面,在公開的優質數據集中,如在ImageNet的殘差網絡[2]在識別物體時已經超越人類的性能,Google的Smart Reply[3]系統在谷歌海量優質數據的訓練下可以自動處理所有移動手機的10%的回復,其神經網絡翻譯模型系統已經被用在了超過10種以上的語言之中。這些成功的模型都是在精心多年收集的數據集上進行訓練的。然而當我們把這些機器學習的模型應用在自然環境中時,模型會面臨大量之前未曾遇到的條件。每一個任務都有它們自己的偏好,也需要處理和生成不同于之前用來訓練的數據,要求模型執行很多和訓練相關但是不相同的任務。在此情況下,盡管最先進的模型在它們被訓練的任務和域上展示出了和人類一樣甚至超越人類的性能,然而還是遭遇了明顯的表現下降甚至完全失敗。
因此,從遷移學習的角度出發,對不具有完備數據集的缺陷目標檢測領域展開研究是一個有效的解決方案。近年來已有較多關于遷移學習的研究進展,清華大學的Tan.C等人[4]跟據遷移學習的方式的差別將目前的遷移學習分為四大類:基于實例的深度遷移學習[5-6]、基于映射的深度遷移學習[7]、基于網絡的深度遷移學習和基于對抗的深度遷移學習。其中基于實例的遷移學習是指使用特定的權重調整策略,通過為那些選中的實例分配適當的權重,從源域種選擇部分實例作為目標訓練集的補充。基于映射的深度遷移學習是指將源域和目標域種的實例映射到新的數據空間,在這個新的數據空間中,來自兩個域的實例都是相似且適用于聯合深度神經網絡。基于網絡的深度遷移學習是指服用在源域中預先訓練好的部分網絡,包括其網絡結構和連結參數,將其遷移到目標中使用的深度神經網絡的一部分。基于對抗的深度遷移學習是利用生成對抗網絡技術,找到適用于源域和目標域的可遷移表征。
在單源域遷移學習方面,目前已有較多相關研究,但是如果源域和目標域的相關度比較小,僅僅只是簡單粗暴的進行直接遷移將導致負遷移問題,這不僅不能促進對缺陷目標檢測的性能,而且還會降低整體的檢測精度。同時,僅僅利用一個源域的數據也是對數據集資源的浪費,因此有必要采取多源域深度遷移學習的方式,從多種不同相似任務的數據集上挖掘更多有用的特征信息,使得網絡具有更好的泛化性能和魯棒性。
本文的研究是在基于網絡的深度遷移學習基礎上進行的,以Mask R-CNN網絡為基礎框架,通過混淆域學習的遷移學習方式在多源域數據集上實現了對液晶面板缺陷目標的精準檢測。
一、多源域深度遷移學習定義
(一)遷移學習問題的定義
定義1:(域)數據(domain)由兩個部分組成,特征空間X和邊緣概率分布P(X),其中X=x1,x2,…,xn。
定義2:(任務)給定一個域D={X,P(X)},一個任務T由一個標簽空間Y以及一個條件概率分布P(Y|X)構成,這個條件概率分布是從由特征—標簽對xi∈X,yi∈Y組成的訓練數據中學習得到。
定義3:(遷移學習)給定一個基于域Dt的學習任務Tt,我們可以從Ds中獲取對任務Ts有用的知識。遷移學習旨在通過發現并轉換Ds和Ts中的隱知識來提高任務Ts的預測函數fT(·)的表現,其中Ds≠Dt或Ts≠Tt。此外,大多數情況下,Ds的規模遠大于Dt的規模。
定義4:(深度遷移學習)給定一個由
如圖1所示,為深度遷移學習概念示意圖。

圖1 深度遷移學習示意圖
(二)多源域深度遷移學習定義
定義5:(多源域深度遷移學習)給定一個由<
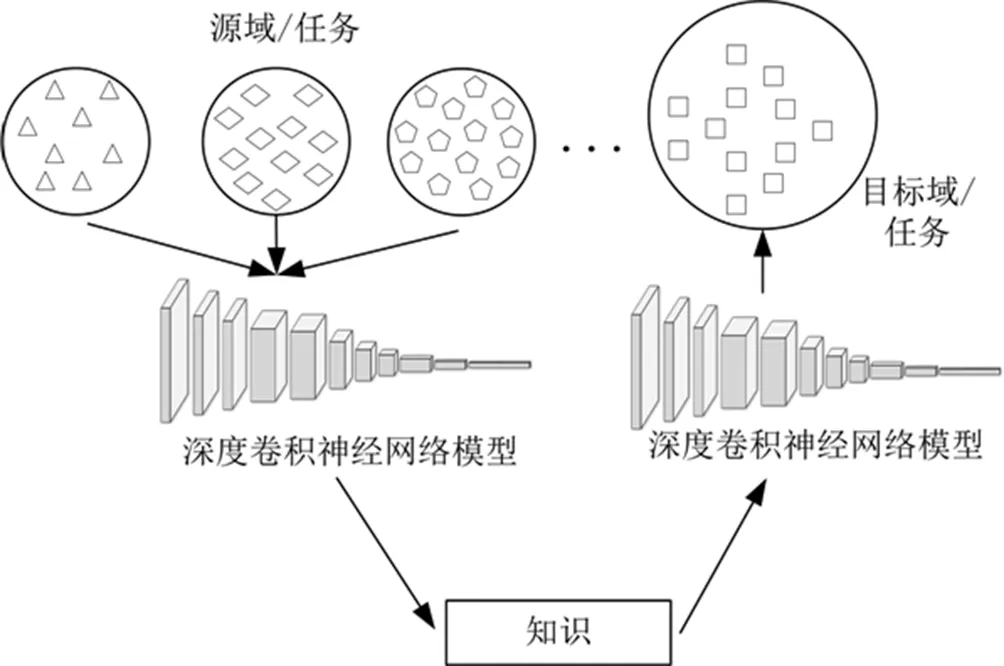
圖2 多源域深度遷移學習示意圖
二、多源域深度遷移學習的液晶面板缺陷檢測
本文采用Mask R-CNN作為遷移學習的主干網絡,Mask R-CNN是何凱明等人在2016年發表的論文中提出的目標檢測的深度神經網絡框架,是目前領先的目標檢測算法。該網絡使用了焦點損失、特征金字塔和Faster R-CNN網絡框架等算法,將位置信息引入最終的全卷積網絡中,實現了較高的精確度。但是直接將該算法應用在液晶面板缺陷檢測的任務時,發現檢測性能達不到工業生產的要求,蛀牙原因是因為數據質量參次不齊,類似于液晶面板等表面缺陷檢測面臨著缺陷語義信息模糊、目標尺度跨度大和小目標占比多等難點。本文以Mask R-CNN框架為基礎,進行了基于混淆域學習的方式遷移學習訓練,最終提高了對液晶面板缺陷的檢測精度。
(一)基于混淆域的深度遷移學習算法框架
設X為樣本的輸入空間,x∈X為一個輸入樣本;Y為缺陷類型的標簽空間,y∈Y為一個對應的標簽。將源域和目標域上存在的分布分別記作f=G(x,θf)和f=G(x,θf),他們均是未知的分布,且他們有著一定的相似性和差異性。整個目標檢測任務的學習最終的目的是給定目標域中的任一個樣本x,通過其分布f=G(x,θf)能夠預測其準確的標簽y。由于目標域的數據質量和數量都不足以表達該目標檢測任務的真實分布,所以僅僅只在目標域上進行訓練得到的預測的性能并不理想。多源域遷移的作用就在于能夠利用多源域的分布對目標域的分布進行補充,將多種分布的知識整合至目標域中。如圖3所示,整個網絡由四個部分組成,第一部分是由Mask R-CNN的特征提取骨干網絡組成的特征提取模塊(Feature extraction Module,FEM),第二部是由Mask R-CNN的分類回歸和全卷積網絡部分所組成的液晶面板缺陷目標檢測模塊(LCD Defect target detection module,LDTDM),第三部分為全卷積層和交叉熵組成的域分類模塊(Domain classification module,DCM),第四部分則是多源域學習網絡結構中承上啟下的關鍵部分:多源域逆梯度層(Multi-source domain reverse gradient layer,MDRGL)。
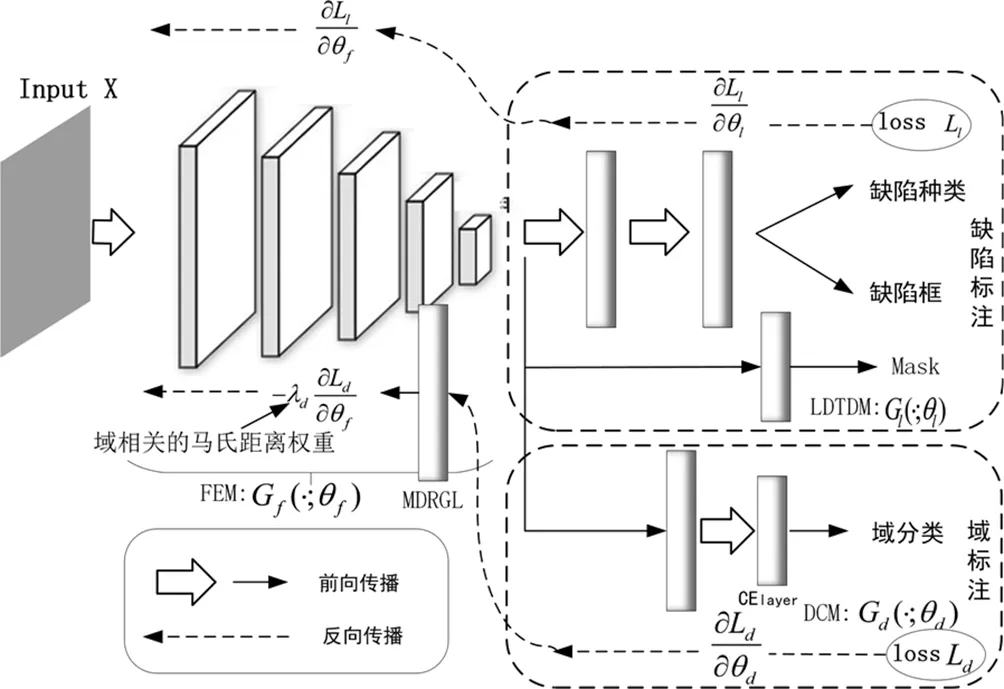
圖3 基于域混淆學習的多源域深度遷移學習算法框架
將圖3中特征提取模塊所對應的輸出記為f=G(x,θf),其中θf為第一部分的學習參數,Gf為該部分所對應的函數映射。同理,將液晶面板缺陷目標檢測模塊部分對應的函數記為Gl,該部分網絡的參數記為θl;將域分類模塊對應的函數記為Gd,該部分網絡的參數記為θd。在模型訓練期間,所有的源域數據樣本共享特征提取部分進而產生特征f,該特征再分別向后續的LDTDM和DCM傳播,訓練的最終期望達效果是特征提取部分和目標域檢測部分所產生的損失達到最小,從而得到缺陷檢測和域分類結果。
(二)基于混淆域的深度遷移學習損失函數及使用馬氏距離作為數據集間度量的反向傳播算法
為保證源域數據集對目標域做出正向影響,本算法在網絡的特征提取模塊進行了混淆域學習,保證該模塊內源域數據和目標域數據均對網絡的參數學習均有貢獻。要保證源域數據對目標域是正遷移(即對目標域分類器性能有促進而非干擾),則必須保證源域學習和目標域學習具有域不變的特性,也即分布函數式子(1)和(2)所示:
S(f)={Gf(x;θf)|x~S(x)}
(1)
T(f)={Gf(x;θf)|x~T(x)}
(2)
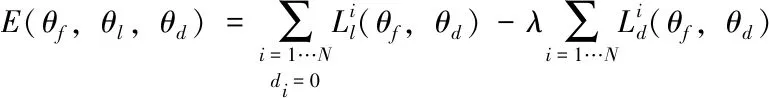
(3)
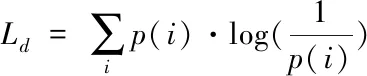
(4)
其中,n為源域數,本文選取了四個源數據域的數據集參與混淆訓練,因此n取值為4。
基于式(3)混淆域損失,多源域深度遷移算法的訓練最終要尋找的最佳參數如式(5)和(6)所示。
(5)
(6)

(7)
(8)
(9)


(10)

三、實驗結果與分析
(一)實驗評價指標
本論文中使用所有缺陷類別的平均準確率(mean Average Precision,mAP)作為最終的評價指標,其定義為所有缺陷類別的準確率-召回率曲線面積之和除以缺陷類別數目,如式(11)所示。
(11)
(二)實驗結果分析
本實驗的環境為Intel Core i7-7700HQ、CPU2.80GHz、GPU Nvidia1080、內存8GB的平臺上,利用Tensorflow2.0平臺完成。本實驗使用的數據集為自制的液晶面板缺陷數據集,該數據集主要由6種液晶面板缺陷組成,這六種缺陷類別分別是:Mura、劃痕、暗點、亮點、劃缺和漏光。數據集中包含每種缺陷類別的圖片數量在800張左右。為了進行多源域的遷移學習,本文收集了多種類似液晶面板圖像的四種源域數據集,它們分別是DAGM數據集、GDXay數據集、Crack Forest數據集和Isheet數據集。其中DAGM數據是一個在2007年在“工業光學檢測的弱監督學習”比賽中所發布的數據集;GDXay數據集是論文所發布的工業缺陷的X射線數據集。Crack Forest數據集是論文所發布的針對城市道路缺陷的數據集。最后一個Isheet是本文所收集制作的鐵皮缺陷數據集。
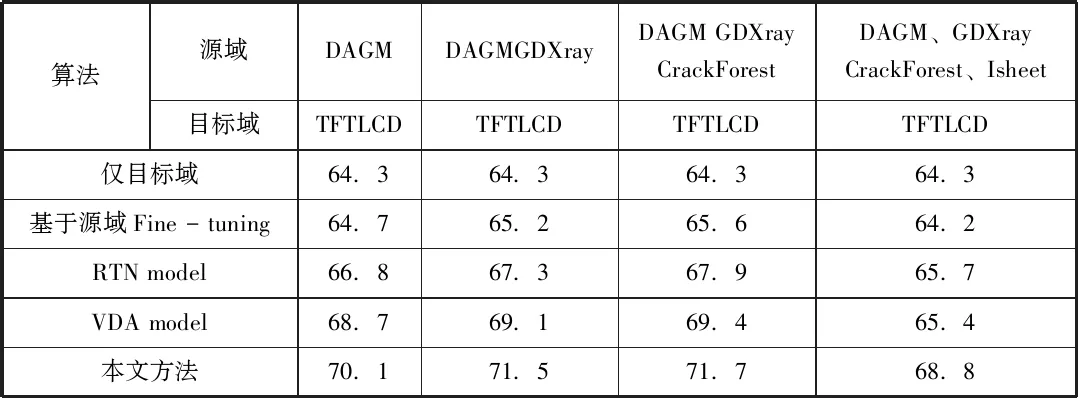
表1 算法性能對比表
表1展示了本文所提出的算法和目前在遷移學習領域表現最好的幾種算法進行對比的結果。表中涉及的算法如下:第一行為Mask R-CNN僅在目標檢測數據集TFT-LCD上進行訓練,第二行為Mask R-CNN網絡在對應的源域數據集上進行預訓練之后,在目標數據集上進行Fine-tuning,第三行為論文所提出的基于遷移學習的RTN網絡,其主要算法為將網絡的前大半部分層的預訓練參數遷移至目標任務的網絡,作為其特征提取模塊,并在其后添加自適應分類器(adaptive classifiers,AC)進行預測。第四行為論文在2017年所提出的VDA算法(Visual domain adaptation,VDA),其核心思想是將自適應學習和遷移學習結合,基于自適應的矩陣進行知識的遷移。本文將上述四種算法框架在表1所示的四種源域數據集和液晶面板缺陷數據集上進行了性能對比。
實驗結果表明,來自多源數據的豐富度越高時,算法在目標域上表現有顯著提升,但從表的最后一列觀察得到其性能有所下降,其主要原因在于該數據集Isheet為自制的鐵皮缺陷數據集,其與目標域特征相差較大,因此產生了負遷移。從表的縱向結果可以看到,相對于僅在目標域的液晶面板數據集TFTLCD數據集上訓練所得的檢測效果而言,本文所提的算法有11.5%的提升,達到了71.7%的mAP;相較于基于源域Fine-tuning的方法提升了9.3%。同時,本文算法在液晶面板任務檢測中的性能也超過了目前性能最優的VDA和RTN算法,相較于RTN算法提升了6%,相較于VDA算法有小幅的提升,提升為3.3%。同時,本文針對Mura缺陷對比了上述幾種學習算法框架,得到了他們的precision-recall圖,如圖4所示。
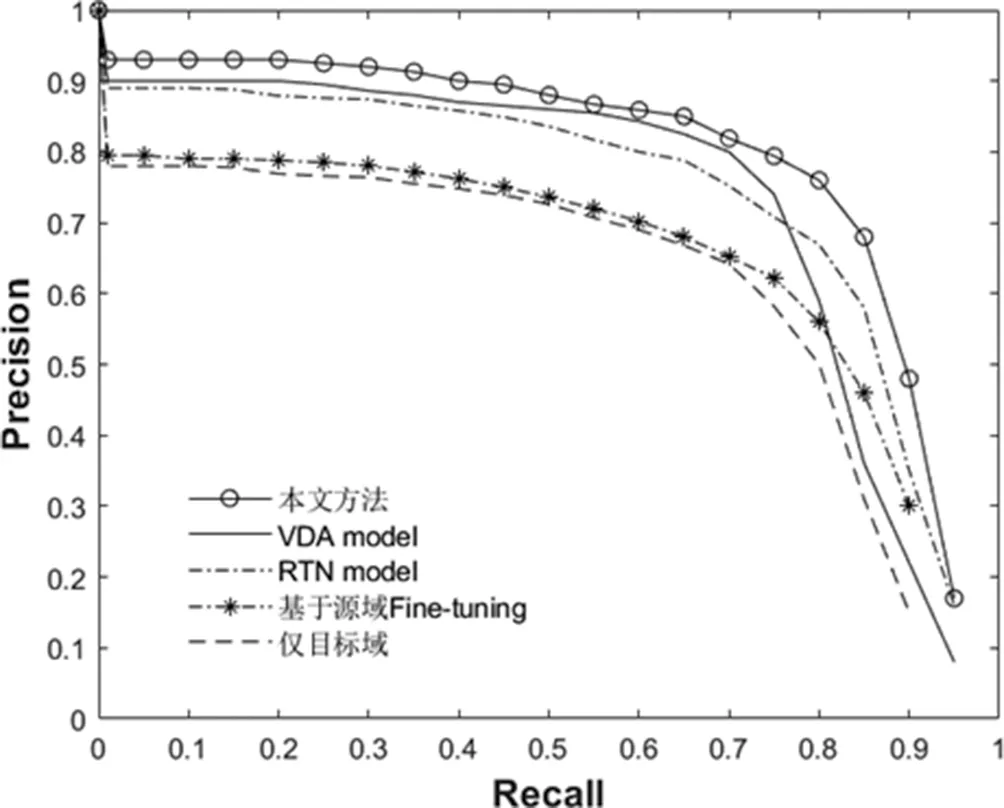
圖4 不同算法下Mura缺陷的Precise-Recall圖

圖5 分割效果圖
四、結束語
本文提出了基于Mask R-CNN的多源域遷移學習的液晶面板缺陷檢測方法,主要針對缺陷檢測問題中普遍存在的數據不足和模型泛化性能較差等問題,采用來源于四種源域的數據進行混淆域學習。實驗表明,該算法與已有的缺陷檢測算法對比,具有更高的檢測精度和泛化性能,在液晶面板數據集TFT-LCD上達到了79.6%的mAP,相比非遷移學習方法提升了23.8%。該算法還且擁有良好的檢測效率,適用于工業生產的要求。
本文認為針對此類訓練數據不充足的異常檢測類型的問題,在遷移學習方面仍有進一步研究的空間,后續的研究將在針對優化缺陷知識的遷移方式上展開。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
