基于改進遺傳算法的配電網故障定位方法*
2019-03-22 12:00:56蒯圣宇朱曉虎高傳海
沈陽工業大學學報 2019年2期
謝 濤, 蒯圣宇, 朱曉虎, 高傳海
(國網安徽省電力有限公司 a. 發展策劃部, b. 經濟技術研究院, c. 合肥供電公司, 合肥 230022)
分布式電源(如風電、光伏發電、天然氣發電等)具有低能耗、低污染的特點[1-2],近年來得到了迅速的發展,雖然分布式電源的接入能帶來巨大的經濟效益,但也嚴重地影響了配電網的安全穩定運行[3-4].
據統計,95%的用戶側停電是由配電網故障所引起的[5].為了保證配電網的安全性和穩定性,需要快速準確地定位故障線路,并恢復正常線路的供電,以使經濟損失最小化[6].但隨著分布式電源的接入,傳統的輻射型單電源配電網絡變成了用戶和電源互聯的多電源復雜網絡.傳統的潮流計算、繼電保護和故障定位方法也受到不同程度的影響,為配電網故障定位的準確性和效率帶來了新的挑戰[7-8].
諸多專家和學者提出了不同的故障檢測與定位方法,如行波法[9-12]、阻抗法[13-15]和基于人工智能的方法[16-18].行波法基于輸電線路終端與故障點之間的行波傳輸與反射特性確定故障的位置.該種方法需要高速的數據采集設備、傳感器、故障檢測器和全球定位系統來捕捉故障位置的瞬態波形,然而由于配電網存在各種分支結構,故較少使用行波法進行故障定位[11-12].阻抗法根據節點處的電壓和電流值來計算阻抗值,從而確定故障位置[13],其根據測量方式的不同,可以分為單端測量法和雙端測量法[14].單端測量法使用變電站的電壓和電流進行故障定位,雙端測量法則使用配電系統兩端的電壓和電流進行故障定位與識別.雖然雙端測量法具有更高的精度,但需要花費更多代價和通訊鏈路[15].盡管阻抗法在眾多系統中取得了較高的定位精度,但文獻[15]指出其精度可能受到多種因素的影響,如系統不均勻、線路參數的測量誤差、不準確的繼電器測量值和故障電阻等.基于人工智能的方法通過分析饋線與變電站的開關狀態以及沿饋線和大氣條件安裝的故障檢測設備所提供的信息進行故障定位.此類方法包括人工神經網絡[16]、支持向量機[17]、遺傳算法[18]以及其他各種機器學習方法[19-21],通常具有較高的精度與檢測速度.其中,基于人工神經網絡的方法實現簡單,只需檢測獨立或非獨立變量的非線性關系,但其精度依賴于訓練數據的質量,且訓練過程收斂較慢[16,19];基于支持向量機的方法即使在處理大規模配電網時仍具有較快的定位速度,但核函數和超參數的選擇將極大地影響模型性能[17,20];而基于遺傳算法的故障定位方法不僅能大幅提高檢測速度,還能減小問題規模,但在分布式電源不同投切情況下,需要更改適應度函數與開關函數,從而降低了故障定位的穩定性及精度[21].
針對上述問題,本文提出了一種基于改進遺傳算法的含分布式電源配電網故障定位方法.該方法通過改進傳統遺傳算法的變異算子、交叉算子、適應度函數和開關函數等來更好地適應分布式電源的不同投切情況.仿真結果表明,該算法可以適應配電網結構多變的特點,與傳統的遺傳算法相比具有更優的穩定性和定位精度.
1 遺傳算法故障定位
遺傳算法的基本流程如圖1所示,其使用選擇、交叉和變異3個基本操作搜索解空間,來求解優化問題.

圖1 遺傳算法基本流程Fig.1 Basic flow chart of genetic algorithm
選擇操作即根據適應度值的大小從解集中淘汰劣質個體,選出優質個體,并經遺傳或交叉操作遺傳到下一代.交叉操作通過模仿生物進化的基因重組過程來產生新個體,一般只交換兩個有較高適應度個體的部分基因來產生新個體,即單點交叉,示例如圖2所示.變異操作則以小概率隨機改變某個個體的基因來構造新個體,包括二進制變異與實值變異兩種方式.

圖2 單點交叉示例Fig.2 single point cross example
基于遺傳算法的配電網故障定位首先通過分析饋線終端設備(feeder terminal unit,FTU)和數據采集與監視控制系統(supervisory control and data acquisition,SCADA)獲取故障過流信息,并得到各饋線開關的過流狀態;其次使用如圖2所示的二值編碼方式編碼線路狀態和開關狀態,并定義開關函數聯系線路狀態與開關過流狀態;然后根據線路的故障狀態得到個體的基因表達,并生成初始化種群;最后使用上述遺傳算法尋找適應度函數取最大值的個體,并定位故障區域.
該種方法主要針對傳統配電網的故障定位問題,當分布式電源接入配電網后,網絡的拓撲結構發生了改變,傳統的適應度函數和開關函數已不再適用.此外,當配電網接入多個分布式電源時,需要使用N次遺傳算法定位故障區域,因而效率低、速度慢.
2 改進遺傳算法故障定位
針對傳統遺傳算法存在的問題,通過改進變異算子、交叉算子、適應度函數和開關函數等來更好地適應分布式電源的不同投切情況,有效解決含分布式電源的配電網故障定位問題.當配電網發生故障時,系統將接收到FTU和SCADA獲取的故障過流信息,并啟動故障定位算法流程.經過迭代求解可以直接獲取故障區域,具體處理流程如圖3所示.
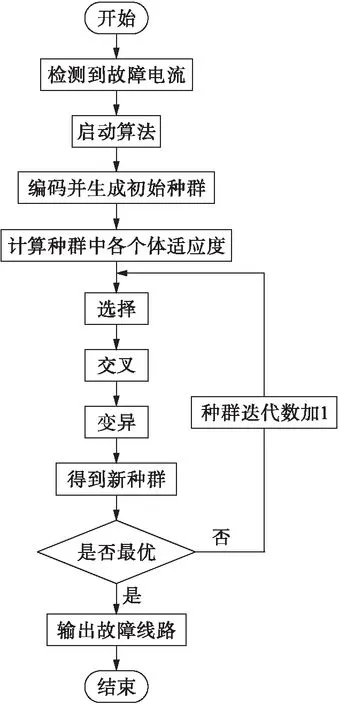
圖3 基于改進遺傳算法的配電網故障定位算法流程Fig.3 Flow chart of fault location algorithm of distributionnetwork based on improved genetic algorithm
2.1 交叉和變異算子
傳統的遺傳算法使用固定的交叉和變異概率,導致不同適應度的個體具有相同的變異概率,從而不易于保存具有較大適應度的個體.因此,本文提出了一種自適應的交叉、變異概率,其定義分別為
(1)
(2)
式中:Pcmax、Pcmin和Pmmax、Pmmin分別為交叉和變異概率最大值及最小值;f為個體的適應度值;fmax、favg為種群最大適應度和平均適應度.式(1)、(2)表明,交叉與變異概率在適應度的最大值和平均值間按照sigmoid函數進行非線性調整,以壓低最大適應度附近個體的交叉、變異概率,并盡可能多地遺傳到下一代.
2.2 開關和線路編碼
隨著分布式電源接入配電網,配電網的運行方式變得復雜多樣.傳統的基于電源位置的開關正方向定義方式需要將多電源網絡分成多個單電源網絡并反復計算定位,降低了算法的自適應能力,因此,本文提出了一種基于潮流流向的開關正方向定義方式.當分布式電源的投切狀態發生改變時,可直接根據網路的潮流值來定義各開關正方向,該種方式不僅可以提高算法的自適應能力和定位速度,還能簡化適應度函數與開關函數的定義方式.
傳統算法使用0、1值編碼線路,即開關正常時編碼為0,而流過故障電流時編碼為1.當分布式電源接入配電網后,開關可能流過與規定正方向相反的電流,已無法再使用0、1值來編碼.因此,本文引入了中間狀態編碼方式,用-1表示開關正流過與規定正方向相反的故障電流.
含分布式電源配電網的電流方向如圖4所示,電網中包含1個主電源S和3個分布式電源DG1、DG2和DG3,使用PSCAD仿真可以得到系統潮流如圖4中實線所示(圖中1~14表示開關,(1)~(14)表示饋線).當饋線2出現故障時,可得到此時電流方向如圖4中虛線所示.使用本文編碼方法,可得到14個開關的狀態編碼值為1,1,-1,-1,-1,-1,-1,1,1,1,0,0,1,0.
2.3 開關函數
針對分布式電源經常投切的問題,本文根據分布式電源的開關函數來表示各電源的投切情況,并引入了含分布式電源的開關函數,即
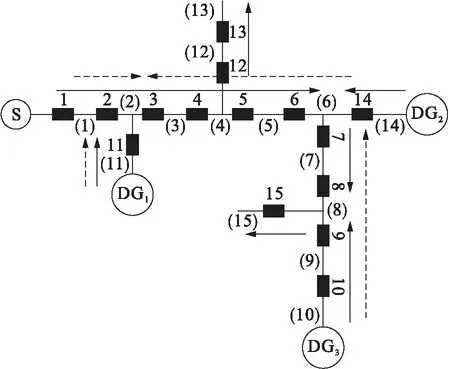
圖4 含分布式電源配電網的電流方向Fig.4 Current direction of distribution networkwith distributed power generation
(3)
式中:s(i)為第i個開關的期望函數;‖為邏輯或運算;cj和ch為開關的投切系數;p、q分別為開關i上半區與下半區饋線區段總數;xi,p、xi,q分別為開關i上半區與下半區饋線的故障狀態;xi,k、xi,h分別為開關i上半區和下半區所經過的饋線區間的故障狀態.該開關函數可適用于單電源和多電源配電網,同時還可適應分布式電源的不同投切狀態.
2.4 適應度函數
傳統適應度函數應用于含分布式電源的配電 網時,易出現誤判的問題.本文根據最小集理論,在原始適應度函數的基礎上加入了一個正則項,即
(4)
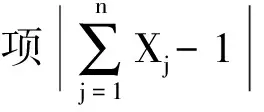
使用對偶原理可將式(4)所示的求最小適應度問題轉化為求最大適應度問題,即
(5)
式中,M一般取開關總數的兩倍以保證適應度恒正.
2.5 分級處理
本文針對我國配電網具有開關運行、閉環結構和呈輻射狀的特點,提出了一種分級處理的方式,以解決FTU監測點過多導致種群規模變大、處理效率低的問題.具體流程為:首先確定配電網的主干線路;然后沿這條主干線路將配電網分成一系列不相交的子區域,以減小可行解數目;最后使用改進的遺傳算法對各子區域進行故障定位,該種方法能有效地減小種群規模、提高計算速度.
3 算例分析
本文結合文獻[20]的配電網,選用如圖5所示包含1個主電源S、3個分布式電源DG1、DG2和DG3的33節點配電系統進行算例仿真,分析單故障與多故障時算法的性能.

圖5 含分布式電源33節點配電網Fig.5 Distribution network with distributed power generation with 33 nodes
本文通過設置投切開關K1、K2和K3的不同開閉狀態來改變系統的潮流方向,如K1=1表示接入DG1,K1=0表示未接入DG1,同時電網在不同的開關狀態下具有不同的主干電路.本文使用改進遺傳算法對在多種不同情況下發生的單個或多個故障狀態進行仿真分析.實驗過程中設置算法的最大迭代次數為50,種群規模為100,M為70,仿真結果如表1所示.

表1 不同故障情況下的測試結果Tab.1 Test results under different fault conditions
從表1中可以看出,在單個或多個分布式電源接入配電網以及存在單故障與多故障的情況下,所提出的算法均可根據各開關的故障狀態準確定位出故障區間.
為了進一步證明所提出算法的優越性,將提出的改進算法與傳統的遺傳算法進行了適應性比較.假設圖5中配電系統的4、18處開關出現了故障,此時,系統獲取的各開關的狀態信息為[1,1,1,0,1,1,1,-1,-1,-1,-1,-1,1,1,0,0,-1,1,-1,-1,-1,-1,0,0,0,-1,-1,-1,-1,-1,-1,-1,-1],分別使用兩種算法運行3次,得到的仿真分析結果如圖6、7所示.
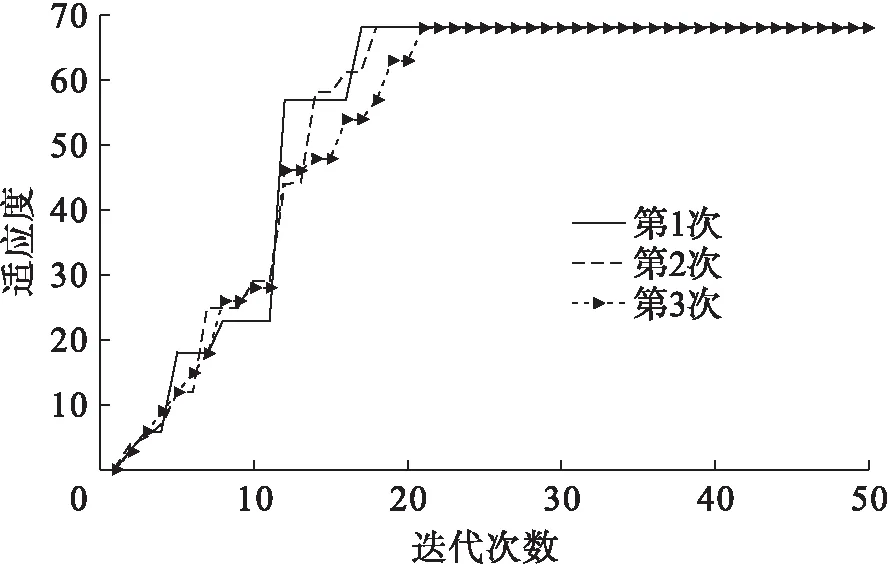
圖6 改進遺傳算法的3次測試結果Fig.6 Three test results of improved genetic algorithm
由圖6、7可知,改進遺傳算法所需的迭代次數明顯比傳統遺傳算法要少.同時,提出算法3次測試結果較相近,而傳統遺傳算法易陷入局部最優解.由此表明,改進的遺傳算法具有更優的穩定性和適應度.
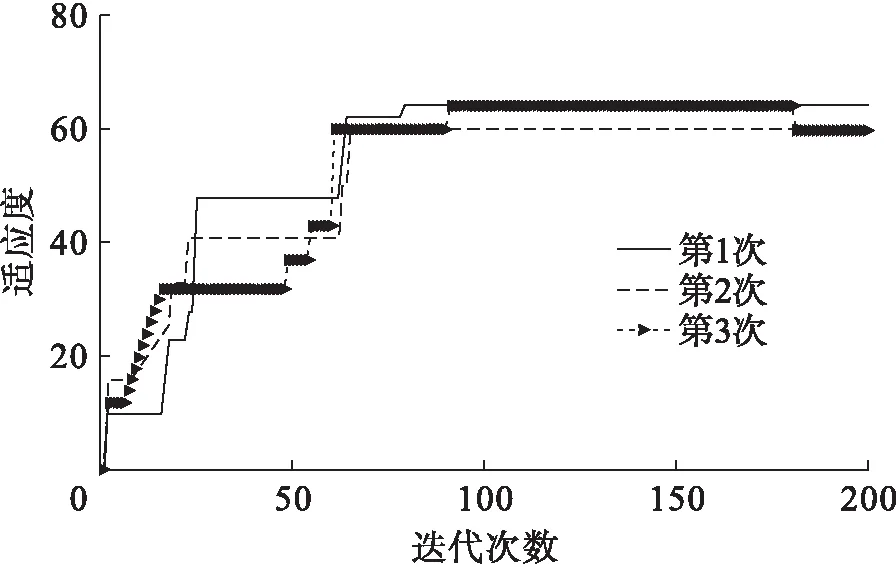
圖7 傳統遺傳算法的3次測試結果Fig.7 Three test results of traditional genetic algorithm
綜上所述,本文提出的改進遺傳算法能有效定位含分布式電源配電網的單重或多重故障,具有收斂速度快、迭代次數少以及計算效率高的優點.相比于傳統的遺傳算法,本文提出的算法還具有更優的穩定性與適應度,可以更好地適應配電網結構多變的特點.
4 結 論
雖然分布式電源接入配電網能帶來巨大的經濟效益,但也嚴重地影響了配電網的安全穩定運行.本文針對傳統遺傳算法在分布式電源不同投切情況需要改變適應度函數與開關函數,從而導致故障定位穩定性與精度降低的問題,提出了一種基于改進遺傳算法的含分布式電源配電網故障定位方法.通過改進變異算子、交叉算子、適應度函數和開關函數等來更好地適應分布式電源的不同投切情況,有效解決含分布式電源的配電網故障定位問題.實例與仿真結果表明,所提出的方法能有效定位含分布式電源配電網的單重或多重故障,具有收斂速度快、迭代次數少和計算效率高的優點.
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
汽車維護與修理(2016年10期)2016-07-10 08:17:41
電子制作(2016年23期)2016-05-17 03:54:05
電測與儀表(2016年5期)2016-04-22 01:14:14
河南電力(2016年5期)2016-02-06 02:11:24
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
電測與儀表(2015年13期)2015-04-09 11:57:38
