基于PageRank與HITS的改進(jìn)算法的網(wǎng)頁排名優(yōu)化
2019-03-20 11:46:08庫珊,劉釗
武漢科技大學(xué)學(xué)報(bào) 2019年2期
關(guān)鍵詞:頁面
庫 珊,劉 釗
(1. 武漢科技大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,湖北 武漢,430065;2. 武漢科技大學(xué)智能信息處理與實(shí)時(shí)工業(yè)系統(tǒng)湖北省重點(diǎn)實(shí)驗(yàn)室,湖北 武漢,430065)
PageRank算法是1998年由Google創(chuàng)始人Sergey Brin和Lawrence Page提出的基于鏈接分析的網(wǎng)頁排序算法[1],其思想是通過分析網(wǎng)絡(luò)的鏈接結(jié)構(gòu)來獲得網(wǎng)絡(luò)中網(wǎng)頁的重要性排名。傳統(tǒng)的PageRank算法中,對(duì)于同一網(wǎng)頁鏈出時(shí)的頁面等級(jí)值(PageRank)是同等對(duì)待且平均分配的,沒有考慮到不同鏈接的重要性會(huì)有所不同,而這與Web鏈接的實(shí)際情況不符。幾乎在同一時(shí)期,康奈爾大學(xué)的Kleinberg博士提出了HITS算法[2],作為同樣基于鏈接分析的算法,該算法中引入了樞紐(Hub)頁面和權(quán)威(Authority)頁面的概念,兩者的相互優(yōu)化關(guān)系構(gòu)成了HITS算法的基礎(chǔ),但是兩者在迭代過程中會(huì)相互增強(qiáng),對(duì)查詢結(jié)果的準(zhǔn)確性造成影響。此后,相繼出現(xiàn)了ARC[3]、SALSA[4]算法等一系列以鏈接分析為基礎(chǔ)的頁面分級(jí)算法,并且在實(shí)際應(yīng)用中取得了一定的成果。另一方面,為解決傳統(tǒng)PageRank和HITS算法中存在的不足,國內(nèi)外研究者也提出了許多改進(jìn)算法,如文獻(xiàn)[5]提出了結(jié)合鏈接和內(nèi)容信息的改進(jìn)PageRank算法,其去除了PageRank算法需要的前提,考慮到了用戶從一個(gè)網(wǎng)頁直接跳轉(zhuǎn)到非直接相鄰但內(nèi)容相關(guān)的另外一個(gè)網(wǎng)頁的情況。文獻(xiàn)[6]提出了通過在PageRank算法中添加鏈入鏈出權(quán)重因子、用戶反饋因子、主題相關(guān)因子和時(shí)間因子,使得搜索結(jié)果更接近用戶查詢需求,同時(shí)兼顧了搜索內(nèi)容的相關(guān)度和查準(zhǔn)率。文獻(xiàn)[7]提出利用PageRank算法對(duì)Lucene原有的排序算法進(jìn)行改進(jìn),設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)針對(duì)移動(dòng)信息的個(gè)性化搜索引擎。文獻(xiàn)[8]提出了一種結(jié)合網(wǎng)頁文本分析和擴(kuò)散速率改進(jìn)的F-HITS算法,以解決傳統(tǒng)HITS算法中易發(fā)生主題漂移、計(jì)算效率低等問題。
基于此,本文通過分析傳統(tǒng)PageRank和HITS算法中存在的不足,提出了一種基于這兩種算法的改進(jìn)算法PHIA(PageRank and HITS Improved Algorithm),該算法繼承了HITS算法獲取根集和基本集的方法,并使用根集中所有網(wǎng)頁的PageRank值作為Hub值和Authority值的初始迭代值,放棄了HITS算法中的相互迭代方式,而是通過求馬爾可夫矩陣的方式來獲取網(wǎng)頁排名的靜態(tài)分布。
1 網(wǎng)頁排序算法
1.1 PageRank算法
PageRank算法是根據(jù)網(wǎng)頁超鏈接之間的相互關(guān)系來確定網(wǎng)頁的重要性和排名的,基于“由許多網(wǎng)頁或一些權(quán)威網(wǎng)頁鏈接的網(wǎng)頁必然是權(quán)威網(wǎng)頁”的前提條件,以網(wǎng)頁間的鏈接結(jié)構(gòu)為基礎(chǔ),來劃分網(wǎng)頁的重要性等級(jí)[9]。在鏈接網(wǎng)絡(luò)中,將網(wǎng)頁A指向網(wǎng)頁B的鏈接看作是A對(duì)B的投票,根據(jù)一個(gè)網(wǎng)頁所獲得的投票次數(shù)來判斷網(wǎng)頁的重要性,一個(gè)網(wǎng)頁的PageRank值PR可由下式(1)表示:
(1)
式中:i、j表示網(wǎng)頁;Q(i)表示網(wǎng)頁i指向的鏈接集合;S(j)表示網(wǎng)頁j指向的所有鏈接的數(shù)目;PR(j)表示頁面集Q(i)中任意一個(gè)頁面j的PR值;PR(j)/S(j)則表示網(wǎng)頁i的鏈入網(wǎng)頁j給予網(wǎng)頁i的PR值。
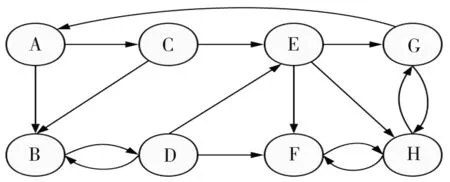
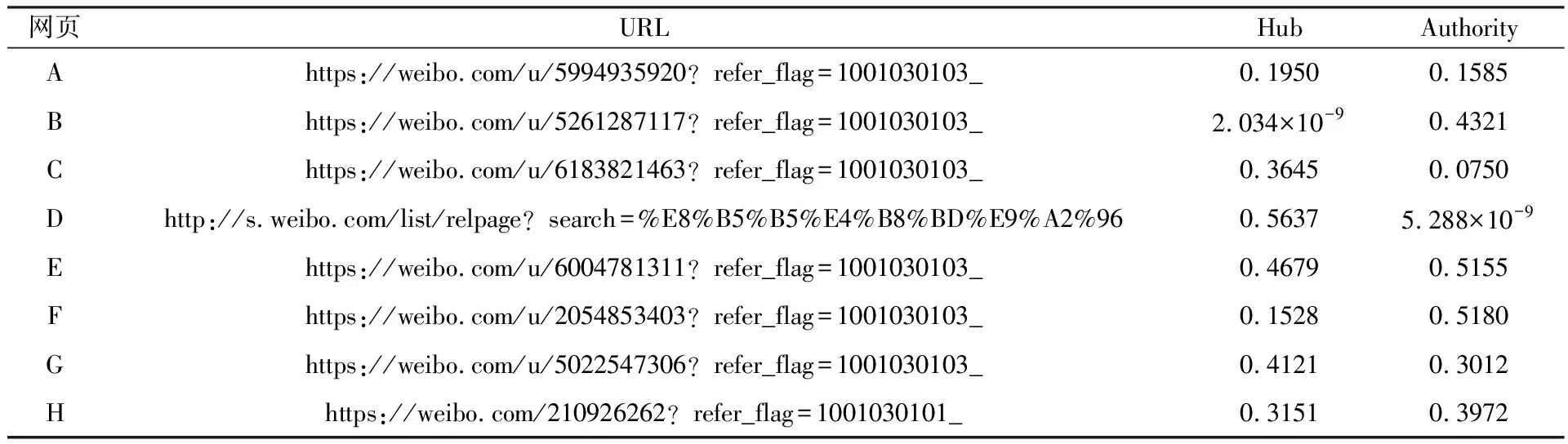
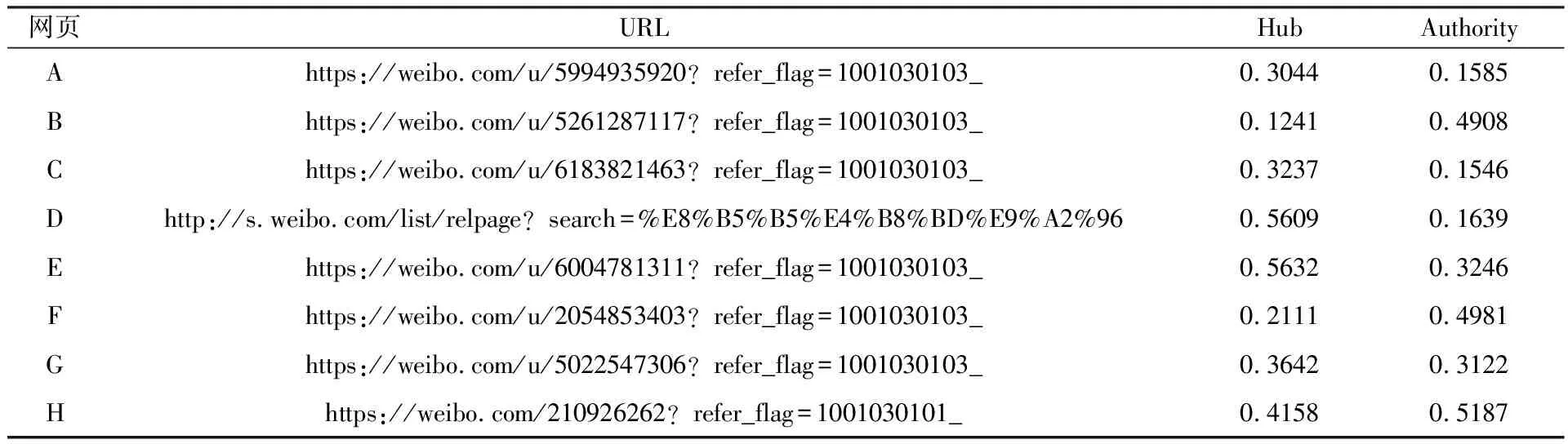
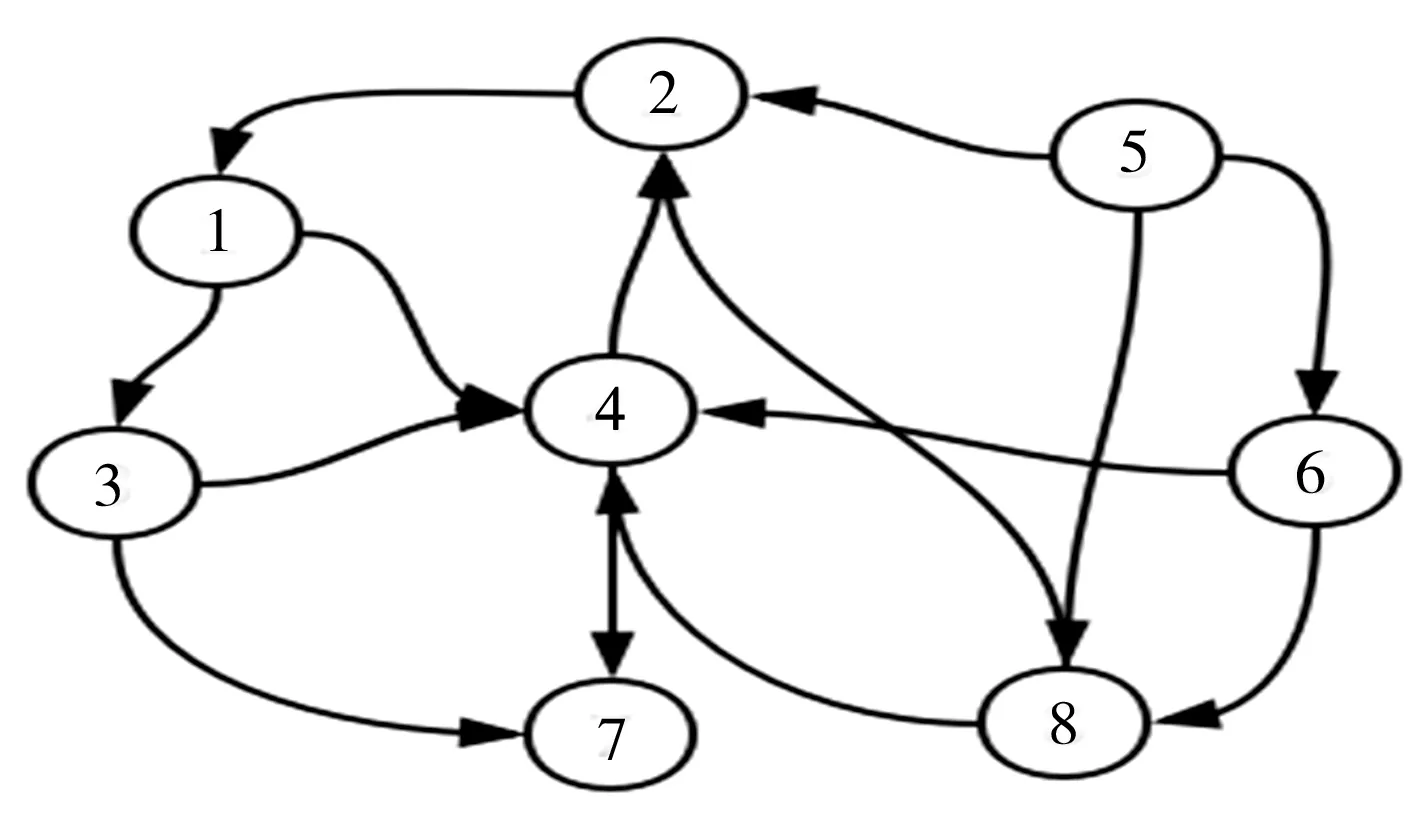
但在實(shí)際應(yīng)用中,Web連接圖中常常存在一些出度或入度為0的節(jié)點(diǎn),即存在環(huán)的情況,這時(shí)會(huì)出現(xiàn)兩種異常:等級(jí)泄露(Rank Leak)和等級(jí)下沉(Rank Sink)[10]。為避免上述現(xiàn)象,可以在去掉Web鏈接中所有出度為0的節(jié)點(diǎn)后,定義一個(gè)阻尼系數(shù)d(0 (2) 式中:m表示節(jié)點(diǎn)的總個(gè)數(shù)。 一個(gè)頁面的PageRank值是由所有鏈向它的頁面(鏈入頁面)的重要性經(jīng)過遞歸算法得到的,計(jì)算過程需要迭代。大量實(shí)驗(yàn)證明,經(jīng)過反復(fù)迭代計(jì)算得到網(wǎng)頁的PageRank值是收斂且有效的。PageRank 算法作為與查詢主題無關(guān)的靜態(tài)算法,所有網(wǎng)頁的PageRank 值均可以通過后臺(tái)離線計(jì)算獲得,這有效地減少了在線查詢時(shí)的計(jì)算量,降低了用戶查詢相應(yīng)的時(shí)間。然而,PageRank算法的特點(diǎn)使其仍受制于主題漂移、偏重舊網(wǎng)頁、忽視用戶個(gè)性化等問題。 HITS算法是一種基于超鏈接分析的網(wǎng)頁排序算法。該算法中,網(wǎng)頁被分為Authority和Hub兩種類型,所謂Authority頁面指的是與查詢主題最為相關(guān)并具有高質(zhì)量、權(quán)威性的網(wǎng)頁,Hub頁面則是指提供指向Authority網(wǎng)頁鏈接集合的網(wǎng)頁。同時(shí),也為每個(gè)網(wǎng)頁定義了兩個(gè)權(quán)值,即Authority值和Hub值,用來判斷該網(wǎng)頁對(duì)特定主題的重要性。 HITS算法的建立基于以下兩點(diǎn)假設(shè):①一個(gè)好的Authority頁面會(huì)被很多好的Hub頁面指向;②一個(gè)好的Hub頁面會(huì)指向很多好的Authority頁面。該算法的具體實(shí)現(xiàn)過程為: Step1將查詢主題q提交給某搜索引擎,從返回結(jié)果頁面的集合中取前n個(gè)結(jié)果作為根集Q,Q需要滿足:①Q(mào)中網(wǎng)頁數(shù)量足夠小;②Q中包含很多與查詢相關(guān)的頁面;③Q中包含很多高質(zhì)量的Authority頁面。 Step2通過向Q中加入被Q引用的網(wǎng)頁和引用Q的網(wǎng)頁,將其擴(kuò)展成一個(gè)更大的集合T。以T中的Hub 網(wǎng)頁為頂點(diǎn)集V1,以Authority網(wǎng)頁為頂點(diǎn)集V2,以V1到V2的超鏈接為邊集E,形成一個(gè)二分有向圖G=(V1,V2,E)。對(duì)于V1中任一頂點(diǎn)v,用h(v)表示其Hub值;對(duì)于V2中任一頂點(diǎn)u,用a(u)表示其Authority值。 Step3初始化a、h,令a0=h0= 1。 Step4分別對(duì)u、v進(jìn)行如下操作,以修改a(u)和h(v)的值: ①a(u)=∑h(v);②h(v)=∑a(u)。 Step5對(duì)a(u)、h(v)進(jìn)行規(guī)范化處理,即: Step6不斷地重復(fù)Step4和Step5,直至a(u)、h(v)收斂,輸出最大的Authority值和Hub值。 與PageRank算法不同,HITS算法與用戶輸入的查詢請(qǐng)求密切相關(guān),因而必須在接收到用戶查詢后進(jìn)行實(shí)時(shí)計(jì)算,計(jì)算效率較低;另一方面,盡管HITS算法在某些查詢主題下能夠較為準(zhǔn)確地提取出Authority網(wǎng)頁,但若擴(kuò)展網(wǎng)頁集合里包含部分與查詢主題無關(guān)的頁面,且這些頁面之間有較多的相互鏈接指向,那么使用HITS算法很可能會(huì)給予這些無關(guān)網(wǎng)頁很高的排名,導(dǎo)致搜索結(jié)果發(fā)生“主題漂移”。此外,HITS算法還存在易被作弊者操縱結(jié)果、結(jié)構(gòu)不穩(wěn)定等問題。 針對(duì)上述不足,本文提出了一種基于PageRank和HITS算法的改進(jìn)算法PHIA。該算法繼承了HITS算法獲取根集和基本集的方法,并且使用根集中所有網(wǎng)頁的PageRank值作為Hub值和Authority值的初始迭代值,以避免“主題漂移”現(xiàn)象的發(fā)生;其次,改進(jìn)算法放棄了HITS算法中的Hub值和Authority值相互迭代方式,而是通過求馬爾可夫矩陣及其特征向量的方式來獲取網(wǎng)頁排名的靜態(tài)分布,以避免其相互迭代所產(chǎn)生的增強(qiáng)值誤差。算法PHIA的具體實(shí)現(xiàn)步驟為: Step1根據(jù)用戶請(qǐng)求,用Google、Firefox等常用搜索引擎進(jìn)行查詢,取返回頁面中的前n個(gè)網(wǎng)頁作為算法的根集,記為Q。隨后對(duì)集合Q進(jìn)行擴(kuò)充,方法為將根集Q中每一節(jié)點(diǎn)的入鏈(所有指向該節(jié)點(diǎn)的頁面)和出鏈(該節(jié)點(diǎn)指向的所有網(wǎng)頁)補(bǔ)充進(jìn)來,形成基本集,記為SQ。 Step2求SQ中頁面的PageRank值。設(shè)W為SQ中頁面的集合,N=|W|,Ri為頁面i指向的所有頁面的集合,Bi為指向i的所有頁面的集合;對(duì)每個(gè)出度為0或出度頁面不在SQ中的頁面s,設(shè)RS={SQ中所有頁面的集合},則所有其他節(jié)點(diǎn)的Bi={Bi∪s},這樣可以將結(jié)點(diǎn)s所具有的PageRank值均勻地傳遞給其他所有頁面i。由此,頁面i的PageRank值PR(i)可以通過以下兩步計(jì)算得出:①以概率“1—m”隨機(jī)取基本集SQ中任意頁面i;②以概率m隨機(jī)取指向當(dāng)前頁面i的頁面j,如果j?SQ,則重新選擇頁面j。PageRank算法的具體迭代公式為: (3) 式中:參數(shù)m為取值范圍在0~1范圍的衰減因子,通常被置為0.85。 Step3用計(jì)算得到的PageRank值代替SQ集中每一個(gè)頁面的Authority和Hub初始值。從集合SQ構(gòu)造無向圖G′ = (Vh,Va,E),得到兩條鏈,即Authority鏈和Hub鏈: Vh=(sh|s∈SQ∪出度(s)>0} (G′的Hub邊) Va={sa|s∈SQ∪入度(s)>0} (G′的Authority邊) E={(sh,ra)}s→rinSQ} Step4根據(jù)2條馬爾可夫鏈[11]定義其變化矩陣,也即隨機(jī)矩陣,分別是Hub矩陣H和Authority矩陣A。 (4) (5) Step5求出矩陣H、A的主特征向量,即為對(duì)應(yīng)的馬爾可夫鏈的靜態(tài)分布,H、A中較大數(shù)值所對(duì)應(yīng)的網(wǎng)頁為所查找的重要網(wǎng)頁。 為驗(yàn)證改進(jìn)PHIA算法的正確性和有效性,本文建立了一個(gè)實(shí)驗(yàn)系統(tǒng),即用網(wǎng)絡(luò)爬蟲工具Heritrix在Google搜索引擎上,采用BroadScope模式對(duì)新浪微博網(wǎng)站的“娛樂版塊”和“研究版塊”進(jìn)行網(wǎng)頁抓取。這兩個(gè)板塊中,各節(jié)點(diǎn)之間具有良好的互動(dòng)關(guān)系,因此能夠較好地模擬互聯(lián)網(wǎng)的網(wǎng)絡(luò)結(jié)構(gòu)。本文隨機(jī)選取“趙麗穎”和“Web前端”作為查詢主題,由于本實(shí)驗(yàn)選擇的新浪微博中兩個(gè)板塊的網(wǎng)頁是由人工分類所形成的,并且所查詢關(guān)鍵字的含義較為簡單,故根據(jù)改進(jìn)算法得到的每個(gè)網(wǎng)頁的Hub值和Authority值是可以信賴的。 從以“趙麗穎”為主題查詢得到的頁面中選取前8 個(gè)頁面,分別用A~H表示,各頁面之間的鏈接關(guān)系如圖1所示。利用PageRank、HITS及改進(jìn)PHIA算法計(jì)算各網(wǎng)頁的權(quán)值,結(jié)果列于表1~表3中。從表1和表2中可以看出,所選擇的 圖1 以“趙麗穎”為搜索主題的頁面鏈接關(guān)系 Fig.1Pagelinkrelationshipwith“ZhaoLiying”asthesearchtopic 表1 以“趙麗穎”為搜索主題的基于PageRank算法的計(jì)算結(jié)果(迭代次數(shù):15次) 表2 以“趙麗穎”為搜索主題的基于HITS算法的計(jì)算結(jié)果(迭代次數(shù):20次) 表3 以“趙麗穎”為搜索主題的基于PHIA算法的計(jì)算結(jié)果(迭代次數(shù):10次) 8個(gè)網(wǎng)頁中,PageRank值最高的頁面是H頁面,其次為F頁面和G頁面;最好的Authority頁面為F頁面和E頁面,最好的Hub頁面為D頁面,其次為E頁面和G頁面,同時(shí)有較高的Authority權(quán)值和Hub權(quán)值的頁面為E頁面、G頁面和H頁面。由表3所示改進(jìn)PHIA算法的計(jì)算結(jié)果可知,具有高Authority值的頁面為H頁面、F頁面和B頁面,有高Hub值的頁面為E頁面、D頁面和H頁面,同時(shí)具有高Authority值和Hub值的頁面為H頁面、E頁面和G頁面。 以“Web前端”為搜索主題進(jìn)行查詢,從返回結(jié)果網(wǎng)頁中選取8個(gè)頁面,分別標(biāo)號(hào)為1~8,其鏈接關(guān)系如圖2所示,3種算法計(jì)算得到各網(wǎng)頁的權(quán)值列于表4中。由表4可見,利用PageRank算法計(jì)算得到排序第一的是頁面4,其次為頁面1 和網(wǎng)頁7;HITS算法下,最好的Hub網(wǎng)頁為頁面8,次為頁面5和頁面6,最好的Authority頁面為頁面4,其次為頁面2;而改進(jìn)PHIA算法下,計(jì)算得到Hub值較高的頁面依次為頁面5、頁面8和頁面1,Authority值較高的頁面依次為頁面4和頁面2。 圖2 以“Web前端”為搜索主題的頁面鏈接關(guān)系 Fig.2Pagelinkrelationshipwith“Webfront-end”asthesearchtopic 根據(jù)上述實(shí)驗(yàn)結(jié)果可知,基于PageRank和HITS的改進(jìn)算法PHIA能夠更全面地找出所查詢關(guān)鍵詞的重要頁面;更重要的是,PHIA算法所需要的迭代次數(shù)為10次,少于PageRank算法(15次)和HITS算法(20次)所需的迭代次數(shù),計(jì)算量大大減少;根據(jù)對(duì)查詢結(jié)果進(jìn)行分析可知,頁面H和頁面E在內(nèi)容上與搜索主題“趙麗穎”關(guān)聯(lián)密切,頁面4的內(nèi)容與“Web前端”的關(guān)聯(lián)度也相對(duì)較高。另外,當(dāng)限制最大迭代次數(shù)時(shí),若迭代次數(shù)較少,PageRank算法得到的高PR值頁面是隨機(jī)出現(xiàn)的,即可能是8個(gè)頁面中的任一頁面;HITS算法一直指向的是同一個(gè)頁面,與迭代次數(shù)無關(guān);PHIA算法則能夠找到最好的Authority頁面和Hub頁面。可見,PHIA算法的精度要高于PageRank和HITS算法,不足之處是當(dāng)?shù)螖?shù)足夠多時(shí),HITS算法和PHIA算法精確度相差不大。 本文通過分析經(jīng)典的基于鏈接分析排序算法PageRank和HITS中存在的不足,提出了一種改進(jìn)算法PHIA。該算法繼承了HITS算法獲取根集和基本集的方式,并利用根集中各網(wǎng)頁的PageRank值作為Hub值和Authority值的初始迭代值,在一定程度上避免了“主題漂移”現(xiàn)象的發(fā)生;另外,PHIA算法放棄了HITS算法中Hub值和Authority值相互迭代的方式,而是通過求馬爾可夫矩陣來獲取網(wǎng)頁排名的靜態(tài)分布,以解決兩權(quán)值相互迭代過程中產(chǎn)生的增強(qiáng)值誤差。從針對(duì)兩個(gè)隨機(jī)關(guān)鍵詞的檢索結(jié)果來看,PHIA算法雖然在一定程度上削弱了主題漂移和Hub值和Authority值相互迭代導(dǎo)致的增強(qiáng)效果,并且收斂速度也有了一定的提高,但是PHIA算法仍然存在一些缺陷,有待進(jìn)一步改進(jìn):① PHIA算法只是在一定程度上削弱了“主題漂移”現(xiàn)象的產(chǎn)生,并不能完全避免;② 目前本系統(tǒng)只在本機(jī)中實(shí)驗(yàn),未考慮到人機(jī)交互、并發(fā)等問題,故還需在實(shí)際應(yīng)用中加以完善。1.2 HITS算法
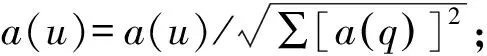
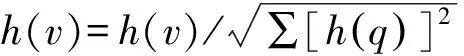
2 基于PageRank和HITS的改進(jìn)算法PHIA
3 實(shí)驗(yàn)結(jié)果及驗(yàn)證

4 結(jié)語
猜你喜歡
文萃報(bào)·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報(bào)·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
電腦愛好者(2022年3期)2022-05-30 10:48:04
工業(yè)設(shè)計(jì)(2016年1期)2016-05-04 03:58:09
通信技術(shù)(2012年4期)2012-02-15 07:10:35
電腦愛好者(2011年11期)2011-06-22 08:20:18
網(wǎng)絡(luò)安全技術(shù)與應(yīng)用(2011年3期)2011-03-14 06:44:46
赤峰學(xué)院學(xué)報(bào)·自然科學(xué)版(2010年11期)2010-09-21 11:30:50
河北軟件職業(yè)技術(shù)學(xué)院學(xué)報(bào)(2010年3期)2010-06-06 07:18:42
