基于公平性的打孔調度算法*
2019-03-05 08:56:24袁春經王鳳麗
通信技術 2019年2期
關鍵詞:用戶
夏 杰 , 袁春經 ,王鳳麗
(1.重慶郵電大學通信與信息工程學院,重慶 400065;2.移動計算與新型終端北京市重點實驗室,北京 100190)
0 引 言
第三代合作伙伴項目(3GPP)正在全力推進第五代通信技術(5G)的標準化。5G NR的雄心壯志旨在增強對多種服務的多路復用支持,如增強型移動寬帶(eMBB)、低延遲通信(LLC)以及超可靠性約束[1]。URLLC是指未來需要極其可靠和低延遲無線電傳輸的應用,即1 ms的單向無線電延遲與99.999%的成功概率[2-3]。也就是說,如果不能在1 ms延遲期限內成功解碼URLLC數據包,那么它就沒有用處。因此,支持這種嚴格的URLLC延遲規范能夠實現許多新的場景[4],包括智能電網、觸覺互聯網、無線工業控制和實時車輛間通信。文獻[5-7]對未來5G移動通信做了分析和拓展。文 獻[8]對采用不同的TTI長度對系統的性能影響進行了分析。近來,3GPP協議[9]提出了靈活框架,TTI的長度不再是固定的,而是靈活可變的。具體地,一個子幀可以根據不同的配比設置(可分為1、2、4、8、16、32個時隙個數),其包含的時隙個數也不同。5G框架結構的敏捷設計對于滿足URLLC延遲具有重要意義,用戶可以根據不同持續時間的傳輸間隔(TTIs)進行調度。例如,eMBB流量的TTI持續時間較長,以滿足其極端的頻譜效率(SE)需求,而URLLC流量的TTI持續時間較短,延遲 時間較短。
然而,盡管使用不同的TTI大小進行調度可以為用戶帶來好處,但存在一些不可忽視的問題需要進一步研究。例如,如何有效地多路復用eMBB和LLC下行共享信道,尤其是對eMBB流量主要以長TTI進行調度的場景,以及突發的零星LLC流量的到來必須立即采用短TTI進行調度以避免超過其規定的時延門限。在基站和小區內多個請求不同業務的用戶通信過程中,在EMBB數據傳輸時可能出現一個急需被傳輸的URLLC數據。如果等待EMBB數據完全傳輸完成再調度URLLC數據傳輸,可能無法滿足低時延、高可靠通信的需求。文獻[10]提出了預留資源的策略,但大大降低了系統的頻譜資源利用率。文獻[11]提出了一種用于高效傳輸低延遲通信(LLC)流量的打孔調度(PS)方案,在具有增強型移動寬帶流量(eMBB)的下行鏈路共享信道上復用,但提出的打孔策略對處于信道質量較差的eMBB用戶缺乏一定的公平性。為了提高系統中用戶之間的公平性和邊緣小區的吞吐量,本文提出一種基于公平性的打孔調度算法FPS(Fairness Punctured Scheduling)。
1 系統模型
本文采用文獻[9]中概述的5G NR框架,主要關注下行性能。用戶使用正交頻分多址(OFDMA)在一個共享信道上實現動態復用。本文設定子載波間隔為15 kHz。如圖1所示,eMBB流量按14個OFDM符號的長TTI調度,以最大化感知頻譜效率(SE)。同時,由于URLLC的延遲需求,因此按2個OFDM符號的短TTI調度。頻域中,最小可調度單元是PRB,每個PRB是12個15 kHz間距的子載波。用戶使用以用戶為中心的下行控制通道傳輸調度授權[12],以被基站動態調度。這些授權信息包括通知用戶使用哪些無線資源被調度、何種調制和編碼方式(MCS)以及異步混合自動重復請求(HARQ)信息。提出的系統盡力承載eMBB流量的下載和零星的、不定時到達的LLC流量。后者被建模為B比特的有效載荷大小的突發,下行鏈路上每個LLC用戶服從到達速率為λ的均勻泊松過程。因此,每個小區提供的LLC業務負載等于NBλ,其中N是每個小區的LLC用戶的平均數。

圖1 靈活5G系統模型和幀結構
2 打孔原理
在eMBB傳輸信道上進行打孔的原理,如 圖2所示。基站(gNB)在下行共享無線信道上使用長TTI(1 ms)為eMBB流量用戶進行調度。對于eMBB用戶傳輸塊,傳輸期間用于傳輸的共享無線信道是獨占的。然而,可能發生當一個LLC用戶到達時,基站正在調度另外的eMBB用戶。為了避免需要等到eMBB用戶傳輸塊的傳輸完成,采用正在對eMBB用戶傳輸的一部分數據進行打孔來立即調度LLC用戶的數據。該解決方案的優勢在于LLC用戶的數據延遲被最小化,代價是犧牲了eMBB用戶的性能。由于eMBB傳輸的一些資源已損壞,它基本上導致了一個錯誤下限,其中塊錯誤概率(BLEP)與UE的SINR的性能已經飽和[13]。打孔對于eMBB用戶的性能影響取決于多個因素:已經被打孔了多少資源、eMBB用戶是否知道被打孔以及如何將eMBB傳輸塊(TB)的信息比特編碼、交織并映射到物理層資源[13]。eMBB傳輸由代碼塊(CB)組成。對于LTE[14],最大CB大小等于Z=6 144 bit,且CB的數量由C表示。為了簡單,CB在TB的分配資源上具有相同的大小和完全時頻交織。應注意,圖2中的圖示在某種意義上是簡單的,即eMBB傳輸(在該示例中)僅通過一個LLC傳輸,經歷一個時域打孔的實例。然而,在加載的多用戶蜂窩系統中,eMBB傳輸實際上可能經歷多個LLC傳 輸的穿孔。
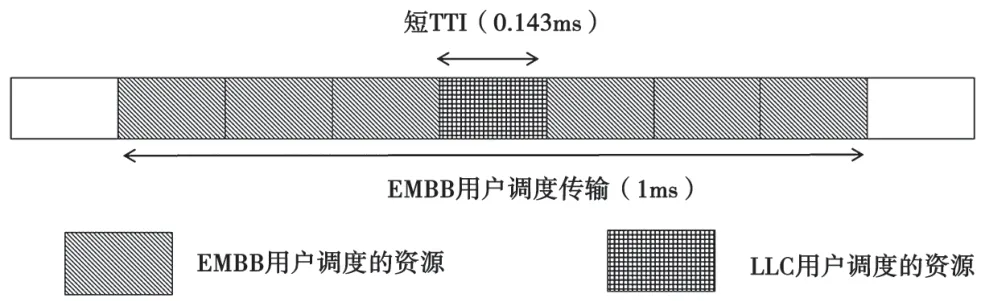
圖2 下行打孔的原理
3 打孔調度(PS)算法分析和改進
3.1 打孔調度(PS)算法分析
對于eMBB用戶調度的TTI大小為1 ms,且等待的eMBB HARQ重傳優先于新的eMBB傳輸。當LLC業務到達gNB時,調度器旨在立即調度具有0.143 ms的短TTI大小(對應于2個OFDM符號)的這種業務。文獻[11]中提出的打孔調度(PS)算法如下:

其中rv,p(t)是用戶V在第p塊PRB上的瞬時支持速率的估計,Rv(t)是過去的平均傳輸吞吐量,Wp是當前用戶V在第p塊PRB上的傳輸塊大小(對應于MCS值)。從式(1)可以看出,對于處于信道質量差或者邊緣小區的eMBB用戶,其Wp值小,則大;而對于處于信道質量差的用戶其Rv(t)較低,即相對應值的升高,使得其被打孔的優先級提高。因此,會出現打孔不斷發生在信道質量差的eMBB用戶上,造成其不斷重傳,引起Rv(t)值的下降而造成其優先級不斷增大而再次被打孔,從而造成用戶間的不公平性。
3.2 公平性改進的打孔調度算法(FPS)
本文提出一種基于公平性的打孔調度算法FPS(Fairness Punctured Scheduling)。具體地,引入調度eMBB用戶的平均打孔次數和每個用戶的打孔次數的比值作為加權因子,以提升信道質量差的用戶的吞吐量,提高用戶之間的公平性。
為了計算每個用戶的打孔次數,基站側為每個用戶設置相應的計數器。Cv(t)是t時第v個用戶一定時間內被打孔的次數,是N個eMBB用戶的平均被打孔次數,即:

基于公平性的打孔調度(FPS)算法為:
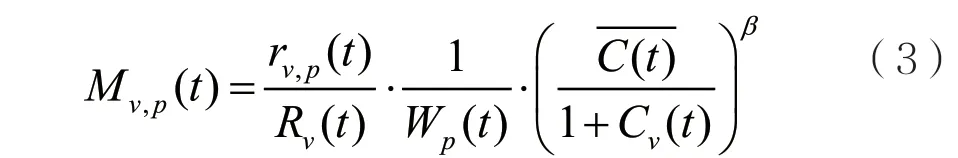
其中Wp是當前用戶v在第p塊PRB上的傳輸塊大小,Cv(t)代表過去一段時間用戶v共被打孔的個數,β為可調節因子,這里將β設為數值2。隨著用戶v被打孔個數Cv(t)的增加,值變小,其再次被選中進行數據打孔的優先級降低。對于隨著信道質量差的eMBB用戶打孔次數的減少,重傳次數也就相應減少,提高了其吞吐量,在一定程度上保證了用戶之間的公平性。
4 仿真及分結果析
4.1 仿真配置
假設宏蜂窩多小區場景,遵循3GPP[9]中的5G NR進行廣泛的動態系統級仿真。對于eMBB用戶使用full buffer模型,對于LLC用戶在泊松到達過程后生成30 B大小的數據包。如表1所示,總結了仿真參數設置。

表1 仿真參數設置
4.2 性能分析
為了比較FPS算法與PS算法的性能,假設小區內的eMBB用戶服從均勻分布,且都靜止不移動,分別研究了FPS和PS算法的吞吐量和公平性。
4.2.1 公平性比較
本文采用Jain公平算法機制對PS和改進的FSP兩種打孔算法的公平性進行比較,Jain公平算法機制被表示為:

式中,xn是第n個eMBB用戶的平均吞吐量,J值代表著用戶之間的公平性。J值越大,代表用戶間公平性越好。
如圖3所示,FPS算法下eMBB用戶間公平性明顯大于PS算法的公平性,且其差距伴隨著小區LLC用戶數量的增加而擴大。PS算法由于選擇信道質量差的eMBB用戶進行穿孔,隨著質量差的用戶數據不斷被打孔而導致其數據包不斷重傳,從而導致其在一段時間內的吞吐量極低。吞吐量的下降對應式(2)中Rv(t)的減少,也就提高了其再次被選中打孔的優先級,導致其吞吐量更低,公平性顯著下降。FPS算法中由于引入了加權因子,使得信道質量差的eMBB用戶在過去一段時間內隨著打孔次數的增加,降低了期再次被打孔的優先級,從而提高了用戶間的公平性。

圖3 不同LLC用戶數時PS算法和FPS 算法公平性比較
4.2.2 吞吐量比較
從圖4可以看出,FPS算法下的小區總吞吐量比PS算法低約4 Mb/s。這是因為本文提出的FPS算法中引入了加權因子,使信道條件略差的用戶比在PS算法下減少了對其進行數據打孔的優先級,一定程度上減少了對信道質量差的用戶進行打孔而造成一直重傳的情況,提升了信道質量差的eMBB用戶的吞吐量。而距離小區中心較近的用戶,由于其被打孔的次數較少,因此被LLC用戶選中打孔的優先級得到相應提升。處于小區中心信道質量很好的eMBB用戶被選中打孔,導致本來傳輸速率很高的用戶數據被迫重傳,系統整體吞吐量下降,即犧牲系統的總體吞吐量換取eMBB用戶間的公平性。相對于PS算法,小區邊緣用戶被打孔的優先級被降低,數據包重傳的次數降低,所以FPS算法下邊緣用戶的整體吞吐量得到提升。

圖4 PS算法和FPS算法的小區吞吐量對比
5 結 語
在未來5G移動網絡中,如何對低延遲通信(LLC)業務和增強型移動寬帶(eMBB)業務進行調度成為研究的重點。為了更好地保證eMBB業務用戶之間的公平性,提出了公平性打孔調度算法(FPS)算法,即在原有的打孔調度算法(PS)基礎上引入加權因子,提高用戶間公平性和邊緣小區吞吐量。系統仿真結果表明,FPS較PS算法有著良好的用戶公平性和邊緣小區吞吐量,驗證了算法的有效性。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
