一種基于代數規(guī)約的面向服務集成方法?
2019-03-01 02:52:10劉冬梅何娟娟
計算機與數字工程 2019年1期
蘭 斌 劉冬梅 陳 穎 何娟娟
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
面向服務計算(Service-oriented Computing,SOC)是一種新興的分布式計算范型,它使用面向服務架構(Service-oriented Architecture,SOA),通過整合服務來構建軟件解決方案[1]。SOA支持更加快速地開發(fā)業(yè)務流程以及更加輕松地對業(yè)務流程進行改變,可以使組織更迅速地適應他們業(yè)務環(huán)境的改變。Web服務憑借其平臺無關、軟件模塊松耦合性、異構平臺互通性和高重用性等特征成為了SOA實現的首要選擇。
受到面向服務趨勢的影響,許多現有的非面向服務軟件系統為了更靈活、更快地響應不斷改變的消費者需求,將進行面向服務的重新設計和集成。目前對Web服務已經有了比較充分的研究,對服務接口模型的設計以及服務組合的建模研究,成果豐碩[2~3]。但在面向服務集成的靈活性上還存在一些問題,一方面以逆向工程技術為主的白盒方法從現有代碼中恢復業(yè)務邏輯,再根據業(yè)務邏輯開發(fā)全新的Web服務。雖然提高了依賴源代碼的事務處理效率,但業(yè)務邏輯恢復難以保證完整性,同時通過源代碼侵入系統容易影響系統的穩(wěn)定性。另一方面以形式化技術為主的黑盒方法通過適配器來傳輸請求數據和應用程序響應數據。雖然避免了侵入系統內部,但通用性和響應變更的及時性方面都不夠理想。因此,面向服務集成仍是當前研究的熱門課題。
本文分析服務集成的白盒與黑盒方法,提出一種基于代數規(guī)約的灰盒方法。首先在系統的形式化描述的基礎上,結合數據流分析提取系統的核心業(yè)務邏輯,其次將改進的聚類分析算法應用于服務鑒別,然后設計和開發(fā)新的功能組件來實現服務功能,最后通過實際的應用案例和實驗分析驗證了本文方法的有效性。
2 相關工作
現有的研究中,面向服務集成的方法主要分為黑盒方法和白盒方法兩大類[4]。
黑盒方法是通過適配器來傳輸請求數據和應用程序響應數據,解決了系統和集成環(huán)境接口不匹配的問題從而實現系統面向服務集成[5~6]。Mehta等通過一個細粒度的組件模型明確定義應用程序界面,以遞增的方式實現面向服務集成[9]。Canfora等通過屏幕抓取技術動態(tài)分析用戶交互行為,收集系統返回的屏幕序列和交換的消息并分類包裝在SOA接口中作為Web服務來被訪問[7]。Li等提出了一種基于有窮狀態(tài)自動機描述的黑盒系統的服務集成方案[8],給出了包裝方案的參考模型,并對模型內的主要包裝組件的功能進行了描述。在理想情況下,這種集成方法僅分析應用程序界面,忽略系統的內部構件。但是由于系統的多樣性和消費者需求的不斷變化,這種方法在通用性和響應需求變更的及時性方面都存在問題。在許多情況下,借助白盒現代化工具研究待集成系統的內部結構是很重要的。
白盒方法通過逆向工程技術從現有代碼中恢復業(yè)務邏輯,然后根據業(yè)務邏輯開發(fā)全新的Web服務[10]。Chen等使用特征分析來實現面向服務的集成[12],特征分析包括識別系統特征、構建特征模型,以及通過特征定位技術在待集成系統中定位特征的實現。Li Xiang等針對Java語言的面向對象系統構造了一種描述軟件行為和依賴關系的圖模型,并在此基礎上給出了面向服務的系統分解算法[11]。Alahmari等從服務粒度出發(fā),定義7種不同粒度的服務原模型。通過描述業(yè)務程序的業(yè)務邏輯和對實體的CRUD操作,結合原模型來定位候選服務的粒度和數量[13~14]。這種集成方法簡化了系統,節(jié)省了維護費用,并提高了依賴源代碼的事務處理效率。但是這種方法很難完美地恢復業(yè)務邏輯,通過源代碼侵入系統后系統的穩(wěn)定性也存在問題。
Zhang等綜合前兩種方法提出了灰盒的集成方法[17],將面向對象程序中的函數、過程和類定義為要聚類的實體,根據標識符名稱來定義特征,采用更加強調功能的分層聚類方法提取服務。后續(xù)又提出高層次的形式概念分析和低層次的程序切片分析組合實現服務提取[16],形式概念分析捕獲可重復使用的代碼段、基于符號有向圖的切分算法剔除無用代碼并調整實現實體的松耦合組件化。該方法雖然能夠準確地定位功能代碼塊,但后續(xù)的服務提取操作仍對系統有一定的入侵性,很難保證不會對系統的穩(wěn)定性造成影響。
在已有的研究中,形式化方法憑借其準確、規(guī)范的描述和驗證軟件系統行為和性能的優(yōu)勢被廣泛地采用。由于代數規(guī)約高度抽象、完全獨立于實現細節(jié),很適合對系統進行抽象描述。本文以系統的代數規(guī)約描述為基礎,將描述類的類子模型定義成聚類的實體,根據類和業(yè)務邏輯的關聯定義特征,采用改進的聚類分析算法提取服務,最后基于業(yè)務邏輯設計和開發(fā)實現服務功能的新組件。與之前的研究相比,本文提出的方法更少對系統進行入侵,保證穩(wěn)定性的同時具有更高的靈活性。
3 基于代數規(guī)約的面向服務集成
基于代數規(guī)約的面向服務集成主要分為三個步驟:“自底向上”的代數規(guī)約描述類結合“自頂向下”的邏輯分析用于系統的理解與分析、聚類分析方法用于服務的鑒別、服務封裝技術用于服務的封裝,最后將非面向服務系統集成到SOA中作為Web服務并驗證服務功能。
3.1 系統的理解與分析
在面向服務環(huán)境下,服務集成是面向數據和功能的,因此系統的理解與分析主要分為面向數據的“自底向上”類描述和面向功能的“自頂向下”邏輯分析,如圖1。

圖1 面向服務集成系統理解圖
3.1.1 “自底向上”的類描述
本文采用代數規(guī)約語言SOFIA對系統進行語義描述,稱之為系統的類子模型。SOFIA是Liu等在大量案例研究的基礎上提出的面向服務軟件的代數規(guī)約語言[20],它由若干個規(guī)約單元構成,每個規(guī)約單元描述一個類子Sort。
定義1(類子模型)三元組
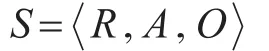
R(Relation)表 示 類 之 間 的 關 系 ,R=Si,Sj,r ,Si,Sj表示第i、j個類,r表示兩個類間具體的關系,包括extends關系和uses關系。
A(Attribute)表示類的成員變量,包過類變量和實例變量。
O(Operation)表示類的函數,包過除構造函數及成員變量get/set函數之外的所有成員函數。
以第4節(jié)中MTAC類描述中的FunctionExpression類子模型為例,其主要的SOFIA語言規(guī)約如下:
Spec FunctionExpression;
extends Expression;
uses String,Function,Expression,Namespace,Bool,
VariableExpression,Integer,Vector;
Attr
name:String;
function:Function;
args:Expression;
Operation
simplify(Namespace,Bool):Expression;
differentiate(Namespace,VariableExpression):Expression;
toString(Integer):String;
prettyPrint(String,Integer,Integer):PrettyPrintBox;
getAllVariables(Vector):void;
equals(Object):Bool;
hashCode():Integer;
End
為了更好地區(qū)分類子模型間的關系,我們將uses關系分為Attribute-uses關系和Operation-uses關系。以FunctionExpression類子模型為例,它與Expression呈extends關系;與Function和Variable-Expression分別呈Attribute-uses關系和Operation-uses關系。
通過對源代碼數據流分析得到系統核心流程圖。核心流程圖由數據、過程和決策組成,是系統核心功能流程的體現。數據是過程的輸入輸出,過程是系統功能實現的基本組成部分,決策是數據分流的依據。
結合核心流程圖對類子模型進行精簡。剔除與核心流程圖中數據、過程和決策無關的類。這些類是面向對象系統常用的如用戶界面、彈窗提示等功能的實現類,在服務鑒別過程中不需要用到這些類。此操作不對源代碼做任何的修改,只是從類子模型中剔除這些無關類,降低類子模型的復雜度,從而加快后續(xù)處理的速度。
3.1.2 “自頂向下”的邏輯分析
計算系統核心流程圖中除去循環(huán)決策之后的圈復雜度,根據流程圖的圈復雜度確定基本路徑,基本路徑集合表示為P={p1,p2,…,pk},其中 pk表示第k條基本路徑。
通過閱讀已有的系統開發(fā)文檔、人工操作、用戶評價等方式理解系統核心功能,結合核心流程圖中的基本路徑設計相應的操作用例驗證核心功能的正確性并分析得出系統的業(yè)務邏輯,業(yè)務邏輯集合表示為L={ }bl1,bl2,…,blk,其中blk表示第k個業(yè)務邏輯。
3.2 服務鑒別
聚類技術已經在許多學科中廣泛應用多年。聚類分析是根據數據集的大小關系和相似度,將數據集中的實體組合成群集。應用聚類分析前,需要定義聚類實體集、兩個實體之間的相似度和一個聚類算法。應用聚類分析后,需要對結果進行評估和解釋[18]。本文在系統理解與分析的基礎上改進聚類算法用于服務鑒別。
3.2.1 改進的聚類分析算法
從系統核心流程圖來看,每個核心流程實際上是過程調用數據來完成特定的系統部分業(yè)務邏輯。業(yè)務邏輯是對業(yè)務實體及相關業(yè)務規(guī)則的封裝,可以通過類子模型來描述。因此,本文在提取業(yè)務邏輯的時候選用的X樣本點集合是以類子模型為基礎,以類子模型間依賴關系的強度作為關聯值。本文定義“關鍵類子模型”與“非關鍵類子模型”,作為關聯值矩陣的行和列,進行關聯值計算。
關鍵類子模型,是指從核心流程圖中挑選出核心的、關鍵的類子模型,挑選的原則是分清業(yè)務相關類子模型的主次關系。我們依據核心流程圖中業(yè)務邏輯相關過程來確定關鍵類子模型,如果某類子模型涉及到的過程權重較大,即該類子模型用于實現核心的功能業(yè)務,則將其作為“關鍵類子模型”的候選者。除去關鍵類子模型之外的其他類子模型稱為非關鍵類子模型。改進算法如下:
輸入:代數規(guī)約語言SOFIA描述的類子模型
輸出:作為服務的類子模型集合
算法過程:
1)劃分m個“關鍵類子模型”的樣本點記為X={Xi}(i=1,2,…m);劃分n個“非關鍵類子模型”的樣本點記為X={Xj}(j=1,2,…n);
2)求任意兩個樣本點的過程關聯值Pij和業(yè)務邏輯關聯值Lij;
3)計算m+n個樣本點的關聯值Vij,得到以 Xi為行,Xj為列的關聯值矩陣D;
另一類研究則是以溫特為代表的建構主義理論。溫特將文化定義為“社會共有知識”,包括微觀結構中的共同知識和宏觀結構中的集體知識。他認為,大部分國家所處的重要結構是由觀念而不是物質力量構成的。國際生活的特征取決于國家與國家之間相互存有的信念和期望,即霍布斯、洛克、康德三種文化哪一種占主導地位。它們分別基于三種角色關系,即:敵人、競爭對手、朋友。而共有觀念形成后則會塑造國家的身份,進而影響其利益與行為。[9]
4)設定閾值Vmin;
5)ifVij≥Vmin,thenXiXj放 入 一 個 聚 集(∈collect i);
6)ifXiXk∈collect iandXkXj∈collect i,then XiXkXj∈ collect i;
7)將collect i轉化為作為服務的類子模型集合。
對于某些特殊情況:1)如果類子模型對應的所有關聯值都小于Vmin,那么有必要根據這些類子模型對應的業(yè)務功能,將這些非關鍵類子模型單獨作為一個服務的類子模型集合或者舍去不予考慮;2)如果某個非關鍵類子模型Xj與多個關鍵類子模型Xi(i=1,2,…,m)的關聯值都相等,且都大于Vmin,則需比較所有Vij(i=1,2,…,m)的大小,然后將Xj分配給Vij值最大的那個關鍵類子模型。
3.2.2 確定關聯值

由于業(yè)務邏輯和類子模型不是孤立存在的事物,它們通過相互作用以完成系統特定的功能需求。綜合考慮以上因素,本文提出關聯值計算公式:其中Ip和Il分別代表Pij和Lij的權重系數,根據兩者在具體系統的相對重要性來確定數值。Pij表示過程關聯值,Lij表示業(yè)務邏輯關聯值,關聯值Vij為兩者加權和。
類子模型間的過程關聯主要通過類子模型關系來表示,因此,我們需要依據類子模型來計算類間的過程關聯值。3.1.1介紹了類子模型間的關系,本文設定extends關系為類子模型間最緊密的關系,其過程關聯值為3;uses關系中的Attribute-uses關系為次緊密關系,其過程關聯值為2;uses關系中的Operation-uses關系為微緊密關系,其過程關聯值為1;除以上三種關系之外的皆為稀疏關系,過程關聯值為0。
除了需要確定類子模型間的過程關聯值以外,還需要結合系統核心流程圖和業(yè)務邏輯來計算類子模型間的業(yè)務邏輯關聯值。業(yè)務邏輯關聯值的計算公式如下:
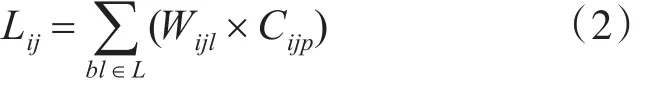
我們以關鍵類子模型和非關鍵類子模型作為矩陣的行和列,分別計算其過程關聯值表Pij和業(yè)務邏輯關聯值Lij,得到過程關聯值矩陣和業(yè)務邏輯關聯值矩陣,最后,由關聯值計算公式Vij=Ip×Pij+Il×Lij計算得到關聯值矩陣D。由于在業(yè)務邏輯關聯值的計算中往往一個業(yè)務邏輯涉及多個類子模型,我們設定閾值公式:
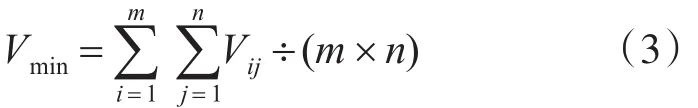
3.3 服務封裝
從本質上說,封裝就是將非面向服務系統中的業(yè)務邏輯包裝成Web服務,使這些Web服務能對外提供服務[15]。封裝者可以直接調用系統的事務處理程序,接收返回的結果再傳給Web服務的消費者,為此封裝者要知道系統中事務所能完成的工作以及輸入輸出參數。服務的封裝包括以下步驟:
1)新功能組件的開發(fā)
識別后的服務需要經過封裝形成Web服務。考慮到系統的穩(wěn)定性,開發(fā)實現了服務的功能的新功能組件來作為SOA和系統底層實現的中間層結構,實現松耦合組件化的同時保證了系統的穩(wěn)定性。按照自底向上的原則,先實現簡單服務的功能組件,然后根據組合服務的調用關系在簡單服務功能組件的基礎上組合開發(fā)實現組合服務功能。
2)服務接口的開發(fā)
服務接口開發(fā)主要分為消息類型的定義和服務的描述。根據新功能組件的輸入輸出類型定義服務對應的輸入輸出消息類型。通過Web服務描述語言(WSDL)對服務功能、服務可以支持的操作,以及每個操作接受和返回的參數進行描述。
3)消息的傳輸
因為服務是面向消息的,因此傳輸機制對于服務是必需的。SOAP使用基于XML的數據結構和超文本傳輸協議(HTTP)的組合定義了一個標準的方法來使用Internet上各種不同操作環(huán)境中的分布式對象。因此要實現Web服務需集成SOAP處理器以支持消息在Web上的傳輸。
4 應用實例:MTAC
本文選取開源軟件MTAC(More than a Calculator)進行服務集成。MTAC是一個功能強大、小而易用的數學計算工具軟件,它具有計算、求導和函數圖像繪制等功能。它的很多功能都能作為Web服務集成在面向服務環(huán)境中。
經過初步的類子模型描述得知MTAC由72個類、5869行代碼組成。其中抽象類個數為3、總方法數為293、總屬性數為168。如表1所示。
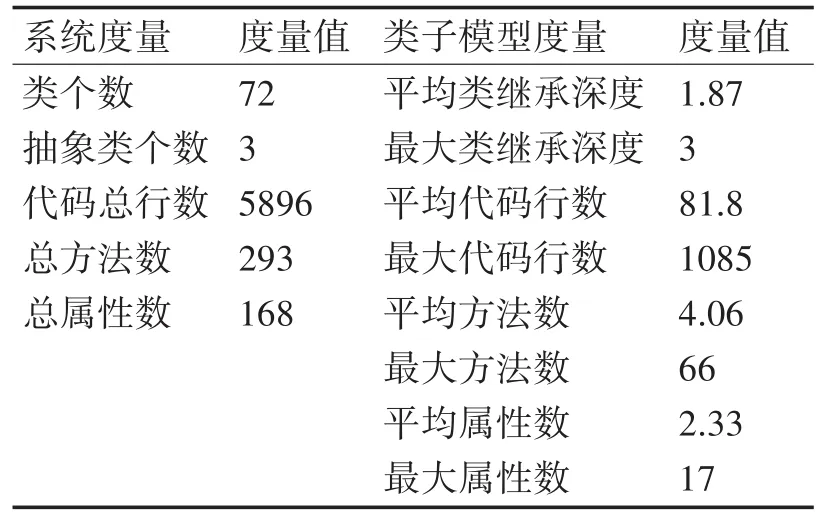
表1 MTAC類子模型度量
通過對源代碼進行數據流分析得到系統核心流程圖,如圖2所示。由圖可知,MTAC核心過程分為表達式解析、數字運算、功能運算和求導運算;核心數據為表達式;核心決策為表達式類型決策、變量個數決策、求導決策和計算完成決策。根據3.1.1節(jié)類子模型精簡原則,我們剔除了8個系統主界面類子模型、12個功能界面類子模型、8個異常類子模型、3個靜態(tài)內部類子模型和1個主程序入口類子模型。精簡后的類子模型規(guī)模大小為40,包含兩個抽象類。
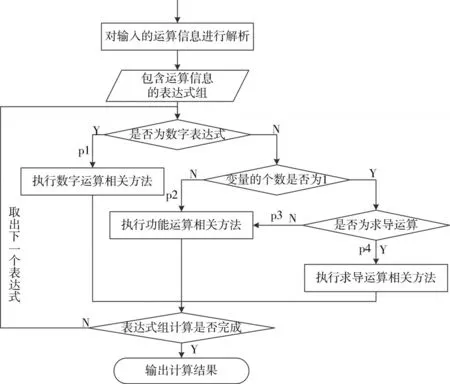
圖2 MTAC核心流程圖
從系統核心流程圖中除去循環(huán)決策之后的圈復雜度為4,因此可以確定基本路徑有4條,圖2中以 pi(i=1,2,3,4)表示4條基本路徑。
通過閱讀程序說明文檔和人工對程序進行操作等面向功能的“自頂向下”的邏輯分析,結合核心流程圖中的基本路徑得出以下4個業(yè)務邏輯:
1)純數字的數字表達式運算業(yè)務邏輯bl1;
2)單個變量的求導運算業(yè)務邏輯bl2;
3)多個變量的功能表達式運算業(yè)務邏輯;
4)單個變量的功能表達式運算業(yè)務邏輯。
其中3)、4)業(yè)務邏輯涉及的類子模型是相同的,因此我們將3)、4)合并成一個業(yè)務邏輯:
變量的功能表達式運算業(yè)務邏輯bl3
為了清晰可見,本文實驗過程中將Function的25個子類按照功能特性合并成3個類子模型用作聚類分析,分別以Function1(S16)、Function2(S17)和Function3(S18)表示。MTAC參與聚類分析的類子模型和類的對應關系如表2所示。
表2 MTAC類子模型度量
按照3.2.1關鍵類子模型的挑選原則選取“關鍵類子模型”,結果用集合{Si}(i=4,5,9,12)表示;其余類子模型為“非關鍵類子模型”,結果用集合{Sj}( j=1,2,3,6,7,8,10,11,13,14,15,16,17,18)表示。
根據本文3.2.2節(jié)過程關聯值設定規(guī)則,分析關鍵類子模型和非關鍵類子模型之間的關系,得到過程關聯值矩陣1。
矩陣1過程關聯值矩陣

下面求類子模型之間的業(yè)務邏輯關聯值,由上文業(yè)務邏輯的分析過程我們得知,純數字的數字表達式運算業(yè)務邏輯bl1涉及的類子模型有S4、S5、S7、S8、S11、S15,其中對 S5、S8、S11、S15會進行多次調用,所以對應矩陣值為2;單個變量的求導運算bl2涉及的類子模型有 S2、S4、S5、S8、S9、S10、S11、S12、S13、S16,其中 S5、S9、S10、S11、S12、S13、C16需調用多次,所以對應矩陣值為2;變量的功能表達式運算業(yè)務邏輯bl3涉及的類子模型有 S2、S4、S5、S9、S10、S11、S16、S17,其中S2、S9、S10、S11、S17進行多次調用,同理他們的矩陣值為2。建立0-1包含矩陣(如果某業(yè)務邏輯涉及到類子模型 Si,就將 Si的矩陣值記為 1,否則記為 0),另外考慮類子模型的調用次數,單次調用為1,多次調用為2。
繼續(xù)考慮每個業(yè)務邏輯 bli所占的權重,本文通過每個業(yè)務邏輯關聯的功能個數來定義Wi,比如變量的功能表達式運算W3=13/25=0.52,同理Wi={1,0.24,0.52}(i=1,2,3),將這些權值乘以0-1包含矩陣得到業(yè)務邏輯關聯矩陣,如矩陣2所示。
矩陣2業(yè)務邏輯關聯矩陣

對照矩陣2,根據式(2)計算出關鍵類子模型和非關鍵類子模型的業(yè)務邏輯關聯值Lij,結果如矩陣3所示。根據式(1)計算關聯值,取 Ip=0.4,Ip=0.6,綜合矩陣1和矩陣3,得到關聯值矩陣4。
矩陣3業(yè)務邏輯關聯值矩陣
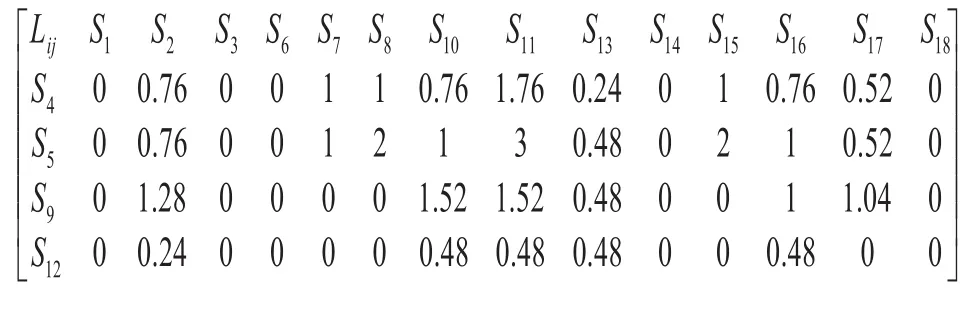
矩陣4關聯值矩陣

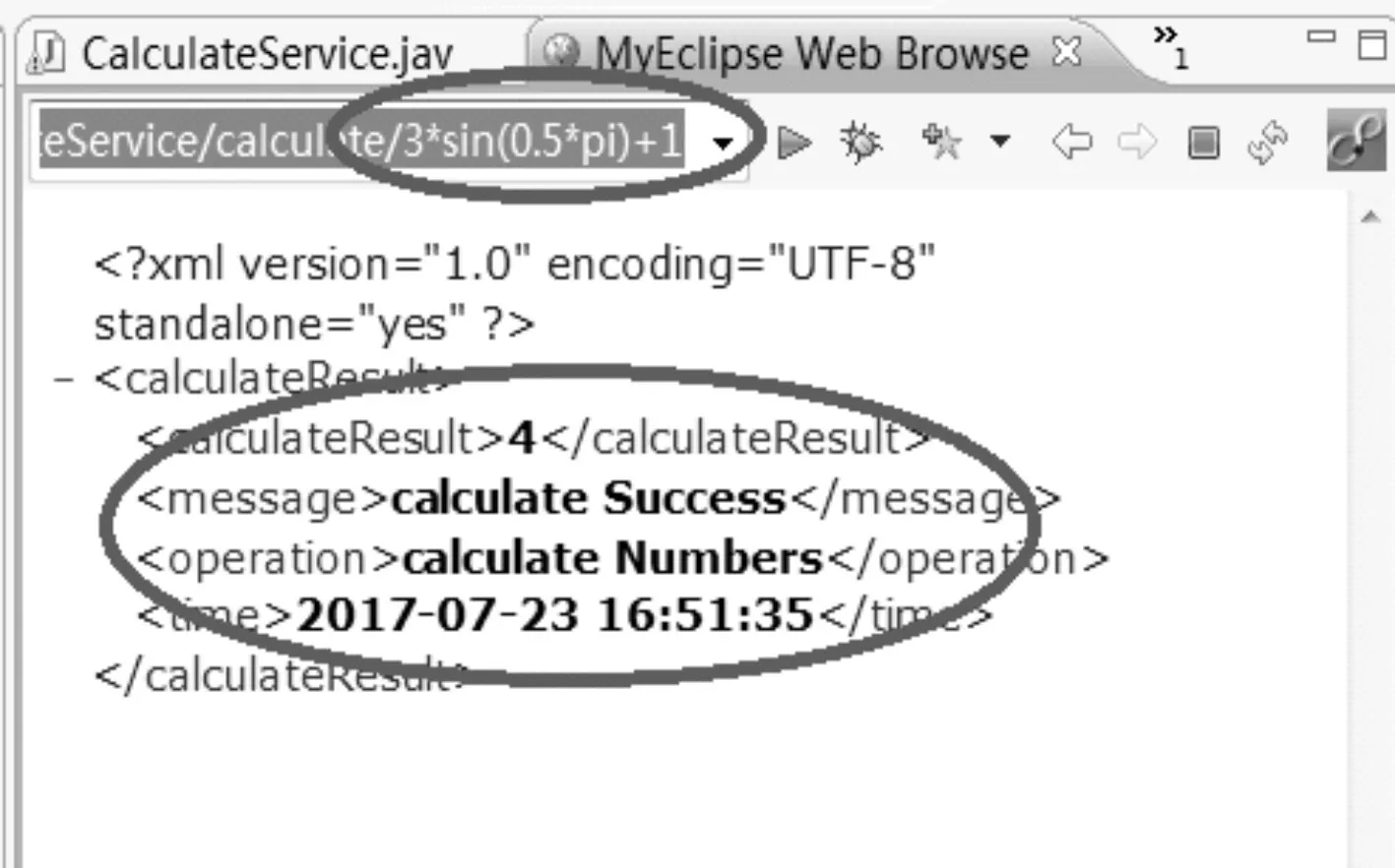
根據式(3)可以計算出閾值Vmin=0.499。結果顯示,兩個關鍵類子模型S4和S9聚合了類子模型S2,但是 V42=0.856 實驗結果表明,從MTAC系統中可以提取以下粗粒度、松耦合的服務:表達式解析服務;算術表達式計算服務;功能表達式計算服務;表達式求導服務。由于業(yè)務邏輯是用戶需求功能的體現,所以在服務提供時需要將服務進行組合以實現相應的業(yè)務邏輯,最后以組合服務的形式體現給用戶使用:表達式解析服務+算術表達式計算服務實現純數字的數字表達式運算業(yè)務邏輯、表達式解析服務+功能表達式計算服務實現變量的功能表達式運算業(yè)務邏輯、表達式解析服務+表達式求導服務實現單個變量的求導運算業(yè)務邏輯。 圖3 MTAC Web服務的WSDL描述文檔 最后,利用服務封裝技術對服務進行封裝。在MyEclipse中創(chuàng)建了一個簡單的Web服務和Web服務客戶端,開發(fā)與服務對應的功能組件和接口,并使用Apache Tomcat和REST框架的自下而上策略進行部署。圖3顯示了WSDL中的MTAC Web服務的接口描述。圖4顯示了從Web服務客戶端測試生成的MTAC Web服務時的屏幕截圖。 圖4 測試生成的Web服務 本文通過分析當前面向服務集成方法的局限性,從業(yè)務邏輯和形式化描述系統出發(fā),結合聚類技術和服務封裝技術提出了一種基于代數規(guī)約的面向服務集成的灰盒方法。這種方法提供了更高的適應性,能更好地理解系統,使得維護變得更加簡單。通過實際的應用案例MTAC及其實驗分析驗證了本文方法的有效性。本文的工作還有待進一步完善。首先,人工的參與和決策在規(guī)模較大的系統中難以保證準確性和完整性。其次,對集成后系統的功能驗證還僅局限于實驗參與人員的手動測試。在未來的研究中,將從服務鑒別自動化和服務驗證兩方面對本文的方法進行優(yōu)化和改進。一方面優(yōu)化聚類算法,提供一套可用于鑒別不同類型業(yè)務邏輯的度量準則,實現非面向服務系統中服務的自動化鑒別。另一方面結合代數規(guī)約語言SOFIA在Web服務自動化測試的研究成果[18~19],對服務進行驗證。
5 結語
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
當代陜西(2021年17期)2021-11-06 03:21:36
今日農業(yè)(2019年12期)2019-08-15 00:56:32
今日農業(yè)(2019年10期)2019-01-04 04:28:15
今日農業(yè)(2019年16期)2019-01-03 11:39:20
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
商周刊(2017年9期)2017-08-22 02:57:56
中國科技論壇(2017年7期)2017-07-25 08:49:53
讀者(2017年5期)2017-02-15 18:04:18
中國中醫(yī)藥現代遠程教育(2014年22期)2014-03-01 04:32:55
