基于相似度融合算法的主觀題自動(dòng)閱卷機(jī)制
2019-02-23 05:25:32李紀(jì)扣韓建宇
天津科技大學(xué)學(xué)報(bào) 2019年1期
李紀(jì)扣,韓建宇,王 嫄
(天津科技大學(xué)計(jì)算機(jī)科學(xué)與信息工程學(xué)院,天津 300457)
主觀題目閱卷自動(dòng)化是目前機(jī)考領(lǐng)域的前沿課題之一.主觀題目答案中不同種語(yǔ)言、字符、語(yǔ)言模式差異所導(dǎo)致相似度計(jì)算中的復(fù)雜性和準(zhǔn)確性問(wèn)題是研究的重點(diǎn)方向[1].文本結(jié)構(gòu)差異、語(yǔ)義的不一致導(dǎo)致了相似度刻畫(huà)的多樣性,而且語(yǔ)義依存樹(shù)下的相似度、基于知網(wǎng)的語(yǔ)義相似度等算法均對(duì)應(yīng)用環(huán)境有較嚴(yán)格的要求[2].基于語(yǔ)義依存樹(shù)的相似度計(jì)算方法要先將語(yǔ)句的主干語(yǔ)義信息抽取成為語(yǔ)義表達(dá)式,再通過(guò)計(jì)算該語(yǔ)義表達(dá)式的相似度用以代替語(yǔ)句的相似度[3–4];基于知網(wǎng)的相似度計(jì)算通過(guò)維護(hù)一個(gè)大規(guī)模語(yǔ)料庫(kù)來(lái)得到文本的相似度[5].通過(guò)挖掘獨(dú)立詞對(duì)(word to word)之間潛在語(yǔ)義關(guān)系的方法的必要條件是能夠在語(yǔ)料庫(kù)中找到詞對(duì)的最優(yōu)搭配[6–7].這些方法均從語(yǔ)言學(xué)角度去分析語(yǔ)法特征,從語(yǔ)法上解決相似度問(wèn)題.而對(duì)于理工科教學(xué)中題目答案的正確性判定,答案文本的關(guān)鍵詞特征比其語(yǔ)法特征具有更高的重要度,并且基于關(guān)鍵詞特征的相似度計(jì)算不需要大量的語(yǔ)法分析,能夠降低相似度計(jì)算的復(fù)雜度[8].在這種以文本結(jié)構(gòu)作為切入點(diǎn)的模式下,有人提出了一種基于人工指定參數(shù)的相似度計(jì)算方法,該方法將關(guān)鍵詞特征通過(guò)人為指定參數(shù)的方式組合得到文本的綜合相似度[9].以上的分析研究表明,對(duì)文本結(jié)構(gòu)特征進(jìn)行計(jì)算能夠得到文本相似度,但計(jì)算過(guò)程中很少考慮語(yǔ)序特征.
針對(duì)特定背景下的主觀題目自動(dòng)閱卷,本文提出了一種基于相似度融合算法的相似度模型,在關(guān)鍵詞匹配的基礎(chǔ)上根據(jù)相對(duì)距離計(jì)算語(yǔ)序相似度,進(jìn)而用統(tǒng)計(jì)回歸分析方法對(duì)關(guān)鍵詞相似度與詞序相似度特征進(jìn)行融合,得到文本的綜合相似度,從而實(shí)現(xiàn)基于文本結(jié)構(gòu)特征的主觀題自動(dòng)閱卷.
1 主觀題目閱卷原理
主觀題目閱卷采用基于文本結(jié)構(gòu)的相似度模型實(shí)現(xiàn),模型結(jié)構(gòu)見(jiàn)圖 1.模型主要包含關(guān)鍵詞相似度計(jì)算方法、詞序相似度計(jì)算方法以及相似度融合方法.由于文本中關(guān)鍵詞同時(shí)代表著語(yǔ)義與結(jié)構(gòu)特性,所以文本的相似度通過(guò)文本關(guān)鍵詞特征來(lái)進(jìn)行計(jì)算[10].關(guān)鍵詞特征相似度通過(guò)關(guān)鍵詞相似度與詞序相似度兩維度分別進(jìn)行計(jì)算,最后通過(guò)基于樣本數(shù)據(jù)的二元回歸分析實(shí)現(xiàn)不同維度的相似度融合,得到文本的綜合相似度.
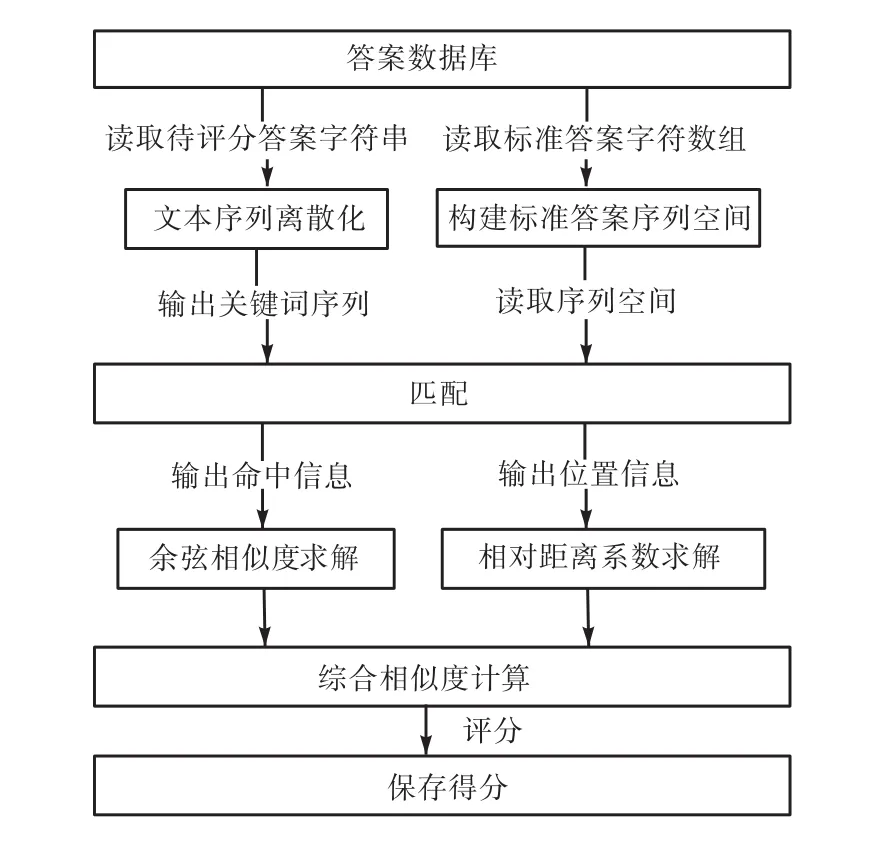
圖1 基于文本結(jié)構(gòu)的相似度模型結(jié)構(gòu)Fig. 1 Similarity model structure based on text structure
在關(guān)鍵詞特征相似度計(jì)算過(guò)程中,通過(guò)將答案關(guān)鍵詞在標(biāo)準(zhǔn)答案關(guān)鍵詞序列空間中進(jìn)行搜索匹配,得到關(guān)鍵詞的命中信息用于計(jì)算關(guān)鍵詞相似度,得到位置信息用于計(jì)算詞序相似度.其中,關(guān)鍵詞相似度通過(guò)求解關(guān)鍵詞序列的余弦向量夾角值得到[11],詞序相似度通過(guò)計(jì)算關(guān)鍵詞在不同文本中的位置差的相對(duì)距離來(lái)得到.關(guān)鍵詞不同維度的相似度可以抽象為影響文本綜合相似度的因子,通過(guò)線性回歸分析得到不同因子對(duì)于因變量的權(quán)重關(guān)系,即得到不同維度的相似度對(duì)于文本綜合相似度的影響程度.將關(guān)鍵詞特征相似度與文本綜合相似度的二元線性回歸函數(shù)作為題目答案評(píng)分準(zhǔn)則函數(shù)進(jìn)行題目評(píng)分.
2 方法設(shè)計(jì)與實(shí)現(xiàn)
2.1 關(guān)鍵詞搜索匹配
在關(guān)鍵詞搜索匹配前,通過(guò)數(shù)組 Trie樹(shù)構(gòu)建標(biāo)準(zhǔn)答案序列空間.?dāng)?shù)組 Trie樹(shù)是將樹(shù)形節(jié)點(diǎn)狀態(tài)通過(guò)數(shù)組保存的一種字符前綴樹(shù),Trie樹(shù)節(jié)點(diǎn)定義[12]為
typedef struct{
Py_ssize_hash;
PyObject * key;
PyObject * value
} PyDictEntry;
其中:key用于存儲(chǔ)節(jié)點(diǎn)字符;value用于存儲(chǔ)該節(jié)點(diǎn)的子節(jié)點(diǎn)以及當(dāng)前節(jié)點(diǎn)的狀態(tài)、子節(jié)點(diǎn)相對(duì)于當(dāng)前節(jié)點(diǎn)的偏移值(數(shù)組 base)、當(dāng)前節(jié)點(diǎn)的父節(jié)點(diǎn)狀態(tài)(數(shù)組check)以及當(dāng)前節(jié)點(diǎn)的位置標(biāo)記值(index).
基于 Trie樹(shù)的序列空間構(gòu)建過(guò)程包括初始狀態(tài)確定、字符編碼讀取、狀態(tài)轉(zhuǎn)移、結(jié)果存儲(chǔ).在狀態(tài)轉(zhuǎn)移過(guò)程中,對(duì)于每一個(gè)關(guān)鍵詞,從狀態(tài) s到 t滿足base[s]+code=t、check[t]=base[s].字符編碼用 code表示,狀態(tài)轉(zhuǎn)移中選取字符的 GBK2312編碼集的十進(jìn)制數(shù)取哈希映射后的值作為該值.序列空間構(gòu)建過(guò)程如下:
(1)初始化 root節(jié)點(diǎn)為根節(jié)點(diǎn),并設(shè)置 base[root]=1作為起始狀態(tài).
(2)初始化base和check兩個(gè)狀態(tài)轉(zhuǎn)移記錄數(shù)組.
(3)找出root節(jié)點(diǎn)的子節(jié)點(diǎn)集合 root.childs,并修改 base數(shù)組和check數(shù)組,使得 check[root.childs]=base[root]=1成立.
(4)對(duì)于每一個(gè)子節(jié)點(diǎn),找到一個(gè)初始值 begin,使得每一個(gè)子節(jié)點(diǎn)經(jīng)過(guò)狀態(tài)轉(zhuǎn)移后均有空間進(jìn)行存儲(chǔ).此時(shí),設(shè)置當(dāng)前的base值為該begin值.
(5)根據(jù)得到的 begin值與字符 code,通過(guò)狀態(tài)轉(zhuǎn)移方程對(duì)節(jié)點(diǎn)進(jìn)行插入,同時(shí)修改字符的check值.
(6)對(duì)于每一個(gè)子節(jié)點(diǎn),循環(huán)調(diào)用步驟(3)、步驟(4),如果狀態(tài)i對(duì)應(yīng)某一個(gè)關(guān)鍵詞,且base[i]=0,那么令 base[i]=(-1)*i;如果 base[i]!=0,那么令base[i]=(-1)*base[i].即使得關(guān)鍵詞詞尾(葉子節(jié)點(diǎn))其base值為負(fù)值.通過(guò)狀態(tài)轉(zhuǎn)移插入得到的Trie樹(shù)如圖2所示.
(7)經(jīng)過(guò)逐個(gè)插入得到關(guān)鍵詞字符的 i、base、check以及index數(shù)組列表.
在進(jìn)行關(guān)鍵詞搜索匹配時(shí),首先對(duì)待評(píng)分答案進(jìn)行分詞、去停用詞等操作,得到待評(píng)分答案的關(guān)鍵詞集合.然后讀取根據(jù)標(biāo)準(zhǔn)答案文本構(gòu)建好的序列空間,根據(jù)當(dāng)前狀態(tài)與轉(zhuǎn)移規(guī)則,通過(guò)字符編碼進(jìn)行狀態(tài)轉(zhuǎn)移,根據(jù)命中條件進(jìn)行命中判定.
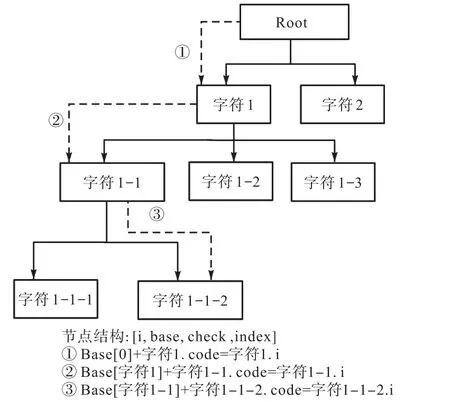
圖2 Trie樹(shù)示意圖Fig. 2 Diagram of Trie tree
命中條件:定義當(dāng)前狀態(tài)為 p,如果 base[p]==check[base[p]] && base[base[p]]<0則查找命中.關(guān)鍵詞搜索匹配流程見(jiàn)圖3.
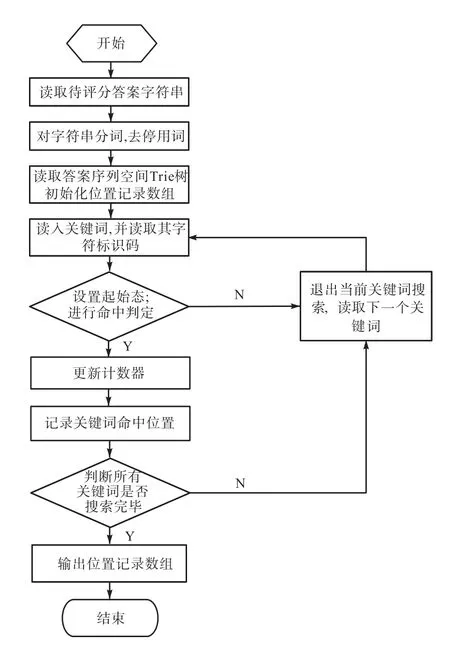
圖3 關(guān)鍵詞搜索匹配流程Fig. 3 Matching process of keywords
關(guān)鍵詞搜索匹配的具體步驟如下:
(1)讀取待匹配關(guān)鍵詞,并將其拆解成為單個(gè)字符.
(2)讀取構(gòu)建好的關(guān)鍵詞序列結(jié)果數(shù)組,并將root節(jié)點(diǎn)定義為起始狀態(tài)p.
(3)讀取第一個(gè)字符的編碼 code,根據(jù)轉(zhuǎn)移規(guī)則驗(yàn)證是否滿足條件 base[p]==check[base[p]] &&base[base[p]]<0.如果滿足,則當(dāng)前字符的查找命中,繼續(xù)讀取下一個(gè)字符進(jìn)行驗(yàn)證;如果不滿足,修改位置記錄數(shù)組值為0并退出查找過(guò)程.
(4)如果字符串中最后一個(gè)字符滿足步驟(3),則該字符串查找命中,修改對(duì)應(yīng)位置記錄數(shù)組的值為其index值并退出.
將待評(píng)分答案關(guān)鍵詞集合中的每一個(gè)關(guān)鍵詞都進(jìn)行搜索匹配后,根據(jù)記錄關(guān)鍵詞位置情況的數(shù)組進(jìn)行相似度特征計(jì)算.
2.2 相似度求解
相似度求解包括關(guān)鍵詞相似度求解與詞序相似度求解.在計(jì)算關(guān)鍵詞相似度時(shí),首先通過(guò)詞袋模型對(duì)文本進(jìn)行量化,將關(guān)鍵詞結(jié)構(gòu)特征轉(zhuǎn)化為向量特征.在向量空間模型中,文本被拆解成單字或者詞語(yǔ)組成的特征項(xiàng)集 D(T1,T2,…,Tn),其中 Tk(1≤k≤n)是特征項(xiàng),對(duì)應(yīng)的是關(guān)鍵詞.兩個(gè)文本s1和s2之間的相似度可以用其特征項(xiàng)集對(duì)應(yīng)的向量 V1,V2間夾角的余弦值表示.那么,標(biāo)準(zhǔn)答案文本與待評(píng)分答案文本的關(guān)鍵詞相似度 C可以通過(guò)式(1)進(jìn)行求解.

詞序相似度通過(guò)相對(duì)距離進(jìn)行計(jì)算.其中關(guān)鍵詞的位置標(biāo)記為關(guān)鍵詞在文本特征項(xiàng)集中的序號(hào);同一關(guān)鍵詞在不同文本特征項(xiàng)集中的位置差值定義為相對(duì)距離,用于刻畫(huà)其在語(yǔ)句內(nèi)部的位置差異,相對(duì)距離越小,相似程度越大.關(guān)鍵詞相對(duì)距離的計(jì)算方法見(jiàn)式(2),其中dn2和dn1分別代表第n個(gè)關(guān)鍵詞在兩個(gè)不同文本s2、s1中的位置標(biāo)記.

文本相對(duì)距離D的計(jì)算公式見(jiàn)式(3).

將文本相對(duì)距離進(jìn)行歸一化,得到表示文本詞序相似度的相對(duì)距離系數(shù)R,記為式(4).

其中,Dmax為文本s1與文本s2間的最大相對(duì)距離.未命中關(guān)鍵詞的相對(duì)距離 d記為(n-1),當(dāng) s2中關(guān)鍵詞全部缺失時(shí),文本 s1與文本 s2間達(dá)到最大相對(duì)距離 Dmax=(n-1)n.n為 s2中的元素個(gè)數(shù),也就是集合長(zhǎng)度.
2.3 相似度融合
在得到答案文本基于結(jié)構(gòu)的相似度特征后,采用統(tǒng)計(jì)回歸方法將不同維度的相似度以最優(yōu)的權(quán)重融合成為文本的綜合相似度.基于文本二維的結(jié)構(gòu)相似度特征,將關(guān)鍵詞相似度與詞序相似度定義為自變量,學(xué)生答案得分與題目滿分比值定義為因變量,定義二元線性回歸方程

式中:b0為常數(shù)項(xiàng);b1、b2為回歸系數(shù);C、R分別代表關(guān)鍵詞相似度與詞序相似度;y為答案得分與題目滿分的比值;μi為隨機(jī)誤差.
多子句文本的相似度選取各子句相似度的平均值作為其相似度,計(jì)算公式見(jiàn)式(6).Si為文本第i個(gè)子句的綜合相似度.

3 實(shí) 驗(yàn)
首先需要采集特定學(xué)科背景下的主觀題目人工閱卷結(jié)果作為樣本數(shù)據(jù),通過(guò)統(tǒng)計(jì)分析方法獲得其相似度回歸函數(shù).本次實(shí)驗(yàn)采集“計(jì)算機(jī)體系結(jié)構(gòu)”課程的500道已閱試題作為樣本數(shù)據(jù),數(shù)據(jù)來(lái)源為天津科技大學(xué)課程考試試題,試題類型包括簡(jiǎn)答題、名詞解釋題和論述題,每條數(shù)據(jù)包含題目、標(biāo)準(zhǔn)答案、學(xué)生答案與得分四項(xiàng)內(nèi)容.
根據(jù)相似度算法求得學(xué)生答案與標(biāo)準(zhǔn)答案的關(guān)鍵詞相似度 C、相對(duì)距離系數(shù) R,并對(duì)得分與滿分比值進(jìn)行二元回歸分析,得到回歸函數(shù)見(jiàn)式(7)(隨機(jī)誤差忽略不計(jì)).
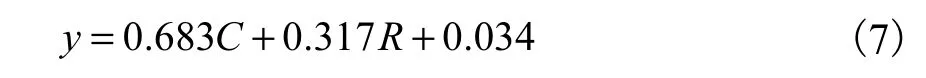
對(duì)回歸函數(shù)進(jìn)行顯著性檢驗(yàn) F檢驗(yàn)(顯著性水平取 α=0.05)得 F0.05=2.735<F(2497)=3.014,接受線性回歸顯著假設(shè).T檢驗(yàn)得 T=2.003,查表得2.003> T0.025/497=1.965,接受函數(shù)回歸參數(shù)顯著有效假設(shè).即該回歸方程具有統(tǒng)計(jì)學(xué)意義,可以用來(lái)進(jìn)行題目評(píng)分.
選取 200道“計(jì)算機(jī)體系結(jié)構(gòu)”主觀題目作為測(cè)試數(shù)據(jù),其中包含 100道簡(jiǎn)答題、50道名詞解釋題、50道論述題.將題目滿分標(biāo)準(zhǔn)化為 100分.對(duì)樣本數(shù)據(jù)進(jìn)行閱卷,首先調(diào)用中科大分詞系統(tǒng)(NLPIR)進(jìn)行分詞與去停用詞處理,將文本字符串處理成為關(guān)鍵詞序列集合.然后通過(guò)數(shù)組 Trie樹(shù)將關(guān)鍵詞集合構(gòu)建成為可供搜索的序列空間,在關(guān)鍵詞搜索匹配的基礎(chǔ)上計(jì)算關(guān)鍵詞相似度與詞序相似度作為文本不同維度的相似度,進(jìn)而通過(guò)二元線性回歸進(jìn)行融合,得到答案文本的綜合相似度.
實(shí)驗(yàn)對(duì)比方法采用人工指定參數(shù)的相似度計(jì)算方法[9].該方法在關(guān)鍵詞集合的基礎(chǔ)上通過(guò)計(jì)算關(guān)鍵詞相似度與集合貼近度,得到文本最終的相似度并將其作為題目得分權(quán)重.其中人工指定關(guān)鍵詞權(quán)重參數(shù) P=0.7作為可信參數(shù),語(yǔ)義貼近度閾值選取 0.15作為可信參數(shù),ψ(A, B)表示關(guān)鍵詞相似度,δ(A, B)表示文本 A、B貼近度,S0為題目滿分.方法 2中的得分計(jì)算公式見(jiàn)式(8).
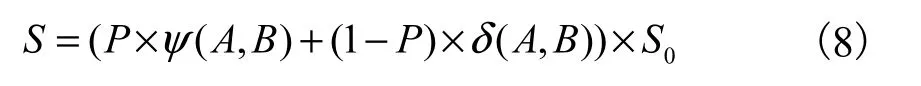
本文方法、對(duì)比方法及人工評(píng)閱的結(jié)果見(jiàn)圖 4,分段統(tǒng)計(jì)結(jié)果見(jiàn)表1.
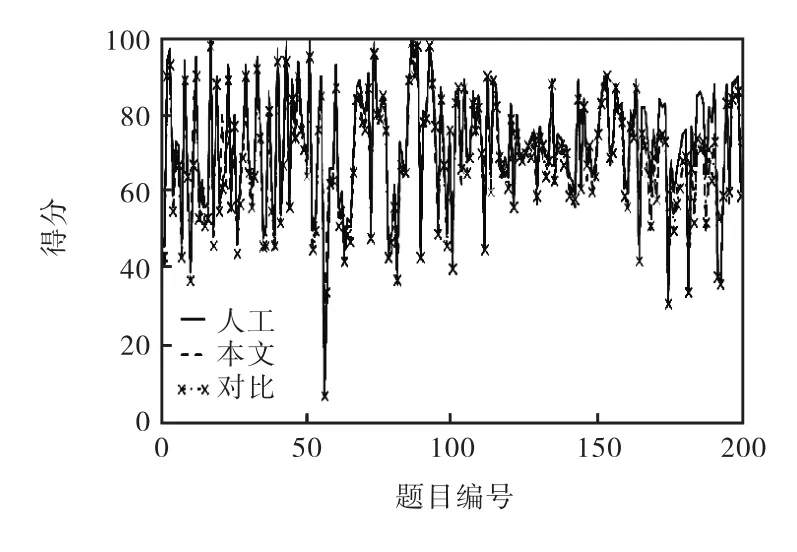
圖4 閱卷結(jié)果對(duì)比Fig. 4 Comparison of grading results
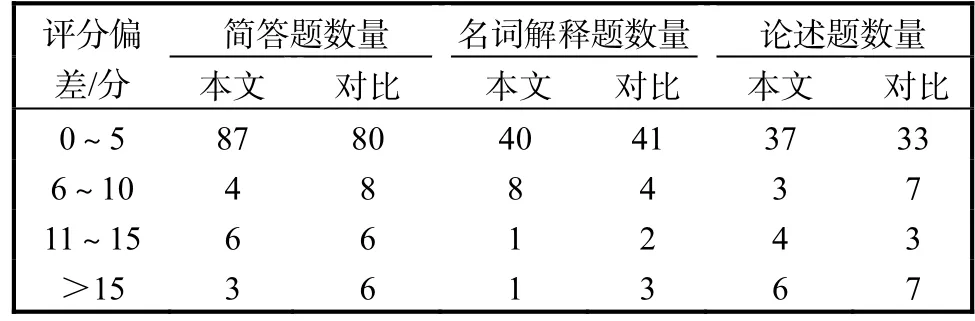
表1 分段統(tǒng)計(jì)結(jié)果Tab. 1 Results of section calculation
統(tǒng)計(jì)評(píng)分結(jié)果誤差在 10分以內(nèi)的題目數(shù)量,本文方法為 89.5%,對(duì)比方法為 86.5%.不同答案的用詞差異導(dǎo)致關(guān)鍵詞匹配命中率較低,致使相似度差異較大;論述題中包含較多子句,句子整體相似度求解時(shí)子句權(quán)重平均分配導(dǎo)致差異增加;簡(jiǎn)答題與名詞解釋題等短文本答案中的關(guān)鍵詞特征明顯,評(píng)閱效果較好;由于答案中的語(yǔ)序關(guān)系通過(guò)關(guān)鍵詞的相對(duì)距離系數(shù)得到了更準(zhǔn)確的描述,所以,對(duì)語(yǔ)序關(guān)系突出的題目評(píng)閱效果較好.評(píng)閱準(zhǔn)確率整體較高,說(shuō)明該模型方法對(duì)于主觀試題有較好的評(píng)閱效果.
雖然在個(gè)別題目上存在評(píng)分偏差較大的情況,但是整體來(lái)看,本文方法的閱卷結(jié)果更加貼近人工閱卷結(jié)果,與人工評(píng)閱結(jié)果的兩條評(píng)分曲線也更加吻合,閱卷結(jié)果基本一致.對(duì)于某些特定需求下的閱卷工作,該相似度模型可行有效.
4 結(jié) 語(yǔ)
對(duì)于學(xué)科背景下的主觀題閱卷,本文通過(guò) Trie樹(shù)實(shí)現(xiàn)關(guān)鍵詞匹配下的二維相似度模型,有效地避免了傳統(tǒng)閱卷模式的句法樹(shù)分析與向圖分析的復(fù)雜性,節(jié)約了系統(tǒng)開(kāi)銷.其方法對(duì)于主觀題目的快速閱卷具有一定的現(xiàn)實(shí)意義.
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
