基于深度學習的局部描述符
2019-02-14 08:51:22唐家琳
電子制作 2019年2期
唐家琳
(西北工業大學啟迪中學,陜西咸陽,712000)
0 前言
人工智能發展關系著未來,近年來黨和政府對人工智能越來越重視,然而人工智能發展是一個十分曲折的歷程,從20世紀50年代以來,隨著科技的飛速發展,自1936年,阿蘭·圖靈的兩篇論文開始,為計算機開創了理論先河;又有1940年,維納發現的人工智能核心-反饋,1955年,約翰·麥卡錫第一次提出“人工智能”一詞,從此人工智能一詞出現在了人們視野之中。21世紀開始世界進入數字化時代,人們也隨科技的進步而進入了一個日新月異的全新世界,隨之而來的出現了許多問題,如:社會人口老齡化,勞動力成本上升,大量信息沖擊。人們對家庭服務機器人和人工智能的需求已迫在眉睫。隨著計算機的運算速度的提高與網絡的日益完善,給人工智能提供了一個良好的發展基礎。深度學習是人工智能目前的一個重要方向,深度學習局部描述符廣泛應用于計算機視覺領域和圖像理解領域。相比較傳統手工局部描述符,深度學習局部描述符經深度學習提取到的描述符精度高,而傳統手工局部描述符精度不高,這會導致之后計算出現偏差甚至出現錯誤。而現今大多數SLAM主要應用傳統手工局部描述符,它的精度達不到很高,基于這一問題我們準備利用一個深度學習提取到的描述符來代替傳統手工局部描述符,這樣會大大提高視覺精度。
同時定位與建圖(Simultaneous Localization And Mapping)其目的在于讓機器人了解周圍環境,并且知道自己在環境中的位置。然而,目前已經存在的SLAM系統都是基于傳統手工提取的描述符,這種方法不僅浪費了大量的空間,而且效率極低,對于光照等變化也不夠魯棒。此外,其構建的地圖沒有包含語義等更多的信息。因此我們準備構造一個基于深度學習的slam系統以提高性能,首先通過深度學習提取局部描述符。在回環檢測的部分使用基于深度學習的場景識別,摒棄BOW(Bag of words)的方式。在構建地圖的階段,我們采用了全卷積網絡進行圖像語義分割,然后將分割結果映射到地圖中,這樣構建的語義地圖可以為后續的機器人導航提供更多的信息。
我們通過查閱文獻和資料發現對人工智能機器人需求量較大的是家庭服務機器人,可見家庭服務機器人的基于深度學習的局部描述符研究尤為重要。文中寫出來其他描述符的局限性,同時也寫出來基于深度學習的局部描述符相比較其他描述符的優點,在提出設計原理的基礎上詳細分析了具體的實現途徑和技術路線。
1 局部描述符
■1.1 局部特征描述符
局部特征描述符現今的運用是非常廣泛的,如基于梯度的描述符SIFT(Scale-invariant feature transform)特征描述符是現今運用最廣泛也是現今最主流的局部空間描述符。
SIFT 已成功用于圖像分類、圖像致密對應、目標檢索、機器人導航等領域。但是SIFT還有許多問題,如:SIFT描述符高緯度,SIFT描述符計算復雜度高,SIFT描述符計算速度較慢等。Ke 和 Sukthankar PCA-SIFT 描述符,很好的解決了SIFT描述符的高維度問題;針對SIFT描述符計算復雜高,Bay等人提出了SURF(Speed Up Robust Features)描述符,解決SIFT描述符運算速度較慢的問題;Mikolajczyk等人提出的GLOH描述符,使得提取局部描述符的魯棒性與辨別性都有了很大的提升。
二進制描述符,具有計算簡單,速度較快,所需處存容量少的特點,現今此描述符受到很多關于計算機視覺領域研究者的關注。Calonder 等人提出了二進制魯棒獨立描述符( BRIEF)。之后Galvezlopez等人又提出利用BRIEF描述符識別位置的移動機器人。但二進制魯棒獨立描述符不具備旋轉不變性以及其強度對位置采樣策略。基于此問題,Rublee等人提出了基于BRIEF 的ORB( oriented fast and rotatedBRIEF)二進制描述符。這個描述符很好的解決了上述問題,后經大量的訓練以及對性能的評估,得到一個結論:[1]在大的旋轉和和幾何變化條件下,BRIEF 的性能要低于ORB和BRISK描述符。后Alahi等人提出額FREAK( fast retina keypoint)描述符。對此類描述符在新的視角上給出了分析和解釋的Ziegler等人,他們認為:此類描述符都是在序相關性上的 Hash 方法。對于此,他們提出了一種新方法: 局部一致對比圖像描述符( LUCID)。
■1.2 基于機器學習的局部描述符
由于目前利用手動設計出來的描述符很難確定參數配置,手動設計出的描述符很難同時具備較高的不變性、緊密型和獨特性。近些年來局部不變描述符研究領域的一大熱點是研究學者把機器學習的方法用于描述符的設計。
■1.3 基于物體檢測的視覺里程計
視覺里程計(Visual Odometry,VO)在基于視覺傳感器的SLAM系統里,視覺里程計又被稱為SLAM前端,視覺里程主要通過計算相鄰圖像之間的相對運動,給出在當前時刻相機對于給定的坐標系中的姿態并且恢復周圍環境的空間結構。目前,現在主流的實現視覺里程的方法主要有兩種:第一種是“不基于提取特征的直接法”;第二種是“基于提取特征的特征點法”。其中的代表為LSD-SLAM(Large-Scale Direct Monocular SLAM)和ORB-SLAM的前端模塊。由于在場景光照發生改變或者時間的變化會導致直接法的失敗。而對于特征點來講特征點法對光照的變化具有一定的魯棒性,可以很好的解決這一問題。
2 Siamese Network模型
■2.1 Siamese Network網絡的訓練
Siamese網絡結構為兩個完全相同的網絡,且它們的權值一樣。神經網絡要經過一個訓練,例如:在室內隨機選取許多的圖像,提取圖像中的特征點,隨機的通過兩個網絡相同權值共享的網絡,得到兩組描述符,算它們之間的距離,求出損失函數,若特征點相似,其之間距離較小,損失函數值為1;若特征點相似,其之間距離較大,即dij大于α,則損失函數值為max0,α-dij,使dij大于α,減小損失函數值,讓其趨近于零。提取大量特征點對損失函數進行訓練,使相似點的距離小于不相似點的距離,基于此識別出相似描述符。
■2.2 Siamese Network網絡的實例
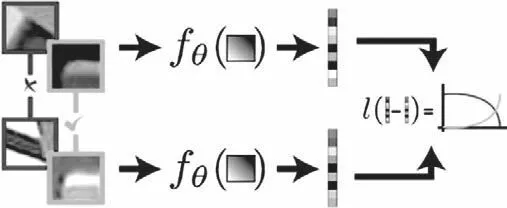
圖1 局部描述符提取網絡架構
圖1中紅色和綠色為輸入局部圖像,fθ為網絡的一個擬合函數。例如上圖中,輸入已知的圖像,形成局部描述符。紅色輸入相似度差的圖像,減小損失函數值;綠色的是相似度較高的圖像,提高損失函數值;使其相似點的距離小于不相似點的距離,基于此訓練識別相似的局部描述符。
3 線性損失函數
■3.1 損失函數
損失函數(Loss function)通常如下所示:
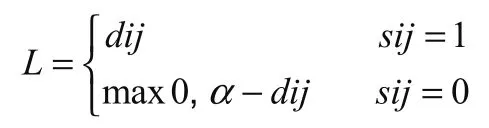
L表示損失函數,dij表示i和j之間的距離,如果sij=1,即為同類,損失為0;如果sij=0,即損失為max(0,α- dij )。
■3.2 hinge loss
鉸鏈損失(hinge loss)是線性損失函數的常見類型,鉸鏈損失這一叫法來自其函數圖像,如圖2所示。其函數圖像為一個折線。
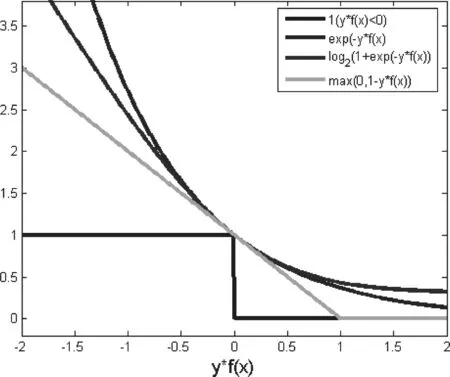
圖2 鉸鏈損失函數圖像
4 深度學習相關概論
■4.1 人工神經網絡
人工神經網絡(Arti fi cial Neural Network,ANN),他是一個模仿模仿生物神經網絡一個理論模型,和神經系統一樣,他也是由許多神經元一樣的帶有權值的神經元,動物的神經網絡是由大量的神經元連接而成,人工神經網絡利用大量的神經單元來模擬出動物一樣的神經網絡,人工神經網絡中神經單元的權值大小可以很好的模擬出動物神經網絡中的抑制或者興奮狀態。其結構如圖3所示。
圖中的圓為神經單元,每個神經單元之間的連接都有一個權重。人工神經網絡的完善需要經過大量訓練,首先利用大量具備標簽的樣本集去訓練人工神經網絡,然后根據人工神經網絡的輸出值與輸入進去的具備標簽的樣本集之間的誤差來修正人工神經網絡中的參數值,使人工神經網絡的誤差更小。
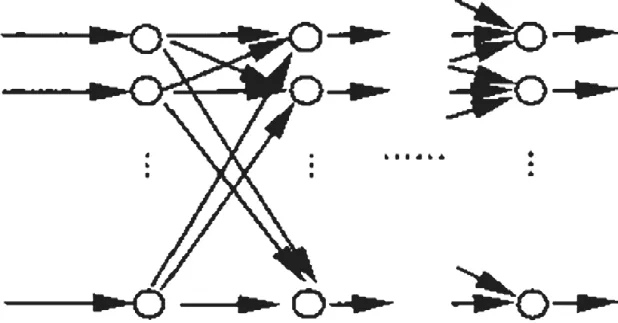
圖3 一般的人工神經網絡結構模型
■4.2 深度學習概論
深度學習技術(Unsupervised Feature Learning)是目前最主要的運用于機器學習領域的十分熱門的一個方法,也是機器學習學科中的重要組成部分,機器學習的主要目的是可以讓計算機模擬出像人一樣的學習能力,從而獲得新的知識或者完成識別和預測等工作[2]。在過去的機器學習領域存在著許多問題,比如以前的特征提取主要靠的是人工的手動提取來完成的,因為人工提取特征點需要耗費大量的時間和人力物力,而且要求提取的人有十分豐富的專業性知識和經驗。
而基于深度學習的機器學習就很好的解決了上述的問題,它是一種不需要人為參與的特征學習的方法。深度學習的主要思想是:使用多層神經來表示輸入的數據。
5 對深度學習局部描述符的總結
利用計算機視覺技術來模仿人類感知能力的一個最核心問題就是: 如何對所要識別的物體進行表示[3]。而基于深度學習的局部描述符,為解決上述問題提供了一個很好的手段。
本文主要通過介紹并提出其他描述符的不足,和基于深度學習的局部描述符之間進行對比,比較出基于深度學習的描述符與傳統描述符之間的優點。通對比證明出基于深度學習的局部描述符相比較傳統描述符來講在魯棒性、辨別性和實用性都有很大的提高。近些年來比較主流的深度學習很好的解決了傳統手工局部描述符精度較低的問題。深度學習是利用模擬生物神經網絡來進行分析學習的一個神經網絡。深度學習模擬類似人的大腦分層思維,形成本身具有的分層結構。所以利用深度學習來提取局部描述符是完全可行的。
為了驗證本文基于深度學習來提取局部描述符的過程,本文通過代表進行這一過程的描述,即人工神經網絡和Siamese Network的訓練。
6 研究展望
本文提出了基于深度學習提取到的局部描述符,很好的解決了目前以手工提取局部描述符的精度不高的問題,但只是進行了理論分析和模型的構建,并沒有進行實際的實驗進行檢驗與驗證,在未來可以結合實際的實驗的結果來對這一研究進行檢驗與驗證,可以對這一審計再一次研究和突破。盡管目前局部圖像描述符的研究取得了很大的進步,但仍存在很多挑戰和發展機遇。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小康(2017年16期)2017-06-07 09:00:59
