基于神經網絡算法的新聞分類研究
2019-02-14 08:51:20宋文浩
電子制作 2019年2期
關鍵詞:模型
宋文浩
(諸城市實驗中學,山東濰坊,261000)
1 概述
神經網絡的研究在機器學習中具有重要的意義。人工神經網絡以其特有的優越性,成為研究的熱點。神經網絡的特點可以從三個方面來介紹:第一,人工神經網絡的自學習能力。對于圖像識別問題,只需要將圖片及其對應類別輸入神經網絡,不需要構造復雜的組合特征,神經網絡可以通過強大的自學習能力捕捉特征之間的關聯,實現圖像識別功能。第二,人工神經網絡的聯想存儲功能。第三,人工神經網絡的高速優化能力。對于機器學習問題來說,復雜度越高的問題,尋找優化解的計算量往往會越大。而設計好的反饋型人工神經網絡,則能夠充分利用計算機高速運算的能力,能夠大大縮短尋找優化解的時間。
娛樂文章按體裁能分成七類:資訊熱點,電影電視劇報道評論,人物深扒,組圖盤點,明星寫真,行業報道,機場圖。本文根據娛樂文章的文本信息構建神經網絡,將文章進行多分類。
■1.1 數據集特征
娛樂新聞數據集包含了7個特征:
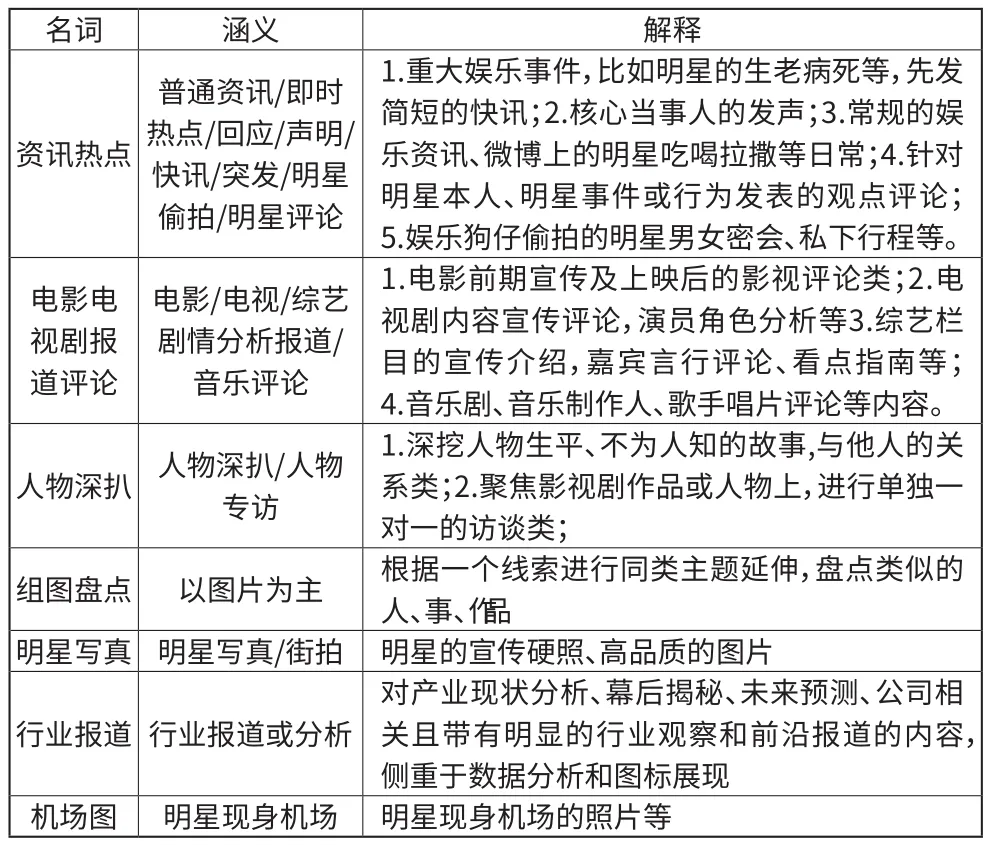
名詞 涵義 解釋資訊熱點普通資訊/即時熱點/回應/聲明/快訊/突發/明星偷拍/明星評論1.重大娛樂事件,比如明星的生老病死等,先發簡短的快訊;2.核心當事人的發聲;3.常規的娛樂資訊、微博上的明星吃喝拉撒等日常;4.針對明星本人、明星事件或行為發表的觀點評論;5.娛樂狗仔偷拍的明星男女密會、私下行程等。1.電影前期宣傳及上映后的影視評論類;2.電視劇內容宣傳評論,演員角色分析等3.綜藝欄目的宣傳介紹,嘉賓言行評論、看點指南等;4.音樂劇、音樂制作人、歌手唱片評論等內容。人物深扒 人物深扒/人物專訪電影電視劇報道評論電影/電視/綜藝劇情分析報道/音樂評論1.深挖人物生平、不為人知的故事,與他人的關系類;2.聚焦影視劇作品或人物上,進行單獨一對一的訪談類;組圖盤點 以圖片為主 根據一個線索進行同類主題延伸,盤點類似的人、事、作品明星寫真 明星寫真/街拍 明星的宣傳硬照、高品質的圖片行業報道 行業報道或分析對產業現狀分析、幕后揭秘、未來預測、公司相關且帶有明顯的行業觀察和前沿報道的內容,側重于數據分析和圖標展現機場圖 明星現身機場 明星現身機場的照片等
■1.2 數據集預處理
通常,在工程實踐中,拿到的實際數據往往存在以下問題:數據缺失、數據重復、數據冗余等。這就要求我們在將數據喂入模型開始訓練之前,針對現有數據存在的問題進行特定的處理,即數據預處理。數據預處理要具有針對性,對于不同類型的數據以及不同類型的數據問題,采取的預處理方式也不同。我們的娛樂新聞數據集的預處理一共包含分詞,去停用詞和計算TF-IDF三個步驟。對訓練數據進行整體分析,抽取出正文和標簽部分作為輸入。對測試數據做相同處理,抽取出測試數據的真實標簽和正文內容。
1.2.1 去停用詞
停用詞包括標點、數字、單字等對于分析文本內容貢獻很小的詞語以及其它一些無意義的詞。這些詞(如“你我他”)往往無法表示文本的特征,對于模型的訓練幫助不大,應當從文本中清除掉。本文用到的是哈工大的停用詞表。將文章中的詞與停用詞表中的詞作比較,如果在表中出現該詞,就將其刪除,如果沒有出現,就跳過。
1.2.2 分詞
文本分詞是文檔處理中的一個必不可少的操作,因為后續的操作需要用文檔中的詞來表征這篇文檔的內容。本文中對文本進行分詞步驟如下:
(1)構造詞典
(2)分詞操作
目前主要用來構造詞典的方法是字典樹。分詞主要采用的有正/反/雙向最大匹配以及語言模型和最短路徑等算法。
我們使用的是結巴分詞程序包。
1.2.3 tf-idf指標
tf-idf(term frequency-inverse document frequency)又稱之逆文檔頻率,是一種統計學上對詞出現的頻繁程度的一種量化指標。用于衡量一個單詞在一篇文章中或者在一個大型的語料庫中的重要程度,詞語的重要性和詞語在一篇文檔中出現的次數有著正相關關系,但和整個語料庫中該次出現的頻率有著負相關關系。通俗地說,就是一個詞在某篇文章中出現的次數越高,而在這一堆文章中的其他文章中出現越少,它就更能表征這篇文章的內容。
詞頻(TF)指的是一個給定的詞語在某篇文章中出現的次數,為了防止文章過長導致頻率偏向長文章,這個出現的次數一般會采用某種算法進行歸一化操作(通常采用該次出現的頻數/該篇文檔的總詞數)。TF(W)=在某一類中詞條W出現的次數除以該類中所有的詞條數目。
IDF的計算方法是由語料庫中文檔的總數除上出現該詞語的文檔數,將結果再取對數。IDF=log(語料庫的文檔總數除以包含詞條w的文檔數+1),分母之所以要加1,是為了避免分母為0 IDF=log(語料庫的文檔總數包含詞條w的文檔數+1),分母之所以要加1,是為了避免分母為0。
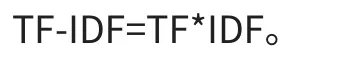
最終輸入模型的即每篇文章的TF-IDF值。
■1.3 數據集劃分
為了模型的訓練與模型的性能檢驗,我們需要把數據集分為訓練集和測試集兩部分。數據集共包含9000+訓練數據,2000+測試數據。
2 構建神經網絡模型
■2.1 構建神經網絡模型
2.1.1 基本原理
神經網絡結構:一個經典的神經網絡包含三個層次。紅色的是輸入層,綠色的是輸出層,紫色的是中間層(也叫隱藏層)。輸入層有3個輸入單元,隱藏層有4個單元,輸出層有2個單元。如圖1所示。
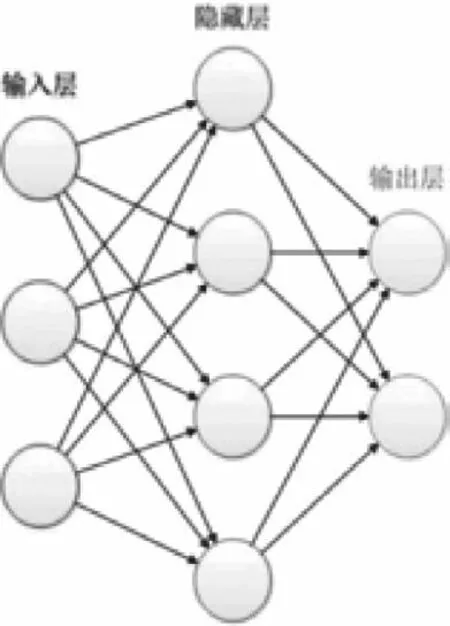
圖1
神經元結構如圖2所示。
一個神經元一般由輸入z和輸出a兩個函數組成。每個神經元和其他的每個神經元都具有一個連接權重,它們各自的權重通常是一些隨機值。對于一個神經元,將所有對應的權重和上一層的輸出a相乘,然后,把這些值相加。然后運用激活函數對這個值進行非線性變換,這個激活函數的輸出成為這個神經元的最后的輸出。Z=n0*w0+n1w1+n2w2+b.激活函數常用sigmoid函數:sigmoid函數的輸出介于0~1之間,它是人工神經網絡中比較常用的一種激活函數。
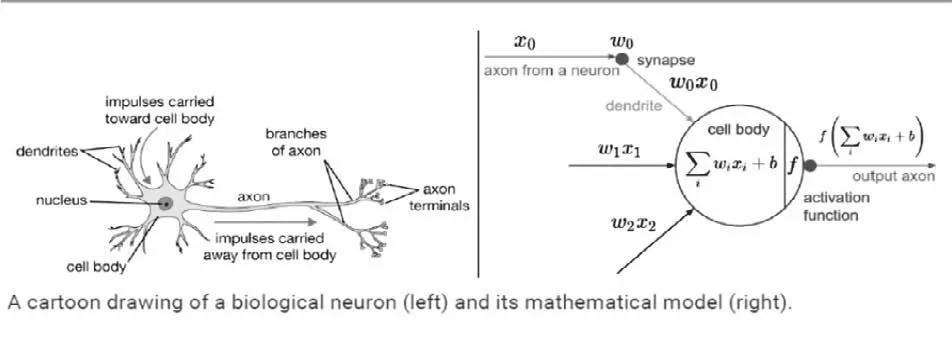
圖2
神經網絡(感知機)算法:訓練的目的是求出最適權重(即W)與最適b。為描述預測模型的準確度,在此引入了損失函數。求最優解的的過程就是求損失函數最小的過程。公式如下:
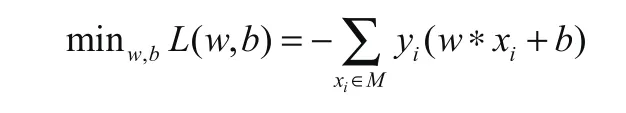
2.1.2 前向傳播算法
神經網絡的前向傳播算法,在神經網絡中,下一層的輸入是通過上一層結點進行卷積運算(加權運算),并且加上bias偏置項,最后再通過一個非線性函數進行非線性變換而得到。這里的非線性函數也就是激活函數,常見的激活函數包括ReLu, sigmoid等。這里得到的結果就是本層結點的輸出,也是下一層的輸入。重復以上過程,進行一層層的運算,直到網絡最后一層,得到輸出層結果。
不管維度多高,前向傳播每層進行的計算過程都可以用如下公式表示:

上述公式中,l表示網絡層數,*表示向量運算,W為權重,b為偏置,σ表示激活函數。本文采取ReLu作為激活函數。
2.1.3 反向傳播算法
網絡初始訓練時采用的隨機初始權重得到的輸出結果和實際值之間肯定存在很大的偏差,因此,需要更新網絡中每一層的權重值,優化網絡的預測準確率,此時需要使用反向傳播算法。
假設前向傳播算法計算得到的輸出值為yk,yk表示輸出層輸出的對第k個結果的預測,而第k個結果的真實值記為tk,定義損失函數如下:

反向傳播算法也就是采用梯度下降的方法對參數W和偏置b進行迭代優化,再梯度下降過程中需要計算誤差函數分別對網絡中每一層的參數W和b的偏導數。從而找到梯度下降最快的方向(即損失函數下降最快的方向),從而優化算法模型。
神經網絡是根據網絡深度進行劃分,工作原理主要包括前向傳播和反向傳播。通常的神經網絡包括輸入層,隱藏層,和輸出層。隱藏層的深度往往遠遠大于1。我們通過輸入特征,進行前向傳播,然后計算出輸出誤差(真實值和計算值之間的誤差)。反向傳播算法的目的即通過得到的輸出誤差,不斷的迭代,從而更新網絡的權重,不斷的減小訓練誤差,達到最小化模型誤差的目的。從而提高網絡預測的準確率和泛化能力。
2.1.4 過擬合問題
過擬合,就是擬合函數需要顧忌每一個點,對訓練模型的一些噪音或者離群點也做出了擬合,最終形成的擬合函數對測試集數據擬合的有所欠缺,導致預測結果波動很大。可以很明顯地看到,模型在訓練集上效果很好,但是在測試集上效果很差。這會導致模型泛化能力弱,達不到預期的結果。針對神經網絡的過擬合問題,通常采用隨機失活部分神經元(dropout)的方法進行解決。即,簡化了神經網絡的模型,避免模型過于復雜而導致過擬合問題。本文中的模型也采用了dropout方法來降低過擬合。
■2.2 模型的特點分析
構建了結構為:64個神經元的Dense層->0.2Dropout層->7個神經元的Dense層的神經網絡,采用SGD算法,設置了10個epoch,batch size為128。在訓練集上達到80.89%的準確率,在測試集上達到了73.27%的準確率,如圖3所示。
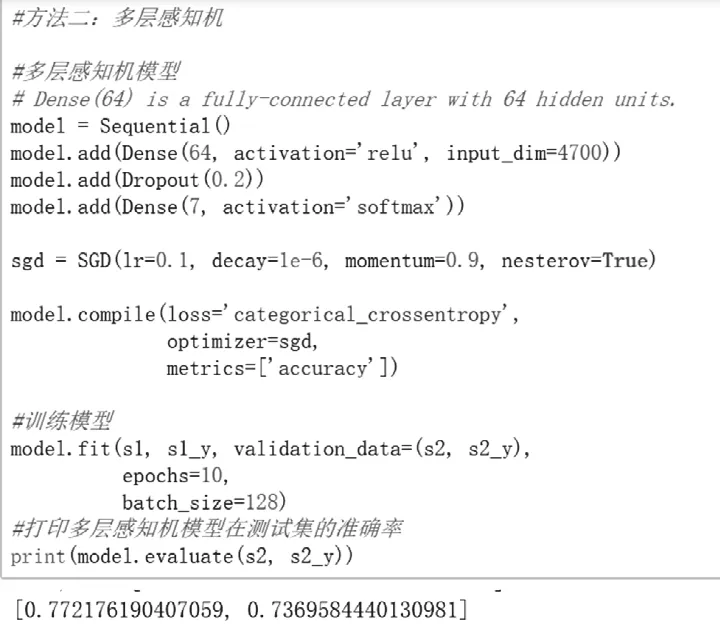
圖3
3 結語
本項目根據具體的娛樂新聞分類數據,在該數據上探索了神經網絡算法。構建了結構為:64個神經元的Dense層->0.2Dropout層->7個神經元的Dense層的神經網絡,采用SGD算法,設置了10個epoch,batch size為128。在訓練集上達到80.89%的準確率,在測試集上達到了73.27%的準確率。表現出了神經網絡學習方法的優異性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
