恰當的水務大數據才符合數據挖掘的需求
2019-02-13 07:32:58張俊杰
城鄉建設 2019年2期
■ 張俊杰

近年來,大數據快速興起。它和人工智能、云計算一起,成為智慧水務技術創新的一種標志。但是能夠正確理解、認識、應用大數據,把大數據挖掘真正應用于生產經營和產銷差控制中的,卻寥寥無幾。原因是人們對大數據的認識還停留在簡單、膚淺的概念上,根本就沒掌握大數據的精髓和本質。大數據本質是為了獲取規律和見解,與獲取收集的數據量無關,與數據是否恰當、正確有關。因此,非常有必要對大數據的恰當性和正確性進行探討和研究,以便為未來大數據的挖掘和應用提供一種嶄新的視野。
一、問題和現狀
大數據(big data)是一個寬泛的概念,大數據不是數據大,這一點是公認的。大數據本質和精髓在于價值,而不是體量和規模。因此,辯證地看待大數據的體量才是科學的。就水務行業而言,大數據存在著數據體量不夠大、數據冗余、數據品質差等諸多問題。因此,有必要對當前水務大數據的現狀進行分析。
(一)數據體量不夠大
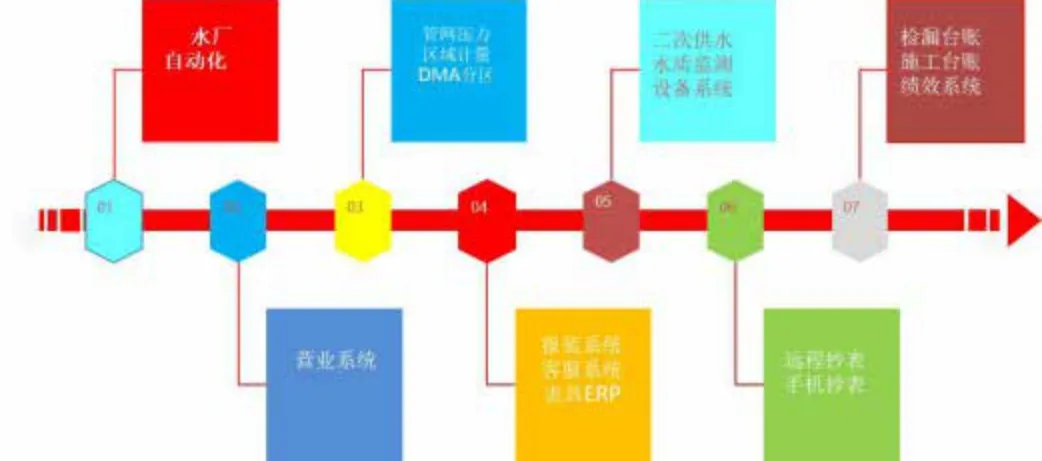
圖1 水務大數據架構圖
不論從產銷差控制與管理,還是從智慧水務角度看,水務大數據體量都不夠大。首先,對水務大數據理解和認識上就有偏差,總以為水務大數據就是水務行業本身產生的大數據,這顯然是欠妥的。從狹義上講,水務大數據是指水廠、生產、調度、管網、客服、營業、施工、檢漏、搶維修、物資采購等部門,通過調度系統、壓力監測系統、GIS 管網系統、DMA分區計量系統、ERP 資產管理系統、客戶服務系統、營銷系統以及人工臺賬等各種途徑,采集的實時數據,人工數據、電子報表數據集成的海量數據。
從狹義上看,只有少量數據是實時的,只是為滿足某項業務需要,缺乏統一的規劃和設計,數據類型復雜、多樣存在著很大的局限性,難以滿足和支撐數據挖掘、應用、決策的需求,導致了數據豐富,知識和信息貧乏的尷尬局面。
從廣義上講,水務大數據除了水務生產經營過程中產生的海量數據外,還應包括與水務大數據緊密關聯的行業、領域以及企業內部行為產生的大數據。諸如:電力、燃氣、污水、酒店、GOOGLE、高德、百度衛星地圖以及年齡結構、區域消費水平、氣候環境、居民生活習慣、消費行為產生的海量數據。
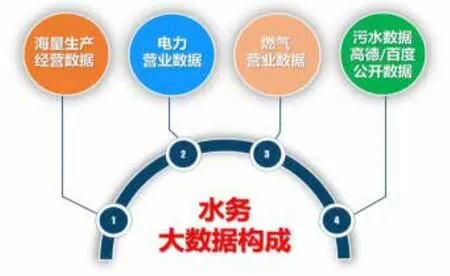
圖2 外部大數據架構圖
從廣義上看,外部數據是滿足了水務大數據“大”的概念,補充和支撐了水務大數據的挖掘、應用的需求,甚至對數據挖掘、轉化商業價值起著決定性的作用。例如,普查燃氣和電力數據地址和用氣量、用電量,對分析客戶用水量就有著很強的借鑒作用;打擊違章用水,可通過用戶用水量和排水量對比直接確定其是否存在違章用水等等。說明外部數據對水務大數據挖掘、應用極其重要。
(二)數據冗余嚴重
大數據的冗余和浪費是大數據挖掘中常見一種現象,是阻撓和影響數據挖掘的一種因素,造成了數據和時間、精力的浪費,甚至有時候還會走彎路,受大數據的體量“大”的拖累,導致無法從大數據中挖掘出規律,進行決策。海量數據的冗余根本原因在于盲目追崇大數據,刻意在數據采集端、系統設計、開發上夸大了大數據作用,卻把大數據本質拋諸腦后。諸如:DMA分區計量系統、管網壓力監控系統以及大表遠傳系統等諸如此類信息系統,把正常半小時、每小時采集、發送1次非要設計為每分鐘采集1次,盲目追求數據集量級,結果導致了海量數據冗余,給數據挖掘人員增加了苦惱。既造成數據浪費,又造成數據采集端電池能耗高。總之,大數據挖掘不應取決于數據量級,而應取決于數據恰當和正確。
(三)大數據品質
大數據的品質是大數據挖掘最大的攔路虎。原因如下:一是數據采集方式多樣,受各種設備、通訊、人為因素的影響,數據失真度,正確性、品質太差。諸如通訊中斷、解析錯誤,儀表故障、人為失誤、修正、篡改等等,這些因素都是導致數據品質差的主要因素。二是數據管理跟不上,總以為數據采集到了就可以挖掘,實際上這是極其錯誤的。基于以上兩種因素,數據品質即正確性才是大數據真正所需要的。數據體量再大,倘若品質太差,冗余太多,就不具挖掘價值。因此,數據品質才是大數據挖掘的靈魂。只有從數據采集端到數據管終端全壽命跟蹤管理數據、嚴控數據質量,在數據管理端實時數據審計和跟蹤,才能保障數據的品質。
二、恰當正確的數據
(一)何為恰當正確的數據?
恰當正確的數據是指數據集的體量要適當,能夠充分滿足數據挖掘的需求,且數據品質即數據要可靠真實,能夠代表事物發展的真實屬性和特征,能夠保證從大數據挖掘中尋找到規律和見解,并準確地應用到生產經營中,為決策分析,預測未來提供目標和方向。
(二)如何選擇恰當正確的大數據?
對數據挖掘人員來講,如何從海量數據中選擇恰當、正確的數據用于挖掘分析這是個難題。因為,根本無法得知多少量級的大數據才能滿足挖掘的需求。從以往對水務大數據挖掘經驗看,除了正常歸類、清洗外,仍有一定規律可循。首先,根據挖掘對象和應用,選擇數據集的體量。其次,堅持數據量級從小到大的原則。假設一個或幾個數據能代表和反映事物本質就選擇一個或幾個數據集。倘若無法滿足挖掘需求,則可以逐級提升數據的量級直到能滿足挖掘需求。最后,在數據采集端要控制和減少冗余數據產生的根源。比如,壓力監測數據每小時數據體量就可以滿足日常監測和數據挖掘需求,就沒必要設置成每1分鐘采集1次,人為造成海量冗余數據的產生。
(三)怎樣應用恰當正確的數據?
應根據挖掘的對象和目的選擇適當的大數據體量。有的需要幾TG,有的則需要幾十K、上百K數據即可。例如:客服系統數據、表具尺寸選型等挖掘則數據體量越大越好,而壓力優化則要根據壓力波動情況而定。大數據挖掘應用如圖3所示。
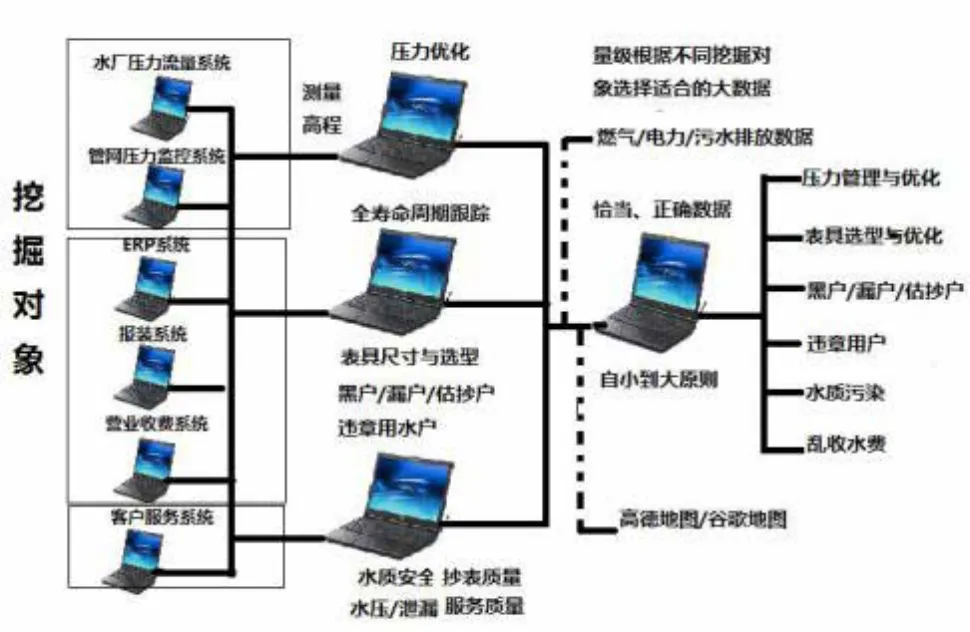
圖3 大數據挖掘應用圖
三、案例分析
(一)壓力數據挖掘
為了充分證明恰當、正確數據才是大數據挖掘所需要的。在這里,以某市最不利點的壓力數據挖掘應用為例。為了便于挖掘、分析,從壓力曲線中找到最不利點壓力的變化規律,數據挖掘人員采用12個月、連續24小時的壓力數據,結果發現數據量太大,壓力曲線毫無規律可循。最后,決定以供水高峰2018年10月壓力數據為樣本。最不利點測壓點數據如圖4所示。
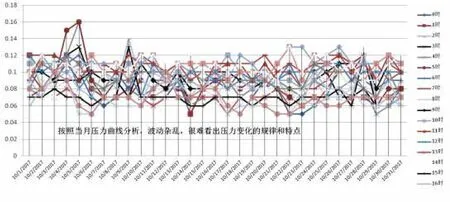
圖4 2018年10月二路車總站的圧力曲線
從上面壓力曲線可以看出,壓力曲線變化雜亂無章,毫無規律和特點。即使在波峰06:0~09:00和波谷23:00~05:00時段的波峰、波谷壓力曲線都無規律可循。這還是采用每小時的壓力數據。倘若大數據挖掘、分析采用5分鐘、15分鐘的壓力大數據分析,壓力曲線的波動、變化更大,更難找出規律。可見,大數據不是數據大,更不是每種數據都需要海量數據,有價值數據夠用即可。

為了進一步挖掘、分析最不利點管網壓力變化的規律和特性,大數據挖掘人員對海量的壓力數據進行了拆解,縮短了壓力數據的周期,采用了上、下半月分析的思路,結果上、下月的壓力曲線呈現了明顯的規律和特點,波峰、波谷的壓力變化顯露無疑。上半月壓力數據挖掘分析曲線如圖5所示。
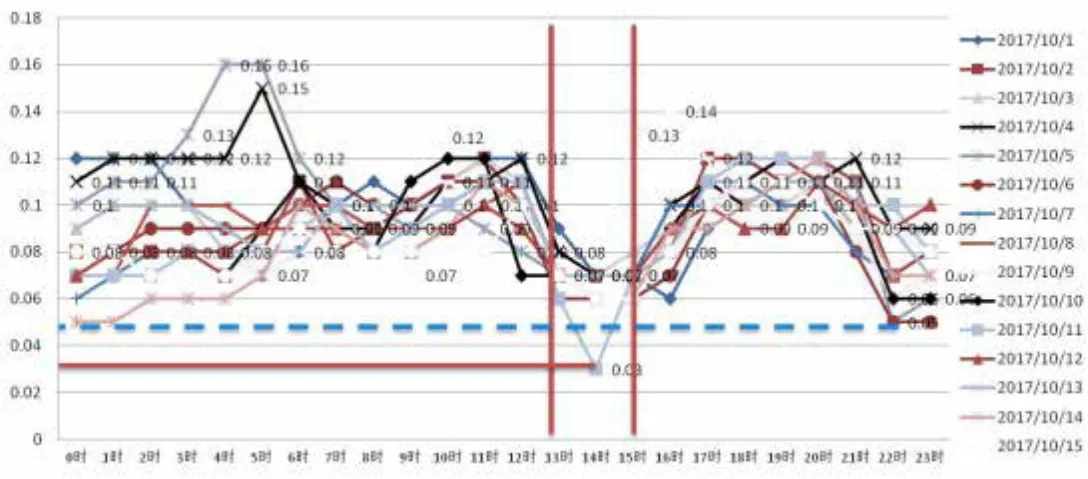
圖5 2018年10月上旬最不利點二路車站圧力曲線
從上半月的壓力大數據挖掘曲線看,每天24小時的波峰、波谷供水時段與水廠調壓時間完全匹配。其中,波峰供水時段06:00~09:00和17:00~21:00,水廠多開一臺機組增壓;反之,波谷時段夜間22:00~05:00時段,水廠關停一臺機組或變頻調壓。另外,下午13:00~15:00花園路泵站高位水池進行補水,導致13:00~15:00的管網壓力下降。可見,供水、用水和壓力變化規律和特點是完全一致的。下半月壓力數據挖掘分析曲線如圖6所示。
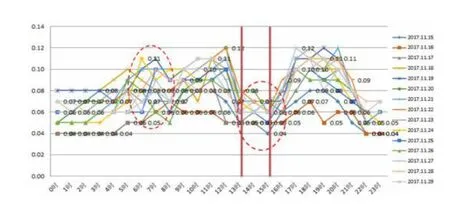
圖6 2018年11月下旬最不利點二路車總站圧力曲線
通過上、下月測壓點壓力曲線對比,波峰、波谷以及波峰、波谷以及13:00~15:00增壓站補水引起的管網壓力曲線變化趨勢完全吻合。
(二)表具尺寸與選型
表具尺寸與選型對新裝水表是十分困難的,但對于在服役的水表進行大數據挖掘分析卻是可行的。計量人員可通過大數據跟蹤、分析用水規律和特性,結合水表特性參數進行分析和優化。以DN80mm垂直螺翼遠傳水表為例,從營業系統統計報表顯示數據,全年平均月用量為20865m3/m,平均小時流量為28.98m3/h,最大流量為41.67m3/h。查詢某品牌的DN80mm垂直螺翼水表的流量參數,常用流量Q3為63m3/h,過載流量為78.75m3/h。如果根據表具尺寸與選型公式0.2Q3~1.5Q3選型,顯然表具口徑是合適的。
為了進一步挖掘分析,保證選型準確性,采用遠傳大數據進行跟蹤和分析,按照恰當、正確大數據挖掘的原則,從遠傳系統中采樣了200個小時的流量數據,結果發現最大流量為為40.71m3/h,最小流量為0m3/h(系統故障),實際上最小流量為7.9m3/h,很顯然也滿足尺寸與選型公式0.2Q3~1.5Q3的要求。一段時間遠傳流量數據圖如圖7所示。
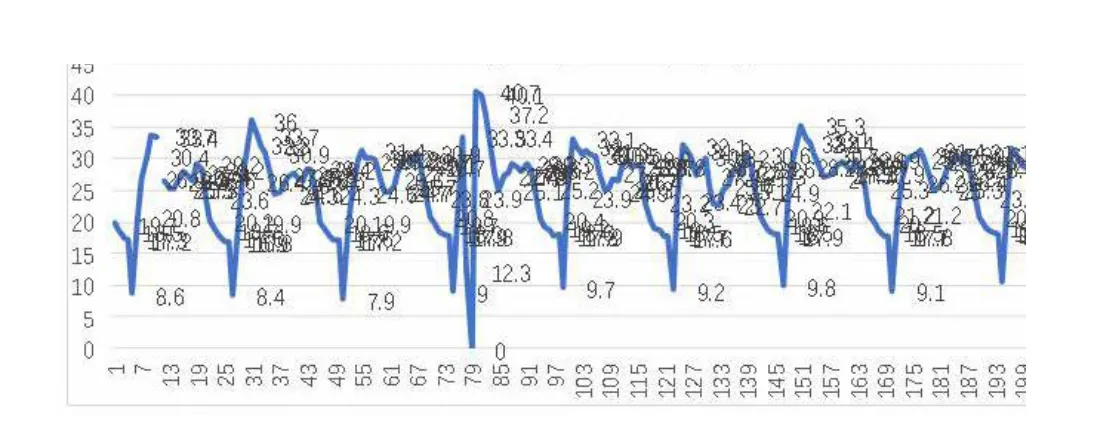
圖7 一段時間遠傳實時數據曲線分析
對全年每小時采樣數據進行清理,剔除掉故障時段數據,進行進一步挖掘分析,結果發現,在全年運行時間范圍內34小時超多了常用流量63m3/h,2個小時超過了過載流量為78.75m3/h,最高流量達到了118.8m3/h。根據表具尺寸選型優化公式0.2Q3~1.5Q3計算,顯然最大流量超出了1.5Q3,選型不合理。按照表具尺寸選型公式,應該上浮一個等級。可見,一年的大數據即可滿足表具選型優化的要求,沒有必要對2以上的數據挖掘分析。
從表具尺寸與選型案例看,顯然需要大數據量級更大一些,才能滿足表具選型的要求。可見,大數據量級大小跟挖掘對象和需求有關,受大數據品質影響,而不是由大數據本身來決定。
通過正、反兩個案例分析和論述,證明大數據挖掘應根據挖掘的對象,需求、數據品質選取。
由此可見,恰當、正確的數據比數據量級更為重要。只要數據的體量、品質能夠滿足數據挖掘應用,滿足尋找規律和商業價值就是當之無愧的大數據。數據挖掘人員要走出“大”的誤區,避免受“大”的拖累。只有滿足挖掘對象和需求的恰當、正確、有價值的數據才是真正的大數據技術。大數據技術本質在價值,而非量級。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
山東工業技術(2016年15期)2016-12-01 05:31:22
信息通信技術(2015年6期)2015-12-26 01:16:46
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
河南科技(2014年23期)2014-02-27 14:18:43
