基于DDPG的仿人形機器人仿真研究
2019-02-10 06:35:14
福建質量管理 2019年24期
(西華師范大學電子信息工程學院 四川 南充 637000)
一、前言
人形機器人步態控制是驗證各種機器學習算法的有效平臺,在現有各種機器學習算法中,為實現人形機器人學會穩定行走,基于強化學習的步態控制算法取得了突破性成功[1]。通過強化學習的思想,讓人形機器人行走時連續的感知周圍環境,根據當前狀態選擇最優動作,最終訓練出能使機器人穩定行走的模型。Timothy等人提出的深度確定性策略梯度算法(DDPG,Deep Deterministic Policy Gradient)取得不錯的效果[2]。本文通過BipedalWalker-v2仿真環境驗證該算法,并對提高環境探索能力的正態分布噪聲的參數進行分析。
二、DDPG算法
DDPG結合DQN(Deep Q-Learning)算法中得緩沖回放模型和目標網絡結構,緩沖回放將一些采樣樣本收集起來,每次優化時從中隨機取出一部分進行優化,從而減少一些不穩定性。目標網絡結構使計算目標價值的模型在一段時間內被固定,從而減少模型的波動性。融合Actor-Critic算法的框架,建立Actor和Critic網絡,Actor網絡用于與環境交互,并產生當前策略,Critic網絡用來評估當前策略。以及DPG(Deterministic Policy Gradient)算法的結論,可以用一個值函數模型來擬合目標函數中得價值估計部分[3]。為提高對環境的探索能力,動作選取公式如式(1),N為正態分布噪聲。
(1)
DDPG算法流程如下:
首先初始化Actor網絡參數θ、θ’,Critic網絡參數ω、ω’,以及經驗回放D,令ω'=ω,θ'=θ。
對每一個回合,循環以下步驟:
(1)初始化S為當前狀態序列的第一個狀態S,拿到其特征向量φ(S);
(2)在Actor當前網絡基于狀態S得到A=πθ(φ(S))+Ν;
(3)執行動作A,得到新狀態S',獎勵R,判斷是否終止狀態,未終止,執行(4);
(4)將{φ((S),A,R,φ((S'),is_end}存入在經驗回放集合D中;
(5)從經驗回放D中均勻采樣m個樣本{φ((Sj),Aj,Rj,φ((S'j),is_endj},j=1,2,…,m,并計算當前目標Q值yj:
yj=rj+γQ'(φ(S'j),πθ'(S'j),ω')
(2)
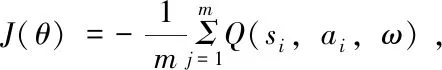
(8)更新目標網絡參數:
θ'←τθ+(1-τ)θ'
(3)
ω'←τω+(1-τ)ω'
(4)
(9)如果S'是終止狀態,當前輪迭代完畢,否則轉到步驟(2)。
三、實驗數據與分析
本次研究仿真部分,使用ubuntu16.04操作系統和Sublime代碼編輯器,仿真環境是OpenAI的Gym環境,深度學習框架是TensorFlow。
(一)BipedalWalker-v2仿真環境
在Gym提供的BipedalWalker-v2環境中,機器人通過調整到比較好的姿態獲得更高的分數。通過讀取場景的信息,環境狀態輸入部分有24個值,包括角速度,水平速度,垂直速度,關節位置,關節角速度,腿與地方接觸的位置,以及10個激光雷達測距儀測量等。每個值得范圍都是從負無窮到正無窮,反饋輸出的動作有4個值,每個值的范圍都是從-1到1,環境信息如表1所示[4]。
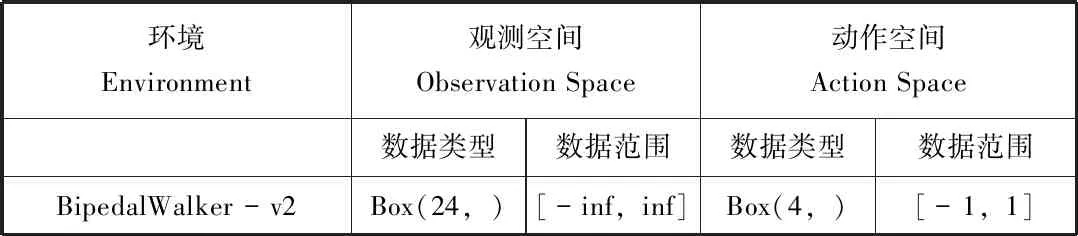
表1 BipedalWalker-v2的信息
(二)仿真結果
1.算法有效性
在BipedalWalker-v2環境中的學習效果如圖1所示,正態分布中標準差最大值為4,最小值為0.001,經過1000輪的學習。可以取得較好的學習效果。
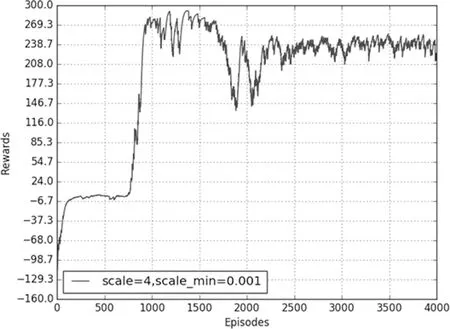
圖1 BipedalWalker-v2仿真結果
2.數據分析
當標準差最大值一定時,改變標準差最小值,仿真結果如圖2所示。當標準差初始值為4時,分別設定標準差最小值為0.01、0.001和0.0001,從圖中可以看到隨著訓練次數的增加,獎勵最后趨于穩定,當標準差最小值為0.01時,在訓練回合到3000時還是會有較大的波動,獎勵值沒有很好的收斂。標準差最小值為0.0001時,獎勵值雖然可以收斂,但是收斂值保持在30左右,沒有獲得較好的分數。標準差的值為0.001時,獎勵值不僅可以收斂還能夠保持較高的分數。這種現象說明,隨著訓練次數的增加,機器人可以逐漸得到較高的獎勵,但是在已經得到高獎勵的情況下,還是以較大的標準差來處理動作值,就會帶來較大的波動,同時若標準差的最小值設置過小,機器人在開始的學習中容易因為探索不夠,會需要更多的學習回合才能獲得較好的獎勵值。在訓練過程中,隨著訓練次數的增加,后期所用的都是標準差最小值,并且因為其獎勵隨訓練回合數的曲線變化是呈鋸齒狀的,若標準差最小值過小,就很可能出現收斂在較小獎勵值的情況。
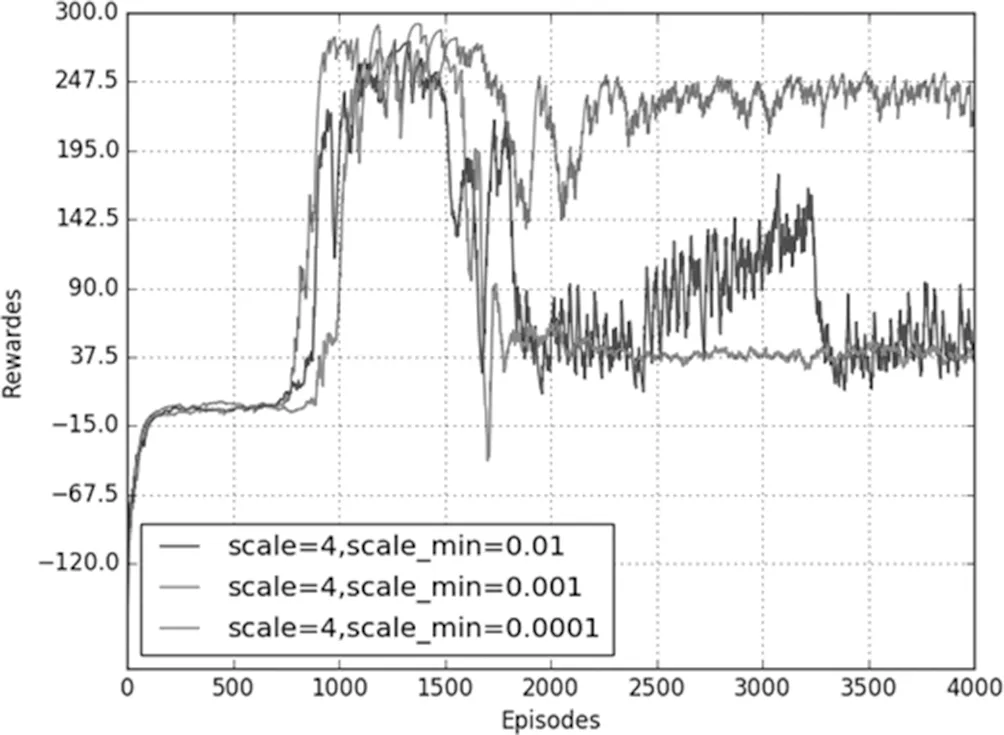
圖2 scale=4仿真結果
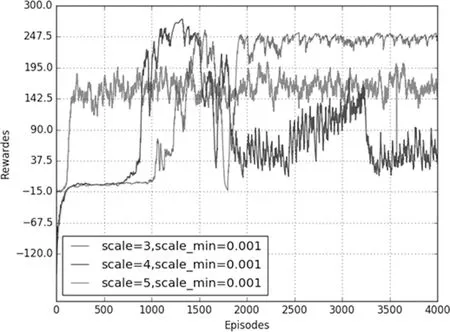
圖3 scale_min=0.001仿真圖
當標準差最小值一定時,改變標準差最大值,仿真結果如圖3所示。從圖中可以看到,當標準差初始值分別為3,4,5時,隨著訓練次數的增加最后都可以收斂,但是它們最后的收斂值來看,標準差初始值為3時收斂值最小,標準差初始化值為4時收斂值在240左右,初始值為5時的收斂值在230左右,并且標準差為4時獎勵最大值相較其他兩種最大。標準差初始值主要是為了在開始訓練的一段時間給機器人較大的動作選擇自由,能夠進行充分的探索,通過嘗試得到獲取高獎勵的經驗,為后期的訓練積累到好的學習經驗。初始值過小會使得機器人還未能有一定的好的學習經驗,但是隨著訓練回合數的增加,給予機器人的自由會逐漸減少至0.001,從而導致它將很難再學習到更好的結果。初始值設置過大,即給予機器人的自由度過大,甚至遠遠超過DDPG模型中原本的動作選取策略,顯然會使DDPG模型的訓練效果大打折扣。
從仿真結果可以得出標準差的最小值在很大程度上影響獎勵是否收斂,標準差的初始值會影響收斂值的大小,它們都是DDPG模型的關鍵參數。調整好這兩個參數的大小,會決定是否能得到好的訓練結果。
四、結束語
本文將深度確定性策略梯度算法用于人形機器人的步態研究,在BipedalWalker-v2環境中驗證該算法的可行性,驗證中發現該算法中,提高對環境探索能力的正態分布參數對于學習效果的影響很大,分別討論正態分布中的標準差和最小標準差對學習效果的影響,以及Batch Size的大小對于學習效果的影響,具有一定的參考意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
光學精密工程(2016年6期)2016-11-07 09:07:19
