關聯規則算法在醫療大數據中的應用探索
2019-02-08 07:35:58李強陳東濤羅先錄
軟件工程 2019年1期
關鍵詞:數據挖掘
李強 陳東濤 羅先錄


摘? 要:隨著中國互聯網越來越快的發展,互聯網+、大數據和人工智能技術等最新科技技術也越來越多的滲透到醫療領域,對于提升多種疾病的篩查和診斷效率作用明顯,而大數據處理技術上仍然面對著許多難題。本課題針對智慧醫療發展的難點之一,將大數據處理技術和醫療海量數據相結合,應用Apriori關聯規則算法在醫療信息系統中海量醫療數據中的應用,發現疾病與其他疾病之間的聯系,從而為人們的健康預警及醫療機構對疾病的診斷提供科學依據參考,本文實驗數據以心肌炎和胃癌為例,發現與病癥相關性強的病因。
關鍵詞:智慧醫療;數據挖掘;關聯規則;醫療大數據
中圖分類號:TP301? ? ?文獻標識碼:A
Implementation of the Association Rule Algorithm in Medical Big Data
LI Qiang,CHEN Dongtao,LUO Xianlu
(Guangdong Neusoft University,Foshan 528225,China)
Abstract:With the rapid development of Internet in China,Internet+,big data,artificial intelligence and other latest technologies are increasingly involved in the medical field,promoting the screening and diagnosis of various diseases.However,there are still many challenges in big data processing techniques.Aimed at the development of smart medical care,this paper combines big data processing technology with massive medical data and adopts the Apriori algorithm in massive medical data in the medical information system,to identify the relationship between one disease and others.Therefore,it provides some scientific evidence and reference for health warning and disease diagnosis in medical institutions.The study is conducted with the experimental data of myocarditis and gastric cancer.
Keywords:smart medical care;data mining;association rules; medical big data
1? ?引言(Introduction)
隨著物聯網、云計算和大數據等各項新技術的高速發展,國家頒布了各項政策以促進醫療服務的發展。促進醫療信息平臺的轉變,以三項技術為核心,以患者數據為連接點,將醫療信息平臺逐步向專業的、便于醫患使用的智慧醫療信息平臺轉變。智慧醫療這個新興的產業已經引起了政府、集團和許多公司的關注,其中代表有推想科技的推想人工智能致力于進行肺癌輔助篩查,騰訊醫療人工智能實驗室推出了一項帕金森病AI輔助診斷新技術等。數據表明人工智能針對一些疾病的診斷效果已經達到甚至超越了傳統的人工治療方案。但至今仍未形成成熟的產業鏈,其中,醫療物聯網已逐步走向產業化,而大數據處理技術上仍然面對著許多難題[1]。
本課題就智慧醫療發展的難點,基于Apriori關聯規則算法在醫療信息系統中海量醫療數據中的應用,研究疾病與疾病之間的關聯,為個人健康提供預警和為醫療診斷提供科學依據參考。
2? ?關聯規則算法(The apriori algorithm)
Apriori算法是一種最有影響的挖掘布爾關聯規則頻繁項集的算法,其核心是基于兩階段頻集思想的遞推算法。該關聯規則在分類上屬于單維、單層、布爾關聯規則。在這里,所有支持度大于最小支持度的項集稱為頻繁項集,簡稱頻集[2]。
關聯規則一般主要分為兩個過程:
(1)基于數據產生頻繁項集,對于每一個頻繁項集來說,該項集在數據集中所出現的頻率必須滿足一定的要求。項集在數據集中出現頻率稱之為支持度,所需滿足的要求稱之為最小支持度。支持度可以表示關聯規則是否普遍適用,通過設置最小支持度來使最終的關聯規則擁有更廣的適用面,也使最終獲得的結果更具有價值[3]。
(2)產生關聯規則,通過所發現的頻繁項集產生規則,計算每一個規則的置信度,規則的置信度若滿足最小置信度,那么這條規則就稱之為關聯規則。置信度的大小表示使用該關聯規則對數據進行推理的準確性。
其中規則的支持度的數學表達式為:
support(AB)=P(A∪B)=supportCount(A∪B)/count(D),其中A和B表示不相交的項集,D表示數據集,supportCount(A∪B)表示A項集和B項集的并集在數據集中出現的次數,count(D)表示數據集的總事務數。置信度的數學表達式為:confidence(AB)=P(A|B)=supportCount(A∪B)/supportCount(A)。如果置信度為100%,意味著在數據集中該規則總是準確的。
最小支持度和最小置信度的閥值一般由用戶或者專家進行設定,滿足這兩個閥值的規則稱為強規則。
例如:年齡≥45歲糖尿病(支持度7%置信度60%)
則表示在所有患者的診療信息中有7%的患者年齡大于等于45歲并且患有糖尿病,其中年齡大于等于45歲的患者中有60%的患者患有糖尿病。由此可見,如果針對醫療信息系統中大量的醫療數據使用關聯規則算法進行挖掘,并能得出一些有趣的規則,那么將對醫療機構關于各種疾病的決策方面有著很大的幫助。
Apriori算法的基本思想是:算法掃描一次數據集,計算每一個項的支持度,找出所有的頻繁1-項集L1,基于L1,產生所有可能頻繁2-項集C2,也就是候選2-項集,再基于C2統計支持度,找出頻繁2-項集L2,如此反復循環,直至發現所有的頻繁項集。
候選項集的產生中使用的方法主要是F_(k-1)×F_(k-1)方法:通過合并兩個上一步獲得的頻繁(k-1)-項集來生成候選k-項集。令F_(k-1)={C_1,C_2,C_3,…,C_(k-1)}和L_(k-1)={D_1,D_2,D_3,…,D_(k-1)}為兩個頻繁(k-1)-項集,當它們的前k-2項相同,且k-1項不同,則合并兩項,獲得候選k-項集,這個方法能有效的避免產生重復的候選項集問題,以及能確保該方法生成的候選k-項集的其余k-2個子集均為頻繁的[4]。
3? ?應用與實現(Application and implementation)
3.1? ?數據的準備和預處理
實際的數據庫極易受噪聲、缺失值和不一致數據的侵擾,因為數據庫太大,并且多半來自多個異種數據源。低質量的數據將會導致低質量的挖掘結果,所以首先需要對原始數據進行數據預處理[5]。主要根據數據分析的任務選擇任務所需的數據對象和屬性,以及對數據進行數據清洗等。本次研究將對系統中門診就診基礎數據表,住院就診基礎數據表中的數據列,如身份證、疾病代碼進行處理,提取所需的數據列數據。數據預處理的過程主要有:
(1)去重處理:為了提高數據分析結果的價值,將數據中完全重復的記錄去掉,屬于去噪的一種。
(2)異常值處理:檢測和處理異常值,可以自行確定一個異常值的標準和方法。如:為避免由于錯誤的身份證信息而導致不同病人之間的疾病歷史混合在同一個記錄中,根據一代身份證位數為15位數,以及二代身份證位數為18位數的特征[6],刪除數據中所有身份證不符合位數要求的數據,并將所有身份證為空的數據刪除;創建省份與身份證前兩位特征碼的對應表,刪除不符合身份代碼對照表的身份證的記錄。
(3)特征提取:根據身份證號碼中的性別特征碼的奇偶性對身份證屬性進行特征提取,創建病人的性別屬性,如圖1所示。
(4)降維處理:創建concat_array存儲函數,以便之后對疾病代碼列進行行轉列操作,降低數據的維度,減輕算法的負擔[7]。函數代碼如圖2所示。
3.2? ?數據挖掘
本文基于Python語言作為編程語言實現關聯規則算法的應用。Python語言的語法清晰,易于操作純文本文件,并且有著豐富的第三方庫,包括numpy、scipy、matplotlib等,使用python語言使本課題關聯規則算法的實現更加快捷簡明,并使用了pycharm和anaconda工具進行開發,利用這兩款工具有效的簡化了本課題中的開發工作流程[8,9]。整個程序主要流程有:
(1)輸入疾病名稱,模糊查詢確認對應的疾病代碼,輸入最小支持度和最小置信度。
(2)對所有患有或曾患有胃癌疾病的患者的記錄根據疾病代碼進行聚合,統計此類患者的各種疾病的記錄數(count(dm)),降序排列,獲取前十條記錄,即獲取此類患者患病較多的前十種疾病,并根據這十種疾病篩選數據,將數據根據身份證進行行轉列。
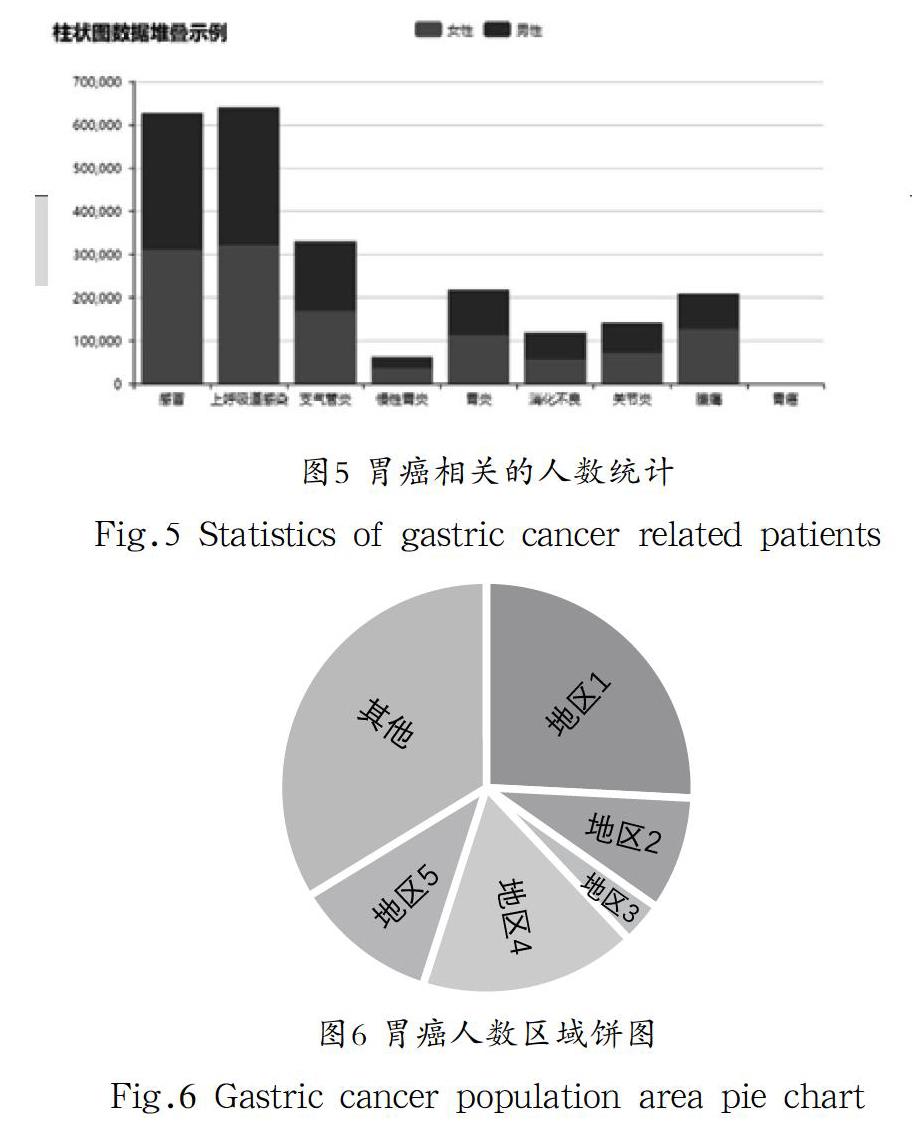
(3)根據性別分別統計每種疾病的患病人數,以及輸入的疾病名稱的地區分布人數,對其進行可視化。
(4)利用Apriori算法對數據進行數據挖掘。
3.3? ?挖掘結果
程序以疾病名稱和代碼作為輸入,并輸出與之關聯的計算結果。
例如:運行程序,輸入心肌炎,輸入對應的疾病代碼編號20,并設置最小支持度為0.001和最小置信度為0.6,進行數據挖掘和可視化。最終得到關聯規則715條,其中的部分挖掘結果如圖3所示。
由于胃癌患者的數量較小,為獲得與胃癌相關的關聯規則,經過多次對支持度與置信度的調整,最終設置支持度為0.00009,置信度為0.5。最終得到關聯規則715條,從中篩選與胃癌相關的關聯規則如圖4所示。
3.4? ?數據可視化
本文分別對男性與女性在與胃癌相關的10項疾病的患病人數進行統計,根據數據調用pyecharts繪制柱狀圖和省份分布地圖,其中柱狀圖的數據包括疾病的名稱,患各疾病的男性人數,患各疾病的女性人數,地圖的數據包括分析的疾病在各省份的人數。最終得到胃癌相關的各疾病男女性患病人數統計條形圖,以及患病人群省份分布圖如圖5和圖6所示。
3.5? ?數據分析
針對胃癌相關的關聯規則結果進行分析可以得出以下結論:
規則第一條:患胃癌的患者性別為男性的置信度約為58.6%。該關聯規則較為符合現今的醫療相關研究及實際醫療診斷情況:男性患胃癌的幾率比女性高。
規則第二條:患胃癌的患者患胃炎的置信度約為67.9%。胃癌是胃黏膜上皮的惡心腫瘤,胃炎是胃黏膜炎癥,胃癌一般都是由胃炎發展而來的。根據數據可視化可以直觀的看到各個疾病中男女性的患病人數比例。
由此可見,該關聯規則算法的程序能夠有效的研究各種疾病與性別,以及其他疾病之間的關聯。
4? ?結論(Conclusion)
本課題利用python實現Apriori關聯規則算法用于分析了醫療數據中疾病與疾病之間關系,發現了疾病之間的關聯規則。通過本課題發現利用關聯規則算法研究醫療數據中疾病之間的關系的數據是有效的。關聯規則算法能發現海量的醫療數據中蘊藏的信息并能得出關聯規則的可信度。該結果能為醫療機構對疾病診斷提供參考,降低疾病的漏檢誤診情況的發生。同時也證明了利用關聯規則算法對醫療大數據進行數據挖掘所得出的結論有重要的參考價值[10]。
同時由于源數據基于規模較小,分析結果并未能很好的展示疾病之間的明顯關系。通過本課題的研究,探討了Apriori關聯規則算法在醫療數據中的應用,可更進一步的結合利用醫療數據中的個人信息和家庭信息數據對疾病相關數據進行研究,針對患者的年齡、地區、家族遺傳、收入情況等數據進行分析,尋找疾病與這些數據間的關聯,為疾病預防和治療提供依據。
參考文獻(References)
[1] 降惠.醫學大數據可視分析研究[J].軟件工程,2017,20(11):1-3.
[2] 程廣,王曉峰.基于MapReduce的并行關聯規則增量更新算法[J].計算機工程,2016(02):21-25;32.
[3] 李慶鵬,張龍軍,耿新元.I-Apriori:一種基于Spark平臺的改進Apriori算法[J].科學技術與工程,2017(12):243-248.
[4] 宋波,楊艷利,馮云霞.基于關聯規則Apriori算法的心肺性職業病病情分析及預測[J].中國數字醫學,2017(04):68-70.
[5] 謝志明,王鵬.基于MapReduce架構的并行矩陣Apriori算法[J].計算機應用研究,2017(02):401-404.
[6] 馬繼剛.第二代居民身份證防偽特征的研究[D].中國人民公安大學學報(自然科學版),2005.
[7] 崔妍,包志.關聯規則挖掘綜述[J].計算機應用研究,2016,33?(02):330-334.
[8] Pang-Ning Tan.數據挖掘導論(完整版)[M].北京:人民郵電出版社,2011.
[9] 曾勇.基于關聯規則的電子病歷挖掘的應用研究[D].廣州:華南理工大學,2012.
[10] 邸書靈,黃琳.關聯規則挖掘在研究生個人學習計劃制定中的應用[D].石家莊:石家莊鐵道學院學報,2007.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
