基于PNN神經網絡的CVT液壓系統故障診斷系統的研究*
2019-01-22 02:22:32左桂蘭
小型內燃機與車輛技術 2018年6期
程 越 左桂蘭
(1-浙江工商職業技術學院 浙江 寧波 315012 2-寧波大紅鷹學院)
引言
無級變速器在汽車的燃油經濟性、動力性和廢氣排放方面較其他變速器有很大程度提高;液壓傳動技術是實現CVT傳動與控制的關鍵技術之一,CVT的液壓系統具備了速比控制、夾緊力控制、離合器變矩控制、傳動潤滑及冷卻等功能,是綜合性的機電液系統,因此液壓系統的運行影響到整個變速器甚至整車的運行狀況[1]。
液壓系統通常故障診斷方法有主觀診斷法、數學模型與信息處理診斷法、智能技術診斷法[2],而CVT液壓系統的故障現象與傳感器信號之間的對應關系呈現復雜的非線性,較難用函數描述,同時以人工經驗為主的無級變速器故障診斷存在故障判斷不準確、維修困難等缺點,基于診斷系統的結構建立的數學模型需要經驗數據得出的狀態模型,進行冗長的計算,造成對其故障體系建模困難。神經網絡有學習和記憶能力,并對環境的變化有很好的適應性,可以解決復雜的非線性問題,通過權值矩陣存儲故障現象與故障信號之間的映射關系,通過樣本數據訓練,神經網絡系統將故障數據通過矩陣運算,判斷出相應的診斷結果[3]。
概率神經網絡(PNN)[4]分類器是一種典型的非線性分類器,融合了密度函數估計和貝葉斯理論,具有訓練速度快、結構簡單等特點,通過計算輸入向量與訓練樣本的距離,競爭函數取舍網絡輸出的概率向量[5]。因此,概率神經網絡分類器適用于模式識別、故障類別分類等。
1 概率神經網絡結構與算法
概率神經網絡結構如圖1所示,該網絡是徑向基神經網絡的一種,通常用于模式分類問題。a1i代表向量a1的第i個元素,R為輸入向量元素的數目,Q為徑向基神經元數(輸入目標樣本數),K是競爭神經元的數目(輸入向量類別數)。首先計算輸入向量與訓練樣本之間距離,產生的輸出向量表示輸入向量與訓練樣本的接近程度,競爭神經元通過Parzen方法求各估計類別的概率,輸出表示概率的向量,最大概率值的類別為1,其余為0。
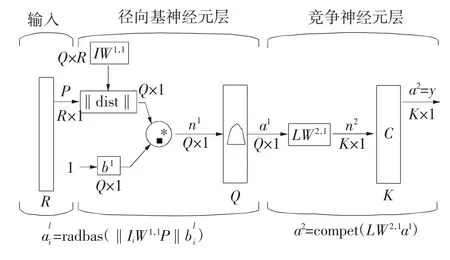
圖1 概率神經網絡結構
圖1 中假設輸入期望值的樣本向量數目為Q,Pi為輸入向量(R×1),輸入以列向量形式組成訓練輸入向量矩陣R×Q;期望值向量為K維,代表模式類別數目,每種分量對應一種模式類別,根據概率值大小,只有最大值分量為1,其余為0,表示所對應的輸入向量屬于與該分量對應一類模式,目標向量組成訓練目標向量矩陣 T(K×Q)[6]。

權值矩陣 IW1,1當中的第 i個行向量為 IiW1,1,將概率神經網絡的第一層徑向基神經元的輸入權值矩陣IW1,1設為Q個訓練樣本對的轉置P′。該神經網絡存在輸入量時,由‖dist‖計算得到一個歐氏距離向量D。
D=(d1,L,dQ),即
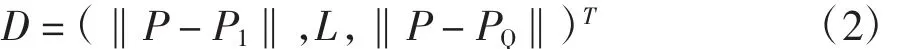
將生成的向量D與偏差向量b1的元素逐個相乘,相乘的結果用n1表示,即n1為徑向量傳遞函數的輸入向量:
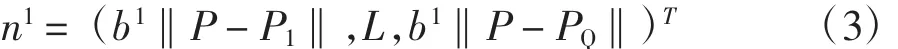
結果傳遞給radbas函數,得到徑向基函數的輸出
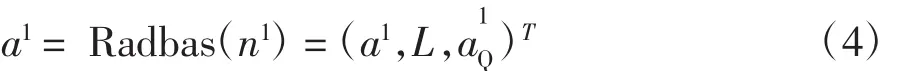
第二層權值矩陣LW2,1設為期望目標響應T。根據競爭原則,權值矩陣的行向量元素中僅有一個元素為1,代表其中一類輸入,經過矩陣乘積計算和競爭傳遞函數計算n2,概率向量n2為
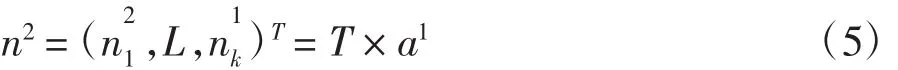
輸入向量P對應模式類別的概率由n2中每一分量數值的大小表示,最后經過一個競爭傳遞函數C輸出,其運算規則為
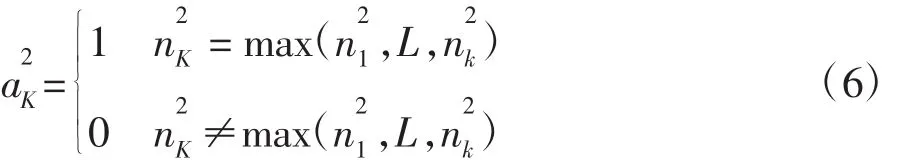
競爭層輸出向量a2對其中最大的元素輸出1,其余元素取為0。從而,概率神經網絡完成對輸入向量的劃分。因此,概率神經網絡可用于CVT液壓控制系統故障的類型識別劃分。
2 CVT液壓控制系統故障邏輯
2.1 CVT液壓控制系統故障樣本
CVT的液壓系統包含了壓力、流量、溫度、油液污染、振動等信號控制系統和液壓動力系統,屬于復雜的非線性動力學系統,而信號系統控制了液壓控制閥的動作,影響了液壓系統效能[7-8]。
CVT液壓控制系統如圖2所示。根據工作要求,液壓泵輸出流量為20 L/min,溢流閥的調定壓力為2.5 MPa。直動式溢流閥、比例換向閥、控制離合器的三位四通閥、齒輪泵、比例減壓閥、液壓缸內泄漏均是液壓系統的故障點,故障表現形式為CVT的金屬帶傳動打滑,前進擋或倒擋離合器無法緊密結合等現象。通過采集各檢測點的壓力、流量、電壓、電流信號等傳感器檢測值,作為概率神經網絡的輸入變量,從而自動判斷出CVT液壓系統故障類型。
此液壓系統常見的故障原因有以下7種:Q1為油泵泄漏;Q2為溢流閥阻尼孔堵死;Q3為換向閥燒壞;Q4為三位四通閥燒壞;Q5為前進擋油缸內泄漏;Q6為倒擋油缸內泄漏;Q7為油泵超負荷。
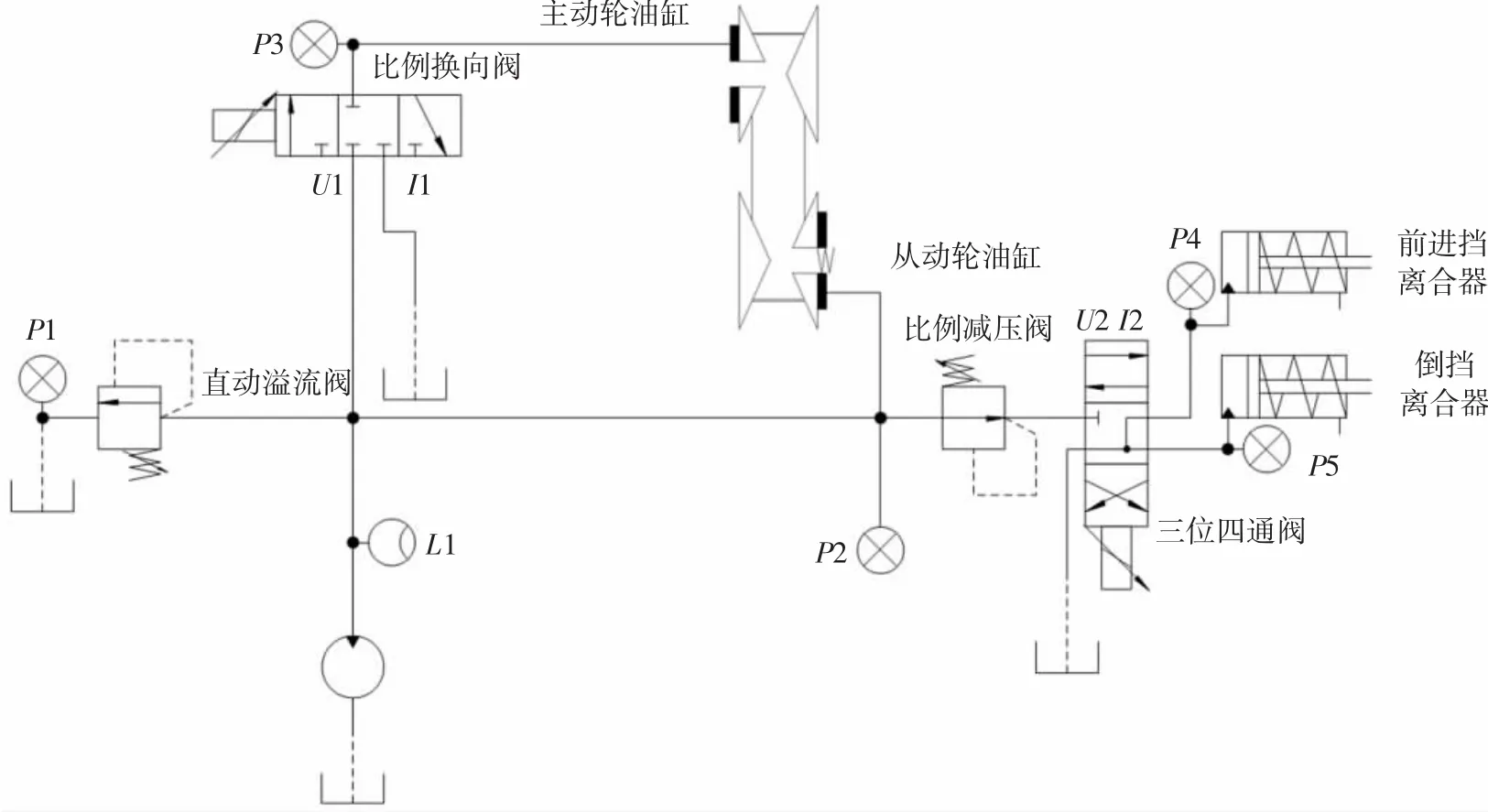
圖2 CVT液壓回路簡化圖
CVT液壓故障診斷系統以壓力P、流量L、電磁閥電壓U和電磁閥電流I等10個傳感器進行信息采集,L1 分別代表齒輪泵輸出流量;P1、P2、P3、P4、P5分別代表回油壓力、系統壓強、主動輪油缸壓強、前進擋離合器油缸壓強、倒擋離合器油缸壓強。利用10個信號參數構成概率神經網絡的輸入層,以1~6的故障類型構成線性輸出層的權值矩陣。
2.2 CVT液壓控制系統概率神經網絡訓練仿真分析
CVT液壓控制系統的故障研究對象為汽車怠速時的液壓系統中壓力、流量、電壓、電流等參數,齒輪泵轉速n=800 r/min時,油泵輸出油壓P>1.8 MPa,流量 Q=3~5 L/min;轉速 n=1 000~2 200 r/min 時,油泵輸出油壓 p=1.9~2.5 MPa;轉速 n=2 200~3 800 r/min時,油泵輸出油壓p=2.5~3 MPa;最大工作壓力不大于4 MPa,6 000 r/min時最大流量為Q=15~22 L/min,倒擋壓力0.6 MPa,前進擋壓力0.97 MPa。
概率網絡的訓練與仿真以MATLAB 2010b語言作為仿真平臺,通過net工具箱進行模型訓練與仿真,網絡輸入層確定為10個參數,在每個實驗故障下,各采集17組振動數據進行實驗研究。
PNN 網絡的創建代碼為:net=newpnn(P,T,SPREAD),其中,P表示網絡的輸入樣本向量,T表示網絡的目標向量,SPREAD為徑向基函數傳播率,默認為1。為了更好地分析學習樣本數量和SPREAD參數對CVT液壓故障診斷系統故障模式識別的影響,仿真過程中學習樣本個數分別為10、20、30,SPREAD 分別設置為 0.1,0.2 和 0.5,如表 1、圖 3、4所示。
圖3~圖4說明PNN網絡學習樣本數量多少影響網絡預測效果,數量越多,模式識別越準確,誤差越小的特點;SPREAD默認值為1.0,其值越大,輸出結果越光滑,相同學習樣本個數條件下,SPREAD值越大導致預測效果下降,模式判斷誤差增大。
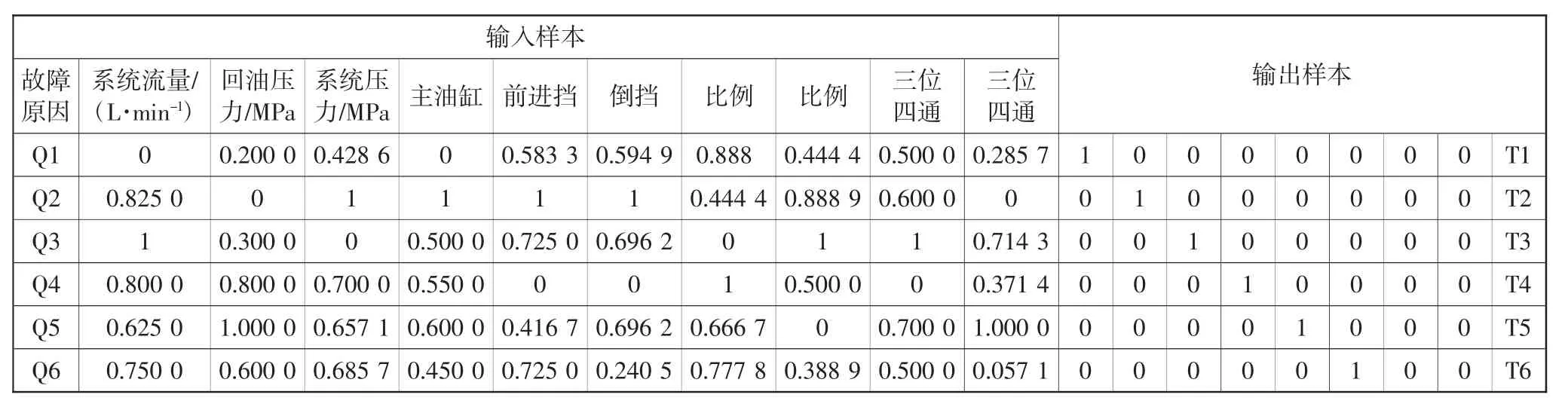
表1 CVT液壓系統故障診斷學習標準化樣本
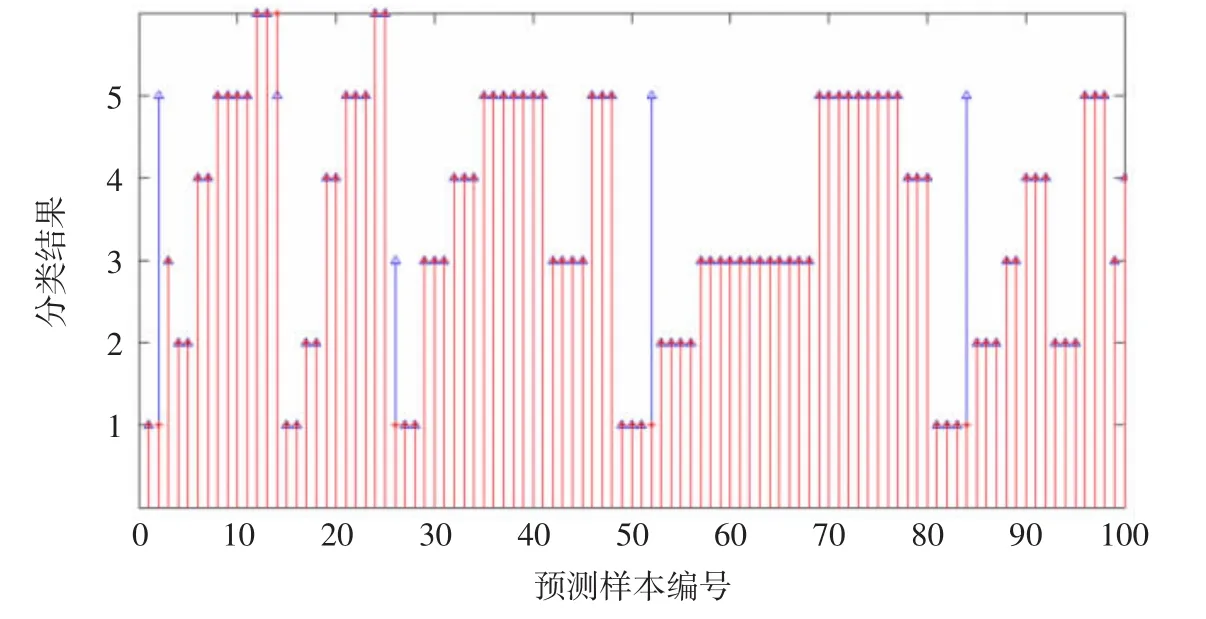
圖3 30個學習樣本SPREAD=0.5的預測圖
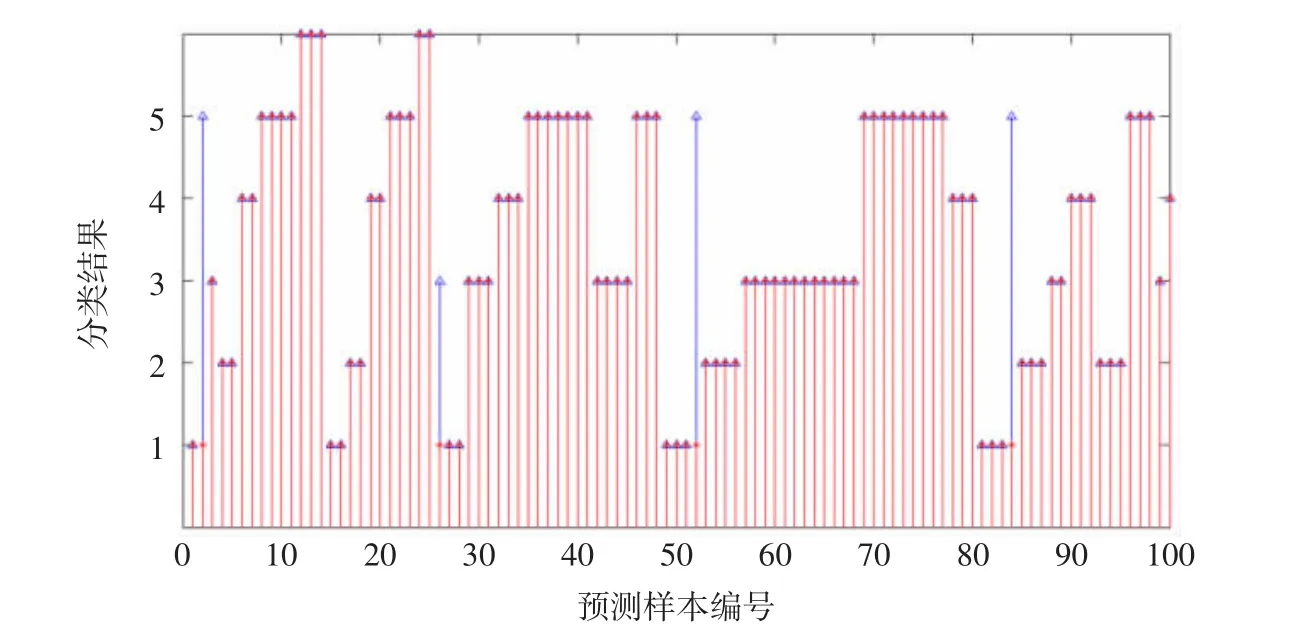
圖4 30個學習樣本SPREAD=0.1的預測圖
不同學習樣本與SPREAD的綜合比較如表2所示。PNN網絡用于CVT液壓系統故障診斷是有效的,該網絡組成的狀態分類器可以有效準確地識別各種運行狀態,為故障檢測提供了有效的工具。
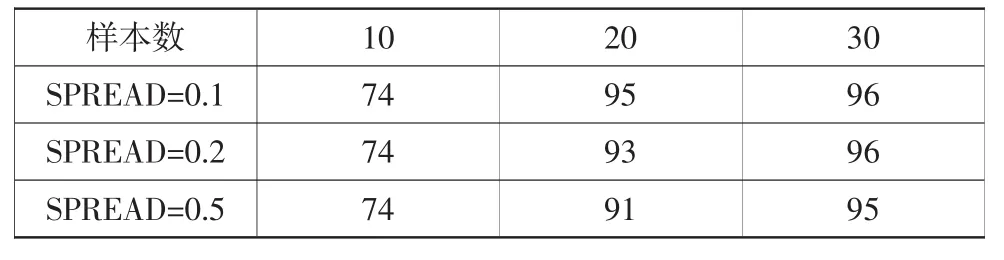
表2 不同學習樣本與SPREAD的綜合比較%
3 結論
本文介紹了PNN網絡的基本原理及貝葉斯分類決策理論,并以某汽車CVT液壓控制系統的液壓回路作為試驗對象,對該液壓系統的故障模式學習樣本學習及測試樣本預測。通過仿真實驗結果證明PNN網絡具有極強的非線性處理能力,在不同的學習樣本數量下,故障診斷率逐步提升,并可以通過故障知識積累與不斷學習提高診斷精度。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
汽車維修與保養(2019年7期)2020-01-06 03:30:42
家庭影院技術(2017年9期)2017-09-26 03:41:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
