基于BiLstm神經網絡的DGA域名檢測方法
2019-01-18 01:10:36林思明陳騰躍梁煜麓
網絡安全技術與應用 2019年1期
◆林思明 陳騰躍 梁煜麓
基于BiLstm神經網絡的DGA域名檢測方法
◆林思明 陳騰躍 梁煜麓
(廈門安勝網絡科技有限公司 福建 361008)
DGA域名檢測是檢測僵尸網絡C&C通信的關鍵技術之一,傳統的檢測方法通常是基于黑名單過濾、統計特征。傳統檢測方法存在大量瓶頸,包括:特征提取繁瑣,自動化程度低,編碼實現難度較高,檢測率偏低以及誤報率偏高等。針對上述問題,提出一種基于BiLstm神經網絡的DGA域名檢測方法。首先,采用詞袋模型對域名進行處理,將字符類型的域名轉換為適合BiLstm神經網絡的輸入數據,然后基于BiLstm神經網絡設計適合DGA域名檢測的各層神經網絡的參數,構建能夠實現DGA域名的特征自主學習的最優檢測模型,從而實現DGA域名的檢測。所提方法能夠自動提取DGA域名的特征,完全脫離人工特征提取;實現較高的檢測率以及較低的誤報率。
神經網絡;域名檢測
0 引言
隨著互聯網使用不斷的普及,以僵尸網絡為代表的惡意域名攻擊數量也在不斷的增長。僵尸網絡(BotNet)是指使用將大量僵尸主機(Bot)感染病毒,通過命令與控制服務器(Command and Control Server,C&C Server)形成一個可一對多控制的網絡。攻擊者通過使用多個域名鏈接到C&C服務器,以達到操作入侵設備的目的。2017年中國互聯網網絡安全報告指出聯網智能設備惡意程序控制服務器IP地址約1.5萬個,位于境外的IP地址占比約81.7%;被控聯網智能設備IP地址約293.7萬個,其中控制規模在1萬個以上的僵尸網絡39個,5萬個以上的5個,其余的均為10到10000不等的僵尸網絡。由此可見僵尸網絡對網絡安全運行和用戶數據安全都是極具威脅的存在。
惡意域名的檢測是遏制僵尸網絡的主要手段之一,為了躲避域名黑名單檢測技術手段,一種利用隨機字符來生成C&C域名算法應運而生,簡稱DGA。因此DGA域名檢測成為檢測僵尸網絡C&C通信的一個重要的環節。
傳統的DGA域名檢測通常是基于黑名單過濾、統計特征。傳統的DGA檢測方法存在特征提取繁瑣,自動化程度低,編碼實現難度較高,檢測率偏低以及誤報率偏高等瓶頸。針對上述問題,本文提出一種基于BiLstm神經網絡的DGA域名檢測方法。首先,采用詞袋模型對域名進行處理,將字符類型的域名轉換為適合BiLstm神經網絡的輸入數據,然后基于BiLstm神經網絡設計適合DGA域名檢測的各層神經網絡的參數,構建能夠實現DGA域名的特征自主學習的最優檢測模型,從而實現DGA域名的檢測。針對DGA域名檢測實驗表明,本文所提方法很好的解決了傳統DGA域名檢測存在的瓶頸,取得了較好的檢測結果。
1 基于BiLstm神經網絡的DGA域名檢測
1.1 域名分析
一個完整的域名由兩個或者兩個以上部分組成,各個部分使用英文的句號”.”分隔。至少包含一個頂級域名和一個二級域名。例如: baidu.com; 由一個頂級域名com和一個二級域名baidu組成。域名的最后一個"."的右邊部分稱為頂級域名或一級域名(TLD),最后一個"."的左邊部分稱為二級域名(SLD) ;以英文的句號”.”為分隔符,以此類推二級域名的左邊部分為三級域名,三級域名的左邊部分為四級域名。DGA域名是由字符和數字結合隨機算法生成的頂級域名除外的部分。因此本文在后面提到的域名均是不考慮頂級域名部分,只對除了頂級域名外的部分進行特征提取。
1.2 域名詞袋處理
由域名分析剔除頂級域名后,引入詞袋模型對域名進行處理,構建適合BiLSTM神經網絡的輸入數據。
域名自身字符串包含豐富的詞法特征,與自然語言非常相似,適合用自然語言的處理方式。而詞袋(BoW)模型就是將自然語言中的詞進行數學化的一種方式。

圖 1 域名結構
BoW可以理解為一種直方圖統計,是用于自然語言處理和信息檢索中的一種簡單的文檔表示方法。 BoW模型忽略掉文檔的語法和語序等要素,其只是作為若干詞匯的集合,在文檔中每個單詞的出現都是獨立的。
由域名分析可得到域名是由0到9;a到z;英文句號”.”;符號”_”及符號”-”組成,共38個符號,為此形成如下圖2所示的詞袋。

圖 2 詞袋
通過詞袋模型,把域名轉化為適合BiLstm神經網絡的輸入數據,轉換原理如圖3所示。轉換過程中,域名的長度限制為100個字符;當域名長度不夠100個字符時,轉換時使用數值40進行填充。

圖 3 轉換原理
1.3 BiLstm神經網絡
目前檢測DGA域名的方法主要有傳統的統計特征和基于深度學習。相比較于傳統的統計特征,深度學習模型擁有優秀的自動特征提取能力。
LSTM 是深度學習模型中一種特殊的RNN模型,可用于學習長期依賴信息,處理序列數據,在文本分類、翻譯等領域廣泛使用。LSTM 通過刻意的設計來避免長期依賴問題,它是從左往右推進的,就像傳送帶一樣,將信息從上一個單元傳送到下一個單元,和其他部分只有很少的相互作用。圖4為LSTM的推導圖及計算公式,其整體的推導過程和RNN是一致的,唯一的區別在于LSTM的每個神經元。圖5為LSTM每個神經元內部推導圖及計算公式,LSTM巧妙的在每個神經元的內部增加了輸入門限,遺忘門限和輸出門限,使得自循環的權重發生變化。輸入門限,一個Sigmoid層,觀察ht?1和xt,對于神經元狀態ct?1中的每一個元素,輸出一個0~1之間的數,1表示完全保留該信息,0表示完全丟棄該信息。遺忘門限,一個Sigmoid層決定我們要更新哪些信息,并由一個tanh層創造了一個新的候選值,結果在(-1, 1)(?1,1)范圍。輸出門限,控制哪些信息需要輸出。
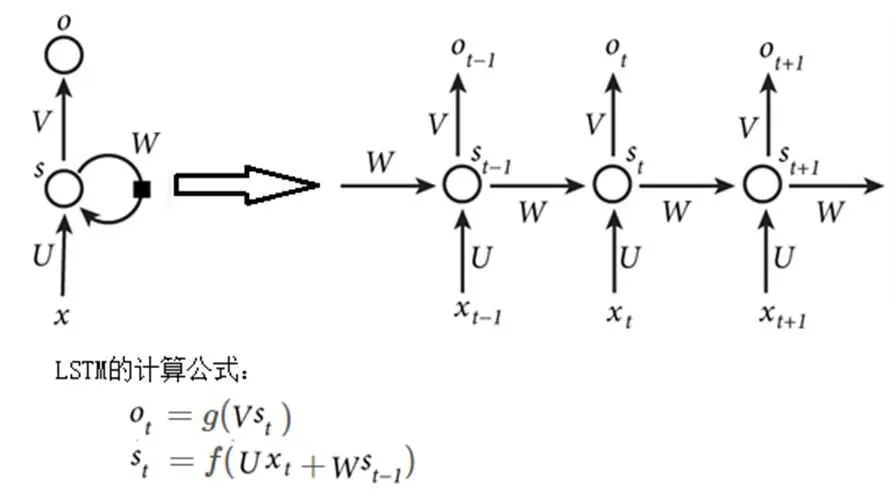
圖 4 LSTM的推導圖及計算公式
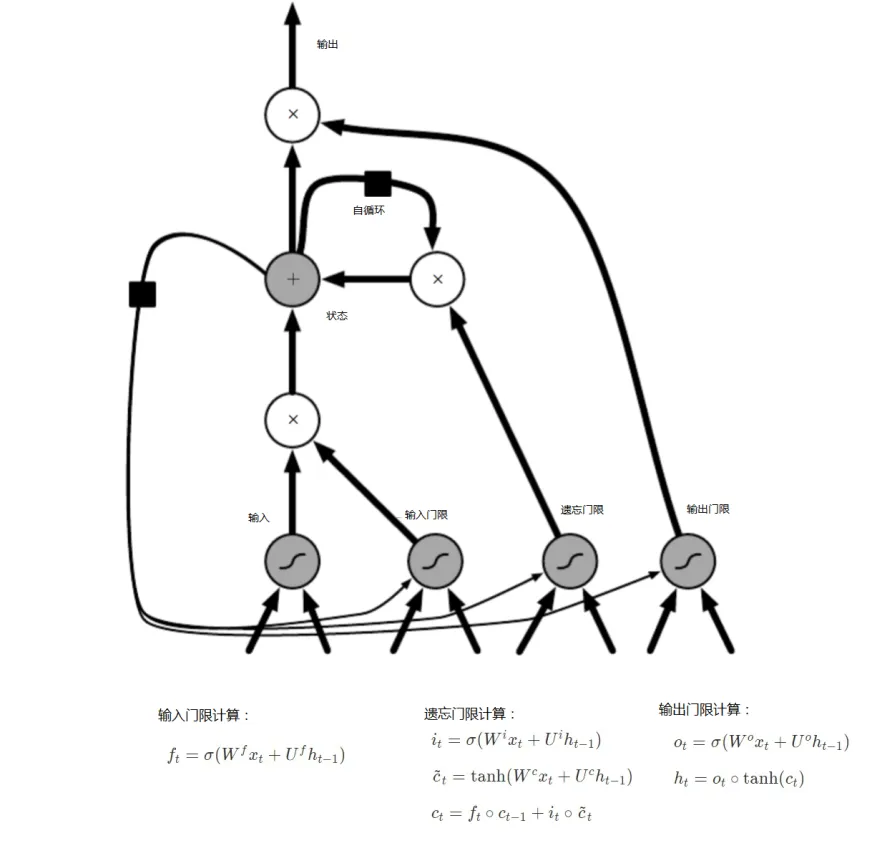
圖 5 LSTM每個神經元內部推導圖及計算公式
BiLSTM是在LSTM的基礎上演變而來的;與LSTM相比較,BiLSTM同時考慮了過去的特征和未來的特征,使用兩個LSTM,一個正向輸入序列,一個反向輸入序列,再將兩者的輸出結合起來作為最終的結果。BiLSTM的隱藏層需要保存兩個值,一個參數Ci參與正向計算,另一個參數C′i參與反向計算,最終輸出的yi取決于Ci和C′i。圖6為BiLSTM的推導圖及計算公式。
在1.2節中,使用Bow模型處理DGA域名,使得域名中的每個字符變得獨立,字符所在域名中的語法和語序被隱藏起來,而BiLstm可以很好的保留文檔的過去特征、未來特征和時序特征,完美解決了該問題,使得DGA域名中的每個字符的語法和語序重新顯現。
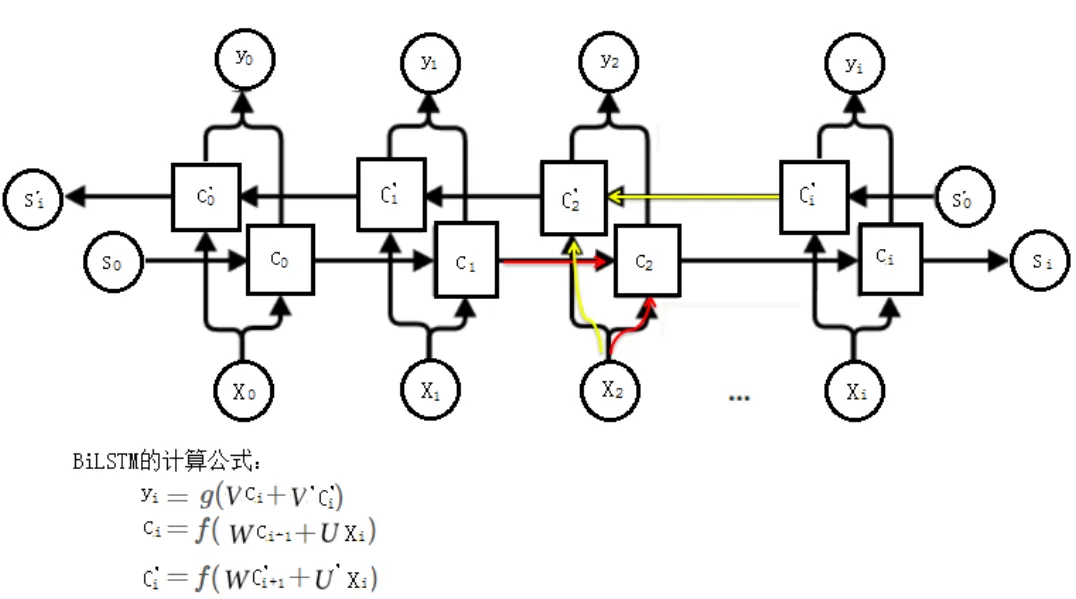
圖 6 BiLSTM的推導圖及計算公式
2 實驗與結論
(1)實驗數據集
本文實驗數據集包含正域名樣本和負域名樣本,正域名樣本主要來自于Alexa網站收集的前100萬的域名;負域名樣本使用360開源的前100萬的DGA域名,并且給正負樣本標注相應的分類標簽。Alexa收集的前100萬的域名為正樣本,標注為0;360開放的前100萬的DGA域名為負樣本,標注為1。對所使用的域名數據集進行數據劃分為訓練集160萬個、驗證集20萬個、測試集20萬個;訓練集、驗證集和測試集的正負樣本各一半。
(2)實驗調參
本文使用的是Keras框架結合Tensorflow進行實驗。經過反復的實驗,最終選取最佳參數值為:學習率a=0.1;訓練輪數epochs = 200;訓練batch_size = 512;Dropout = 0.5;激活函數使用sigmoid;整個網絡模型如圖8所示。
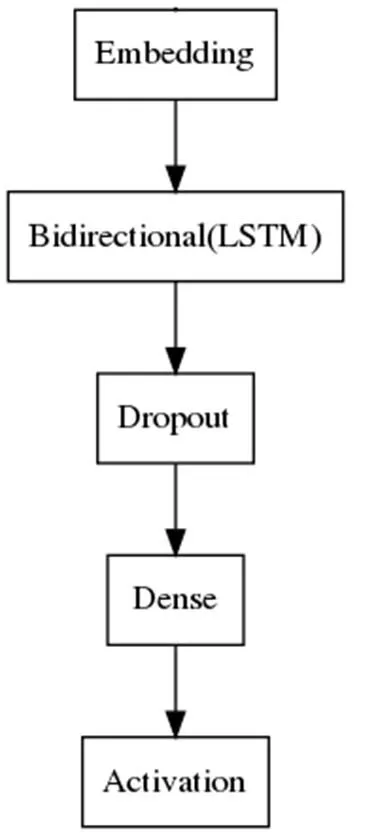
圖 8 網絡模型
(3)實驗結果分析
本文在相同的數據集的基礎上進行了兩組實驗,兩組實驗的區別在于一個使用了LSTM一個使用BiLSTM;表1是兩個模型訓練檢測率和測試檢測率。

表1 兩個模型訓練檢測率和測試檢測率
從表1的實驗結果可以得出BiLSTM的效果要明顯優于LSTM。LSTM對域名的每個字符產生的向量的處理方式都是一樣的,即使不同域名在不同位置的相同字符所產生的向量也是一樣的。而BiLSTM把字符的位置及未來特征等都考慮在內;結合了位置關系的BiLSTM比沒有結合位置關系的LSTM的識別率提高了0.07。
整個實驗的過程中,僅僅是將實驗數據進行標識和數據集劃分,沒有建立任何依賴人工提取特征的工程,完全實現自動提取DGA域名的特征。
實驗使用的BiLSTM神經網絡方法取得了較好的效果,訓練檢測率達到99.54%,測試檢測率達到99.41%。
3 結束語
本文針對傳統的DGA域名檢測方法所存在的瓶頸,提出了基于BiLstm神經網絡的DGA域名檢測方法,并且對該方法進行了實驗。通過實驗的過程和實驗結果驗證了該方法能夠有效的解決傳統的DGA域名檢測方法所存在的特征提取繁瑣,自動化程度低,編碼實現難度較高,檢測率偏低以及誤報率偏高的問題。
[1]Bidirectional LSTM-CRF Models for Sequence Tagging.
[2]End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF.
[3]QUIRK C,MOONEY R,GALLEY M.Language to code:Learning semantic parsers for if-this-then-that recipes[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics(ACL-15).Beijing, China:ACL,2015:878-888.
[4]J.Lafferty, A.McCallum,and F. Pereira.2001.Conditional random ?elds: Probabilistic models for segmenting and labeling sequence data. Proceedings of ICML.
[5]AlexGraves.SupervisedSequence Labelling with Recurrent Neural Networks.Textbook,Studies in Computational Intellige nce,Springer,2012.
[6]張維維.基于詞素特征的輕量級域名檢測算法[J].軟件學報,2016.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
