基于聚類和XGboost算法的心臟病預測①
2019-01-18 08:30:34劉宇,喬木
計算機系統(tǒng)應(yīng)用 2019年1期
劉 宇, 喬 木
1(南京烽火天地通信科技有限公司, 南京 210019)
2(武漢郵電科學研究院, 武漢430074)
早在上個世紀初, 心臟病就已經(jīng)成為人們對于健康隱患關(guān)注的焦點. 全世界每年約有1750萬人死于心臟病及其并發(fā)癥, 占全部死亡人數(shù)的1/3; 而我國社會開始進入老年化階段, 老齡化趨勢明顯, 患有慢性病的人群(如患有心臟病和血壓不穩(wěn)定人群)也逐漸增長.對于慢性病患者而言, 他們的生命體征數(shù)據(jù)應(yīng)該進行實時監(jiān)測, 否則會嚴重影響醫(yī)生的準確診斷.
目前, 大部分醫(yī)療機構(gòu)對于心臟病的檢測診斷還是以醫(yī)生個人經(jīng)驗和體檢結(jié)果為標準. 不僅在人工上花費很高, 也會延誤患者最佳就診時間, 但是, 如果可以以機器學習的方法作為輔助診斷, 為臨床診斷提供有效精準的指導幫助, 將會很大程度的提高診斷的科學性. 而且現(xiàn)在大數(shù)據(jù)時代下的技術(shù)融合屢見不鮮, 利用機器學習來輔助心臟病診斷和預測會是一個值得研究的問題.
近年來, 陳天奇對GBDT (Gradient Boosting Decision Tree)算法進行改進[1], 提出了一種設(shè)計高效、靈活并且可移植性強的最優(yōu)分布式?jīng)Q策梯度提升庫 XGBoost (Extreme Gradient Boosting, XGBoost), 其原理是通過弱分類器的迭代計算實現(xiàn)準確的分類效果,本文將XGBoost 引入到心臟病預測中, 分析用戶在醫(yī)療平臺的檢查數(shù)據(jù)信息建立分類預測模型, 從而個作為醫(yī)生的輔助判斷. 實驗結(jié)果表明, 所提出的基于聚類和XGboost算法的預測方法的可行性和有效性, 為就醫(yī)推薦等應(yīng)用提供了精準有效的幫助.
1 方法
1.1 數(shù)據(jù)預處理
因為數(shù)據(jù)是從真實場景下獲取的, 所以大體上并不完整, 不能夠直接應(yīng)用于實驗訓練, 因此正需要數(shù)據(jù)預處理來解決這一問題。所謂預處理就是對不標準的數(shù)據(jù)進行類型變換, 除去空值等操作[2], 本次實驗的數(shù)據(jù)包括14個特征, UCI開源數(shù)據(jù)集某醫(yī)院的300個心臟病患者體側(cè)數(shù)據(jù)和一萬個經(jīng)過數(shù)據(jù)清洗的某健康A(chǔ)pp的用戶調(diào)查數(shù)據(jù). 而本次算法模型的應(yīng)用場景是根據(jù)這些特征對樣本進行預測, 并判斷是否患病. 樣本是否患病是一個分類問題, 正好符合本文模型的應(yīng)用標準,因為本次算法模型選用的是線性模型邏輯回歸, 全部特征的值對應(yīng)的都是double型, 且不能為空.
(1) 二值類的數(shù)據(jù)
這類數(shù)據(jù)通常只有兩個值, 如性別字段有兩種表現(xiàn)形式female和male, 我們可以將female表示成0,把male表示成1.
(2) 多值類的數(shù)據(jù)
比如表示胸部的疼痛感的cp字段, 我們可以通過疼痛的由輕到重映射成1~4的數(shù)值以及缺陷種類可以劃分0~10個不同的等級, 并以此處理為訓練可用的數(shù)據(jù).
(3) 去空的數(shù)據(jù)
在實際情況下的患者的檢查數(shù)據(jù)中, 會有部分檢查項未填或者未進行, 該特征會為空, 在數(shù)據(jù)中會以?表示, 我們就需要去掉有空值的那行數(shù)據(jù), 去噪, 保持訓練模型的精準性.
第一步和第二步的處理通過sql腳本來實現(xiàn), 最后一步去空則是在Python里遍歷每一行進行操作. 處理過后的數(shù)據(jù)特征包括年齡, 性別, 胸部疼痛, 血壓,膽固醇,心電圖,最大心跳等14個變量. 變量列表如表1所示.
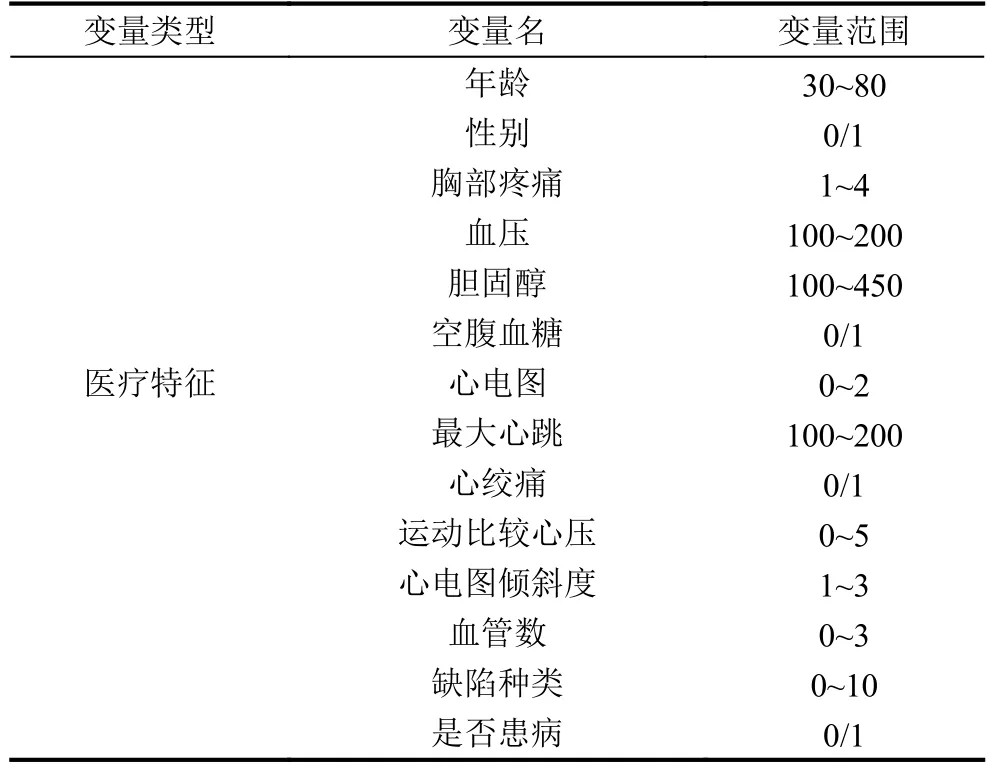
表1 變量名列表
1.2 聚類算法
本文引用的聚類算法是K-means 算法, K-means算法中的K代表類簇個數(shù), means代表類簇內(nèi)數(shù)據(jù)對象的均值(這種均值表示的是類簇中心)[3]. K-means算法是一種經(jīng)典的聚類算法, 此算法以數(shù)據(jù)對象之間的距離作為聚類標準, 即數(shù)據(jù)對象之間距離越小則表示這類數(shù)據(jù)擁有較高的相似度, 就會朝著一個中心點聚集, 距離越大則作用相反. 而數(shù)據(jù)對象的間距通常用歐氏距離來計算. 算法流程就是一直重復這一計算過程到標準測度函數(shù)收斂為止. 給出聚類K和數(shù)據(jù)子集
K-means算法的基本思想[4]如下:
步驟1. 隨機選擇K作為初始質(zhì)心點;
步驟2. 對于所剩下的對象, 則根據(jù)它們與這些聚類中心距離, 分別將它們分配給與其最相似的聚類;
步驟3. 計算每個所獲新聚類的聚類中心;
步驟4. 如果滿足了標準, 就停止步驟, 否則轉(zhuǎn)回步驟 2, 直到條件滿足.
停止條件如下: 沒有需要分配的任務(wù)到不同的簇,質(zhì)心不再發(fā)生變化, 或者均方誤差值下降幅度很小, 其計算式:
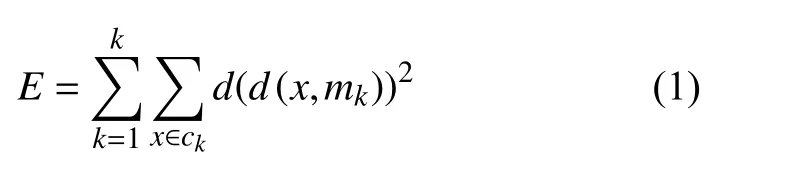
其中,ck是第k個簇,mk是簇ck的質(zhì)心,是x和質(zhì)心mk之間的距離[5], 在本文提出的方法中, 歐氏距離是每個目標點到簇中心的距離:

本文使用K-means算法是為了分割數(shù)據(jù)集, 因為海量數(shù)據(jù)會對模型精準度產(chǎn)生影響, 根據(jù)某個特征做聚類分成若干的小數(shù)據(jù)集, 可以使模型更加準確.
1.3 XGboost算法
XGBoost 是一種改進的 GBDT 算法, GBDT 是2001 年Friedman 等人提出的一種Boosting算法. 它是一種迭代的決策樹算法, 該算法由多棵決策樹組成, 所有樹的結(jié)論加起來作為最終答案[6]. 而XGBoost算法與GBDT 有很大的區(qū)別. GBDT 在優(yōu)化時只用到一階導數(shù), XGBoost 則同時用到了一階導數(shù)和二階導數(shù), 同時算法在目標函數(shù)里將樹模型復雜度作為正則項,用以避免過擬合[7].
XGBoost 算法目標函數(shù):

根據(jù)泰勒公式[8]展開:
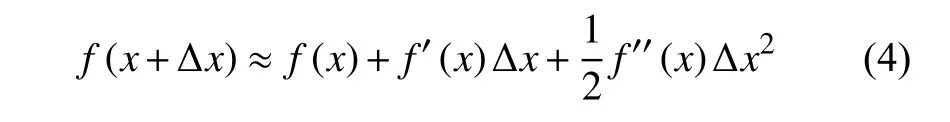
同時令:

決策樹復雜度[9]計算公式:

將式 (4)、(5)、(6)代入式 (3), 求得目標函數(shù):


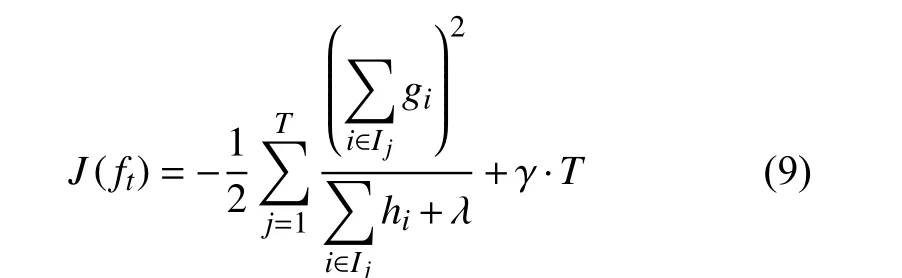
不過通過解得的目標函數(shù)來尋找出一個最優(yōu)結(jié)構(gòu)的樹, 加入到模型中, 通常情況下枚舉出所有可能的樹結(jié)構(gòu)是不可能的, 因此最后會使用貪心算法來尋找最優(yōu)的分割方案, 也就是一種分割尋找算法, 這個算法稱為精確貪心算法[11].
2 模型流程
2.1 流程實施
本文提出的基于聚類和XGboost算法的心臟病預測模型, 數(shù)據(jù)集是取自UCI開源數(shù)據(jù)集某醫(yī)院的300個心臟病患者體側(cè)數(shù)據(jù)和一萬個經(jīng)過數(shù)據(jù)清洗的某健康A(chǔ)pp的用戶調(diào)查數(shù)據(jù). 模型流程是將輸入值通過K-means算法進行聚類, 找到對應(yīng)某特征不同分段的類, 并將數(shù)據(jù)離散化分開成單獨的簇, 每個簇經(jīng)過XGboost算法訓練和測試得到預測的輸出值. 算法包括數(shù)據(jù)預處理、任務(wù)構(gòu)造、數(shù)據(jù)離散、模型訓練和結(jié)果分析5個部分, 如圖1所示.

圖1 基于聚類和XGboost算法的心臟病預測模型
步驟一. 拿到初始數(shù)據(jù)后, 對初始數(shù)據(jù)做預處理,即對數(shù)據(jù)進行去噪、填充缺失值、類型變換等操作. 獲得一個相對完整可用于訓練模型的數(shù)據(jù)集.
步驟二. 選定一個與心臟病判斷相關(guān)的特征, 如本文選取了膽固醇(chol)來作為K-means 算法的聚類特征, 因為膽固醇特征與本文的心臟病預測模型并無直接聯(lián)系, 且數(shù)據(jù)跨越度大, 聚類區(qū)分效果明顯, 很適合作為實驗特征對象. 根據(jù)目標估計值構(gòu)造k個學習任務(wù)t+1,t+2,···,t+n,n≤h,針對每個任務(wù)對應(yīng)的輸出值,分別從數(shù)據(jù)集通過K-means 算法聚類. 本文選取k值為3, 并找到3個聚類的中心點. 根據(jù)數(shù)據(jù)離散化, 即統(tǒng)計學習中最大熵的原理, 將數(shù)據(jù)分成指標程度為高中低的3個數(shù)據(jù)集. 因為訓練模型時, 在所有可能的概率模型中, 熵最大的模型是最好的模型, 通常用約束條件來確定概率模型的集合, 所以最大熵原理也可以表述為在滿足約束條件的模型集合中選取熵最大的模型[12].如本文所確定膽固醇指標的聚類中心在212和291兩處, 所以我們的數(shù)據(jù)集應(yīng)該是小于 212, 212 至 291, 大于291, 分別對應(yīng)低中高三類數(shù)據(jù)集.
步驟三. 將N個任務(wù)的訓練集同時訓練XGboost模型, 得到最終的預測模型.
步驟四. 將離散化過后的數(shù)據(jù)集以測試集和訓練集比例1:4分割, 將n個任務(wù)相應(yīng)的測試樣本輸入訓練好的XGboost模型, 可同時得到n個估計值, 最后從中選擇需要的估計值. 選取需要的估計值之后, 即可以與實測數(shù)據(jù)進行對比, 從而得出本文算法預測的精確情況.
3 實驗結(jié)果與分析
3.1 評價標準
評價分類器性能的優(yōu)劣通常是用分類準確率(Accuracy), 精確率 (Precision)與召回率 (Recall), 準確率(Accuracy)表示的是對于給定的測試數(shù)據(jù)集,分類器正確分類的樣本數(shù)與總樣本數(shù)之比[13], 精確率(Precision)通常表示的是預測是正例的結(jié)果中, 實際為正例的比例. 召回率(Recall)表示的是實際為正例樣本中, 預測也為正例的比例. 通常以關(guān)注的類為正類, 其他類為負類,分類器在測試數(shù)據(jù)集上的預測是否準確, 如表2所示.

表2 分類結(jié)果混淆矩陣
樣本預測的Accuracy、Recall和F1 值作為評價指標其公式[14,15]如下:

其中,P為陽性樣本總數(shù),TP為正確預測的陽性樣本數(shù)量,NP為錯誤預測的陽性樣本數(shù)量. 同時, 對于大量樣本的數(shù)據(jù)處理, 算法模型的運算速度也是重要的評價指標. 本實驗在個人計算機(CPU: Intel i7 7700HQ 2.8 GHz; RAM: 16 GB)上運行, 用 Python 包的time.time()函數(shù)[16]記錄時間模型運行前后時間差, 即為運行時間,方便運行效率比較.
3.2 結(jié)果比較分析
通過調(diào)參后得到的三種算法的最佳模型, 并且拿到測試樣本對測試集進行預測, 以分類器評價標準對三種算法的各個方面作比對, 比對結(jié)果如表2所列. 實驗結(jié)果表明, 在三種分類算法中, 以XGBoost算法訓練的模型只是在準確率上稍遜隨機森林算法, 而在運行速度方面顯著優(yōu)于隨機森林算法. 而以SVM算法為基礎(chǔ)的模型在原理上相對簡單, 盡管運行速度與XGBoost算法訓練的模型相近, 但是準確率卻大大不如前者優(yōu)秀. 因此經(jīng)過最后的交叉比較以XGBoost算法訓練的模型具有準確性較高, 運行速度快等優(yōu)勢. 經(jīng)過這樣的交叉比較, 突出了XGBoost算法在分類預測上的高效性.

表3 運行結(jié)果比較
但是單純的使用XGboost算法, 在實際應(yīng)用場景中可能不能達到最好的預測效果, 因為龐大的數(shù)據(jù)集也需要模型的準確性, 因此對數(shù)據(jù)集做了分割, 以高中低三種指標分別訓練模型提高精確性, 根據(jù)表4的直觀分析, 分別訓練的三種模型在準確率上確實基本比初始模型要高, 在召回率上L模型和H模型表現(xiàn)的較為優(yōu)秀. 而F1值也都差別不大. 因為都是使用的同一算法, 所以運行時間上不會有太大的差別. 綜合三個數(shù)據(jù)集所訓練的模型數(shù)據(jù), 普遍優(yōu)于初始數(shù)據(jù)集的模型,并且有所提升1%~2%. 尤其表現(xiàn)在中等指標的數(shù)據(jù)集訓練模型, 其預測效果是最佳的.

表4 模型準確率對比
3.3 重要特征分析
通過XGBoost的建模可以判斷每個特征變量對模型的貢獻程度, 從而判斷哪些特征變量對于患心臟病的影響更為顯著. 并可以以此對醫(yī)生的判斷其參考輔助作用, 分析結(jié)果如圖1 所示.
如圖2所示為XGBoost 模型的變量重要性結(jié)果,其中, f0、f4、f7 和f9 這4個變量在模型中的重要性排序中在前四位, 這四個變量分別代表著年齡、膽固醇、最大心跳和運動后比較心壓. 而重要性最低的變量是心電圖傾斜度. 從常識上講, 年齡越大患心臟病概率越大, 不僅是心臟病, 各種心腦血管疾病患病概率都很大, 畢竟在數(shù)據(jù)集中高齡患者也是占很多的, 因此不作為主要判斷參數(shù). 而膽固醇, 最大心跳, 心壓這三個參數(shù)是需要經(jīng)過檢測的, 在醫(yī)生判斷的時候根據(jù)檢測結(jié)果, 這三個參數(shù)也可以作為主要參考. 就算患者本人體檢自測三個參數(shù), 也可以根據(jù)異常值推薦就醫(yī). 因此不僅僅是預測心臟病, 重要特征的顯示也能給醫(yī)生和患者帶來重要的參考意見.

圖2 特征變量重要性
4 結(jié)論
本文針對醫(yī)療行業(yè)的心臟病預測問題, 提出了一種聚類和機器學習相結(jié)合的心臟病預測方法, 首先從患者數(shù)據(jù)中提取特征, 將醫(yī)療特征作為心臟病預測的輸入變量, 然后使用XGBoost 算法來對心臟病進行預測, 最后將該方法與其他機器學習算法進行比較.
實驗結(jié)果證明, XGBoost 算法在各個評價標準中普遍優(yōu)于傳統(tǒng)算法, 說明了此模型精準性較高, 論證了使用XGBoost 算法來對心臟病進行預測的可行性和可靠性. 且通過對變量重要性進行分析, 我們識別了對模型貢獻較高的變量. 可以此為依據(jù)針對就醫(yī), 給醫(yī)生和患者帶來重要的參考意見. 對當前的醫(yī)療系統(tǒng)中疾病預防的完善有著重要的現(xiàn)實意義. 雖然模型準確率得到了提高, 但是在實驗過程中發(fā)現(xiàn), 改進的算法運行時間要更長, 如何在大數(shù)據(jù)量的情況下, 降低算法運行時間是接下來的工作.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
