基于PLSA的新聞評論情緒類別自動標(biāo)注方法①
2019-01-18 08:30:28林江豪顧也力周詠梅陽愛民
計(jì)算機(jī)系統(tǒng)應(yīng)用 2019年1期
林江豪, 顧也力, 周詠梅, 陽愛民
1(廣東外語外貿(mào)大學(xué) 語言工程與計(jì)算實(shí)驗(yàn)室, 廣州 510006)
2(廣東外語外貿(mào)大學(xué) 東方語言文化學(xué)院, 廣州 510420)
3(廣東外語外貿(mào)大學(xué) 信息科學(xué)與技術(shù)學(xué)院, 廣州 510006)
網(wǎng)絡(luò)新聞是社會事件傳播的載體, 人們通過評論新聞參與事件, 形成了海量信息. 對新聞評論文本進(jìn)行情緒分析可應(yīng)用到輿情管理、民意調(diào)查、商業(yè)營銷情報(bào)等領(lǐng)域, 有著廣闊的應(yīng)用空間和發(fā)展前景[1,2]. 新聞評論語料庫是進(jìn)行新聞評論情緒分析研究的重要基礎(chǔ),要提高語料的利用價(jià)值, 關(guān)鍵在于語料的標(biāo)注, 所謂標(biāo)注[3]就是對語料庫中的原始語料進(jìn)行加工, 把各種表示語言特征的附碼標(biāo)注在相應(yīng)的語言成分上, 以便于計(jì)算機(jī)的識讀. 然而, 規(guī)模龐大的評論文本如果通過人工標(biāo)注, 是非常困難的. 當(dāng)前在文本情緒分析研究領(lǐng)域還沒有標(biāo)準(zhǔn)的語料庫, 特別是細(xì)粒度的情緒標(biāo)注語料庫更是缺乏, 這在一定程度上影響了該領(lǐng)域的研究. 為了減輕標(biāo)注人員的負(fù)擔(dān), 提高標(biāo)注的效率和精確度, 減少標(biāo)注的錯(cuò)誤率, 非常有必要研究自動標(biāo)注方法, 以便協(xié)助標(biāo)注人員的工作. 因此, 探索研究新聞評論文本情緒類別自動標(biāo)注方法是一項(xiàng)非常重要的工作.
目前, 在文本自動標(biāo)注領(lǐng)域, 文獻(xiàn)[4]提出了一種漢語意見型主觀性文本標(biāo)注語料庫的構(gòu)建方法, 重點(diǎn)討論了語料的選取、標(biāo)注、存儲、檢索和統(tǒng)計(jì)等工作.陽愛民等提出了中文微博語料情感類別自動標(biāo)注的方法, 包括基于關(guān)鍵詞的、基于概率求和的和基于概率乘積的3種自動標(biāo)注方法和一種集成標(biāo)注方法, 實(shí)驗(yàn)驗(yàn)證了集成方法的準(zhǔn)確率可達(dá)到90%以上[5]. 文獻(xiàn)[6]對網(wǎng)絡(luò)新聞評論數(shù)據(jù)的特點(diǎn)進(jìn)行歸納總結(jié), 選取不同的特征集、特征維度、權(quán)重計(jì)算方法和詞性等因素進(jìn)行文本情感自動標(biāo)注. 文獻(xiàn)[7]使用機(jī)器學(xué)習(xí)方法進(jìn)行新聞的情感自動標(biāo)注, 發(fā)現(xiàn)選擇具有語義傾向的詞匯作為特征項(xiàng)、對否定詞正確處理和采用二值作為特征項(xiàng)權(quán)重能提高分類的準(zhǔn)確率, 準(zhǔn)確率能達(dá)到90%. 文獻(xiàn)[8]基于語義的方法, 實(shí)現(xiàn)了微博情感類別的自動標(biāo)注.文獻(xiàn)[9]通過抽取主題句, 將抽取到的主題句與JST模型結(jié)合, 對新聞評論文本進(jìn)行情感標(biāo)注. 吳江等基于語義規(guī)則, 對金融領(lǐng)域的文本進(jìn)行情感標(biāo)注[10]. Khoo等[11]案例分析了基于認(rèn)知理論的在線新聞文本情感標(biāo)注方法. Moreo等[12]提出了一種基于詞典的新聞評論情感自動標(biāo)注系統(tǒng)(LCN-SA), 多維度分析網(wǎng)民的情感傾向.Penalver-Martinez等[13]運(yùn)用本體論, 提出了基于特征的觀點(diǎn)挖掘方法. 國內(nèi)已公開的人工標(biāo)注語料包括NLPCC評測的語料、譚松波等人標(biāo)注的酒店評論語料等.
在現(xiàn)有語料情感類別自動標(biāo)注研究中, 主要將標(biāo)注結(jié)果設(shè)定為正向和負(fù)向來進(jìn)行研究, 這種方法下自動標(biāo)注的語料不能適用于細(xì)粒度的文本情緒分析. 鑒于此, 本文以新聞評論的樂、好、怒、哀、懼、惡、驚七類情緒作為標(biāo)注的類別, 提出一種基于概率潛在語義分析 (Probabilistic Latent Semantic Analysis, PLSA)的新聞評論情緒類別自動標(biāo)注方法. 這種方法通過利用PLSA計(jì)算獲得語料集的“文檔-主題”和“詞語-主題”概率矩陣, 基于“詞語-主題-文檔”之間的概率轉(zhuǎn)換關(guān)系, 認(rèn)為某一類情緒詞匯出現(xiàn)的概率最高的主題與詞匯的情緒類別相同, 對主題進(jìn)行情緒類別標(biāo)注; 認(rèn)為出現(xiàn)在某一主題概率最高的文檔與主題的情緒類別相同, 對文檔進(jìn)行情緒類別標(biāo)注, 達(dá)到自動標(biāo)注的效果.文章的內(nèi)容安排如下, 第1節(jié)重點(diǎn)介紹了基于PLSA的新聞評論情緒自動標(biāo)注方法; 第2節(jié)給出了基于PLSA的概率矩陣抽取方法; 第3節(jié)對文本提出的方法進(jìn)行實(shí)驗(yàn)驗(yàn)證和分析; 第4節(jié)給出了結(jié)論以及下一步的改進(jìn)方向.
1 基于PLSA的新聞評論情緒自動標(biāo)注方法概述
本文采用如圖1所示的新聞評論情緒自動標(biāo)注方法, 首先將采集的新聞評論集進(jìn)行文本預(yù)處理, 分詞后過濾掉停用詞和無用詞, 進(jìn)行詞頻統(tǒng)計(jì), 獲得“文檔-詞匯”矩陣; 接著, 利用 PLSA 模型計(jì)算, 獲得“詞匯-主題”和“文檔-主題”概率矩陣; 結(jié)合情感本體庫[14]和“詞匯-主題”, 認(rèn)為某一類情緒詞匯出現(xiàn)的概率最高的主題與詞匯的情緒類別相同, 對主題進(jìn)行情緒類別標(biāo)注; 最后,基于“文檔-主題”概率矩陣, 認(rèn)為出現(xiàn)在某一主題概率最高的文檔與主題的情緒類別相同, 達(dá)到對文檔情緒類別的自動標(biāo)注.
根據(jù)圖 1, 用[Mword-topic]m×k和“文檔-主題”矩陣[Mdoc-topic]n×k來表示分類為k個(gè)主題的PLSA計(jì)算結(jié)果, 其中[Mword-topic]m×k表示詞匯在對應(yīng)主題中的概率,也即詞匯對主題的貢獻(xiàn)度, 則對于詞匯wordj在k個(gè)主題中的概率p有pj1+pj2+…+pjk=1. 分別對每個(gè)主題下的詞語概率按照由大到小排序, 利用情感本體庫OL,抽取概率高的情緒詞匯, 對情緒詞匯的情緒強(qiáng)度直接加總計(jì)算, 得到主題在每一類情緒中的強(qiáng)度, 則主題在m類情緒中的權(quán)重分布Et={e1,e2,e3,···,em}, 通過判斷Et中的最大值, 獲得主題的情緒類別. 同理, 利用“文檔-主題”矩陣, 認(rèn)為對主題貢獻(xiàn)度高的文檔與主題的情緒類別相同, 對文檔的情緒類別進(jìn)行標(biāo)注. 則基于PLSA的新聞評論情緒自動標(biāo)注算法如算法1.

算法1. 基于PLSA的新聞評論情緒自動標(biāo)注算法輸入: 情感本體庫OL, 語料集Data_set輸出: [doc, e]m

步驟1. 對Data_set進(jìn)行預(yù)處理, 包括分詞、詞頻統(tǒng)計(jì)等, 獲得“文檔-詞頻”矩陣 Mt;步驟 2. 計(jì)算 PLSA(Mt)→“詞匯-主題”矩陣[Mword-topic]m×k 和“文檔-主題”矩陣[Mdoc-topic]n×k;Zk={[w1,w2,w3,··,wo]1,[w1,w2,w3,··,wp]2,··,步驟3. 逐列對[Mword-topic]m×k進(jìn)行排序, 獲取每個(gè)主題zj中概率較高的情緒詞匯, 得到;EZk={[wt1,wt2,wt3,··,wto]1,[w1,w2,w3,··,wq]k}步驟4. 在情感本體庫查詢情緒詞的權(quán)重, 得到主題的情緒權(quán)重矩陣[wt1,wt2,wt3,··,wtp]2,··,[wt1,wt2,wt3,··,wtq]k};步驟 5. 對每個(gè)主題 zj的情緒權(quán)重進(jìn)行加總, 得到;{[e1,e2,e3,··,em]1,[e1,e2,e3,··,em]2,··,[e1,e2,e3,··,em]k}Etk=

步驟6. 逐列對Etk進(jìn)行排序, 獲得情緒強(qiáng)度最強(qiáng)的類別為對應(yīng)主題的情緒, 則主題情緒標(biāo)注結(jié)果為ZEk;步驟 7. 逐列對[Mdoc-topic]n×k 進(jìn)行排序, 結(jié)合 ZEk, 將對主題貢獻(xiàn)度高文檔的情緒類別標(biāo)注為主題的情緒類別, 對每一個(gè)doc獲得對應(yīng)的情緒類別e;結(jié)束. 輸出[doc, e]n.
算法的最終輸出為[doc,e]m, 為驗(yàn)證該標(biāo)注結(jié)果的準(zhǔn)確性, 本文采集了鳳凰網(wǎng)涉及中日關(guān)系的新聞評論語料, 自動篩選出含有兩個(gè)情緒詞匯以上的評論語料, 進(jìn)行人工標(biāo)注, 與自動標(biāo)注結(jié)果對比驗(yàn)證[doc,e]m的準(zhǔn)確率.
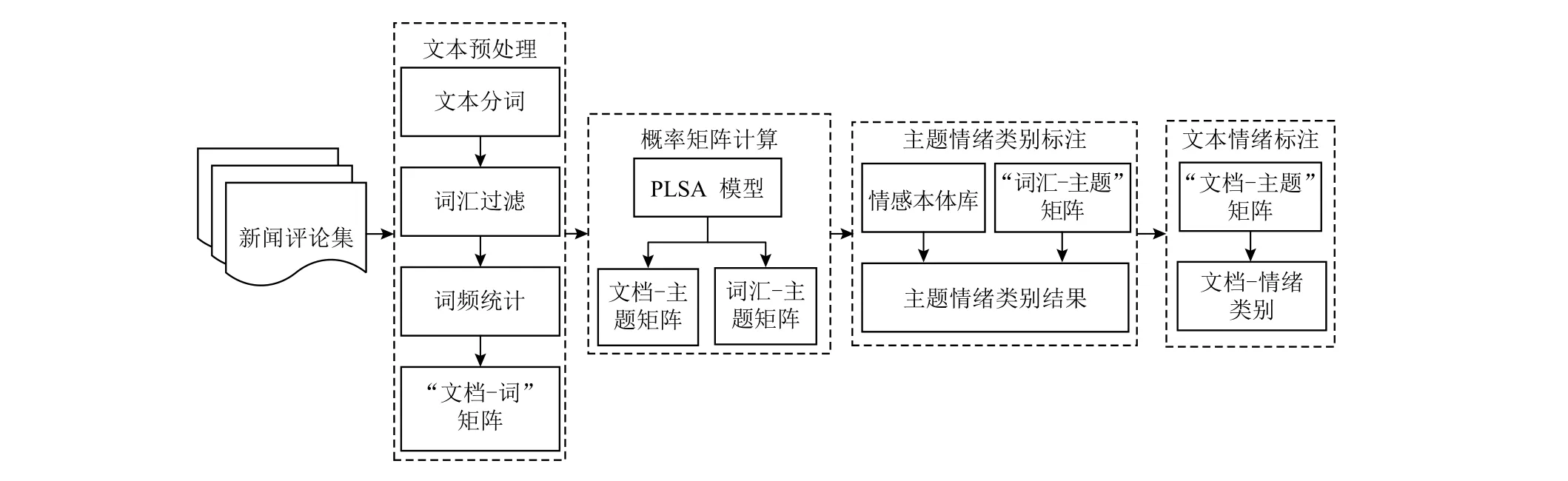
圖1 基于PLSA的新聞評論情緒自動標(biāo)注過程
2 基于PLSA的概率矩陣抽取方法
PLSA模型是由Hofmann在1999年提出的, 首先給定文檔集D={d1,d2,···,dn}和詞集W={w1,w2,···,wm},用freq(di,wj)表示詞wj在文檔di中出現(xiàn)的概率, 則“文檔-詞語”共現(xiàn)矩陣MD-W=[freq(di,wj)]. 假設(shè)主題類別Z={z1,z2,···,zk},k為主題個(gè)數(shù). PLSA模型假設(shè)詞與文檔之間、話題與文檔或者詞之間的概率服從條件獨(dú)立, 由此得到相應(yīng)的聯(lián)合分布概率為:
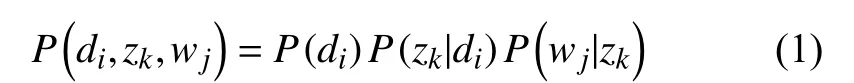
P(di)表示選擇文檔di的概率,P(zk|di)表示某個(gè)主題zk在給定文檔di下出現(xiàn)的概率;P(wj|zk)表示詞wj在給定主題zk下出現(xiàn)的概率, 本文基于該“詞語-主題”的概率分布獲取事件Evt, 根據(jù)貝葉斯法則可得到:
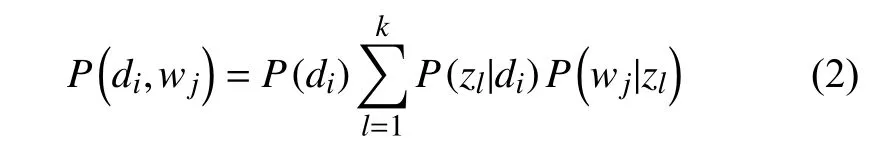
采用最大期望算法(Expectation Maximization,EM) 算法對潛在語義模型進(jìn)行擬合[13]. 用隨機(jī)數(shù)初始化之后, 交替執(zhí)行E步驟和M步驟進(jìn)行迭代計(jì)算.E步驟計(jì)算(di,wj)所產(chǎn)生的潛在語義zk的先驗(yàn)概率:

在 M 步驟中, 根據(jù)P(z|d,w)對P(w|z)和P(z|d)矩陣重新估計(jì):
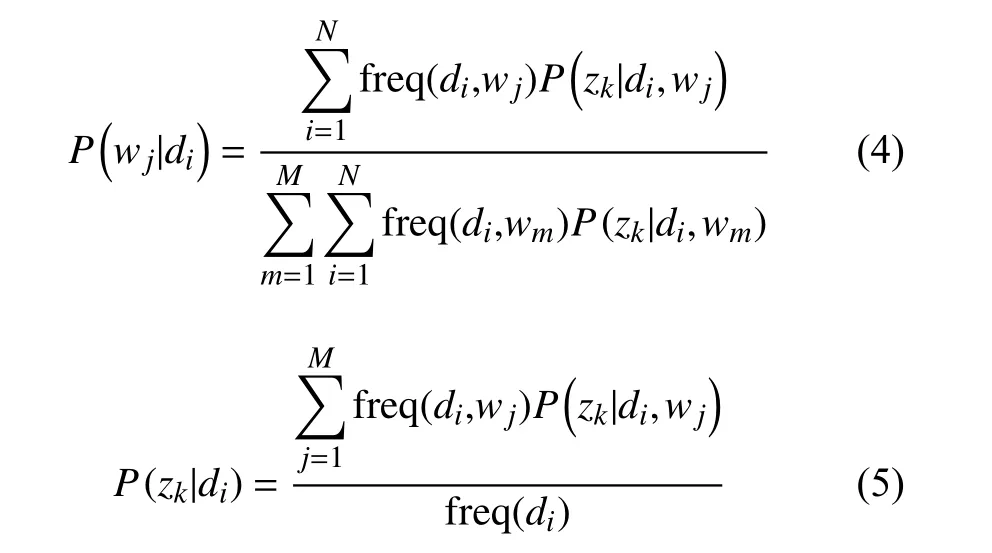
似然函數(shù)的對數(shù)如下:
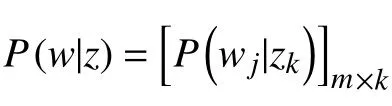
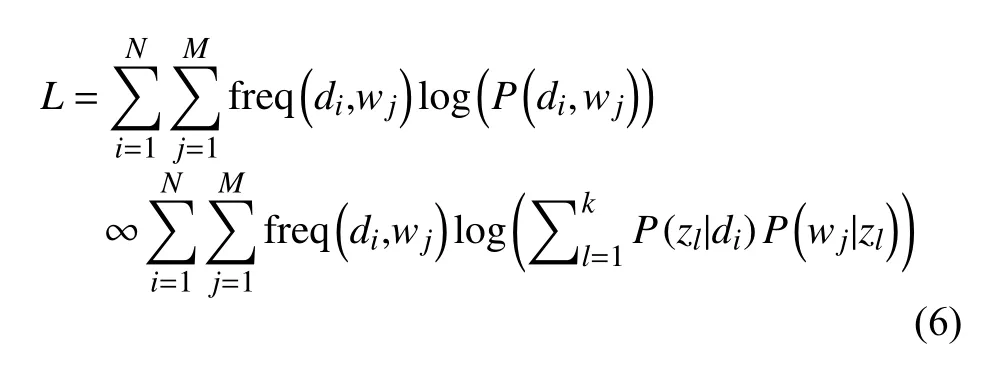
3 實(shí)驗(yàn)結(jié)果及分析
3.1 實(shí)驗(yàn)數(shù)據(jù)采集
實(shí)驗(yàn)采集了鳳凰網(wǎng)(http://www.ifeng.com/)涉及中日關(guān)系新聞“習(xí)近平應(yīng)約會見日本首相安倍晉三”, 新聞為2014年APEC期間發(fā)布的, 共有2346條新聞評論. 由于本文利用情感本體庫結(jié)合“詞匯-主題”矩陣實(shí)現(xiàn)主題的情緒類別標(biāo)注, 因此對不含情緒詞匯和評論長度小于10的評論直接去掉, 取其中1500條來進(jìn)行標(biāo)注. 請3名研究人員對語料進(jìn)行人工標(biāo)注, 標(biāo)注為7類情緒, 對于標(biāo)注結(jié)果采用投票方式, 有兩人標(biāo)注結(jié)果為一致, 則認(rèn)為語料標(biāo)注有效, 最終取1200條新聞評論作為本文的實(shí)驗(yàn)語料.
3.2 PLSA中主題數(shù)的確定
利用PLSA進(jìn)行計(jì)算時(shí), 需要先設(shè)定主題的數(shù)量,而主題數(shù)的確定受到語料的規(guī)模和內(nèi)容的影響. 對于主題明確的語料, 設(shè)定了正確的主題數(shù)量, 能有效提升主題的自動情緒標(biāo)注準(zhǔn)確性, 進(jìn)而提高文檔的情緒類別自動標(biāo)注準(zhǔn)確率. 鑒于此, 本文利用情感本體庫OL作為情緒標(biāo)注的基礎(chǔ), 而本體庫中將情緒分為7類,分別是樂、好、怒、哀、懼、惡、驚. 因此, 本文主題的數(shù)量的設(shè)定從7類開始, 一直增加到28類, 探索最適合于選定語料的主題數(shù)量.
對于主題zj的情緒強(qiáng)度向量Vzj=[e1,e2,e3,···,em]j,如果Vzj中除了情緒最強(qiáng)的類別之外, 其他情緒類別ei的強(qiáng)度不能同時(shí)滿足公式(7), 則認(rèn)為該主題的情緒類別不能準(zhǔn)確分類.

因此, 主題情緒類別自動標(biāo)注準(zhǔn)確率的計(jì)算公式如公式(8)所示.

根據(jù)公式(8), 在本文選定的語料集中, 計(jì)算主題情緒自動標(biāo)注的準(zhǔn)確率隨著主題數(shù)增加的結(jié)果, 如圖2所示,x軸表示主題數(shù)量,y軸表示自動標(biāo)注準(zhǔn)確率.

圖2 主題數(shù)與標(biāo)注準(zhǔn)確率

3.3 基于PLSA的文本情緒類別自動標(biāo)結(jié)果
將主題數(shù)設(shè)定為17, 利用PLSA的分析結(jié)果, 對主題進(jìn)行情緒標(biāo)注, 能正確標(biāo)注的主題數(shù)為16個(gè), 則7類情緒對應(yīng)的主題數(shù)如表1所示, 主流情緒為樂、好. 進(jìn)一步觀察語料發(fā)現(xiàn), 多數(shù)網(wǎng)民對中日兩國友好關(guān)系和共同發(fā)展, 表示支持和高興. 同時(shí), 網(wǎng)民也對中日的釣魚島、靖國神社、南京大屠殺等中日歷史事件表現(xiàn)出其他情緒.
利用表1中主題情緒類別標(biāo)注結(jié)果, 根據(jù)算法1中的步驟7, 對文檔進(jìn)行情緒標(biāo)注, 各類情緒下語料標(biāo)注的準(zhǔn)確率如表2所示.
從表2的實(shí)驗(yàn)結(jié)果可以看出, 每一類情緒對應(yīng)的文檔自動標(biāo)注準(zhǔn)確率均高于85%, 最高準(zhǔn)確率達(dá)到93.7%,7類情緒的平均準(zhǔn)確率達(dá)到88.98%, 總體的準(zhǔn)確率達(dá)到90.87%. 說明了采用PLSA可有效對文檔進(jìn)行細(xì)粒度的情緒類別自動標(biāo)注, 特別是大規(guī)模語料, 可以快速地實(shí)現(xiàn)語料的自動標(biāo)注.
4 結(jié)論與展望
文本自動標(biāo)注能有效解決手工標(biāo)注的困難, 本文提出一種基于PLSA的新聞評論文本情緒類別自動標(biāo)注方法, 這種方法主要利用的PLSA計(jì)算輸出“文檔-主題”和“詞語-主題”概率矩陣, 基于“詞匯-主題-文檔”三者的關(guān)系, 認(rèn)為某一類情緒詞匯出現(xiàn)的概率最高的主題與詞匯的情緒類別相同, 對主題進(jìn)行情緒類別標(biāo)注;認(rèn)為出現(xiàn)在某一主題概率最高的文檔與主題的情緒類別相同, 對進(jìn)行情緒類別標(biāo)注. 實(shí)驗(yàn)結(jié)果表明, 這種方法是可行的和有效的, 標(biāo)注準(zhǔn)確率達(dá)到90%以上.

表1 主題情緒標(biāo)注結(jié)果

表2 新聞評論情緒類別自動標(biāo)注結(jié)果
由于語料的規(guī)模和內(nèi)容對PLSA的分析有一定的影響, 同時(shí)本體庫的詞匯涵蓋面以及領(lǐng)域適應(yīng)性等問題, 都會影響標(biāo)注的效果. 因此, 本文的下一步工作是探索領(lǐng)域自適應(yīng)性的語料標(biāo)注方法, 拓展本體庫, 利用句法依存關(guān)系等抽取領(lǐng)域關(guān)鍵情緒詞匯, 提升自動標(biāo)注的準(zhǔn)確率.
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
風(fēng)流一代·青春(2018年4期)2018-04-19 16:18:48
風(fēng)流一代·青春(2018年3期)2018-03-15 17:07:26
風(fēng)流一代·青春(2018年2期)2018-02-26 15:27:06
風(fēng)流一代·青春(2017年6期)2018-02-14 19:28:55
風(fēng)流一代·青春(2017年5期)2018-02-14 09:32:37
山東醫(yī)藥(2017年35期)2017-10-10 02:45:28
商業(yè)評論(2014年6期)2015-02-28 04:44:25
