LBSN中融合類(lèi)別信息的混合推薦模型①
2019-01-18 08:30:28張岐山林小榕
計(jì)算機(jī)系統(tǒng)應(yīng)用 2019年1期
張岐山, 李 可, 林小榕
1(福州大學(xué) 經(jīng)濟(jì)與管理學(xué)院, 福州 350108)
2(北京交通大學(xué) 下一代互聯(lián)網(wǎng)互聯(lián)設(shè)備國(guó)家工程實(shí)驗(yàn)室, 北京 100044)
近年來(lái), 基于位置的社交網(wǎng)絡(luò)服務(wù)(Location-Based Social Network, LBSN)得到迅速發(fā)展, 如 Loopt、Yelp、Foursquare、Whrrl等[1]. 在這些 LBSNs中, 用戶訪問(wèn)線下的興趣點(diǎn) (Point-Of-Interest, POI), 如: 餐館、電影院、博物館等, 在線上進(jìn)行“簽到”活動(dòng), 并分享他們?cè)L問(wèn)興趣點(diǎn)時(shí)豐富的建議與經(jīng)歷[2]. 興趣點(diǎn)推薦可以減少用戶的搜尋時(shí)間, 為商家提供精準(zhǔn)營(yíng)銷(xiāo)策略. 所以如何利用這些信息, 為目標(biāo)用戶推薦正確的興趣點(diǎn)集是一個(gè)很有前途、很有趣的研究問(wèn)題. 目前, 有很多學(xué)者運(yùn)用協(xié)同過(guò)濾、矩陣分解、LDA模型等技術(shù)于興趣點(diǎn)推薦之中, 但是普遍存在以下幾個(gè)問(wèn)題:
(1) 數(shù)據(jù)稀疏問(wèn)題. 在LBSNs中興趣點(diǎn)推薦研究遭遇到了嚴(yán)重的數(shù)據(jù)稀疏問(wèn)題. 通常情況下, 一個(gè)用戶訪問(wèn)的興趣點(diǎn)的數(shù)量?jī)H僅是興趣點(diǎn)總數(shù)當(dāng)中很小的一部分. 例如, Netflix電影推薦的數(shù)據(jù)密度是1.2%, 而興趣點(diǎn)推薦研究實(shí)驗(yàn)中使用的數(shù)據(jù)密度通常在0.1%左右[3]. Ye等人[4]提出了融合地理位置、用戶偏好和社會(huì)影響的統(tǒng)一協(xié)同過(guò)濾模型, Lian等人[5]提出了加權(quán)矩陣分解模型, 均容易受到數(shù)據(jù)稀疏性的影響. 協(xié)同過(guò)濾算法利用用戶之間的相似性進(jìn)行有效地推薦, 很容易受到數(shù)據(jù)稀疏性的影響. 而且該算法只考慮到了簽到數(shù)據(jù)的顯式反饋, 不能有效地融合異構(gòu)數(shù)據(jù)源[6]. 矩陣分解算法可緩解數(shù)據(jù)稀疏性的影響, 但是其忽略了用戶之間的相似性.
(2) 隱私問(wèn)題. 很多保護(hù)隱私意識(shí)比較強(qiáng)的用戶,他們?cè)贚BSNs中不會(huì)透露家庭住址、公司地址等有效信息. Li等人[7]考慮了用戶“家”的地理位置, 認(rèn)為單考慮地理位置影響則家與興趣點(diǎn)之間的距離同其訪問(wèn)該興趣點(diǎn)的概率呈冪律分布. 但在這些信息不完全甚至是沒(méi)有這些信息的情況下, 如何進(jìn)行有效的興趣點(diǎn)推薦是我們要研究的問(wèn)題之一.
(3) 類(lèi)別信息. 每個(gè)興趣點(diǎn)都會(huì)有其類(lèi)別信息, 如:飯店、電影院、博物館等. 從歷史簽到記錄來(lái)看, 每個(gè)用戶都會(huì)偏向于訪問(wèn)類(lèi)別相同或者相似的興趣點(diǎn)[7]. 因此, 如何利用興趣點(diǎn)的類(lèi)別信息提高興趣點(diǎn)推薦的準(zhǔn)確率是我們研究?jī)?nèi)容的重點(diǎn).
本文針對(duì)上述的問(wèn)題, 提出了SoGeoCat(Social-Geography-Category, SoGeoCat)模型, 主要貢獻(xiàn)如下:
(1) SoGeoCat模型結(jié)合了協(xié)同過(guò)濾算法和矩陣分解算法的優(yōu)點(diǎn), 首先根據(jù)用戶行為相似性發(fā)現(xiàn)目標(biāo)用戶的潛在興趣點(diǎn), 然后將潛在興趣點(diǎn)納入矩陣分解模型當(dāng)中, 克服了單純協(xié)同過(guò)濾和矩陣分解算法的不足,即考慮了用戶相似度又很大程度上緩解了數(shù)據(jù)稀疏性的問(wèn)題.
(2) 本文利用貝葉斯規(guī)則, 根據(jù)目標(biāo)用戶的歷史簽到軌跡來(lái)判斷擬推薦興趣點(diǎn)在地理位置因素上對(duì)目標(biāo)用戶的影響.
(3) 本文將興趣點(diǎn)的類(lèi)別標(biāo)簽納入矩陣分解模型中, 提高SoGeoCat模型的推薦效率.
1 相關(guān)工作
協(xié)同過(guò)濾和矩陣分解是興趣點(diǎn)推薦研究中主流的兩種算法.
(1) 基于協(xié)同過(guò)濾算法的推薦. 協(xié)同過(guò)濾的主要思想是: 分析用戶之間的關(guān)系和項(xiàng)目之間的相互依賴關(guān)系, 以識(shí)別新的用戶—項(xiàng)目關(guān)聯(lián)[8-10].
Ye等人[4]提出了融合地理位置、用戶偏好和社會(huì)影響的統(tǒng)一協(xié)同過(guò)濾方法. 采用冪律概率模型捕捉興趣點(diǎn)之間的地理位置影響, 通過(guò)樸素貝葉斯方法實(shí)現(xiàn)基于地理影響的興趣點(diǎn)協(xié)同推薦. Yuan等人[11]在統(tǒng)一的協(xié)同過(guò)濾框架上納入了時(shí)間信息的影響, 利用時(shí)間感知進(jìn)行興趣點(diǎn)推薦. 但該算法很容易受到數(shù)據(jù)稀疏性的影響, 也不能很好地實(shí)現(xiàn)對(duì)隱式反饋數(shù)據(jù)集的挖掘.
(2) 基于矩陣分解算法的推薦. 矩陣分解法的核心是訓(xùn)練出用戶和興趣點(diǎn)的特征向量, 并以此來(lái)預(yù)測(cè)用戶對(duì)于某一特定興趣點(diǎn)的偏好. 其不僅可以緩解數(shù)據(jù)稀疏性的影響還可以融合異構(gòu)數(shù)據(jù)源,考慮隱式反饋數(shù)據(jù)集[5,12-14].
Lian等人[5]將地理位置影響納入加權(quán)矩陣分解框架當(dāng)中, 根據(jù)簽到記錄的空間聚集現(xiàn)象, 提出了GeoMF模型, 模擬用戶活動(dòng)區(qū)域與地理位置之間的影響關(guān)系.高榕等人[14]在經(jīng)典的矩陣分解模型的基礎(chǔ)上, 融合異構(gòu)數(shù)據(jù), 提出了GeoSoRev模型, 采用基于矩陣分解的主題模型來(lái)發(fā)現(xiàn)評(píng)論中的隱藏“主題”. 矩陣分解算法雖然緩解了數(shù)據(jù)的稀疏性, 也融合不同的異構(gòu)數(shù)據(jù), 但它沒(méi)有考慮到用戶之間的相似性.
(3) 混合算法推薦. 為了克服兩種算法的不足之處,有一些學(xué)者提出了混合算法. Li等人[7]提出了“兩步走”的框架. 第一步設(shè)計(jì)基于線性聚集和基于隨機(jī)游走兩種方法, 為每個(gè)用戶學(xué)習(xí)一組他們可能感興趣的潛在興趣點(diǎn). 在第二步驟中, 用基于平方誤差的損失函數(shù)和基于排名誤差的損失函數(shù)來(lái)模擬這三種簽到.
文獻(xiàn)[5]中認(rèn)為用戶的簽到概率和從家到相應(yīng)位置的距離遵循冪律分布. 一方面, 家的位置信息較難獲得,很多用戶隱私保護(hù)意識(shí)越來(lái)越強(qiáng), 不愿意透露家庭位置信息; 另一方面, 用戶簽到過(guò)的興趣點(diǎn)可能會(huì)聚集在某兩個(gè)距離比較遠(yuǎn)的區(qū)域, 如家和公司附近. 因此, 本文針對(duì)上述問(wèn)題, 在文獻(xiàn)[5]的基礎(chǔ)上繼續(xù)研究, 提出了 SoGeoCat (Social-Geography-Category)模型, 用樸素貝葉斯方法計(jì)算地理位置因素對(duì)于用戶決策的影響,保護(hù)用戶家庭位置信息, 并將簽到信息、朋友信息、地理位置信息和類(lèi)別信息納入混合模型中, 即考慮了用戶相似性又緩解了數(shù)據(jù)稀疏問(wèn)題, 提高了模型的推薦效果.
2 用戶潛在興趣點(diǎn)數(shù)據(jù)模型
2.1 問(wèn)題描述
本文主要研究的問(wèn)題與傳統(tǒng)的基于協(xié)同過(guò)濾的推薦模型或基于矩陣分解的推薦模型不同, 而是采用了“兩步走”的框架模型SoGeoCat: 首先, 建立用戶潛在興趣點(diǎn)數(shù)據(jù)模型, 利用用戶的簽到信息、朋友信息、地理位置信息對(duì)用戶的簽到信息進(jìn)行有效地?cái)U(kuò)充; 然后,建立一個(gè)融合類(lèi)別標(biāo)簽的矩陣分解模型, 訓(xùn)練出用戶特征矩陣和興趣點(diǎn)特征矩陣; 最后考慮用戶特征、興趣點(diǎn)特征的影響, 估算出目標(biāo)用戶對(duì)于某一特定的興趣點(diǎn)的訪問(wèn)概率, 進(jìn)而推薦有效的興趣點(diǎn)集.
假設(shè)ui為目標(biāo)用戶,lj為擬推薦興趣點(diǎn). U為用戶集 , 即 U={u1,u2,… ,un}, L 為 興 趣 點(diǎn) 集 , 即L={l1,l2,…,lm}. 運(yùn)用 SoGeoCat模型計(jì)算出ui訪問(wèn)每一個(gè)未訪問(wèn)過(guò)的POI的概率, 選取TopS作為ui的擬推薦興趣點(diǎn)集.
2.2 基于簽到行為相似度建模
用戶在LBSNs中有大量的簽到信息, 簽到信息包括用戶ID, 興趣點(diǎn)ID和訪問(wèn)次數(shù). 訪問(wèn)次數(shù)越多, 則說(shuō)明用戶對(duì)該興趣點(diǎn)的偏好越強(qiáng). 用戶i與用戶u已簽到過(guò)的共同的興趣點(diǎn)越多, 則他們的簽到行為越相似,即簽到行為相似度Sim(ui,uu)越高, 本文采用余弦相似度來(lái)度量?jī)捎脩糁g的簽到行為相似度, 建模如下:
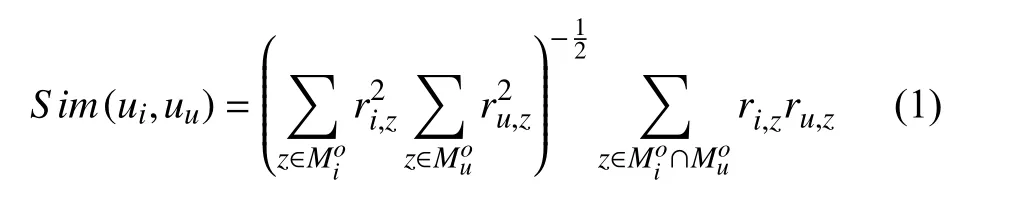
其中,ri,z表示ui在興趣點(diǎn)lz的簽到次數(shù),ru,z表示uu在興趣點(diǎn)lz的簽到次數(shù)表示ui訪問(wèn)過(guò)的興趣點(diǎn)的集合表示uu訪問(wèn)過(guò)的興趣點(diǎn)的集合.
注意: 這里的uu曾經(jīng)在興趣點(diǎn)lj處有簽到行為.
2.3 基于朋友相似度建模
用戶在LBSNs上有一些相互關(guān)注的好友, 這些好友關(guān)系也反映了該用戶在現(xiàn)實(shí)生活中的朋友圈. 現(xiàn)實(shí)中, 你朋友的推薦會(huì)激發(fā)你對(duì)某些興趣點(diǎn)的興趣, 在LBSNs中亦是如此. 所以,uf(ui的朋友)的簽到記錄很有可能是ui想要訪問(wèn)的潛在興趣點(diǎn). 但是ui有很多好友, 不一定每一個(gè)好友簽到過(guò)的興趣點(diǎn),ui都會(huì)感興趣.對(duì)此, 提出了朋友相似度Sim(ui,uf), 朋友相似度越高,其歷史簽到記錄越有參考價(jià)值, 建模如下:
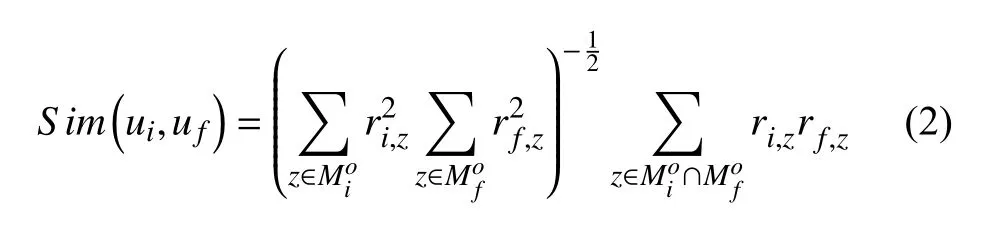
其中,ri,z表示ui在興趣點(diǎn)lz的簽到次數(shù),rf,z表示uf在興趣點(diǎn)lz的簽到次數(shù),表示ui訪問(wèn)過(guò)的興趣點(diǎn)的集合,表示uf訪問(wèn)過(guò)的興趣點(diǎn)的集合.
注意: 這里的uf曾經(jīng)在興趣點(diǎn)lj處有簽到行為.
2.4 基于地理位置相似度建模
人們往往喜歡訪問(wèn)地理位置離自己近的興趣點(diǎn),單考慮地理位置影響因素, 用戶訪問(wèn)興趣點(diǎn)的概率同其距離遵循冪率分布, 模型[5]如下:

其中,d表示用戶同興趣點(diǎn)之間的距離,a和b均為冪律分布的參數(shù).

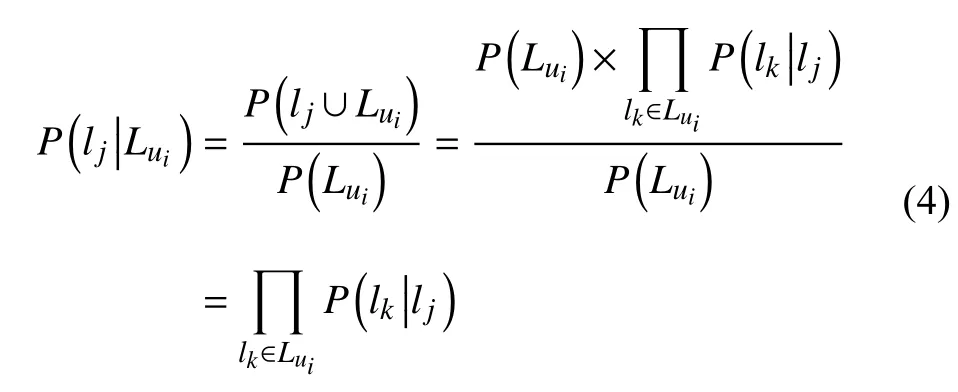
2.5 相似度的線性聚集
綜合考慮上述三個(gè)因素的影響, 對(duì)簽到行為相似度、朋友相似度和地理位置相似度進(jìn)行線性聚合. 但是, 它們是通過(guò)不同的方法來(lái)衡量的, 具有不同的價(jià)值范圍. 因此, 我們采用最小-最大歸一化進(jìn)行處理, 然后再進(jìn)行聚集.
同時(shí), 簽到次數(shù)也能側(cè)面地反映用戶的偏好. 根據(jù)公式(8)計(jì)算出ui對(duì)于擬推薦興趣點(diǎn)lj的分?jǐn)?shù), 選取分?jǐn)?shù)高的前S個(gè)興趣點(diǎn)作為ui的潛在興趣點(diǎn).

其中,U表示與ui訪問(wèn)過(guò)相同興趣點(diǎn)的用戶及ui的朋友的集合且表示用戶ui對(duì)擬推薦興趣點(diǎn)lj的聚集相似度.是調(diào)整參數(shù).
3 SoGeoCat模型
3.1 SoGeoCat模型
用戶ui對(duì)于興趣點(diǎn)lj的偏好程度受用戶潛在特征和興趣點(diǎn)潛在特征影響. 令用戶特征矩陣為U, 興趣點(diǎn)特征矩陣為V, 偏好矩陣為P, 則:

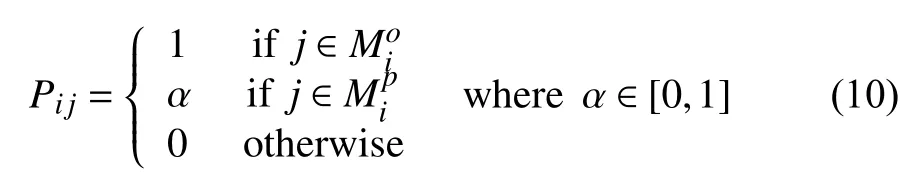
在LBSNs的興趣點(diǎn)推薦中, 其類(lèi)別信息發(fā)揮著重要的作用. 從歷史簽到記錄來(lái)看, 每個(gè)用戶都會(huì)偏向于訪問(wèn)類(lèi)別相同或相似的興趣點(diǎn), 如:ui之前經(jīng)常訪問(wèn)飯店, 但幾乎沒(méi)去過(guò)電影院, 此時(shí)如果給他推薦電影院,則其訪問(wèn)的可能性就會(huì)大大降低. 設(shè)表示ui對(duì)于lj對(duì)應(yīng)的類(lèi)別c的偏好程度,Q表示類(lèi)別特征矩陣. 將類(lèi)別信息納入矩陣分解模型中, 模型為:

損失函數(shù)為:


3.2 SoGeoCat模型優(yōu)化
本文采用變更最小二乘(ALS)優(yōu)化損失函數(shù), 訓(xùn)練出特征矩陣U,V和類(lèi)別特征矩陣Q.U,V,Q的更新公式如下:

其中,Ik為k維單位矩陣,Nc為類(lèi)別為c的興趣點(diǎn)的集合.
4 實(shí)驗(yàn)
4.1 實(shí)驗(yàn)數(shù)據(jù)集
本實(shí)驗(yàn)的數(shù)據(jù)來(lái)自Foursquare真實(shí)數(shù)據(jù)集[13], 采集的是2009年12月至2013年6月期間在加利福尼亞的簽到數(shù)據(jù), 包括用戶ID、朋友信息、興趣點(diǎn)ID、興趣點(diǎn)經(jīng)緯度及其類(lèi)別信息. 數(shù)據(jù)集中一共含有2551名用戶, 13 474個(gè)興趣點(diǎn)及124 933條簽到記錄. 用戶-興趣點(diǎn)矩陣密度為0.002 91. 由于LBSNs中存在嚴(yán)重的數(shù)據(jù)稀疏性, 所以LBSNs背景下的推薦模型準(zhǔn)確率和召回率普遍較低. 數(shù)據(jù)集的相關(guān)內(nèi)容詳見(jiàn)表1.
為了驗(yàn)證SoGeoCat模型的準(zhǔn)確性, 對(duì)Foursquare數(shù)據(jù)集做了如下的處理.
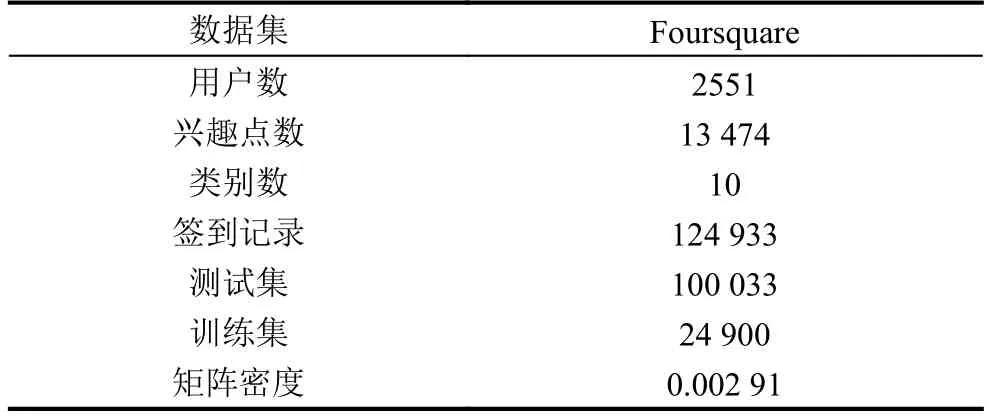
表1 實(shí)驗(yàn)數(shù)據(jù)集
1) 剔除訪問(wèn)少于10個(gè)興趣點(diǎn)的用戶.
2) 剔除少于10個(gè)用戶訪問(wèn)的興趣點(diǎn).
3) 采用數(shù)據(jù)集中的80%的數(shù)據(jù)作為訓(xùn)練集, 剩余的20%作為測(cè)試集.
隱含層節(jié)點(diǎn)個(gè)數(shù)的確定沒(méi)有準(zhǔn)確的理論依據(jù),需要依據(jù)前人設(shè)計(jì)經(jīng)驗(yàn)以及具體試驗(yàn)來(lái)確定,對(duì)用于模式識(shí)別/分類(lèi)的BP網(wǎng)絡(luò),可參照下式進(jìn)行設(shè)計(jì)。
4.2 評(píng)價(jià)指標(biāo)
本文采用準(zhǔn)確率(Precision)和召回率(Recall)來(lái)評(píng)估推薦算法的性能, 計(jì)算公式如下:
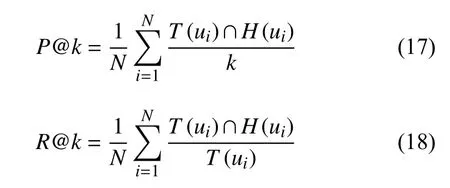
實(shí)驗(yàn)中, 我們將k設(shè)置為: 5, 8, 10, 12, 15, 20.
4.3 推薦模型對(duì)比
為了評(píng)估SoGeoCat模型的性能, 本文選取三個(gè)經(jīng)典模型同本模型進(jìn)行對(duì)比:
IRenMF[15]采用了融合地理位置信息的矩陣分解模型, 根據(jù)地理特征將領(lǐng)域分為實(shí)例級(jí)別領(lǐng)域和區(qū)域級(jí)別領(lǐng)域這兩個(gè)層次, 利用領(lǐng)域的特征進(jìn)行個(gè)性化推薦;
USG[4]采用了統(tǒng)一的協(xié)同過(guò)濾框架, 綜合考慮了用戶偏好、朋友信息和地理位置信息對(duì)興趣點(diǎn)推薦的影響;
ASMF-LA[13]采用了“兩步走”框架, 融合用戶偏好、朋友信息、地理位置信息和類(lèi)別信息對(duì)興趣點(diǎn)推薦的影響.
參考文獻(xiàn)[13], 實(shí)驗(yàn)的相關(guān)參數(shù)設(shè)置如下:
4.4 實(shí)驗(yàn)結(jié)果分析
為了評(píng)估SoGeoCat模型的性能, 本節(jié)從推薦模型(USG、IRenMF、ASMF-LA、SoGeoCat)之間比較、SoGeoCat模型中各要素影響和用戶潛在興趣點(diǎn)數(shù)據(jù)模型影響這三個(gè)方面進(jìn)行分析, 具體內(nèi)容如下.
4.4.1 推薦模型的比較與分析
在k=5, 8, 10, 12, 15, 20 的條件下準(zhǔn)確率和召回率分別用P@k、R@k表示, 各模型的準(zhǔn)確率和召回率見(jiàn)表2.
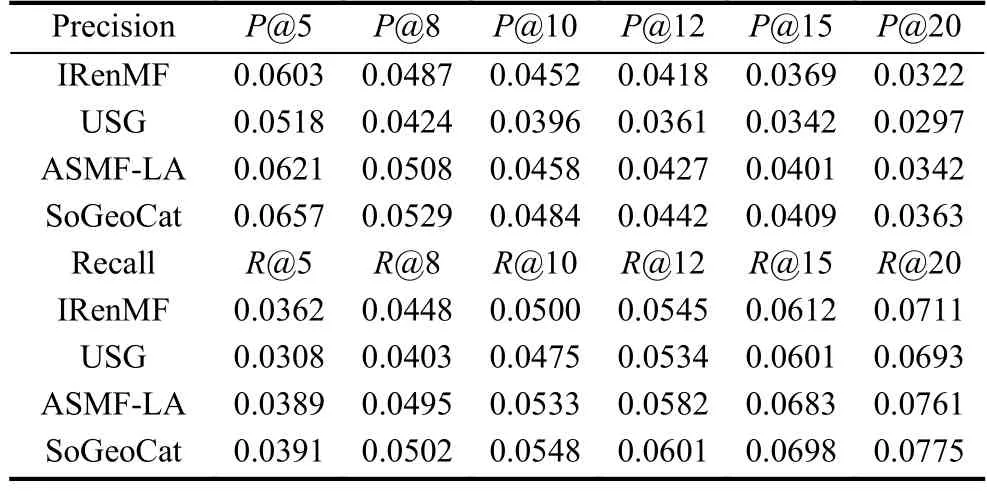
表2 各模型在Foursquare數(shù)據(jù)集中的性能

圖1 基于Foursquare數(shù)據(jù)集各模型的準(zhǔn)確率對(duì)比

圖2 基于Foursquare數(shù)據(jù)集各模型的召回率對(duì)比
從表2中可以看出:
(1) IRenMF采用了加權(quán)矩陣分解模型, 對(duì)于實(shí)例級(jí)別領(lǐng)域和區(qū)域級(jí)別領(lǐng)域分別采用興趣點(diǎn)相似性和用戶相似性進(jìn)行個(gè)性化推薦, 但由于沒(méi)考慮朋友信息和類(lèi)別信息, 因此相對(duì)于ASMF-LA和SoGeoCat而言表現(xiàn)出了更差的推薦效果, 如表三所示, IRenMF表現(xiàn)出了第3好的推薦效果;
(2) USG是采用了融合用戶偏好、朋友信息和地理位置信息的統(tǒng)一協(xié)同過(guò)濾模型, 但由于其沒(méi)有考慮類(lèi)別信息, 且各要素的影響只是進(jìn)行簡(jiǎn)單的線性加權(quán)組合, 忽略了要素之間的相互作用, 再者, 協(xié)同過(guò)濾算法很容易受到數(shù)據(jù)稀疏性的影響. 所以, USG模型表現(xiàn)出最差的推薦效果;
(3) ASMF-LA采用了“兩步走”框架, 考慮了直接朋友、鄰居朋友、位置朋友和類(lèi)別信息對(duì)興趣點(diǎn)推薦的影響, 表現(xiàn)出了不錯(cuò)的推薦效果. 但是在獲取鄰居朋友和計(jì)算地理位置因素對(duì)興趣點(diǎn)推薦的影響時(shí), 都需要用到用戶“家”的信息. 實(shí)際上, 越來(lái)越多的用戶不愿意公開(kāi)自己“家”的位置等隱私信息, 而且, 并非用戶只愿意訪問(wèn)離家近的興趣點(diǎn), 如: 白領(lǐng)小A, 他家和公司相離10公里, 他經(jīng)常訪問(wèn)的興趣點(diǎn)就容易集中在以家和公司為圓心的兩個(gè)領(lǐng)域當(dāng)中. 所以, ASMF-LA表現(xiàn)出了第2好的推薦效果;
(4) SoGeoCat同樣采用了“兩步走”框架, 既考慮到了用戶之間的相似性, 又緩解了數(shù)據(jù)稀疏性, 融合了簽到信息、朋友信息、地理位置信息和類(lèi)別信息對(duì)興趣點(diǎn)推薦的影響. 而且, 本模型中, 改進(jìn)了地理位置對(duì)興趣點(diǎn)推薦的影響, 根據(jù)用戶的歷史簽到足跡來(lái)估計(jì)地理位置因素對(duì)目標(biāo)用戶的影響, 保護(hù)了用戶的隱私信息, 表現(xiàn)出了最好的推薦效果.
4.4.2 要素影響分析
從圖3、圖4中我們可以看出: (1)三個(gè)要素對(duì)于興趣點(diǎn)推薦都發(fā)揮著重要作用, 且融合三個(gè)要素時(shí)推薦效果最好; (2)朋友信息、地理位置信息對(duì)興趣點(diǎn)推薦的影響大于類(lèi)別信息對(duì)于推薦的影響. 分析其原因,主要在于用戶在選擇興趣點(diǎn)時(shí)受到了多個(gè)方面的影響,如朋友的介紹、距離的遠(yuǎn)近和自己的愛(ài)好等等, 所以我們不能片面地根據(jù)某一影響因素進(jìn)行建模. 在SoGeoCat模型的第二步中運(yùn)用了矩陣分解算法, 在矩陣分解算法中訓(xùn)練出的用戶特征向量和矩陣特征向量中也有考慮到社會(huì)關(guān)系、地理位置等因素的影響, 但是在特征矩陣中沒(méi)有具體地說(shuō)明.
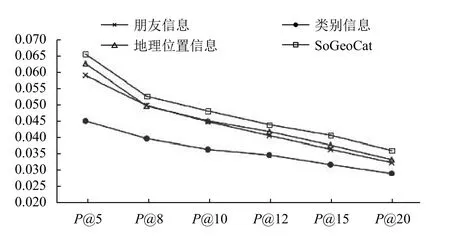
圖3 基于Foursquare數(shù)據(jù)集各要素間的準(zhǔn)確率對(duì)比
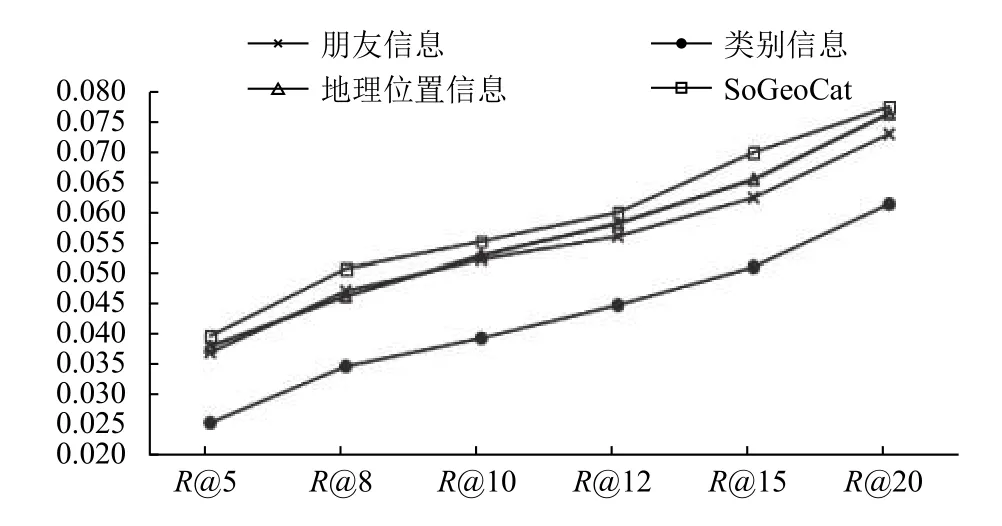
圖4 基于Foursquare數(shù)據(jù)集各要素間的召回率對(duì)比
4.4.3 用戶潛在興趣點(diǎn)數(shù)據(jù)模型影響分析
在這個(gè)部分中, 我們比較納入用戶潛在興趣點(diǎn)數(shù)據(jù)模型的推薦模型和未納入用戶潛在興趣點(diǎn)數(shù)據(jù)模型的推薦模型的推薦效果, 圖5、圖6結(jié)果表明, 納入用戶潛在興趣點(diǎn)數(shù)據(jù)模型的推薦效果優(yōu)于未納入用戶潛在興趣點(diǎn)數(shù)據(jù)模型的推薦效果. 分析其原因, 主要有兩點(diǎn): (1)雖然矩陣分解算法中已經(jīng)將朋友信息、類(lèi)別信息和地理位置信息考慮在特征矩陣之中, 但是不能確切地說(shuō)明. 我們通過(guò)用戶潛在興趣點(diǎn)數(shù)據(jù)模型, 單獨(dú)考慮了朋友信息和地理位置信息的影響, 利于發(fā)揮其對(duì)推薦效果的影響; (2)用戶潛在興趣點(diǎn)數(shù)據(jù)模型不僅考慮了這三個(gè)要素, 它還為偏好矩陣填充了大量的潛在興趣點(diǎn)的簽到信息, 緩解了數(shù)據(jù)稀疏性.
還有一個(gè)有趣的發(fā)現(xiàn), 表2中只考慮類(lèi)別信息的模型的推薦效果低于未納入用戶潛在興趣點(diǎn)數(shù)據(jù)模型的的推薦模型的推薦效果. 因?yàn)榍罢咴谟?jì)算用戶潛在興趣點(diǎn)數(shù)據(jù)模型時(shí), 沒(méi)有考慮朋友信息和地理位置信息, 使得計(jì)算出來(lái)的潛在興趣點(diǎn)與實(shí)際用戶偏好有較大的出入, 于是將其帶入矩陣分解算法中的時(shí)候產(chǎn)生了噪聲, 影響推薦效果.
5 結(jié)論與展望
SoGeoCat模型采用了混合算法, 融合了兩種算法的優(yōu)點(diǎn), 既考慮了用戶之間的相似性又緩解了數(shù)據(jù)稀疏問(wèn)題. SoGeoCat模型還融合了類(lèi)別標(biāo)簽, 保護(hù)了用戶的常駐位置信息. 通過(guò)對(duì)真實(shí)的Foursquare數(shù)據(jù)集進(jìn)行實(shí)驗(yàn), 實(shí)驗(yàn)結(jié)果表明, SoGeoCat模型相對(duì)于其他三個(gè)對(duì)比模型而言在Precision和Recall上都表現(xiàn)出較好的推薦效果.
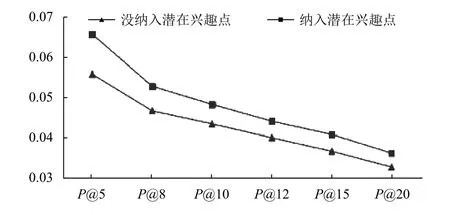
圖5 基于Foursquare數(shù)據(jù)集是否納入潛在興趣點(diǎn)模型的準(zhǔn)確率對(duì)比

圖6 基于Foursquare數(shù)據(jù)集是否納入潛在興趣點(diǎn)模型的召回率對(duì)比
未來(lái), 希望在此模型的基礎(chǔ)上, 納入“時(shí)間信息”和“評(píng)論信息”等上下文信息, 進(jìn)一步地提高推薦算法的精確度和召回率.
猜你喜歡
中學(xué)生數(shù)理化·八年級(jí)物理人教版(2022年3期)2022-03-16 05:55:08
當(dāng)代陜西(2021年2期)2021-03-29 07:41:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(chē)(2016年11期)2016-12-19 01:20:16
商用汽車(chē)(2016年6期)2016-06-29 09:18:54
中國(guó)塑料(2016年3期)2016-06-15 20:30:00
商用汽車(chē)(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會(huì)展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
