基于GDBN網(wǎng)絡(luò)的文本情感傾向分類算法①
2019-01-18 08:30:20陳穎熙廖曉東蘇例月
計算機系統(tǒng)應(yīng)用 2019年1期
陳穎熙, 廖曉東,2,3, 蘇例月, 陶 狀
1(福建師范大學(xué) 光電與信息工程學(xué)院, 福州 350007)
2(福建師范大學(xué) 醫(yī)學(xué)光電科學(xué)與技術(shù)教育部重點實驗室 福建省光子技術(shù)重點實驗室, 福州 350007)
3(福建師范大學(xué) 福建省先進光電傳感與智能信息應(yīng)用工程技術(shù)研究中心, 福州 350007)
1 引言
近年來, 隨著互聯(lián)網(wǎng)信息技術(shù)的高速發(fā)展, 各種社交平臺和電子商務(wù)平臺的興起使得門戶網(wǎng)站上的評論信息呈指數(shù)增長, 用戶通過移動網(wǎng)絡(luò)可以方便、自由的對人或事進行評價與分析, 表達自己的看法、觀點以及情感傾向[1]. 面對線上各大平臺的大量無規(guī)律的評論詞語和文本內(nèi)容, 有必要利用自然語言處理技術(shù)建立一種智能高效的文本情感分類模型對文本所表達的情感傾向(正向、負向、中立)進行分析判斷, 從海量無規(guī)律的文本數(shù)據(jù)中提取重要的信息.
目前, 互聯(lián)網(wǎng)上的信息大多以短文本的形式存在,例如淘寶商品評論、搜索引擎的搜索結(jié)果、微博、豆瓣、文檔文獻摘要等. 其中在微博評論中就有明確規(guī)定字數(shù)必須限制在140字以內(nèi). 由于短文本具有特征稀疏性、實時性、動態(tài)性、交錯性、不規(guī)則性等特點[2],傳統(tǒng)的文本情感分類方法對其分類的準確率較低, 無法達到理想的結(jié)果.
短文本在搜索引擎、論壇信息交流等方面具有重要作用, 因此對短文本情感分類的研究具有一定的實用價值并且得到了廣泛的關(guān)注. 近些年國內(nèi)外學(xué)者們提出了許多在文本情感傾向性分類的有效的方法, 大致可分為三大類, 即基于規(guī)則的方法、基于機器學(xué)習(xí)的方法和深度學(xué)習(xí)方法.
基于規(guī)則的方法最早是由麻省理工媒體實驗室的Picard教授提出[3], 它通過將文本中表達情感傾向的詞語與已建立的情感詞典對比然后進行評估打分, 進而通過計算分數(shù)實現(xiàn)文本情感傾向性分類. 由于該方法過分依賴于人工構(gòu)建的詞典, 所以存在一系列缺點, 如詞典覆蓋面窄、易丟失部分有挖掘價值的文本數(shù)據(jù)、易受到一詞多義的影響等,并且該方法難以捕捉到深層次特征.
基于深度學(xué)習(xí)的文本情感分類方法是近幾年的研究熱點, 它廣泛應(yīng)用于計算機視覺領(lǐng)域和音頻領(lǐng)域, 近幾年才被引用到自然語言處理領(lǐng)域中, 其中深度置信網(wǎng)絡(luò)(Deep Belief Networks, DBN)[4]是最經(jīng)典的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)之一, 它彌補了機器學(xué)習(xí)方法的局限性, 可以通過網(wǎng)絡(luò)模型自動地學(xué)習(xí)提取文本的深層次特征,但是存在隱層單元個數(shù)的選擇問題. 深度置信網(wǎng)絡(luò)的隱層單元個數(shù)通常依據(jù)經(jīng)驗進行認為選擇, 且一旦選定則無法修改. 當(dāng)隱層單元數(shù)超過所需個數(shù)時, 多余的隱層單元會增加網(wǎng)絡(luò)的復(fù)雜度, 使得計算量變大從而導(dǎo)致訓(xùn)練時間呈指數(shù)增長; 當(dāng)隱層單元數(shù)低于所需個數(shù)時, 由于網(wǎng)絡(luò)無法滿足訓(xùn)練所需規(guī)模, 從而導(dǎo)致達不到理性的訓(xùn)練結(jié)果. 因此, 本文提出了GDBN網(wǎng)絡(luò)(Genetic Deep Belief Networks), 通過利用遺傳算法 (Genetic Algorithm, GA)[5]的全局快速尋優(yōu)的能力對DBN的隱層單元個數(shù)自動進行設(shè)定. 實驗結(jié)果表明, 本文所提出的GDBN網(wǎng)絡(luò)在文本情感傾向性分類中能取得較好的分類效果.
2 相關(guān)工作
2.1 深度置信網(wǎng)絡(luò)
深度置信網(wǎng)絡(luò)(Deep Belief Networks, DBN)最初是由Hinton等學(xué)者于2006年提出的一種由多層RBMs堆疊和一層反向傳播(Back Propagation)網(wǎng)絡(luò)組成的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)[4]. DBN的主要任務(wù)是實現(xiàn)對數(shù)據(jù)從底層到高層的特征提取, 幫助系統(tǒng)將數(shù)據(jù)分類成不同的類別. 其網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示[6].
DBN的訓(xùn)練步驟分為兩步: 第一步為預(yù)訓(xùn)練, 對網(wǎng)絡(luò)中RBMs采用逐層無監(jiān)督的方法來學(xué)習(xí)各層參數(shù), 使得每層RBM達到最佳特征表示; 第二步為微調(diào),將BP網(wǎng)絡(luò)輸出數(shù)據(jù)和標準標注信息進行對比, 對從下往上的認知權(quán)重w和從上往下的生成權(quán)重進行反向微調(diào), 以得到更好的生成模型.
近些年來學(xué)者們在DBN模型上提出了一系列的改進, 使得改進后的模型能夠更高效的應(yīng)用于文本檢測. 例如, Mleczko等[7]在DBN模型的基礎(chǔ)上引入粗糙集理論(RDBN), RDBN模型主要用于識別與分類具有缺失文字的文本信息. Jiang等[8]提出將采用不同參數(shù)優(yōu)化算法的Softmax分類器與DBN模型結(jié)合, 利用分類器對DBN所提取到的文本數(shù)據(jù)特征進行分類, 該模型能有效地提高分類精度.
2.2 RBM預(yù)訓(xùn)練過程
受限玻爾茲曼機(Restricted Boltzmann Machine,RBM)[9]是以玻爾茲曼機為基礎(chǔ)的改進算法, 它是一種具有快速學(xué)習(xí)和簡單網(wǎng)絡(luò)結(jié)構(gòu)的無監(jiān)督訓(xùn)練特征提取器. 其結(jié)構(gòu)模型如圖2所示.

圖2 RBM結(jié)構(gòu)模型圖

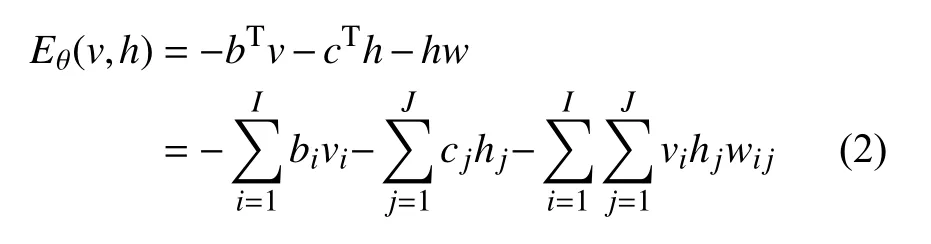

(2) Gibbs采樣. 通過Gibbs采樣得到
訓(xùn)練時, 采用逐層無監(jiān)督的方法來學(xué)習(xí)參數(shù). 進而完成DBN的預(yù)訓(xùn)練過程.
2.3 BP網(wǎng)絡(luò)微調(diào)過程
RBM訓(xùn)練中無監(jiān)督學(xué)習(xí)方法只能使得該層單元狀態(tài)達到局部最優(yōu), 然而并不能使模型整體效果最優(yōu),因此, 采用BP網(wǎng)絡(luò)[12]對整個網(wǎng)絡(luò)的參數(shù)進行微調(diào). 在RBM完成預(yù)訓(xùn)練后, 將RBM訓(xùn)練好的數(shù)據(jù)正向傳播,做為BP網(wǎng)絡(luò)的輸入, 當(dāng)輸出數(shù)據(jù)和標準標注信息有誤差時, 利用BP網(wǎng)絡(luò)的誤差反向傳播的特性, 對從下往上的認知權(quán)重w和從上往下的生成權(quán)重以及偏置進行微調(diào), 讓整個網(wǎng)絡(luò)的單元狀態(tài)達到全局最優(yōu), 以得到更好的生成模型.
3 GDBN情感分類算法
本文提出的基于GDBN網(wǎng)絡(luò)的文本情感傾向性分類算法的主要工作有: 首先通過網(wǎng)絡(luò)爬蟲程序從微博平臺上采集實驗所需文本數(shù)據(jù), 之后對文本數(shù)據(jù)進行預(yù)處理, 然后通過遺傳算法來改進深度置信網(wǎng)絡(luò)模型, 并以此模型進行深層建模與特征提取, 最后通過反向傳播網(wǎng)絡(luò)對提取到的特征進行情感傾向性分類.
3.1 GDBN理論基礎(chǔ)
遺傳深度置信網(wǎng)絡(luò)(GDBN)是結(jié)合遺傳算法(Genetic Algorithm, GA)[5]和深度置信網(wǎng)絡(luò)(Deep Belief Networks, DBN)[4]的學(xué)習(xí)方法, 它利用遺傳算法的全局尋優(yōu)搜索能力對DBN的隱層單元個數(shù)進行自動尋優(yōu),結(jié)合DBN強大的數(shù)據(jù)特征提取和處理高復(fù)雜度的非線性數(shù)據(jù)的能力, 使網(wǎng)絡(luò)模型效果更接近于其上限.GA具有較強全局尋優(yōu)搜索能力, 然而它最大的缺點就是易出現(xiàn)“早熟”現(xiàn)象, 即容易陷入局部極值, 導(dǎo)致神經(jīng)網(wǎng)絡(luò)參數(shù)質(zhì)量不高, 所以在設(shè)計GDBN算法的遺傳操作中, 增大交叉率和變異率. GDBN算法設(shè)計如下:
(1)編碼
(2)適應(yīng)度函數(shù)
GDBN網(wǎng)絡(luò)模型中可見層和隱層之間表現(xiàn)為層內(nèi)無連接, 層間全連接, 隱單元的狀態(tài)只與可見單元有關(guān), 所以在函數(shù)設(shè)計時不但要考慮樣本的似然程度還要考慮維度對模型訓(xùn)練的影響.
本文采用重構(gòu)誤差[13]的方法來評價樣本的似然程度, 所謂重構(gòu)誤差就是通過Gibbs采樣重構(gòu)的單元與訓(xùn)練樣本原始數(shù)據(jù)的平方差, 其具體流程如下:


式中,I為可見單元個數(shù),S為樣本維度, 根據(jù)適應(yīng)度的大小對個體進行選擇, 當(dāng)適應(yīng)度值越大時, 則個體越好,即該個體對應(yīng)的GDBN模型似然度最高.
(3)遺傳操作
在遺傳算法(GA)改進網(wǎng)絡(luò)模型后, 進一步優(yōu)化精調(diào)真?zhèn)€模型, 其算法流程如圖3所示.

圖3 算法流程
3.2 框架實現(xiàn)
(1)文本預(yù)處理: 將通過爬蟲得到的數(shù)據(jù)內(nèi)容進行處理, 將其中涉及到個人隱私、url鏈接或敏感信息的內(nèi)容刪除.
(2)分詞、去停用詞: 由于中文評論無法像英文評論一樣直接通過空格來分隔單詞, 所以本文采用Jieba工具, 進行中文分詞, 并去掉停用詞, 如“的”、“和”等一些出現(xiàn)頻率高但無情感意義的詞, 為特征提取提供較為準確的基元.
(3)特征提取: 通過GDBN網(wǎng)絡(luò)模型進行深層建模與特征提取.
(4)情感分類: BP網(wǎng)絡(luò)對提取到的特征進行情感傾向性分類.
4 實驗驗證及結(jié)果分析
4.1 實驗環(huán)境與數(shù)據(jù)
本文具體實驗環(huán)境如表1所示.
為了驗證本文所提出的分類算法的有效性, 本文基于三個中文文本數(shù)據(jù)集進行實驗驗證. (1)使用中科院譚松波教授的酒店評論語料(D1), 該語料采集于攜程網(wǎng), 規(guī)模為 10 000 篇, 被整理成 4 個子集, 1、ChnSentiCorp-Htl-ba-2000: 平衡語料, 正負類各 2k; 2、ChnSentiCorp-Htl-ba-4000:平衡語料, 正負類各 4k; 3、ChnSentiCorp-Htl-ba-6000: 平衡語料, 正負類各 3k; 4、ChnSentiCorp-Htl-ba-10000: 非平衡語料, 其中正類為7k. (2)使用COAE2014微博觀點數(shù)據(jù)集, 在該數(shù)據(jù)集中隨機抽取30 000條作為實驗數(shù)據(jù)集, 對其中部分訓(xùn)練數(shù)據(jù)進行不同情感傾向的人工標注, 主要情感有開心、憤怒、厭惡、低落四個類別. (3)通過網(wǎng)絡(luò)爬蟲程序從微博平臺上采集的50 000條微博數(shù)據(jù)(D3), 其中標注的積極微博有25 000條, 消極微博有20 000條,中性微博有5000條. 考慮到其中部分能容可能含有用戶隱私, 刪除了數(shù)據(jù)集中的url鏈接等信息.

表1 實驗環(huán)境
4.2 實驗設(shè)計
實驗方案總體過程如圖4所示.

圖4 實驗方案
首先對訓(xùn)練數(shù)據(jù)進行預(yù)處理, 生成文本特征向量,然后將訓(xùn)練后的GDBN情感分類模型用于測試數(shù)據(jù)分類并檢驗分類效果.
4.3 性能評估
precision主要體現(xiàn)模型對負樣本的區(qū)分能力, 通常用P表示, 設(shè)TP為分類正確的文本數(shù),N為樣本總數(shù),其計算公式如下:

recall主要體現(xiàn)模型對正樣本的識別能力, 通常用R表示, 設(shè)N+為某一類的樣本總數(shù), 其計算公式如下:

F1值為兩者的綜合, 當(dāng)F1值越高時證明模型越好. 其計算方法如下:

4.4 實驗結(jié)果與分析
為了驗證本文提出的基于GDBN網(wǎng)絡(luò)的文本情感傾向性分類算法的有效性, 將SVM、DBN與本文算法進行對比, 其對比實驗結(jié)果如表2所示. 且作出GDBN算法用于三個中文文本數(shù)據(jù)集(D1、D2、D3)的迭代曲線圖如圖5所示, 其結(jié)果表明, GDBN算法較于DBN和SVM算法更能有效的對文本情感傾向進行分類.
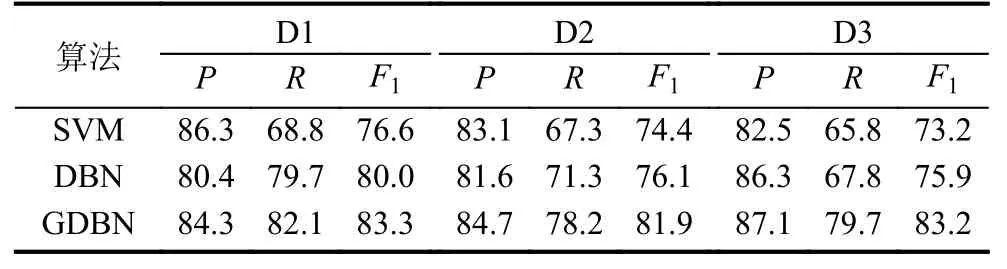
表2 實驗結(jié)果對比(單位: %)

圖5 GDBN迭代曲線圖
本文對三種分類算法做ROC曲線進行模型評估,如圖6所示. ROC曲線下面積越大代表模型性能越好,由圖6可知基于GDBN算法的文本情感分類模型具有更高的分類性能.
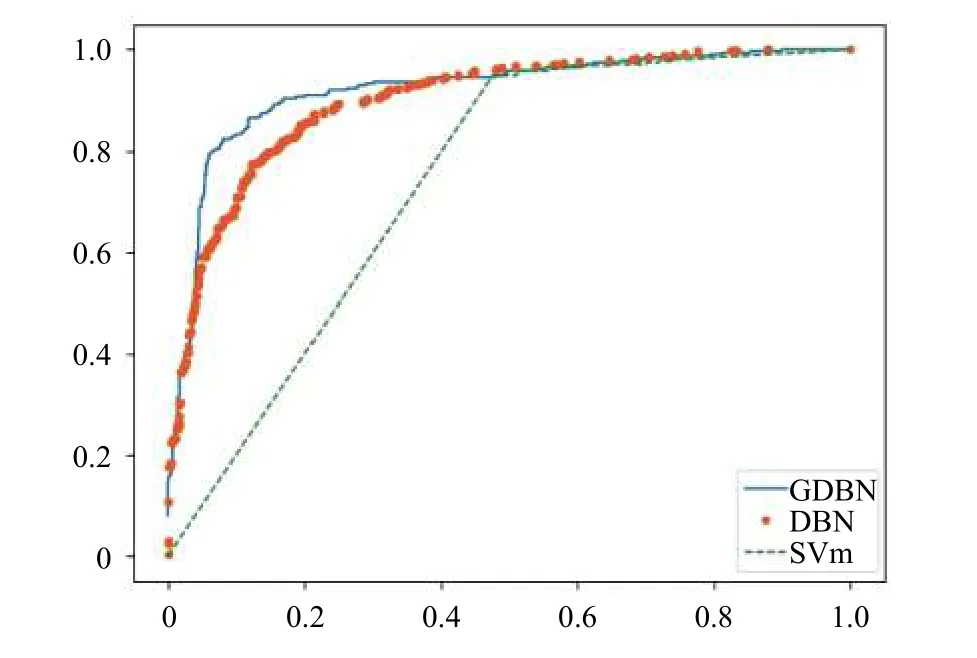
圖6 ROC曲線圖
5 結(jié)語
為了更好的解決中文文本情感分類問題, 本文基于深度學(xué)習(xí)算法構(gòu)建了一個GDBN網(wǎng)絡(luò)模型, 針對DBN網(wǎng)絡(luò)人工進行隱層單元個數(shù)選擇從而導(dǎo)致模型性能存在極大不確定性的問題, 引入具有強大全局尋優(yōu)搜索能力的遺傳算法, 根據(jù)實驗輸入數(shù)據(jù)自行對隱單元個數(shù)尋優(yōu), 取得當(dāng)前模型的適宜值. 經(jīng)實驗驗證可得, 本文所提方法在分類準確性和降低模型復(fù)雜性上均有提升, 能取得良好的效果, 但仍存在不足. 在今后的工作中, 將繼續(xù)改進本文算法, 比如在對提取到的特征進行分類時候, 針對BP網(wǎng)絡(luò)存在的網(wǎng)絡(luò)“震蕩”等問題, 采用XGBoost算法來進行分類, 進一步提高模型情感分類的精度.
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
