抗傾斜的中文文本圖像文件識別技術①
2019-01-18 08:29:52周一楓張華熊
計算機系統應用 2019年1期
周一楓, 張華熊
(浙江理工大學 信息學院, 杭州 310018)
現階段在紙質資料數字化的大背景下, 傳統的紙質資料由于占空間、不便保存、查找繁瑣、易丟失等缺點正被數字化的資料所取代, 然而傳統的數字化大量采用的是掃描方式, 以圖像的形式進行各種資料的存檔保存. 在實際應用中如何快速從大量的數字化圖像文件中找出中文印刷體文本圖像文件進行OCR (Optical Character Recognition) 識別是一個現實存在的實際需求.
針對圖像文本的檢測技術目前主要有以下5種: (1)基于邊緣的方法; (2)基于連通域的方法; (3)基于紋理的方法; (4)基于深度學習的方法; (5)基于上述混合的方法.其中Epshtein等人[1]提出的筆畫寬度變換算法(Stroke Width Transform, SWT)由于利用了文字特有的筆畫寬度特征, 因而在文本檢測算法中被廣泛使用, Yao等人[2]在SWT算法的基礎上提出了一種檢測自然場景下任意傾斜角度的文本, 但該算法處理時間較長, 不太適合在批量文本圖像文件檢測中使用. Chen等人[3]在SWT算法基礎之上, 提出了一種利用邊緣增強的MSER技術[4], 該方法較好的提取極值區域, 但在傾斜文本的檢測上, 效果不太理想并且處理耗時長. 還有最近這幾年由于深度學習技術[5]的快速發展, 基于深度學習的技術也開始應用在圖像文本檢測中, 其中Zhou等人[6]提出了利用全卷積網絡(FCN)模型來檢測文本, 在ICDAR2015[7]測試數據集上, 取得了F值為0.8072的效果. Tian 等人[8]提出了一種應用卷積模型VGG16結合雙向長短時記憶網絡 (Bi-LSTM)的方法, 在 ICDAR2011, ICDAR2013, ICDAR 2015 測試數據集上, 分別取得了 0.84, 0.88, 0.61 的F值效果, 然而由于神經網絡的訓練, 往往需要大量的訓練數據, 才能有比較好的訓練效果, 有時各種數據的獲取難度也較大, 故也不好利用在本文的檢測算法中.
在中文文本檢測方面, 繆裕青等人[9]根據漢字的結構特征, 通過分別改進MSER和SWT的方法來檢測中文, 在自建的中文環境自然場景圖像數據庫上, 取得了F值為0.794的效果. Ren等人[10]通過在CNN卷積神經網絡的基礎之上, 設計了一種適合中文文本結構組件的檢測器(TSCD)層來增加檢測中文的正確率.Jiang等人[11]通過采用Harris角點檢測的方法來選擇初始的文字候選區域, 然后基于區域特征、文本筆畫寬度、顏色信息過濾非文本區域, 最后再結合行掃描的方法來檢測中文, 在自建的中文圖像數據庫上, 取得了F值為0.703的效果.
傳統的SWT算法因為是以英文文字為研究對象,而中文相較英文而言, 在字符筆畫, 結構上都更加復雜,因而在檢測中文的效果上, SWT效果并不十分理想,同時我們研究發現, 在有傾斜的文本檢測效果中, SWT算法由于一般以檢測水平文本為目標, 在傾斜文本的檢測上, 效果也不太理想.
通過非固定式移動相機或者掃描儀對文本圖像文件進行數字化掃描的過程中, 由于相機的抖動或者掃描文本放置角度的偏斜, 數字化后的文本圖像難免會存在著一定的傾斜角度, 傳統的OCR識別技術對待識別圖像是否存在傾斜角度, 有著較強的敏感性, 傾斜角度的存在不僅影響著文本圖像檢測的準確性, 也會降低后續文本圖像文件進行OCR識別的性能.
Sakila等人[12]通過對比實驗, 研究了現有的4種常見的文檔圖像傾斜校正的方法: (1)基于霍夫變換的方法; (2)基于互相關的方法; (3)基于K近鄰的方法;(4)基于傅里葉變換的方法. 其中基于傅里葉變換的方法由于利用了傅里葉變換的旋轉不變性, 從而在對文檔圖像的傾斜校正方面, 擁有較好的魯棒性. 實驗結果也表明, 上述方法中基于傅里葉變換[13,14]的圖像傾斜校正方法在校正正確率以及處理時間上效果都是最優的.
由于本文算法只是用于是否是文本圖像文件的識別, 因此識別時不需要檢測出所有的文字區域, 我們只需判斷檢測圖像是否帶有中文即可, 同時利用中文印刷體圖像文本行與空白行交替變化的水平投影分布特征, 運用水平投影技術快速提取第一行文本, 在SWT算法中新增前景文本像素數所占的特定比率特性, 來檢測文本行連通域, 即可判斷圖像是否帶有中文,以便決定是否進行OCR識別.
1 算法設計
本文圖例所示的文本圖像均以政府部門、企事業單位所使用的紅頭文件[15]為主, 提出的算法基本流程如圖1所示, 主要步驟分為圖像預處理、圖像傾斜檢測、水平投影、邊緣檢測、SWT變換這5個步驟.
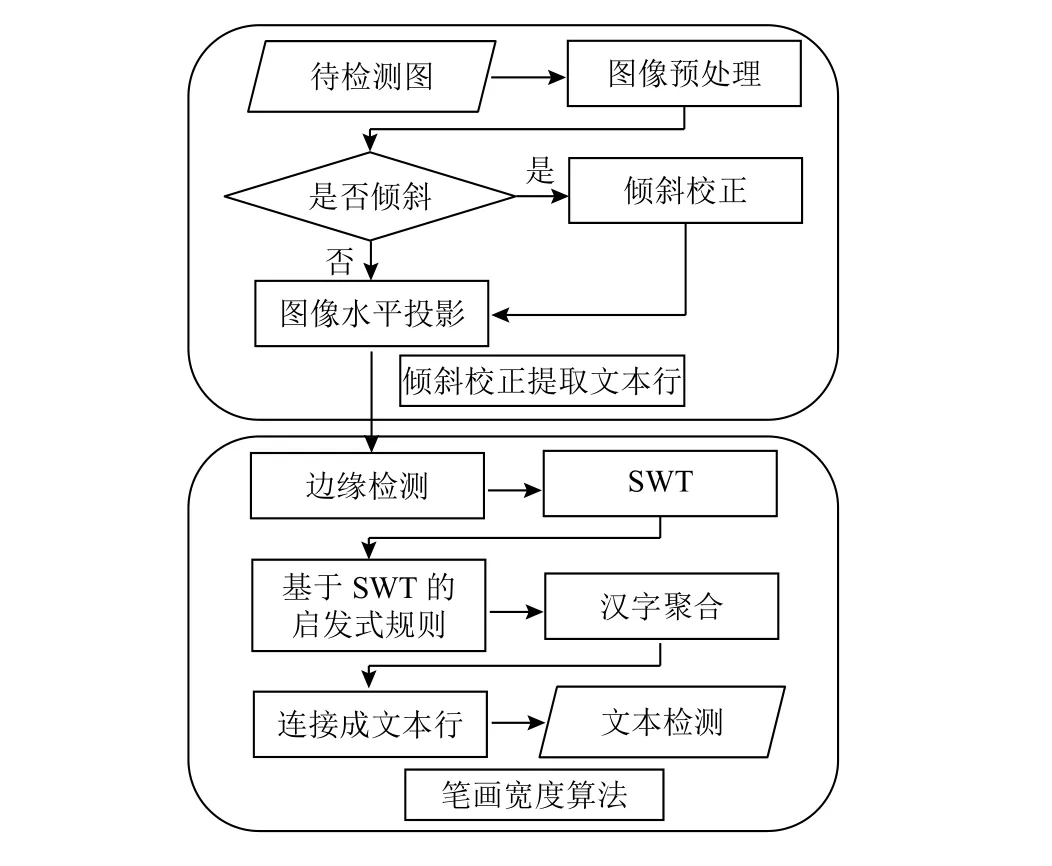
圖1 文本圖像文件識別算法基本流程
a) 圖像預處理. 首先對圖像寬度大于650像素且高度大于 850 像素的圖像, 縮放到 650×850 像素, 以加快圖像檢測速度.
b) 圖像傾斜檢測. 由于基于傅里葉變換的圖像傾斜校正方法具有時間短、準確率高的優點. 本文對每一幅待檢測圖像, 進行二維離散傅里葉變換, 根據圖像高低頻譜交換頻譜象限區域, 移頻到圖像中心、然后采用大津閾值法對圖像進行二值化處理, 同時利用霍夫線檢測方法檢測出傾斜直線與水平直線相交的傾斜角度θ, 根據此傾斜角度θ, 校正傾斜圖像.
c) 水平投影. 將進行傾斜校正后的圖像, 進行水平投影, 根據文本區域與空白區域的水平投影直方圖投影分布區間來快速提取出識別區域.
d) 邊緣檢測. 利用canny算子, 提取文本行的邊緣檢測圖.
e) 改進的SWT算法. 首先根據文本特有的固定筆畫寬度特征, 計算每個像素的筆畫寬度(歐式距離), 得到包含文字筆畫寬度信息的SWT圖像, 然后查找文字候選區域, 對其中明顯不符合中文文字的區域基于改進的SWT文本啟發式規則進行過濾, 得到字符連通域. 對滿足相關聚類條件的字符候選區域聚類成行, 形成文本行連通域, 最后對文本行連通域進行基于啟發式規則的檢測, 從而識別出待檢測的圖像是否是中文印刷體圖像.
2 離散傅里葉變換
2.1 圖像頻譜成分
對于一副圖像, 變換域的圖像能量主要集中在低頻部分, 其頻譜分布示例圖如圖2所示.

圖2 傅里葉變換頻譜分布
圖2中, 圖2(a)為紅頭文件傾斜圖; 圖2(b)為圖2(a)帶有傾斜角度的紅頭文件對應的傅里葉變換頻譜圖.
2.2 圖像傅里葉變換平移效果圖
圖3為圖像傅里葉變換平移效果圖, 其中, 圖3(a)為傾斜的紅頭文件; 圖3(b)為傅里葉頻譜平移圖;圖3(c)為傅里葉頻譜平移二值化圖; 圖3(d)為根據平移效果圖計算出的傾斜角度θ.
通過對傾斜圖像采用二維離散傅里葉變換, 來對傾斜圖像在[-90,90]度之間進行校正, 從而獲得更好的文本檢測效果.
3 圖像水平投影與切割
印刷體文本圖像, 包括紅頭文件等一些文本圖像,文本行與空白行之間有著明顯的明亮交替特征, 由此我們根據圖像水平投影直方圖的原理, 對中文印刷體圖像進行水平投影處理, 提取我們的ROI(感興趣區域), 提高文本檢測效率.

圖3 圖像傅里葉變換平移
圖4是圖像水平投影直方圖, 其中, 圖4(a)為Lena 圖; 圖 4(b)為圖 4(a)的水平投影圖; 圖4(c)為紅頭文件; 圖4(d)為圖4(c)對應的水平投影直方圖.

圖4 圖像水平投影直方圖
4 改進的筆畫寬度算法
基于自然場景的文本檢測, 一直是國內外的研究熱點, 傳統的自然場景文本檢測算法, 基本上都是以英文文本為檢測對象, 對于像中文這種筆畫多樣, 結構復雜的象形類文字, 檢測效果往往不太理想, 本文基于SWT算法的基礎之上, 利用了該算法將文本筆畫寬度作為文字一個固有特征來提取文本文字, 同時結合中文固有的筆畫結構特征, 設計了以下4點啟發性規則:
(a)增加文本行前景像素數占連通區域的占有比,來進一步過濾掉強干擾噪點, 使檢測中文文本的效果更加魯棒, 經測定當前景像素數占整體文本行連通域的比值SwtRule1>0.6時, 效果最優. 公式如(1)所示:
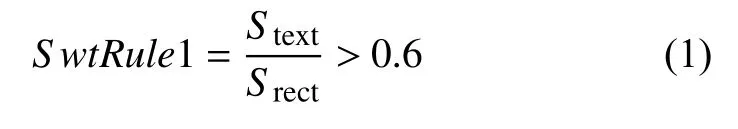
其中,Stext為前景像素數面積,Srect為整體文本行連通域面積.
(b)增加文本行連通域高寬比, 公式如(2)所示:
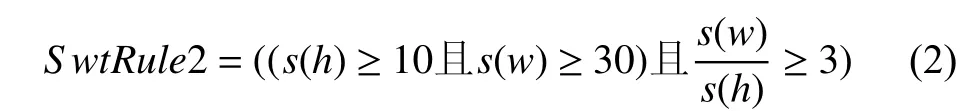
其中,s(h),s(w)分別為文本行連通域的高與寬.
(c)針對原算法對查找文字筆畫寬度的方向閾值π/6, 進行了適當的修正, 我們在檢測研究的過程中發現, 原算法閾值π/6, 在針對英文文本這類文字形態變換簡單的語言上, 效果尚可, 在針對中文這類形態復雜的文字上, 該閾值設定過于嚴格, 導致檢索筆畫寬度方向的過程中常常出現筆畫越界現象, 經我們針對中文印刷體圖像的研究發現, 當檢測筆畫寬度方向閾值為π/3 時, 效果最優, 公式如 (3)所示:
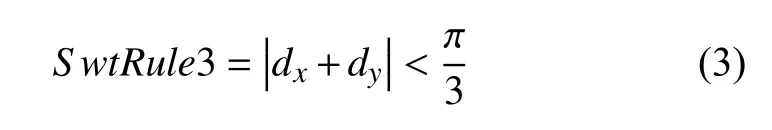
其中,x為筆畫邊緣像素點,dx為其梯度方向;y為對應檢索方向上邊緣像素點,dy為其梯度方向.
(d)針對中文的筆畫特征, 重新設定了字符連通域筆畫的方差與連通域均值的比值, 公式如(4)所示.

其中,SwtVariance為字符連通域筆畫的方差,SwtMean為字符連通域筆畫的均值.
5 針對中文印刷體的檢測算法改進
對于中文印刷體圖像, 我們采取通過水平投影直方圖的方法來快速提取檢測文本行, 同時我們設定規則排除中文印刷體中明顯不是文本的投影區域(類似紅頭文件固有的紅線), 公式如下所示:

其中,proEindex為水平投影圖的文本行結束索引,pro-Sindex為文本行開始索引.
為了提高檢測速度, 我們分別對輸入圖像的大小以及檢測的文本區域進行了設定優化, 經研究發現把輸入圖像寬高(W×H)大于650×850像素的圖像按公式(6)設定時, 檢測效果最優.

其中, 650和850分別為圖像的寬與高, 單位為像素;input-Size為輸入圖像大小;imageSize為處理圖像大小.
在檢測文本區域上, 我們采取優先選取首行文本為檢測對象, 同時為了保證對于傾斜角度過大的文本,圖像校正之后出現文字消失, 我們追加了正文頭三行為檢測感興趣區域, 保證了圖像傾斜角度過大時, 圖像文字區域的文字消失給檢測帶來的干擾, 同時也避免了對整個文本的檢測, 也加快了算法檢測速度.
文本圖像文件檢測具體流程圖如圖5所示.

圖5 文本圖像文件檢測流程
圖5中, 圖5(a)為待文字檢測的水平圖與傾斜圖;圖5(b)為經過傅里葉變換的傾斜校正圖; 圖5(c)為經過水平投影直方圖提取到的檢測ROI區域; 圖5(d)為經過Canny邊緣檢測的效果圖; 圖5(e)為包含像素筆畫寬度信息的SWT圖; 圖5(f)為基于啟發式規則過濾的文本行; 圖5(g)為文字檢測結果輸出圖; 圖5(f)與圖5(g)是我們為了更好的說明我們的檢測流程, 實體化的效果圖, 在我們實際的檢測算法中圖5(f)與圖5(g)的過程我們合為一步, 最終是否是文本圖像文件的檢測結果記入到日志當中.
6 實驗與結果分析
6.1 中文文本圖像樣本庫建立
本文采用的圖像測試樣本集為我們自己建立的紅頭文件樣本庫, 我們以每2度為一個傾斜角度對測試圖像在[-90,90]度上進行旋轉, 測試集含有水平, 以及上述傾斜角度的紅頭文件圖像, 共計1106張. 同時為了驗證在自然場景下對圖像文件的識別效果, 我們從ImageNet2012[16]視覺識別挑戰賽50 000張測試集中挑選出500張圖作為非文本類場景測試集. 上述測試集圖像庫共計1606張圖像.
6.2 圖像傾斜校正對比實驗
為了驗證傾斜圖像的傾斜角度與基于二維離散傅里葉變換方法檢測得到的傾斜角度之間的正確性, 我們從1106張傾斜圖像測試集中選取了1092張圖, 按每10度區間作為一個測試分組, 共計18個分組對傾斜圖像校正進行對比實驗, 測試結果如表1、表2.

表1 圖像傾斜角度分組對比結果
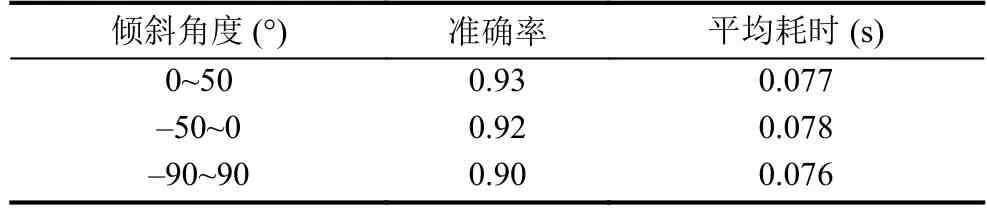
表2 圖像傾斜校正整體對比結果
表1與表2的實驗結果表明, 通過基于二維離散傅里葉變換對傾斜圖像進行傾斜校正, 在各個測試分組, 常見的文本傾斜角度[-50,50]區間上, 以及在整體傾斜角度[-90,90]區間上, 都有較好的校正效果.
6.3 文本檢測結果對比規則
實驗采用文本檢測領域常用的以準確率、召回率和F值為主要指標, 來評價文本檢測方法的效果, 具體計算公式如下 (7), (8), (9)所示.
準確率(P)的公式如下:

召回率(R)的公式是:

F值計算公式如下:

其中, (1)TP: 為正確檢測到的文本文件數; (2)FN: 為漏檢的文本文件數; (3)FP: 為錯誤檢出的文本文件數.
我們比較了 Epshtein[1], Chen[3], 以及 Zhou[6]的算法. 測試結果如表 3, 圖 6, 表 4, 圖 7 所示.
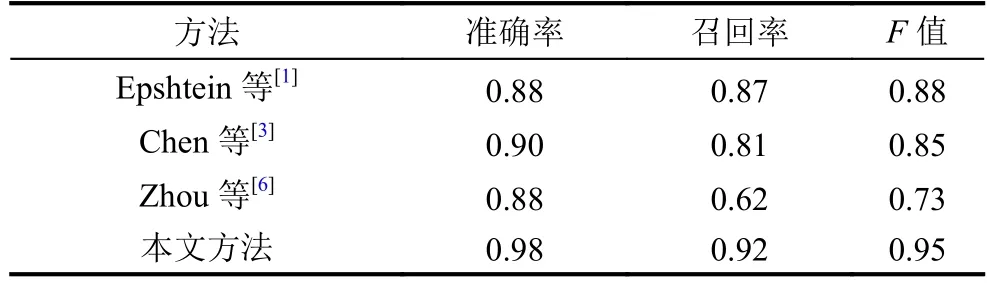
表3 不同文本檢測算法的準確率, 召回率和F值
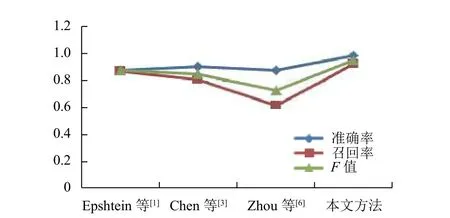
圖6 不同文本檢測算法的準確率, 召回率和F值
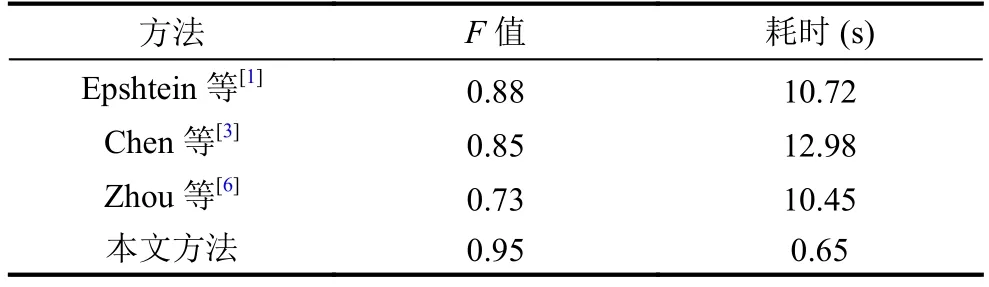
表4 文本圖像中文檢測的F值與耗時結果
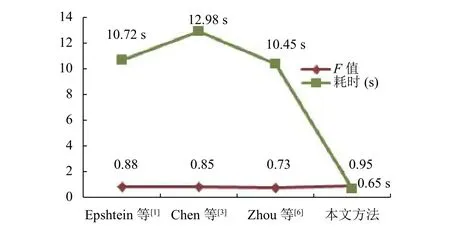
圖7 文本圖像中文檢測的F值與耗時結果
7 結束語
本文通過采用二維離散傅里葉變換的方法, 對傾斜中文印刷體文本圖像文件在[-90,90]度上進行傾斜校正, 通過水平投影直方圖快速提取ROI區域, 最后通過改進的SWT算法, 來對文本圖像進行中文的檢測.通過上述的實驗對比, 可以發現本文針對中文印刷體圖像文件的識別結果, 無論在檢測準確率、召回率和F值上, 還是在識別文本圖像的處理時間上, 效果都是最優的, 這也表明本文的算法具有較好的實用價值.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
