基于多級特征和混合注意力機制的室內人群檢測網絡
2019-01-06 07:27:07沈文祥秦品樂曾建潮
計算機應用 2019年12期
沈文祥 秦品樂 曾建潮


摘 要:針對室內人群目標尺度和姿態多樣性、人頭目標易與周圍物體特征混淆的問題,提出了一種基于多級特征和混合注意力機制的室內人群檢測網絡(MFANet)。該網絡結構包括三部分,即特征融合模塊、多尺度空洞卷積金字塔特征分解模塊以及混合注意力模塊。首先,通過將淺層特征和中間層特征信息融合,形成包含上下文信息的融合特征,用于解決淺層特征圖中小目標語義信息不豐富、分類能力弱的問題;然后,利用空洞卷積增大感受野而不增加參數的特性,對融合特征進行多尺度分解,形成新的小目標檢測分支,實現網絡對多尺度目標的定位和檢測;最后,用局部混合注意力模塊來融合全局像素關聯空間注意力和通道注意力,增強對關鍵信息貢獻大的特征,來增強網絡對目標和背景的區分能力。實驗結果表明,所提方法在室內監控場景數據集SCUT-HEAD上達到了0.94的準確率、0.91的召回率和0.92的F1 分數,在召回率、準確率和F1指標上均明顯優于當前用于室內人群檢測的其他算法。
關鍵詞:室內人群檢測;特征融合;注意力機制;空洞卷積;特征金字塔
中圖分類號: TP389.1 人工神經網絡計算機;TP391.41圖像識別及其裝置文獻標志碼:A
Indoor crowd detection network based on multi-level features and
hybrid attention mechanism
SHEN Wenxiang, QIN Pinle, ZENG Jianchao*
(College of Big Data, North University of China, Taiyuan Shanxi 030051, China)
Abstract: In order to solve the problem of indoor crowd target scale and attitude diversity and confusion of head targets with surrounding objects, a new Network based on Multi-level Features and hybrid Attention mechanism for indoor crowd detection (MFANet) was proposed. It is composed of three parts: feature fusion module, multi-scale dilated convolution pyramid feature decomposition module, and hybrid attention module. Firstly, by combining the information of shallow features and intermediate layer features, a fusion feature containing context information was formed to solve the problem of the lack of semantic information and the weakness of classification ability of the small targets in the shallow feature map. Then, with the characteristics of increasing the receptive field without increasing the parameters, the dilated convolution was used to perform the multi-scale decomposition on the fusion features to form a new small target detection branch, realizing the positioning and detection of the multi-scale targets by the network. Finally, the local fusion attention module was used to integrate the global pixel correlation space attention and channel attention to enhance the features with large contribution on the key information in order to improve the ability of distinguishing target from background. The experimental results show that the proposed method achieves an accuracy of 0.94, a recall rate of 0.91 and an F1 score of 0.92 on the indoor monitoring scene dataset SCUT-HEAD. All of these three are significantly better than those of other algorithms currently used for indoor crowd detection.
Key words: indoor crowd detection; feature fusion; attention mechanism; dilate convolution; feature pyramid
0 引言
計算機視覺一直是計算機科學領域研究熱點之一。作為計算機視覺領域的一個典型應用,公共室內場所人數統計在人流量商業數據統計分析、公共安全等許多方面有著重要的應用價值。目前室內場景人群計數主要有兩種思路:一種是直接通過回歸的方式得到人群數量,另一種是采用檢測的方式進行人群檢測。基于回歸的方法只能預測人群密度,得到一個粗略的結果;基于檢測的方法可以得出精確的定位信息和人數統計。目前針對人的檢測方法主要有兩種:一類是人臉識別的算法[1-4],一類是行人識別的算法[5-6]。但是,這兩種方法在室內人群檢測中性能均不好。人臉識別只能檢測人臉,這意味著相機無法檢測人的背面。由于室內場景人群的復雜性,很多身體部位被相互遮擋,因此,行人識別同樣也無法很好地解決該問題。然而,人頭檢測卻沒有這些限制,可以很好地適用于室內人群定位和計數。當然,室內場景人頭檢測同樣存在很多挑戰。
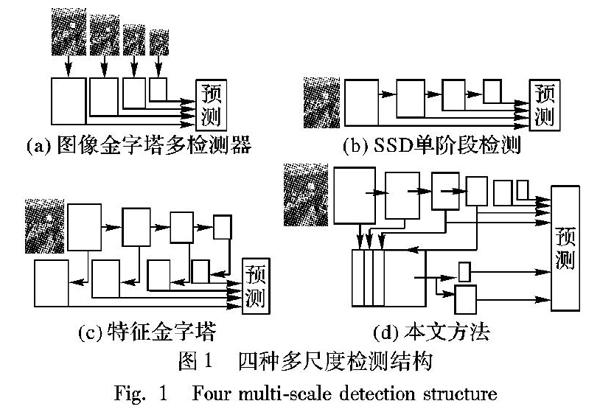
頭部姿態和尺度的多樣性是人頭檢測的第一大關鍵難題。目前主要采用測試階段輸入多尺度圖像和訓練過程中對中間特征層進行多尺度變換兩種主要的思路改善這個問題。第一種圖像金字塔結構的思路,如圖1(a)所示。多任務卷積神經網絡(Multi-Task Convolutional Neural Network, MTCNN) [4]直接通過下采樣得到不同尺度的輸入圖像送入訓練好的檢測網絡中進行預測,最終通過非極大值抑制(Non Maximum Suppression, NMS)[7]輸出目標位置和種類。Singh等[8]提出在訓練和測試中,建立大小不同的圖像金字塔,在每張圖上都運行一個檢測網絡,同時只保留那些大小在指定范圍之內的輸出結果,最終通過非極大抑制操作輸出目標位置和種類。由于這類基于圖像金字塔結構的算法計算復雜度高,內存消耗嚴重,耗時長,因此在檢測任務上的效率非常低。第二種特征金字塔結構的思路是目前目標檢測算法中出現最多的,SSD(Single Shot multibox Detector)[9]采用多層特征圖獨立檢測輸出,構成多尺度特征檢測結構,如圖1(b)所示。Lin等[10]提出了一種將高層特征和淺層特征圖融合的至上而下的結構FPN (Feature Pyramid Networks),最后在融合后的不同層進行獨立預測,如圖1(c)所示。Zhou等[11]同樣也提出了一種對稱的結構進行多尺度融合。相比于第一種思路,第二種思路利用更少的內存和耗時,并且還可以作為組件嵌入到不同的檢測網絡中。因此本文也采用這種思路。通過分析,發現淺層特征對于小尺度目標有很好的定位能力,但是語義表征信息弱,由于連續下采樣,小目標區域在中間層特征圖中的表征區域已經降為1×1像素大小,因此,本文只利用上采樣融合淺層和中間層特征,然后采用多尺度空洞卷積金字塔結構生成新的淺層和中間層檢測分支,高層檢測分支仍然采用原來的特征層,形成一個兩級檢測的混合結構,如圖1(d)所示。通過本文設計的特征融合結構和多尺度空洞卷積金字塔結構很好地改善了頭部姿態和尺度多樣性的問題。
圖像質量不高容易使得人頭區域與周圍物體特征混淆,因此如何只關注目標特征,忽略背景特征干擾是室內場景人頭檢測另一個關鍵難題。目前很多算法引入注意力機制,引導神經網絡關注目標區域,排除背景特征的干擾。Jaderberg等[12]發現神經網絡中池化和下采樣操作直接將信息合并會導致關鍵信息無法識別出來,提出了一種新的空間轉換模塊結構,用于指導網絡顯式的學習目標的空間特性,例如旋轉、平移等,這相當于空間域的注意力機制。Hu等[13]發現不同的特征圖對關鍵信息的貢獻不同,因此通過學習的方式來自動獲取到每個特征通道的重要程度,然后依照這個重要程度去提升有用的特征并抑制對當前任務用處不大的特征,這相當于通道域的注意力機制。Zhang等[14]引入一種關注特征相似性,從而擴大圖像感受野的注意力機制用于圖像超分辨率。因此,注意力機制已經被很好地證明適用于關鍵特征的提取。本文提出了一種混合通道域和空間域的注意力模塊,嵌入到不同的檢測分支中,增強了不同分支對目標特征和背景特征的區分能力。
通過本文設計的特征融合模塊和混合注意力模塊很好地解決了上述兩個難題。本文算法在標準數據集上達到了0.91的召回率(recall),大幅優于現有的單階段人群檢測算法[9,15-17]。
本文的主要工作有以下幾點:
1)設計了一種新穎的特征融合結構。首先通過上采樣操作將中間層特征圖和淺層特征圖尺度歸一化,然后利用concate操作融合特征圖,構成包含豐富小目標定位信息和語義信息的融合層,改善了網絡淺層對小目標表征不足的問題。
2)設計了一種新穎的多尺度空洞卷積金字塔特征分解結構。利用多尺度空洞卷積金字塔結構對融合特征圖進行多尺度分解,構成對小目標和中等目標檢測的新分支,利用原網絡針對大目標的檢測分支和新生成的檢測分支構成多特征層檢測結構,有效地利用了網絡不同層對目標檢測的貢獻,有效地改善了單階段網絡對多尺度和多姿態人頭的檢測性能不足的問題。
3)設計了一種混合空間域和通道域的注意力結構嵌入到不同的檢測分支中,增強對關鍵信息貢獻大的特征圖,大幅增強了網絡對目標區域和背景區域的分辨能力。
4)以VGG(Visual Geometry Group)16輕量級特征提取網絡為基本網絡結構,結合本文提出的特征融合分解結構和注意力機制,構成了單階段兩級檢測的端到端網絡,在訓練和檢測階段實現了實時的人群檢測網絡。
1 相關工作
目前基于深度學習的目標檢測算法主要分為兩類:一類是兩階段檢測算法,例如Fast-RCNN(Fast Region-CNN)[18],Faster-RCNN[15]和R-FCN(Region-based Fully Convolutional Network)[16]。這類方法都是先生成目標的候選區域并進行粗篩選,然后對篩選后的候選區域進行目標分類和邊界框回歸。第二類是單階段檢測算法,主要有:OverFeat[19]、SSD[9]、YOLO(You Only Look Once)[17]系列。
單階段檢測網絡增強淺層特征對小目標表征能力的方法主要分為兩類:第一類是是直接將輸入圖像放大提升小目標尺度,如MTCNN(Multi-Task Convolutional Neural Network)、SNIP(Scale Normalization for Image Pyramids),這一類算法都是將輸入圖像多尺度放大后用于訓練或測試階段。第二類是對特征圖進行多尺度變換再利用,如多尺度深度卷積神經網絡(Multi-Scale deep CNN, MS-CNN)[20]、反卷積單目標檢測器(Deconvolutional Single Shot Detector, DSSD) [21]。
深度學習中的注意力是一種模擬人大腦處理視覺任務的機制,人類視覺只關注感興趣區域,忽略其他背景干擾。注意力機制(Attention mechanism)[22]可以被解釋為將可用的計算資源的分配偏向于包含最有用信息的特征部分,首先用于自然語言處理中關注對下文詞語貢獻高的詞語,之后在很多圖像處理任務中也已經證明了注意力機制的實用性,包括目標檢測[13]、圖像超分辨率[14]等。在這些任務中,注意力機制作為一種模塊嵌入網絡層中,表示用于模態之間的自適應高級抽象。
2 本文室內人群檢測網絡
2.1 網絡整體結構
本文提出的基于多級特征和混合注意力機制的室內人群檢測網絡(Network based on Multi-level Features and hybrid Attention mechanism for indoor crowd detection, MFANet)整體結構如圖2所示,它和SSD一樣是端到端的單階段檢測網絡。主干網絡采用輕量級網絡VGG16的卷積層用于提取特征,替換用于分類的全連接層,并且額外增加了卷積層,形成特征提取主干網絡;通過上采樣操作將淺層和中間層特征尺度歸一化,再通過concate操作構建融合層融合淺層和中間層特征圖,對原有淺層和中間層特征進行融合形成新的融合特征圖;然后,再利用多尺度空洞卷積分解結構對融合層進行多尺度分解形成新的小目標檢測分支,結合原有特征層形成的大目標檢測分支,形成一個兩級檢測分支用于產生密集的預測框和分類置信度;最后,通過軟化非極大值抑制(soft Non-Maximum Suppression, soft-NMS)輸出最終的檢測結果。MFANet主要包含3部分結構:特征融合模塊(Feature Fusion Module, FFM)、多尺度空洞卷積金字塔特征分解結構(Multi-Scale Dilated convolution Feature Pyramid decomposition Module, MSDFPM)、混合注意力模塊(Fusion Attention Module, FAM)。特征融合模塊通過將淺層特征和中間層特征信息融合,形成包含上下文信息的融合特征,用于解決淺層特征圖中小目標語義信息不豐富、分類能力弱的問題;多尺度空洞卷積金字塔結構主要利用空洞卷積感受野增大、參數不增加的特性,對融合特征進行多尺度分解,形成新的小目標檢測分支,滿足網絡對多尺度目標的定位和檢測;局部混合注意力模塊通過融合全局像素關聯空間注意力和通道注意力,增強對關鍵信息貢獻大的特征,大幅增強網絡對目標和背景的區分能力。
2.2 特征融合模塊
本文將絕對尺寸在圖像中占據的區域小于32×32像素的目標定義為小目標。單次檢測網絡均存在小目標檢測能力弱的問題,究其原因是由于用于特征提取的主干網絡淺層特征圖雖然包含豐富的細節定位信息,但是包含的小目標語義信息少,對小目標的分類能力弱。隨著網絡層加深,深層特征圖包含豐富的語義信息,但是丟失了小目標的細節定位信息。因此,最直接的想法是將包含豐富細節定位信息的淺層特征圖和包含豐富語義信息的深層特征圖通過一定的融合規則融合形成既包含豐富細節定位信息又包含豐富語義信息的特征圖。由于小目標特征在經過多層下采樣之后,原有細節和語義信息已經丟失,在深層網絡層中已經不再包含小目標的語義信息。如圖3所示,當原圖像中一個頭部區域為30×30時,淺層特征圖中的豐富細節特征隨著網絡層的加深,圖像不斷被下采樣,最終在conv7_2特征圖中目標區域已經被抽象成一個點特征,在conv7_2之后的特征圖中已經丟失了該目標的特征信息。因此,直接使用最深層特征圖對淺層進行語義增強的效果并不明顯。
基于此分析,采用將中間層特征和淺層特征進行融合的思路,在SSD模型中原有的主干特征提取網絡中嵌入了新穎的特征融合模塊形成包含全局上下文信息的融合特征。如圖4所示,首先利用1×1的卷積構建瓶頸層壓縮淺層和中間層特征圖的通道,然后分別將中間層特征圖通過上采樣放大到和淺層特征圖相同的尺寸,最后這里沒有采用將所有特征圖相加形成新的特征圖,而是利用concate將所有相同尺寸的特征圖連接起來形成第二層特征圖,主要是由于像素級相加操作要求兩個特征圖有相同的長寬和通道,那么就需要在融合前確保兩個特征圖尺度完全一致,這么做的缺點是新增了額外的歸整化操作,并限制了被融合feature map的靈活性,并且concate連接操作可以很好地保證不同特征圖檢測的同一個目標所包含的特征區域被相同激活。相較于主干網絡提取的特征,新的融合特征圖既包含特征提取主干網絡中淺層特征圖中小目標豐富的細節特征,同時又利用中間層特征圖中小目標豐富的語義信息,這大幅提升了檢測小目標的準確率。
2.3 多尺度空洞卷積金字塔結構
在得到融合特征圖后,需要生成新的檢測分支。受FPN的啟發,對融合后的特征圖可以進行多尺度下采樣,構成多尺度金字塔結構用于生成新的檢測分支。由于主要目標是需要提升小目標的檢測能力,因此,本文只生成conv4_3和fc7兩個新的檢測分支,用于構成小目標檢測分支,如圖5所示。新生成的檢測特征圖需要和原檢測特征圖尺寸相同,感受野相同,這樣可以保證平均地檢測不同尺度的目標,而標準的卷積由于感受野局限,傳統做法一般采用池化操作進行下采樣,但是這樣容易丟失定位信息。因此,為了增大感受野的同時,又不丟失小目標定位信息,研究者們提出一種新的卷積操作:空洞卷積[23]。如圖6所示,它是在標準卷積的基礎上,通過填零操作,增大了感受野的同時,而不增加學習參數,只增加了一個超參數:空洞率(dilate rate)。由于空洞卷積操作容易引起網格效應,根據Wang等[24]提出的空洞卷積級聯參考設計準則,首先利用空洞率為2的空洞卷積操作增大感受野,再級聯一個空洞率為1的標準卷積用于消除網格效應,最后利用滑動步長為2的3×3卷積進行下采樣操作生成conv7_2,在新生成的檢測分支之后,均添加了一個3×3卷積用于整合通道內部相關性信息。新生成的小目標檢測分支相較原檢測分支,擁有更豐富的小目標細節特征和語義特征。
2.4 混合注意力模塊
由于室內監控圖像成像質量差、人群密度大、場景內容復雜,很容易造成目標和周圍背景的特征相似度高,影響網絡對目標的判斷,因此,要求設計的模型能夠很好地區分目標和背景特征。最直接的想法是對圖像進行超分辨率,然后再進行目標識別;但是,這樣會造成內存占用高、計算復雜度增加,并且無法滿足端到端的訓練和推理,大幅增加了推理和訓練時間。根據壓縮感知神經網(Squeeze-and-Excitation Networks, SENet)的論述[13],神經網絡不同特征圖、同一特征圖內不同區域對不同目標的貢獻率都是不同的,如果能夠只使用對關鍵目標貢獻率高的特征圖,舍棄對關鍵目標貢獻率不高的特征圖,則會大幅提升對目標的定位和識別效果。而新近快速發展的注意力機制可以很好地實現這個功能。因此,本文設計了一種混合注意力模塊用于提取關鍵特征,整體結構如圖7所示。輸入特征圖x∈RH×W×C,經過通道注意力模塊提取對目標貢獻率大的的通道注意力圖F(x)∈R1×1×C,通過級聯的方式,利用空間注意力模塊提取二維的空間注意力圖G(x)∈RH×W×1,得到最終的輸出。整個注意力提取的過程如式(1)所示:
Z(x)=G(F(x)x)F(x)(1)
其中:是像素級點乘,在點乘過程中,注意力圖被廣播到不同通道、不同區域的特征圖中;最終的輸出Z(x)既包含空間注意力,又包括通道注意力。如圖8所示,輸出了淺層添加注意力機制和不添加注意力機制后的部分特征圖,可以看出,本文設計的注意力結構很好地增強了特征圖中目標區域的語義信息和細節定位信息。
2.4.1 通道注意力子模塊
每一個通道特征圖都可以看作是特征檢測器,針對不同的目標,不同通道的特征圖對關鍵信息的貢獻率是不同的,通道注意力關注的就是不同的通道對關鍵信息的貢獻率。因此本文設計了一種用于提取通道和目標之間內在關系的結構,如圖9所示。
為了只學習不同通道的貢獻率,首先壓縮空間信息,目前普遍采用全局平均池化的方法。Hu等[13]提出使用全局平均池化來獲得目標檢測候選區域,文中提出的SENet在注意力模塊中使用了全局平均池化統計特征圖的空間信息。不同于他們的思路,本文認為全局最大池化操作可以獲得目標之間差異性最大的特征,可以有助于推斷更精細的通道注意力。因此,本文同時采用全局平均池化和全部最大池化兩種操作。首先利用全局平均池化和全局最大池化分別生成不同的空間描述特征:Mcave∈R1×1×C,Mcmax∈R1×1×C。然后通過像素級相加得到融合后的通道描述特征Mcmerge。融合后的通道描述特征送入一個多層感知機得到最終的通道注意力圖。為了壓縮參數,本文設置了一個壓縮比(ratio),通過大量實驗,最終該參數設置為16。最后整個通道注意力提取的過程可以描述如下:
Mcmerge(x)=Mcave(x)+Mcmax(x)(2)
F(x)=σ(W1(ReLU(W0Mcmerge(x))))(3)
其中σ為sigmoid函數,因為通道注意力提取過程是獲得通道特征圖對關鍵信息的貢獻率,屬于廣義二分類問題。多層感知機的權重: W0∈RC×C/r,W1∈RC/r×C,W0之后使用ReLU激活函數來提升網絡的非線性程度。
2.4.2 空間注意力子模塊
空間位置注意力主要是尋找特征圖中對關鍵信息重要的區域,這是對通道注意力的一種補充。由于普通的卷積操作受限于卷積核的大小,只能考慮鄰域內的特征內在聯系,無法考慮全局區域中相似特征的關聯性。因此為了獲取全局區域對關鍵信息的貢獻,本文受非局部網絡啟發,設計了一種新穎的空間注意力結構,如圖10所示。
輸入特征圖x∈RH×W×C首先通過全局最大池化和全局平均池化操作,沿通道維度生成兩個新的特征描述: Msave∈RH×W×1,Msmax∈RH×W×1。然后通過concate操作融合新的特征描述,之后通過一個標準的卷積操作激活獲得最終的注意力圖。整個注意力提取過程描述如下所示:
Msmerge(x)=[Msave,Msmax](4)
G(x)=σ(f3×3Msmerge(x))(5)
其中:σ為sigmoid函數; f3×3表示3×3的標準卷積操作。本文設計的空間注意力機制首先通過壓縮通道維度,只留下空間位置信息,然后通過卷積操作對全局區域進行注意力學習,得到包含全局上下文信息的注意力圖。通過本文設計的空間注意力模塊,網絡可以有效地學習到不同區域對目標的增益,從而有效地增強目標識別能力。最后,本文通過級聯的方式融合了通道注意力模塊和空間位置注意力模塊,構成混合注意力模塊。
3 損失函數
目標檢測既包含分類任務又包含回歸任務,因此需要構建多任務損失函數。本文的損失函數定義為定位損失和分類損失加權求和,如下所示:
L(x,c,l,g)=1N(Lconf(x,c)+αLloc(x,l,g))(6)
其中超參數α為平衡系數,用于平衡分類損失和定位損失對最終結構的影響,這里根據多次實驗選取α=1。N是匹配到的默認框數量,如果N=0,則設置損失為0。本文使用框的中心點坐標(cx,cy)和寬(ω)、高(h)四個參數定義一個目標框的圖像位置。由于smoothL1相較于直接使用L2回歸損失更平滑,因此使用預測框(l)和真實標簽(g)之間的smoothL1損失作為定位損失,如式(7)所示:
Lloc(x,l,g)=∑Ni∈Pos∑m∈{cx,cy,ω,h}xkij smoothL1(lmi-mj)(7)
cxj=(gcxj-dcxi)/dωi
cyj=(gcyj-dcyi)/dhi
ωj=lg(gωj/dωi)
hj=lg(ghj/dhi)
分類損失使用softmax多分類損失,如式(8)所示:
Lconf(x,c)=-∑Ni∈Posxpij lg(pi)-∑i∈Neglg(0i)(8)
pi=exp(cpi)/∑pexp(cpi)
4 實驗與結果分析
本文在公開的大學教室人群檢測數據集SCUT-HEAD[25]上進行實驗。SCUT-HEAD數據集包含兩個部分:PartA包含2000張大學教室監控圖片,其中標記人頭數67321個。PartB包含2405張互聯網中下載的圖片,其中標記人頭數43930個。該數據集采用Pascal VOC標注標準。本文采用PartA部分訓練,其中1500張用于訓練,500張用于測試。訓練完成后本文選用查準率(Precision, P)、查全率(Recall, R)和F1 score指標共同評估本文模型和其他模型的性能。同時,針對特征融合模塊、注意力模塊的結構合理性進行了對比實驗,驗證結構設計的合理性。
4.1 SCUT-HEAD實驗
首先將本文提出的算法和其他常用目標檢測算法進行性能對比實驗。數據集使用SCUT-HEAD PartA和PartB數據集。通過分析主干網絡的感受野,設置default box默認尺寸如表1所示。數據增廣采用了隨機左右鏡像、隨機亮度和數據歸一化三種方式對數據進行了預處理。訓練時,設備使用了1臺NVIDIA P100 GPU服務器,基于VGG16作為骨干網絡的SSD在MSCOCO數據上預訓練的參數開始訓練。采用隨機梯度下降(Stochastic Gradient Descent, SGD)優化器,動量設置為0.9,權重正則衰減系數設置為0.0005,初始學習率設置為1E-3;當訓練80000次后,學習率設置為1E-4;當再訓練20000次后,學習率設置為1E-5;最后,再訓練20000次。網絡訓練階段的分類損失和定位損失曲線分別如圖11所示。
表格(有表名)表1 默認框基礎尺寸設置和理論感受野
Tab. 1 Basic size setting and theoretical receptive field of default boxes
檢測層步長候選框尺寸感受野尺寸conv4_383292fc732128420conv6_232128452conv7_264256516conv8_2128512644conv9_2128512772
本文對比了Faster-RCNN、YOLOv3、SSD、R-FCN(ResNet-50)和Redmon等[17]提出的基于特征增強網絡(Feature Refine Net, FRN)的改進R-FCN算法,對比結果如表2 所示。相較于其他算法,本文算法在各個評估指標下均有很高的提升,并且各個性能指標均高于0.9,在人群檢測領域,本文算法MFANet達到了最好的檢測效果。
4.2 結構對比實驗
本文為驗證特征融合模塊融合淺層和中間層的合理性,設計了不同的淺層特征圖和中間層特征圖組合結構進行實驗。數據集選用SCUT-HEAD PartA部分,所有實驗訓練配置均相同。如表3所示,可以發現使用淺層conv4_3至中間層conv7_2進行融合,最終性能指標最好,表明了本文特征融合模塊結構設計的合理性。
為驗證新檢測分支生成數量設計的合理性,設計了兩種不同數目的檢測分支結構:第一種是只生成新的conv4_3檢測分支;第二種是生成新的conv4_3 fc7檢測分支。數據集選用SCUT-HEAD PartA部分,所有實驗訓練配置均相同。如表4所示,可以發現,本文選取的新檢測分支數量合理,可以有效地提升算法性能。
本文設計實驗驗證混合注意力模塊結構設計的合理性,數據集選用SCUT-HEAD PartA 部分。設計了五種不同的結構:第一種是在檢測分支中不增加局部注意力模塊;第二種是在檢測分支中增加SENet 的中通道注意力模塊(SEBlock);第三種是在檢測分支中增加本文設計的通道注意力模塊(Channel Attention Module, CAM);第四種是在檢測分支中增加本文設計的空間注意力模塊(Spatial Attention Module, SAM);第五種是在檢測分支中增加本文設計的混合注意力模塊(CAM+SAM)。根據表5 所示的結果可以看出,本文設計的混合注意力機制可以更好地提升網絡的性能。
4.3 測試結果展示
如圖11所示,第一行展示的是小目標有遮擋的場景測試結果;第二行展示了既有多尺度目標,也有多姿態目標的一般場景;第三行和第四行分別展示的是前向和后向密集場景測試結果;最后一行展示的是在人工手動標注無法包含全部真實目標的場景下,不同算法的檢測結果。通過不同方法的結果對比可以看出,本文提出的MFANet很好地解決了目標多尺度、多姿態的檢測問題和目標易與環境特征相似的檢測問題,并且本文算法在密集型人群中的檢測結果性能達到了領先水平。
5 結語
本文提出了一種基于多級特征和混合注意力機制的人群目標檢測網絡MFANet,主要是用于檢測室內人群,并根據檢測結果得到最終的人群計數統計。首先,設計了淺層和中間層特征融合模塊用于解決目標尺寸多樣性的問題;然后,設計了混合注意力模塊用來解決目標區域和周圍背景特征混淆的問題;最后,采用類SSD的單階段檢測框架融合設計的新結構,實現了端到端的訓練和預測,在GPU上的推理速度達到每秒25幀,并且在標準數據集上實現了0.92的F1 score和0.91的召回率;并且,本文算法靈活簡單,同樣可以用于其他目標的檢測任務中。目前,只使用了以輕量級的VGG16作為主干網絡,使用ResNet-50、DenseNet等性能更優的深度網絡作為主干網絡會更好地提升模型的性能,這也是我們接下來的研究方向。
參考文獻 (References)
[1]WANG Q, FAN H, SUN G, et al. Laplacian pyramid adversarial network for face completion [J]. Pattern Recognition, 2019, 88: 493-505.
[2]YIN X, LIU X. Multi-task convolutional neural network for pose-invariant face recognition [J]. IEEE Transactions on Image Processing, 2018, 27(2): 964-975.
[3]LU J, YUAN X, YAHAGI T. A method of face recognition based on fuzzy clustering and parallel neural networks [J]. Signal Processing, 2006, 86(8): 2026-2039.
[4]ZHANG K, ZHANG Z, LI Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks [J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[5]CAO Y, GUAN D, HUANG W, et al. Pedestrian detection with unsupervised multispectral feature learning using deep neural networks [J]. Information Fusion, 2019, 46: 206-217.
[6]JUNG S I, HONG K S. Deep network aided by guiding network for pedestrian detection [J]. Pattern Recognition Letters, 2017, 90: 43-49
[7]NEUBECK A, VAN GOOL L. Efficient non-maximum suppression [C]// Proceedings of the 18th International Conference on Pattern Recognition. Piscataway: IEEE, 2006: 850-855
[8]SINGH B, DAVIS L S. An analysis of scale invariance in object detection-SNIP [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 3578-3587
[9]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 14th European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 21-37.
[10]LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 936-944.
[11]ZHOU P, NI B, GENG C, et al. Scale-transferrable object detection [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 528-537.
[12]JADERBERG M, SIMONYAN K, ZISSERMAN A, et al. Spatial transformer networks [C]// Proceedings of the 2015 International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2015: 2017-2025.
[13]HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
[14]ZHANG H, GOODFELLOW I, METAXAS D, et al. Self-attention generative adversarial networks [C]// Proceedings of the 36th International Conference on Machine Learning. New York: PMLR, 2019: 7354-7363.
[15]李曉光,付陳平,李曉莉,等.面向多尺度目標檢測的改進Faster R-CNN算法[J].計算機輔助設計與圖形學學報,2019,31(7):1095-1101.(LI X G, FU C P, LI X L, et al. Improved faster R-CNN for multi-scale object detection [J]. Journal of Computer-Aided Design and Computer Graphics, 2019, 31(7): 1095-1101.)
[16]李靜,降愛蓮.復雜場景下基于R-FCN的小人臉檢測研究[J/OL].計算機工程與應用:1-12[2019-04-22].http://kns.cnki.net/kcms/detail/Detail.aspx?dbname=CAPJLAST&filename=JSGG20190123006&v=.(LI J, JIANG A L. Face detection based on R-FCN in complex scenes [J/OL]. Journal of Computer Engineering and Applications: 1-12[2019-04-22]. http://kns.cnki.net/kcms/detail/Detail.aspx?dbname=CAPJLAST&filename=JSGG20190123006&v=.)
[17]REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525.
[18]LI J, LIANG X, SHEN S, et al. Scale-aware fast R-CNN for pedestrian detection [J]. IEEE Transactions on Multimedia, 2018, 20(4): 985-996.
[19]SERMANET P, EIGEN D, ZHANG X, et al. OverFeat: integrated recognition, localization and detection using convolutional networks? [EB/OL]. [2019-04-11]. https://arxiv.org/pdf/1312.6229v4.pdf.
[20]CAI Z, FAN Q, FERIS R S, et al. A unified multi-scale deep convolutional neural network for fast object detection [C]// Proceedings of the 14th European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016: 354-370.
[21]FU C, LIU W, RANGA A, TYAGI A, et al. DSSD: deconvolutional single shot detector [EB/OL]. [2019-04-11]. https://arxiv.org/pdf/1701.06659.pdf.
[22]楊康,宋慧慧,張開華.基于雙重注意力孿生網絡的實時視覺跟蹤[J].計算機應用,2019,39(6):1652-1656.(YANG K, SONG H H, ZHANG K H. Real-time visual tracking based on dual attention Siamese network [J]. Journal of Computer Applications, 2019, 39(6): 1652-1656.)
[23]QUAN Y, LI Z, ZHANG C. Object detection by combining deep dilated convolutions network and light-weight network [C]// Proceedings of the 12th International Conference on Knowledge Science, Engineering and Management, LNCS 11775. Cham: Springer, 2019: 452-463.
[24]WANG P, CHEN P, YUAN Y, et al. Understanding convolution for semantic segmentation [C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 1451-1460.
[25]PENG D, SUN Z, CHEN Z, et al. Detecting heads using feature refine net and cascaded multi-scale architecture [C]// Proceedings of the 24th International Conference on Pattern Recognition. Piscataway: IEEE, 2018: 2528-2533.
This work is partially supported by the Shanxi Provincial Key Research and Development Plan (201803D31212-1).
SHEN Wenxiang, born in 1995, M. S. candidate. His research interests include deep learning, computer vision.
QIN Pinle, born in 1978, Ph. D., associate professor. His research interests include computer vision, big data, medical imaging.
ZENG Jianchao, born in 1963, Ph. D., professor. His research interests include evolutionary calculation, machine learning.
收稿日期:2019-06-24;修回日期:2019-09-19;錄用日期:2019-09-19。基金項目:山西省重點研發計劃項目(201803D31212-1)。
作者簡介:沈文祥(1995—),男,安徽淮南人,碩士研究生,主要研究方向:深度學習、計算機視覺; 秦品樂(1978—),男,山西長治人,副教授,博士,CCF會員,主要研究方向:機器視覺、大數據、醫學影像; 曾建潮(1963—)男,陜西大荔縣人,教授,博士,CCF會員,主要研究方向:演化計算、機器學習。
文章編號:1001-9081(2019)12-3496-07DOI:10.11772/j.issn.1001-9081.2019061075
