基于三維卷積神經網絡的航運監控事件識別
2019-01-06 07:27:07王中杰張鴻
計算機應用 2019年12期
關鍵詞:深度學習
王中杰 張鴻

摘 要:針對傳統的機器學習算法對大數據量的航運監控視頻識別分類的效果不佳,以及現有的三維(3D)卷積的識別準確率較低的問題,基于3D卷積神經網絡模型,結合較為流行的視覺幾何組(VGG)網絡結構以及GoogleNet的Inception網絡結構,提出了一種基于VGG-16的3D卷積網絡并引入Inception模塊的VIC3D模型對航運貨物實時監控視頻進行智能識別。首先,將從攝像頭獲取到的視頻數據處理成圖片;然后,將等間隔取幀的視頻幀序列按照類別進行分類并構建訓練集與測試集;最后,在保證運行環境相同并且訓練方式相同的前提下,將結合后的VIC3D模型與原模型分別進行訓練,根據測試集的測試結果對各種模型進行比較。實驗結果表明,VIC3D模型的識別準確率在原模型的基礎上有所提升,相較于組約束循環卷積神經網絡(GCRNN)模型的識別準確率提高了11.1個百分點,且每次識別所需時間減少了1.349s;相較于C3D的兩種模型的識別準確率分別提高了14.6個百分點和4.2個百分點。VIC3D模型能有效地應用到航運視頻監控項目中。
關鍵詞:智能航運監控;視頻識別;深度學習;三維卷積;神經網絡
中圖分類號: TP391.4 文獻標志碼:A
Shipping monitoring event recognition based on three-dimensional
convolutional neural network
WANG Zhongjie1,2*, ZHANG Hong1,2
(1. College of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan Hubei 430065, China;
2. Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System
(Wuhan University of Science and Technology), Wuhan Hubei 430065, China)
Abstract: Aiming at the poor effect of traditional machine learning algorithms on large data volume shipping monitoring video recognition classification and the low recognition accuracy of previous three-Dimensional (3D) convolution, based on 3D convolutional neural network model, combined with the popular Visual Geometry Group (VGG) network structure and GoogleNets Inception network structure, a new VGG-Inception 3D Convolutional neural network (VIC3D) model based on VGG-16 3D convolutional network and introduced Inception module was proposed to realize the intelligent recognition of the real-time monitoring video of shipping goods. Firstly, the video data acquired from the camera were processed into images. Then, the video frame sequences by equal interval frame fetching were classified according to the categories, and the training set and the testing set were constructed. Under the premise of the same operating environment and the same training mode, the VIC3D model after combination and the original model were trained separately. Finally, the various models were compared based on the test results of the testing set. The experimental results show that, compared with the original model, the recognition accuracy of VIC3D model is improved, which is increased by 11.1 percentage points compared to the Group-constrained Convolutional Recurrent Neural Network (GCRNN) model, and the time required for every recognition is reduced by 1.349s; the recognition accuracy of VIC3D model is increased by 14.6 percentage points and 4.2 percentage points respectively compared to the two models of C3D. The VIC3D model can be effectively applied to the shipping video surveillance projects.
Key words: intelligent shipping monitoring; video recognition; deep learning; three-Dimensional (3D) convolution; neural network
0 引言
近幾年人工智能[1]迅速發展,越來越多地應用到計算機以外的行業,許多傳統行業開始不斷地智能化。特別是關于視頻監控這一領域,很多傳統行業以及各大安全部門都設有相應的監控系統,一般是安排相關人員管理監控室進行人工監控,并對異常情況發出警報。但由于人類會產生疲勞感并且在監視大量的攝像頭時難免產生遺漏,因此有必要考慮引入人工智能實現自動化,也就是智能監控系統[2-4]。
航運監控是針對江海中運輸貨物的船舶進行監控,通過在船上安裝攝像頭來監視船只,以防止船家偷取貨物,以及對船舶的異常狀態進行預警。而監控時產生的視頻數據是智能航運監控的數據集來源,這就需要使用視頻識別的方法來訓練模型。
目前智能航運監控跟城市交通監控系統[5]一樣,對攝像頭要求比較高,需要得到較高分辨率的視頻,并且拍攝角度的不同也會產生較大影響。還有江海上不良天氣的影響,如雨雪天氣、大霧以及光照不一等對識別率的影響也較大。這些因素使得獲取的視頻或者圖像數據質量較差,而傳統方法對這類數據的訓練效果不佳,并且傳統方法在訓練數據量較大的模型時效果也不好。
近幾年隨著大量學者對深度學習[6-8]的不斷研究,越來越多的研究領域開始使用深度學習,深度學習方法在計算機視覺領域不斷取得突破,并且取得了相對較好的效果,特別是訓練數據量較為龐大的模型時,其優勢較為明顯。然而,以往的深度學習使用的卷積神經網絡并不能用于處理視頻數據。因此,針對視頻識別領域,學者們以深度學習為基礎提出了一些新的網絡結構,如:以文獻[9]為代表的雙流(two-stream)網絡,以文獻[10]為代表的三維卷積神經網絡(three-Demensional Convolutional Neural Network, 3DCNN),以及以文獻[11]為代表的循環卷積神經網絡等。
本文基于3D卷積神經網絡模型,對航運貨物實時監控視頻進行智能識別,并對船的異常情況進行預警,提出了基于視覺幾何組-16(Visual Geometry Group-16, VGG-16)網絡并與Inception結構[12]融合的VIC3D(VGG-Inception 3D CNN)模型,對識別模型的準確率進行優化。本文使用智能航運監控項目中獲取的數據集,并將其分為裝卸貨等8個類別進行訓練,將不同方法訓練獲得的模型進行檢測并比較分析。實驗結果表明,本文模型在識別精度方面優于基礎模型: 在稍微降低識別速度的前提下將識別準確率提高到了93.8%;相較于單純使用VGG-11結構的模型,本文模型的準確率提高了4.2個百分點,識別速度則平均僅慢了0.198s。
1 相關工作
近幾年深度學習的相關研究逐漸成熟后,國內外眾多研究者針對視頻識別提出了許多新方法或者基于現有研究的改進方法,基于這些方法,視頻識別領域的研究得到了迅速的發展。可以將其大致分為兩類:傳統方法和深度學習方法。
1.1 傳統方法
傳統方法也就是深度學習引入之前的方法,通常從檢測時空興趣點(Space-Time Interest Points, STIP)[13]開始,然后用局部表示來描述這些點,基本步驟為關鍵點的選取、特征提取、特征編碼、訓練分類器。比較經典的有:密集軌跡(Dense Trajectories, DT)算法[14],利用光流場獲取視頻序列中的一些軌跡,沿著軌跡提取光流直方圖(Histograms of Optical Flow, HOF)、定向梯度直方圖(Histograms of Oriented Gradients, HOG)、運動邊界直方圖(Motion Boundary Histogram, MBH)和軌跡(trajectory)四種特征,最后利用Fisher矢量(Fisher Vector, FV)方法對特征進行編碼,再基于編碼結果訓練支持向量機 (Support Vector Machine, SVM)分類器;改進的密集軌跡(Improved Dense Trajectories, IDT)算法[15],在DT算法的基礎上利用前后幀視頻間的光流和快速魯棒特征(Speeded Up Robust Features, SURF)關鍵點進行匹配,從而消除/減弱相機運動帶來的影響。相對來說,傳統方法計算速度快,結構也相對簡單,但是數據量過大時識別準確率較低。
1.2 深度學習方法
隨著深度學習方法的提出,卷積神經網絡逐漸廣泛應用于計算機視覺領域,無論是圖像分類、目標檢測還是視頻識別方面,都有大量學者采用深度學習的方法來進行研究。
文獻[16]使用固定大小的窗口來堆疊由卷積神經網絡提取的每一幀特征圖,然后用時空卷積來學習視頻特征。文獻[17] 提出了一個多任務端到端聯合分類回歸遞歸神經網絡,以更好地探索動作類型和時間定位信息,并通過采用聯合分類和回歸優化目標,自動定位動作的起點和終點。文獻[18]提出了時序保留卷積 (Temporal Preservation Convolutional, TPC)網絡,采用時序卷積操作能夠在不進行時序池化操作的情況下獲得同樣大小的感受野而不縮短時序長度,但在卷積解卷積卷積(Convolutional-Deconvolutional -Convolutional, CDC)濾波器之前時間上的下采樣存在一定時序信息的丟失。
文獻[19]在文獻[11]的基礎上將循環卷積神經網絡加以改進,提出了一種新的端到端深度神經網絡模型——組約束卷積循環神經網絡(Group-constrained Convolutional Recurrent Neural Network, GCRNN)用于時間序列分類(Time-Series Classification, TSC)。首先,采用并列的數個卷積神經網絡對連續的幾個視頻幀提取特征并訓練,再將前面提取的特征輸入到后續的門控循環單元(Gated Recurrent Unit, GRU)神經元構成的循環神經網絡來學習時序特征,最后進行全連接并使用softmax層訓練。
可以看出,上述GCRNN模型訓練過程較為繁雜,并且計算量較大,進行識別時所花的時間也相對較長。文獻[10]中的3D卷積神經網絡則解決了該問題,該網絡將傳統的二維卷積擴展到了三維,相比前面的方法,能更好地學習到視頻幀的時序特征。因為二維卷積在進行第一次卷積之后就將時序信息完全折疊了,而三維卷積則在卷積之后保留了時序信息。文獻[10]中采用的卷積網絡是VGG-11網絡,網絡結構較為簡單并且訓練速度非常快,但由于訓練的節點信息較少所以準確度相較于現在研究較為一般。因此基于上述考慮,本文將目前在識別準確率方面明顯優于VGG-11網絡的VGG-16網絡作為三維卷積網絡的骨干,并為了學習到更多的特征在此基礎上加入部分Inception網絡結構,并取得了更高的識別精度。
2 VIC3D模型
由于船舶的狀態變化不明顯,采用短時間內的連續幀的方法很難提取到有效的時序信息,對裝卸貨的識別準確率影響較大。因此本文采用每5min取一幀的方法,將相鄰幀之間船舶的變化幅度擴大使裝卸貨的過程中貨物量的變化更加明顯,以6幀時序幀序列作為輸入,以三維卷積作為基礎框架,使用VGG-16網絡并結合Inception網絡的VIC3D模型來訓練數據集,最后用模型對航運監控中船舶一段時間內的狀態進行預警。
2.1 基于航運監控視頻的三維卷積方法
三維卷積神經網絡既學習圖片的空間特征,也學習了視頻相鄰幀之間的時序信息,這得益于它采用的特殊卷積核。本文航運監控圖像三維卷積的方法如圖1所示。
從圖1中可以看出,三維卷積不僅提取了單幀圖片的空間特征,也提取了不同幀之間的時序特征,通過采用三維卷積核來提取相鄰幀中同一區域的特征,因此獲得的特征圖也是三維的,而圖中同種線型的線條代表提取特征時共享了權重。相較于使用傳統的二維卷積,該方法解決了以往卷積方式無法提取時序特征的問題;然而該方法在卷積過程中,每次卷積都會對時間維度進行壓縮,因此只能采用淺層的神經網絡,但最后的卷積過程仍使用二維卷積,導致時序信息提取失敗。
2014年牛津大學計算機視覺組合和Google DeepMind公司研究員提出了VGGNet系列的結構之后,文獻[10]在文獻[20]的研究基礎上,引入了VGG-11網絡,將其擴展到三維并經過改進后能保持使用三維卷積進行特征提取,避免了因引入二維卷積而丟失時序信息。因此本文將后者作為基礎結構并加以改進。
2.2 基于三維卷積網絡的Inception結構
最初,谷歌網絡(GoogLeNet)對網絡中的傳統卷積層進行了修改,提出了Inception結構,主要特點在于不僅增加了神經網絡的深度,還增加了寬度,以此來提高神經網絡的性能,從最開始的Inception v1不斷改進延伸到Inception v4,均在當時取得了不錯的效果。
本文采用了Inception v4中的第三個模塊(Inception-C),并對其中的各項參數作出調整來適用于本文的三維卷積神經網絡模型。該模塊可以更方便地與本文的模型結合,并且不會讓模型過于復雜而導致計算資源不足的問題。由于網絡層次過深的話容易出現梯度彌散而導致模型性能下降,并且會導致實際應用中的識別所需時間大幅增加,因此本文放棄了其他模塊的加入。本文改進后的Inception-C結構如圖2所示。
從圖2中可以看出,該結構除了深度上的卷積層外,并列了多個卷積層以提取更多的特征,從而提高了模型的學習效果。
2.3 基于VGG與Incption網絡的三維卷積網絡模型
本文在上述三維卷積神經網絡的基礎上,選用效果更優的VGG-16網絡作為基礎網絡,加入了Inception-C模塊,并將最后一層卷積后的特征矩陣作為本文Inception-C結構的輸入,在進行了級聯操作后經過3個全連接層,最后一層是softmax層。本文VIC3D模型結構如圖3所示。
本文的輸入部分為等間隔取幀的連續6張圖片,針對這種輸入方式將VGG結構的前3層中池化層的步長設置為了1×2×2,避免了過早地將時間維度壓縮而導致時序特征提取不夠充分的問題。
該VGG結構的5層卷積層后的池化操作均采用了最大池化的方式,前2層卷積層均連續進行2次卷積,后3層則均連續進行3次卷積,共計13次卷積操作。
在第5層卷積層池化之后為Inception結構,由圖2可以看出,該部分將前面卷積之后的特征圖分別并列進行了4種卷積操作,最左側的平均池化操作中的步長為1×1×1,采用了Valid填充方式,因此不會使輸入的特征圖大小發生改變。由于本文輸入數據的時間維度為第一個維度,因此圖2中的1×3×3卷積核僅是對空間部分特征的提取,而3×1×1卷積核則是單獨對時間部分特征的提取,這種方式能夠提取更加豐富的特征。該結構的最后部分是將5個特征圖并聯起來作為后續輸入。
本文三維卷積結構的最后部分首先采用了一層平均池化層將時間維度進行最后的壓縮,然后進行全連接,這里將全連接層的大小改為2048以減少計算量。
此外,本文對基于VGG的三維卷積網絡加入了滑動平均來更新變量,滑動平均可以看作是變量的過去一段時間取值的均值,相較對變量直接賦值而言,滑動平均得到的值在圖像上更加平緩光滑,抖動性更小,不會因為某次的異常取值而使得滑動平均值波動很大。變量的更新可以表示為:
其中:變量v在t時刻更新之后記為v(t);變量v在t時刻更新之前的取值為θ(t);衰減率α決定了變量的更新速度,取值越大變量越趨于穩定,一般選取接近1的值。
本文損失函數選用的多分類任務中常用的交叉熵(Cross-Entropy)損失函數,其定義如下:
其中:n表示樣本數;m為類別數;y為實際類別的one-hot向量;f∧(x)為預測的類別概率。用式(2)來計算softmax回歸處理之后預測概率分布與真實概率分布之間的距離。
3 實驗與結果分析
3.1 數據集描述
本文采用的數據集為航運智能監控項目中積累的數據集,船上攝像頭的監控視頻傳到服務器后處理成了連續的視頻幀,本文將從圖片服務器上獲取的數據按照相應類別分好后形成了初步的數據集,并舍棄了黑夜部分的數據,僅保留了白天部分用作訓練。
經過長時間的篩選,去除了數據集中圖像質量不佳、圖片顯示不完整以及一些嚴重受到天氣影響的數據,然后將剩下的數據集每一類的數量進行了平衡,避免因不同類別之間數據量差異過大而導致模型訓練不佳的問題;對那些數據量過大的類別,采取對同一條船同一天的數據適量選取的方法,既可以適當削減該類別占數據集的比重,又可以豐富該類別數據的多樣性。
經過上述篩選,截至目前為止,本文的數據集總共包含153000張圖片,相當于25500個視頻片段,共計8個類別,其中裝貨以及卸貨部分數據量最少,兩者分別為9990張和10800張。因此,在進行數據預處理時按照適量選取的方式將每一類數據量控制在12000張圖片,也就是2000段視頻片段,并按照9∶1的比例建立訓練集與測試集。
3.2 模型訓練
1)GCRNN模型訓練。
該部分采用的是GCRNN模型[17]對本文的數據集進行訓練,輸入的圖片大小為256×256,首先用6個卷積網絡對每張圖片進行特征提取,然后將提取的特征合并后輸入循環神經網絡(采用的GRU神經元)學習時序特征,設置如下:丟失率為0.9,學習率為0.001,batch_size為32,訓練總次數為7000。
本文在上述基礎上將前面提取特征的卷積網絡替換為了50層的殘差網絡(Resnet50),該網絡能更充分地提取圖像特征。對于該部分網絡提取的特征,經過實驗比較之后,最終選擇了第二模塊的最后一層特征圖作為后續循環神經網絡的輸入,因為層數過淺的特征提取得信息不夠完善,而層數過深的則損失了過多的船體結構信息,導致后續循環神經網絡部分提取的時序信息不足,從而影響模型的效果。其他參數的設置與上述一致。
2)以VGG與Inception結構為基礎的三維卷積模型訓練。
首先將分好的數據集進行后續處理,按照每連續6張圖來建立一個子文件夾,這樣一個子文件夾就相當于一段輸入視頻,由于VGG網絡的標準輸入為224×224,所以將連續的6張圖片縮放為224×224的大小作為VGG網絡的輸入,也就是輸入數據的大小為6×224×224×3。
首先,采用基于VGG-11網絡結構的三維卷積模型進行訓練,設置:丟失率為0.8,batch_size為8,學習率為0.0001,滑動平均衰減率為0.9999,訓練總次數為3000次。然后,在VGG-11網絡的最后一層卷積層之后加入Inception-C模塊,將訓練次數設置為4000,其他參數不變。接著,將VGG-11網絡替換為VGG-16網絡,訓練次數設置為4000。最后,將Inception-C模塊加入到VGG-16網絡中,其他參數不變。
3.3 結果分析
所有方法均以視頻監控項目中收集的數據集來進行實驗。將數據集按照9∶1的比例來建立訓練集和測試集,分別采用每一種方法進行訓練,然后用測試集測試,最后統計了各類別的識別準確率以及平均的準確率,并且以平均準確率作為不同方法之間比較的指標,同時為了考慮方法的實用性,比較了每種模型的處理速度,結果如表1所示。
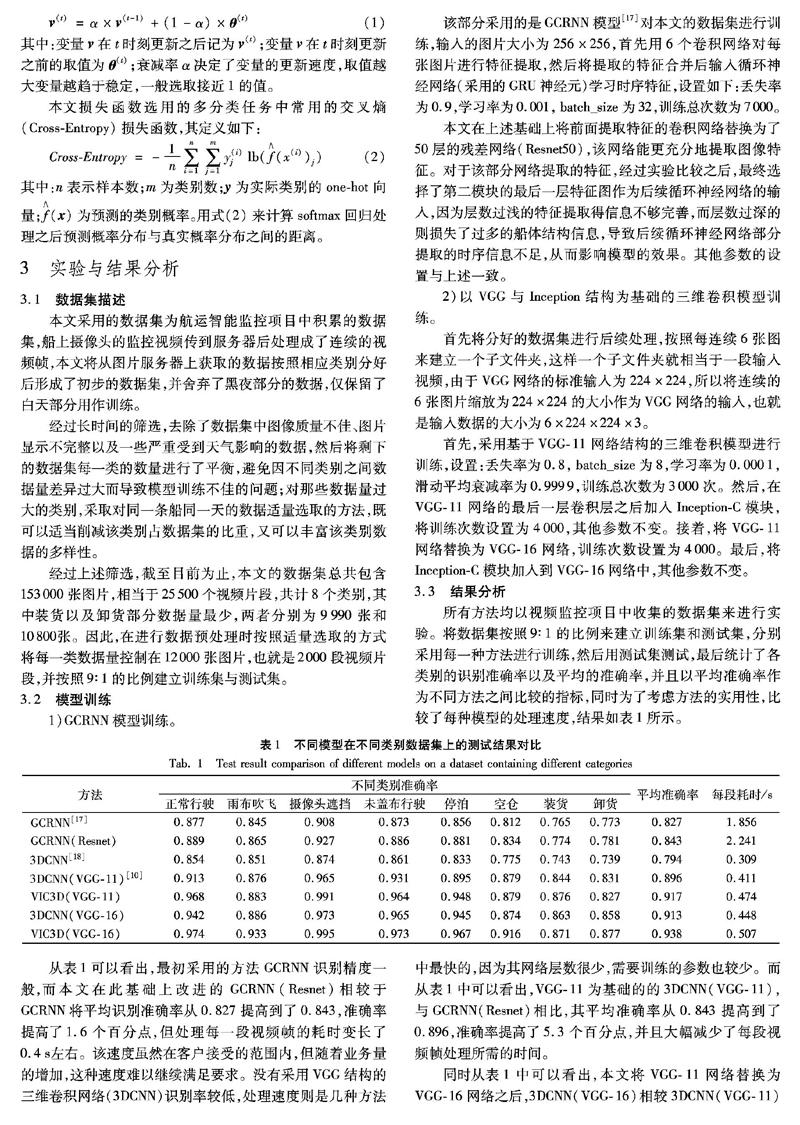
從表1可以看出,最初采用的方法GCRNN識別精度一般,而本文在此基礎上改進的GCRNN(Resnet)相較于GCRNN將平均識別準確率從0.827提高到了0.843,準確率提高了1.6個百分點,但處理每一段視頻幀的耗時變長了0.4s左右。該速度雖然在客戶接受的范圍內,但隨著業務量的增加,這種速度難以繼續滿足要求。沒有采用VGG結構的三維卷積網絡(3DCNN)識別率較低,處理速度則是幾種方法中最快的,因為其網絡層數很少,需要訓練的參數也較少。而從表1中可以看出,VGG-11為基礎的的3DCNN(VGG-11),與GCRNN(Resnet)相比,其平均準確率從0.843提高到了0.896,準確率提高了5.3個百分點,并且大幅減少了每段視頻幀處理所需的時間。
同時從表1中可以看出,本文將VGG-11網絡替換為VGG-16網絡之后,3DCNN(VGG-16)相較3DCNN(VGG-11)平均準確率提高了1.7個百分點,處理速度稍微下降,表明了VGG-16網絡相較于VGG-11能更有效地學習視頻特征。而與之相對的,采用VGG-11與Inception結構相結合的方法VIC3D(VGG-11)比單純替換為VGG-16的方法3DCNN(VGG-16)平均準確率提高了0.4個百分點,相較VGG-11的方法3DCNN(VGG-11)則提高了2.1個百分點。相較之前用到的三種三維卷積方法3DCNN(VGG-11)、VIC3D(VGG-11)、3DCNN(VGG-16),本文選用的最終方法VIC3D(VGG-16)的平均準確率分別提高了4.2個百分點、2.1個百分點和2.5個百分點,處理每段視頻幀的速度也只是稍微下降,并且該處理速度在實際應用中完全滿足需求。
通過對比不同方法的檢測結果可以發現:GCRNN中的循環神經網絡部分雖然可以學習時序特征,但應用到視頻識別方面的效果還是不太理想,并且模型過于復雜而導致了訓練所需時長較長,收斂速度與處理速度也比較慢;沒有使用VGG網絡的三維卷積網絡3DCNN與使用的3DCNN(VGG-11)相比,準確率差別達到了10.2個百分點,主要是因為3DCNN在卷積時折疊了時序特征,導致最后的特征圖中時序信息大部分丟失,從而影響了識別效果。對于基于VGG結構的三維卷積網絡,加入了Inception模塊的方法在稍微犧牲處理速度的前提下準確率均要優于沒有加入該模塊的方法,并且本文提出的VIC3D方法在這些方法中取得了最高的識別準確率。
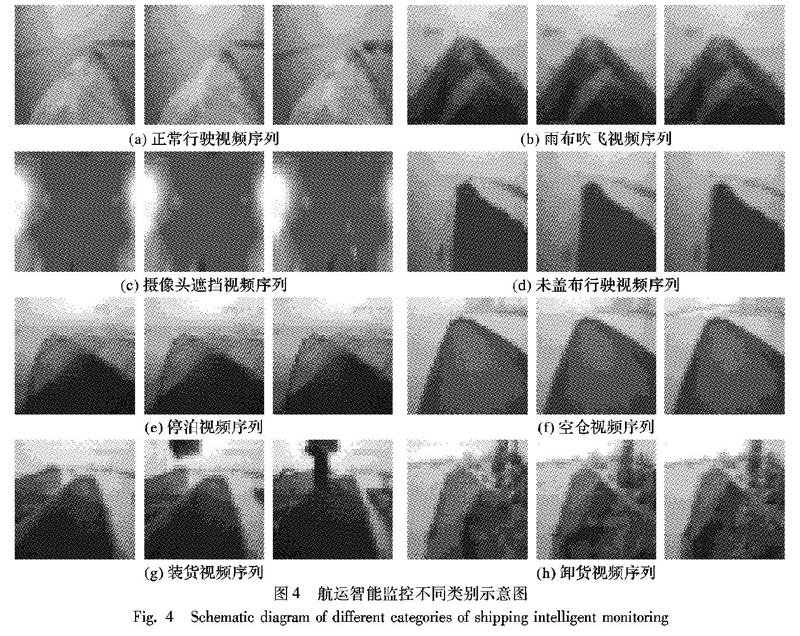
表1中各個類別為客戶要求而選擇的類別劃分,從表1中可以看出,本文提出的VIC3D方法在各類別的識別準確率相較其他方法要更高;但各類別之間識別率差別較大,裝卸貨、空倉以及雨布吹飛的準確率相對較低,其中雨布吹飛容易錯分為正常行駛,空倉容易錯分為未蓋布,裝卸貨則容易錯分為停泊等,主要原因是有些類別之間的界限不是很明確,以及江海上惡劣天氣的影響。航運智能監控類別示意圖如圖4所示,其中:(1)~(3)為正常行駛,(4)~(6)為雨布吹飛,(7)~(9)為攝像頭遮擋,(10)~(12)為未蓋布行駛,(13)~(15)為停泊,(16)~(18)為空倉,(19)~(21)為裝貨,(22)~(24)為卸貨。
由于在實際應用中客戶會對某一類別比較關注,這時僅采用準確率作為衡量指標不能滿足客戶需求,如出于對貨物安全的考慮,客戶對雨布吹飛這個類別更為關注,因此對于該類別,本文比較了不同方法的查全率、查準率以及F1度量。不同方法對于雨布吹飛這個類別的上述三種指標值的結果如表2所示。
從表2中可以看出,本文提出的方法VIC3D(VGG-16)取得了最高的查準率和F1度量,并且查全率也相對較高,表明了本文所提模型有相對最優的性能。
4 結語
針對傳統的機器學習算法對大數據量的航運監控視頻識別分類效果不佳,以及以往的三維卷積識別準確率較低的問題,本文提出了一種基于VGG-16的三維卷積網絡并引入Inception模塊的VIC3D模型對航運貨物實時監控視頻進行智能識別。實驗中,使用智能航運監控項目中獲取的數據集,并將其分為裝卸貨等8個類別進行訓練,將不同方法訓練獲得的模型進行檢測并比較分析。在航運智能監控項目數據集上的實驗結果表明,本文提出的VIC3D模型能有效提高監控視頻識別的準確率,并且在處理每段視頻幀的速度上也足以滿足客戶需求。
本文方法是在多個現有方法的基礎上,針對該數據集以及現有研究上的不足,最后將不同網絡結構進行結合,以較高的準確率對航運監控視頻作出類別預測,并在識別速度上滿足了需求。但本文方法最終的準確率對于應用到項目上來說還不是很高,個別類別準確率仍有待于進一步提升,因此還需要進一步的研究以達到更高的準確率。
參考文獻 (References)
[1]HASSABIS D, KUMARAN D, SUMMERFIELD C, et al. Neuroscience-inspired artificial intelligence [J]. Neuron, 2017, 95(2): 245-258.
[2]鄧昀,李朝慶,程小輝.基于物聯網的智能家居遠程無線監控系統設計[J].計算機應用,2017,37(1):159-165.(DENG J, LI C Q, CHENG X H. Design of remote wireless monitoring system for smart home based on Internet of things [J]. Journal of Computer Applications, 2017, 37(1): 159-165.)
[3]梁光勝,曾華榮.基于ARM的智能視頻監控人臉檢測系統的設計[J].計算機應用,2017,37(S2):301-305.(LIANG G S, ZENG H R. Design of intelligent video surveillance face detection system based on ARM [J]. Journal of Computer Applications, 2017, 37(S2): 301-305.)
[4]GUAN Z, MIAO Q, SI W, et al. Research on highway intelligent monitoring and warning system based on wireless sensor network [J]. Applied Mechanics and Materials, 2018, 876: 173-176.
[5]LIU Z, JIANG S, ZHOU P, et al. A participatory urban traffic monitoring system: the power of bus riders [J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(10): 2851-2864.
[6]劉全,翟建偉,章宗長,等.深度強化學習綜述[J].計算機學報,2018,41(1):1-27.(LIU Q, ZHAI J W, ZHANG Z Z, et al. A summary of deep reinforcement learning [J]. Chinese Journal of Computers, 2018, 41(1): 1-27.)
[7]REN R, HUNG T, TAN K C. A generic deep-learning-based approach for automated surface inspection [J]. IEEE Transactions on Cybernetics, 2018, 48(3): 929-940.
[8]SCHMIDHUBER J. Deep learning in neural networks: an overview [J]. Neural Networks, 2015, 61: 85-117.
[9]LAN Z, ZHU Y, HAUPTMANN A G, et al. Deep local video feature for action recognition [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1219-1225.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
