結合支持向量機與半監督K-means的新型學習算法
2019-01-06 07:27:07杜陽姜震馮路捷
計算機應用 2019年12期
杜陽 姜震 馮路捷


摘 要:半監督學習結合少量有標簽樣本和大量無標簽樣本,可以有效提高算法的泛化性能。傳統的半監督支持向量機(SVM)算法在目標函數中引入無標簽樣本的依賴項來推動決策面通過低密度區域,但往往會帶來高計算復雜度和局部最優解等問題。同時,半監督K-means算法面臨著如何有效利用監督信息進行質心的初始化及更新等問題。針對上述問題,提出了一種結合SVM和半監督K-means的新型學習算法(SKAS)。首先,提出一種改進的半監督K-means算法,從距離度量和質心迭代兩個方面進行了改進;然后,設計了一種融合算法將半監督K-means算法與SVM相結合以進一步提升算法性能。在6個UCI數據集上的實驗結果表明,所提算法在其中5個數據集上的運行結果都優于當前先進的半監督SVM算法和半監督K-means算法,且擁有最高的平均準確率。
關鍵詞:支持向量機;K-means;半監督聚類;分類;融合
中圖分類號: TP181;TP301.6算法理論文獻標志碼:A
Novel learning algorithm combining support vector machine and semi-supervised K-means
DU Yang, JIANG Zhen*, FENG Lujie
(College of Computer Science and Communication Engineering, Jiangsu University, Zhenjiang Jiangsu 212013, China)
Abstract: Semi-supervised learning can effectively improve the generalization performance of algorithm by combining a few labeled samples and large number of unlabeled samples. The traditional semi-supervised Support Vector Machine (SVM) algorithm introduces unlabeled sample dependencies into the objective function to drive the decision-making surface through the low-density region, but it often brings problems such as high computational complexity and local optimal solution. At the same time, semi-supervised K-means algorithm faces the problems of how to effectively use the supervised information to initialize and update the centroid. To solve these problems, a novel learning algorithm of Semi-supervised K-means Assisted SVM (SKAS) was proposed. Firstly, an improved semi-supervised K-means algorithm was proposed, which was improved from two aspects: distance measurement and centroid iteration. Then, a fusion algorithm was designed to combine semi-supervised K-means algorithm with SVM in order to further improve the performance of the algorithm. The experimental results on six UCI datasets show that, the proposed method outperforms the current advanced semi-supervised SVM and semi-supervised K-means algorithms on five datasets and has the highest average accuracy.
Key words: Support Vector Machine (SVM); K-means; semi-supervised clustering; classification; fusion
0 引言
傳統的機器學習算法需要大量的有標簽樣本作為訓練集,但現實生活中大量數據往往是沒有被標注的,人工標注數據的代價太高。半監督學習[1-3]則利用大量無標簽樣本和少量有標簽樣本來提高學習模型的泛化性能,主要可分為兩大類:
1)半監督分類算法利用無標簽樣本結合有標簽樣本進行模型訓練,獲得性能更優的分類器,彌補有標簽樣本不足的缺陷。其中半監督支持向量機(Support Vector Machine, SVM)[4-7]是目前應用較為廣泛的一種半監督分類算法,其主要思想是在同時考慮有標記樣本和未標記樣本的前提下,找到最大間隔劃分超平面并穿過數據低密度區域。大量無標簽樣本的引入提高了算法的復雜度,并且容易陷入局部最優解。半監督SVM集成是[8-10]當前的一個研究熱點,通過集成多個半監督SVM基分類器來進一步提高泛化性能;但仍面臨著算法復雜性和局部最優解等問題。
2)半監督聚類算法通過利用額外的監督信息來獲得更好的聚類效果。目前所用的監督信息主要有兩種形式:第一種形式是“必連”(must-link)與“勿連”(cannot-link),即兩個樣本屬于同一類為“必連”,不屬于同一類則為“勿連”[11];第二種形式是利用少量樣本的類別標簽,即用有標簽樣本初始化K值和質心[12]。但簇的個數不一定等于類別數以及質心迭代等問題依然對算法性能有著較大的影響。
半監督分類和聚類分別從不同的角度結合有標簽樣本和無標簽樣本進行樣本的劃分,將二者結合是提高學習性能的一種可行方向,但是當前類似的研究極少。本文提出了一種結合SVM和半監督K-means的新型學習算法(novel learning algorithm of Semi-supervised K-means Assisted SVM, SKAS)。該算法融合了SVM和半監督K-means(Semi-Supervised K-means, SSK)的預測結果,通過二者的優勢互補提升了算法的分類性能。特別地,從距離度量和質心迭代兩個方面對半監督K-means算法進行了改進,進一步提高了算法的泛化性能。
1 相關工作
1.1 半監督SVM
半監督SVM是目前半監督分類算法中較流行的一種分類算法。其中,半監督SVM的目標函數優化問題是一個混合整數規劃問題,難以有效地解決。目前,針對該問題人們已經提出了各種方法,經典的方法有:Belkin等[4]提出的Laplacian SVM算法,Joachims等[5]提出的Transductive SVM算法,Chapelle等[6]提出的半監督支持向量機(Semi-Supervised Support Vector Machines, S3VMs)算法,以及Li等 [7]提出的安全半監督SVM(Safe Semi-Supervised SVMs, S4VMs)算法等。
另一方面,一些研究者發現:半監督SVM與集成學習相結合可以進一步提高分類性能[9-10]。Zhang等 [8]提出了一種新的半監督SVM集成算法。該算法綜合考慮了多種干擾因素對數據分布的影響,并提出了一種基于聚類評價方法的綜合評價方法。
1.2 半監督聚類
目前,關于半監督聚類的研究主要基于約束信息[13-16]。根據用戶提供的約束信息,相應地修改聚類算法的目標函數來指導聚類過程。Wagstaff等 [11]提出了Constranined K-means算法,根據樣本集以及“必連”和“勿連”關系進行算法的迭代[17-18]。Basu等[12]提出了Constrained Seed K-means算法,即將有標簽樣本作為“種子”,用它們初始化K個質心,并且在聚類簇迭代更新過程中不改變種子樣本的簇隸屬關系[19-20]。Pelleg等[14]提出了線性時間約束向量化誤差算法。Zeng等[15]引入有效損失函數克服了成對約束違反問題,提出了成對約束最大間隔聚類算法。何萍等 [16]研究成對約束對周圍無約束樣本點的影響,將在頂點上低層隨機游走和在組件上高層隨機游走相結合,提出了一種雙層隨機游走半監督聚類算法。
2 SKAS
本文提出了一種改進的半監督K-means算法,并結合SVM來提高分類算法的性能,其基本思想如圖1所示。
設訓練樣本Dl、測試樣本Du、訓練樣本的標簽C分別為:
Dl={(x1,y1),(x2,y2),…,(xm,ym)}
Du={(xm+1,ym+1),(xm+2,ym+2),…,(xm+l,ym+l)}
C={C1,C2,…,CK}
其中:m為訓練樣本的個數;l為測試樣本的個數;K為類別個數。
2.1 SVM算法
2.1.1 訓練
基于訓練集Dl,在樣本空間中找到劃分超平面,將不同類別的樣本分開。得到基于SVM訓練的模型。
minw,b,ξ=12‖w‖2+c∑mi=1ξi
s. t. yi((w*xi)+b)≥1-ξi; i=1,2,…,m
ξi≥0; i=1,2,…,m(1)
其中:w是法向量,決定了超平面的方向;b是位移項;m是樣本個數;ξi為標準數據上的松弛變量;c是給定的懲罰因子。
2.1.2 測試
SVM的決策函數f(x)為:
f(x)=sgn(wTψ(x)+b)=
sgn(∑li=1yiαiK(xi,x)+b)(2)
式(2)第二個等式右邊括號里面的量是一個與超平面的距離成正比的量。這種算法的思想是離超平面越遠的點認為分對的可能性越大。
基于上述原理,利用sigmoid函數將決策函數f(x)投射到[0,1]上,得到SVM輸出樣本預測概率值的計算式為:
Pr(y=1|x)≈PA,B(f)≡11+exp(Af+B)(3)
其中f為式(2)中的f(x)。
式(3)中的A和B值這兩個參數是用來調整映射值的大小,這兩個參數是未知的,需要估計,計算式如下:
min{-∑i(ti lb(pi)+(1-ti)lb(1-pi))}(4)
其中:
Pi=11+exp(Afi+B)
t+=N++1N-+2
t-=1N-+2(5)
式中:t+表示樣本屬于正類; t-表示樣本屬于負類。
在處理多分類問題上采用one-versus-one法,在任意兩類樣本之間找到一個超平面,樣本屬于每個類有一個概率函數。因此K個類別的樣本就需要設計K(K-1)/2個超平面。當對一個未知樣本進行分類時,根據投票法原則,最后得票最多的類別即為該未知樣本的類別。
2.1.3 置信度計算
為了計算預測樣本的置信度,最直接的方法是將數據預測類別的概率作為權重,選擇最大的類預測概率PSVM(y=cmax_ j|xj)作為置信度CSVM(xj),即:
CSVM(xj)=PSVM(y=cmax_ j|xj)(6)
但僅將類的最大預測概率作為置信度不夠合理,因此采用一種新的置信度計算方法[21],其通過類別最大的概率與第二大概率的差值來衡量置信度,即:
CSVM(xj)=PSVM(y=cmax_ j|xj)-
PSVM(y=csub_max_ j|xj)(7)
這種置信度計算方法可以針對類重疊區域的數據,有效解決SVM在類重疊情況下性能下降的問題。
2.2 半監督K-means算法
2.2.1 初始化質心
K-means算法有著K值和初始質心難以確定的問題,一般認為:同一個簇內的樣本應該屬于一個類,而同一個類的樣本可能位于不同的簇。本文假定簇個數K等于類別數,若一個類對應多個簇,則將這些簇當作一個大簇的子簇進行處理,從而在尋找最優的K值的過程中實現算法簡化。因此,本文首先根據訓練集中的類別確定K值以及每個簇的標簽。其次,根據訓練集中每個樣本的標簽,把它們依次劃分入每一個簇中,計算每個簇的初始質心:
μi = 1|Ci|∑xi∈Ci xi(8)
其中Ci表示當前樣本屬于的簇。
確定了K值并初始化質心后,計算樣本與各個質心的距離,將樣本劃入相應的簇并更新質心,直到滿足某個停止條件為止。
對于給定的質心μ和樣本x,傳統的距離計算公式為:
distance(μ,x)=∑Dd=1(μd-xd)2(9)
由于數據集中各類別之間的樣本數會存在差異,訓練過程會向樣本數較多的類別傾斜。針對該問題,本文提出了一種基于權重的改進距離公式如下:
distance(μ,x)=ViV∑|D|d=1(μd-xd)2(10)
其中:Vi代表訓練集中質心i所屬的類別中樣本的個數; V代表訓練集中所有樣本的個數;D代表數據集中樣本的維度。
根據式(10),將樣本劃入相應的簇,并確定其所屬類別。
2.2.2 質心迭代的終止條件
傳統的聚類學習中,質心迭代的終止條件往往有兩種:第一種是預先設置好迭代次數;第二種是計算迭代前后的誤差,若小于某個值,則終止迭代。這種迭代的終止條件往往會造成迭代次數超過最優迭代次數時,算法的性能會急劇下降。特別地,在半監督K-means中,由于簇中的噪聲會影響到質心的計算,并可能造成算法性能的下降。因此,本文提出一種新的迭代終止條件,根據Dl上預測結果的準確率進行判斷。
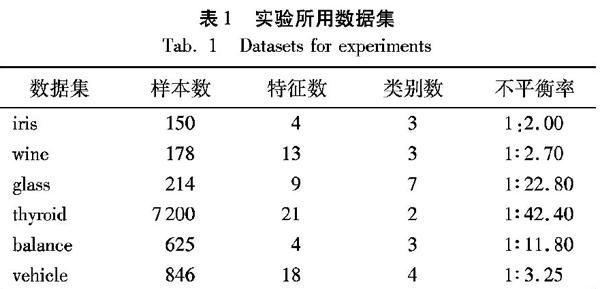
ACC(Dl) 其中:ACC為基于當前質心的預測準確率;old_ACC為基于上一輪質心的準確率。當準確率下降即滿足式(11)時,表明受簇內噪聲的影響,繼續迭代所產生的質心會降低算法性能。此時,停止迭代并恢復上一輪的質心。 該方法兼顧了聚類的傳統指標誤差平方和(Sum of Squares of Errors, SSE)和分類的準確度,在實驗中表現出比較明顯的優勢。 2.2.3 置信度計算 P[i]代表樣本i屬于當前簇的概率,其計算式為: P[i]=(1/d[cluster[i]])/sum(12) 其中:cluster[i]代表樣本i屬于的簇標號;d[j]代表第j個簇中,當前樣本i到達質心的距離;sum=∑Kj=11d[j]代表當前樣本i到達每個質心的距離的倒數和。 置信度的計算式如下: CSKAS(xj)=PSKAS(y=cmax_ j|xj)- PSKAS(y=csub_max_ j|xj)(13) 2.3 融合算法 結合2.1節和2.2節中的算法,并為了進一步提高準確率,將SVM和半監督K-means結合起來進行最終的預測。SVM和半監督K-means的預測結果都轉化為概率的形式,但二者預測的概率并不在同一尺度上,直接把預測的結果結合起來并不能得到滿意的結果。因此,對SVM和半監督K-means預測的置信度做了歸一化處理,然后給出了最終的分類結果。 P(yi|xi)SKAS= P(yi|xi)SSK, μ·CSSK(xi)∑xj∈UCSSK(xj)>(1-μ)CSVM(xi)∑xj∈UCSVM(xj) P(yi|xi)SVM,其他 (14) 其中,μ∈[0,1],是一個用來調節SVM和半監督K-means權重的參數。為了獲得更好的效果,根據SVM和半監督K-means在訓練集上的準確率來調節其權重,如式(15)所示: μ=W1/(W1+W2)(15) 其中,W1、W2分別代表SVM和半監督K-means對有標簽樣本所屬類別預測的準確率。 2.4 SKAS SKAS的流程如下: 輸入 Dl={(x1,y1),(x2,y2),…,(xm,ym)},Du={(xm+1,ym+1),(xm+2,ym+2),…,(xm+l,ym+l)}; 輸出 Du中每個樣本的預測標簽。 步驟1 在Dl上訓練SVM,然后分類Du中樣本,根據式(7)得到每個樣本的置信度。 步驟2 根據Dl中的有標簽樣本初始化K個質心,并根據距離公式(10)將Dl∪Du中的所有樣本劃分到最近的簇中。 步驟3 重復步驟4~5直到質心不再變化或滿足式(11)。 步驟4 根據式(8)更新每個簇里面的質心。 步驟5 根據距離公式(10)重新把Dl∪Du中所有的樣本劃分到最近的簇中。 步驟6 根據迭代終止后每個簇的質心,把Du中樣本重新劃分到最近的簇中,根據式(13)得到每個樣本的置信度。 步驟7 對SVM和半監督K-means的預測結果進行融合,根據式(14)計算Du中樣本所屬類別及其概率。 3 實驗與結果分析 3.1 數據集 針對本文提出的算法模型,使用來自UCI的六個數據集作為性能測試數據,隨機選取30%作為訓練集。同時,為了防止類別不平衡或樣本數量較少導致訓練集未能覆蓋所有類別的情況,當隨機選取的訓練集中缺少某個類別的樣本時,則向訓練集中補充一個缺失類別的樣本,從而保證K值等于訓練集中類別的個數。數據集的詳細信息如表1所示。 3.2 結果分析 為了評估SKAS的分類性能,在標準SVM的基礎上加入S4VMs[7]、EnsembleS3VM[8]和Constrained Seed K-means算法[12]進行實驗對比。對于每種算法,均使用與SKAS相同的訓練預測方法,即基于LIBSVM使用五折交叉檢驗,所有算法均使用五次結果的平均值作為最終結果;其五折交叉驗證通過調用LIBSVM軟件包中的grid函數實現,并對特征值進行了歸一化的處理,通過調用svm-scale來實現。 表2給出了四種不同算法對六個數據集進行訓練預測的實驗結果。實驗采用跟文獻[8]相同的參數設置,對比后發現:在所有數據集中,SKAS中的五個數據集具有最高的準確率,剩下一個接近最好算法的準確率,并且SKAS的平均準確率為75.77,優于其他三種算法。實驗結果表明SKAS能夠提高預測模型的準確率。 選擇其中三個數據集iris、glass和thyroid,分別給出它們的準確率在SVM、Constrained Seed K-means和本文提出的SKAS迭代訓練過程中的變化情況。 首先,由圖2可以看出,本文提出的SKAS在迭代開始的準確率都有上升,并在到達峰值后開始下降,峰值點在圖中已標出。根據2.2.2節中本文提出的新的迭代終止條件,發現圖2(a)至圖2(c)中SKAS的峰值即為迭代的終止點,進一步說明,根據新設置的迭代終止條件提前終止迭代可以取得更好的聚類效果。 其次,從圖2可以發現,SKAS的準確率均高于SVM算法和半監督K-means算法。這也表明了本文提出的融合算法綜合了SVM和半監督K-means的預測結果,確實能有效地提高模型的泛化性能。 圖2(c)中,SKAS的準確率遠遠高于其他兩種算法,主要是因為thyroid的樣本數量較大,且樣本的不平衡率較高。本文提出的算法有效地解決了在樣本數量較多以及類別不平衡時,SVM算法分類性能下降的問題。此外,圖2(c)中半監督K-means的準確率低于SVM,分析其原因可能是thyroid的特征數較多,類重疊現象較為嚴重。 4 結語 本文對半監督K-means算法進行了相應改進,提出了一種結合SVM與半監督K-means算法的新型學習算法——SKAS,該算法可以實現半監督聚類和分類算法的優勢互補。實驗結果表明,SKAS相較于對比算法取得了更好的性能結果,特別是在樣本數量較大的情況下,本文算法的優勢更為明顯。 為進一步優化學習算法,我們后續工作將主要集中在半監督K-means算法的進一步改進上,特別是簇的數量與實際類別數量不一致的問題。此外,我們還將關注類別不平衡問題,研究通過改進算法的目標函數以提高小類別樣本的查全率。 參考文獻 (References) [1]ZHU X, GOLDBERG A B. Introduction to Semi-Supervised Learning [M]. San Rafael: Morgan and Claypool Publishers, 2009: 130. [2]ZHANG Z, SCHULLER B. Semi-supervised learning helps in sound event classification [C]// Proceedings of the 37th IEEE International Conference on Acoustics, Speech, and Signal Processing. Piscataway: IEEE, 2012: 333-336. [3]ZHU X. Semi-supervised learning [C]// Proceedings of the 2011 International Joint Conference on Artificial Intelligence. Menlo Park: AAAI, 2011: 1142-1147. [4]BELKIN M, NIYOGI P, SINDHWANI V. Manifold regularization: a geometric framework for learning from labeled and unlabeled examples [J]. Journal of Machine Learning Research, 2006, 7: 2399-2434. [5]JOACHIMS T. Transductive inference for text classification using support vector machines [C]// Proceedings of the 1999 International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1999: 200-209. [6]CHAPELLE O, CHI M, ZIEN A. A continuation method for semi-supervised SVMs [C]// Proceedings of the 2006 Twenty-Third International Conference on Machine Learning. New York: ACM, 2006: 185-192. [7]LI Y, ZHOU Z. Towards making unlabeled data never hurt [C]// Proceedings of the 28th International Conference on Machine Learning. Madison: Omnipress, 2011: 1081-1088. [8]ZHANG D, JIAO L, BAI X, et al. A robust semi-supervised SVM via ensemble learning [J]. Applied Soft Computing, 2018, 65: 632-643. [9]ZHOU Z. When semi-supervised learning meets ensemble learning [C]// Proceedings of the 8th International Workshop on Multiple Classifier Systems, LNCS 5519. Berlin: Springer, 2009: 529-538. [10]PLUMPTON C O, KUNCHEVA L I, OOSTERHOF N N, et al. Naive random subspace ensemble with linear classifiers for real-time classification of fMRI data [J]. Pattern Recognition, 2012, 45(6): 2101-2108. [11]WAGSTAFF K, CARDIE C, ROGERS S, et al. Constrained K-means clustering with background knowledge [C]// Proceedings of the 8th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2001: 577-584. [12]BASU S, BANERJEE A, MOONEY R J. Semi-supervised clustering by seeding [C]// Proceedings of the 9th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2002: 27-34. [13]DING S, JIA H, ZHANG L, et al. Research of semi-supervised spectral clustering algorithm based on pairwise constraints [J]. Neural Computing and Applications, 2014, 24(1): 211-219. [14]PELLEG D, BARAS D. K-means with large and noisy constraint sets [C]// Proceedings of the 18th European Conference on Machine Learning. Berlin: Springer, 2007: 674-682. [15]ZENG H, CHEUNG Y. Semi-supervised maximum margin clustering with pairwise constraints [J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(5): 926-939. [16]何萍,徐曉華,陸林,等.雙層隨機游走半監督聚類[J].軟件學報,2014,25(5):997-1013.(HE P,? XU X H, LU L, et al. Semi-supervised clustering via two-level random walk [J]. Journal of Software, 2014, 25(5): 997-1013.) [17]STEINLEY D, BRUSCO M J. K-means clustering and mixture model clustering: reply to McLachlan (2011) and Vermunt (2011) [J]. Psychological Methods, 2011, 16(1): 89-92. [18]HONG Y, KWONG S. Learning assignment order of instances for the constrained K-means clustering algorithm [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 2009, 39(2): 568-574. [19]LI K, ZHANG C, CAO Z. Semi-supervised kernel clustering algorithm based on seed set [C]// Proceedings of the 2009 Asia-Pacific Conference on Information Processing. Piscataway: IEEE, 2009: 169-172. [20]GU L, SUN F. Two novel kernel-based semi-supervised clustering methods by seeding [C]// Proceedings of the 2009 Chinese Conference on Pattern Recognition. Piscataway: IEEE, 2009: 1-5. [21]尹玉,詹永照,姜震.偽標簽置信選擇的半監督集成學習視頻語義檢測[J].計算機應用,2019,39(8):2204-2209.(YIN Y, ZHAN Y Z, JIANG Z. Semi-supervised integrated learning video semantic detection with false label confidence selection [J]. Journal of Computer Applications, 2019, 39(8): 2204-2209.) This work is partially supported by the National Natural Science Foundation of China (61672268), the Research Initiation Fund for Senior Talents of Jiangsu University (14JDG036). DU Yang, born in 1994, M. S. candidate. His research interests include machine learning. JIANG Zhen, born in 1976, Ph. D., associate professor. His research interests include machine learning. FENG Lujie, born in 1996, M. S. candidate. Her research interests include machine learning. 收稿日期:2019-05-14;修回日期:2019-07-23;錄用日期:2019-07-25。 基金項目:國家自然科學基金資助項目(61672268);江蘇大學高級人才科研啟動基金資助項目(14JDG036)。 作者簡介:杜陽(1994—),男(漢族),江蘇揚州人,碩士研究生,主要研究方向:機器學習; 姜震(1976—),男(漢族),山東煙臺人,副教授,博士,主要研究方向:機器學習; 馮路捷(1996—),女(漢族),江蘇淮安人,碩士研究生,主要研究方向:機器學習。 文章編號:1001-9081(2019)12-3462-05 DOI:10.11772/j.issn.1001-9081.2019050813
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
