一種基于HBase的RDF數據存儲改進方法
2019-01-02 09:01:18朱道恒,秦學,劉君鳳
軟件
2019年12期
關鍵詞:數據存儲


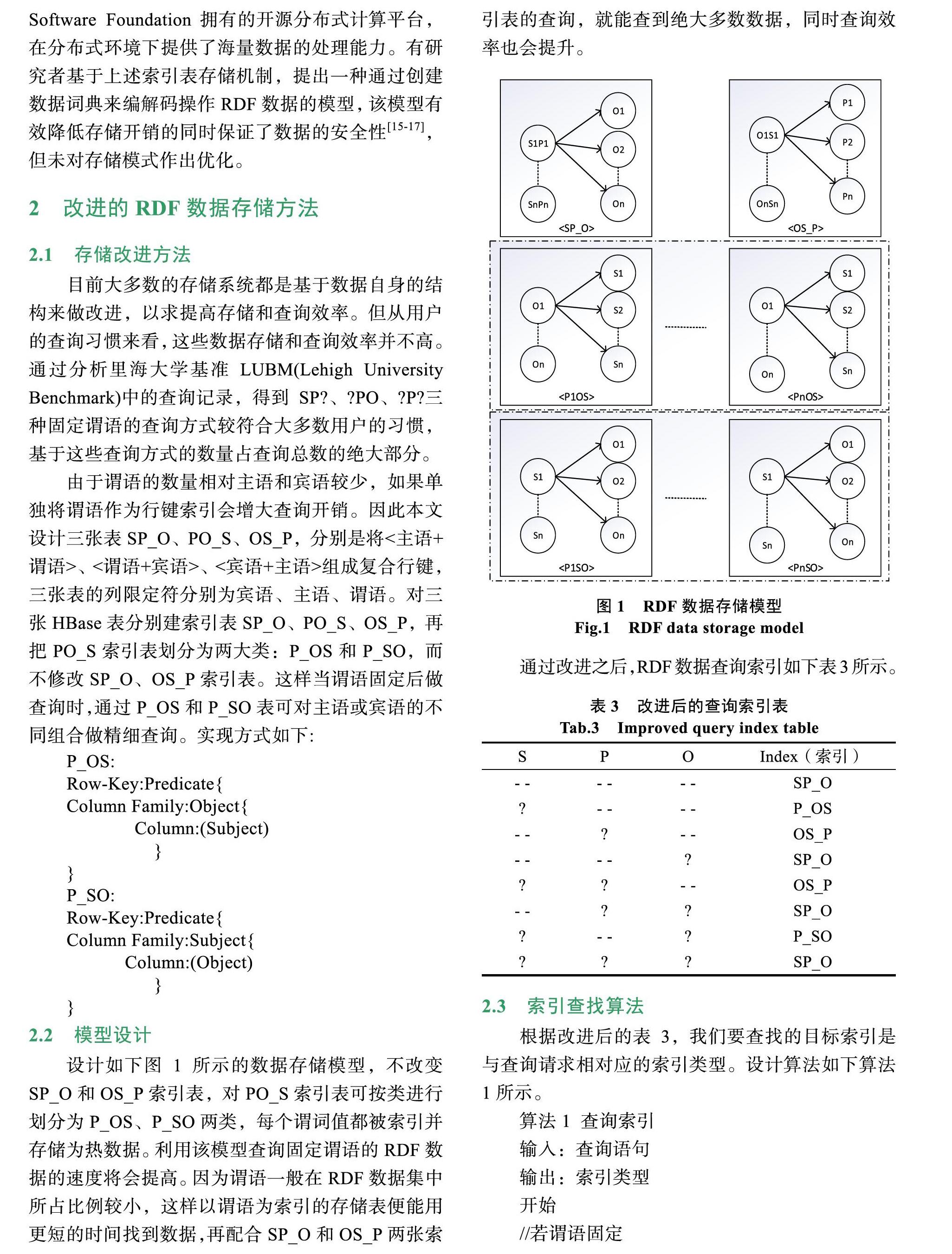
摘 ?要: 為高效地存儲和管理大規模語義Web數據,結合語義Web數據查詢的特點,提出一種基于HBase的資源描述框架RDF(Resource Description Framework)數據存儲改進方法。該方法將以主語+謂語、謂語+賓語、賓語+主語為索引的RDF數據存放在SP_O、PO_S、OS_P三張索引表中,同時將PO_S表按類劃分為P_SO和P_OS兩類,并給出改進的查詢索引方法。對數據的加載存儲,利用HBase自帶的BulkLoad工具將數據上傳至HBase存儲表中。通過理論分析和實驗結果顯示,改進的存儲方法對固定謂語的查詢能作出快速響應;BulkLoad并行加載數據具有較高的加速比,在縮短數據加載時間的同時能提升系統整體存儲性能。
關鍵詞: 語義Web;HBase;RDF;數據存儲
中圖分類號: TP391.9 ? ?文獻標識碼: A ? ?DOI:10.3969/j.issn.1003-6970.2019.12.003
本文著錄格式:朱道恒,秦學,劉君鳳. 一種基于HBase的RDF數據存儲改進方法[J]. 軟件,2019,40(12):1317
An Improved Method of RDF Data Storage Based on HBase
ZHU Dao-heng, QIN Xue, LIU Jun-feng
(College of Big Data and Information Engineering, Guizhou University, Guiyang Guizhou 550025, China)
【Abstract】: In order to efficiently store and manage large-scale semantic Web data , an improved method of data storage based on HBase's resource description framework RDF is proposed., which combines the characteristics of semantic Web data query. In this method, RDF data indexed by subject + predicate, predicate + object, object + subject is stored in three index tables of SP_O, PO_S and OS_P.At the same time, PO_S table is divided into two categories, P_SO and P_OS, and an improved query index method is given. To load and store the data, the BulkLoad tool that HBase brings is used to upload the data to the HBase storage table. The theoretical analysis and experimental results show that the improved storage method can respond quickly to the fixed predicate query; BulkLoad parallel loading data has a high acceleration ratio, which can improve the overall storage performance of the system while shortening the data loading time.
【Key words】: Semantic web; HBase; RDF; Data storage
0 ?引言
語義Web核心思想是:通過在Internet上的文檔中添加可被計算機所理解的語義,從而使整個Internet成為一個通用的信息交換媒介[1]。為規范化地描述Web資源及其屬性,W3C組織提出了一個Web資源之間語義關系的開放元數據框架RDF[2]。RDF作為一種典型的非結構化數據,是一種規范的語義Web描述方法。
近年來,由于語義網發展迅速,語義Web數據呈現井噴式的增長,這使得關系型數據庫管理系統已經很難管理這些數據。而關系型數據庫在處理大規模語義Web數據時存儲與查詢效率均低于分布式數據庫,越來越多的研究者開始利用分布式系統的海量數據存儲與并行計算能力來解決海量數據管理問題[3-4]。
RDF數據的存儲從以下兩個方面入手:
(1)存儲方面:建立合適的表結構使數據存儲空間開銷與查詢性能達到一定平衡;
登錄APP查看全文
猜你喜歡
文理導航(2017年2期)2017-02-16 13:18:46
辦公室業務(2016年11期)2017-01-09 18:02:44
中國科技博覽(2016年24期)2016-12-28 23:25:48
電子技術與軟件工程(2016年20期)2016-12-21 11:11:51
電腦知識與技術(2016年28期)2016-12-21 10:13:14
電腦知識與技術(2016年27期)2016-12-15 20:33:05
電腦知識與技術(2016年12期)2016-06-14 19:10:43
電腦知識與技術(2016年12期)2016-06-14 01:13:57
電腦知識與技術(2016年8期)2016-05-19 13:33:11
科技視界(2016年4期)2016-02-22 13:10:37
