機器學習在批次生產過程操作尋優中的應用
2018-12-28 03:56:24韓曉春吳學華婁海川吳玉成侯衛鋒
自動化儀表 2018年12期
韓曉春,田 甜,吳學華,婁海川,吳玉成,侯衛鋒
(浙江中控軟件技術有限公司,浙江 杭州 310053)
0 引言
由于石化工業生產機理的復雜性、生產模式的不斷變化、設備狀況的老化及生產過程的擾動等原因,常常使生產偏離優化狀態,產品質量降低。化工批次生產過程的產品質量主要取決于操作參數和原料,在供給原料相同的條件下,操作參數的調整將直接影響產品品質的穩定性。因此,需隨時對操作參數進行適當調整,以保證產品質量。一般情況下,現場工藝人員會結合化驗分析結果和操作經驗調整生產操作參數,而化驗分析結果通常滯后于實時生產,難以根據原料變化和產品的規格要求將操作參數及時調整到相應的最優狀態。針對過程操作參數優化問題,大量學者進行了深入研究,力求在現有設備、原料和工藝流程不變的條件下,通過優化過程操作參數提高產品質量[1-3]。
為提高產品品質,本文給出基于機器學習算法進行工藝參數尋優的方法,尋求批次生產操作參數的最優組合,并結合參數建議值和操作經驗對工藝操作作出相應調整。
1 操作尋優有關算法
1.1 隨機森林
隨機森林[4]采用Bootstrap[5]重采樣技術,以K個決策樹{h(X,θk),k=1,2,…,K}為基學習器,進行集成學習后得到組合模型。其中,參數{θk,k=1,2,…,K}是獨立同分布的隨機向量。在給定樣本時,通過每個決策樹的輸出結果投票來決定隨機森林的最優預測結果[6-7]。
隨機森林可以用于分類和回歸。針對分類問題,因變量為分類變量,組合方法是簡單多數投票法;針對回歸問題,因變量是連續變量,則是簡單加權平均法。大量的理論和試驗都證明了隨機森林簡單易實現,計算開銷小,具有很高的預測準確率,對異常值和噪聲具有較好的穩定性,且不易產生過擬合,具有較強的泛化能力。
隨機森林回歸算法的步驟如下。
①采用Bootstrap重復抽樣法,從原始樣本集中隨機采樣,產生K個訓練樣本集{θ1,θ2,…,θK}。
②從所有特征中隨機選擇m個特征作為當前節點的分裂特征集,利用這些特征進行決策樹[8]建模,選擇最好的特征方式對節點進行分裂。
③不對任何決策樹進行剪枝處理,使其最大限度地生長。
④對K個訓練樣本集進行學習,重復以上步驟K次,即生成K棵決策樹{T(θ1),T(θ2),…,T(θK) },形成隨機森林。
⑤對于新樣本數據x,單個決策樹T(θ)的預測值可通過因變量的觀測值Yi(i=1,2,…,n)的加權平均得到,即:
(1)
式中:wi(x,θ)為決策樹權重向量,i=1,2,…,n,滿足∑wi(x,θ)=1;
⑥對決策樹權重wi(x,θ)(i=1,2,…,n)取平均,得到每個觀測值Xi(i=1,2,…,n)的權重:
(2)
⑦經過每棵樹決策,對于所有y,隨機森林的最終預測值為所有因變量觀測值的加權和:
(3)
1.2 Mean Shift聚類
Mean Shift算法是一個非參數聚類技術,不需要預先確定聚類的類別數,且可以根據數據的特征發現任意形狀的聚類簇。
給定d維空間的n個數據點集{xi,i=1,2,…,n},對于空間中任意點的Mean Shift向量,其基本形式可以表示為:
(4)
式中:k表示在這n個樣本點中,有k個點落入Sh區域中;(xi-x)表示樣本點xi相對于原點x的偏移向量;Sh為以h為半徑的高維球。
Sh(x)={y|(y-xi)T(y-xi)≤h2}
(5)
對于基本的Mean Shift向量,可以增加核函數和樣本權重,從而得到改進的Mean Shift 向量形式[9]進行聚類分析。Mean Shift聚類步驟如下。
①從未被標記的數據集中,隨機選取點x作為初始中心點,在指定的區域Sh內計算出偏移均值。
②更新球圓心x的位置x←x+Mh。
③重復步驟①和步驟②,直至滿足條件||Mh||<ε。記此時的球圓心x為簇中心點,將區域Sh內的點都標記并劃入該簇中。
④如果收斂時當前簇ci+1的中心與其他已存在的簇ci中心的距離小于閾值,那么將兩類簇合并;否則,把ci+1作為新的聚類。
⑤重復步驟①~步驟③,直至所有點都被標記,得到簇劃分c1,c2,…,cn。
2 機器學習算法進行操作參數尋優
基于機器學習算法進行批次生產過程操作參數優化的步驟如下。
①獲取產品品質要求的實驗室信息管理系統(laboratory information management system,LIMS)化驗分析數據進行頻次圖分析,根據過程能力指數(capability index of process,Cp/Cpk)和過程性能指數(performance index of process,Pk/Ppk)判斷批次生產過程是否穩定操作,品質要求是否控制在合理范圍內。
②通過人工錄入批號,將產品品質要求的化驗分析數據與實際生產操作進行匹配,結合現場工藝人員的操作經驗,選擇可能影響產品品質的工藝過程參數。
③將化驗分析數據和工藝過程參數進行歸一化處理,分析其關聯性,選擇重要的特征參數。
④采用隨機森林算法進行數據擬合建模。
⑤計算出指定范圍內工藝操作參數組合對應的產品品質擬合值,通過網格搜索找到產品品質要求范圍內的所有工藝操作參數組合。
⑥對找出的工藝操作參數進行Mean Shift聚類分析,自動尋找合適的工藝操作參數組合。
機器學習算法在批次生產過程操作參數優化的流程圖如圖1所示。
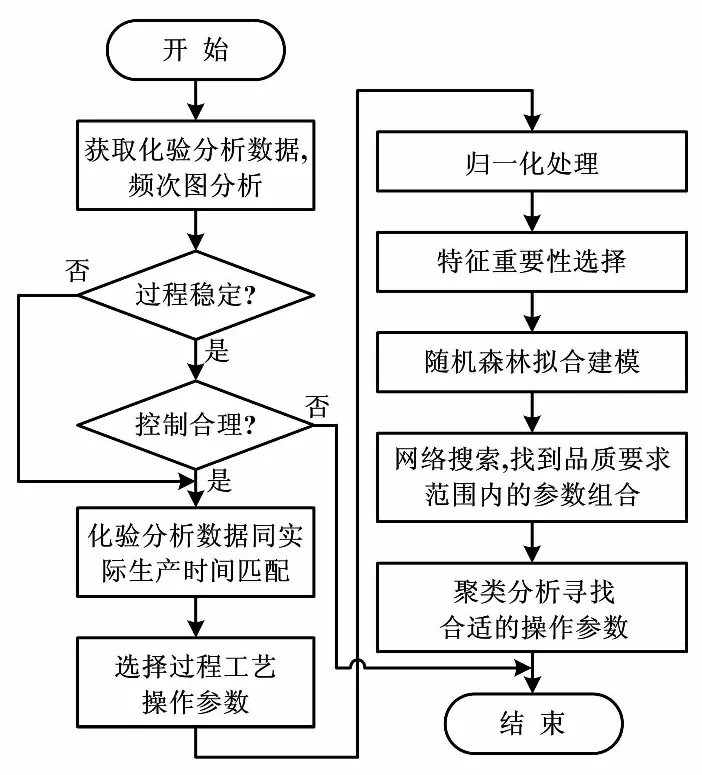
圖1 操作參數優化流程圖
3 實例分析
某工廠生產107膠,原料是水解物,生產過程主要包含脫水、聚合和脫低3個工藝過程。由于對產品的黏度要求較高,根據不同的黏度規格,其生產操作參數的控制不同,現場工藝人員必須通過調節充氮氣時間、聚合時間和聚合溫度等操作參數,控制產品黏度值。由于缺乏定量的操作指標,控制效果并不理想,相同規格、不同批次的黏度差異較大。因此,迫切需要應用機器學習算法尋找最優工藝操作參數,對該廠的107膠產品進行黏度控制。
3.1 黏度頻次圖分析
107膠黏度檢驗結果如圖2所示。
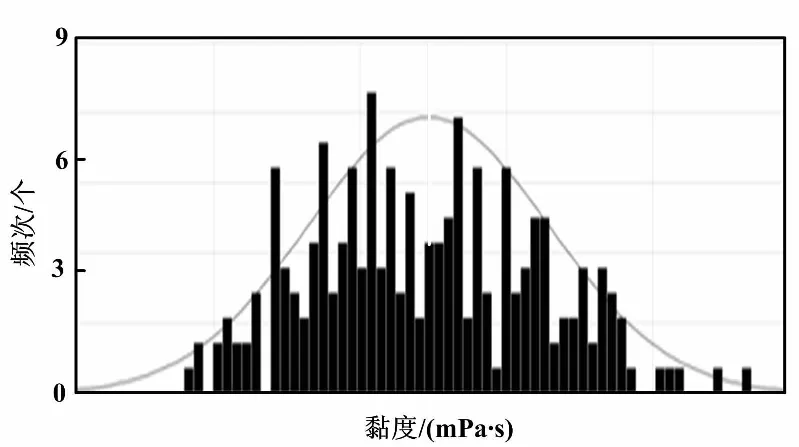
圖2 107膠黏度檢驗結果
對107膠20 000黏度的LIMS化驗分析數據進行正態分布檢驗。圖2中,直方圖表示107膠粘度的頻次分布,曲線表示對應的密度曲線,可以直接反映出107膠黏度的分布情況。由圖2可發現,黏度波動范圍較大,不符合正態分布生產趨勢。經過現場調研發現,一般情況下,在生產過程中,工藝人員并沒有實時跟蹤107膠的生產操作參數并進行調整,且不同班次的工藝人員依據經驗來調整生產操作參數。這樣雖不會超出工藝規程中的上下限,但生產操作參數并不是最優的,具有一定的優化空間。
3.2 工藝參數選擇
影響107膠最終質量的關鍵過程工藝參數很多,包括能夠實時測量的位號參數,以及需要從工藝單中提取的階段性參數。結合實時位號趨勢和工藝人員的經驗,從中挑選了19個不同的工藝過程參數。
3.3 相關性分析
從實時數據庫中提取某個月的107膠批次生產過程中的19個工藝參數,首先進行規范化預處理,即作如下變換。其目的是將工藝參數的值控制在[0,1] 之間。
(6)
對該19個工藝參數與對應的黏度進行相關性分析:
(7)
式中:Cov(X,Y)為X、Y的協方差;D(X)、D(Y)分別為X、Y的方差。
計算黏度與各工藝參數的相關系數,黏度與聚合時間和充氮氣時間的相關系數較大,分別為0.49和0.47。由此可以推斷,聚合時間以及充氮氣時間是與黏度相關性最大的兩個工藝過程參數。除此之外,根據90%相關度的原則,增加了脫水結束溫度、壓料結束溫度、脫低結束溫度3個工藝過程參數,由此提取出關聯性較高的5個過程工藝參數。
3.4 數據建模與優化建議
提取出對建模最重要的5個過程工藝參數,并結合對應黏度值進行非線性數據建模,包括人工神經網絡、支持向量機、隨機森林等多種非線性擬合模型,從而挑選出最優擬合模型。利用3種非線性數據驅動模型對該批數據進行擬合建模,并從中找出最能表達這批數據內部規律的隨機森林模型。以隨機森林的高維擬合曲面為基礎,以20 000上下5%的黏度值為限制條件,分別對歸一化后的工藝參數數據進行10等分,對該參數空間進行網格搜索,尋找滿足條件的參數組合。由于滿足條件的參數組合很多,因此需要再對這些參數組合進行聚類分析,得到最優參數組合。此處通過Mean Shift聚類分析,找出了滿足限制條件的兩大類參數中心。工藝參數組合建議值如表1所示。
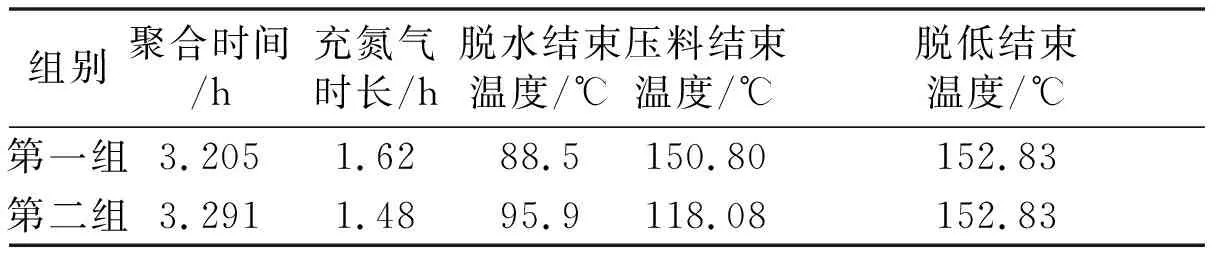
表1 工藝參數組合建議值
根據工藝人員的實際經驗以及操作指導規程,脫水與聚合反應之間的壓料溫度不宜過低。通過對模型的訓練數據集中的壓料結束溫度分布進行檢驗,發現大部分樣本的壓料結束溫度分布在152 ℃,僅有較少樣本的壓料結束溫度分布在122 ℃。因此,在實際生產過程中,只對第一組操作建議值進行了測試。
最后,將20 000黏度107膠的操作優化建議值與新建的虛擬位號相關聯,并實時顯示在工藝流程圖上。工藝人員可以參考操作參數建議值,結合運行工況和現場實時數據及時調整參數,使產品的質量品質在可控范圍內。
3.5 產品黏度控制效果對比
結合運行工況,工藝人員根據操作優化建議值對操作參數進行了調整,并對操作優化前和采用第一組操作優化建議值這兩種運行狀態下的控制指標進行對比分析,控制指標包括過程能力指數Cp/Cpk、最大值、最小值。107膠產品黏度控制測試結果如表2所示。
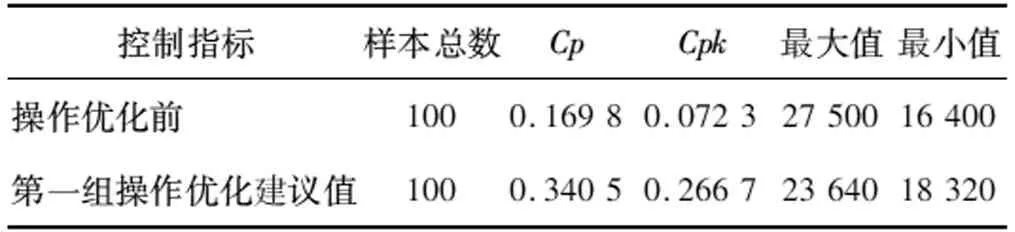
表2 107膠產品黏度控制測試結果
采用優化建議值后,Cp指標由0.169 8升到0.340 5,Cpk指標由0.072 3上升到0.266 7,極差(最大值-最小值)也明顯減小。107膠質量控制結果可視化分析如圖3所示。
最后,對質量控制結果進行了可視化分析。由圖3可知,直方圖通過給出每個值的頻次來反映樣本的分布規律,而密度曲線可以看出數據分布的密度情況。采用優化建議值后,可以發現20 000黏度值型號107膠的質量分布更加集中,說明了采用優化建議后,生產過程的質量控制能力有了較為明顯的提升。
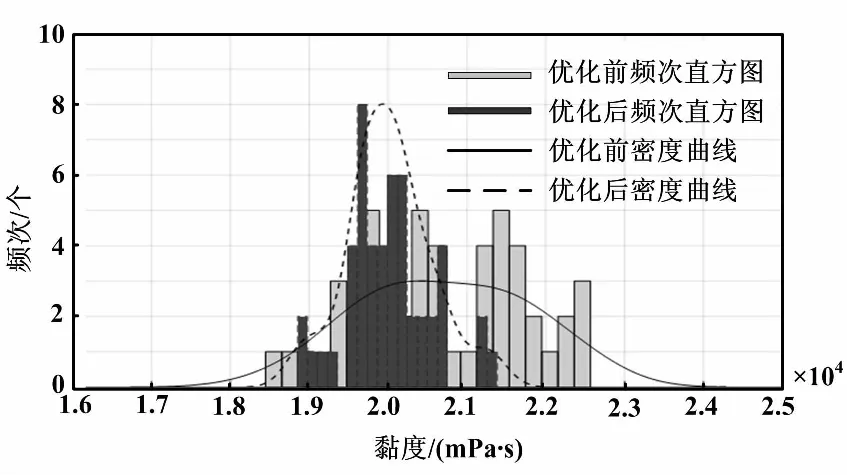
圖3 107膠質量控制結果可視化分析
4 結束語
為了尋找批次生產過程中操作參數的最優組合、提高產品品質,本文提出了基于機器學習算法進行工藝操作參數尋優的方法。將該方法應用于某工廠20 000黏度的溫室硫化甲基硅橡膠(107膠)生產中,可知:首先,通過人工錄入批次、將LIMS化驗分析數據與實際生產操作數據相關聯;然后,根據產品黏度要求,應用機器學習算法尋求最優的操作參數組合;最后,由現場工藝人員結合參數建議值和操作經驗作出相應調整,使產品的質量控制得到了明顯改善。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
小學科學(學生版)(2020年10期)2020-10-28 07:52:12
中國化肥信息(2020年7期)2020-03-19 01:54:02
山東冶金(2019年6期)2020-01-06 07:45:54
世界農藥(2019年2期)2019-07-13 05:55:12
中國軍轉民(2017年6期)2018-01-31 02:22:28
銅業工程(2015年4期)2015-12-29 02:48:39
