基于用戶群、項(xiàng)目、模型的協(xié)同推薦服務(wù)研究
2018-12-23 06:46:06陳蘊(yùn)博
科技與創(chuàng)新 2018年1期
陳蘊(yùn)博
(山東省德州市第一中學(xué),山東 德州 253023)
基于用戶群、項(xiàng)目、模型的協(xié)同推薦服務(wù)研究
陳蘊(yùn)博
(山東省德州市第一中學(xué),山東 德州 253023)
協(xié)同推薦技術(shù)在信息資源檢索與利用領(lǐng)域具有廣泛的應(yīng)用前景,但是,由于數(shù)據(jù)稀疏、冷啟動(dòng)等原因,導(dǎo)致現(xiàn)有的協(xié)同推薦技術(shù)個(gè)性化服務(wù)的水準(zhǔn)不高。為了提高技術(shù)服務(wù)的高效性,提出了基于用戶群、項(xiàng)目、模型多種方式的協(xié)同推薦服務(wù)的方法創(chuàng)新和技術(shù)改進(jìn),希望通過(guò)必要的技術(shù)闡釋為業(yè)界人士的研究提供參考。
協(xié)同推薦技術(shù);用戶群;技術(shù)服務(wù);信息資源
1 協(xié)同推薦服務(wù)的基本原理
協(xié)同推薦是一項(xiàng)極為重要的、被廣泛研究的、具有極高應(yīng)用價(jià)值的個(gè)性化推薦服務(wù)技術(shù)。它通過(guò)發(fā)現(xiàn)用戶與使用用戶之間、資源項(xiàng)目與受益項(xiàng)目之間存在的關(guān)系特征和關(guān)聯(lián)模式,來(lái)向使用用戶推薦具有興趣取向的、有價(jià)值的資源或項(xiàng)目。協(xié)同推薦的認(rèn)知基礎(chǔ)是:①用戶對(duì)資源的認(rèn)同是可以按照興趣分類的;②用戶對(duì)各類資源的分析評(píng)判或訪問(wèn)行為內(nèi)包含用戶的興趣和需求;③用戶對(duì)新生資源的分析評(píng)價(jià)將與其興趣相似用戶的分析評(píng)價(jià)具有一致性。這3點(diǎn)構(gòu)成了協(xié)同推薦的基礎(chǔ)。一般情況下,協(xié)同推薦體系選擇與使用用戶有相同或相似興趣的用戶群作為實(shí)施對(duì)象,為此,如何明確用戶興趣的相似性以及如何選擇使用用戶群應(yīng)是協(xié)同推薦服務(wù)技術(shù)的研究重點(diǎn)。
在一般性的協(xié)同推薦處理過(guò)程中,被推薦的資源稱為項(xiàng)目或條目。在不同的應(yīng)用領(lǐng)域,項(xiàng)目可以是文獻(xiàn)(圖書、期刊)、視頻(電影、歌曲)或者是其他某商品,用戶與項(xiàng)目相互之間的訪問(wèn)、評(píng)論、采購(gòu)和下載等行為被解釋為用戶—項(xiàng)目評(píng)價(jià)矩陣,如圖1所示。矩陣中所呈現(xiàn)的評(píng)價(jià)值可以是用戶自主判斷給出的顯性評(píng)價(jià),也可以是矩陣系統(tǒng)給出的用戶行為的隱性評(píng)價(jià)[1]。這樣,協(xié)同推薦行為被轉(zhuǎn)化為如何從用戶—項(xiàng)目評(píng)價(jià)矩陣中評(píng)議、挖掘和獲取出有價(jià)值的特征模式和項(xiàng)目用于生成使用用戶的活動(dòng)內(nèi)容推薦列表。
如圖1所示,協(xié)同推薦的機(jī)理過(guò)程由輸入評(píng)價(jià)、協(xié)同推薦算法和輸出結(jié)果3部分組成,也就是用戶輸入評(píng)價(jià)信息、協(xié)同推薦引擎運(yùn)行產(chǎn)生推薦預(yù)測(cè)評(píng)判、輸出推薦預(yù)測(cè)結(jié)果3個(gè)步驟。一般來(lái)說(shuō),協(xié)同推薦引擎對(duì)用戶來(lái)說(shuō)是一個(gè)“黑盒”處理過(guò)程,推薦結(jié)果的處理程序?qū)τ谟脩羰峭该鞯摹?/p>
獲取使用用戶的訪問(wèn)行為、用戶對(duì)資源的興趣等數(shù)據(jù),例如用戶對(duì)資源的閱覽、下載、采購(gòu)等交互行為,用戶對(duì)資源屬性或興趣程度的評(píng)價(jià)等。用戶訪問(wèn)、下載和評(píng)價(jià)資源的獲得方式是顯性的,是一個(gè)明確標(biāo)引的過(guò)程。
分析和發(fā)現(xiàn)用戶之間、項(xiàng)目之間的特征指數(shù),例如相似性和關(guān)聯(lián)度,將其視為協(xié)同推薦預(yù)測(cè)評(píng)價(jià)的基礎(chǔ)。使用用戶之間的相似程度的概率可以通過(guò)相似性計(jì)算方法或邏輯統(tǒng)計(jì)算式來(lái)預(yù)算使用用戶的若干個(gè)最近相鄰值,而發(fā)現(xiàn)用戶的關(guān)聯(lián)值則可以利用相似規(guī)則數(shù)據(jù)挖掘的方式得到[2],也可以通過(guò)使用用戶給予資源的評(píng)價(jià)而計(jì)算出發(fā)現(xiàn)用戶的相似性表達(dá)意向。根據(jù)用戶的訪問(wèn)實(shí)時(shí)過(guò)程,相應(yīng)產(chǎn)生和表現(xiàn)推薦列表。推薦列表有2種表現(xiàn)形式,即推薦和預(yù)測(cè)。推薦是提供給發(fā)現(xiàn)用戶一個(gè)具有若干項(xiàng)最感興趣的項(xiàng)目列表,也就是根據(jù)用戶的興趣愛(ài)好推薦最有可能吸引用戶的若干個(gè)項(xiàng)目,按照推薦程度的強(qiáng)烈排序。預(yù)測(cè)是依據(jù)用戶設(shè)定的一系列待評(píng)價(jià)項(xiàng)目,根據(jù)預(yù)測(cè)算法計(jì)算用戶對(duì)系列項(xiàng)目的預(yù)測(cè)評(píng)分值,并進(jìn)行預(yù)測(cè)值表現(xiàn)。

圖1 用戶—項(xiàng)目評(píng)價(jià)矩陣
協(xié)同推薦的特點(diǎn)是無(wú)需全面分析用戶的內(nèi)在屬性,對(duì)用戶無(wú)特殊的要求,能夠及時(shí)處理非結(jié)構(gòu)化的復(fù)雜對(duì)象。另外,協(xié)同推薦根據(jù)評(píng)價(jià)內(nèi)容能夠產(chǎn)生意想不到的效果,超出用戶原本預(yù)測(cè)推薦的目的。協(xié)同推薦重點(diǎn)注重群體性用戶的訪問(wèn)行為,與基于趨向內(nèi)容的推薦技術(shù)不同,它預(yù)測(cè)評(píng)價(jià)和計(jì)算處理的是群體用戶之間的訪問(wèn)行為或興趣描述,而不是單個(gè)用戶與資源的直線式交流。由于協(xié)同推薦是指,向群體性用戶來(lái)推薦資源和預(yù)測(cè)評(píng)價(jià)的,因此,它完全可以為使用用戶推薦出更為新鮮的項(xiàng)目和內(nèi)容。
從理論上講,協(xié)同推薦技術(shù)具有客觀的明確性,在實(shí)踐應(yīng)用上具有可操作性。但是,通過(guò)實(shí)際運(yùn)用,發(fā)現(xiàn)其存在一定的局限性,即為了獲得令人滿意的效果,必須建立在擁有足夠數(shù)量的用戶信息數(shù)據(jù)的基礎(chǔ)上,這是很難做到的,所以,迫使協(xié)同推薦技術(shù)在應(yīng)用上被約束、限制,例如在面向內(nèi)容的文本信息處理和信息資源開放獲取等方面還存在應(yīng)用的空白。協(xié)同推薦面臨的問(wèn)題有:①內(nèi)容量少的問(wèn)題。在一些推薦系統(tǒng)中,用戶所內(nèi)含的信息量相當(dāng)有限,即使在一些大系統(tǒng),例如Amazon網(wǎng)站中,用戶最多也就評(píng)價(jià)了一百萬(wàn)本書中的1%~2%.由于評(píng)價(jià)數(shù)據(jù)量少,尋找相似的用戶群相當(dāng)困難,導(dǎo)致推薦效果大大降低。②首先評(píng)價(jià)問(wèn)題,也稱為冷啟動(dòng)問(wèn)題,包括新項(xiàng)目問(wèn)題和新用戶問(wèn)題。如果一個(gè)新項(xiàng)目沒(méi)有被用戶所評(píng)價(jià),這個(gè)項(xiàng)目肯定不會(huì)被推薦,推薦系統(tǒng)則就失去了原有的作用。同樣,如果一個(gè)新用戶沒(méi)有評(píng)價(jià)推薦系統(tǒng)中的項(xiàng)目,則推薦系統(tǒng)不可能獲知用戶的興趣指數(shù),也就無(wú)法向用戶評(píng)價(jià)、推薦。③擴(kuò)展性問(wèn)題。目前,大部分協(xié)同推薦預(yù)測(cè)計(jì)算算法的量值隨著用戶群數(shù)和項(xiàng)目數(shù)的增加而不斷增加,對(duì)于百萬(wàn)級(jí)的數(shù)目,一般的算法遭遇到擴(kuò)展性的問(wèn)題。對(duì)于上述前2個(gè)問(wèn)題,較為妥善的解決方案是,將協(xié)同推薦和基于趨向內(nèi)容的興趣資源推薦結(jié)合應(yīng)用于推薦系統(tǒng)中。對(duì)于第3個(gè)問(wèn)題,由于大多數(shù)預(yù)測(cè)算法可以離線實(shí)施后臺(tái)計(jì)算,隨著計(jì)算機(jī)運(yùn)算能力的提高和運(yùn)算方法的改進(jìn),可擴(kuò)展性問(wèn)題并非是特別嚴(yán)重的問(wèn)題。
2 基于用戶群的協(xié)同推薦服務(wù)
基于用戶群的協(xié)同推薦,其核心思想是假如用戶之間的檢索行為具有一定程度上的相似性,即為相似行為的用戶群,會(huì)實(shí)施相同或相似的選擇。系統(tǒng)研究、分析用戶對(duì)項(xiàng)目的興趣評(píng)價(jià),得出用戶群之間的相似性,從而進(jìn)一步進(jìn)行預(yù)測(cè)、推薦。基于用戶群的協(xié)同推薦使用統(tǒng)計(jì)的方法來(lái)查詢和落實(shí)用戶相近的鄰居,如果用戶的相鄰鄰居被找到,系統(tǒng)會(huì)運(yùn)用不同的算法綜合分析這些相似的評(píng)價(jià),并依此為使用用戶提供預(yù)測(cè)或?qū)θ舾蓚€(gè)評(píng)價(jià)項(xiàng)目進(jìn)行推薦[3]。這種算法簡(jiǎn)捷明了,精確度相對(duì)比較高,目前,實(shí)際使用的協(xié)同推薦算法方式大多屬于這種類型,如圖2所示。

圖2 基于用戶群的協(xié)同推薦流程
對(duì)于給定的用戶—項(xiàng)目評(píng)價(jià)矩陣,典型的基于用戶群的協(xié)同推薦可以分為3個(gè)部分:①計(jì)算發(fā)現(xiàn)用戶與使用用戶之間的相似程度。當(dāng)用戶被指定推薦時(shí),他們往往信任與他們有相似興趣的用戶。為此,要先得出發(fā)現(xiàn)用戶與使用用戶之間的相似度。②實(shí)施最相鄰查詢。依據(jù)發(fā)現(xiàn)用戶與使用用戶之間的相似度和所匹配的項(xiàng)目,明確發(fā)現(xiàn)用戶的最近相鄰用戶群集合。③計(jì)算預(yù)測(cè)數(shù)值。將相鄰用戶的測(cè)評(píng)分值進(jìn)行加權(quán),作為使用用戶的評(píng)分值。這樣做的目的是為需要推薦服務(wù)的使用用戶找尋具有相似度的最近鄰居集合,即通過(guò)一個(gè)發(fā)現(xiàn)用戶A,產(chǎn)生按照相似度大小排列的鄰居集合N={N1,N2,…,Ni},A≠N,從N1到Ni,用戶之間的相似度sim(A,Ni)從大到小排列。圖3顯示了協(xié)同推薦服務(wù)中用戶鄰居的形成過(guò)程:當(dāng)計(jì)算發(fā)現(xiàn)用戶A與使用用戶之間的相似性時(shí),圖中以A為中心的K=5個(gè)最相鄰用戶被確定為鄰居。在得到發(fā)現(xiàn)用戶與各個(gè)使用用戶之間的相似性數(shù)值以后,要確定應(yīng)該選取多少個(gè)使用用戶作為該發(fā)現(xiàn)用戶的鄰居來(lái)計(jì)算最終的預(yù)測(cè)值。一般情況下,有2種方法選取鄰居數(shù)目:①提前設(shè)定一個(gè)相似性閾值,只有那些與發(fā)現(xiàn)用戶之間相似值超過(guò)閾值的使用用戶才能被視為鄰居。在這種方法中,閾值高,則說(shuō)明發(fā)現(xiàn)用戶與鄰居具有較好的相似性,但是滿足條件的鄰居數(shù)量會(huì)減少,導(dǎo)致很多預(yù)測(cè)不會(huì)產(chǎn)生;如果閾值過(guò)低,則超過(guò)閾值的鄰居數(shù)目會(huì)增多,閾值的作用沒(méi)有體現(xiàn)出來(lái)。②選擇K個(gè)相似性較大的使用用戶作為鄰居,如果K值過(guò)大,那么,相似性小的鄰居會(huì)影響到最終的預(yù)測(cè)結(jié)果;反之,如果K值過(guò)小,那么,一些使用用戶的要求沒(méi)有被考慮進(jìn)去。
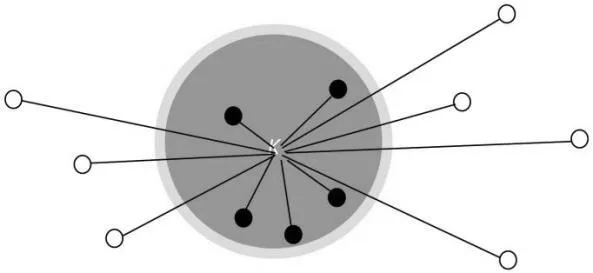
圖3 用戶“鄰居”的形成過(guò)程
發(fā)現(xiàn)用戶的最新鄰居集合形成之后,可以依據(jù)若干個(gè)符合閾值要求的鄰居集合對(duì)項(xiàng)目的評(píng)分來(lái)預(yù)測(cè)使用用戶對(duì)各個(gè)項(xiàng)目的感興趣程度。使用的預(yù)測(cè)公式為:

式(1)中:Wa,u為發(fā)現(xiàn)用戶a與相鄰的使用用戶u的相似度;Ru為鄰居u的平均評(píng)分值;k為一個(gè)規(guī)范化系數(shù)。
為了獲得最相鄰用戶對(duì)項(xiàng)目的評(píng)分,需要運(yùn)算發(fā)現(xiàn)用戶與使用用戶之間的相似度。運(yùn)算用戶之間相似度的方法主要有3種,即余弦相似性、相關(guān)相似性、修正的余弦相似性。在余弦相似性運(yùn)算中,可以將用戶對(duì)項(xiàng)目的評(píng)分視為n維項(xiàng)目立體空間上的向量,如果用戶沒(méi)有給項(xiàng)目評(píng)分,則評(píng)分值設(shè)為0.用戶之間的相似性通過(guò)向量之間的余弦?jiàn)A角度量。設(shè)定用戶i、用戶j在n維項(xiàng)目空間上的評(píng)分值分別表示為向量,那么,用戶i與用戶j之間的相似度sim(i,j)為:
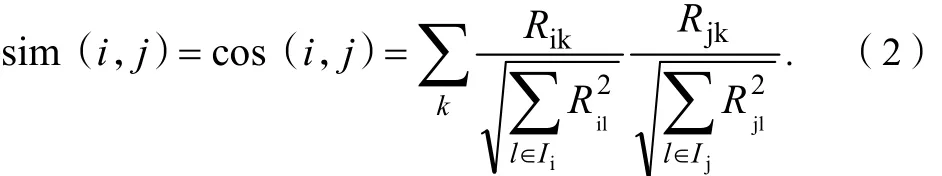
式(2)中,分母用于平衡化,促使預(yù)測(cè)評(píng)分較多的用戶在運(yùn)算中保持與其他用戶之間的平衡。在余弦相似性計(jì)算中,將用戶沒(méi)有給項(xiàng)目評(píng)分的分值定為0,這樣能夠提高運(yùn)算效能,但是,在項(xiàng)目數(shù)量特別多且用戶評(píng)價(jià)數(shù)據(jù)少的情況下,這樣做會(huì)導(dǎo)致推薦程度的可信度降低。
設(shè)定用戶i和用戶j一同評(píng)價(jià)過(guò)的項(xiàng)目集合用Iij來(lái)表示,這樣用戶i與用戶j之間的相似性sim(i,j)可以通過(guò)Pearson系數(shù)wi,j來(lái)衡量。Pearson系數(shù)用來(lái)衡量變量之間的平衡關(guān)系。用戶i與用戶j之間的相似性sim(i,j)為:
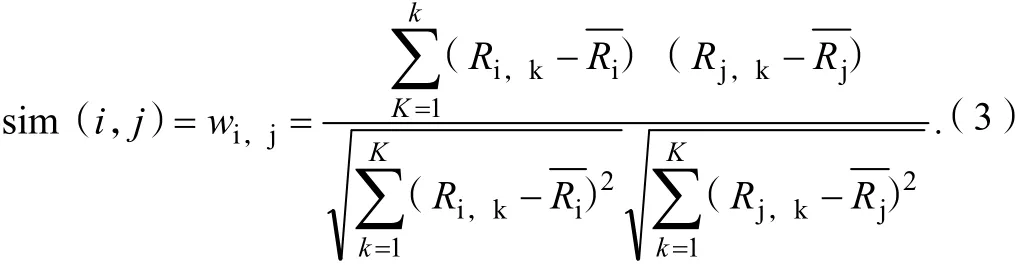
式(3)中:Ri,k和Rj,k分別為用戶i和用戶j對(duì)項(xiàng)目k的評(píng)分值;Ri和Rj分別為用戶和用戶在各自所有測(cè)評(píng)項(xiàng)目上的評(píng)分的平均值;K為用戶i和用戶j重合的項(xiàng)目數(shù)。
由于Pearson系數(shù)是從線性運(yùn)算模型產(chǎn)生的,所以,它需要在滿足一定的條件下才能使用,即預(yù)測(cè)評(píng)價(jià)值之間的關(guān)系是線性的,殘差之間必須相互獨(dú)立。
在余弦相似性計(jì)算中,沒(méi)有考慮用戶之間的測(cè)評(píng)尺度問(wèn)題,例如用戶甲給其最感興趣的項(xiàng)目評(píng)分是4,而不是5,給印象最差的項(xiàng)目評(píng)分是1而不是2;用戶乙給其最感興趣的項(xiàng)目評(píng)分是5,印象最差項(xiàng)目評(píng)分是2.如果采取余弦相似性方法運(yùn)算,2個(gè)用戶的評(píng)價(jià)差異很大。修正的余弦相似性計(jì)算方法是通過(guò)減去用戶對(duì)項(xiàng)目的平均評(píng)分值來(lái)改善以上缺陷的。設(shè)定用戶i和用戶j一同評(píng)議過(guò)的項(xiàng)目集合為Iij,Ii和Ij分別表示用戶i和用戶j評(píng)議過(guò)的項(xiàng)目集合,則用戶i與用戶j之間的相似性sim(i,j)為:
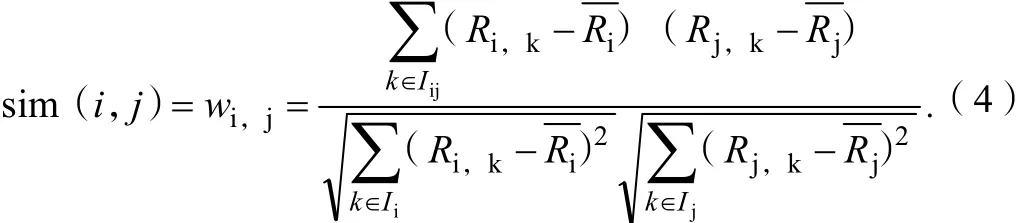
3 基于項(xiàng)目的協(xié)同推薦服務(wù)
基于項(xiàng)目的協(xié)同推薦服務(wù),其基本點(diǎn)是項(xiàng)目之間有某種程度的關(guān)聯(lián)性或相似性。通過(guò)用戶對(duì)項(xiàng)目的評(píng)價(jià)分析,得出項(xiàng)目之間的相似性,或者發(fā)現(xiàn)項(xiàng)目之間的關(guān)聯(lián)性,從而進(jìn)行合理的推薦。項(xiàng)目之間的關(guān)聯(lián)性分析歸為基于關(guān)聯(lián)挖掘的方法進(jìn)行處理,本文將在基于模型的協(xié)同推薦技術(shù)中進(jìn)行討論。基于項(xiàng)目的協(xié)同推薦的處理方法是先依據(jù)用戶—項(xiàng)目矩陣求出項(xiàng)目之間存在的關(guān)系,然后依據(jù)這些關(guān)系推出推薦給用戶的結(jié)果,推薦給用戶的結(jié)果通常是通過(guò)發(fā)現(xiàn)用戶感興趣的項(xiàng)目來(lái)完成的。與基于用戶群的協(xié)同推薦技術(shù)一樣,基于項(xiàng)目的協(xié)同推薦技術(shù)的關(guān)鍵是計(jì)算項(xiàng)目之間的相似度,從而選擇相似的項(xiàng)目,如圖4所示。計(jì)算項(xiàng)目i與項(xiàng)目j之間相似度的出發(fā)點(diǎn)是,先分離對(duì)項(xiàng)目進(jìn)行過(guò)評(píng)價(jià)的用戶群,然后通過(guò)相似度計(jì)算技術(shù)運(yùn)算出項(xiàng)目之間的相似度。項(xiàng)目之間的相似度計(jì)算公式如前所述,主要有余弦相似性、相關(guān)相似性和修正的余弦相似性。

圖4 基于用戶評(píng)價(jià)的項(xiàng)目相似度處理示意圖
通過(guò)相似度的計(jì)算方式明確了那些最相似的項(xiàng)目之后,接著就是根據(jù)發(fā)現(xiàn)用戶的評(píng)價(jià)進(jìn)行項(xiàng)目預(yù)測(cè)計(jì)算分值。Sarwar提出了2種預(yù)測(cè)計(jì)算方法,即加權(quán)和方法、回歸方法。加權(quán)和方法是通過(guò)用戶u對(duì)與項(xiàng)目i具有相似性的項(xiàng)目的評(píng)價(jià)之和來(lái)計(jì)算用戶u對(duì)項(xiàng)目i的預(yù)期。每一個(gè)評(píng)價(jià)結(jié)果Ri均運(yùn)用項(xiàng)目i與項(xiàng)目j之間的相似度來(lái)進(jìn)行加權(quán)。這種預(yù)測(cè)值Pu,i可表示為:

回歸方法與加權(quán)和方法相似,不過(guò)回歸方法不是直接利用項(xiàng)目相似性的評(píng)價(jià),而是根據(jù)回歸模型利用評(píng)價(jià)的近似值。在實(shí)際情況中,2個(gè)評(píng)價(jià)向量可能是歐幾里德距離,相離比較遠(yuǎn),兩者之間的相似度比較高。在這種情況下,使用余弦函數(shù)或系數(shù)方式計(jì)算的相似度會(huì)產(chǎn)生一定的誤導(dǎo)。這樣使用所謂的相似項(xiàng)目的原始評(píng)價(jià)會(huì)導(dǎo)致較大差錯(cuò)的預(yù)測(cè)。回歸的根本點(diǎn)還是運(yùn)用與加權(quán)和方法相同的公式,但是,這種方法不使用相似項(xiàng)目N的原始評(píng)價(jià)值Ru,n,而是依據(jù)線性回歸模型使用它們的近似值R’u,n.用Ri和Rn來(lái)表示發(fā)現(xiàn)項(xiàng)目i向量和使用項(xiàng)目n向量,則線性回歸方法可以表示為:

式(6)中:參數(shù)α和β是由2個(gè)評(píng)價(jià)向量同時(shí)決定的;ε為回歸方法的計(jì)算誤差。
以上討論的基于項(xiàng)目的協(xié)同推薦的指導(dǎo)思想是,根據(jù)用戶—項(xiàng)目評(píng)分來(lái)尋找和衡量與某一項(xiàng)目相似的項(xiàng)目集合。實(shí)際上,基于項(xiàng)目的協(xié)同推薦完全可以從項(xiàng)目之間被訪問(wèn)的關(guān)聯(lián)程度大小出發(fā)來(lái)尋找具有最大相關(guān)程度的項(xiàng)目集合。在這種情況下,就可以使用數(shù)據(jù)挖掘技術(shù)中的關(guān)聯(lián)規(guī)則來(lái)探尋項(xiàng)目之間的關(guān)聯(lián)性。
4 基于模型的協(xié)同推薦服務(wù)
基于模型的協(xié)同推薦服務(wù)方法,是將用戶的示例記錄、項(xiàng)目的屬性分析等,運(yùn)用統(tǒng)計(jì)方法或機(jī)器學(xué)習(xí)方法挖掘數(shù)據(jù),進(jìn)而建立與用戶群或項(xiàng)目集合相關(guān)的特征模型,從而利用模型來(lái)生產(chǎn)推薦。基于模型的協(xié)同推薦大多采用離線預(yù)處理的方式進(jìn)行運(yùn)算,這樣可以加快推薦反饋的時(shí)間。當(dāng)前,運(yùn)用于協(xié)同推薦中模型建立的方法很多,主要有聚類方法、貝葉斯網(wǎng)絡(luò)方法和關(guān)聯(lián)規(guī)則方法等。
4.1 聚類方法
聚類方法是將具有相似興趣的用戶聚類成組,進(jìn)行聚類分析后,對(duì)當(dāng)前用戶的推薦可以通過(guò)與當(dāng)前用戶同類的其他用戶的選擇或觀點(diǎn)進(jìn)行平均化處理來(lái)實(shí)現(xiàn)。聚類方法推薦結(jié)果的個(gè)性化稍差一些,但是,聚類一旦形成,最終的結(jié)果會(huì)很好,這是因?yàn)榇藭r(shí)要分析的組數(shù)要少得多[4]。聚類方法可以被當(dāng)作最近鄰法中的第一步來(lái)縮小候選集。雖然將整體分為多個(gè)類會(huì)影響精確度或推薦結(jié)果,但聚類法是可以在精確度與推薦效率之間權(quán)衡的。由于聚類操作可以在離線狀態(tài)下進(jìn)行,所以,在線的推薦算法產(chǎn)生的推薦效率還是比較高的。Q.L.Li等運(yùn)用基于項(xiàng)目的最鄰近方法,使用K-means算法將項(xiàng)目聚類,選擇發(fā)現(xiàn)用戶已打分并且與發(fā)現(xiàn)用戶在同一聚類的項(xiàng)目,將用戶鄰居限制在與目標(biāo)項(xiàng)目同一聚類的項(xiàng)目中,分別計(jì)算項(xiàng)目之間的相似度,依據(jù)最近相鄰法求出使用用戶對(duì)項(xiàng)目的評(píng)分預(yù)測(cè)值。Rectree與這種方法相類似,它是基于用戶的方法,先把用戶群進(jìn)行聚類,擇取同一聚類的用戶群作為聚類鄰居,再進(jìn)一步從聚類中明確某一用戶的鄰居。Ungar等提出了將用戶、項(xiàng)目分別聚類的計(jì)算方法,通過(guò)數(shù)據(jù)樣本來(lái)訓(xùn)練模型。
4.2 貝葉斯網(wǎng)絡(luò)方法
根據(jù)概率論原理,協(xié)同推薦是讓人們對(duì)一個(gè)用戶有明確的認(rèn)識(shí),用來(lái)運(yùn)算預(yù)測(cè)評(píng)分的期望值。假定預(yù)測(cè)評(píng)分是從0到m的整數(shù)值,則概率表達(dá)式為:
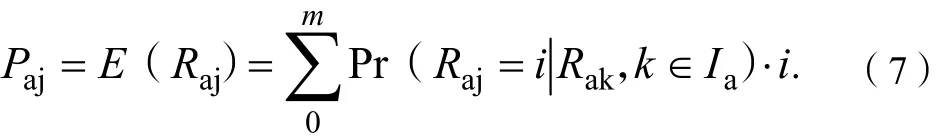
其中,概率表達(dá)式為確定的用戶對(duì)一些項(xiàng)目的評(píng)分,根據(jù)式(7)計(jì)算出該用戶對(duì)項(xiàng)目j評(píng)分為l的概率值。貝葉斯網(wǎng)絡(luò)技術(shù)方法利用訓(xùn)練集構(gòu)建相應(yīng)的模型,模型可以通過(guò)離線運(yùn)行得到,通過(guò)訓(xùn)練集得到的模型比較小,預(yù)測(cè)評(píng)分結(jié)果的精確度可以與最相鄰方法媲美,因此,對(duì)模型的應(yīng)用很快。貝葉斯網(wǎng)絡(luò)方法比較適用于用戶的興趣變化較慢的情況。
Pennock等人在協(xié)同推薦過(guò)程中將一個(gè)用戶看作一個(gè)聚類,n個(gè)用戶就有n個(gè)聚類,依據(jù)用戶給一些項(xiàng)目的評(píng)分,通過(guò)貝葉斯概率表達(dá)公式計(jì)算出一個(gè)用戶屬于n個(gè)聚類的概率,即該用戶與其他用戶屬于相同個(gè)性類型的概率,然后求出該用戶最感興趣的項(xiàng)目的概率。這種方法既保持了傳統(tǒng)的相似性計(jì)量方法的優(yōu)點(diǎn),又涵蓋有概率意義,完全可以向用戶解釋推薦的結(jié)果。
4.3 關(guān)聯(lián)規(guī)則方法
此方法在零售業(yè)被廣泛應(yīng)用,通過(guò)關(guān)聯(lián)規(guī)則挖掘可以發(fā)現(xiàn)不同類別商品在銷售過(guò)程中的相關(guān)性,并在個(gè)性化的協(xié)同推薦服務(wù)中得到應(yīng)用和研究。用于協(xié)同推薦服務(wù)的關(guān)聯(lián)規(guī)則方法最早是由Fu Budizk和Hammond提出的,他們?cè)趥€(gè)性化Web網(wǎng)站應(yīng)用研究中,運(yùn)用Apriori算法通過(guò)挖掘用戶瀏覽歷史記錄的關(guān)聯(lián)性來(lái)推薦。算法先從聚集樹發(fā)現(xiàn)匹配用戶當(dāng)前訪問(wèn)操作路徑的關(guān)聯(lián)規(guī)則,然后再根據(jù)推薦因子的大小確定推薦項(xiàng),推薦因子定義為關(guān)聯(lián)規(guī)則的置信度乘以距離因子。由于關(guān)聯(lián)規(guī)則模型的生成可以離線進(jìn)行,因此,可以保證推薦系統(tǒng)的實(shí)時(shí)性。Lin等對(duì)普通的關(guān)聯(lián)規(guī)則挖掘方法進(jìn)行擴(kuò)展后將其運(yùn)用于協(xié)同推薦中。在他們的算法中,關(guān)聯(lián)規(guī)則的置信度定義為用戶或者項(xiàng)目之間的相關(guān)系數(shù),支持度則定義為該相關(guān)系數(shù)的顯著性。關(guān)聯(lián)規(guī)則可以與用戶相關(guān),也可以與項(xiàng)目相關(guān)。與用戶相關(guān)的關(guān)聯(lián)規(guī)則可以表示為:80%的用戶A和用戶B都感興趣的項(xiàng)目會(huì)被使用用戶所喜歡,25%的所有項(xiàng)目會(huì)被這3個(gè)用戶同時(shí)感興趣。具體表示公式為:{用戶A感興趣}AND{用戶B感興趣}=>{使用用戶感興趣}(C=80%,S=25%).
為每條關(guān)聯(lián)規(guī)則給定一個(gè)分?jǐn)?shù),該分?jǐn)?shù)為此規(guī)則的置信度與支持度的乘積。對(duì)于每一個(gè)項(xiàng)目,與此項(xiàng)目關(guān)聯(lián)的分?jǐn)?shù)為此項(xiàng)目相關(guān)的所有滿足最小支持度和置信度的關(guān)聯(lián)規(guī)則的分?jǐn)?shù)之和。如果與項(xiàng)目關(guān)聯(lián)的分?jǐn)?shù)大于設(shè)定的閾值,則將此項(xiàng)目推薦給使用用戶。與項(xiàng)目相關(guān)的關(guān)聯(lián)規(guī)則可以表示為:80%同時(shí)感興趣項(xiàng)目1和項(xiàng)目2的用戶會(huì)感興趣目標(biāo)項(xiàng)目,25%的用戶會(huì)同時(shí)對(duì)3個(gè)項(xiàng)目感興趣,具體表示公式為:{感興趣項(xiàng)目1}AND{感興趣項(xiàng)目2}=>{感興趣目標(biāo)用戶}(C=80%,S=25%).如果得到的關(guān)聯(lián)規(guī)則的支持度大于自動(dòng)調(diào)整的閾值,則將該目標(biāo)項(xiàng)目推薦給使用用戶。
Mobasher等將Web使用挖掘應(yīng)用于協(xié)同推薦,從用戶的訪問(wèn)數(shù)據(jù)中發(fā)現(xiàn)有用的模式,例如關(guān)聯(lián)規(guī)則、序列模式、用戶會(huì)話聚類等,然后從這些模式中挖掘出高質(zhì)量的、有用的“總體使用概貌”。比如,提出通過(guò)對(duì)服務(wù)器日志進(jìn)行事物聚類和關(guān)聯(lián)規(guī)則超圖分割聚類獲取用戶的共同瀏覽特征,再掃描所有的數(shù)據(jù)集,產(chǎn)生個(gè)性化的推薦。O’Sullivan等將協(xié)同過(guò)濾技術(shù)與基于推理的方法相結(jié)合,用于提高PTV(推薦電視節(jié)目的在線系統(tǒng))的性能,通過(guò)關(guān)聯(lián)規(guī)則挖掘方法抽取項(xiàng)目之間的關(guān)系,將得到的關(guān)聯(lián)規(guī)則的置信度作為項(xiàng)目之間的相似度,從而得到一個(gè)相似度矩陣,然后利用得到的相似度矩陣來(lái)計(jì)算用戶之間的相似度,這樣會(huì)減少系統(tǒng)的稀疏性。
[1]李聰,梁昌勇.基于屬性值偏好矩陣的協(xié)同過(guò)濾推薦算法[J].情報(bào)學(xué)報(bào),2009,27(6):884-890.
[2]Zhang M L,Zhou Z H.Multi-instance Clustering with Applications to Multi-instance Prediction[J].Applied Intelligence,2009,31(1):47-48.
[3]李春,朱珍民.基于鄰居決策的協(xié)同過(guò)濾推薦算法[J].計(jì)算機(jī)工程,2010,36(13):34-36.
[4]鄭丹,王潛平.K-means初始聚類中心的選擇算法[J].計(jì)算機(jī)應(yīng)用,2012,32(8):2186-2188.
TP18
A
10.15913/j.cnki.kjycx.2018.01.019
2095-6835(2018)01-0019-05
〔編輯:白潔〕
猜你喜歡
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
石油瀝青(2021年4期)2021-10-14 08:50:44
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國(guó)教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
俄羅斯問(wèn)題研究(2012年1期)2012-03-25 09:54:51
