基于v-SVRM模型的起重機載荷譜預測軟件編制及應用
2018-12-20 06:28:12李東亞江星星張曉萍
現代制造技術與裝備 2018年11期
關鍵詞:模型
王 爽 李東亞 江星星 張曉萍
(1.蘇州大學應用技術學院,蘇州 215325;2.蘇州大學軌道交通學院,蘇州 215131)
模擬真實使用情況并繪制載荷譜,是起重機可靠性計算的關鍵。目前,起重機載荷譜精度要求不斷提升,載荷譜繪制的方法由最早的現場測試記錄法升級到計算機仿真模擬法,隨著計算機技術的發展,智能算法也被應用到載荷譜繪制工作中,如最小二乘法、神經網絡法、支持向量回歸機(Support Vector Regression Machine,SVRM)在起重機載荷譜繪制中都有比較廣泛的應用。相比較而言,利用支持向量回歸機法對起重機載荷譜進行預測精度最高,為了使SVRM模型更符合橋式起重機工作特性,太原科技大學的陸鳳儀、王爽、徐格寧提出了利用核函數重構技術以及決策函數技術對原有模型進行的思路,并成功建立了改進后的v-SVRM模型,同時結合模型參數特點,對果蠅算法進行改進,實現模型三類參數同時尋優采用反約束思維,進行參數二次優化,提升參數選擇的穩健性。
在利用支持向量回歸機方法進行載荷譜繪制時,模型建立、參數選擇、數據訓練以及數據計算復雜度都較高。考慮到起重機械行業壽命預測和安全監測要求越來越高,本文運用v-SVRM模型編制起重機載荷譜獲取軟件,該軟件可供完全不具備支持向量回歸機和起重機相關知識的工作人員使用,獲取起重機載荷譜輕松方便。同時該方法可為起重機壽命預測提供更加可靠的數據支持,從而降低起重機械發生事故的概率。
1 軟件編制的理論模型
支持向量回歸機種類有很多種,本文所提到v-SVRM是在已知的數據樣本集上找到一個函數,然后把輸入值近似映射到真實值上,v-SVRM模型建立步驟如下。
1.1 訓練樣本集的確定
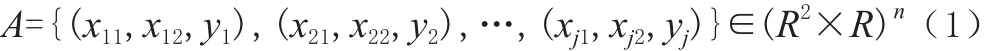
式中,A為數據樣本集;xj1、xj2∈R2,為輸入變量;yj∈R,為輸出值;j為數據樣本總量,j=1,2,3,...。
1.2 選定合適的參數
v-SVRM模型共有三類參數:容錯參數(C、v)、核參數(d、σ)、權參數(ρ1、ρ2),利用改進后的果蠅算法同步搜索三類參數,并在此基礎上,運用果蠅算法與懲罰函數法再次精選參數。
1.3 確定混合核函數
鑒于起重機所受載荷具有高度隨機性及不穩定性的特點,選擇的核函數K(x,x′)至關重要。太原科技大學構造出符合起重機載荷譜特性的混合核函數,如式(2)所示。

式中,ρ1、ρ2為權參數;K1、K2分別為多項式核函數和高斯核函數,如式(3)、式(4)所示。
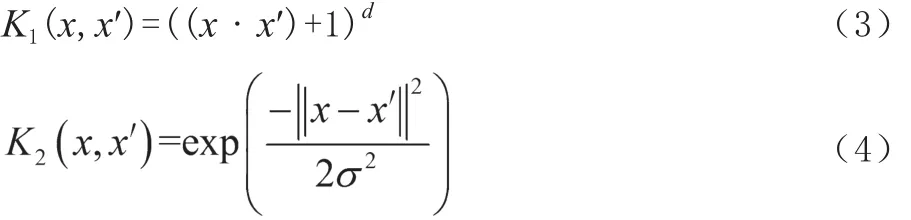
1.4 建立決策函數
結合起重機間歇動作、循環作業的工作特點,太原科技大學建立改進后的決策函數,如式(5)、式(6)所示

式中:k1、k2為工況特征因子,如式(7)、式(8)所示。

式中,Kp為起重機載荷譜系數。
2 基于v-SVRM模型的起重機載荷譜預測軟件開發
v-SVRM無論是模型的建立、參數選擇以及數據計算,復雜度都比較高,為了解決這一問題,相關研究人員以Visual C++6.0為開發工具,基于v-SVRM模型,設計了一種起重機載荷譜獲取軟件,該軟件的內部機理是利用支持向量機的非線性回歸理論,通過核函數重構和決策函數改進,對原有v-SVRM預測模型進行優化。
2.1 軟件功能
本軟件設計共有八個重要模塊,分別為原始數據的選擇、數據處理、數據訓練、參數初選、參數精選、樣本測試、載荷預測和控制面版,可實現以下多種功能:
優化研究對象,本軟件主要以橋式起重機為研究對象,在“系統默認典型數據”及“用戶自定義數據”中,分為通用橋式起重機和鑄造起重機兩類數據。該軟件在數據處理過程中,首先測試數據樣本的平穩性,隨后去除數據樣本中對是數據總體分布沒有影響的無效幅值,最后利用概率推斷法或者曲線板外推法求解最大載荷。
實現數據歸一化,為了降低樣本向量內積給算法帶來的巨大運算量,該軟件在用戶輸入數據后,自動進行歸一化處理,使數據轉化在(-1,1)范圍內,所選用的處理公式如式(9)所示。

實現樣本分類及樣本訓練功能,該軟件自動調用歷史數據庫中的167個樣本數據,隨機選擇其中的119個樣本作為訓練數據,余下48個樣本作為測試數據。并且通過改進的v-SVRM預測模型對樣本進行回歸訓練,建立橋式起重機實際起重量與工作循環次數之間的映射關系。
完成參數初選與精選工作。通過“參數獲取”按鈕,初選v-SVRM模型的三類參數。在參數初選的基礎上,通過“數據再次訓練”、“參數再次選取”按鈕,進行參數二次優化。
進行樣本測試及結果預測,該軟件利用“測試結果顯示”功能,獲取部分起重量所對應的工作循環次數,以及與實際記錄數據相比的誤差。然后通過“預測結果顯示”功能,顯示不同類型、不同額定起重量的起重機載荷譜的最終結果。
為了更貼近生產實際的需要,除了系統默認典型數據外,該軟件還允許用戶自行輸入待訓練數據,彌補了原始數據不足的問題,增強了軟件的適應能力。
2.2 軟件使用流程及主要界面
該軟件可針對不同類型、不同額定起重量的橋式起重機,實現載荷譜的建立、訓練、追加、獲取和預測機制功能。軟件使用流程及主要界面,如圖1、圖2所示。
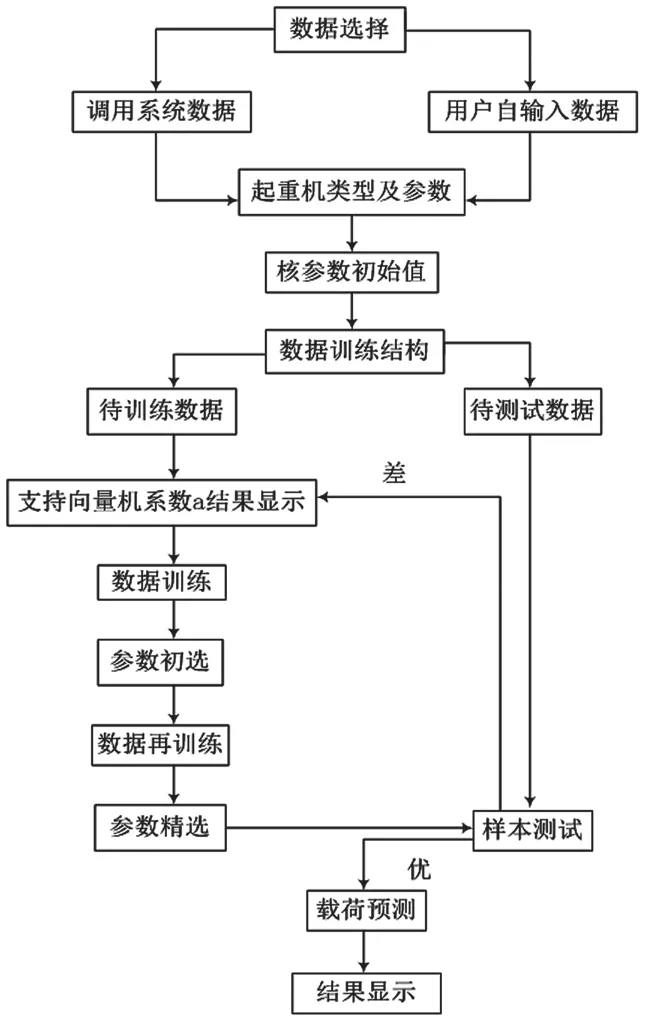
圖1 系統結構流程

圖2 軟件主界面
3 工程實例
3.1 數據選擇與預測結果
為了驗證基于v-SVRM模型的起重機載荷譜預測軟件預測精度,以某鑄造橋式起重機的實際記錄數據作為訓練數據集和測試數據集,利用起重機載荷譜預測軟件進行預測。實測內容為在規定時間內,橋式起重機在不同額定起重量(100t、160t及200t)下所構成的訓練數據樣本集和測試數據集。為了方便分析比對,在同樣的數據基礎上,運用BP神經網絡法對起重機載荷譜進行計算與測試。預測結果如表1至表3所示。
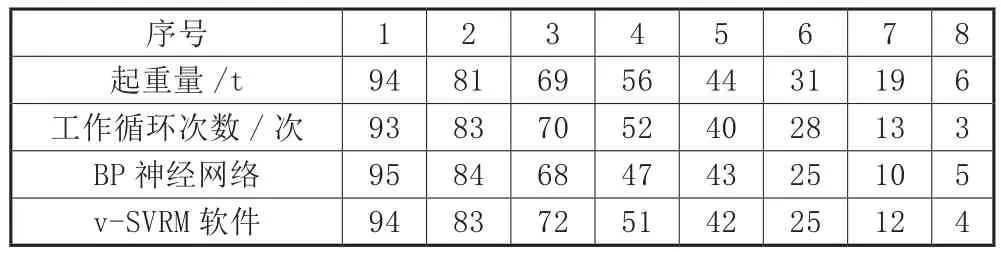
表1 100t鑄造橋式起重機典型數據
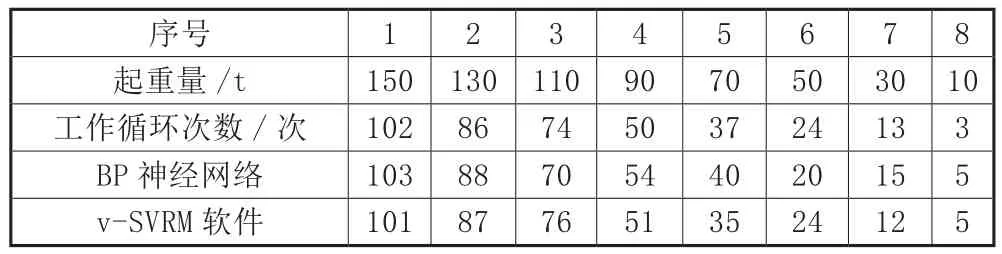
表2 160t鑄造橋式起重機典型數據
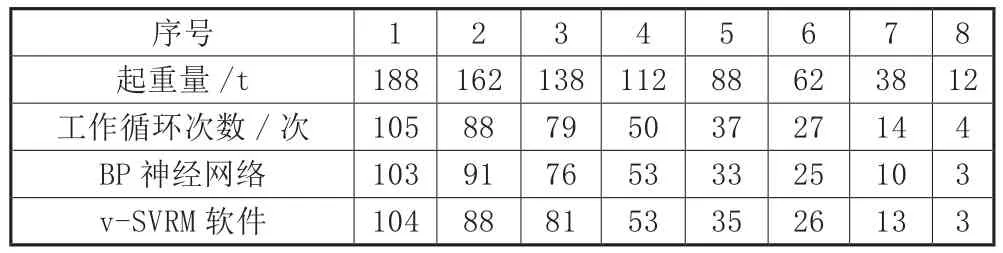
表3 200t鑄造橋式起重機典型數據
另外,為了更加直觀的反應BP神經網絡法與起重機載荷譜預測軟件在精度和穩定性上的區別,將兩種算法的預測結果以及實測數據用折線圖的方式表現出來,如圖3~圖5所示。
3.2 預測結果分析
預測結果的相對誤差和擬合度計算公式,如式(10)~式(12)所示。
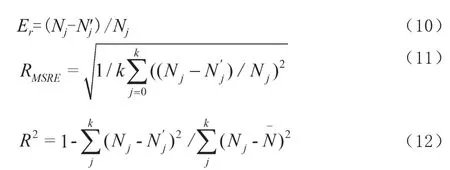
式中,k表示數據容量;Nj表示實際工作循環次數;表示實際工作循環次數均值;N′j表示預測工作循環次數。
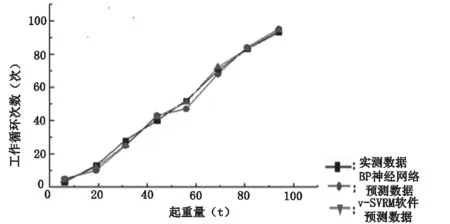
圖3 額定起重量100噸預測結果對比
預測結果顯示,Er、RMSRE越接近0,預測準確度越高;另外,R2越接近1,預測精度越高。預測結果分析如表4~表6所示。

表5 額定起重量160t預測誤差分析
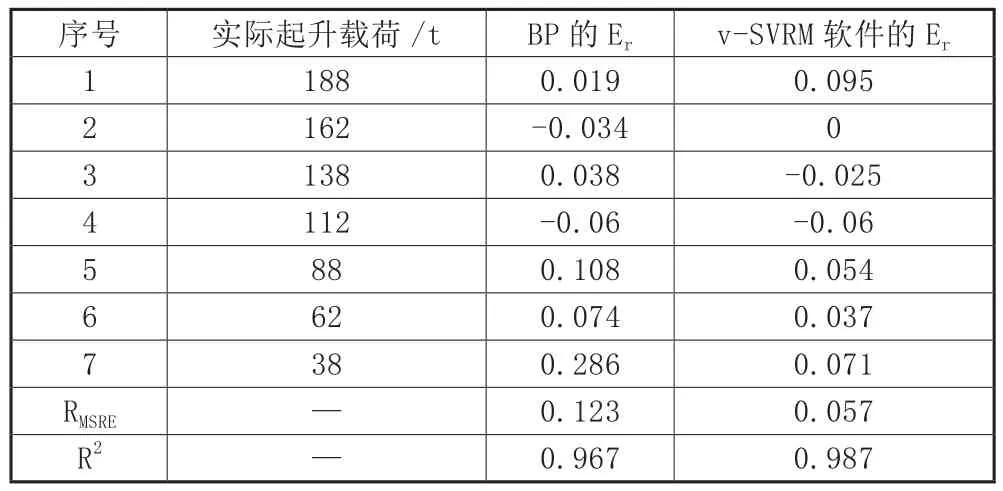
表6 額定起重量200噸預測誤差分析
通過表4至表6分析,大部分BP神經網絡模型的相對誤差絕對值比基于載荷譜預測軟件大。由RMSRE可知,預測軟件的RMSRE均小于6%,比BP神經網絡模型至少降低了4%,預測精度大幅度提高。再觀察R2,預測軟件中,0.98<R2<1;BP神經網絡中,0.96<R2<0.96,表明載荷譜預測軟件的擬合精度高而且穩定性好。
另外,通過圖3至圖5,可以發現兩種預測方法的折線圖的大致趨勢是一樣的,BP神經網絡折線振動幅度較大,誤差較大,穩健性差;基于v-SVRM預測軟件折線與實測折線的擬合度最高,預測精度的穩健性好。因此,從數理統計分析和圖線比較兩個方面,基于v-SVRM預測軟件獲取的起重機載荷譜都是最接近實際情況的。
4 結論
利用Visual C++6.0平臺,改進了v-SVRM預測模型程序,并將改進的果蠅算法和懲罰函數法應用到v-SVRM模型參數選擇過程中,快速完成橋式起重機載荷譜建立、訓練、追加、獲取及預測的軟件編制。該軟件可快速高效地獲取起重機載荷譜,有效地節省了現場實測工作帶來的人力、物力消耗,具有投資少、省人力、操作簡單的特點。
另外通過工程實例分析表明,BP神經網絡存在收斂時間較長、穩健性不高等問題,而基于v-SVRM的載荷譜預測軟件因其運算方便、訓練時間短、預測精度高、實用性和穩健性好等特點,為起重機載荷譜實現高精度預測目標,提供了一種新的工作思路與方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
