基于深度神經網絡的圖像碎片化信息問答算法
2018-12-20 01:12:04王一蕾卓一帆吳英杰陳銘欽
計算機研究與發展 2018年12期
王一蕾 卓一帆 吳英杰 陳銘欽
(福州大學數學與計算機科學學院 福州 350108)
近年來,隨著智能設備的飛速發展和大數據時代的到來,信息傳播的媒介已經從過去的文字拓展到了圖像、視頻、音頻等形式,與此同時,人們所能獲取到的信息量呈爆炸式增長,信息的內容也逐步趨向分散,知識的體系越來越碎片化,以文本、圖像、視頻、網頁等不同模態高度分散在多個數據源中.碎片化知識對人類社會的發展存在著兩面性,一方面有助于人們快速了解相關領域知識的概貌;另一方面碎片化知識往往存在著片面性與非完整性,會對接受信息者的思考與判斷產生一定影響,并且潛移默化地影響他們的知識體系結構.若能有效地將大量碎片化的知識去粗取精,提取出關鍵有效的信息,并構建出完備的知識體系結構,將有助于提升人們的學習效率.這已成為人工智能中知識密集型應用的新興問題.
隨著深度學習在各個領域取得不斷的突破,如何利用計算機視覺和自然語言處理領域相關知識實現對不同模態的碎片化信息的融合與理解成為了一個重要的研究趨勢.因此,近年來許多研究通過構建視覺問答系統(visual question answering, VQA),以實現對多模態碎片化信息的提取、表達和理解.視覺問答任務以一張圖片和一個與圖片相關的問題作為輸入,以推理相應的答案作為輸出.該任務針對給定圖像的內容回答與圖像相關的問題,不僅涉及更多的知識和推理技巧,還需要對人工智能不同領域的知識進行融合,因此成為當前人工智能領域一個十分熱門的研究課題.
本文擬在現有關于視覺問答任務的前沿研究背景下,進一步研究結合變分推斷方法與注意力機制的視覺問答算法并實現完整的視覺問答系統框架.重點深入研究視覺問答任務中,圖像與問題的特征提取、多模態的特征融合和答案推理4個子流程的模型與算法,以期實現對圖像和文本中碎片化信息的提取、表示,并提升視覺問答系統答案推理的準確率.
1 相關工作
近年來,國內外的眾多研究人員對視覺問答進行了深入的研究,提出了基于神經網絡的基礎視覺問答模型[1-3].這類模型的基本思路是使用卷積神經網絡(convolutional neural network, CNN)[4]提取圖像特征,使用循環神經網絡(recurrent neural network, RNN)[5]提取問題文本特征,并融合2種不同模態的特征用以推理產生答案.該模型的整體框架主要分為圖像特征提取、問題文本特征提取、多模態特征融合等模塊,并成為之后視覺問答研究的主流框架.
現有的視覺問答模型使用各種不同結構的卷積神經網絡提取圖像特征.早期的視覺問答模型采用預訓練的VGGNet[6]提取圖像特征.VGGNet是一個自底向上的19層CNN,該網絡中不同隱層的神經元能夠提取到圖像中不同層次的特征信息,越深層次的網絡能夠提取到越豐富的圖像特征.2016年文獻[7]提出了使用ResNet提取圖像特征,設計殘差塊結構并加入到卷積神經網絡中,有效解決了隨著神經網絡層數增加所導致的梯度彌散問題,在視覺問答任務中取得了更高的準確率,因此成為當年視覺問答模型的基準方法.目標檢測任務中的R-CNN[8]模型,將傳統的單目標圖像特征進一步擴展到多目標圖像特征,為視覺問答任務的圖像特征提取模型提供了新的思路.
針對問題文本特征的提取,早期的視覺問答模型主要利用詞袋模型提取問題文本特征.詞袋模型假定句子中每個單詞相互獨立,無法提取到問題文本的上下文關聯信息.為解決該問題,現有的視覺問答模型主要采用循環神經網絡RNN來提取包含上下文信息的問題文本特征.原始的RNN結構隨著序列長度增長易導致梯度彌散,為了突破該局限性,RNN出現了許多變種模型,主要包括門控循環單元(gated recurrent unit, GRU)[9]和長短期記憶網絡(long short-term memory, LSTM)[10].LSTM相比GRU網絡參數更多,更適用于數據量較大的視覺問答任務,因此被廣泛應用在目前的視覺問答模型中.RNN結構對于句子各個級別的語義信息缺乏較好的理解方式,文獻[11]提出了Hierarchical Co-Attention模型使用了分層結構對語義信息進行提取,提升了文本不同層次信息之間的關聯性.目前視覺問答任務中對于語義信息分析的研究較為缺乏,仍存在很大的研究空間.
視覺問答任務的關鍵流程是將提取到的圖像與問題文本2種不同模態的特征,融合為包含圖像與問題關聯信息的特征.基礎的視覺問答模型對圖像與問題特征的融合只使用簡單的拼接方法,這種方法得到的融合特征會丟失掉圖像與問題的關聯性.隨著研究的深入,已有若干研究工作在視覺問答模型的多模態特征融合過程中引入注意力機制,使視覺問答模型的答案更關注與其相關性強的信息,從而避免被相關性弱的信息干擾.文獻[11]提出了一種圖像和問題協同注意的分層架構,該方法可以使圖像特征和問題文本特征產生彼此的注意力權重,并利用該權重對相應的原始特征進行加權,有效提高了視覺問答準確率;文獻[12]提出以問題為導向的空間注意力機制,該方法根據問題文本的特征為圖像特征分配注意力權重;文獻[13]提出了SAN模型,該模型通過不斷迭代修正注意力權重,實現圖像區域的注意力權重分配;文獻[14]提出了基于多目標圖像特征建立的注意力機制模型,這種注意力機制更具有針對性,因此該方法取得了顯著的效果,為視覺問答模型中多模態特征融合提供了新的思路.
在答案推理流程中,現有的視覺問答模型[1-2]將數據集出現頻率較高的答案提取出來構造答案集合,并在該集合上進行分類,將分類結果作為推理的答案.該方法可以簡化視覺問答的模型結構,并確切地計算出視覺問答模型的準確率用于模型評估,因此成為目前答案推理的通用方法.

Fig. 2 Basic model structure for object detection tasks圖2 目標檢測任務基礎模型結構
2 基礎知識與模型
完整的視覺問答任務可分解為圖像特征提取、問題文本特征提取、多模態特征融合和答案推理4個流程.本節將對用于提取圖像和問題文本特征的卷積神經網絡、循環神經網絡,以及用于多模態特征融合和答案推理的注意力機制與變分推斷方法的相關基礎知識進行介紹.
2.1 卷積神經網絡CNN
CNN概念由Lecun[4]提出,在圖像處理方面得到了廣泛的運用.CNN的特征提取器由卷積層與子采樣層組成:卷積層包含了若干個維數較小的二維卷積核,每個卷積核在二維的特征平面上進行平移并通過卷積運算,將計算出的數值組合成新的特征平面并進行疊加組合,形成新的圖像特征.對圖像特征進行子采樣,降低特征的維度.采樣操作通常使用最大值子采樣和均值子采樣.
完整的卷積神經網絡由多個特征提取器疊加而成,將最末端的特征提取器輸出的特征平面通過全連接網絡生成最終的圖像特征.CNN有多種不同的網絡結構,用于視覺問答任務的網絡結構主要包含VGGNet,ResNet以及Faster-R-CNN.
2.1.1 VGGNet
VGGNet由多個卷積塊與子采樣層堆疊而成,每個卷積塊中包含若干個卷積核尺寸為3×3的卷積層,每個卷積塊的輸出特征輸入到尺寸為2×2的子采樣層.設置不同卷積塊與卷積層數量,得到不同深度的模型,用以提取不同層次的特征信息.
2.1.2 ResNet
ResNet的基本思想是引入了帶有“跳躍鏈接”的殘差塊,如圖1所示.部分梯度在卷積神經網絡中跳躍傳遞,將原始輸入向量x直接累加到之后的權重層上,一定程度上避免了梯度彌散的問題.
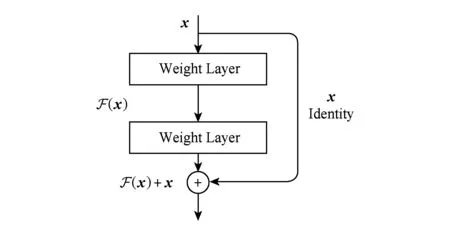
Fig. 1 Residual block圖1 殘差塊
2.1.3 Faster-R-CNN
計算機視覺中目標檢測任務在對圖像中的對象進行正確分類的基礎上,還需要找出目標在圖像中的位置.通過在傳統圖像分類的模型中加入回歸器可有效解決該問題,總體模型結構如圖2所示:
早期的目標檢測方法使用窮舉法選取目標對象的候選邊框.2014年文獻[8]提出了R-CNN模型,該模型使用選擇性搜索極大降低了選取邊框的數量;文獻[15]提出的Fast-R-CNN模型在R-CNN模型基礎上優化了特征提取結構,進一步提升了效率;文獻[16]提出Faster-R-CNN模型,將選取候選框的過程合并到神經網絡中,利用圖像特征信息計算候選框信息,在目標檢測領域中建立了完整的端到端訓練的神經網絡模型.
2.2 循環神經網絡RNN
RNN將當前信息xi和前綴序列特征值hi-1輸入到單元模塊Uniti,計算出當前序列特征值hi,i的取值范圍為1到t.因此每個單元模塊輸出的特征信息包含前綴所有位置的信息,RNN展開的模型結構如圖3所示:
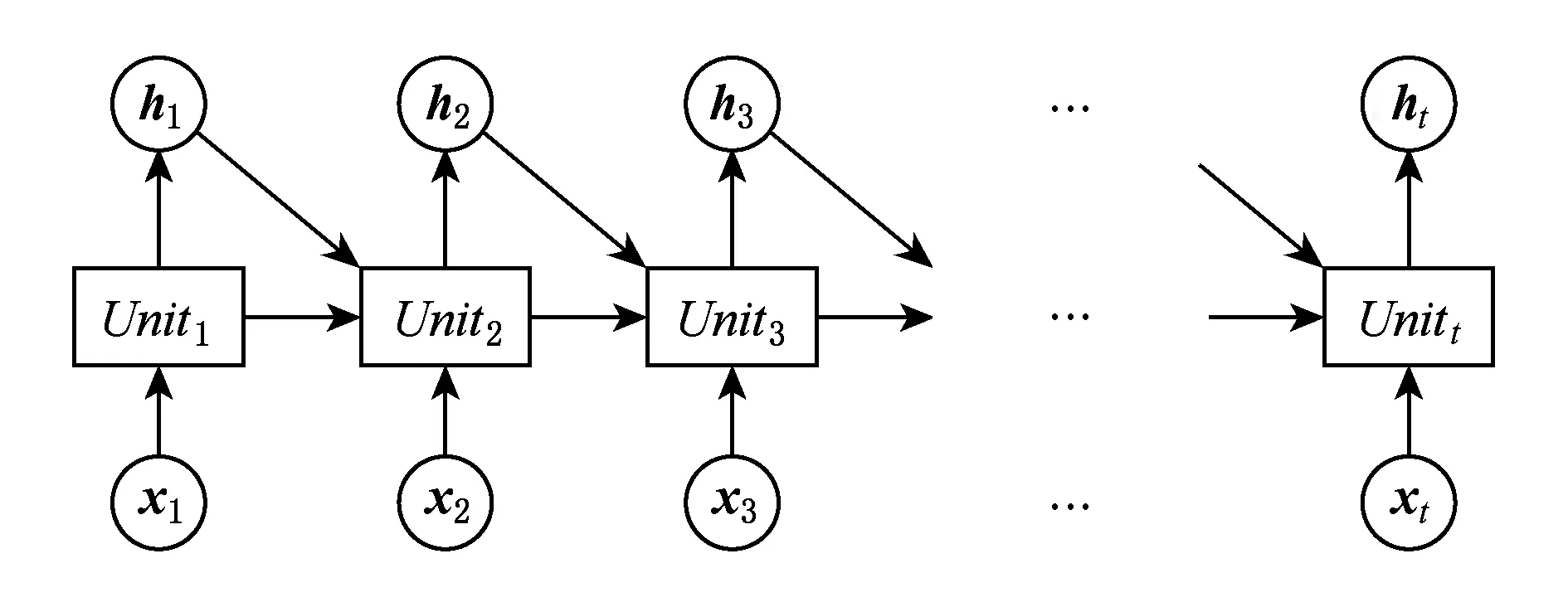
Fig. 3 Recurrent neural network圖3 循環神經網絡
為解決傳統RNN梯度彌散的問題,模型出現了許多變種,主要有門控循環單元(gated recurrent unit, GRU)[9]和長短期記憶網絡LSTM[10].通過在循環神經網絡單元中加入門控單元模塊,以控制梯度的傳播,一定程度上避免了梯度彌散的問題,圖4展示了門控單元模塊結構,S為sigmod激活函數,tanh為tanh激活函數,每個單元輸入原始向量x,輸出特征向量h.

Fig. 4 Gated unit module圖4 門控單元模塊
2.3 注意力機制
注意力機制是通過對每個時刻的特征進行加權,表示每個特征對當前時刻的重要程度,提取出更為關鍵的特征信息,從而提升模型效果.
注意力機制在機器翻譯領域中主要通過自編碼框架實現.輸入特征向量x進行編碼,用每一時刻編碼結果和前一時刻解碼結果計算注意力權重矩陣并進行特征加權,得到解碼的特征向量y.具體的模型結構如圖5所示:
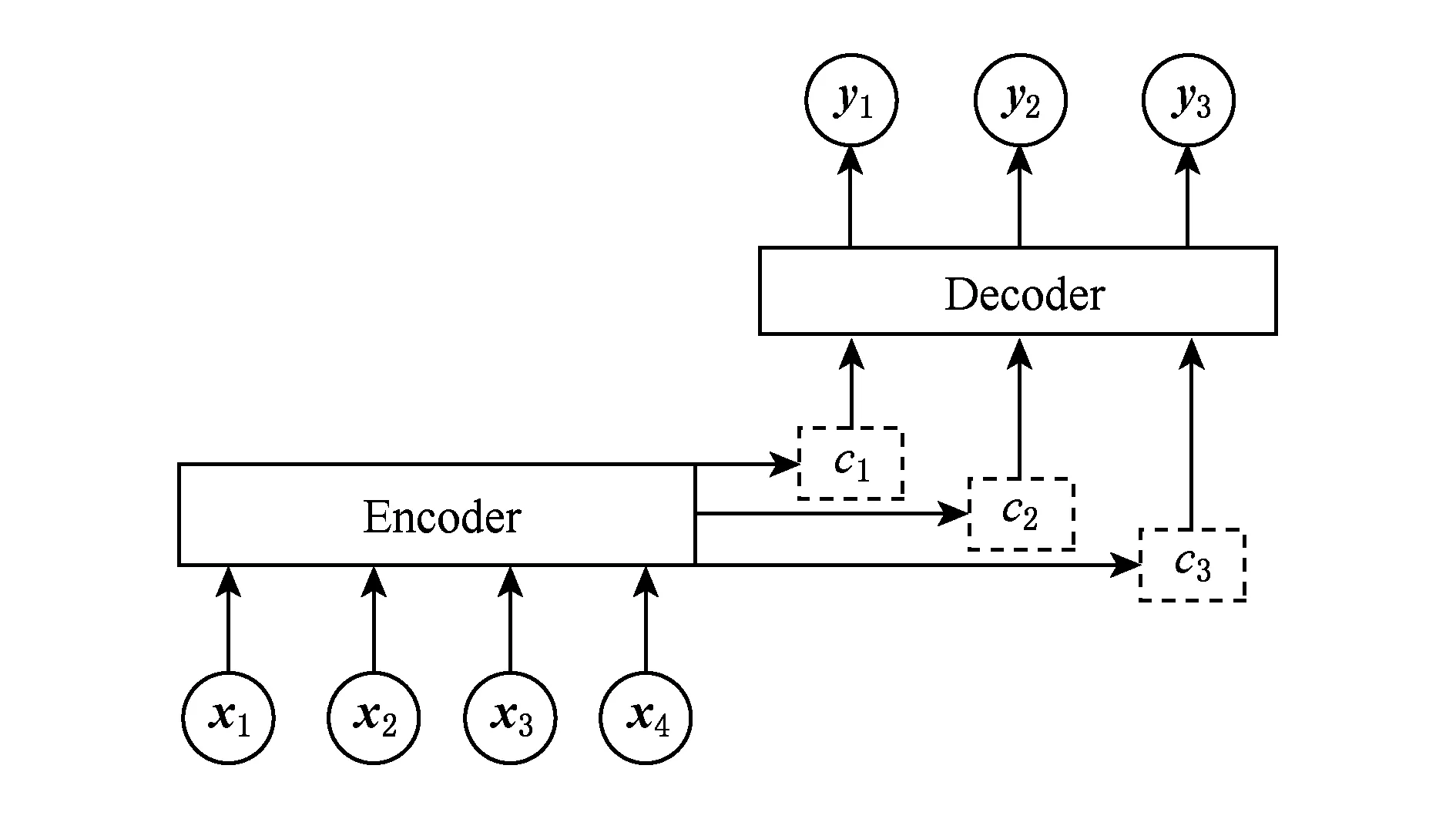
Fig. 5 Attention mechanism on machine translation圖5 機器翻譯中的注意力機制
注意力機制在機器翻譯中取得了顯著的效果,成為該領域的基準方法之一.在視覺問答任務中,圖像的多目標特征與問題文本特征均可轉化為序列特征,因此該注意力機制同樣適用于視覺問答任務.
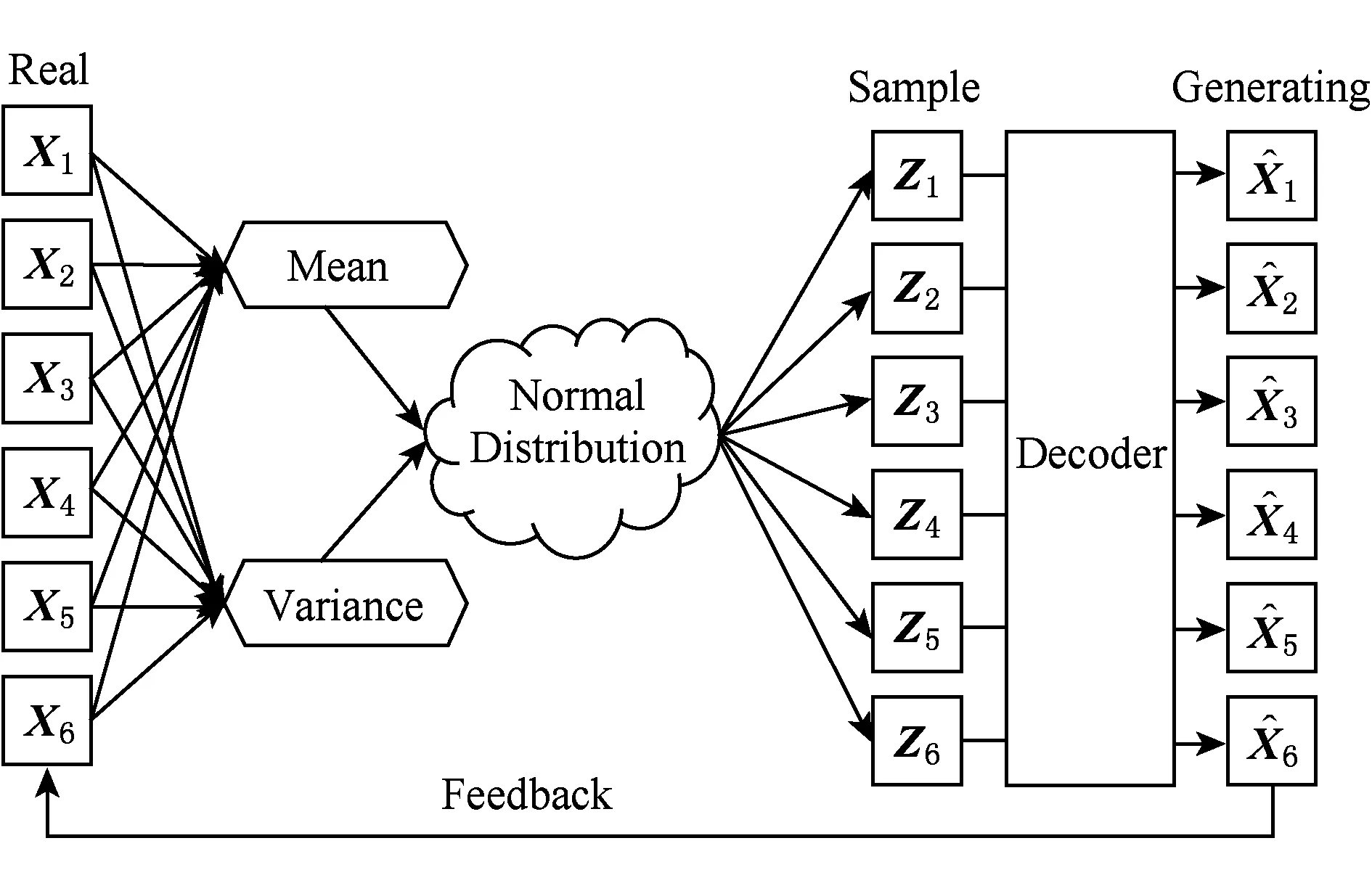
Fig. 6 Variational auto-encoder圖6 變分自編碼器
2.4 變分推斷
假設z是符合概率分布p(z|x)的高維向量,帶有高維隨機變量z的概率分布積分難以計算.變分推斷是一種求解近似概率分布的方法,它的核心思想是利用簡單概率分布q(z)來近似表示復雜概率分布p(z|x).文獻[17]提出變分自編碼器 (variational auto-encoder, VAE),通過使用多層神經網絡擬合高斯分布的均值與方差,用以表示近似復雜的后驗概率分布.VAE模型能夠表示數據分布的隱向量編碼的概率分布,在該分布上進行采樣即可得到隱向量編碼,模型結構如圖6所示:
3 基于深度神經網絡的視覺問答模型
本文提出一種基于深度神經網絡的視覺問答模型,模型包括基于LSTM的圖像特征提取方法、基于RNN+CNN的問題文本特征提取方法、結合注意力機制與變分推斷的多模態特征融合方法,以及使用分布距離作為神經網絡損失值的答案推理方法.
3.1 基于LSTM的圖像特征提取
本文所提出的圖像特征提取方法流程如下:使用Faster-R-CNN提取多目標圖像特征,并基于LSTM對多目標圖像特征進行融合,同時設計權重調整調整方法平衡各個目標的特征權重.
3.1.1 Faster-R-CNN提取多目標圖像特征
將圖像輸入到訓練好的Faster-R-CNN模型,計算出k個用以表示目標位置的邊框信息.根據每個邊框位置得到k張局部圖像,并利用CNN進行圖像特征提取,最終得到k個的圖像特征.
3.1.2 基于LSTM的多目標圖像特征融合
圖像中不同的目標之間存在關聯信息,為了保留這些信息,將圖像特征作為長度為k的序列(V1,V2,…,Vk),利用LSTM從該序列中提取多目標組合的圖像特征.
3.1.3 權重調整
利用LSTM提取出的特征可以有效保留多目標特征之間的關聯性,將每個目標特征當成LSTM單元輸入,輸入靠后的圖像特征將會獲得更大的權重,對輸出結果產生更大的影響.而所有的目標特征應具有相同的權重,因此需要對模型中每個時刻輸入的圖像特征進行權重調整,使其能夠均衡處理每個目標特征.本文使用拓展時序與BiLSTM兩種方法:
1) 拓展時序
模型如圖7所示,將圖像特征序列(V1,V2,…,Vk),進行反轉得到(Vk,Vk-1,…,V1),與原特征序列拼接得到新的圖像特征序列(V1,V2,…,Vk-1,Vk,Vk-1,…,V2,V1),作為LSTM的輸入.這種模型結構令每個目標的圖像特征在序列首尾均出現一次,起到了均衡每個目標特征權重的效果.

Fig. 7 Weight adjustment by extended sequence圖7 擴展時序調整權重
2) BiLSTM
BiLSTM是雙向的LSTM模型,序列分別從兩端輸入到2個不同的LSTM中.將前向傳遞的輸出與反向傳遞的輸出進行拼接,作為當前時刻的輸出.本文使用BiLSTM來進行多目標圖像特征融合,使用k/2位置的LSTM單元輸出作為融合的圖像特征,整體的模型如圖8所示.通過減少每個目標特征到達輸出時刻的距離,起到均衡權重的效果.LSTM的單元輸出為output,使用k/2位置的LSTM單元輸出outputk/2作為融合的圖像特征.
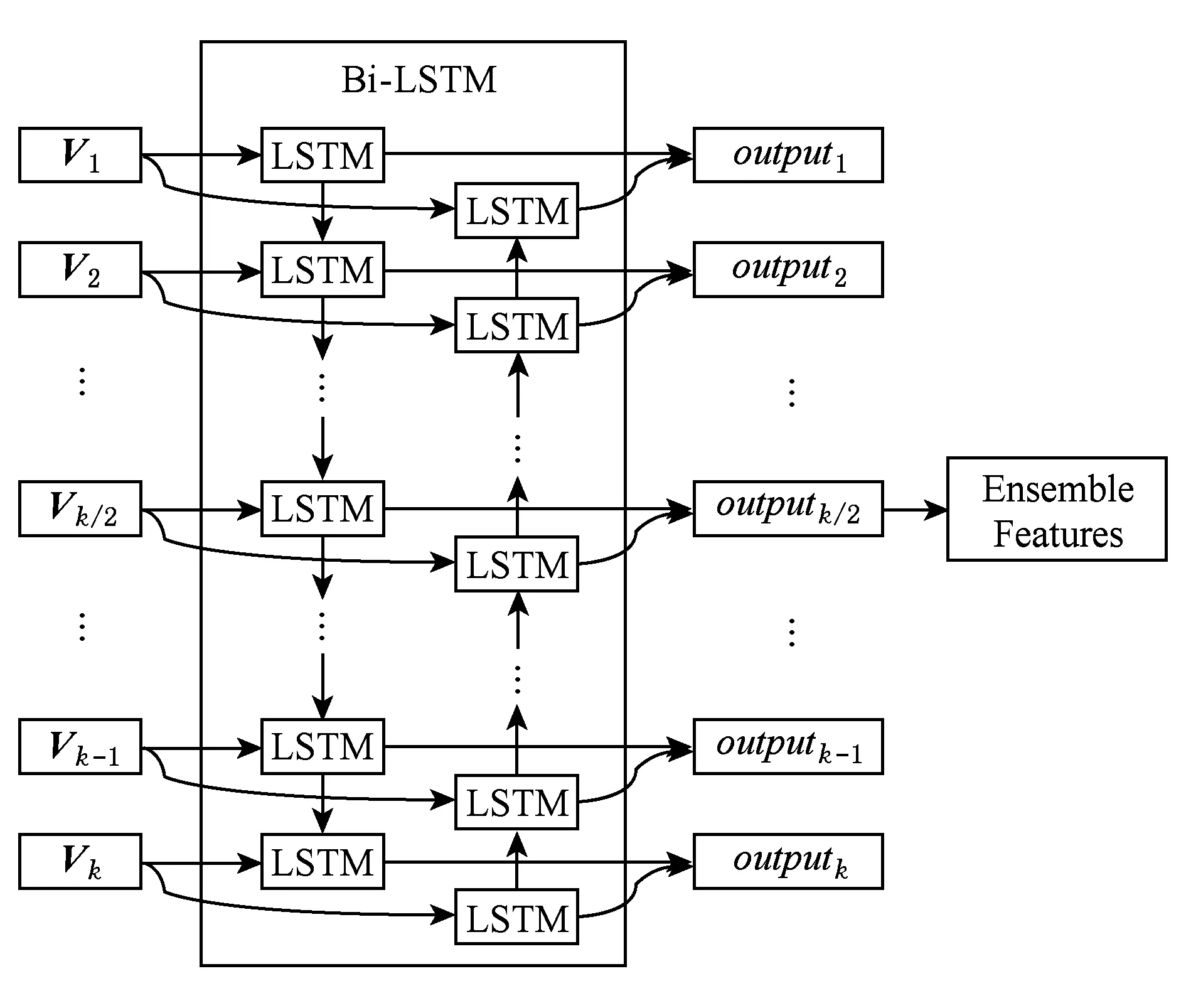
Fig. 8 Weight adjustment by BiLSTM圖8 BiLSTM調整權重
3.2 基于RNN+CNN的問題文本特征提取
本文所提出的問題文本特征提取方法流程如下:首先將問題的單詞轉換為詞向量,并將詞向量序列輸出到RNN中提取初步的文本特征,最終使用CNN進行文本特征的組合.
3.2.1 提取詞向量
問題是由多個單詞組成的序列,使用word2vec[18]將問題單詞序列轉換為詞向量序列,將該序列作為RNN的輸入.
3.2.2 RNN提取初步文本特征
RNN的輸入輸出都是一個序列,把輸入序列標記為(x1,x2,…,xt-1,xt,xt+1,…,xT),輸出標記為(o1,o2,…,ot-1,ot,ot+1,…,oT),RNN中的隱層狀態集合標記為(s1,s2,…,st-1,st,st+1,…,sT),其中xt表示時刻t的輸入,ot表示時刻t的輸出,st表示時刻t的隱層狀態,T為序列的最大時間索引.
st=f(Uxt+Wst-1),
(1)
ot=softmax(Vst).
(2)
如式(1)所示,在時刻t隱層節點的輸入包括輸入層的xt和時刻t-1的隱藏層狀態值st-1,U為輸入層和隱層之間連接的參數矩陣,W為隱層單元之間連接的參數矩陣.如式(2)所示,時刻t的輸出ot與st和V有關,其中V為隱層與輸出層之間連接的參數矩陣.通過編碼可得到(o1,o2,…,ot-1,ot,ot+1,…,oT)作為初始文本特征,其中softmax函數為非線性激活函數,計算為
(3)
3.2.3 CNN組合文本特征
利用3個CNN對初始文本特征進一步提取,其中時刻t大小為c的卷積核的輸出為
hc,t=tanh(WcOt:t+c-1+bc).
(4)
窗口大小為c的卷積核的所有時刻輸出為
hc=(hc,1,hc.2,…,hc,T-c+1).
(5)
將最大池化應用于的時間維度上輸出為

(6)
將不同窗口大小的CNN輸出進行拼接得到最終的問題文本特征:

(7)
整體流程如圖9所示.
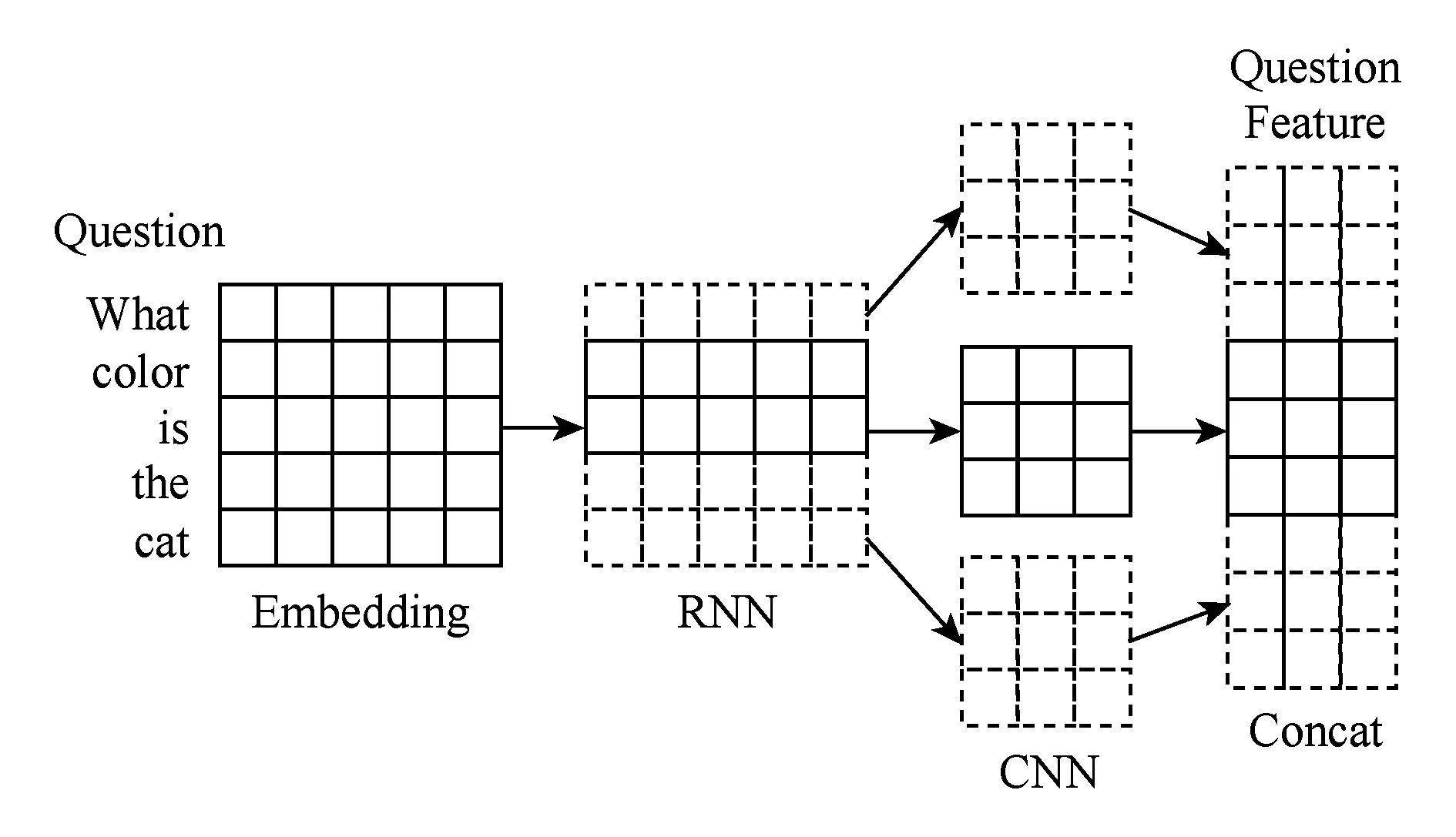
Fig. 9 Problem text feature extracting process圖9 問題文本特征提取流程
3.3 多模態特征融合
本文所提出的多模態特征融合方法主要有:結合問題文本信息,使用注意力機制對圖像特征進行加權.基于變分自編碼器計算圖像與問題的隱向量概率分布,在隱向量上進行特征融合.
3.3.1 基于注意力機制的圖像特征加權
通過前2個步驟提取圖像中的k個目標特征和問題文本特征,將每個目標特征分別輸入到全連接層,轉換為與問題特征相同的維度n并將特征相乘,得到圖像與問題初步融合的特征Vk n.

3.3.2 基于變分自編碼器的特征融合
假設經過注意力機制加權的圖像特征向量為I,問題文本特征為Q,隱向量編碼z是表示問題特征與問題文本特征關聯性的隱含向量.它的概率分布表示為p(z|I,Q),該概率分布過于復雜無法計算,因此基于變分推斷方法,利用簡單概率分布q(z)近似表示該概率分布.
變分推斷的基本思想是利用Kullback-Leibler(KL)散度值描述2個概率分布之間的相似度:
KL(p(z|I,Q)‖q(z)).
(8)
KL散度值越小則表示2個概率分布越相似,式(8)經過推導可得:
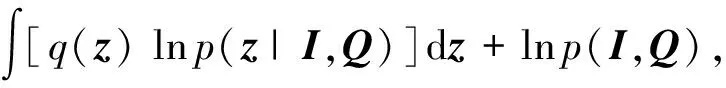
(9)
進一步化簡得到:
KL(p(z|I,Q)‖q(z))=KL(q(z)‖p(z)).
(10)
最終將問題特征與問題文本特征聯合概率分布的計算轉換為優化KL(p(z|I,Q)‖q(z))的最小值.
為獲取圖像特征與問題文本特征的維數為d的融合編碼z,需要近似出可供采樣的概率分布q(z).假設p(z)是正態分布,q(z)是標準正態分布N(0,I),則可對式(10)進一步推導得到:
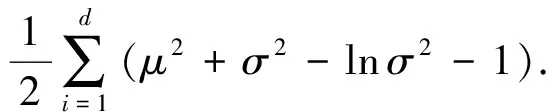
(11)
通過最小化KL散度值,計算參數σ與參數μ,得到圖像特征與問題文本特征聯合表示的隱含向量編碼z的近似概率分布.
計算隱向量編碼z可視為對特征編碼的過程,為了構建完整的自編碼器的模型還需要構造解碼器用于解碼隱向量編碼,模型結構如圖10所示:

Fig. 10 Encoder-Decoder structure圖10 自編碼結構
在解碼的過程中,直接對融合特征隱向量編碼的概率分布進行采樣解碼,將無法計算梯度,從而導致神經網絡無法正常訓練.為解決該問題,本文借鑒文獻[17]的思想對采樣過程進行重參數化,分為2個過程:
1) 在標準正態分布N(0,I)上采樣,獲得一定數量隱含向量編碼z.
2) 對隱含向量編碼z重參數化:z′=μ+σz,將z′作為新的隱含向量編碼.
通過神經網絡對隱向量編碼進行解碼,使用反卷積解碼為新的圖像特征,使用多層神經網絡解碼為新的問題特征,并對2種特征分別計算它們與原始特征的平方差距離并作為整個神經網絡模型訓練損失值的一部分.
將提取到的低維的圖像與問題文本特征的隱含向量編碼進行外積相乘,輸入到全連接層,全連接層中的參數可以表示圖像特征與問題文本特征每個位置之間的關聯性.最后將二維特征向量水平轉換為一維特征向量,作為圖像特征與問題特征的融合特征向量,這個階段完整模型如圖11所示:
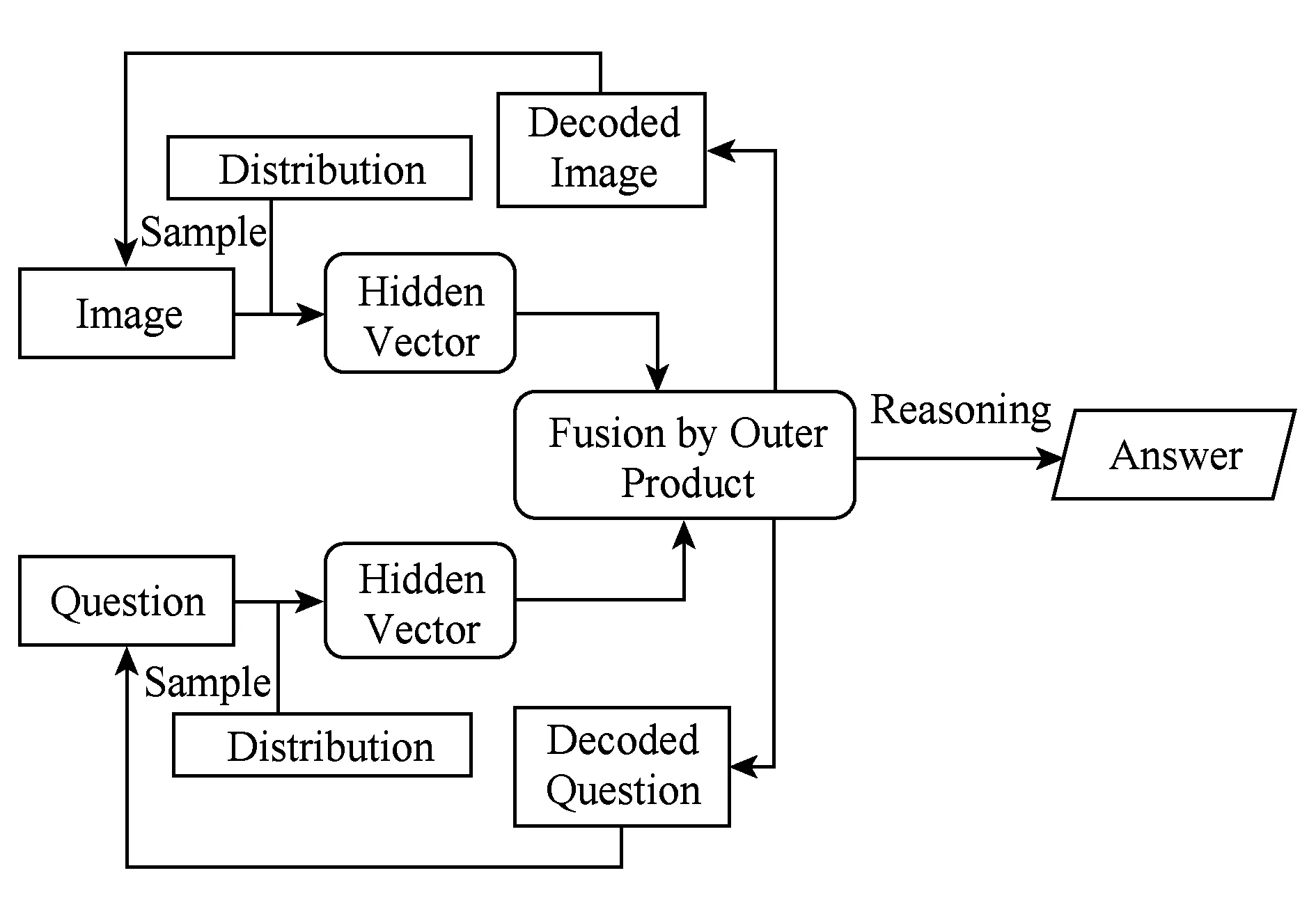
Fig. 11 Model structure of multi-model feature fusion圖11 多模態特征融合模型結構
3.4 答案推理
統計數據集中的答案,將出現頻率最高的3 000個答案作為答案集,答案推理轉換為多分類問題.

4 實驗與結果分析
對于視覺問答的4個階段,本節通過實驗的方式分別將文中所提出的模型與算法跟基準模型進行實驗對比,以驗證模型與算法的有效性.最終將這些模型與算法整合到完整的視覺問答模型中,與現有的視覺問答模型進行實驗對比分析.
4.1 數據集
實驗采用COCO -VQA-V2數據集[2],該數據集中的圖像來自于MS-COCO數據集,主要包括123 287張圖像,其中72 738張用于訓練、38 948張用于測試.數據中圖像數量龐大、內容繁雜,包含大量碎片化信息.每張圖像都有一個對應的問題與答案.該數據集的子數據集test-standard和test-dev,在EvalAI上提供了可以提交答案的評估系統.本文實驗均使用該系統進行評估,將測試數據集作為已訓練好的模型輸入,輸出對應的答案文件,并提交到系統評估模型準確率,從而驗證模型的有效性.
答案的評估分為3種類型:Yes/No,Number,Other,分別對應判斷問題、計數問題、開放式問題.對于每一類問題分別統計準確率,并統計出該模型在所有問題(All)上的準確率,根據準確率評估模型效果.
4.2 圖像特征提取
為驗證基于LSTM的圖像特征提取模型的有效性,使用基礎的RNN模型進行問題文本特征提取,基礎的拼接方法進行圖像問題特征融合.將LSTM圖像特征融合方法結合設計的2種權重調整方法:基于正反序列的權重調整(Reverse),基于雙向LSTM的權重調整方法(BiLSTM)與求和(Sum)、拼接(Concat)這些基礎方法進行對比實驗,實驗結果如表1所示.
表1的實驗結果表明:基于LSTM的圖像特征提取方法相比原始的拼接與求和方法有著顯著的提升,使用權重調整方法進一步提升了準確率,并且使用BiLSTM進行權重調整取得了最高的準確率58.49%.

Table 1 Accuracy on the Method of Feature Extractby LSTM
4.3 問題文本特征提取
為驗證基于RNN+CNN的問題文本特征提取模型的有效性,我們使用基礎的ResNet進行圖像特征提取、基礎的拼接方法進行圖像問題特征融合.文本特征提取所使用的RNN模型為LSTM,并將RNN+CNN方法與原始LSTM進行實驗對比,實驗結果如表2所示:
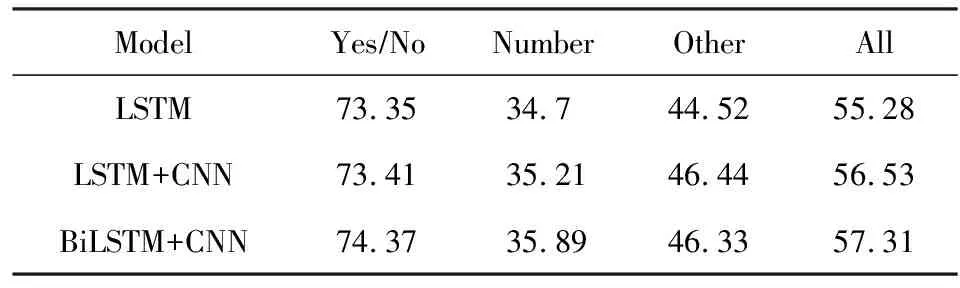
Table 2 Accuracy on RNN+CNN Model表2 RNN+CNN模型準確率 %
表2的實驗結果表明:將RNN與CNN結合的模型對問題文本特征的提取效果優于原始的LSTM,并且進一步提升視覺問答算法的準確率.其中,BiLSTM和CNN結合的文本特征提取方法使得視覺問答準確率達到57.31%,相比于基礎方法有所提升,因此該方法將用于后續視覺問答實驗中文本特征提取.
4.4 特征融合
本文使用Faster-R-CNN作為圖像特征提取的基礎模型,并針對這種圖像特征設計的注意力機制得到新的圖像特征,使用基礎的RNN模型進行問題文本特征提取,并使用變分編碼器分別對圖像與問題文本對隱向量特征信息進行提取與融合.
模型針對是否使用注意力機制(ATT)、是否使用變分自編碼器(VAE)對圖像特征(I)與問題文本特征(Q)進行隱向量編碼的提取進行對比實驗,實驗結果如表3所示:

Table 3 Accuracy on Multi-Model Features Fusion Method表3 多模態特征融合方法準確率 %
表3的實驗結果表明:注意力機制顯著地提升了視覺問答的準確率,在此基礎上對圖像特征提取隱向量編碼的融合方法,取得了最優效果.
將實驗效果最好的Att+I_VAE模型,在隱向量的抽樣過程,考慮隱向量維數大小與隱向量編碼抽樣次數2個參數,進行對比實驗.
對模型設置不同的隱向量維度,并以模型在視覺問答任務中的準確率作為指標進行實驗對比,圖12給出了不同隱向量編碼維度實驗結果:

Fig. 12 Results on differently hidden vector dimension圖12 不同隱向量編碼維度實驗結果
圖12的實驗結果表明:隨著隱向量編碼的維數上升,模型的準確率呈現上升趨勢,一開始上升的趨勢變化較大,隨后便逐步衰減.由于2種特征的隱向量編碼需要外積計算,因此隱向量編碼維數不宜過大.將隱向量編碼的維數設置在100左右,保證模型的準確率的同時,避免模型的空間復雜度過大.
對模型設置不同的隱向量抽樣次數,并以模型在視覺問答任務中的準確率作為指標進行實驗對比,圖13給出了不同抽樣次數實驗結果.
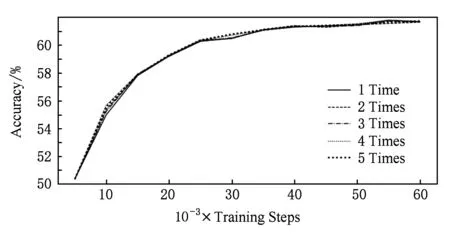
Fig. 13 Results on differently sample time圖13 不同抽樣次數實驗結果
圖13的實驗結果表明:隱向量編碼的抽樣次數對模型準確率本身沒有太大影響.這是由于數據規模足夠大,多次對隱向量編碼進行抽樣實際上起到的是一個增強數據的作用,對擬合數據的分布并沒有太大的影響.抽樣的次數與模型的訓練時間是成正比的,進行多次抽樣將會降低模型的訓練效率,將模型采樣次數設置為1次,模型在準確率基本不變的前提下時間效率達到最優.
4.5 答案推理
針對答案推理過程,本文主要針對使用衡量概率分布距離的Kullback-Leibler散度值與傳統多分類任務所使用的交叉熵Cross Entropy兩種損失值對模型效果的影響.在視覺問答其他流程中用相同的基礎方法,對比了模型使用2種不同損失值的準確率,實驗結果如表4所示:
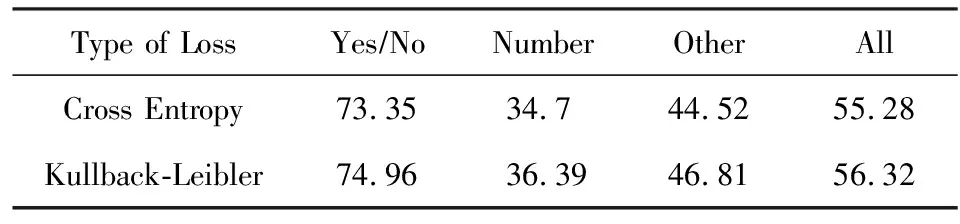
Table 4 Accuracy on Reasoning Answer表4 答案推理準確率 %
表4的實驗結果表明:使用Kullback-Leibler散度能夠更準確地衡量模型預測答案與真實答案的偏差值,將此作為損失值反饋給神經網,進一步提升了答案推理的準確率.
4.6 整體模型
將以上4個流程中的模型算法整合成完整的VQA模型:使用BiLSTM進行權重調整并融合多目標圖像特征;使用LSTM+CNN提取問題文本特征;在多模態特征融合階段,結合注意力機制與變分推斷方法,使用上述方法中最優的ATT+I_VAE模型進行特征融合;在答案推理階段利用KL散度值衡量2個答案分布的差異并作為損失值反饋回神經網絡進行訓練.
該模型的核心方法是特征融合過程中所使用的VAE,將該模型命名為V-VQA并與其他現有的基準模型進行對比實驗,實驗結果如表5所示.
表5的實驗結果表明:本文所提的模型V-VQA在COCO-QA-V2數據集上的整體準確率為64.86%,優于現有的大部分視覺問答模型,通過實驗表明該模型是有效的視覺問答模型.

Table 5 Accuracy on V-VQA Model表5 V-VQA準確率 %
4.7 結果展示
抽取COCO-QA-V2中的若干條圖像與問題數據,通過訓練好的模型進行答案推理,圖14給出了單一形式問題的展示結果.

Fig. 14 Example 1 of VQA圖14 視覺問答示例1
圖14的結果表明:本文所提出的視覺問答模型對于涉及到物體識別、位置判定以及簡單邏輯處理等基礎問題能夠推理出準確的答案.但是對于圖像信息存在一定程度遮擋,或需要結合更多先驗知識類型的答案推理,該模型容易出現錯誤.如圖14(d)問答所示,摩托車數量正確答案是4,由于其中一輛摩托車存在較多遮擋,模型給出的答案是3.因此該模型仍有進一步提升的空間.
針對一張圖像,根據提問的方式可以得到多種答案,圖15展示了針對同一張圖片多種形式問題的視覺問答任務.

Fig. 15 Example 2 of VQA圖15 視覺問答示例2
從圖15可以看出:本文所提出的模型對各種形式的問題均能給出較為準確的答案,有助于提取出圖像中所蘊含的碎片化信息.
5 總 結
本文針對目前互聯網中存在的不同模態、高度分散、結構無序、內容片面的圖像與問題文本數據,提出構建視覺問答系統用以實現對多模態碎片化信息的提取、表達和理解.針對視覺問答任務流程的圖像特征提取、問題文本特征提取、多模態特征融合、答案推理等步驟,基于深度神經網絡,設計用以提取圖像與問題文本特征的模型,結合注意力機制與變分推斷方法,設計多模態特征融合方法,并使用分布距離作為神經網絡損失值,設計答案推理方法.仿真實驗結果表明各個過程中所使用的模型及算法是有效可行的,利用這些模型與算法整合得到的完整視覺問答模型也有效提升了該模型針對視覺問答任務的準確率.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
小學教學參考(2015年20期)2016-01-15 08:44:38
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
語文知識(2014年1期)2014-02-28 21:59:13
