視頻監控下的行人性別檢測
2018-11-17 02:35:12蘇寧陳臨強
現代計算機 2018年29期
蘇寧,陳臨強
(杭州電子科技大學計算機學院,杭州 310018)
0 引言
隨著計算機軟、硬件技術的快速發展,計算機處理圖像、視頻的能力也不斷提升,從而使得計算機視覺得到了飛速的發展,成為近些年來最火熱的研究方向之一。行人屬性分析作為計算機視覺的一部分也得到了空前的發展。行人的屬性信息例如性別、年齡、衣著、身高等,是行人最明顯的生物特征。行人性別識別基于行人識別,在視頻監控和安全防護領域有著廣泛的應用。先進的行人搜索系統可以首先確定性別,縮小搜索范圍,并根據其他屬性信息進一步執行更準確的搜索,大大提高了檢測的準確率以及效率。
性別的檢測主要是通過計算機算法提取人物的一些基本特征,再根據特征的差異來判斷性別。Shan[1]根據局部二值模式直方圖進行性別識別,在LFW人臉數據庫中實現了94.81%的正確率。Xia等[2]提出了一種局部蓋博二值映射模式人臉表示方法,利用SVM(Support Vector Machine)進行性別識別,在GAS-PEAL人臉數據庫中達到94.96%的準確率。Yang等[3]利用局部三元模式和極限學習機進行性別識別,在FERET數據庫中實現了95.625%的準確率。Gil等[4]設計了一種基于卷積神經網絡的方法進行性別識別。Ail等[5]采用局部蓋博二值模式和三維人臉重建進行性別識別,在LFW數據庫中獲得99.8%的準確率。Hamid等[6]運用主成分分析和模糊聚類的方法,在FG-NET數據庫中測試準確率達到92.65%。閆敬文等[7]融合方向梯度直方圖和多尺度 LBP(Local Binary Patterns)特征,提取臉部梯度特征和局部紋理特征實現性別識別。汪濟民等[8]通過卷積神經網絡提取人臉特征進行性別識別。馬千里等[9]對人臉圖像分塊、融合五官特征加權的LBP特征提取的方法進行性別檢測。
根據現有的方法來看,基于人臉特征來進行性別檢測的準確率是最高的,但是在普通的監控攝像頭中,攝像頭的分辨率不高,距離遠一些的人臉會變得很模糊,人臉信息都會丟失掉,通過提取人臉特征來進行性別識別是相當困難的,此時需要根據行人其他部位信息來進行性別的檢測。基于這種情況,以及受到卷積神經網絡在計算機視覺領域上廣泛應用的啟發。本文提出一種根據卷積神經網絡和特征提取相結合的算法對人物身體部位提取信息進行性別檢測。該算法的優點是通過人物的發型、穿著等局部信息,避開了對人臉的檢測,能夠在攝像頭分辨率不高的情況下也能實現對人物性別檢測,使得算法的應用場景更加廣泛。
1 基于高斯混合模型的前景目標提取
幀差法、光流法和背景差分法是前景目標提取中比較典型的幾種方法。幀差法實現起來比較容易,但如果前景目標速度過快,會產生虛影與空洞。光流法雖然適應運動背景中的前景目標檢測,但計算復雜,且對于硬件的要求較高[10]。背景差分法在場景不變的情況下對圖像進行背景建模,能夠很好地提取出前景目標。
由于目標區域會存在一些非檢測目標的晃動,例如波動的水面和搖晃的樹葉,這些對于目標檢測來說會有一定的干擾作用。為了盡量小地消除這些影響,可采用多個單高斯模型線性疊加的高斯混合模型對目標區域進行背景建模。
1.1 建立背景模型
在t時間段內,取0到t時刻的當前幀圖像[F0,F1,F2,…,Ft]。為了提升背景建模的精度,首先要對這t張圖像進行高斯濾波從而減少拍攝時產生的噪聲,然后再將t張彩色圖像從R,G,B空間轉化為灰度空間,即:
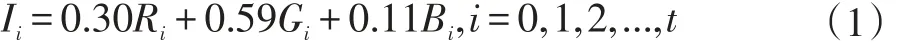
1.2 定義模型與初始化參數
若[X0,X1,X2,…,Xt]表示樣本點的離散灰度值,則可用K的高斯分布來表示像素點Xt的概率:
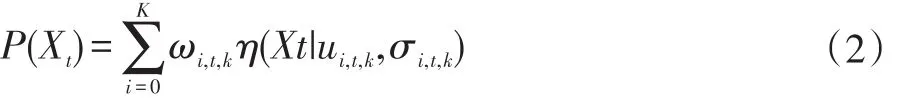
其中σi,t,k表示像素點X的均值,表示像素點X的方差,η(Xt|ui,t,k,σi,t,k)表示高斯分布,ωi,t,k表示單個高斯分布的權值。K表示混合高斯分布中峰值的個數,由于像素點分布情況的不同,K的取值也不同,一般情況下取3-5個。
1.3 運動目標檢測
將當前圖像中像素點的值與模型根據公式(3)進行比較:

符合的即為背景目標,否則為前景目標[11]。
1.4 背景模型的更新
若像素點屬于背景,則用此像素點更新背景得到新的背景模型。更新背景模型的公式如下:
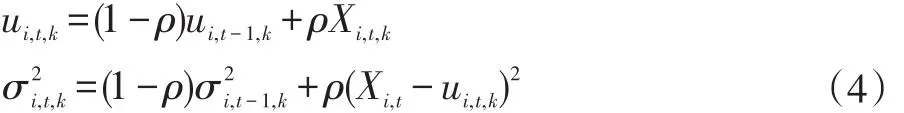
ρ=aη(Xt|ui,t,k,σi,t,k)
其中a表示學習率,ρ表示模型適應的學習因子。

圖1 原圖

圖2 運動目標提取
2 基于Hog的圖像特征提取
由于一幅圖像的外形特征可以根據像素的邊緣分布來描述,Dalal和Triggs在2005年提出了使用Hog特征的描述算子[12](梯度方向直方圖)來表示圖像的外形特征。其特征提取過程如下:
2.1 標準化Gamma空間和顏色空間
對圖像進行Gamma標準化,是為了削弱圖像對于特征提取產生的影響。由于后續步驟中block歸一化與Gamma標準化的作用相同,所以此過程對于結果來說影響并不是很大,故在后續提取hog特征的時候則不需要再進行Gamma標準化。
2.2 計算像素梯度
模板算子選取的好壞,影響著hog特征提取的結果。根據多次試驗的結果表明,使用一維離散微分模板(-1,0,+1)在圖像水平方向以及豎直方向上對像素進行梯度計算的效果都比較好。由公式(5)和公式(6)計算像素點得到梯度模值與方向角。
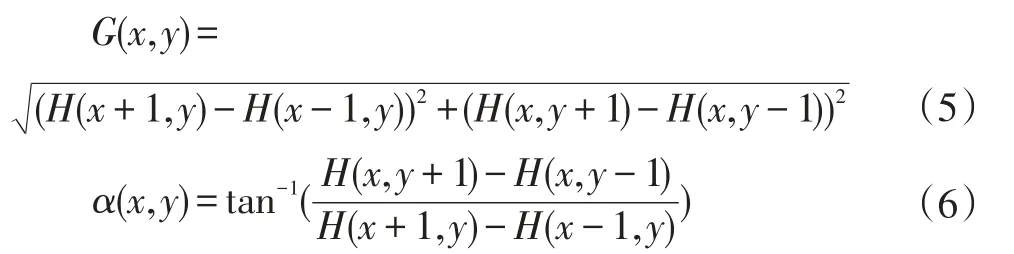
其中,G(x,y),H(x,y),α(x,y)分別表示像素點的梯度幅值、像素點的灰度值以及梯度方向。彩色圖像由于具有多個通道,可以計算出所有顏色通道的梯度,選取幅值最大的作為此像素點的梯度。
2.3 統計單元內梯度直方圖
將訓練圖像平分成多個正方形的細胞(cell),每一個細胞有8×8個像素,再將[-π/2,π/2]的梯度方向平分成9個區段(bin),然后統計在這9個區段上每一個cell內所有像素的梯度直方圖,則每一個cell將會得到一個9維的特征向量。
2.4 block歸一化直方圖
一個block包含有2×2個cell,則一個block將得到36的特征向量,再使用L2-范數對block進行歸一化,結果即為最后的特征向量。
2.5 圖像的Hog特征
訓練時采用的圖像大小為 64×64,cell為 8×8,block為16×16,則一幅圖就會包含49個block,每一個block是36的向量,故一副64×64大小的圖像的Hog特征向量為49×36=1764維。
3 基于卷積神經網絡的圖像分類
3.1 介紹
近年來發展起來的卷積神經網絡在圖像分類和語音識別方面顯示出很大的優勢,由卷積層、激勵層、池化層、全連接層等組成的是最典型的卷積神經網絡結構。其與實際的生物神經網絡相似,能夠有效地降低網絡復雜度,這也是它在圖像處理方面的一大優勢。
3.2 LeNet卷積神經網絡
最早由Yann LeCun與Yoshua Bengio提出的LeNet是第一個真正多層結構學習的算法,在手寫數字識別中具有很高的正確率[13,14],如圖3所示。

圖3 手寫體數字識別
對于圖像分類,需要設計多層的網絡結構。當網絡結構為全連接時,過多參數輸入會使得效率降低。例如對1000×1000的圖像進行卷積,大約需要1000×1000×1000×1000個參數。為了降低參數,可以使用局部卷積降低參數為 1000×1000×10×10≈100M。若再采用權值共享的策略,可以將卷積參數降到10×10。為了較好地保證圖片信息,設計多個卷積特征圖,將參數降至10K。如圖4所示。
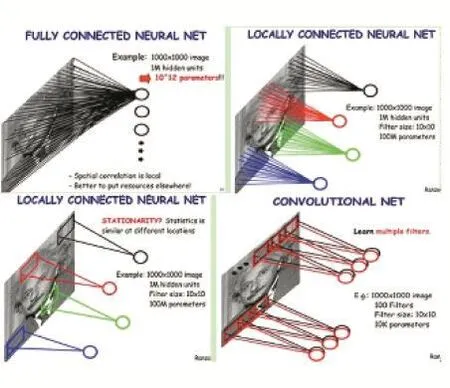
圖4 采用權重共享策略降低參數量
3.3 本文結構設計
輸入層是32×32大小圖像,網絡結構如圖5所示。
第一層:卷積層(C1)。選用6個大小為5×5的卷積核進行卷積操作,得到6個28×28的特征圖。
第二層:下采樣層(S2)。使用2×2的窗口對C1進行池化得到S2,此時每一個特征圖大小變為14×14。
第三層:卷積層(C3)。使用16個大小為5×5的卷積核對S2中得到的6個14×14的特征圖進行卷積,再經過加權組合得到16個10×10的特征圖。
第四層:下采樣層(S4)。用2×2的窗口對C3中得到的特征圖進行池化采樣得到S4,即16個5×5的特征圖。
第五層:卷積層(C5)。使用大小為5×5的卷積核對S4所得特征圖進行卷積,得到120個1×1的特征圖。
第六層:全連接層(F6)。該層有84個節點,與C5層得到的120維向量進行全連接。
第七層:輸出層。由于性別識別是一個二分類的問題,所以徑向基函數(RBF)單元組成的神經元只有兩個。公式(7)為RBF的計算公式。

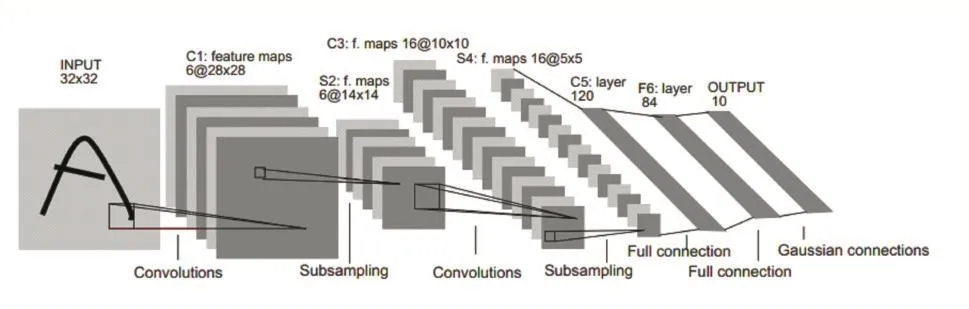
圖5 網絡結構示意圖
4 本文算法流程與實驗
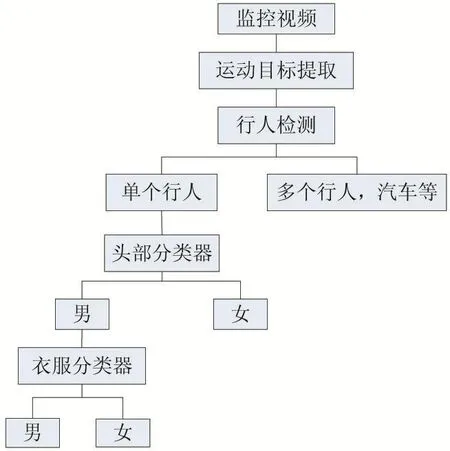
圖6 總體流程圖
由于在低分辨率的攝像頭下,人臉特征提取會變得比較困難,所以根據人臉進行性別檢測的方法就會行不通。但在這種情況下,行人的外觀特征相對容易提取。本文就是根據行人的頭部信息以及服裝的外形信息來進行行人性別的檢測。對行人進行分析就必須先從監控視頻中檢測到行人,先使用卷積神經網絡訓練行人分類器來檢測行人。選取了900張MIT行人數據庫中的行人圖片為正樣本,由于圖片除了行人之外還有一些多余的場景,訓練之前要先進行裁剪。負樣本為無人、人群、汽車等圖片,選取了2000張圖片。訓練樣本如圖7所示。

圖7 行人訓練圖片
將單個行人從前景目標中檢測出來后,對行人相應部位進行檢測即可得出性別結果。在檢測之前,需要對行人相應部位進行訓練。
圖8(a)是在監控攝像機下拍到的行人,(b)圖是將(a)圖中的行人進行了截取,從圖中我們可以看出根據頭部信息是最能夠,也是最明顯的區分行人性別的一個特征。因為目前還沒有行人性別相關的數據庫,所以本文使用的訓練圖片是由拍攝的監控視頻中摳取得到。其中男女訓練樣本均為700張,包括面對攝像頭與背對攝像頭的照片,圖9是部分訓練圖片。

圖8 行人局部區域示意圖

圖9 行人樣本集合
從人體的身體結構來看,不同人的相同部位的相對位置基本上是一樣的。所以根據此種情況,我們可以通過身體部位占人體的比例來進行身體區域的分割,然后進行區域特征提取。本文主要是對行人上半身進行相應的檢測,所以說需要確定行人頭部、肩部以及腰部的比例系數,從而得到局部重合的身體部位。比例系數是由選取的50個行人圖片計算得來,如下所示:
a=0.15 b=0.20 c=0.50
其中a代表頭部占全身的比例,b代表頭肩位置占全身的比例,c為上半身占全身的比例。
取男、女各300張圖片作為訓練樣本,因為現有的行人數據庫不適合做性別研究,所以將剩下男、女各400張圖片用作測試圖片。為了檢測本文算法的有效性,還增加了一組使用Hog特征提取行人頭部特征與衣著特征的對比實驗,結果如下:
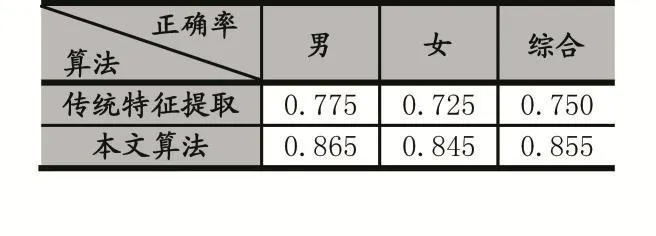
表1 傳統方法與本文方法對比結果
最后,將訓練好的分類器運用到檢測出來的行人上,得到行人性別結果。部分結果如圖10所示:

圖10 部分結果圖
5 結語
鑒于在視頻監控下,受到距離限制以及攝像頭分辨率不高的因素,根據人臉進行性別檢測已經不能達到要求,本文提出了一種提取行人多個部位特征的方法進行性別檢測。此方法避開了對行人臉部特征的提取,可以在攝像機分辨率不高的情況下對中等距離下的行人進行性別檢測。盡管本文的方法在限定的條件下取得了一定的效果,但仍然存在一些不足,例如在遠距離情況下、光線太壞或者太好的情況下都會削減正確率,所以還需要進行進一步的研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
