深度卷積神經(jīng)網(wǎng)絡(luò)在音樂風(fēng)格識別中的應(yīng)用
2018-10-26 02:23:14胡昭華余媛媛
小型微型計算機系統(tǒng) 2018年9期
胡昭華, 余媛媛
1(南京信息工程大學(xué) 電子與信息工程學(xué)院,南京 210044)2(南京信息工程大學(xué) 江蘇省大氣環(huán)境與裝備技術(shù)協(xié)同創(chuàng)新中心,南京 210044)
1 引 言
音樂風(fēng)格分類是音樂信息檢索MIR(Music Information Retrieval)[1]領(lǐng)域非常具有挑戰(zhàn)性但又很有前景的任務(wù).由于音樂是一種不斷發(fā)展的藝術(shù)且音樂風(fēng)格之間沒有明確的界限,自動分類音樂風(fēng)格是一個具有挑戰(zhàn)的問題.音樂風(fēng)格分類問題的關(guān)鍵是音樂信息的特征提取.多種特征提取和分類方法在最近幾年相繼被提出[2,3],這些分類器的性能高度依賴于按經(jīng)驗所選的手動提取特征的適當(dāng)性.一般地,識別任務(wù)中的特征提取和分類是兩個獨立的處理階段,而本文把這兩個階段融合在一起更好地實現(xiàn)了信息間的交互.
最近,深度卷積神經(jīng)網(wǎng)絡(luò)CNN(Convolutional Neural Networks)[4]在通用視覺識別任務(wù)[5,6]上不斷取得顯著進(jìn)步,這激起了人們對于CNN的分類模型[7,8]的研究興趣.CNN包括了多級處理輸入圖像,提取多層和高級特征表示.通過共享一些基本的組成部分,可以把許多手動提取的特征和相應(yīng)的分類方法看作是一個近似或特殊的CNN,然而為了保留有判別力的信息,這些特征和方法必須仔細(xì)設(shè)計和整合.受CNN在通用視覺識別任務(wù)上顯著成功的激勵,本文將CNN用于具有挑戰(zhàn)的音樂風(fēng)格識別,并研究了網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)的調(diào)整對識別率的影響.
Lee[9]是第一個把深度學(xué)習(xí)應(yīng)用于音樂內(nèi)容分析的人,特別是風(fēng)格和藝術(shù)家識別,通過訓(xùn)練一個有2層隱層的卷積深度置信網(wǎng)絡(luò)CDBN(Convolutional Deep Belief Network)以一種無監(jiān)督的方式嘗試使隱層激活,產(chǎn)生來自預(yù)處理頻譜的有意義的特征.相比較于那些標(biāo)準(zhǔn)的MFCCs(Mel Frequency Cepstral Coefficients)特征,其深度學(xué)習(xí)特征有更高的精準(zhǔn)度.對于音樂風(fēng)格識別,Li[10]等人將音樂數(shù)據(jù)轉(zhuǎn)化為MFCC特征向量輸入有3個隱層的卷積神經(jīng)網(wǎng)絡(luò)(CNN),最終得出可用CNN自動提取圖像特征用于分類的結(jié)論,表明CNN具有較強的捕獲變化的圖像信息特征能力.
本文主要進(jìn)行了以下幾個方面的工作:(1)使用HPSS算法分別從時間和頻率方面提取了音樂信號譜圖的諧波分量和沖擊分量,并將其和原始譜圖一起作為CNN網(wǎng)絡(luò)的輸入;(2)詳細(xì)設(shè)計了用于音樂風(fēng)格分類的基于CNN的深度分類框架,對有效訓(xùn)練一個可靠的CNN所需的多個關(guān)鍵因素進(jìn)行了研究和實驗證明.(3)本文使用對頻譜圖像進(jìn)行仿射以及使用PCA改變訓(xùn)練圖像中RGB通道的像素值的方法擴充數(shù)據(jù)集.
2 音樂風(fēng)格識別算法
本文基于卷積神經(jīng)網(wǎng)絡(luò)的音樂風(fēng)格識別的總體框架如圖1所示.首先使用HPSS算法對音樂曲目進(jìn)行分離,把原始曲目分離成諧波音源和沖擊音源;然后對這兩種音源及原始曲目分別作短時傅立葉變換,將變換后的譜圖輸入CNN網(wǎng)絡(luò)中進(jìn)行學(xué)習(xí),訓(xùn)練以及預(yù)測,最后的輸出結(jié)果即為最終的識別率.
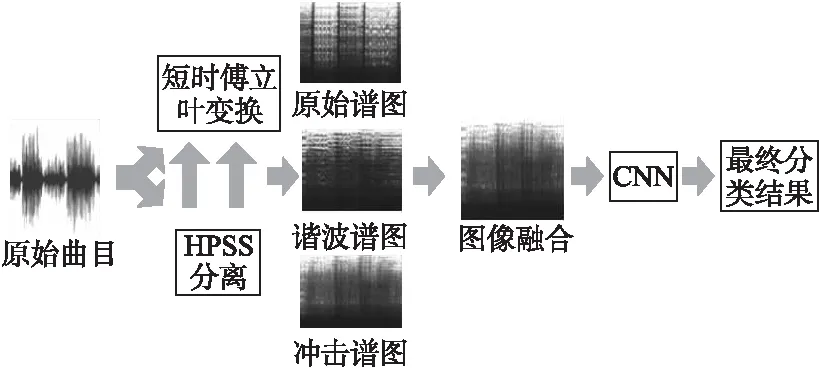
圖1 音樂風(fēng)格識別的流程圖Fig.1 Architecture for music genre classification
2.1 Harmonic/Percussive分離算法
音樂信號通常由諧波聲音成分和沖擊聲音成分組成,其具有非常不同的特性.本文使用了分離音樂信號的諧波和沖擊聲音成分的Harmonics /Percussion 分離算法,其本質(zhì)是基于頻譜圖的各向異性連續(xù)性的信號分離.這個方法的關(guān)鍵在于其側(cè)重于諧波頻譜和沖擊頻譜的連續(xù)方向的差異.諧波頻譜通常在時間方向上是連續(xù)的,沖擊頻譜在頻率上是連續(xù)的.圖2是某個音樂曲目的原始頻譜及分離后得到的諧波頻譜和沖擊頻譜.從圖中可以看出分離后的諧波頻譜是在某個固定的頻率上沿時間軸連續(xù)平滑分布,而沖擊頻譜是在時間軸上很短而沿頻率軸連續(xù)平滑分布,而原始頻譜中包含有縱向沖擊聲音與橫向的諧波聲音.
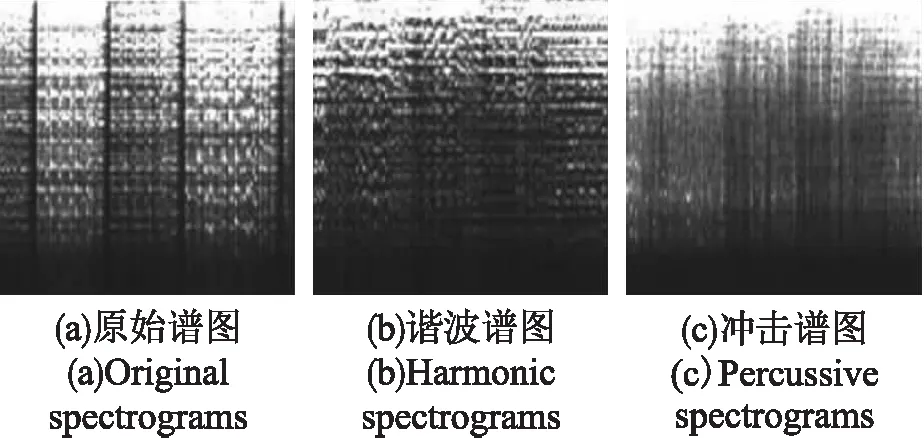
圖2 HPSS算法后的不同譜圖Fig.2 Different spectrograms with HPSS algorithm
2.2 網(wǎng)絡(luò)結(jié)構(gòu)
CNN的網(wǎng)絡(luò)結(jié)構(gòu)的前幾層作為特征提取器通過監(jiān)督訓(xùn)練自動獲取圖像特征,在最后一層通過softmax函數(shù)進(jìn)行分類識別.
本文的CNN網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示,其與傳統(tǒng)的AlexNet共享基礎(chǔ)框架.具體來說,它包含八層,前五層是與pooling層交替的卷積層,剩下三層是用于分類的全連接層.CNN網(wǎng)絡(luò)的輸入圖像是使用HPSS分離的諧波譜圖和沖擊譜圖以及原始音樂信號的譜圖,并將輸入圖像大小歸一化為256*256,然后將其輸入第一個卷積濾波器.在深層網(wǎng)絡(luò)結(jié)構(gòu)中,第一個卷積層利用96個大小為11*11、步長為4個像素(這是同一核映射中鄰近神經(jīng)元的receptive field中心之間的距離)的核對輸入圖像進(jìn)行濾波.接下來max pooling層將第一個卷積層的輸出作為輸入并和96個大小為3*3的核進(jìn)行濾波,響應(yīng)歸一化后,第二個卷積層和其輸出相連接并用256個大小為5*5的核對其進(jìn)行濾波.第三、第四和第五個卷積層相互連接,沒有任何介于中間的pooling或歸一化層,第三個卷積層有384個大小為3*3的核被連接到第二個卷積層的(歸一化的、pooling的)輸出.第四個卷積層擁有384個大小為3*3的核,第五個卷積層擁有256個大小為3*3的核.使用這五個卷積層,最終獲得了256個大小為6*6的特征圖,這些特征圖被饋送到分別三個含有4096,1000和10個神經(jīng)元的全連接層.最后一個全連接層的輸出便是最終的識別結(jié)果.
2.3 網(wǎng)絡(luò)訓(xùn)練和學(xué)習(xí)方法
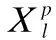
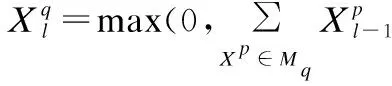
(1)
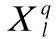
Pooling層使用的是Max Pooling,在卷積神經(jīng)網(wǎng)絡(luò)中卷積層和pooling層都是交替出現(xiàn)的.
輸出層與上一層完全連接,其產(chǎn)生的特征向量可以被送到邏輯回歸層完成識別任務(wù),所有網(wǎng)絡(luò)中的權(quán)重使用反向傳播算法[11]學(xué)習(xí).
本文使用隨機梯度下降SGD(stochastic gradient descent)訓(xùn)練網(wǎng)絡(luò)模型,發(fā)現(xiàn)較小的權(quán)重衰減對模型的學(xué)習(xí)非常重要,權(quán)重衰減可以減少模型的訓(xùn)練誤差,因此在本文的實驗中微調(diào)到0.0005.dropout是訓(xùn)練神經(jīng)網(wǎng)絡(luò)過程中一種防止過擬合的技術(shù),通常dropout和動量可以改善學(xué)習(xí)效果[12].由于所有層使用dropout會使網(wǎng)絡(luò)收斂花費很長時間,因此在本文的實驗中在全連接層設(shè)置dropout值為0.5,α=0.9,λ=0.0005.
本文的網(wǎng)絡(luò)結(jié)構(gòu)中總共有三個全連接層,最后一個全連接層即第八層是輸出層,第七層的輸出即為其輸入,其包含對應(yīng)m類音樂風(fēng)格的m個神經(jīng)元,輸出概率為p=[p1,p2,…,pm]T,使用softmax回歸公式如下:
(2)
其中X8是softmax 函數(shù)的輸入,j是被計算的當(dāng)前類別,j=1,…,m;pj表示第j類的真實輸出.
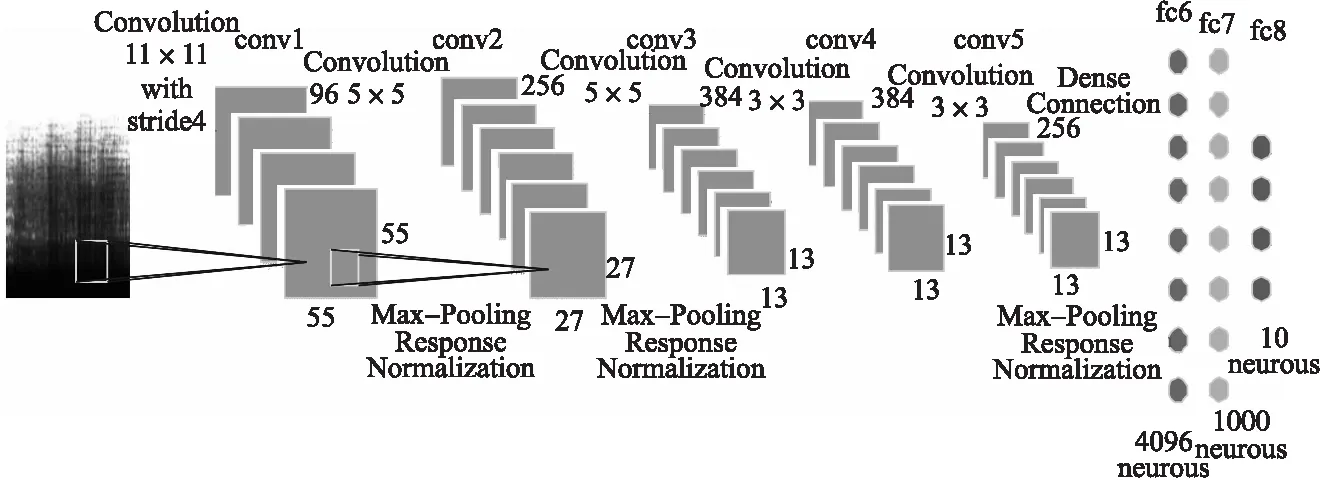
圖3 音樂風(fēng)格識別的CNN結(jié)構(gòu)圖Fig.3 Architecture of our deep convolutional neural network for music genre classification
3 實驗結(jié)果及分析
本文實驗中利用caffe框架來訓(xùn)練CNN模型以實現(xiàn)音樂風(fēng)格的識別.
3.1 數(shù)據(jù)集
使用識別率作為性能指標(biāo),在眾所周知的GTZAN風(fēng)格收集數(shù)據(jù)庫[13]上評估了所提出的方法.GTZAN數(shù)據(jù)集由Tzanetakis和Cook(2002)收集,由10種類型(藍(lán)調(diào),古典,鄉(xiāng)村,迪斯科,嘻哈,爵士,金屬,流行,雷鬼和搖滾)組成.每個風(fēng)格類別包含100個音頻錄音,長達(dá)30秒,共有1000個音樂節(jié)選.
3.2 參數(shù)優(yōu)化實驗
本文實驗表明了正確調(diào)整超參數(shù)的重要性,超參數(shù)可分為兩種:模型相關(guān)的超參數(shù)和訓(xùn)練相關(guān)的超參數(shù),如2.2節(jié)所示和表1所示.
為了調(diào)整這些超參數(shù),數(shù)據(jù)集按5:1的比例被隨機分為二個子集,即2500個音樂曲目用于訓(xùn)練,500個音樂曲目用于測試.
表1 訓(xùn)練相關(guān)的超參數(shù)
Table 1 Training-relevant hyper-parameters obtained

超參數(shù)學(xué)習(xí)率ηBatch-size動量系數(shù)μ權(quán)值衰減系數(shù)λDropout系數(shù)值0.01160.90.00050.5
根據(jù)Bengio[14]所述,參數(shù)要調(diào)整到訓(xùn)練集的錯誤率變得足夠小且穩(wěn)定的時候.通過該調(diào)整過程獲得的超參數(shù)總結(jié)在表1中.
訓(xùn)練相關(guān)的超參數(shù)可以顯著影響網(wǎng)絡(luò)的收斂和學(xué)習(xí)速率,它們的影響通過識別率曲線說明,如圖4-圖7所示.在每張圖中,我們集中于一個超參數(shù),而其他的則設(shè)置為表1中的最佳值.
圖4表示對訓(xùn)練樣本進(jìn)行20000次迭代,學(xué)習(xí)速率η比較小如0.001時,學(xué)習(xí)過程會非常緩慢,識別率也尚不穩(wěn)定.適當(dāng)提高η可以有效提高學(xué)習(xí)效率.同時若η過大如0.1會導(dǎo)致學(xué)習(xí)過程不穩(wěn)定并且降低分類性能.圖5和圖6分別說明了動量μ和權(quán)重衰減λ的影響.圖5表明使用動量μ可以很好地加快學(xué)習(xí)過程,同時,若μ偏大如0.97,會在初期階段引起振蕩,收斂較慢,此外,它降低了后期階段的分類性能.圖6說明了權(quán)重衰減λ的影響,表明較小的λ似乎是一個更安全的選擇,而較大的λ如0.005會破壞學(xué)習(xí)過程的穩(wěn)定性.

圖4 學(xué)習(xí)率η的影響Fig.4 Impact of learning rate
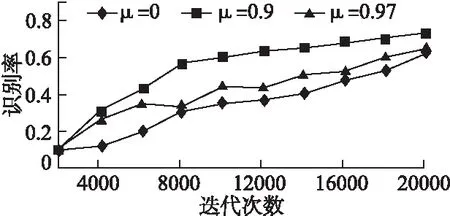
圖5 動量系數(shù)μ的影響Fig.5 Impact of momentum

圖6 衰減系數(shù)λ的影響Fig.6 Impact of weight decay
Dropout是訓(xùn)練神經(jīng)網(wǎng)絡(luò)過程中防止過擬合的一種技術(shù).在文獻(xiàn)[15]中,減少70%輸出的dropout應(yīng)用于最后一個全連接層.本文的實驗采取此技術(shù)并在每個回合中弄亂訓(xùn)練數(shù)據(jù)來減輕過擬合.在這種類型的研究中,通常以一定的概率將隱層神經(jīng)元的輸出設(shè)置為0,這樣此類神經(jīng)元對正向傳播和反向傳播都將不起任何作用,因此每輸入一個樣本,其都使用了不同的網(wǎng)絡(luò)結(jié)構(gòu)但權(quán)值又是共享的,這樣求得的參數(shù)就能適應(yīng)不同情況下的網(wǎng)絡(luò)結(jié)構(gòu),提高了網(wǎng)絡(luò)的泛化能力.本實驗將dropout微調(diào)為0.5或0.6,當(dāng)增大dropout值時,訓(xùn)練時間稍長一些,收斂較慢,該訓(xùn)練進(jìn)行了20000次迭代.基于CNN的分類器經(jīng)過20000次迭代后可以產(chǎn)生良好的分類性能.圖7顯示了不同的dropout值經(jīng)過不同的迭代次數(shù)有不同的識別率.
總之,CNN中的超參數(shù):學(xué)習(xí)速率η,動量系數(shù)μ,權(quán)重衰減系數(shù)λ和dropout值可以顯著影響網(wǎng)絡(luò)訓(xùn)練過程,在獲得滿意的分類性能之前必須仔細(xì)調(diào)整.在本文的實驗中,使用表1中設(shè)置的超參數(shù),在數(shù)據(jù)沒擴充的情況下,GTZAN數(shù)據(jù)集的識別率為73%左右.

圖7 dropout值的影響Fig.7 Impact of dropout
3.3 不同音樂風(fēng)格的識別率比較
表2以混淆矩陣的形式給出了關(guān)于音樂風(fēng)格分類更詳細(xì)的信息,其中列對應(yīng)實際的風(fēng)格,行對應(yīng)預(yù)測的類別,正確分類的百分比位于矩陣的對角線.由于有些音樂風(fēng)格之間的界限不分明,容易產(chǎn)生誤判,比如有的classical音樂的節(jié)奏比較強烈,容易被誤認(rèn)為是jazz音樂;而rock音樂由于其廣泛的特性容易被誤認(rèn)為其他風(fēng)格,所以其分類精度相比于其他風(fēng)格要低一些.
表2 GTZAN數(shù)據(jù)集的混淆矩陣
Table 2 Confusion matrix for GTZAN dataset

bluesclassicalcountrydiscohiphopjazzmetalpopreggaerockblues82.58.30.00.00.07.30.00.04.70.0classical10.274.60.00.00.012.50.00.00.00.0country0.04.591.70.00.00.00.00.00.00.0disco4.04.14.379.10.00.00.08.312.016.7hiphop0.00.00.00.075.60.00.00.08.10.0jazz3.38.20.00.00.076.20.00.04.50.0metal0.00.00.00.020.20.092.00.04.40.0pop0.00.00.012.00.04.00.082.70.016.0reggae0.00.00.00.00.00.00.00.964.38.4rock0.00.04.38.94.20.08.08.12.058.9
3.4 不同特征圖實驗比較
表3表明了手工提取時間序列和頻率序列的特征并以不同的組合方式放入CNN網(wǎng)絡(luò)訓(xùn)練,最后會得到不同的效果,其中把3種特征圖都輸入網(wǎng)絡(luò)時得到的識別率是最高的,說明只有當(dāng)訓(xùn)練的特征更全面時才能得到更好的結(jié)果.
表3 不同譜圖的識別率
Table 3 Classification rate for different spectrograms

圖片類型識別率Original Spectrograms67%Harmonic Spectrograms58%Percussive Spectrograms60%Original + Harmonic + Percussive Spectrograms73%
3.5 數(shù)據(jù)擴充實驗對比
本文主要使用仿射變換以及用PCA改變訓(xùn)練圖像中RGB通道的像素值這兩種方法對圖像數(shù)據(jù)進(jìn)行擴充.
表4是對音樂曲目的圖像進(jìn)行擴充后得到的實驗結(jié)果圖,從此表中可以看出擴充實驗數(shù)據(jù)對本實驗結(jié)果具有改善作用.因此數(shù)據(jù)擴充已經(jīng)成為生成更多圖像樣本和應(yīng)對各種差異獲得魯棒性的重要方式.然而本文的實驗結(jié)果識別率偏低,經(jīng)分析發(fā)現(xiàn):音樂曲目的變化是非常豐富的,因此使用100首曲目來代表一種特定類型的各種變體是不夠的,而且相較于8層的網(wǎng)絡(luò)結(jié)構(gòu)來說本文的訓(xùn)練數(shù)據(jù)是偏少的,以至于最終的分類結(jié)果不是特別理想.可以預(yù)見隨著音樂曲目的增多,本文的識別效果將會進(jìn)一步提升.
表4 擴充實驗數(shù)據(jù)后的識別率
Table 4 Classification rate with data augmentation

圖片類型識別率Original Spectrograms68%Harmonic Spectrograms60%Percussive Spectrograms63%Original + Harmonic + Percussive Spectrograms77%
3.6 與其他方法的準(zhǔn)確率對比
當(dāng)前有很多學(xué)者針對音樂風(fēng)格識別提出了不同的研究方法,如表5所示,Gwardys[16]也使用了HPSS算法獲得頻譜圖,而后微調(diào)了一個8層網(wǎng)絡(luò),最終獲得72%的準(zhǔn)確率,而本文使用此頻譜圖訓(xùn)練了此8層網(wǎng)絡(luò),準(zhǔn)確率有所提升.Lee[17]訓(xùn)練了一個只有2層的CDBN,其識別模型的深度比本文的淺,數(shù)據(jù)量也比本文的少,但實驗結(jié)果很接近本文擴充數(shù)據(jù)前的正確率,由此可見小數(shù)據(jù)集在淺層網(wǎng)絡(luò)里也能有較好的結(jié)果.楊松[18]運用了傳統(tǒng)機器學(xué)習(xí)方法中的K均值聚類來進(jìn)行音樂識別,其識別率為71%,本文提出的深度學(xué)習(xí)方法相比較下分類準(zhǔn)確率有一定的提升.
表5 本文方法與其他方法比較
Table 5 Comparison to other state-of-the-art methods
方法準(zhǔn)確率(%)Gwardys[16]72Lee[17]73楊松[18]71本文方法77
4 總 結(jié)
本文提出了一種基于卷積神經(jīng)網(wǎng)絡(luò)的音樂風(fēng)格識別方法,詳細(xì)設(shè)計了該方法使用的網(wǎng)絡(luò)框架并研究了一些影響其分類性能的關(guān)鍵因素.起初使用原始譜圖進(jìn)行實驗時,得到的識別率只有67%,為了改善結(jié)果,實施了harmonic/percussive分離實驗,最后識別率提高了6%.此外本次實驗表明了數(shù)據(jù)擴充的重要性和有效性,特別是訓(xùn)練數(shù)據(jù)不夠時,當(dāng)把本次實驗數(shù)據(jù)擴充后,實驗效果改善了3%.
本文的實驗取得了一定的識別率,使用了卷積神經(jīng)網(wǎng)絡(luò)的框架,再加上數(shù)據(jù)擴充等手段,使得深度學(xué)習(xí)應(yīng)用于小數(shù)據(jù)集成為可能,并取得了一定的判別能力.在將來的工作中,一方面通過搜集每種風(fēng)格更多的音樂曲目來提高識別率,另一方面可以構(gòu)造混合網(wǎng)絡(luò)結(jié)構(gòu),如卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò),可利用卷積神經(jīng)網(wǎng)絡(luò)提取局部特征,循環(huán)神經(jīng)網(wǎng)絡(luò)對這些提取的特征作時間上的整合,由于循環(huán)神經(jīng)網(wǎng)絡(luò)對前面的信息具有記憶功能,可使提取的特征更具有整體性和連貫性,提高識別結(jié)果.
猜你喜歡
參花(上)(2022年4期)2022-05-23 22:16:48
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
山東農(nóng)業(yè)工程學(xué)院學(xué)報(2020年3期)2020-06-24 06:01:54
樂府新聲(2019年2期)2019-11-29 07:34:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
兒童繪本(2017年24期)2018-01-07 15:51:37
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
東方藝術(shù)·大家(2016年6期)2016-09-05 07:30:56
太原城市職業(yè)技術(shù)學(xué)院學(xué)報(2014年11期)2014-02-27 07:39:26
