基于改進的密度峰值算法的K-means算法
2018-10-17 08:37:34杜洪波白阿珍朱立軍
統計與決策 2018年18期
杜洪波,白阿珍,朱立軍
(1.沈陽工業大學 理學院,沈陽 110870;2.北方民族大學 信息與計算科學學院,銀川 750021)
0 引言
數據的爆炸式增長是大數據時代到來的一個顯著性的標志。雖然,數據量是大的,但是,數據中蘊含的知識只是其中很小的一部分。如果能將數據中蘊含的知識提取出來加以利用會帶來重大價值。傳統的工具和軟件技術在處理大規模數據時已經顯得力不從心,因此,為了找出數據中有價值的知識,人們經過不懈地探索,發現了數據挖掘技術。而聚類分析是該技術的一個研究熱點,并且,往往用來做分類工作。
聚類分析(ClusterAnalysis)又被稱為群分析,為無監督學習,并且,它無需任何先驗知識就可以發現數據的分布模式[1,2]。“物以類聚”為它的關鍵特征。自聚類出現以來,出現了許多不同類型的算法來滿足聚類的不同需求和挑戰,其中包括基于劃分的聚類算法[3]、基于層次的聚類算法[4]、基于密度的聚類算法[5]、基于網格的聚類算法[6]和基于模型的聚類算法[7]以及近幾年提出的新的聚類算法[8]。
K-means算法是典型的基于劃分的聚類算法。由于其優點而在實際中被廣泛應用[9],但是,其也存在著一些缺點。學者們根據應用環境不同以及實際要求,以經典的K-means算法為基礎,針對其存在的多種缺陷,提出很多改進算法。
針對算法對初始聚類中心敏感的不足之處,薛衛等[10]提出一種空間密度相似性度量K-means算法,該算法利用可伸縮空間密度的相似性距離來度量數據點之間的相似度,并將密度和距離一起當作選擇初始聚類中心的相關因子,以及根據類內距離進行迭代的一種新的類中心迭代模型,實驗證明,該算法可得到更加合理的初始聚類中心。賈瑞玉等[11]基于密度的原理,通過對數據對象密度計算方式的再定義,并利用殘差分析從決策圖中自動確定K值和初始聚類中心。考慮到K值選擇的盲目性,張承暢等[12]提出一種基于密度的K-means改進算法,此算法定義了權值積,它是樣本密度、簇內樣本平均距離的倒數以及簇間距離三者的乘積,并通過最大權值積法解決最佳K值確定以及初始聚類中心問題。陳書會等[13]基于人工魚群原理提出了一種人工魚群和K-means相結合的IAFSA-KA算法[13]。為了解決運用歐式距離度量相似性而導致只能發現球狀簇的問題,肖琦[14]利用GSAGSA肘形判據、距離代價函數等算法優化確定最優聚類K值,并依據密度參數來提取合理的初始聚類中心。
DPC算法是2014年由AlexRodriguez和Alessandro在Laio Science上發表的一篇名為《Clusteringby fast searchandfindofdensitypeaks》的核心算法,文章一經發表就引起了眾多學者的關注。該算法簡潔而優美,并且其能夠快速發現任意形狀數據集的密度峰值點(即聚類中心),并且,能夠對樣本點進行高效率地分配以及有效地剔除離群點,容易確定參數,適用于大量數據的聚類算法。
DPC算法[8]對初始聚類中心的確定很有針對性,因此,該算法作為一個關鍵步驟而應用到數據挖掘中[15]。但是,該算法也存在一定的缺陷。謝娟英等[15]基于K近鄰思想提出的K-CBFSAFODP算法能夠很好地解決DPC算法密度度量準則不統一、一步分配策略的缺陷。Wang等[16]提出了一種通過使用原數據集潛在的熵的新方法來自動提取截斷距離dc的最佳值,通過實驗證明,利用數據場獲得的截斷距離dc比人工經驗獲得的聚類效果更好。關曉惠等[17]基于密度原理來確定聚類中心及其樣本點分配,彌補其需人為操作的缺陷。褚睿鴻等[18]在原有的DPC算法中引進一個合理的參數K,并將改進的DPC算法進行集成,從而自動完成聚類中心的選取,從而獲得最后的聚類結果。
實際上,每種聚類算法各有其適用范圍,并有其獨特的優勢以及一定的不足之處,通過眾多學者的研究發現,將某些聚類算法結合起來使用可以有效地提高聚類效率或準確率。
因此,為了克服K-means算法隨機選取初始聚類中心的不足之處,本文提出一種基于改進的DPC算法的K-means聚類算法。首先,運用改進的DPC算法來選取初始聚類中心;然后,運用K-means算法進行迭代得到聚類結果,從而,彌補了K-means算法隨機選取初始聚類中心可能導致易陷入局部最優解的缺陷;并且引入熵值法[19]計算距離優化聚類。
1 熵值法計算賦權歐式距離
為了更好地分析各個數據對象之間的差異,本文利用信息熵來計算各數據對象的賦權歐式距離。
在信息論中,信息熵是對不確定性的一種度量。信息量越大,不確定性越小,熵越小,權重越大;信息量越小,不確定性越大,熵越大,離散程度越小,權重越小[20]。它可以計算指標的離散程度。如果計算出的結果越大就說明該指標對綜合評價的影響(即權重)越大[21]。故,可運用信息熵計算各指標的權重,為綜合評價提供理論依據。算法的實現步驟如下:
假設數據集X有m個對象和n維屬性:


其中,xij是屬性值,Mij是數據對象xi第j維屬性所占比重值。
步驟2:按照等式(2)和式(3)分別計算第j維屬性的熵值與權值:
熵值:
步驟1:首先標準化數據對象的屬性:

權值:

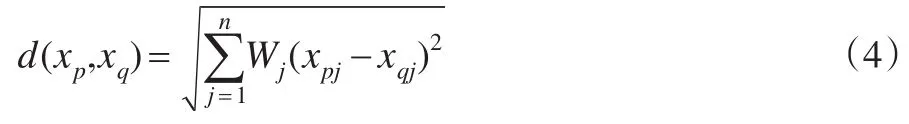
用賦權歐式距離度量相似度,可以精確得出各數據對象彼此間的差異程度,進而提高聚類精確度。
步驟3:計算賦權歐氏距離的公式如下:
2 K-means算法
K-means算法是由MacQueenJB在1967年首次提出的,是硬聚類算法。它的評價指標是距離,距離越小越相似,而最終目標是獲得緊湊并且獨立的集群[22]。
K-means算法中的K值表示要聚類數據集的聚類數,而means代表類簇均值。也就是說,該算法使用一個均值代表一個類簇的聚類中心。并且,該算法用歐式距離來度量數據對象之間的相似性,采用誤差平方和來評聚類效果。
K-means算法的目標函數為:
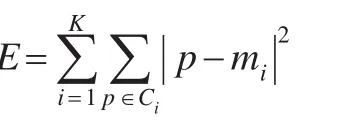
其中,E是數據集中的所有數據對象的平方誤差之和,p是數據集中的數據對象,mi是集群Ci的中心。
K-means算法描述如下:
輸入:包含n個對象的數據集和簇的數目K。
輸出:滿足目標函數E最小值的K個簇。
步驟1:從n個數據對象中隨機選擇K個對象作為初始聚類中心;
步驟2:對于剩余對象,按照其與聚類中心之間的距離,依據就近原則分配到相應的類簇;
步驟3:計算每個類簇的新均值,即新的類簇中心;
步驟4:回到步驟2,循環,直到不再發生變化。
由以上可知,K-means算法的特點是兩階段迭代循環、將數據對象的劃分不再發生變化作為循環終止條件。
3 改進的DPC算法
3.1 DPC算法
DPC算法是以聚類中心點由一些局部密度較低的數據對象所包圍,并且與任何具有較高局部密度的數據對象之間的距離相對較大為假設基礎。此外,為了防止一些分散的離群點被強制分配到類簇當中,從而造成聚類后類簇的邊界不清晰,進而影響聚類的效果,本文為每個類簇確定了一個邊界區域,再把數據對象進一步劃分為核心部分和光環部分(也就是噪聲)[8]。該算法首先定義了兩個量:局部密度ρi和距離δi。
對于數據對象i局部密度ρi:有cut-offkernel和Gaussiankernel兩種定義方法。
(1)cut-offkernel(對于較大規模數據集):


其中,dij為數據對象i和j之間的歐式距離,dc為截斷距離,由人工確定,通常將所有數據對象兩兩之間的距離按升序排列后前2%位置的數值距離作為截斷距離。
數據對象i的距離:
其中:
(2)Gaussiankernel(對于較小規模數據集):)

對于每個數據對象i,首先,需要計算局部密度ρi和距離δi,然后,根據計算得到的這兩個值畫出一個二維平面決策圖。
構造決策圖:

將γi進行降序排序,并以數據對象的下標為橫坐標,γ值為縱坐標構造決策圖,如圖1。可以發現,γ的值越大則數據對象是聚類中心的可能性就越大。而且,從圖1中可以發現,不是聚類中心的數據對象的γ值比較平滑,而在聚類中心的γ值轉換到非聚類中心的γ值時有一個非常明顯的跳躍,并且,無論是肉眼還是數值的檢測這個跳躍都能很容易判斷出來。從而,這個跳躍就是聚類中心與非聚類中心的分界線。
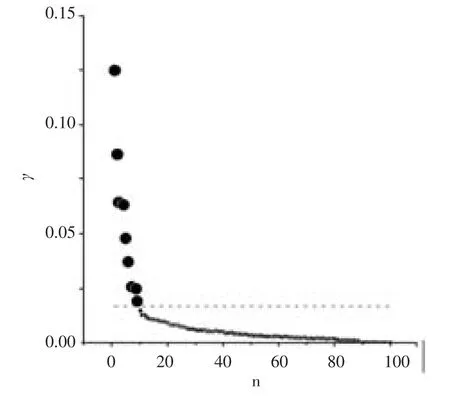
圖1 γ決策圖
當聚類中心選定后,對于剩余的數據對象則采用一種“跟隨”策略,歸屬到密度比其密度大的最近鄰所屬的類簇中,得到最終的聚類結果。
3.2 改進的DPC算法
由于在DPC算法中,局部密度ρi和距離δi的計算依賴于截斷距離dc,而文中的截斷距離dc是通過人工設置的,它是人工經驗方法,即使dc的選擇具有魯棒性,但是依舊缺乏理論依據。因此,本文介紹了一種選擇最優dc值的方法[23]。
步驟如下[23]:
對于數據對象i,令向量:
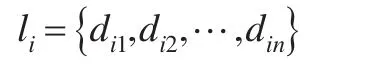
其中,dij(i,j=1,2,…,n;i≠j)為數據對象i到數據對象j之間的賦權歐式距離。將向量li按從小到大的順序進行排序,從而得到向量ci,即則數據對象i的截斷距離dci就可以定義為:

其中,max(ai(j+1)-aij)是向量ci中相鄰的兩個元素之差的最大值。
由圖2可以看出,同一類簇的數據對象之間的距離差距比較小,而不同類簇的數據對象之間的距離差距比較大,所以,在向量ci中,有兩個相鄰元素的差距會較大[23],即:
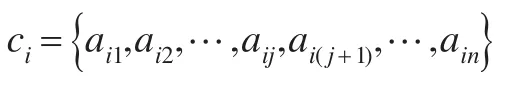
其中,aij=a,ai(j+1)=b。由圖2可認為數據對象是從一個簇跳躍到了另一個簇中,如果找到最大的差值則可找到理想的截斷距離dci,即:


圖2 截斷距離決策圖
本算法對于存在離群點的情形也適用,如圖3所示。
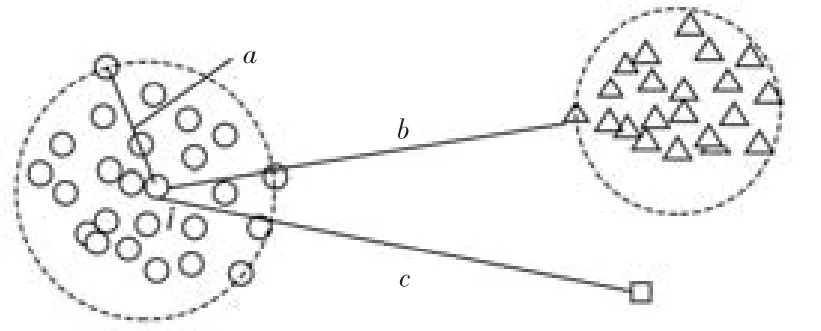
圖3 有離群點的情況
由圖3可知,在升序排序后獲得的向量ci中,相鄰兩個元素之差的最大值為:
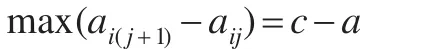
即aij=a,ai(j+1)=c。由式(9)可知,數據對象i的截斷距離為:

各數據對象i均分別有dci與其照應,因此,它們組成了一個集合Dc:
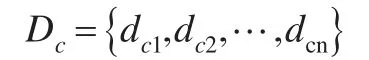
為了減少集群邊界上點和離群點的影響及避免dc過大,dc應取集合Dc的最小值,即:

這種確定截斷距離dc的方法與密度指標和距離指標相同,是基于數據對象之間的距離得到的,所以,不會增加額外的計算負擔。將式(10)帶入求各數據對象i的局部密度ρi的等式(5)或(6)和距離δi的等式(7),然后,求得ρi和δi,從而完成數據對象聚類過程。這種改進的方法為dc的選擇提供了依據,而且算法簡單、易實現。
4 改進的K-means聚類算法
針對K-means算法隨機選擇初始聚類中心進行迭代可能導致不穩定的聚類結果,本文提出一種改進的K-means算法,本文首先通過改進的DPC算法來選取聚類中心作為K-means算法的初始聚類中心;然后,使用K-means算法進行迭代,并且引入信息熵計算賦權歐氏距離[19],以便更準確地規范各對象之間的差異程度,從而更好地聚類。
本文算法描述:
輸入:含有n個數據對象的數據集合。
輸出:滿足目標函數最小值的K個簇。
步驟1:使用熵值法計算各數據對象之間的賦權歐氏距離dij,并令dij=dji,i<j,使其成為一個完整的矩陣;
步驟2:確定截斷距離dc;
步驟3:根據確定的截斷距離dc,并利用DPC算法中的方法計算每個數據對象i的ρi和δi;
步驟4:根據γi=ρi×δi,i=1,2,…,n,選擇聚類中心,γ越大越可能是聚類中心;
步驟5:確定聚類中心cj,j=1,2,…,K與K的值;
步驟6:計算剩余每個數據對象與各類簇的中心的距離,并將每個數據對象賦給距其最近的類簇,進行劃分;
步驟7:重新計算每個新簇的均值作為新的類簇中心;
步驟8:計算目標函數值;
步驟9:直到目標函數不再發生變化,算法終止;否則,轉步驟7。
5 實驗分析
5.1 實驗描述
為了驗證本文算法的有效性,選取UCI數據庫的Iris和Wine作為實驗數據集。實驗數據集的構成描述如表1:

表1 實驗數據集的構成描述
并與傳統的K-means算法以及文獻[16]中提出的算法K-CBFSAFODP進行了對比。
5.2 實驗結果分析
對于選擇的UCI中的數據集運用K-means算法、K-CBFSAFODP算法以及本文提出的算法進行聚類以后發現,本文提出的算法在聚類時間、聚類誤差平方和和聚類的準確率方面有所提升。
將本文算法得到的實驗結果與Iris數據集的實際中心進行比較,如表2所示:
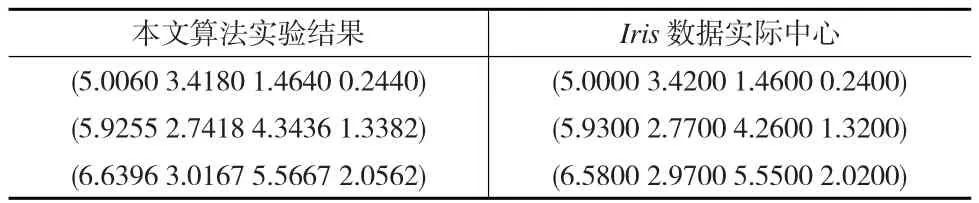
表2 本文算法實驗結果與Iris數據實際中心比較
從表2可以看出,本文算法得到的聚類中心與Iris數據的實際中心非常接近,從而能夠說明該算法對Iris數據比較有效。同理,該算法對Wine數據也比較有效。
本文算法的誤差平方和優于K-means、K-CBFSAF ODP算法,迭代次數優于傳統的K-means算法,如表3所示。
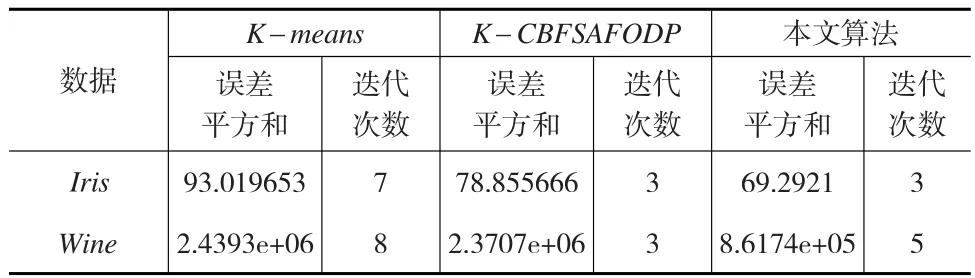
表3 誤差平方和及迭代次數的比較
由表3可以看出,在選擇的數據上本文算法的誤差平方和、迭代次數明顯優于傳統的K-means算法。而與K-CBFSAFODP算法相比,在Iris數據上,雖然兩算法迭代次數相等,但是誤差平方和稍微優于K-CBFSAFODP算法的誤差平方和。在Wine數據上,本文算法的迭代次數雖然比K-CBFSAFODP算法的大,但是其誤差平方和卻明顯優于K-CBFSAFODP算法。
聚類準確率也是衡量聚類結果的重要性指標。而三種聚類算法在UCI數據集上的聚類準確率的比較,如表4所示:

表4 聚類準確率的比較 (單位%)
從表4中可知,在聚類準確率方面,本文算法明顯優于傳統的K-means算法,同時,在Iris數據上本文算法優于K-CBFSAFODP算法,但是,在Wine數據上卻明顯優于K-CBFSAFODP算法。從而,能夠充分說明本文提出的算法具有較好的聚類效果。
6 結論
傳統的K-means算法隨機地選擇初始聚類中心進行迭代,可能導致不穩定的聚類結果,并且算法中的K值需要事先人為確定,因而導致限制了該算法的應用。本文提出的基于改進的密度峰值優化初始聚類中心的K-means算法能夠很好地解決前文敘述的兩點不足之處。利用改進的密度峰值算法選取初始聚類中心,并根據決策圖決定聚類個數K,這彌補了K-means算法的上述不足之處,接著利用K-means算法進行循環迭代,進而得到聚類結果。實驗表明該算法能夠得到較好的聚類結果。
