基于計數型布隆過濾器的可排序密文檢索方法
2018-10-16 08:23:50相中啟
計算機應用 2018年9期
李 勇,相中啟
(1.曲靖師范學院 信息工程學院,云南 曲靖 655011; 2.上饒師范學院 數學與計算機科學學院,江西 上饒 334001)
0 引言
隨著云計算技術的日益推廣,越來越多的用戶選擇將本地數據外包給云服務器存儲,以獲取高質量低成本的應用服務。然而,近年來不斷暴發的信息安全事件,尤其是2016全球“勒索”病毒事件的出現,引起了互聯網用戶對云計算環境下數據隱私安全性的廣泛擔憂。因此,必須對數據進行加密處理,以密文的形式在云中存儲數據,防止隱私信息的泄漏。數據以密文的形式在云中存儲,改變了數據之間原有的特性和關聯,使得傳統基于明文的數據檢索方法不再有效。可搜索加密技術以密文的方式建立安全檢索索引和保存數據,直接在密文狀態下完成對數據的檢索,不會泄漏任何明文信息,被廣泛地應用于云計算環境下對數據的隱私保護和密文檢索;但是,已有的可搜索加密方法存在數據查詢更新和刪除操作不方便、時間效率低、不支持對查詢結果按精確度進行排序等問題,因此,設計一種安全高效、操作方便、支持排序的密文檢索方法具有重要的理論意義和實用價值。
1 相關工作
可搜索加密技術起源于Song等于2000年在文獻[1]中提出的首個對稱可搜索加密(Symmetric Searchable Encryption, SSE)方案——基于密文掃描思想的對稱可搜索加密方案(Symmetric Searchable Encryption Scheme based on Ciphertext Scanning, SWP),但該方案不支持文件檢索索引,而是采用對稱加密技術將文件劃分為“單詞”進行加密,算法的存儲開銷大、時間效率極低。此后,國內外學者圍繞著如何提高可搜索加密算法的安全性、時間開銷、查詢精確度、可操作性等問題開展了大量的研究工作。2003年,Goh在文獻[2]中提出了基于索引的可搜索加密方案Z-DIX(Index-based Searchable Encryption Scheme),相比SWP方案有較大提升,但是,當檢索系統中的文件數目較多時,仍然需要耗費較長的檢索時間,效率較低。2006年,文獻[3]中,Curtmola等在Song等的基礎上,提出了SSE-1、SSE-2方案,進行文件檢索時,服務器只需要O(1)時間復雜度即可完成檢索操作,然而,在文件進行添加、刪除時,服務器需重新構建索引以適應更新狀態,索引維護開銷較大。針對文獻[3]中存在的索引維護開銷大、不支持文件動態更新的問題,文獻[4-6]對服務器中存放的密文文件的動態添加、更新或刪除操作進行了改進,提出了適合密文狀態下動態更新的算法。此外,對于如何提高密文檢索結果的精確度和排序問題,文獻[7]基于樹狀檢索結構提出了改進算法,但該算法存儲開銷較大。文獻[8]為減小存儲空間開銷,基于二叉樹構建了可排序文件檢索結構。針對文獻[7-8]中存在的索引維護開銷大和時間性能低的問題,文獻[9]中,提出了一種基于計數型布隆過濾器的分布式文本檢索模型(Text Retrieval Model based on Counting Bloom Filter, CBFTRM),但CBFTRM模型無法實現對查詢結果排序。文獻[10]提出了一種安全多關鍵詞密文排序檢索方案,但是該方案中對不同關鍵詞計算的相關性分數并不能有效地說明文件與關鍵詞之間的相關性高低,排序結果不夠精確。文獻[11]中首次提出了基于隱私保護的多關鍵詞模糊檢索方案,大幅提高了文件檢索效率和精確度。文獻[12]在文獻[11]的基礎上基于計數型布隆過濾器構建索引向量,使用MinHash算法對關鍵詞降維,減少了索引構建和查詢陷門生成時間,同時以計數型布隆過濾器索引向量的計數表示關鍵詞權重,對查詢結果排序,但是計數型布隆過濾器索引向量的計數并不能準確地表示關鍵詞與文件間之間的關系,對查詢結果的排序并不準確。
綜上所述,已有的可搜索加密技術方案在時間效率、檢索精確度、排序性能、索引更新能力等方面存在不足之處。為了對已有方案進行改進,本文基于計數型布隆過濾器提出一種適合云計算環境下的可排序密文檢索方法——基于計數型布隆過濾器的可排序密文檢索方法(Ciphertext Retrieval Ranking Method based on Counting Bloom Filter, CRRM-CBF)。首先,基于計數型布隆過濾器構建安全檢索索引,以實現對密文數據的高效檢索和索引的動態更新功能;然后,使用文件集中關鍵詞在文件中的出現頻率構建關鍵詞頻率矩陣;最后,使用詞頻逆文本頻率(Term Frequency-Inverse Document Frequency, TF-IDF)模型計算檢索關鍵詞與目標文件的相關度分值,根據檢索關鍵詞與目標文件的相關度分值來實現對文件檢索結果按精確度排序。
2 預備知識
2.1 計數型布隆過濾器
布隆過濾器(Bloom Filter, BF)起源1970年,由Burton Bloom在文獻[13]中首次提出,是一種高時空效率的數據結構,由一個很長的二進制向量和一組相互獨立的哈希函數組成,主要用于判斷某一個元素是否在某一個集合中:若某一元素經過一組相互獨立的哈希函數映射,輸出結果對應于布隆過濾器中向量位置序列的值全為1,則可判斷該元素屬于集合;反之,只要任意相應位置的取值不為1則可判斷該元素不屬于集合。BF只支持插入和查找操作,不支持刪除操作,是一種僅適合應用于靜態集合中元素判斷的簡單數據結構,對于動態集合中的元素判斷顯得無能為力。
計數型布隆過濾器(Counting Bloom Filter, CBF)[14]是一種在BF的基礎上進行改進的數據結構,它的基本原理是,將BF向量中的每一位擴展成一個計數器(Counter),插入元素時,如果有不同元素被r個哈希函數多次映射到同一位置,那么將對應位置Counter的值加1,刪除元素時,將對應位置Counter的值減1,CBF在BF的基礎上增加了刪除操作,支持集合中元素的動態更新,適用于動態集合中的元素判斷,如文件檢索、網頁去重等,BF與CBF的映射結構如圖1所示。
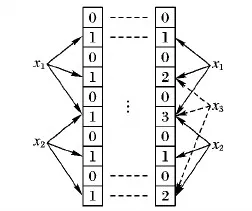
圖1 BF與CBF映射結構
2.2 TF-IDF模型
TF-IDF模型[15]是常用于信息檢索的一種加權統計方法,用于評價某一關鍵詞對于文件集合中的某一份文件的重要程度,由關鍵詞詞頻(Term Frequency, TF)和逆文檔頻率(Inverse Document Frequency, IDF)兩部分組成。其中,詞頻TF表示某關鍵詞在文件中出現的次數,定義為式(1):
(1)
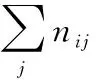
逆文檔頻率IDF表示某一關鍵詞在文件集合中的普遍性重要程度,通常用作關鍵詞的權重因子,定義為式(2):
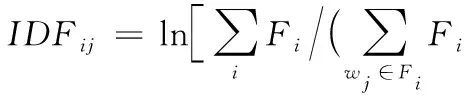
(2)
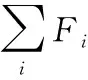
最后,TF-IDF模型以式(3)的值作為查詢關鍵詞與目標文件的相關度分值,并從大到小排序,返回用戶最感興趣的top-p個目標文件。
TF-IDF=TFij*IDFij
(3)
3 系統安全模型
云計算環境下可搜索加密系統的安全模型如圖2所示,由數據擁有者(Owner User, OU)、授權用戶(Authentication User, AU)、不可信云服務器(Cloud Server, CS)3部分組成。
1)數據擁有者:提取文件關鍵詞,構建文件檢索索引,并將索引和文件加密外包給云服務器。
2)授權用戶:輸入查詢關鍵詞,生成查詢陷門發送給云服務器,獲取感興趣的top-p個目標文件。
3)云服務器:根據密文索引和查詢陷門完成計算,給用戶返回感興趣的top-p個目標文件,同時負責密文索引的更新。
由于云計算系統都是在遵守用戶數據托管和通信協議的基礎下進行工作的,本文認為,云計算系統中的服務器是一個“誠實而好奇”的半可信實體,即,云服務器不會刻意地惡意攻擊系統、泄漏用戶隱私、或與其他非授權用戶合謀攻擊系統,但卻會出于“好奇”而挖掘用戶數據和推送應用服務、泄漏用戶隱私。因此,本文考慮選擇已知密文攻擊模型作為安全目標,在云計算系統通信環境下,云服務器或其他未授權用戶不能獲取任何明文信息,數據擁有者上傳的文件集、安全檢索索引,授權用戶的查詢請求及查詢結果等都以密文的形式存在,攻擊者只能選擇唯密文攻擊。

圖2 云環境下可搜索加密系統安全模型
4 CRRM-CBF方法
云計算環境中數據檢索具有數據量大、用戶數量多、檢索更新操作頻繁等特點,已有的需要線性搜索時間來逐次匹配密文信息且需要大量對數運算的可搜索公鑰加密方法顯然是不合適的,已有的排序密文搜索算法雖然計算量小、速度高,但是也存在查詢精確度不高的問題[16],因此,本文基于CBF提出一種可以實現精確密文排序的可排序密文檢索方法CRRM-CBF,下面詳細介紹CRRM-CBF方法的具體實現過程。
4.1 主要符號定義及說明
CRRM-CBF方法中所涉及到的一些主要符號定義及說明如下。
F:明文文件集合F=(F1,F2,…Fm)。
C:密文文件集合C=(C1,C2,…Cm)。
FID:集合F中對應文件的標識符集合FID=(FID1,FID2,…,FIDm),這里的FID是數據擁有者自己為了區分發布的文件而隨機分配的一個標識,不具有任何挖掘語義。
MID:集合F中對應文件在云服務器中的存儲標識符集MID=(MID1,MID2,…,MIDm)。
QID:與檢索關鍵詞相關聯的文件標識符集合QID=(QID1,QID2,…,QIDm1),QID?FID。
W:所有文件關鍵詞構成的集合W=(w1,w2,…,wn),關鍵詞允許在文件中多次重復出現。
ψ:關鍵詞在文件中的出現頻率次數構成的關鍵詞頻率矩陣。
I:將所有關鍵詞映射到CBF中,構成的文件檢索索引向量。
M:擁有k位存儲空間的映射向量,其長度允許動態增加,存儲關鍵詞映射的取值。
Cψ:關鍵詞頻率矩陣密文。
CI:文件檢索索引的密文形式,即安全索引。
Qw:檢索關鍵詞。
Q:檢索關鍵詞向量。
TQ:檢索陷門。
4.2 具體實現過程
CRRM-CBF方法的具體實現過程主要包括:
步驟1 Initial()初始化操作。數據擁有者OU從集合F中提取每個文件的關鍵詞,得到關鍵詞集合W,并對關鍵詞進行向量化處理。
步驟2 Preproc()預處理操作。數據擁有者OU統計各關鍵詞在文件中的出現次數記為ψij,表示關鍵詞wj在文件Fi中的出現次數,并以ψij值構造如(4)所示的關鍵詞頻率矩陣ψ。

(4)
在ψ的基礎上,計算集合F中各文件Fi中包含的關鍵詞數并記為NFi,wj,以及集合F中包含有關鍵詞wj的文件數并記為Nwj,F,其中,NFi,wj的計算公式如(5)所示,Nwj,F的計算公式如(6)所示:
(5)
Nwj,F={Nwj,Fi-1+1,i=i-1|ψij≠0,i=m,j=1,2,…,n|}
(6)
步驟3 BuildIndex_I()、CreatLink()構建文件檢索索引、關鍵詞與文件的關聯鏈表。數據擁有者OU先將W中的每個關鍵詞使用r個相互獨立的值域為[0,k-1)整數的哈希函數映射到CBF中的M向量,以此作為文件檢索索引。然后將索引向量中M[k]位置的計數器Counter擴展成如圖3所示的鏈表頭Link.head={M[k],Next},并在表頭的后面插入元素Link.element={FID,Next},插入的元素即為與M[k]位置上關鍵詞相符的文件標識符,Next為指向下一個元素的指針,尾部元素的Next指針指向Null。最后,得到文件檢索索引I和關鍵詞與文件的關聯鏈表,其結構如圖3所示。

圖3 關鍵詞檢索索引結構
步驟4 KenGen(k,n)產生安全密鑰。數據擁有者OU輸入安全參數k、n,使用概率密鑰生成算法生成安全密鑰sk=(M1,M2,M3,S,Pplu),并使用秘密通道將安全密鑰sk發給授權用戶,這里的秘密通道指采用Kerberos協議來完成對授權用戶的身份認證和密鑰分發,其中M1、M2為k階隨機可逆矩陣,M3為n階隨機可逆矩陣,S=(0,1)k為k位二元向量,Pplu為一個秘密的大素數。
步驟5 Enc(F,ψ,I,sk)加密。數據擁有者OU使用安全密鑰sk對文件集F、詞頻矩陣ψ、文件檢索索引I加密,同時使用MD5函數計算每個文件在云服務器CS中的存儲標識符MIDi=MD5(FIDi),最后,將得到的文件集密文C、詞頻矩陣密文Cψ、安全索引CI、存儲標識符MID一起上傳云服務器CS。
(7)
(8)
其中:ψ的加密過程如式(7),I的加密過程如式(8),I′、I″為I分解出來的兩個子向量,詳細的分解過程參考文獻[12]中的運算規則進行。考慮到高級加密標準(Advanced Encryption Standard, AES)對稱加密運算速率快、安全級別高,適合于加密大規模文件集,本文使用AES加密算法和密鑰Pplu對F加密得到密文文件C。
步驟6 Trap(Q,sk)產生檢索陷門,授權用戶AU輸入文件檢索關鍵詞Qw=(w1,w2,…,wj),并使用步驟3中的同一組哈希函數將查詢關鍵詞映射到CBF中的M向量,得到檢索向量Q。然后再采用步驟5相似的方法,使用安全密鑰加密檢索向量,輸出得到檢索陷門TQ,文件檢索陷門的生成公式如式(9),最后,將檢索陷門TQ發往云服務器CS。
(9)
步驟7 Ranking_Search(CI,Cψ,TQ)。密文檢索與排序的詳細過程如下:
1)云服務器CS收到授權用戶AU的檢索陷門后,首先進行安全索引CI與TQ之間的內積運算,以檢索與查詢關鍵詞相符的目標文件,詳細計算過程[11-12]如下。

I′T·Q′+I″T·Q″=IT·Q
根據上式文件檢索的計算結果,從關鍵詞與文件的關聯鏈表中找到與檢索向量中關鍵詞相符的文件標識符集QID,并將QID發送給授權用戶AU。
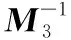
(10)
3)授權用戶AU根據關鍵詞頻率矩陣ψ,使用式(1)~(6)讀取并計算檢索關鍵詞的TF-IDF值,以此TF-IDF值作為區分QID中目標文件的相關度分值,并根據這個相關度分值從大到小對QID中的文件排序,返回授權用戶AU感興趣的前top-p個有序的目標文件的標識符。
4)授權用戶AU使用相同的MD5函數計算top-p個目標文件的MD5[top-p(QID)]值,并將MD5[top-p(QID)]的值依次發送至云服務器CS。
5)云服務器CS收到MD5[top-p(QID)]值后,根據MID值依次按順序將C中的top-p個密文目標文件發送給授權用戶AU,最后,授權用戶AU使用相同的解密算法AES和解密密鑰Pplu對前top-p個密文目標文件解密,還原得到排序的明文目標文件,完成整個通信過程。
5 性能分析
5.1 安全性分析
針對有關文件檢索索引、檢索陷門、關鍵詞頻率矩陣的安全性保護問題,本文借鑒了文獻[11-12]中的做法,隨機生成了可逆矩陣M1、M2、M3,二元向量S,對文件檢索索引向量、關鍵詞檢索向量及關鍵詞頻率矩陣進行加密,由于密鑰矩陣的空間是無窮大的,每次隨機產生的密鑰矩陣只有唯一的一個可逆矩陣,未授權用戶想要正確偽造密鑰矩陣生成檢索陷門、解密關鍵詞頻率矩陣的可能性為0,有效保證了文件檢索索引、檢索陷門、關鍵詞頻率矩陣的安全性;同時,為了保證不會因關聯檢索陷門的泄漏而泄漏隱私信息,本文還使用二元向量S對索引向量I進行分裂運算,針對同一個檢索向量產生兩個完全不同的陷門,保證了陷門的無關聯性。最后,在文件隱私和密鑰管理的安全性保護方面,本文分別使用AES對稱加密算法和Kerberos協議來完成對文件集的加密和密鑰的管理,有效保證了文件集和密鑰的安全性,其中AES算法和Kerberos協議的安全性在許多文獻已有詳細的證明,本文在此不再敘述。綜上所述,在保證密鑰sk不被人為泄漏的前提下,CRRM-CBF方法針對已知密文攻擊模型是安全的。
5.2 可更新能力分析

5.3 可排序能力分析
針對CBF構建索引不帶語義功能,不能實現對文件檢索結果排序的問題,本文在CBF索引的基礎上引入了關鍵詞文件關聯鏈表和關鍵詞頻率矩陣ψ,AU首先通過CBF索引判斷檢索關鍵詞是否屬于關鍵詞集W,若屬于,則在關鍵詞文件關聯鏈表中找到與檢索關鍵詞相關聯的目標文件FID,再通過FID在關鍵詞頻率矩陣ψ中讀取檢索關鍵詞的出現頻率,使用TF-IDF模型統計計算檢索關鍵詞對目標文件區分能力的相關度分值,最后,就可以按相關度分值對文件檢索結果實現排序,并且,查找鏈表和詞頻矩陣兩次比對過程還可以消除CBF索引的假陽性概率。
5.4 效率分析
為了較好地評測CRRM-CBF方法在文件檢索時的時間開銷、檢索精確度方面的性能。本文以安然公司郵件數據集(Enron Email Dataset, EED)作為實驗真實數據集[17],從中隨機選取文件,基于Java程序設計語言,使用開源開發環境Apache-tomcat-7.0.23、MyEclipse2014、JDK1.7,開源分詞器MMSEG4J來實現方案,并在Intel Core i5-3230 2.60 GHz雙核心CPU、2.0 GB RAM內存、Windows 7 64位操作系統平臺上進行實驗測試。
5.4.1 檢索時間開銷
文件檢索的時間開銷主要受文件集的規模、文件檢索索引的效率、檢索陷門的生成時間、檢索結果的排序機制影響,可以較全面地衡量一種可排序密文檢索方案的整體性能,也是衡量系統服務質量的一項重要性能指標。為了較客觀地評價本文CRRM-CBF方法與文獻[11-12]中方法在文件檢索時間方面的性能,本文分別以CRRM-CBF方法、文獻[11-12]中方法構建文件檢索索引和檢索陷門進行測試。1)實驗設定輸入10個檢索關鍵詞、返回top-10個結果為目標文件,隨機從數據集中選取100、200、300、400、500、600、700、800、900、1 000個文件進行文件檢索測試,實驗測得文件檢索的時間開銷如圖4(a)所示。2)實驗設定分別輸入1、5、10、15、20、25、30個檢索關鍵詞、返回top-10個結果為目標文件,在1 000個文件中進行文件檢索測試,實驗測得文件檢索的時間開銷如圖4(b)所示。

圖4 3種方法文件檢索時間開銷比較
圖4(a)顯示,用10個關鍵詞為輸入在不同文件集規模下進行文件檢索的時間開銷結果為,文獻[12]中方法最低,本文方法接近于文獻[11]中方法;圖4(b)顯示,在文件數為1 000檢索關鍵詞數不同的情況下文件檢索的時間開銷結果為,在檢索關鍵詞數量小于5個的情況下,本文方法接近于文獻[12]方法而略優于文獻[11]中方法,隨著關鍵詞數量的增加,本文方法基本接近于文獻[11]中方法而漸差于文獻[12]中方法,主要原因是,3種方法的索引建立和陷門生成機制都基本相同,不同的是,文獻[12]使用了MinHash算法對關鍵詞進行了降維處理,生成文件索引時需要的哈希函數運算次數較少,減少了構建文件檢索索引的時間開銷,但對比圖4(a)與圖4(b)中的結果發現,這種降維處理的效果在少量關鍵詞檢索時的時間開銷優勢并不明顯。文獻[11]中方法相比本文方法雖然少了對檢索結果排序的時間開銷,但在構建索引時卻多了相似度計算的時間開銷,而本文方法的排序只是對常數項關聯文件和精確詞頻的讀取與計算,其算法時間復雜度為O(1),當關鍵詞數量較少時,檢索結果中與關鍵詞相關聯的文件并不多,也就是說,詞頻讀取與計算的時間開銷并不大。因此,總體上來講,本文方法的文件檢索時間開銷是較小的。
5.4.2 檢索精確度
查詢精確度是衡量密文檢索系統服務質量的另一項重要性能指標,為了客觀地測評本文方法與文獻[11-12]中方法在文件檢索精確度方面的性能,實驗設定從數據集中隨機選取1 000個文件、輸入10個檢索關鍵詞、返回top-10個結果作為目標文件,測試在返回的top-10個結果中關鍵詞的相關度分值,以此衡量文件檢索結果的精確度,測試結果如圖5所示,相關度分值越高,表明檢索結果越精確。圖5中結果顯示,本文方法檢索精確度最高,而文獻[11]中方法最低,其主要原因是,文獻[12]僅以索引向量的計數為關鍵詞權重建立排序機制,其排序精確度受假陽性概率影響,所以排序精確度偏低,本文方法則建立精確的詞頻矩陣,依據詞頻矩陣來計算文件檢索關鍵詞區分目標文件的相關度分值相對文獻[12]來講更加精確可靠。最后,文獻[11]中由于沒有建立有效的排序機制,所以精確度最低。

圖5 3種方法文件檢索精確度比較
6 結語
本文基于計數型布隆過濾器提出了一種適用于云計算環境下密文檢索和排序的方法CRRM-CBF。通過構建CBF索引向量,實現了文件的密文檢索和索引的動態更新,同時,考慮到CBF構建的索引向量本身不帶語義功能,不能實現對目標文件的精確排序功能,文中引入了詞頻矩陣和TF-IDF模型計算關鍵詞區分文件能力的相關度分值,有效地實現了對目標文件的排序功能。最后,從理論上對方法的安全性能力、可更新能力和可排序能力進行了分析,通過實驗測試分析了方法的文件檢索時間開銷和檢索精確度,證明了方法的可行性和有效性,但不足之處是,本文方法在實現排序的過程中,由于引入了詞頻矩陣和文件關聯鏈表,增加了存儲空間和索引更新開銷,因此,下一步的研究方向是進一步減少存儲空間和索引更新開銷。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
