基于Hadoop的流媒體轉碼系統設計
2018-10-12 06:41:06
山東農業工程學院學報 2018年9期
關鍵詞:系統
(三明學院 現代教育技術中心,福建 三明365004)
1、前言
近年來流媒體用戶快速增加,如何以最低的成本來滿足所有用戶的流媒體需求是現今網絡內容服務業者關切的熱點。由于網絡帶寬的限制以及多樣化的多媒體設備與視頻格式,網絡內容服務業者將視頻傳遞到用戶必須通過視頻轉碼,將視頻流媒體轉換成相對應的視頻格式,視頻轉碼的用途主要是將視頻流進行壓縮以減少數據量的傳遞[1,2]。分布式視頻轉碼是將一視頻切割成許多區塊,再把這些區塊分配給多臺服務器主機進行視頻轉碼工作,轉碼完成后再將各個區塊合并成一個視頻文件,此方法可提高視頻編碼的效率,降低用戶觀看視頻的等待時間[3,4]。然而傳統分布式視頻轉碼系統,軟硬件設備的更新維護及擴充,對于網絡內容服務業者成本而言是相當大的負擔,網絡內容服務業者為了架設分布式轉碼服務器,必須耗費額外工作量,人力成本也極高[5,6]。為了克服軟硬件擴充的問題,并改善編碼時間,可將分布式轉碼計算應用在云服務系統上。云服務系統可提供可靠且更安全的網絡資料儲存,在軟硬件設備更新與擴充都由云服務支持,使用者只需租用云服務器即可使用軟硬件設備;在成本方面,相較于自行架設服務器,租用云服務系統器成本較低。研究基于云服務使用Hadoop分布式文件系統(HDFS)儲存視頻區塊,并利用MapReduce框架與FFmpeg視頻編碼軟件進行分布式轉碼,可實現云服務器視頻串流轉碼系統,以提高視頻觀看的流暢性。
2、相關研究
2.1 云計算技術
云計算架構主要可分為以下三層:基礎設施服務(Infrastructure as a Service,IaaS),像是 Amazon 隸屬的Amazon EC2與S3;平臺服務 (Platform as a Service,PaaS),如 Amazon Web Service 和 Google APP Engine;軟件服務(Software as a Service,SaaS),例如Microsoft的網絡更新服務與Google Maps等[7]。
基于云計算的Hadoop基礎設施服務構架,主要分為HDFS與MapReduce兩部分。HDFS采主從式(Master/Slave)架構,由一個名稱節點(name節點)與多個數據節點(data節點)這兩種角色組成。一般部署情況下,Master上只運行一個名稱節點(name節點),負責處理文件系統的管理及儲存,并記錄文件的各個數據區塊放置在具體的數據節點(data節點)上。而在每一個Slave上皆有一個數據節點(data節點),負責處理用戶存取數據區塊上的請求,并定時回復數據區塊的狀態給名稱節點(name節點)。當有任何一個數據節點(data節點)損壞時,名稱節點(name節點)作重做操作[8]。Hadoop MapReduce主要架構是由Map與Reduce兩個函數所組成,Map函數的輸入為一組key/value序對,輸出則為多組inter mediate key/value序對組。Reduce函數則將相同inter mediate key的value做合并動作,最后產生輸出結果key/value序對,MapReduce流程如圖一所示。

圖1 MapReduce流程圖
2.2 視頻轉碼模式
目前視頻轉碼的模式可以分成三大類,分別為:(1)單機模式:使用單一機器或服務器來進行視頻轉碼的工作。這種模式的優點就是操作與維護都較簡單,但缺點就是擴展性差,且轉碼速度將受限于單一機器的效能。此外,一旦涌入大量的轉碼需求時,系統將無法及時地處理這些工作。(2)分布式計算模式:同時使用多臺機器(包括服務器)進行視頻轉碼的工作。在進行視頻轉碼工作前,系統會將輸入的視頻文件分割成較小的視頻片段,之后將每個片段傳送到不同的機器上進行轉碼,在完成轉碼后,再將每個轉碼后的視頻片段傳送到特定機器上進行合并。這種模式的優點是轉碼時間短,且可以應付大量的轉碼工作需求;但缺點就是實作上較單機模式復雜,且須考慮單一機器當機以及轉碼程序在任一機器上執行錯誤時的處理方式。(3)云計算模式:使用現有云服務提供商,如Amazon的Elastic Compute Cloud(EC2),來執行視頻轉碼的工作。其中,EC2提供的一個實例就可以負責處理一個視頻轉碼的任務,這種模式的優點就是無需管理系統的硬件,成本控制也更靈活[9,10]。
3、非實時性視頻轉碼系統
3.1 視頻轉碼需求分析
視頻轉碼可以根據輸入數據的特性分成兩大類,其一是針對已存在的視頻數據進行轉碼的工作;另一類則是針對實時性的視頻數據進行轉碼的工作。針對第一種類型的數據來說,系統設計的目標就是希望視頻轉碼的時間越低越好。然而,針對第二種類型的文件來說,系統設計的目標就不是盡可能地降低視頻轉碼的時間,而是在不高于一指定的時間下,讓系統可以同時處理越多的視頻轉碼工作越好。例如,假設實時性視頻幀率是每秒30幀,則轉碼系統就只須在33毫秒處理完一個幀的畫面即可達到即時性的要求。
為了達到上述的目標,可以通過將視頻轉碼這項工作平行化來降低轉碼的時間或增加系統負載量。平行化指的是將視頻轉碼這項工作分割成若干件較小的工作,且這些工作彼此間不存在任何的相依性,也就是任一工作無需等待其他工作執行完畢后才能開始執行。因此,若這些分割后工作不存在任何相依性時,就可以將這些工作同時分派至分布式計算平臺上不同的節點來處理,以達到上述的目標。
對于已存在的視頻數據來說,平行化的方式就是將輸入的視頻數據分割成數個較小的視頻塊,并把每個分割好的視頻塊傳送到不同的節點上進行轉碼。另一方面,對于實時性的數據來說,平行化的方式有兩種,分別為:(1)基于幀率來平行化:這類作法就是將輸入的視頻文件復制成N份后(N取決于輸出的幀率),將每一份交由分布式計算平臺上的一個節點來處理。(2)基于圖像群組(Group of pictures,GOP)與幀率來平行化:這類的作法就是先將輸入視頻文件以GOP為單位切成較小的視頻塊,接著根據輸出的幀率數復制數份視頻塊,并把每個復制后的視頻塊傳送到不同的節點上進行轉碼[11]。
3.2 非實時性視頻轉碼系統設計
非實時性視頻轉碼系統的輸入是需要轉碼的視頻文件和使用者的配置文件,輸出則是轉換后的視頻文件。在目前的系統中,輸出的文件有兩種不同的形式,一種是單一數據,另一種是分割后的數據。其中,產生第二種形式的目的是為了便于跟HLS或DASH等標準整合。第二種形式的文件就可以直接輸出至特定的HTTP服務器來發布。整個非實時性視頻轉碼系統主要包含有視頻封裝格式轉換器、視頻數據分割器與視頻編解碼器,視頻封裝格式轉換器的功能就是將輸入的視頻文件轉換成視頻文件分割器可以處理的文件格式。為了減少視頻文件分割器的操作復雜度,目前視頻數據分割器只接受特定的視頻封裝格式。因此,在對視頻文件進行分割前,系統就得對輸入的視頻文件進行格式上的轉換。通常,格式轉換的速度非常的快,基本上是不會增加太多的轉碼時間[12]。
根據實驗結果,在CPU4核的配置上,視頻封裝格式轉換器的處理速度可以達到約每秒一千多幀(對1080P的視頻)。在格式轉換后,第二步就是視頻分割,將格式轉換后的視頻分割成較小的視頻塊,對于壓縮后的影片來說,一個GOP就是一個最小的處理單位。在視頻分割時,若影片的某一段GOP邊界恰好不在整數秒時,影片分割的結果將可能大于或小于使用者設定的秒數,例如,當影片分割的單位被設為10秒時,視頻文件分割器分割后的結果可能是8.x秒,也有可能是10多秒,這主要取決于GOP邊界的位置。影片分割的下一步就是對每個視頻塊進行轉碼,在對每個視頻塊進行轉碼前,先把每個視頻塊上傳到Hadoop平臺上的文件系統,也就是HDFS,之后再調用FFmpeg轉碼程序來進行轉碼。在Hadoop平臺上所使用的編程模型是MapReduce。在系統中,Map函數是轉碼程序,每個Map函數的輸入是一個視頻塊,各個云計算節點接收視頻塊并進行轉碼,轉碼完成后,通過Reduce函數完成視頻的合并,由于在本系統中因為配置文件有記錄了每個視頻編號信息,Reduce函數只執行將轉碼的結果排序并轉發到流媒體服務器,流媒體服務器依據配置信息推送視頻流到用戶設備上,從而實現非實時性視頻轉碼,如圖2。
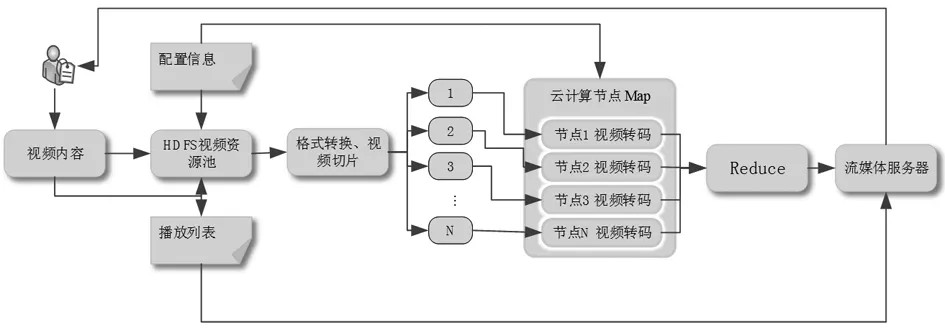
圖2 基于hadoop系統流媒體轉碼結構設計
4、實驗方法與結果
4.1 實驗方法
實驗為了測試非實時視頻轉碼系統的執行效率,通過計時獲取視頻轉碼的時間。測試方案如下:(1)在相同節點數目下,不同視頻輸出格式所需視頻轉碼時間。(2)在不同節點數目下,不同視頻輸出格式所需視頻轉碼時間。(3)在相同節點數目下,不同的視頻塊大小對于視頻轉碼時間的影響。
實驗采用Hadoop0.20.203版作為系統的軟件平臺。硬件的部分,每臺節點配置4核CPU,內存8GB。每臺節點間千兆網絡連接。在本實驗中,輸入是一段長度為10秒的影片,其中影片是采用H.264的影像壓縮技術,影片的分辨率為1920x1080(1080P),幀率為 30fps,碼率為 3500kbps;聲音的部分則是采用AAC的壓縮技術,聲音的采樣頻率為44kHz,碼率為125Kbps。輸出的部分主要差異是在影像的分辨率與碼率上的不同。表1為本實驗輸入與輸出的視頻文件格式列表。
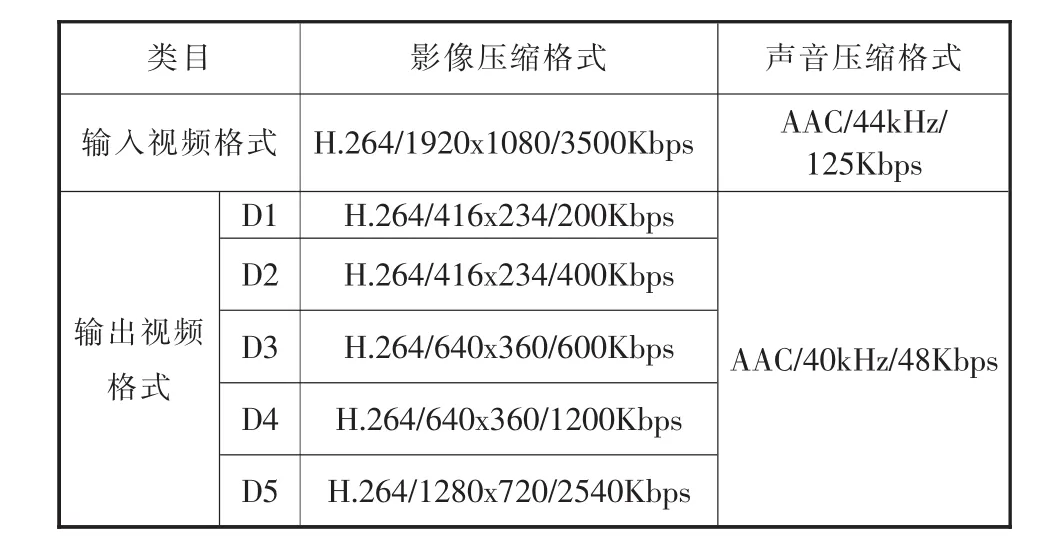
表1 視頻輸入輸出格式
4.2 實驗結果
通過測試在相同節點數目下,不同視頻輸出格式所需視頻轉碼時間,如圖3是在相同節點數目下(在這個實驗中,節點數目是3臺),不同幀率與分辨率所需的轉碼時間,T1、T2、T3代表的是三次實驗的結果,Avg則是這三次實驗的平均值。從圖3的數據中,可以看出:第一,轉碼時間的長短主要取決于分辨率而非幀率,這點可以從比對200K與400K以及600K與1200K來看出;第二,對于五種輸出格式,三次實驗所得到的結果會有所差異。造成這樣差異的主要原因是在于轉碼程序執行錯誤的比例,以及在不同時間可能存在的不同系統開銷。

圖3 不同分辨率轉碼時間比較
根據經驗,在通過Hadoop來執行轉碼程序時,通常會有約1~2%左右的程序發生錯誤。此時,Hadoop就會將這些發生錯誤的程序移除后,再到其他節點上從新執行。由此一來,這將會增加整個轉碼時間。因此,若轉碼程序執行錯誤的比例越低時,則整個轉碼時間就會越短。然而,根試驗的經驗,轉碼程序執行錯誤的情況還具有隨機性。

圖4 不同節點數量轉碼時間比較
通過測試得到了在不同節點數目下,不同視頻輸出格式所需視頻轉碼時間,如圖4中1節點表示在單一節點且無使用Hadoop的情況下所需的轉碼時間,2節點與3節點則是在使用2與3臺節點且使用Hadoop的情況下所需的轉碼時間。從圖4中不難發現,當節點數目增加時,視頻轉碼時間就會隨著下降,相較于單一主機的情況,在一個擁有3個節點的Hadoop系統上執行視頻轉碼,平均節省38.64%轉碼時間,如表2所列。
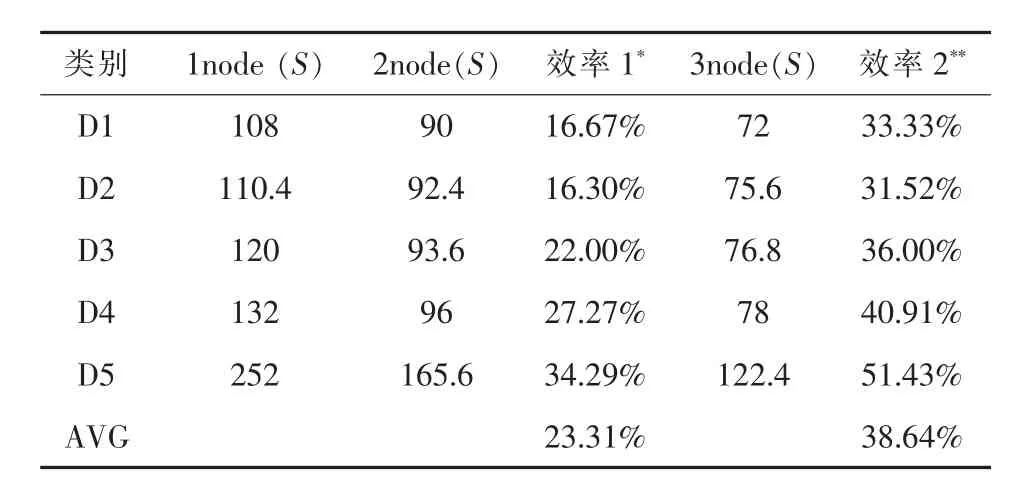
表2 不同節點數量轉碼時間及效率提高情況比較(單位:S)

圖5 不同數據塊長度轉碼數據比較
通過測試在相同節點數目下,不同的視頻塊大小對于視頻轉碼時間的影響,如圖5是在相同節點數目下,就趨勢上來看,視頻轉碼的時間是反比于視頻塊的大小,當視頻塊大小增加時,視頻轉碼的時間通常會跟著下降,造成這現象的主因是網絡傳輸與啟動視頻轉碼程序的時間成本。此外,因為目前架構的系統只有3臺節點,而每個節點上只有4顆CPU核心,也就是最多同時只能執行12個轉碼程序。因此,當文件切割后的視頻塊個數大于12時,有些文件就無法平行地被處理。當系統的節點數足夠多時,視頻塊越小,則可以平行處理的視頻塊個數就越多,此時整體的轉碼時間就可以縮短。因此,視頻塊的大小應該是取決于系統里的節點個數。
5、結論與討論
本文主要針對HLS與DASH等串流標準提出了一套云計算視頻轉碼系統,根據實驗的結果顯示:(1)在轉碼時間上,本實驗設計的系統有著相當不錯表現,較于單一主機的情況,在一個擁有3個節點的Hadoop系統上執行視頻轉碼,平均節省38.64%轉碼時間;(2)不同的視頻塊大小對于視頻轉碼時間的影響,就趨勢上來看,視頻轉碼的時間是反比于視頻塊的大小,當視頻塊大小增加時,視頻轉碼的時間通常會跟著下降,造成這現象的主因是網絡傳輸與啟動視頻轉碼程序的時間成本。
根據實驗的觀察,如果使用Hadoop平臺作為實時性視頻轉碼系統,由于處理延遲的影響,很難滿足實時性視頻的需求,尤其是HLS與DASH等串流標準本身就存在一定的處理延遲。如果針對非實時性與實時性的視頻轉碼需求分別各設計一套專用的視頻轉碼系統,在管理上又將造成使用效率不高。因此,最好的方式就是針對HLS與DASH等串流標準開發一套可以同時支持非實時性與實時性的視頻轉碼服務的通用視頻轉碼系統。此外,通過通用圖形處理器(GPGPU)來加速視頻轉碼程序在每臺機器上的執行效率也是一個值得探究的方向。因此,在后續的研究,將持續朝這兩大方向來發展。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
