基于卷積神經網絡的熱軋帶鋼力學性能預報
2018-10-08 10:50:18胡石雄李維剛
武漢科技大學學報 2018年5期
胡石雄,李維剛,2,楊 威
(1. 武漢科技大學冶金自動化與檢測技術教育部工程研究中心,湖北 武漢,430081; 2. 武漢科技大學高溫材料與爐襯技術國家地方聯合工程研究中心,湖北 武漢,430081)
當今鋼鐵市場競爭日益激烈,如何在不斷改善鋼鐵產品組織性能的同時,縮短產品研發周期、降低生產成本,已成為鋼鐵企業亟需解決的問題。熱軋帶鋼的力學性能預報是目前階段鋼鐵冶金企業開發的重點技術之一,具有廣闊的應用前景。現有的帶鋼力學性能預報模型的建模思路大致分為兩種[1]:一種是機理建模,主要是基于實驗室物理冶金學的實驗結果,建立模型來預測產品的力學性能,如Irvine和Pickering提出了利用數學模型預測鋼材組織演變及力學性能的方法;另一種是數據建模,根據實際生產數據,利用神經網絡等智能算法來預測鋼材的力學性能,如賈濤[2]、Bhattacharyya[3]等均建立了相應的性能預報模型。以上兩種建模方法都取得了不錯的成果,但也有不足之處:機理建模多以鋼種為單位進行研究,局限性強;BP神經網絡各層之間以全連接方式進行連接,不能很好地表達出影響因素之間復雜的交互作用關系。
卷積神經網絡(Convolutional Neural Network,CNN)是近年來特別熱門的深度神經網絡模型。相比于傳統神經網絡,卷積神經網絡采用的局部連接(Locally-connection)方式,有效減少了需要計算的參數個數。另外,權值共享方法可以使圖像具有平移不變性,下采樣操作可使圖片具有一定的縮放不變性。目前,卷積神經網絡結構已被廣泛應用于自然語言分析、模式識別、圖像處理等領域,但在工業生產領域內的研究應用尚不多見。
基于此,本文提出了一種將一維數值型數據轉換成二維圖像型數據的建模方法,并基于卷積神經網絡結構LeNet-5和GoogLeNet,建立了熱軋帶鋼力學性能預報模型,代入實際生產數據并通過對比實驗對所建模型的有效性和準確性進行了驗證。
1 相關工作
1.1 LeNet-5卷積網絡結構
卷積神經網絡LeNet-5[4]的基本結構如圖1所示。由圖1可知,該網絡結構主要包括輸入層、卷積層(Convolutional layer)、下采樣層(Subsampling)、全連接層(Full connection)和輸出層,其中卷積層和池化層(Pooling)交替出現,構成一個特殊的隱層。值得注意的是,輸入圖像需要經過大小歸一化處理,每一個神經元的輸入來自于前一層的一個局部鄰域,并且被加上由一組權值決定的權重。提取到的這些特征在下一層相結合形成更高一級的特征,并且同一特征圖的神經元共享相同的一組權值,次抽樣層對上一層進行壓縮,在減少數據處理量的同時保留了有用信息。

圖1 LeNet-5卷積神經網絡
1.2 GoogLeNet卷積網絡結構
GoogLeNet[5]是2014年Christian Szegedy提出的一種全新的卷積神經網絡結構,共有22個卷積層,相比于AlexNet[6]和VGG[7]等深度卷積神經網絡結構,GoogLeNet在增加了網絡深度和寬度的情況下,具有更少的參數和更小的計算量,其完整結構如圖2所示。

圖2 GoogLeNet卷積神經網絡
1.3 預測方法的融合
在LeNet-5和GoogLeNet網絡結構基礎上,本文提出了兩點重要改進:一是將全連接甚至是一般的卷積均轉化為稀疏連接[8],二是提出應用Inception結構于網絡模型中,即在保證網絡結構稀疏性的同時,又能利用密集矩陣的高計算性能。Inception結構模塊如圖3所示。在Inception結構中,筆者采用了不同大小的卷積核進行特征提取,最后將提取到的不同尺度特征進行堆疊(Concatenation)。相比于單一的卷積核,Inception結構具有更強的適應性。由于使用5×5的卷積核會帶來巨大的計算量,故采用1×1的卷積核進行降維處理[8]。
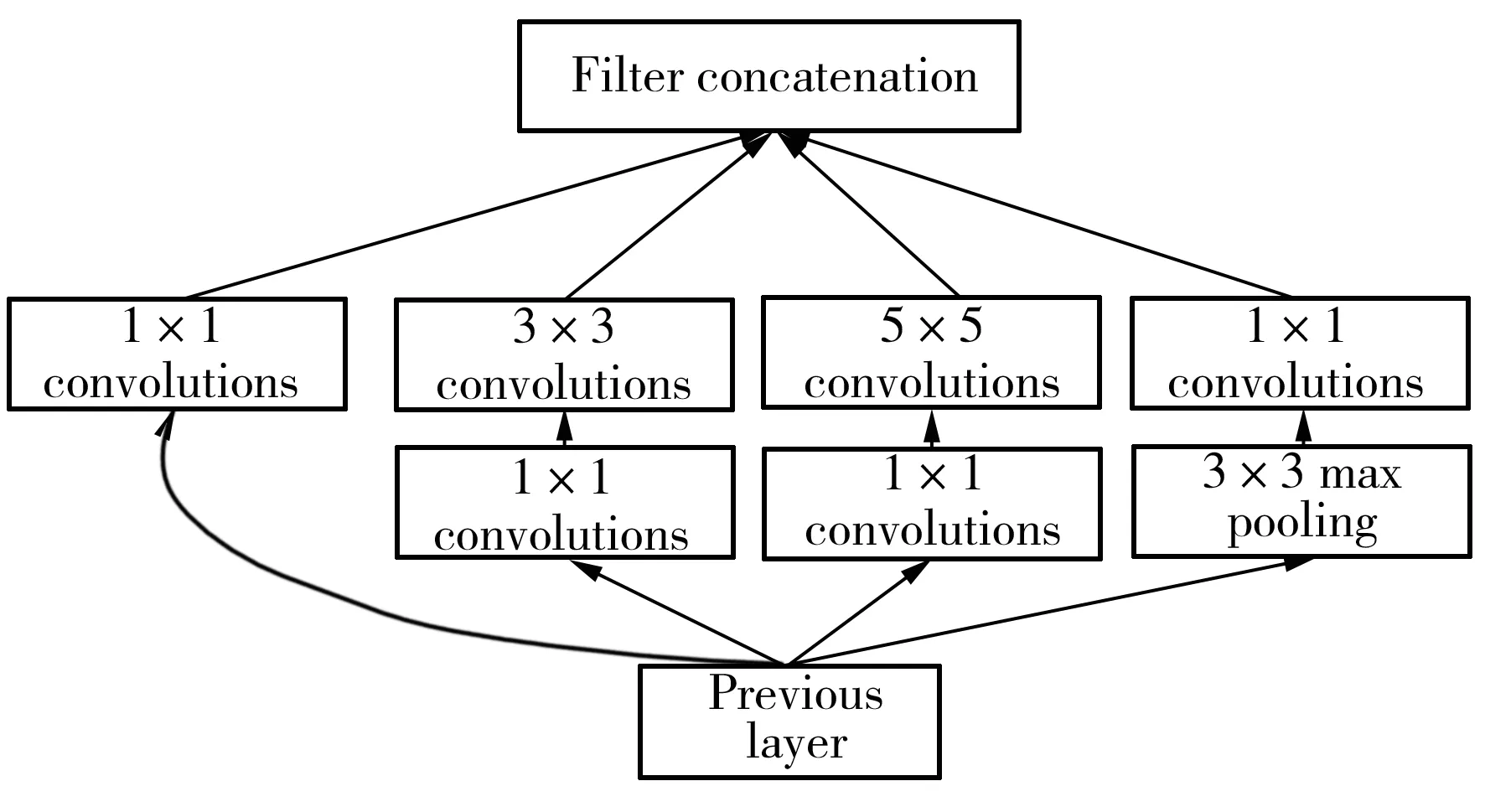
圖3 Inception模塊結構示意圖
2 帶鋼力學性能預報模型的設計
2.1 數據獲取與預處理
獲取某大型熱連軋生產線的歷史實際生產數據,基于隨機森林算法和冶金機理篩選出重要影響因子,并剔除掉一些不可見干擾因素[9],最終得到44 760條帶鋼數據,每條數據中含20個影響因子和一個響應變量抗拉強度(Ts),所得實驗數據集的具體組成如表1所示。
從表1中可以看出,具有不同特征維度的影響因子的表征含義、數量級及量綱單位不同,直接用于訓練會影響模型精度,并且容易陷入局部最優解。因此,在開始訓練前,需要對輸入數據進行歸一化處理,使各項數據指標之間具有可比性。原始數據經過標準化處理后,各指標處于同一數量級,模型收斂速度有所提升。
BP神經網絡通常采用一維數值型數據進行建模,連接方式如圖4(a)所示。由圖4(a)可知,全連接層中每一個神經元均與輸入數據中任一影響因子相連,無法表達出影響因素之間的局部交互作用關系,且需要計算的參數較多,故卷積神經網絡采用如圖4(b)所示的局部相連方式。
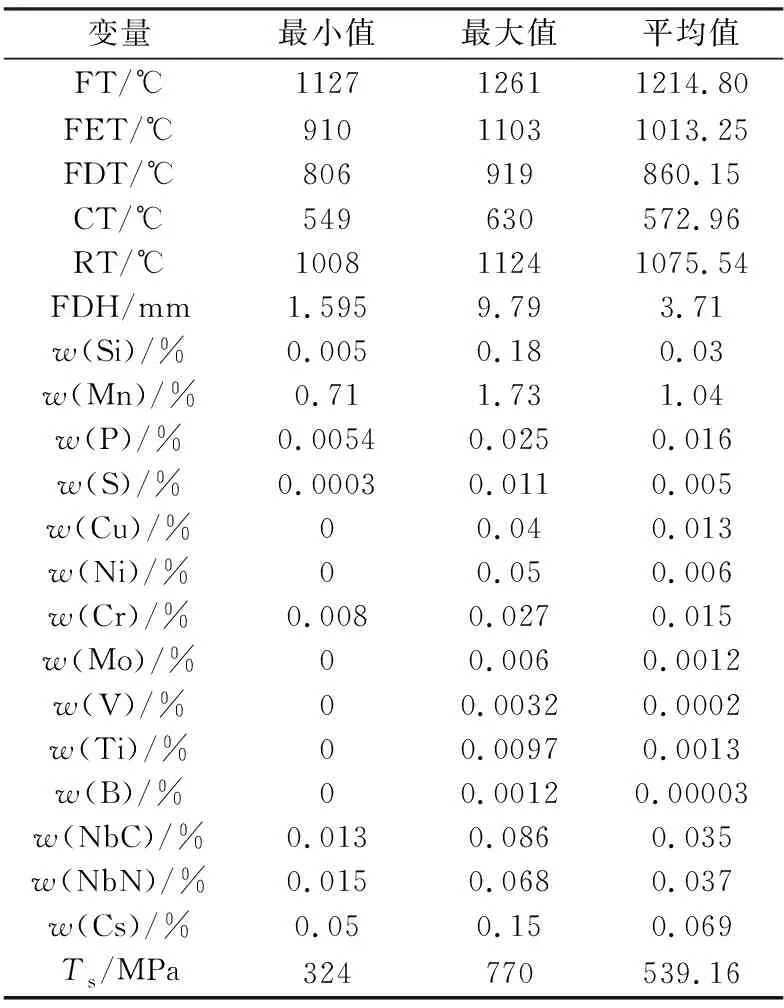
表1 實驗數據集的組成
注:FT為出爐溫度;FET為精軋入口溫度;FDT為終軋溫度;CT為卷取溫度;RT為粗軋出口溫度;FDH為終軋厚度。
在對圖片進行卷積處理的過程中,影響因子通過不同大小的卷積核與周圍其它影響因子局部相連,從而得到影響因子之間的局部交互作用關系。由于卷積核具有權值共享特性,故相比于BP神經網絡,卷積神經網絡具有更少的參數和更小的計算量。數字圖像本質是一個多維矩陣,而傳統的一維數值型數據表示的是一個一維矩陣,將一維數值型數據轉為二維圖像型數據實際是將多個一維矩陣進行拼接的過程。相比于一維數值型數據,二維圖像型數據信息結構更為豐富,進行特征提取時能獲取的有效信息更多。
在進行數據轉換之前,首先需要確定圖像的尺寸,即圖像的高和寬。由于圖像高和寬的乘積需要遠遠大于影響因子個數,故決定將一維數值型數據轉換成大小為32×32的二維圖像型數據,

(a)BP神經網絡 (b)卷積神經網絡
圖4不同神經網絡的連接方式
Fig.4Connectionmethodofdifferentneuralnetworks
其中共包含1024個像素點。依次將與帶鋼力學性能相關的20個影響因子填入1024個像素點中,每個像素點值的大小代表圖片中該點位置顏色的深淺,每個影響因子被填入51次左右。該步驟主要是利用Python編程完成的,大致轉換過程如圖5所示。
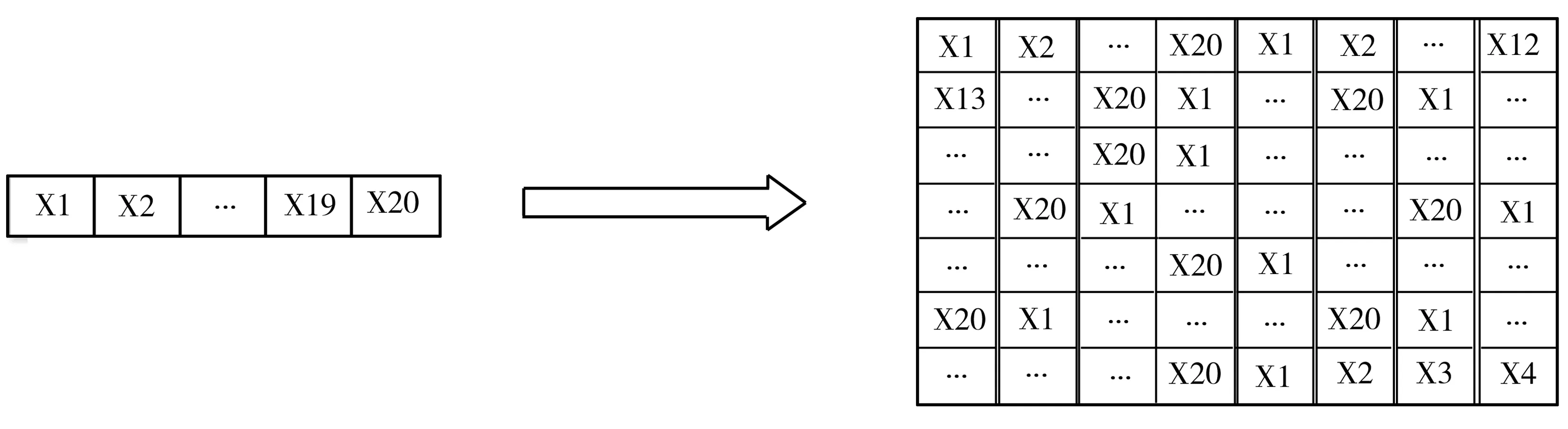
圖5 數值型數據轉換成圖像數據過程示意圖
2.2 模型結構確定
由于本文所建立的熱軋帶鋼力學性能預報模型的影響因子較少,直接使用較深的卷積神經網絡結構難以取得好的效果,而使用太淺的模型結構精確度往往不高,故需要進行對比實驗來確定模型中卷積層的層數。本研究利用Inception結構替代LeNet-5結構中的卷積層,選取均方根誤差(RMSE)和平均絕對百分誤差(MAPE)作為模型準確性的評價指標,即:
(1)
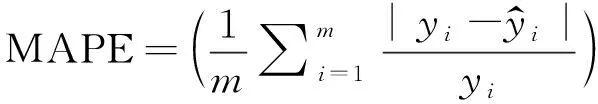
(2)
其余參數相同時,不同Inception結構數量下模型的計算偏差如表2所示,可以看出,當Inception結構個數選取為3時,模型具有較高的預報精度。
表2不同Inception結構個數的實驗結果
Table2ExperimentalresultswithdifferentInceptionnumbers
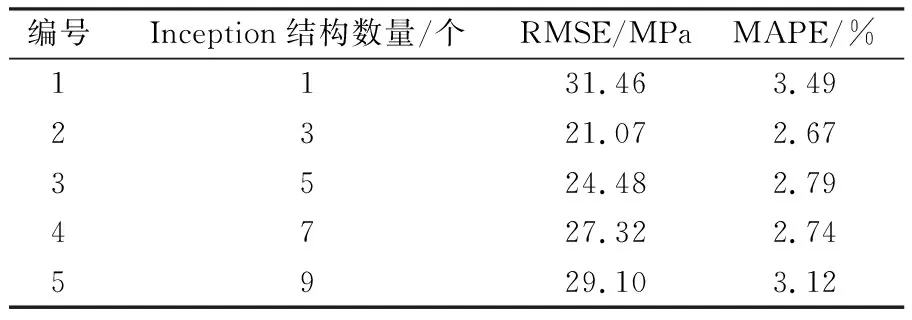
編號Inception結構數量/個RMSE/MPaMAPE/%1131.463.492321.072.673524.482.794727.322.745929.103.12
圖6即為本研究采用的卷積神經網絡模型結構。考慮到輸入圖像尺寸(32×32)較小,故不適合使用太大的卷積核和步長,本文所用卷積核最大為5×5,步長均為1。輸入圖像經過Inception1進行特征提取之后,接一個最大池化層(Max pooling),卷積核大小為3×3,步長為2。該模型中的池化層均采用最大池化,這是因為相比于平均池化(Average pooling),最大池化能更有效地減少卷積層參數誤差所造成的估計均值偏移,其原理如圖7所示。
從圖6中可以看出,模型經過Inception3之后接一個全連接層FC1,模型中最下方的FC2與輸入圖像直接相連,采用的是全連接方式,其能在一定程度上對卷積神經網絡提取特征起到補充作用。最后將FC1和FC2提取到的特征進行融合,經過全連接層FC3后得到輸出結果。

圖6 本研究采用的卷積神經網絡模型結構
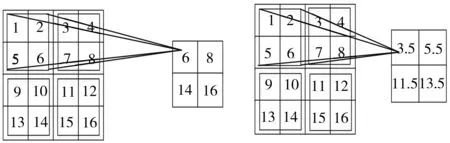
(a)最大池化 (b)平均池化
圖7最大池化和平均池化的原理示意圖
Fig.7Schematicdiagramofmaxpoolingandaveragepooling
模型中采用的的激活函數均為ReLU函數,可表示為:
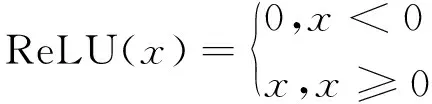
(3)
LeNet-5模型中,激活函數為Sigmoid函數,表示為:
(4)
相比于Sigmoid函數,ReLU函數有以下優點:①選取Sigmoid函數為激活函數,當Ni=f(Wi?Ni-1+bi)過大時,函數導數趨于0,這會造成信息丟失,降低模型的準確性。②當Ni=f(Wi?Ni-1+bi)<0時,ReLU激活函數的輸出為0,在一定程度上造成了網絡的稀疏性,這不僅減少了參數之間的相互依存關系,還緩解了過擬合問題;③ReLU函數的求導計算相對簡單。
2.3 卷積神經網絡模型訓練
卷積神經網絡模型不斷通過訓練樣本進行學習,在信息的前向傳播中求出預測值,并與實際值比較得到誤差。若誤差超過設定閾值,則進入誤差反向傳播階段,在此階段不斷更新權重和偏置,直到預測值與實際值的誤差低于閾值且誤差不再下降時停止訓練,得到最終需要的熱軋帶鋼力學性能預報模型。
3 實驗與結果分析
3.1 實驗環境
本實驗在Windows10 64bit 操作系統下進行,CPU為Intel(R) Core(TM) i7-6700,內存為16GBDDR4,GPU為NVIDIAGeForceGTX745(4 GB顯存),顯卡驅動為CUDA8.0+CUDNN5.1,編譯環境為TensorFlow+Python3.5.2。采用開源深度學習工具TensorFlow作為卷積神經網絡框架,并利用GPU加速整個訓練過程。
3.2 參數選取
實驗開始之前,需要配制卷積神經模型的相關參數,具體數值如表3所示。表3 中,Learning_rate表示學習率;Iteration_nums表示模型訓練次數,如果模型的代價函數低于設定閾值且基本不再變化時,也可主動終止訓練;Batch_size表示每次讀入圖片的批量,該值的選取需要根據實際輸入圖片的大小以及計算機內存和顯存的大小關系來確定,本研究使用GPU加速訓練,故需要保證每次讀入批量圖片小于顯存大小;Dropout表示以一定概率舍棄神經元,其能有效防止過擬合的發生。
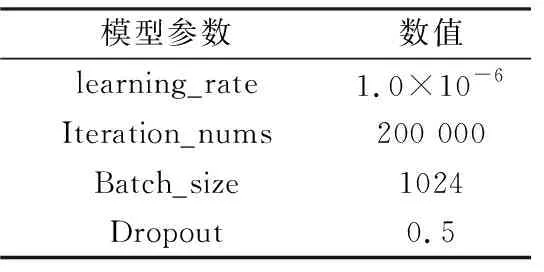
表3 模型參數
選取44 760條數據中的后4760條數據作為測試集,剩下的40 000條數據作為訓練集。關于卷積核數目與神經元數目的選取,本文采用如表4所示的Inception模塊參數以確定最優解。表4中Inception1、Inception2和Inception3的6個參數分別代表Inception結構中從上往下卷積核Conv1×1+1(S)、Conv3×3+1(S)、Conv1×1+1(S)、Conv5×5+1(S)、Conv1×1+1(S)和Conv1×1+1(S)的個數,FC1和FC2表示全連接層FC1和FC2的神經元個數,FC3中神經元個數為FC1和FC2中神經元數目之和。每次實驗訓練到代價函數趨于穩定才終止。從表4可以看出,采用第6組Inception參數的模型預測精度最高,模型MAPE值為2.49%,RMSE值為19.15 MPa。
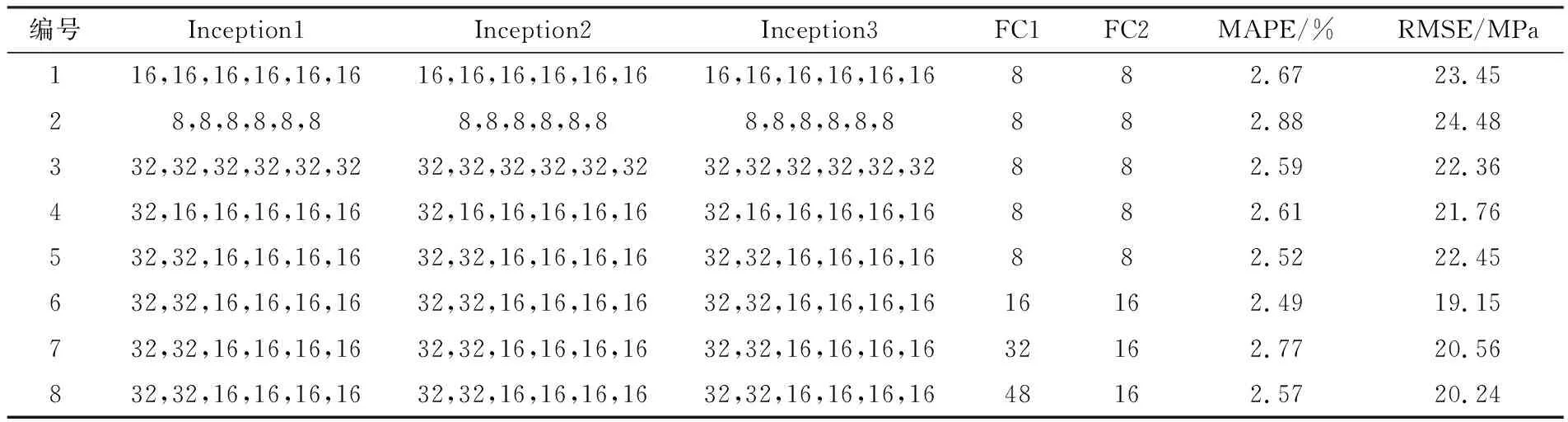
表4 不同Inception參數下的測試結果
3.3 結果分析
選取第6組Incepion模塊參數作為本文模型采用的參數,得到模型中損失函數值(Loss)與訓練次數的關系如圖8所示。從圖8中可以看出,模型訓練12 000次左右時已趨于穩定,在不增加數據量的情況下,模型的Loss值基本保持不變。故從測試集中取100條數據的預測值與實際值進行對比,結果見圖9。由圖9可知,基于本文所建模型的帶鋼抗拉強度預測值與實際值擬合情況較好,模型的適用性得到了驗證。
為進一步驗證所建模型的有效性,利用BP神經網絡、LeNet-5和GoogLeNet三種模型分別對測試樣本進行帶鋼力學性能預測,并選用均方根誤差和平均絕對百分誤差作為模型精度的衡量指標,結果如表5所示。由表5可見,本文所建模型的誤差指標均低于其他模型的預測值,而直接利用卷積神經網絡GoogLeNet模型的預測精度低于其他方法,盡管其深度優于LeNet-5和本文所建模型,表明在熱軋帶鋼力學性能預報問題上模型的預測精度并不完全取決于模型深度。另一方面,LeNet-5模型中,卷積層數目較少且卷積核過于單一,模型的提取特征能力不夠,適應性不強,導致其預測效果不佳。
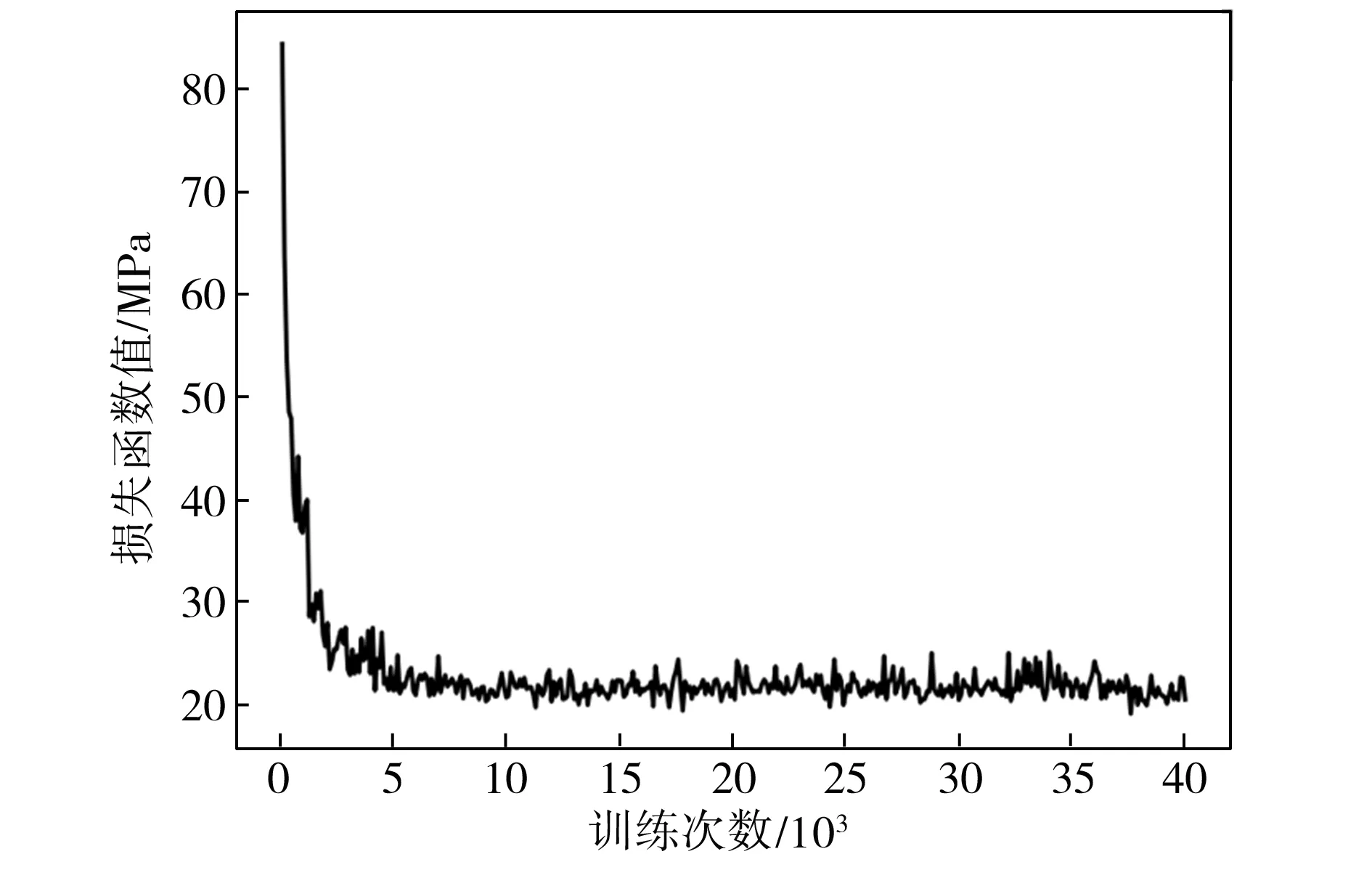
圖8 損失函數值隨訓練次數的變化
Fig.8VariationofLossfuctionvaluewiththeiterationtime
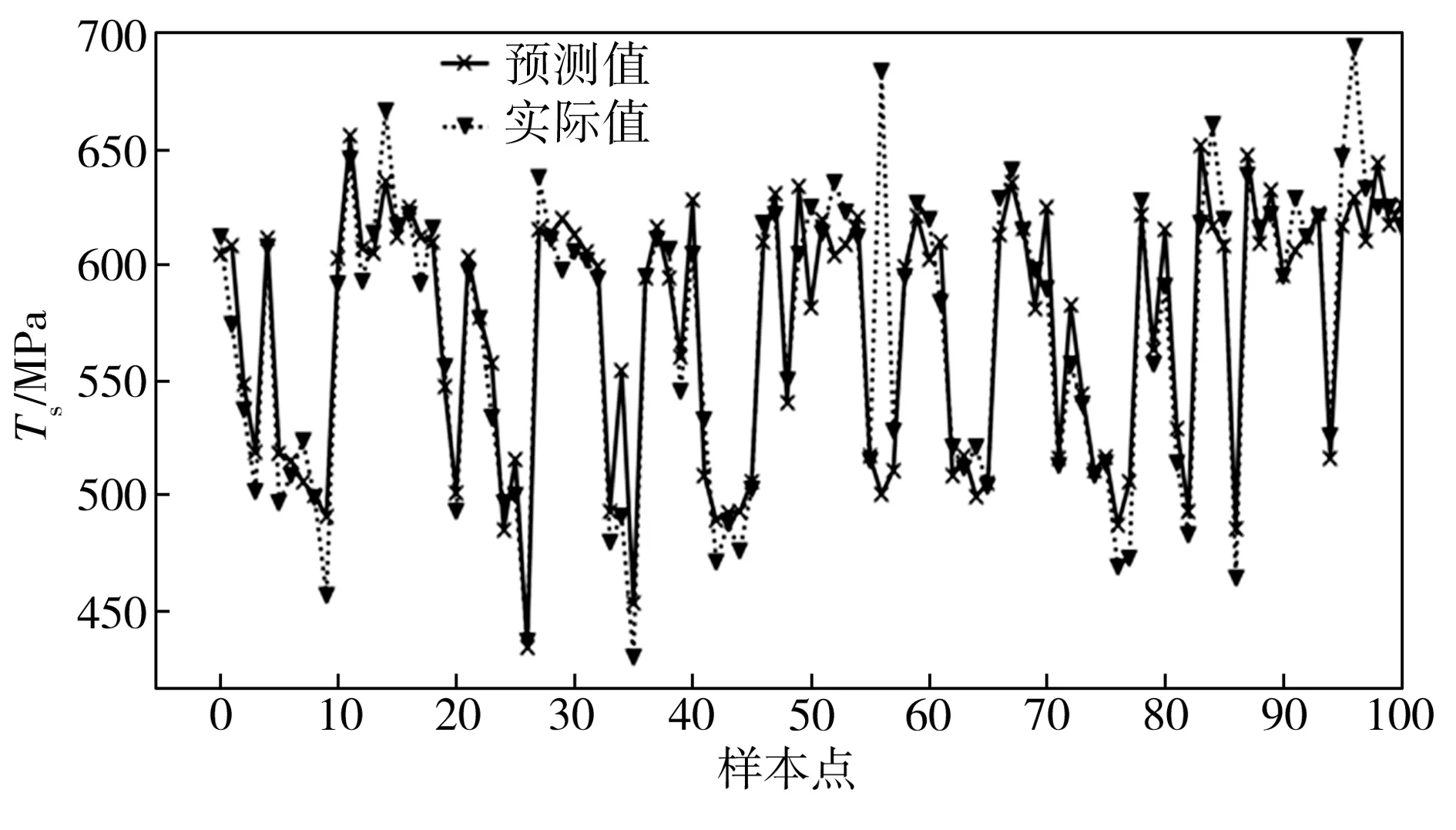
圖9 帶鋼抗拉強度的預測值與實際值對比
Fig.9Comparisonbetweenpredictedandactualvaluesofstriptensilestrength

表5 不同預測方法的評價指標
4 結語
針對熱軋帶鋼的力學性能預測問題,本文提出一種將一維數值型數據轉換成二維圖像數據用來建模的方法,相比于傳統的一維數值型數據,二維圖像型數據中結構信息更豐富,能提取到的有效信息更多。文中引入卷積神經網絡來構建影響因子之間的局部相互作用關系模型,基于GoogLeNet和LeNet-5卷積神經網絡結構的優點搭建帶鋼力學性能預報模型,并通過一個全連接層與輸入層直接相連,將提取到的特征與卷積神經網絡提取到的特征相融合。為驗證該方法的有效性,文中代入某大型熱連軋生產線的44760條歷史實際生產數據進行測試,結果表明,與BP神經網絡及單獨的GoogLeNet和LeNet-5卷積神經網絡結構相比較,本文所提方法的預測精度更高,本研究為熱軋帶鋼力學性能預報建模提供了新的思路。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南化工(2021年11期)2022-01-12 06:06:14
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
山東冶金(2019年3期)2019-07-10 00:54:00
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
焊接(2015年9期)2015-07-18 11:03:53
