基于深度學習算法的坦克裝甲目標自動檢測與跟蹤系統
2018-09-27 12:00:44王全東常天慶戴文君
系統工程與電子技術 2018年9期
王全東, 常天慶, 張 雷, 戴文君
(陸軍裝甲兵學院兵器與控制系, 北京 100072)
0 引 言
圖像處理技術在軍事領域的典型應用是目標自動檢測和自動跟蹤系統。目前,坦克火控系統的目標自動跟蹤技術已達到實用化水平,中、俄、以、日等國的部分3代坦克已安裝了具備目標自動跟蹤功能的穩相式火控系統,能夠在坦克乘員發現和鎖定目標后對其進行自動跟蹤[1]。但由于戰場環境的復雜性,坦克火控系統的目標自動檢測技術尚處于研究和試驗階段,距離實戰應用尚有差距。導致現有坦克火控系統的目標檢測和選取,全部需要依靠乘員人工進行搜索和選擇,系統的自動化、智能化水平和對戰場圖像信息的綜合處理能力有待進一步提高。迫切需要發展一種同時具備目標自動檢測與跟蹤功能的坦克火控系統,實現對目標搜索、檢測、跟蹤和火力打擊的一體化,從而使火控系統能夠從日益復雜的戰場環境中更迅速、準確地發現、識別和跟蹤各類目標,更快地對各類戰場目標做出反應。
目標檢測算法通常包含:建議區域提取、目標特征建模和區域分類與回歸3部分[2],其中特征建模屬于算法的核心部分,其對目標特征的表達能力直接影響分類器精度和算法整體性能。目前主流特征建模方法按照特征提取方式的不同,主要分為:基于人工設計的特征模型和基于自學習的特征模型(以下簡稱人工模型和自學習模型)。常用的人工模型,如尺度不變特征變換(scale invariant feature transform, SIFT)[3-4]、方向梯度直方圖(histogram of oriented gradient, HOG)[5-6]、Haar-like[7-8]等,具有結構簡單、直觀的優點,并且具有良好的可擴展性。采用多種特征組合的可變部件模型[9-11](deformable part-based model, DPM)算法,能夠彌補利用單一特征進行目標表示的不足,是近年來人工模型常用的檢測框架,被大量應用于人臉及行人等目標檢測任務并取得了較好的效果。然而由于人工模型只包含圖像原始的像素特征和紋理梯度等信息,并不具備高層語義上的抽象能力,對目標的刻畫仍不夠本質,使得這種方法在處理復雜場景下目標檢測任務時的效果并不理想。
2006年,文獻[12-13]首次提出了深度學習的概念和方法,指出包含多隱層的卷積神經網絡(convolution neural network,CNN)具有極佳的特征學習和提取能力,與傳統人工模型相比,其通過逐層提取方式學習到的抽象特征對數據本質的刻畫能力更強,更適合于對數據的分類與識別,并且首次提出以“逐層初始化”的方式克服深度神經網絡在參數訓練上容易陷入局部最優的問題,解決了困擾深度神經網絡多年的參數訓練難題,掀起了深度學習的熱潮,已成為目前最為有效的自學習模型方法。2012年,文獻[14]提出的R-CNN算法最早將CNN理論引入目標檢測領域,并獲得了當年PASCAL視覺目標圖像庫(visual object classes, VOC)國際目標檢測競賽的冠軍,相比于之前采用傳統人工模型檢測算法的最佳結果,平均精度(mean average precision,MAP)提高了顯著提升。其后的SPP-Net[15]、Fast R-CNN[16]、Faster R-CNN[17-18]等改進算法在檢測速度和精度上逐步提升,代表了目前該領域的最高水平。
當前,深度學習模型已逐漸代替傳統人工模型算法成為處理圖像檢測問題的主流算法[19-23],為解決復雜戰場背景環境下的目標檢測提供了新的技術途徑。本文采用深度學習的方法對復雜戰場環境下的目標檢測與跟蹤問題進行了研究,選取坦克裝甲車輛這種典型的戰場目標進行識別,相關技術也適用于其他類型目標。
1 基于Faster R-CNN算法的坦克裝甲目標檢測
常用的深度學習網絡模型包括自動編碼器、受限波爾茲曼機、深度置信網絡和CNN等,其中CNN及其改進型網絡是目前深度學習領域采用的主流網絡模型。
1.1 R-CNN系列算法的演化與對比分析
R-CNN算法的原理框架如圖1所示,以對坦克裝甲目標的檢測為例,實現流程是:首先采用選擇性搜索(selective search,SS)方法在整個輸入圖像中提取1 000~2 000個可能包含有目標的矩形建議區域,并通過縮放操作將得到的矩形建議區域統一縮放到相同大小(227像素×227像素)后,用深度CNN提取其特征向量。然后用訓練好的分類器,如Softmax、支持向量機(support vector machine,SVM)等,對各候選區域進行分類。最后采用非極大值抑制的方法,在一個或多個臨近的判定為相同目標的建議區域中,使用邊界回歸算法精細修正建議框位置,得到最終的目標檢測、識別結果。
R-CNN算法的缺點在于:一是需要采用CNN提取近2 000個目標建議區域的特征向量,計算量巨大,算法無法滿足實時性要求;二是由于網絡的全鏈接層需要固定大小的輸入,為固定輸入CNN前的建議區域大小而對所有目標建議區域強制進行的縮放操作,會導致部分建議區域圖像比例的失真和圖像信息的流失。SPP-Net[15]和Fast R-CNN[16]算法針對R-CNN算法存在的問題進行了改進,只需對整幅待檢測圖像進行1次CNN計算后,直接在整幅圖像的特征圖上找到與建議區域相應的特征區域,并采用空間金字塔池化(spatial pyramid pooling,SPP)的方法,對不同大小的特征區域提取出相同固定大小的特征向量用于分類,不再限制輸入神經網絡的建議區域的大小。與R-CNN算法相比,SPP-Net和Fast R-CNN算法既顯著減小了卷積運算的計算量又有效避免了縮放操作帶來的圖像失真和信息流失,使得算法的檢測速度和MAP得到大幅提升。
通過對Fast R-CNN圖像檢測過程中各處理流程時間損耗的分析發現,建議區域的提取占據了整個檢測流程的大部分時間,成為制約該算法速度繼續提高的主要瓶頸。為解決建議區域提取的速度問題,2015年,文獻[17]提出了Faster R-CNN算法,該算法通過采用和檢測網絡共享全圖卷積特征的區域建議網絡(region proposal network, RPN)的方式,產生高質量建議區域,使得建議區域的提取時間顯著減小,顯著提高了算法的檢測速度。R-CNN及其改進算法在VGG-16網絡模型下的MAP及訓練、檢測時間(GPU模式)對比如表1所示[14-18]。
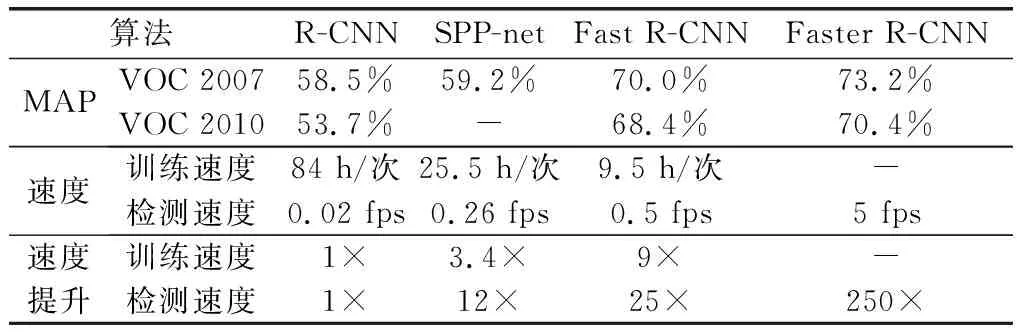
表1 R-CNN及其改進算法的MAP及速度對比
1.2 遷移學習與模型訓練
由表1可知,Fsater-RCNN算法的檢測速度和精度較之前的算法有了明顯提高。因此,本文首先采用遷移學習的方法將Faster R-CNN算法應用解決復雜背景下的坦克裝甲目標檢測問題。
(1) Faster R-CNN算法基本原理
Faster R-CNN算法的基本原理如圖2所示。
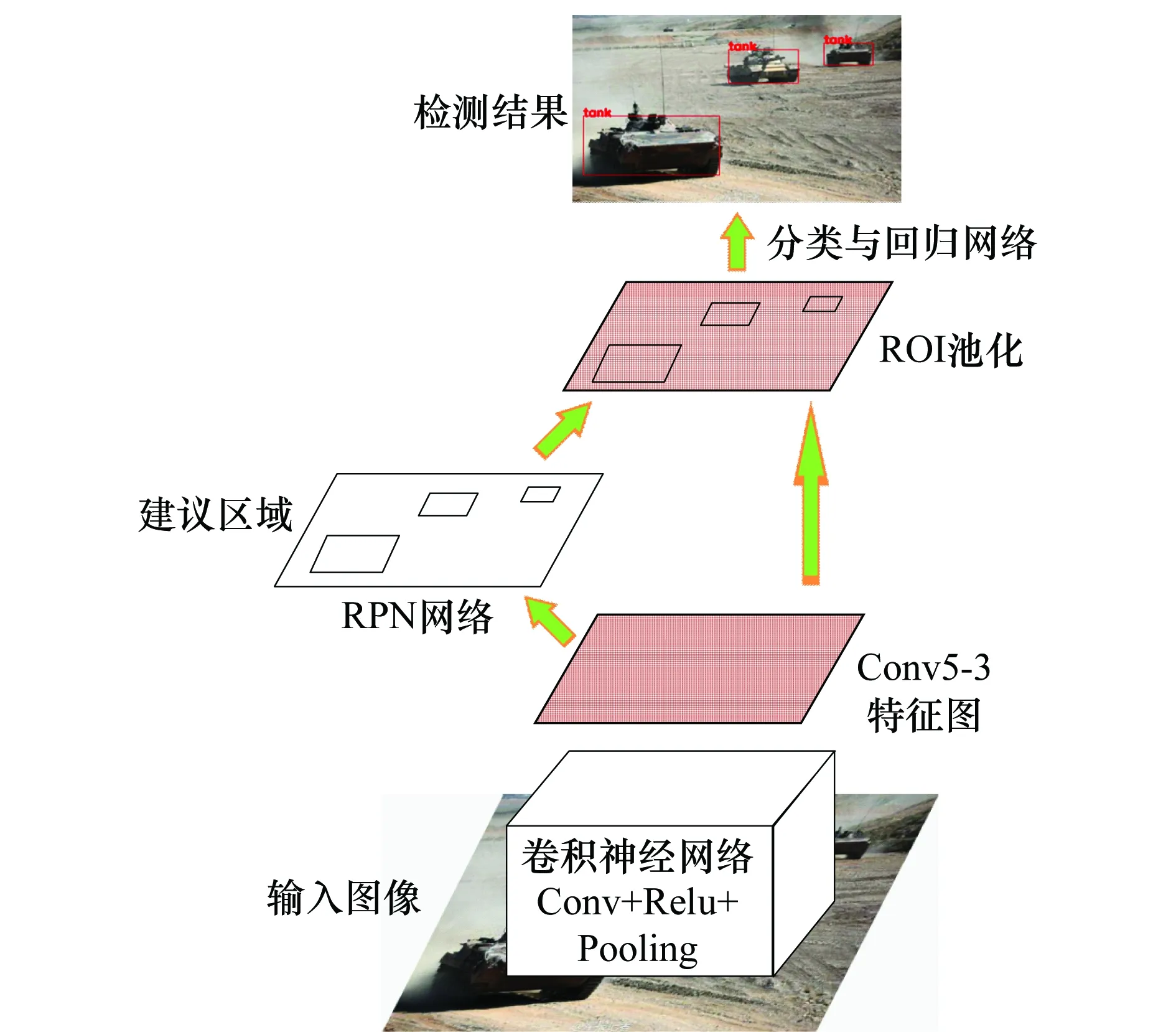
圖2 Faster R-CNN算法原理圖Fig.2 Schematic diagram of Faster R-CNN algorithm
其首先使用一組交替出現的Conv+Relu+Pooling網絡結構,在Conv5-3層(對于VGG網絡而言)得到輸入圖像的卷積特征圖。其次,通過RPN網絡在特征圖上以滑動窗口的方式產生許多個初始建議區域(anchor),并通過softmax分類器判斷該anchor屬于前景或背景的概率,再利用bounding box回歸對初始建議區域的位置進行修正,得到精確的建議區域。最后,通過感興趣區域(region of interest, ROI)池化將PRN網絡產生的建議區域對應的卷積特征池化為統一大小的特征矢量,并通過分類與回歸網絡對建議區域內的目標進行分類和邊界回歸,得到最終的檢測結果。
(2) 遷移學習與模型訓練
多層級的深度CNN通常具有海量(千萬級)的模型參數需要進行訓練和學習,對訓練樣本的數量和計算機的內存、計算速度等硬件條件都有非常高的要求。而且現有大規模圖像數據庫,如ImageNet、VOC、CIFAR等,只包含行人、汽車、飛機等常見目標,通過此類型數據庫訓練的深度網絡模型,只能檢測數據庫中所含有的特定類型的目標(20類)。但經大型數據庫訓練完成的模型參數已具備較強的目標提取能力,可作為遷移學習的初始化參數,顯著提高遷移學習的訓練效率。
遷移學習主要采用小規模的針對某新型目標的數據集對在大規模的圖像數據集上預訓練好的網絡模型的模型參數進行監督訓練和微調[24-26],使新訓練得到的神經網絡模型具備對該新型目標的檢測能力。本文主要針對坦克裝甲目標的檢測,由于本文數據集的樣本數量遠小于ImageNet等圖像數據庫(百萬級),因此采用遷移學習的方法對模型進行訓練。常用的深度卷積網絡模型包括LeNet(5層)、ZF-Net(7層)、Alex-Net(8層)、VGG-Net(19層)和Google-Net(22層)等,較深的網絡層數通常意味著更高的檢測精度,但算法卷積計算量也越大,檢測速度也越慢。在綜合考慮檢測精度和算法速度的情況下,選擇層數適中的ZF-Net模型,本文遷移學習的模型訓練流程如圖3所示。
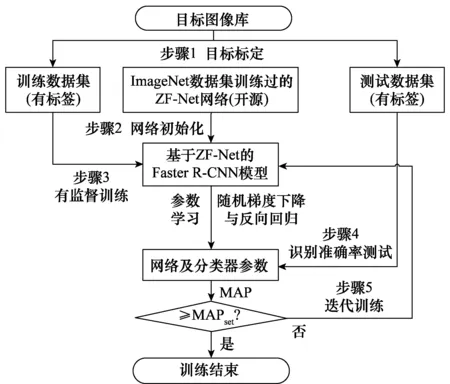
圖3 基于遷移學習的目標檢測模型訓練過程Fig.3 Training process of target detection model based ontransfer learning
步驟1構建訓練與測試數據集。深度學習網絡模型的訓練和測試需要大量的樣本數據,本文建立了由6 000張彩色圖像構成的滿足PASCAL VOC標準數據集格式的坦克裝甲車輛圖像庫(訓練集5 000張,測試集1 000張)。對訓練集和測試集圖像中所有坦克裝甲目標均進行了標注,分別包含12 476和2 317個目標。
步驟2選用經ImageNet數據集上訓練好的ZF-Net作為初始化網絡模型(開源),對模型參數進行有效初始化(區別于傳統訓練模式下的隨機初始化)。
步驟3采用Fsater R-CNN算法框架,以有監督訓練的方式,采用由5 000張圖像構成的訓練數據集對網絡進行訓練,根據損失函數采用隨機梯度下降和反向回歸算法對網絡的模型參數進行微調和更新,得到新的模型參數。
步驟4采用由1 000張圖像構成的測試數據集,對新訓練網絡模型的識別效果進行測試,計算得到MAP。
步驟5根據測試結果,循環步驟3~步驟5,進行多次的迭代訓練,直至模型的MAP達到預期的檢測精度。
1.3 檢測結果及分析
坦克裝甲目標在相機視場中的成像尺度與其和相機之間的距離成反比。實際應用中,目標可能出現在距離坦克幾十米至數公里的范圍內,目標成像尺度變化跨度很大。對于坦克圖像庫圖像中的任意目標,假設其高度和寬度的較大者為maxw&h像素,按照maxw&h的大小將目標分為以下4種尺度類型的目標,具體的分類標準為
(1)
基于人工模型的典型傳統算法:可變部件模型(deformable part models,DPM)算法以及分別采用ZF和VGG網絡的Faster R-CNN算法對坦克裝甲車輛圖像庫的測試集中各種尺度裝甲目標的檢測精度和速度如表2所示,各項指標的最佳效果采用粗體進行標志。所有的測試均在CPU為E5-2650Lv3,GPU(顯卡)為GTX-TITIAN-X配置的圖像工作站上進行。

表2 不同檢測算法在坦克裝甲車輛圖像庫測試集上的檢測精度和速度
由表2可知:
(1) Faster R-CNN算法的檢測精度明顯優于傳統DPM算法。雖然Faster R-CNN算法的模型參數和計算量明顯大于DPM算法,但由于Faster R-CNN算法的絕大部分計算均在GPU上進行,使其平均檢測速度可以達到甚至超過傳統算法(受網絡深度影響)。
(2) Faster R-CNN算法在采用VGG網絡時的平均檢測精度比ZF網絡提高大約7%,但由于VGG網絡的模型深度增加,導致卷積運算量增大,算法檢測速度明顯降低。
(3) 對微型目標的檢測精度明顯低于中型和大型目標,這是傳統DPM算法和Faster R-CNN算法均存在的問題。Faster R-CNN算法對微型目標檢測精度不及大目標的原因在于:算法采用的網絡結構(ZF或VGG)中,相鄰兩個卷積網絡層之間存在一個池化層(作用近似于降采樣),導致深層卷基層輸出特征圖的尺度與原始輸入圖像相比會縮小很多,而算法的RPN和分類與回歸網絡均采用最后一個卷積層(Conv5-3)的輸出特征作為輸入,其尺度比原始輸入圖像縮小了16倍,對于微型目標而言容易造成建議區域的提取不夠精確,同時也無法保留足夠的信息用于后續的分類和回歸。提高Faster R-CNN算法對微型目標的檢測精度是一個值得繼續深入研究的問題。
本文訓練的基于ZF網絡的Faster R-CNN算法對坦克裝甲目標圖像的部分檢測效果如圖4所示,模型輸出目標概率大于0.8即認為是目標。由檢測結果可知,本文經過遷移學習和訓練得到的深度網絡模型在復雜背景下對各種姿態和多種類型的坦克裝甲目標均具備良好的檢測能力。這是由于深度學習算法通過大量的樣本訓練使模型具備了較強的目標提取能力,并且通過CNN的逐層提取方式得到了坦克裝甲目標的深層次結構性特征,與傳統人工規則構造特征的方法相比,該特征更能夠刻畫目標圖像數據的豐富內在信息,對各型坦克均具有較強的泛化能力,而且對目標姿態、顏色、大小和環境的變化具有很高的容忍度,可以較好的適應各種戰場環境,在有限的煙霧及局部遮擋(此類情況在戰場環境中較為常見)情況下,仍能識別坦克目標,顯示出了良好的目標檢測識別能力,實現了對復雜背景環境下坦克裝甲目標的自動檢測。

圖4 復雜背景下的坦克裝甲目標檢測結果Fig.4 Detection results of tank armored targets under complex background
部分錯誤檢測結果如圖5所示,主要表現在算法存在一定的過檢、誤檢、漏檢和檢測失敗的問題。圖5(a)過檢測的原因在于邊界回歸算法存在局限,檢測出的兩個相鄰目標框的重疊度未能滿足將其歸于同一目標的回歸規則。圖5(b)誤檢的原因在于CNN學習到的是目標的深層次結構特征,對于部分局部類似坦克的建議區域存在被誤檢為坦克目標的可能。漏檢(見圖5(c))和檢測失敗(見圖5(d))的原因在于目標較小或者遮擋、偽裝嚴重,CNN難以提取到有用的目標特征用于分類,導致的檢測失敗。上述幾種失敗的檢測識別情形,說明深度學習算法仍有其不足之處。但其與傳統基于人工特征的檢測算法相比還是表現出了極大的優越性,對一般難度的目標圖像具有很高的檢測精度。另外本文算法的模型深度和訓練樣本數量有限,對算法的目標檢測精度也會有一定影響。

圖5 各種檢測失敗情形Fig.5 Various dection failures
2 坦克火控系統現有跟蹤算法的不足與改進
2.1 “相關跟蹤”算法的原理與不足
某典型三代坦克目標自動跟蹤火控系統采用的“相關跟蹤”[1]算法原理,如圖6所示。為保證跟蹤算法的實時性,圖像傳感器一般選用黑白相機。假設瞄準鏡圖像大小為M×N像素,用F(x,y)代表瞄準鏡圖像中某點(x,y)處的灰度值。在t0時刻,炮長采用大小為K×L的跟蹤框鎖定目標,產生一個K×L像素大小的目標樣板圖像Q,用Q(i,j)代表目標樣本圖像點(i,j)處的灰度值。

圖6 目標樣板圖像與瞄準鏡子圖像Fig.6 Target template image and sub-images of sight
用Suv代表左上角坐標為(u,v)大小為K×L的一個瞄準鏡圖像的子圖像,Suv(i,j)代表該子圖像中點(i,j)處的灰度值,則
Suv(i,j)=F(u+i,v+j)
(2)
相關跟蹤算法就是從當前瞄準鏡圖像中,找到與目標樣板最相似的子圖像位置,作為跟蹤結果。這需要對瞄準鏡子圖像和目標樣板圖像的相似度進行衡量,引入相似性測度的概念:
(i,j)-Q(i,j))2
(3)
Ruv越小,說明該子圖像與樣本圖像的相似度越高。為了減小Ruv對光線等環境因素導致的圖像灰度值變化的敏感程度,通常采用式(4)所示的歸一化后的Ruv作為瞄準鏡子圖像和目標樣板圖像相似度的評價指標。
(4)
由式(4)可知,每次相關匹配操作均需要對樣板圖像和子圖像的K×L個像素灰度值進行乘積求和開方運算,計算量較大,影響算法實時性。對于上述問題,序貫相似性檢測算法(sequential similarity detection algorithm,SSDA)[27]方法是一種常用的改進算法,其對于失配位置不需要計算所有點對應的相關性,可以迅速得到該位置不是匹配點的結論。如圖7所示,設定一個閾值T0,對每一搜索位置,按照一定的對比順序比較該子圖像和目標樣板圖像的差值,并累計其誤差Er,當Er超過閾值T0則停止匹配計算。
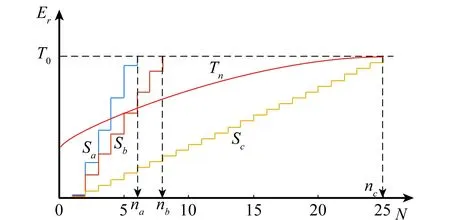
圖7 SSDA算法示意圖Fig.7 Diagram of SSDA algorithm
SSDA算法的匹配精度隨閾值T0的增加而增加,但計算速度隨之降低,因此可以采用單調增加閾值Tn(或閾值自適應算法)代替固定閾值T0,達到速度和匹配精度的最優。
坦克火炮屬于直瞄型武器,從炮長發現目標到火力打擊的過程,可在數秒內完成,在目標姿態和環境變化不大的情況下,“相關跟蹤”算法的跟蹤效果還是不錯的。但現有坦克火控系統的目標跟蹤技術在實際運用中也存在如下問題:
(1) 無法從大范圍戰場環境中快速實現目標的自動檢測與識別,而且目標的選取仍需炮長人工進行選擇。
(2) 現有跟蹤算法對環境變化敏感,難以適應目標姿態和光照的劇烈變化,尤其是目標的快速旋轉和遮擋。
為了彌補采用“相關跟蹤”算法的火控系統在面對環境或目標姿態劇烈變化時的不穩定性,現有坦克火控系統在跟蹤失敗時,允許炮長隨時退出自動跟蹤工況,切換為手動跟蹤工況,但并未從根本上解決上述問題。
2.2 基于TLD框架的復合式目標跟蹤算法
為了彌補“相關跟蹤”算法在面對環境和目標姿態變化時的不穩定性,將基于深度學習的檢測算法與現有“相關跟蹤”算法相結合,提出了如圖8所示的基于跟蹤-學習-檢測(tracking-learning-detection,TLD)框架[28]的復合式目標跟蹤算法,其中檢測器采用基于深度學習模型的Faster R-CNN算法,跟蹤器采用SSDA算法。視頻流首先輸入檢測器模塊,當檢測出目標后,再將目標模板送入跟蹤器進行跟蹤。之后檢測器模塊和跟蹤器模塊同時工作,并將檢測器與跟蹤器輸出的目標位置框Dr和Tr的綜合結果,作為最終的目標跟蹤結果,以此提高火控系統跟蹤的穩定性。同時為保證跟蹤器也能夠適應一定程度目標的狀態變化,以檢測器的最新檢測結果對跟蹤器的跟蹤模板進行在線持續更新。
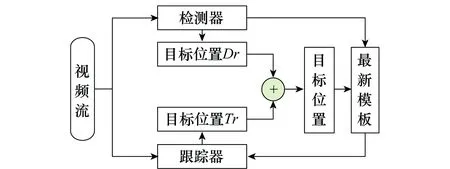
圖8 基于TLD框架的復合式跟蹤算法結構Fig.8 Composite tracking algorithm based on TLD framework
檢測器輸和跟蹤器輸出的目標位置框Dr和Tr的融合規則如下:
(1) 若檢測器檢測失敗,跟蹤器跟蹤成功,則以Tr作為最終跟蹤結果;
(2) 若跟蹤器跟蹤失敗,檢測器檢測成功,則以Dr為最終跟蹤結果,并對跟蹤器模板進行更新和初始化;
(3) 若檢測器、跟蹤器均成功,則計算Dr與Tr的重合度r。若r≥0.8,可認為檢測器和跟蹤器的位置輸出結果基本一致,以Dr為準。若r<0.8,則分別計算Dr、Tr內圖像與上一幀目標位置框內圖像的相似度,以相似度大的作為最終跟蹤結果,相似度的計算參照式(4)。
Dr與Tr的重合度(intersection over union, IoU)定義為
(5)
式中,area( )代表求面積。
(4)如果跟蹤器和檢測器均失敗(目標丟失),則采用檢測器持續對目標進行檢測,待檢測出目標后立即對跟蹤器模板進行更新和初始化,并重啟跟蹤器。
2.3 跟蹤測試結果與分析
選取了如圖9所示的4段典型的坦克運動視頻,對本文復合式跟蹤算法與SSDA算法以及TLD算法的跟蹤效果進行了對比測試。4段測試視頻的特點為:1號視頻中目標進行直線運動,沒有遮擋且目標姿態和成像大小幾乎不變;2號視頻中目標進行快速S型機動,姿態持續變化,用于測試模型對目標姿態變化的適應能力;3號視頻目標運動過程中連續出現樹木遮擋,用于測試算法對目標遮擋的適應能力;4號視頻為目標長時間運動的視頻,運動過程中目標姿態和目標成像大小均存在變化,部分幀中的目標存在樹木遮擋,且目標顏色與背景較為相似,用于測試跟蹤算法的持續穩定跟蹤能力。測試前對所有測試視頻的目標真實位置都進行了標注,以用于對算法的跟蹤效果進行評估,實驗中設定跟蹤框與標注框的重合度大于0.5即視為跟蹤成功。

圖9 跟蹤算法測試視頻Fig.9 Videos for the test of tracking algorithm
采用目標跟蹤測試基準(object tracker benchmark,OTB)跟蹤算法測試基準[29]中的成功率和精確率曲線評估本文算法的實際跟蹤效果,結果如圖10所示,圖10(a)~圖10(d)分別為1~4號視頻的成功率曲線,圖10(e)~圖10(h)分別為1~4號視頻的精度曲線。其中,A為SSDA跟蹤算法,B為TLD跟蹤算法,C、D均為本文提出的復合式跟蹤算法。區別在于:C算法的檢測模塊僅在第一幀及跟蹤器跟蹤失敗時才進行檢測,其目的在于提升算法速度;D算法的檢測模塊采用逐幀檢測(檢測器始終處于工作狀態)。各算法的目標選取方式、成功跟蹤幀數以及平均跟蹤速度如表3所示,各項指標的最佳效果均采用粗體進行標志。
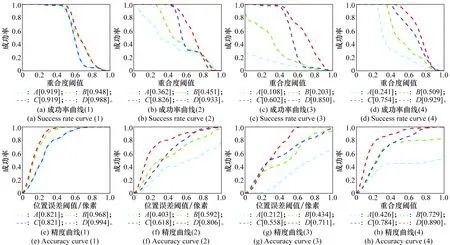
圖10 不同跟蹤算法的成功率與精度曲線對比圖Fig.10 Comparison of success rate and accuracy curves of different tracking algorithms

測試視頻總幀數成功跟蹤幀數ABCD目標選取(手動:×,自動:√)ABCD平均跟蹤速度/(幀/s)ABCD1297297297297297××√√21835286154183××√√33623562276349××√√41 8653821 1521 5341 865××√√40122711
成功率曲線主要反映算法的持續跟蹤能力即跟蹤算法的穩定性,精確率曲線主要反映算法的跟蹤精度。由圖10及表3的測試結果可得如下結論。
(1) 跟蹤穩定性
在處理目標姿態無明顯變化的簡單跟蹤任務時(1號視頻),4種算法均能實現對目標的連續穩定跟蹤,但當目標姿態發生快速變化和被部分遮擋時(2、3、4號視頻),A、B算法均出現了不同程度的跟蹤失敗現象,C、D算法的成功跟蹤幀數明顯高于A、B。原因在于C、D算法的檢測器可以在跟蹤器跟蹤失敗時重新檢測出目標,并對跟蹤器模板進行更新和初始化,使得算法在處理目標姿態變化和遮擋等情況下的跟蹤效果更穩定。B算法雖然也有檢測模塊,但其檢測模塊采用在線PN學習的方式,檢測效果嚴重依賴目標樣版圖像,對目標姿態變化和遮擋的容忍度有限。C算法的成功跟蹤幀數少于D算法的原因在于跟蹤失敗后檢測器重新檢測出目標需要一定的時間,在此期間存在短暫的目標丟失。
(2) 目標選取
A、B算法需要手動選取跟蹤目標,C、D算法可以實現對跟蹤目標的自動選取,自動化程度更高。
(3) 跟蹤精度
當4種算法的成功跟蹤幀數大致相同時(1號視頻),采用跟蹤器和檢測器融合輸出目標位置的方式(B、D)比只采用跟蹤器(A、C)的方法,對目標的跟蹤精度更高。但當目標姿態發生快速變化和被部分遮擋導致跟蹤失敗時(2、3、4號視頻),跟蹤成功率較高算法(C、D)的跟蹤精度優于成功低較低算法(A、B)。
(4) 跟蹤速度
復合式跟蹤算法(D)的跟蹤速度與現有SSDA(A)相比算法仍存在較大差距,比TLD算法(B)更快是因為檢測模塊采用了GPU加速。與D算法相比,C算法是一種折衷的方式,在提高跟蹤速度的同時犧牲了部分跟蹤精度。
3 目標自動檢測與跟蹤實驗系統設計
要從大范圍戰場環境中快速檢測和跟蹤目標,首先要求實驗系統能夠快速、穩定地獲得寬視場、高分辨率的戰場圖像。為使圖像具有足夠的像素點用于對目標的描述,便于后期的目標檢測與跟蹤,相機視場一般很小(坦克瞄準鏡的視場為8°左右)。本文采用動態掃描凝視成像技術,實現小視場探測器對大范圍戰場的快速成像。具體而言:將相機固定在轉臺上,通過轉臺的連續轉動對戰場區域進行連續掃描,以彌補相機視場的不足。但相機隨著轉臺的旋轉會導致曝光時刻景物與探測器間存在相對運動,從而產生像移問題,造成成像的模糊及拖尾效應。本文通過在相機的光學系統前增加快速反射鏡,以控制快速反射鏡旋轉的方式實現對像移的補償。
3.1 動態掃描凝視成像的工作時序
為了在曝光時間保持景物與探測器之間的相對靜止,使探測器在運動狀態下仍能保持對景物的凝視(達到靜止成像的效果),必須通過對快速反射鏡的反掃控制,實現對探測器(隨動于轉臺)轉動速度的補償。
系統連續成像的過程與反掃工作時序如圖11所示,其中,θM為探測器位置,θS為瞄準線(視軸)位置,θFSM為反射鏡位置。當探測器處于位置M,瞄準線處于位置a時,瞄準線處于視場#a的中心,此時要求反射鏡的轉動速度ωFSM和探測器的轉動速度ωM相匹配,使得瞄準線在慣性空間“凝視”;同時必須保證“凝視”時間(反掃時間)大于探測器的積分時間,完成對視場#a的清晰成像。當探測器完成積分成像后,反掃補償鏡快速回到反掃起始位置。當系統判斷探測器位置位于M+1時,瞄準線處于位置a+1,此時兩幅圖像剛好滿足設計的重疊角度,快速反射鏡再次進行反掃,再次使瞄準線在慣性空間“凝視”,完成對視場#a+1的清晰成像,隨后重復本過程(#a+2,…,#a+n),直至完成整個區域循掃或周視成像。
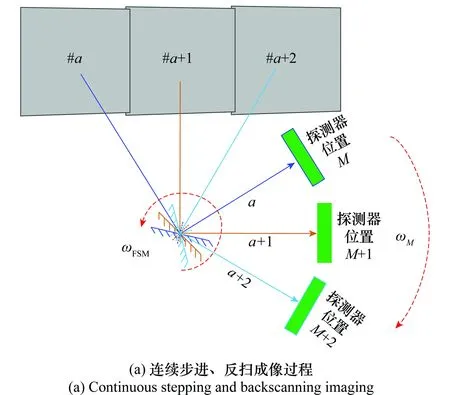
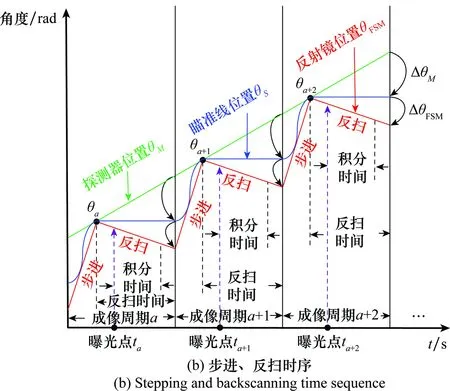
圖11 系統連續成像過程與反掃工作時序Fig.11 Continuous imaging process of the system
在圖11(b)所示的工作時序下,整個光學系統和探測器隨著轉臺進行“勻速轉動”,反掃補償鏡以固定周期進行“步進”和“反掃”,2個運動機構(轉臺和反射鏡)共同運動、精確配合,使瞄準線周期性的“步進”和“凝視”。在“凝視”期間,探測器位置隨轉臺的轉動不斷變化,但瞄準線角度穩定不變,從而實現探測器對戰場偵查區域的高效凝視成像。
3.2 控制系統設計
目標檢測與跟蹤實驗系統的總體控制結構如圖12所示。系統采用復合軸控制,主要包括轉臺位置控制回路和快速反射鏡位置控制回路。2個控制回路均采用由位置環和速度環構成的雙環控制結構,其中轉臺位置控制回路以慣性角速率測量元件(陀螺)為反饋,隔離外界的力矩擾動,確保轉臺以給定的速度掃描成像。
實驗系統主要有區域偵查、全景偵查和目標跟蹤(手動/自動)3種工作模式。區域偵查模式下:首先通過調轉指令將轉臺旋轉至掃描起始位置,然后向掃描方向勻速旋轉,同時通過反掃指令對反射鏡的速度進行控制,實現對指定區域的掃描凝視成像,并通過目標檢測算法快速發現其中的可疑目標及其所處方位。全景偵查模式下:控制系統可無視轉臺實際位置,從轉臺現有位置為掃描起點,在反掃指令的配合下,完成360°掃描凝視成像,并通過目標檢測算法快速發現360°視場中的可疑目標及其所處方位。目標跟蹤模式下:系統在區域偵查或全景偵查發現可疑目標后,將轉臺快速調轉至目標所在區域,并采用復合式跟蹤算法實現對目標的持續跟蹤。
3.3 電氣結構設計
實驗系統的電氣關聯圖如圖13所示。其中,管理計算機接收來自信息處理計算機的各種操控指令,并傳輸給可見光相機、紅外相機、激光測距機、伺服控制計算機等組成單元,控制組成單元的功能和運動,同時將光電系統的視頻圖像信息、瞄準線角度信息等回饋給信息處理計算機。相機獲得的圖像數據通過兩路千兆網分別傳輸,首先由上位光纖收發器將兩路千兆網轉換為光信號,并通過光滑環傳輸到下位光纖收發器,下位光纖收發器將接收到的光信號重新轉化為兩路千兆網信號并最終傳入信息處理計算機進行目標檢測和跟蹤的處理。
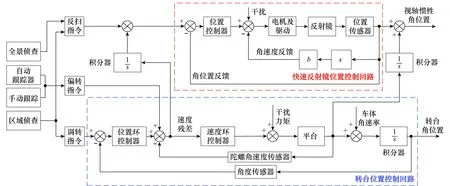
圖12 目標檢測與跟蹤實驗系統總體控制結構Fig.12 Overall control structure of the target detection and tracking experiment system
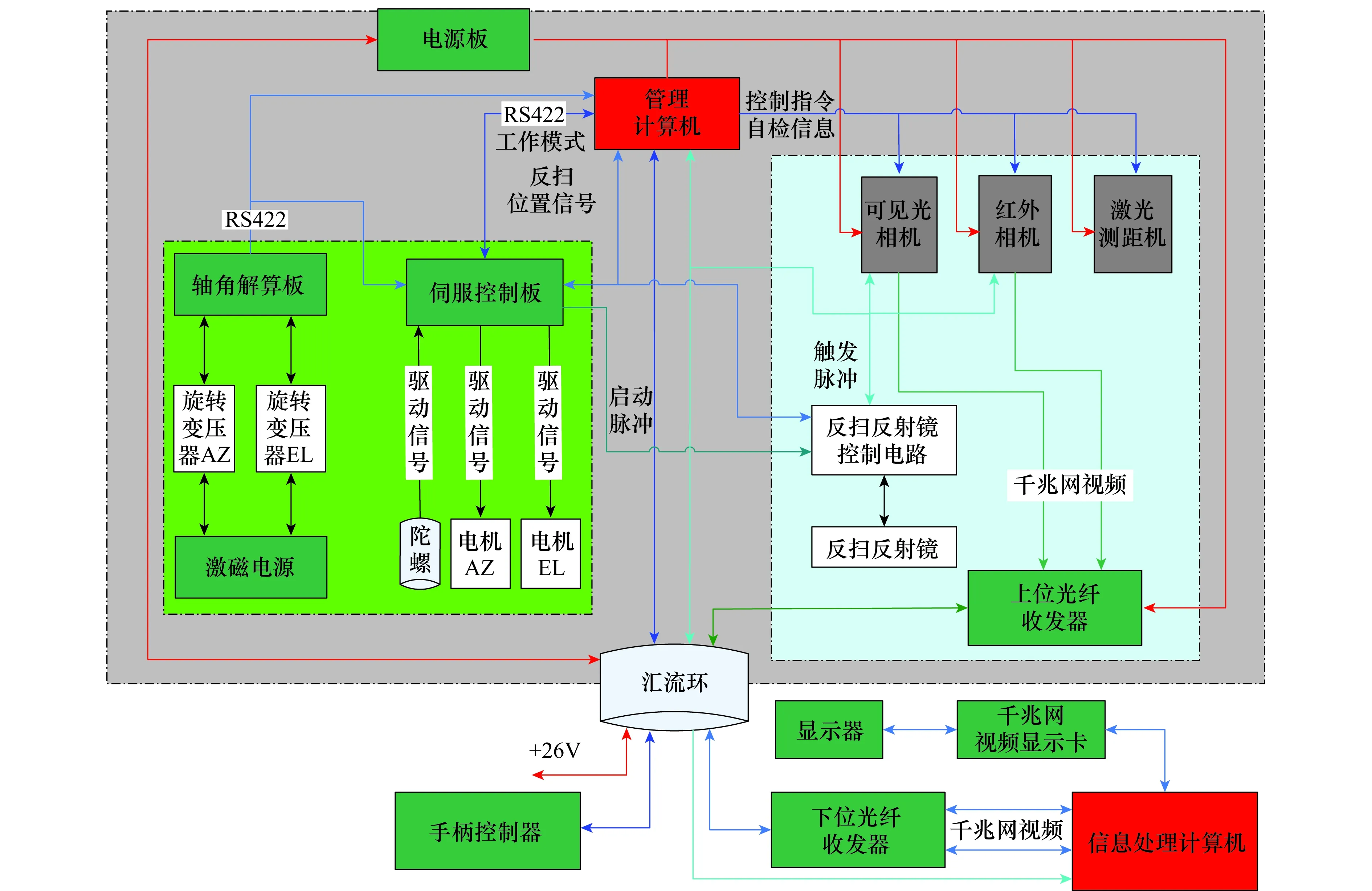
圖13 實驗系統電氣關聯圖Fig.13 Electrical connection diagram of experimental system
光相機與紅外相機的分辨率分別為:1 600×1 200和640×480,二者的視場一致且為同軸設計,水平向均為5.4°,垂直向均為7.2°,光軸一致性小于0.3 mrad。設計了如圖14(a)所示的光路結構,經快速反射鏡反射的入射光線通過一個分光鏡,將入射光線分為可見光和紅外光兩部分,分別送入可見光與紅外相機進行成像。由同一個快速反射鏡彌補轉臺運動導致的像移問題,實現了可見光和紅外相機對快速反射鏡的共用。如圖14(b)所示,可見光相機由于分光鏡的遮擋,未能在實際結構中顯示。
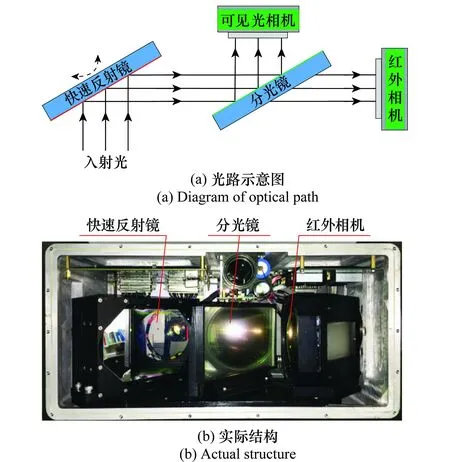
圖14 光路結構設計Fig.14 Design of optical structure
3.4 軟件設計
最終設計的實驗系統及系統終端界面如圖15所示,主要包含:伺服控制、目標調轉、激光測距、軸角解算和目標檢測與跟蹤等功能。通過對轉臺軸角的解算,可以實時獲得掃描圖像的方位信息。當檢測到目標后,通過調轉指令,可將相機視場快速移動到目標所在區域。
系統主要存在區域偵查、全景偵查和目標跟蹤(手動/自動)3種工作模式,為保證可見光相機和紅外相機曝光的一致性,二者均采用統一的外部曝光觸發脈沖。在GPU加速的情況下,本文采用ZF網絡的Faster R-CNN算法的檢測速度可以達到17幀/s。由于算法目前的檢測速度有限,在此我們設計全景偵查的周期為5 s:曝光脈沖頻率15 Hz,由75張掃描圖像構成360°周視成像,相鄰兩幀圖像重疊0.6°。區域偵查的周期為2 s:曝光脈沖頻率12 Hz,由24張掃描圖像構成120°區域成像,相鄰兩幀圖像重疊0.4°。對全景或區域偵查采集的戰場圖像進行目標檢測,根據檢測算法輸出的目標概率大小,只顯示概率最高(≥0.8)的3幅可疑目標圖像及其方位信息。操作人員可通過調轉指令將,將相機視場快速調轉至目標所在區域,并對其進行監視和跟蹤。

圖15 目標檢測與跟蹤實驗系統Fig.15 Target detection and tracking experiment system
4 實驗測試
系統目前的目標檢測和跟蹤功能只針對可見光圖像。由于紅外圖像的訓練樣本十分有限,本文尚未進行對紅外圖像目標檢測和跟蹤的研究,目前紅外相機僅作為一種輔助成像方式,用來人工發現隱蔽目標。對實驗系統的成像以及本文目標檢測和跟蹤算法的實際效果進行了測試。
4.1 動態掃描凝視成像效果測試
保證相機在快速掃描情況下的清晰成像是開展目標檢測和跟蹤的基礎,圖像清晰度對后續目標檢測和跟蹤的結果具有重要影響。對實驗系統在靜止成像、移動成像和移動反掃成像3種成像方式下可見光相機的成像效果進行了測試,其中靜止成像指轉臺和反射鏡均靜止情況下的成像,移動成像指轉臺轉動而反射靜止情況下的成像,移動反掃成像指轉臺和反射鏡均轉動,即動態掃描凝視成像方式下的成像。測試結果如圖16所示,可以發現相機在移動成像方式下的成像結果存在嚴重的像移模糊現象,而移動反掃成像通過對反射鏡的控制,在“動平衡”中實現了對轉臺運動造成的像移補償,使曝光時刻景物與探測器之間保持相對靜止,實現了對景物的穩定清晰成像,成像效果與靜止曝光無明顯差異。
點銳度法是一種改進的邊緣銳度算法,主要根據圖像邊緣灰度變化情況來判別圖像的清晰度,該方法易于實現,適用于細節豐富、有紋理特征的圖像清晰度評價。為了對不同成像方式下的成像效果進行定量分析,本文采用點銳度的方法對系統成像質量進行評價。

圖16 不同成像方式下可見光相機的成像序列對比Fig.16 Comparison of imaging sequences of visible light camera in different imaging modes
對于一幅m×n大小的彩色圖像,首先分別提取圖像三通道的RGB分量:Rm×n,Gm×n,Bm×n。則該彩色圖像最終的點銳度評價值為
PRGBm×n=0.30PRm×n+0.59PGm×n+0.11PBm×n
(6)
對圖16所示的3組不同成像方式下成像序列的點銳度進行了計算,其結果如表4所示。
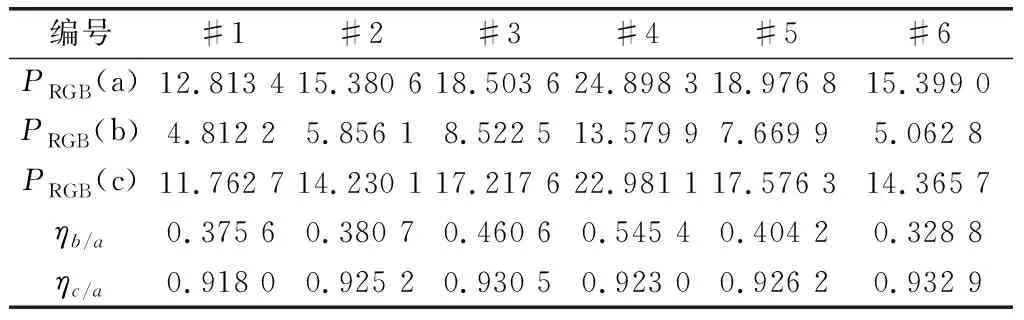
表4 可見光相機各種成像方式下的點銳度及歸一化點銳度值
表4中,PRGB(a)、PRGB(b)、PRGB(c)分別為靜止成像、移動成像和移動反掃成像方式下可見光相機成像序列的點銳度評價值。由于圖像的點銳度會受圖像內容影響,為了彌補圖像內容對點銳度的影響,以靜止成像時圖像的點銳度為參考,對移動成像和移動反掃成像時圖像的點銳度進行歸了一化處理,其中
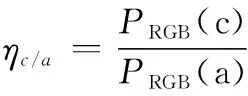
(7)
由表4可知,采用移動反掃成像方式下相機成像序列的相對點銳度值明顯高于移動成像方式,說明移動反掃成像方式下相機成像的清晰度明顯高于移動成像。而且移動反掃成像方式下相機成像序列的點銳度值均在靜止成像方式相機成像序列點銳度值的90%以上,說明兩者清晰度差別不大,系統動態掃描凝視成像效果良好。
4.2 大范圍目標檢測功能測試
120°區域偵查模式下的目標檢測結果如圖17所示。轉臺掃描起點的軸角位置為(60°, 0°),以下均按照(方位角,俯仰角)的方式對軸角進行表示。采用順時針掃描,整個120°掃描區域由24張圖像構成,其中在第7幀和第16幀中發現可疑坦克裝甲目標,輸出的目標概率分別為0.983和0.992,圖像所在軸角位置分別為(92.79°, 0.10°)和(137.58°, 0.08°),與目標實際位置相符。2幅圖像的俯仰方向軸角不為零,是因為轉臺轉動時系統存在輕微抖動,對陀螺儀輸出的角度值存在一定影響,但影響較小,基本可以忽略。操作人員可根據軸角解算得到的圖像方位信息,將相機視場快速調轉至目標所在區域,在跟蹤模式下對其進行后續監視和跟蹤。

圖17 120°區域偵查模式下的目標檢測結果Fig.17 Target detection results in 120° regional detection mode
4.3 復合式目標跟蹤算法測試
選取了一段包含遮擋及目標快速旋轉機動的場景視頻,對上述目標檢測與跟蹤一體化算法(C、D)與現有SSDA(A)及TLD(B)算法進行了對比測試,跟蹤結果如圖18所示。在第30幀附近,目標與背景顏色相近且出現樹木遮擋,A算法由于跟蹤誤差的累積使跟蹤出現漂移,并逐漸導致跟蹤失敗。B、D算法由于檢測器的存在,其跟蹤并未受遮擋的影響,C算法在跟蹤器失敗后,在第34幀通過目標檢測器重新檢測出了目標,并對跟蹤器進行了初始化。目標在第90~150幀進行快速轉彎機動,在此期間目標姿態發生持續快速變化。由于目標機動速度較快,在第125幀附近,B、C算法均出現了目標跟蹤丟失的情況,C算法跟蹤失敗是由于其跟蹤模塊采用SSDA算法,由于目標姿態變化顯著超出模型了容忍度,導致跟蹤失敗(但隨后又通過檢測器模塊在130幀附近檢測出目標)。B算法采用線上PN學習的方式,由于其跟蹤模板更新速度跟不上目標姿態變化或者目標特征變化太大,超出模型容忍度,導致跟蹤失敗。本文復合式跟蹤算法(D)的檢測器模塊,采用深度學習(線下學習)的方法,能夠適應目標的各種姿態變化,在跟蹤器跟蹤失敗的情況下,可以重新檢測出目標,并對跟蹤器模板進行在線跟新,從而實現了對目標的持續穩定跟蹤,取得了較好的跟蹤效果。但基于深度學習的目標檢測器的計算量巨大、速度較慢,導致復合式跟蹤算法的速度目前尚不能達到實時性的要求。

圖18 坦克裝甲目標的檢測跟蹤結果Fig.18 Detection and tracking results of tank armored target
5 結論與展望
信息化戰爭中,坦克乘員往往要在較短時間內處理大量的戰場信息,對整車反應速度提出了更高要求,實現對目標的自動檢測與跟蹤是坦克火控系統未來發展的重要方向,本文設計了一套面向坦克火控系統的目標自動檢測與跟蹤實驗系統。該系統采用動態掃描凝視成像技術實現了對大范圍戰場圖像的快速、清晰獲取,并采用遷移學習和基于深度學習模型的Faster R-CNN算法實現了對復雜背景下的坦克裝甲目標的快速檢測,與基于人工模型的傳統算法相比達到了較高的檢測精度。通過將Faster R-CNN算法與現有跟蹤算法相結合,提出了復合式目標跟蹤算法,實現了對坦克裝甲目標的自動檢測與穩定跟蹤。
本文實驗結果表明:基于深度學習的目標檢測算法通過多層CNN學習和提取坦克的目標深層次結構模型,能夠檢測出各種姿態下的坦克裝甲目標,對目標的煙霧或局部遮擋以及目標姿態、顏色、大小和環境、背景的變化具有較高的容忍度。同時,通過將其與傳統跟蹤算法相結合,可以實現目標的自動檢測和持續穩定跟蹤,為坦克火控系統實現對復雜背景條件下的目標自動檢測與跟蹤,提供了一種穩定、可行的技術方案。研究中發現目前深度學習算法在應用于坦克火控系統的目標檢測、跟蹤時仍然存在部分問題,主要表現在:
(1) 算法實時性有待提高
目前,Faster R-CNN等主流深度學習算法尚無法實現對連續視頻的實時檢測與跟蹤,但深度學習算法的發展速度很快,從R-CNN模型到Faster R-CNN僅用了不到兩年時間,檢測速率已經提高了近百倍,最新的YOLO(you only look once)[30]、SSD(single shot detector)[31]等深度學習模型采用“單步檢測”的方式省略建議區域提取過程,直接利用CNN的全局特征預測每個目標的可能位置,已經可以實現視頻目標的實時檢測,但模型精度有所降低。
(2) 模型復雜度高,計算量大,對系統軟硬件需求較高
現有深度學習算法基本未考慮計算機資源的限制,其對計算機軟硬件的需求遠超目前火控計算機的資源配置,要實現此類技術在坦克火控系統中的工程應用,需要繼續對模型進行適當簡化和優化,降低對系統的軟硬件要求和設備成本。
(3) 對于小微目標仍然存在部分漏檢問題
對于一般場景下的顯著目標,Faster R-CNN算法已經可以達到很高的檢測精度(MAP>60)。但深度學習算法在在小微目標檢測方面的精度與大尺度目標相比仍有較大的提高空間。這是由于算法采用的網絡結構中,相鄰2個卷積網絡層之間存在一個池化層,導致深層卷基層輸出特征圖的尺度與原始輸入圖像相比會縮小很多,對于小微目標而言容易造成建議區域的提取不夠精確,同時也無法保留足夠的信息用于后續的分類和回歸。通過合理利用多個卷基層特征而不僅僅是最后一個卷基層的特征的方式來彌補小微目標的特征在經過多個池化層后在深層卷積特征圖上的信息損失,從而增強算法對小微目標的檢測能力,是一種不錯的改進思路。
未來要實現深度學習算法在坦克火控系統目標自動檢測與跟蹤中的工程化應用,后續應主要圍繞上述3項問題開展相關研究工作。此外,目前尚未有標準的大規模戰場目標圖像數據庫,導致模型訓練樣本數量偏少。如何利用小樣本數據實現高效網絡的訓練也是一項值得深入研究的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
