使用R和Stata軟件實現(xiàn)傾向性評分匹配
2018-09-20 06:48:12南通大學(xué)公共衛(wèi)生學(xué)院公共衛(wèi)生與預(yù)防醫(yī)學(xué)系226019李文超汪徐林
中國衛(wèi)生統(tǒng)計 2018年4期
南通大學(xué)公共衛(wèi)生學(xué)院公共衛(wèi)生與預(yù)防醫(yī)學(xué)系(226019) 周 潔 張 晟 何 書 李文超 汪徐林 沈 毅
隨機對照試驗(randomized controlled trial,RCT)目前被認為是臨床試驗的金標(biāo)準(zhǔn),但在實際工作中常受到倫理、經(jīng)濟等因素的影響,且因研究對象有嚴(yán)格的納入排除標(biāo)準(zhǔn),使其結(jié)論外推受到限制[1]。大樣本觀察性研究可部分彌補RCT的不足,但其研究過程未采用隨機對照,基線以及重要預(yù)后因素在組間分布的不均衡可能會對結(jié)果的真實性造成影響[2]。傾向性評分匹配(propensity score matching,PSM)是一種均衡混雜因素的方法,近年來廣泛用于大樣本、非隨機觀察性研究[3-5]。目前用于實現(xiàn)PSM的軟件為數(shù)不少[6-8],R語言的Matchit程序包以及Stata軟件的psmatch2程序包就是專門用于實現(xiàn)PSM的易學(xué)易用的程序包[9-10]。本文擬通過實例展示如何在R與Stata軟件上逐步實現(xiàn)PSM。
傾向性評分的概念與基本原理
傾向性評分(propensity score,PS)的概念是Rosenbaum 和Rubin 于1983 年首次提出,它是指將多個協(xié)變量的影響通過PS值的變化來表示[11]。根據(jù)PS值在組間進行分層、匹配、回歸(協(xié)變量調(diào)整法)或加權(quán)分析,即均衡組間協(xié)變量的分布,最后在協(xié)變量分布均衡的匹配組內(nèi)或?qū)又羞M行效應(yīng)值的分析[12]。
PS的基本原理是指在一定可觀察協(xié)變量 (Xi) 的條件下,研究對象i(i= 1,2,…,n) 被分配到特定處理組(Zi= 1) 或?qū)φ战M(Zi= 0) 的條件概率。此時,第i個研究對象被分配到處理組的概率可以表示為:
e(xi)=P(Zi=1|Xi=xi)
若給定的特征變量(xi) 與分組變量 (Zi) 是相互獨立的,則:
e(xi) 即為PS值。
Rosenbaum 和Rubin 提出構(gòu)建PS 模型需服從“強烈可忽略”(strongly ignorable)的假設(shè),即計算PS值時,協(xié)變量應(yīng)包含所有影響分組的混雜因素,或者說是不存在未識別的混雜因素[11]。它的使用具有兩個條件:(1)條件獨立性,即觀察對象的分組選擇只受納入模型的協(xié)變量影響,而不受其他協(xié)變量的影響;(2)組間評分分布具有足夠大的重疊區(qū)域,即樣本量足夠大且協(xié)變量的PS值相近。
在R軟件上實現(xiàn)傾向性評分匹配
1.軟件安裝與程序包加載
R是一個自由、免費、源代碼開放的軟件,可用于統(tǒng)計計算、統(tǒng)計編程以及統(tǒng)計繪圖[13]。截止至2017年7月25日,R軟件最新版本為R3.4.1,用戶可從官方網(wǎng)站http://www.r-project.org上獲取最新的版本及相應(yīng)的安裝包。
R軟件安裝完畢后,還需要進一步安裝和加載所需的Matchit程序包,具體安裝與加載代碼如下:
install.packages("Matchit")
library(MatchIt)
2.數(shù)據(jù)背景與加載
數(shù)據(jù)選擇某醫(yī)院2012年1月1日至2015年10月31日期間確診的603例妊娠合并乙肝孕婦,探討HBeAg對妊娠合并乙肝孕婦圍產(chǎn)期不良結(jié)局的影響,其中暴露組(HBeAg陽性)172例,對照組(HBeAg陰性)431例。由表1可見,暴露組與對照組的基線資料無可比性,均衡性較差。
將數(shù)據(jù)以“HBV”為名、以“.csv”為格式存儲在D盤里,使用“read.csv()”命令來讀取數(shù)據(jù),具體讀取命令為:
HBV<-read.csv("D:/HBV.csv",header=TRUE,sep=",")
上述命令執(zhí)行后,在命令欄中輸入命令“HBV”,即可見到導(dǎo)入數(shù)據(jù),表示數(shù)據(jù)加載成功。
3.傾向性評分匹配與結(jié)果輸出
以孕婦是否為HBeAg陽性為分組因素,將其余變量作為協(xié)變量納入PSM模型之中,并將結(jié)果存儲在“m.out”這一新變量之中。匹配的算法選用了最常用的最近鄰匹配算法(nearest neighbor matching),匹配的比例可通過設(shè)定ratio的數(shù)值來實現(xiàn),一般設(shè)置為1~5,本例設(shè)置為1:1匹配。程序命令如下:
m.out=matchit(HBeAg~age+alt+ast+tbil+glu+wbc+cr+pt,data=HBV,method="nearest",ratio=1)
值得注意的是 PSM 中匹配算法的選擇對結(jié)果的影響十分重要,本文列舉了R中主要的匹配方法及其適用條件:

表1 孕婦基線特征表
精確匹配(exact matching)——該算法會精準(zhǔn)地匹配每個協(xié)變量值完全相同的處理組與對照組。但當(dāng)協(xié)變量較多或者協(xié)變量取值范圍較大時,精確匹配可能較難實現(xiàn)。(method =“exact”)
最近鄰匹配(nearest neighbor matching)——該算法將處理組與對照組中傾向性評分最接近的研究對象進行匹配。其優(yōu)點在于可最大化匹配效果,最大程度上保留了研究樣本的信息。(method =“nearest”)
優(yōu)化匹配(optimal matching)——該算法的核心是盡量減少在所有配對組之間的平均絕對距離。需要注意的是使用優(yōu)化匹配時,需要同時安裝optmatch程序包。(method = “optimal”)
遺傳匹配(genetic matching)——該方法是使用遺傳搜索算法找出每個協(xié)變量的權(quán)重,使得匹配之后的樣本達到全局最優(yōu)平衡。缺點是當(dāng)變量較多時,需要運行較長的時間。(method =“genetic”)
粗化精確匹配(coarsened exact matching)——這種算法可對特定協(xié)變量進行匹配,同時保持其他協(xié)變量的平衡。其優(yōu)點是計算速度快,對多分類變量、極度不平衡資料以及多重填補后的缺失資料有著良好的適應(yīng)性。使用粗化精確匹配需安裝cem程序包。(method = “cem”)
接著我們可以對結(jié)果進行描述與繪圖,命令如下:
summary(m.out)
plot(m.out,type="jitter")
plot(m.out,type="hist")
plot(m.out,type="QQ")
圖1給出了匹配前PS模型基本信息(A)、匹配后PS模型基本信息(B)、均衡性檢驗(C)以及樣本匹配結(jié)果(D)。首先匹配的基本信息包括了暴露組與對照組變量與距離(distance)的均值(means treated與means control)、對照組標(biāo)準(zhǔn)差(SD control)、暴露組與對照組的均值差(mean diff)以及QQ圖中暴露組與對照組的中位數(shù)距離(eQQ med)、均數(shù)距離(eQQ mean)和最長距離(eQQ max)。接著均衡性檢驗提示,本例樣本整體距離的均值差由原來的0.0713下降為0.0099,均衡性提升86.11%,所有變量均衡性提高50%以上,匹配效果良好。最后匹配結(jié)果包括了暴露組(treated)與對照組(control)匹配前(all)、匹配成功(matched)、匹配失敗(unmatched)以及被排除(discarded)的樣本量(sample sizes)。
圖2是PS分布抖點圖(jitter plot),它表示暴露組與對照組間匹配與未匹配者(unmatched treatment units:未匹配暴露組,matched treatment units:已匹配暴露組,matched control units:已匹配對照組,unmatched control units:未匹配對照組)PS的分布,從而了解匹配的效果。點的位置表示個體的得分情況;在1:n的情況下,點的大小則表示個體的權(quán)重。本例結(jié)果顯示,獲得匹配的個體傾向性評分較為接近,匹配效果較好。
圖3是PS分布的直方圖,表示暴露組與對照組間匹配前后(raw treated、raw control、matched treated、matched control分別指匹配前暴露組與對照組以及匹配后暴露組與對照組)PS值的分布,通過此圖可看出暴露組與對照組匹配均衡性及匹配效果。本例中,匹配后對照組的PS由匹配前的不均衡變?yōu)榫馇遗c試驗組接近,說明匹配效果較好。
圖4為PS模型變量的QQ圖,它表示暴露組與對照組間各個變量的PS分布,可看出單個變量的匹配前后的均衡情況。如年齡變量(age)的PS由匹配前的非正態(tài)分布變?yōu)槠ヅ浜蟮恼龖B(tài)分布,說明年齡變量匹配效果較好。
4.完成匹配數(shù)據(jù)的導(dǎo)出
匹配完成后,需將成功匹配的數(shù)據(jù)導(dǎo)出進行效應(yīng)值的分析。此時可使用match.data命令將數(shù)據(jù)存儲在“m.data”這一新變量中,并使用“write.csv”命令將數(shù)據(jù)以“mHBV.csv”格式導(dǎo)出到D盤中,以便進一步的分析,具體命令如下:
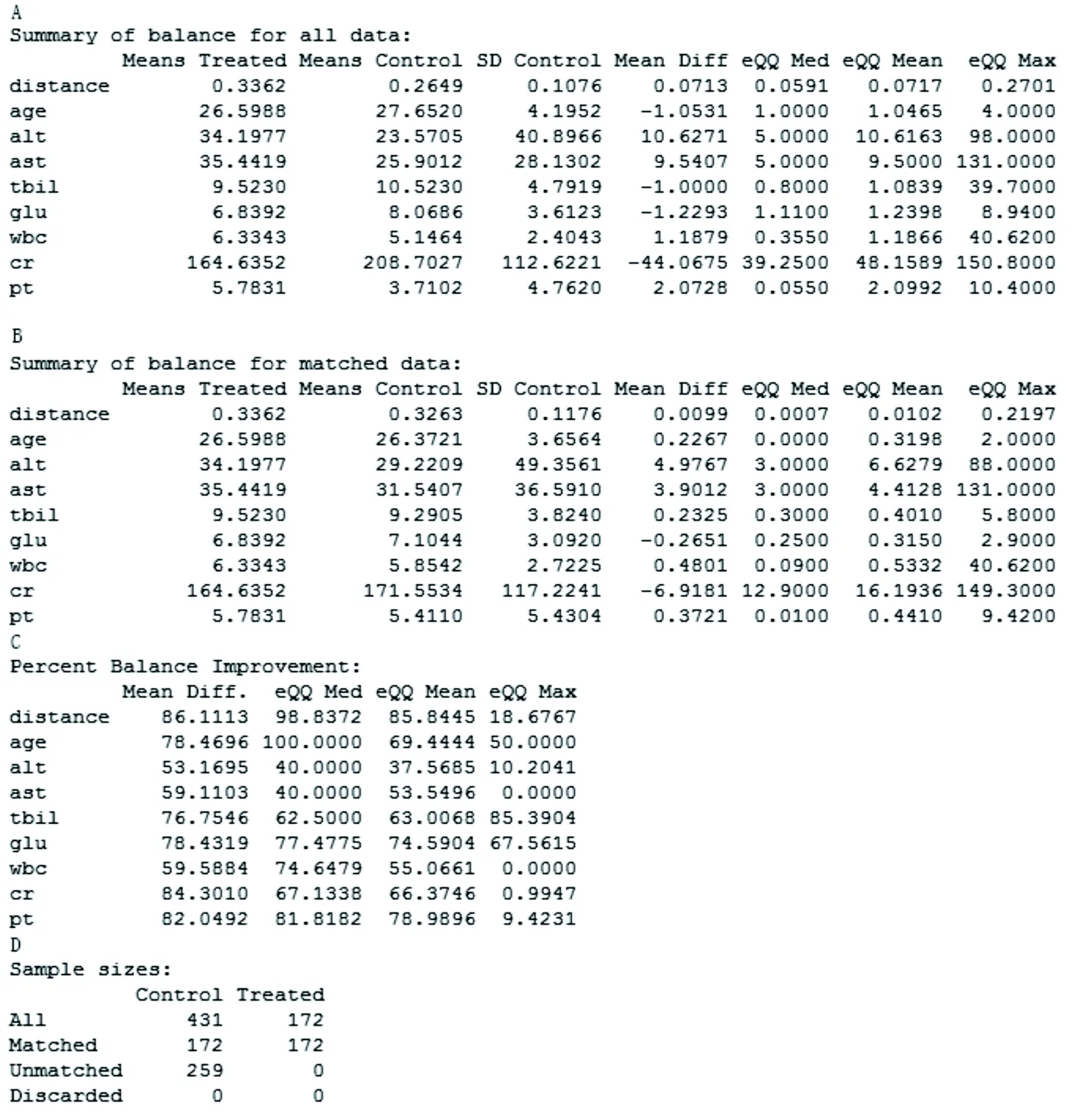
圖1 傾向性評分模型結(jié)果、均衡性檢驗與樣本匹配結(jié)果
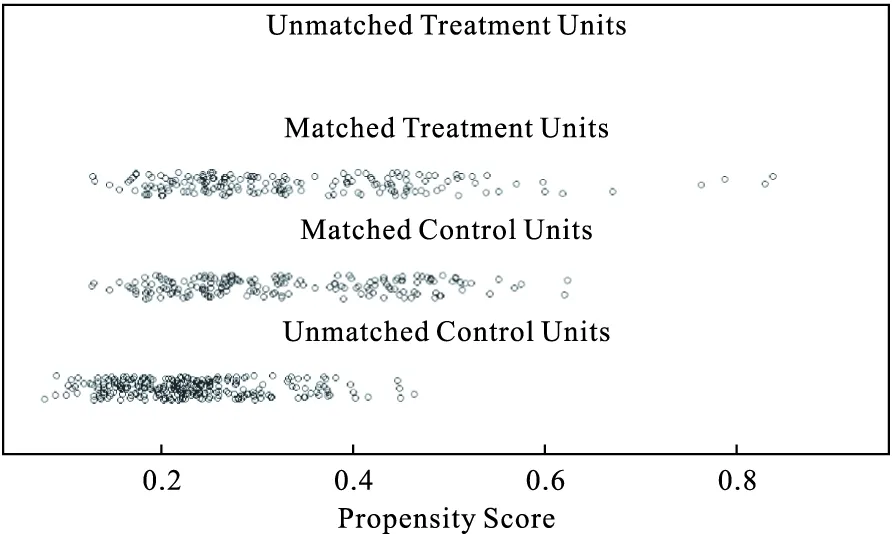
圖2 傾向性評分分布抖點圖
m.data<-match.data(m.out)
write.csv(m.data,file="D:/mHBV.csv")
數(shù)據(jù)導(dǎo)出后,軟件自動生成了三個新變量:id為每一個觀測對象唯一的ID號;distance為最近鄰匹配的距離值;weight為匹配的權(quán)重值。
在Stata軟件上實現(xiàn)傾向性評分匹配
1.Stata軟件的下載與模塊加載
Stata 軟件是一套可進行數(shù)據(jù)分析、數(shù)據(jù)管理以及繪制專業(yè)圖表的統(tǒng)計軟件。用戶既可通過窗口菜單進行操作,也可直接輸入編程代碼完成數(shù)據(jù)運算。用戶可從 http://www.stata.com/stata14/ 購買最新版Stata14.0,本文使用的為該版本。
在 Stata 的命令欄輸入ssc install psmatch2,即可自動搜索及安裝psmatch2程序包。
2.數(shù)據(jù)錄入
分析數(shù)據(jù)同前,可使用菜單欄中import過程來導(dǎo)入數(shù)據(jù)或者直接將excel 表格中的數(shù)據(jù)復(fù)制粘貼至數(shù)據(jù)編輯器之中。
3.傾向性評分匹配與結(jié)果輸出
同樣以孕婦是否為HBeAg陽性為分組因素,將其余變量作為協(xié)變量納入PS模型之中。使用psmatch2命令,匹配的算法選用卡鉗匹配算法(caliper),它是在最近鄰匹配的基礎(chǔ)上加一個限制條件,即暴露組與對照組PS差值需要在一定范圍內(nèi)才能進行匹配,卡鉗值根據(jù)經(jīng)驗設(shè)為0.03[14]。匹配的比例可通過設(shè)定最緊鄰算法后括號中的數(shù)值來實現(xiàn),本例設(shè)置為1:1匹配。common選項可查看暴露組樣本是否支持共同支撐假設(shè),即強制排除暴露組中PS值大于對照組最大PS值或小于對照組最小PS值的樣本。ties強制當(dāng)試驗組觀測有不止一個最優(yōu)匹配時同時記錄。程序命令如下:
psmatch2 hbeag age alt ast tbil glu wbc cr pt,logit neighbor(1) caliper(.03) common ties
pstest,both
psgraph
Stata中的匹配方法主要為:最近鄰匹配、核匹配(kernel matching)、局部線性匹配法(local linear matching)以及基于馬氏距離的匹配方法(Mahalanobis matching)。[15]
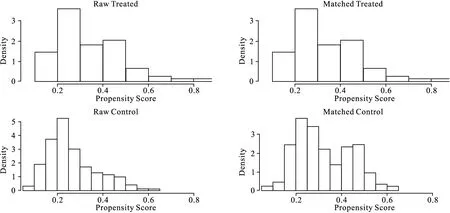
圖3 傾向性評分分布直方圖
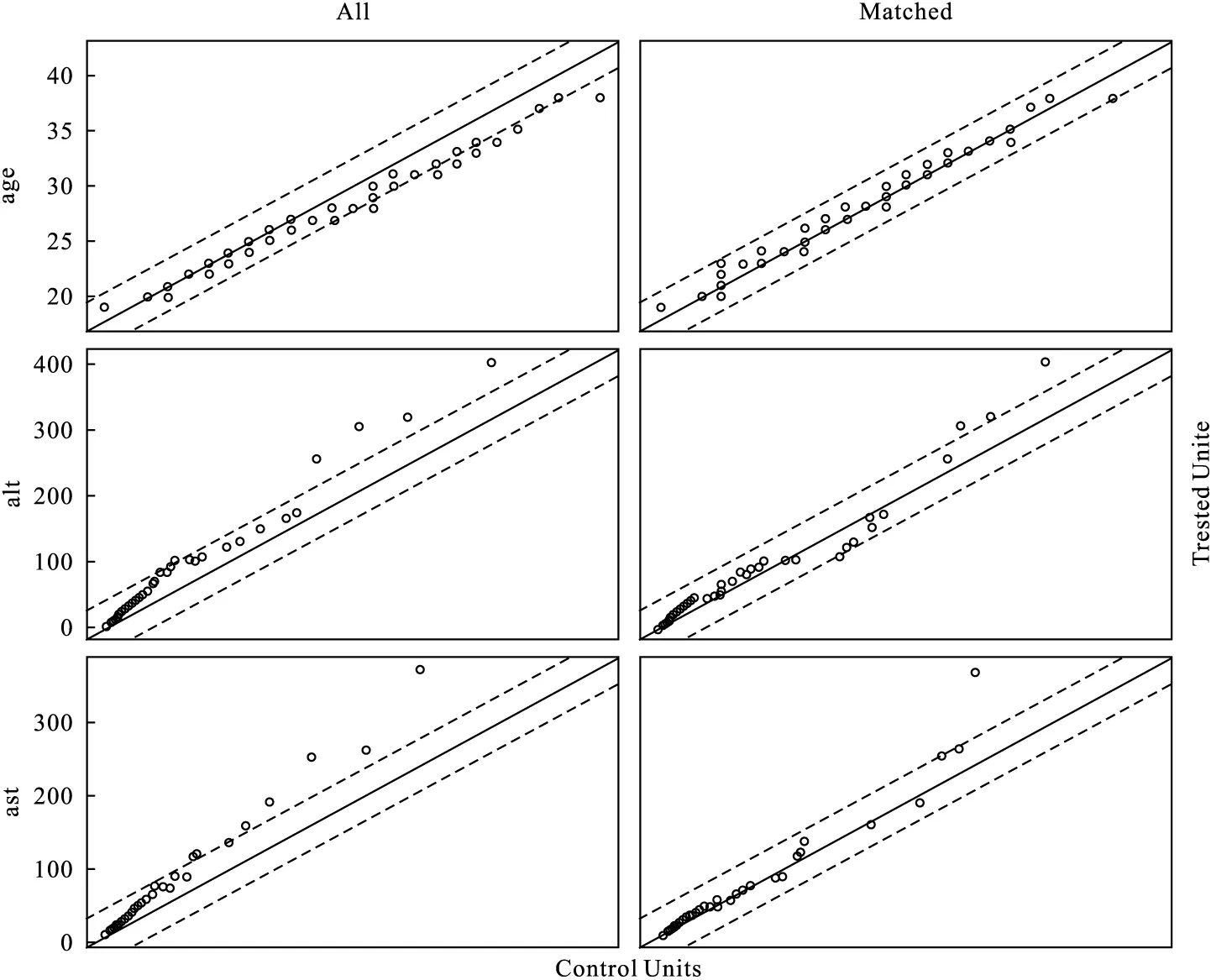
圖4 傾向性評分變量QQ圖*:只列舉前三個變量(年齡,谷丙轉(zhuǎn)氨酶、谷草轉(zhuǎn)氨酶)
pstest命令可做出匹配后均衡性檢驗,理論上pstest只能對連續(xù)變量做均衡性檢驗,對分類變量應(yīng)重新整理數(shù)據(jù)后運用χ2檢驗或者秩和檢驗。psgraph命令可對匹配結(jié)果進行圖示。
首先psmatch2命令可以看到模型回歸結(jié)果以及各變量的整體情況。接著打開數(shù)據(jù)編輯窗口,會發(fā)現(xiàn)軟件自動生成了一些新變量,其中_pscore是觀察對象的PS值;_id是自動生成的每一個觀察對象唯一的ID號;_treated表示觀察對象是否為暴露組;_n1表示的是觀察對象被匹配到的對照的_id;_pdif表示已經(jīng)完成匹配的觀察對象間概率值之差。
pstest命令使用both選項可得到匹配前后的信息,均衡性檢驗結(jié)果可知,所有變量匹配后均由組間不均衡變?yōu)榫?匹配效果良好(表2)。
psgraph命令作圖結(jié)果可見匹配后樣本傾向性評分值大致相同,匹配效果良好。與R不同的是,psgraph命令可繪制出變量是否具有共同支撐區(qū)域,本例中有部分暴露組樣本被排除(圖5)。
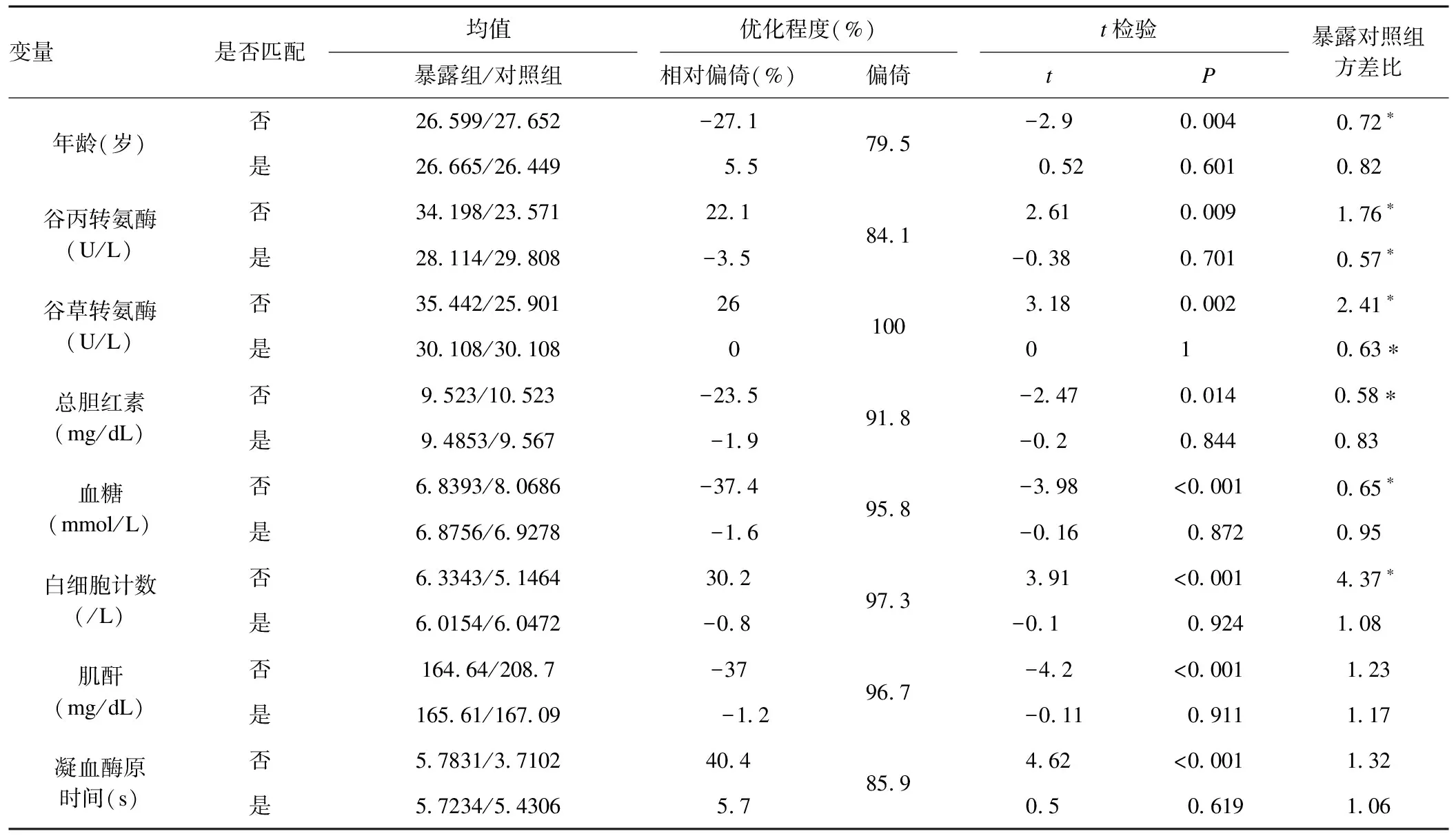
表2 傾向性評分模型均衡性檢驗結(jié)果
* 未匹配組方差比在[0.74,1.35]之外,匹配組方差比在[0.74,1.36] 之外。
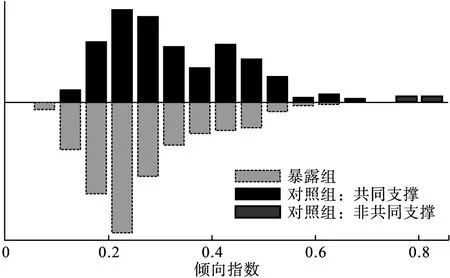
圖5 傾向性評分模型匹配結(jié)果直方圖
討 論
PSM作為一種半?yún)?shù)統(tǒng)計方法,可以更加靈活地處理各種函數(shù)與模型,增加了暴露組與對照組合理匹配的可能性,限制也相對較少。尤其在處理較多混雜因素問題時,PSM與傳統(tǒng)方法相比,運算更為便捷,匹配更為合理,可為研究者提供更高效客觀的匹配選擇。當(dāng)然,PSM的應(yīng)用也有其自身的限制。由于需要組間評分分布具有足夠大的重疊區(qū)域,需要研究有一定的樣本量支持,當(dāng)樣本量較小時,則無法解決協(xié)變量失衡的問題。另外,當(dāng)數(shù)據(jù)存在缺失值,或有未知混雜因素時,此方法也難以使用。
目前,PSM的應(yīng)用已經(jīng)成為一個熱點,但卻缺少易學(xué)易懂易用的軟件。SPSS軟件在22.0之后的版本直接納入了“傾向得分匹配”模塊,雖然實現(xiàn)起來比較方便,但存在只能實現(xiàn)1:1匹配,匹配方法單一,沒有繪圖選項等缺點。如果研究者需要解決這些問題,則需要在SPSS中安裝PS Matching模塊,此模塊的本質(zhì)為調(diào)用R的Matchit包實現(xiàn)PSM,但此模塊安裝步驟較為復(fù)雜[7]。SAS軟件同樣在最新的9.4版本中STAT 14.3模塊下加入了proc psmatch命令,使得實現(xiàn)PSM更加便捷。而之前的版本只能通過宏程序的方式來實現(xiàn)PSM[16]。
R的Matchit程序包與Stata的psmatch2程序包都有著簡明的程序,直觀的結(jié)果以及理想的繪圖。R與Stata相比,有著更加多樣的匹配選項和繪圖選擇;而Stata則可在匹配中選擇共同支持區(qū)域,使結(jié)果更加合理。另外,它的均衡性檢驗可以直接比較匹配前后P值的結(jié)果,更直觀方便。研究者可根據(jù)自身的需求選擇來應(yīng)用。
本文通過實例介紹了如何在R與Stata軟件中實現(xiàn)傾向性評分匹配,并提供了詳細的程序說明和結(jié)果解釋,相信可以對運用PSM的科研工作者有所幫助。

- 中國衛(wèi)生統(tǒng)計的其它文章
- 項目反應(yīng)理論在健康相關(guān)量表中的應(yīng)用現(xiàn)狀及展望*
- 大樣本數(shù)據(jù)標(biāo)準(zhǔn)化率的SAS宏實現(xiàn)*
- 基于翻轉(zhuǎn)課堂的形成性評價在醫(yī)學(xué)統(tǒng)計學(xué)教學(xué)中的實踐與評價*
- 翻轉(zhuǎn)式教學(xué)法在衛(wèi)生統(tǒng)計學(xué)教學(xué)中的應(yīng)用
- 醫(yī)學(xué)大學(xué)生主觀幸福感影響因素的多重線性分層回歸分析
- 某高校碩士研究生對醫(yī)學(xué)統(tǒng)計學(xué)的認知情況分析