潛變量增長混合模型在醫學研究中的應用*
2018-09-20 06:47:38喻嘉宏陳小娜郜艷暉張巖波陳柏楠孔羨怡李麗霞
中國衛生統計 2018年4期
喻嘉宏 陳小娜 郜艷暉 張巖波 陳柏楠 孔羨怡 楊 朔 李麗霞△
【提 要】 目的 介紹潛變量混合增長模型理論,并將該模型應用于醫學研究實踐。方法 以453名接受治療的抑郁患者的隨訪研究為例,采用Mplus7.4軟件構建潛變量混合增長模型。結果 識別出2個增長趨勢不同的亞類“一般抑郁組”和“嚴重抑郁組”,每個亞類人數分別為380人(83.89%)和73人(16.11%),年齡較小患者屬于“一般抑郁組”可能性高(t=-0.051,P<0.05)。結論 潛變量增長混合模型在縱向數據分析中能夠識別不可觀測亞群的不同增長軌跡,可以很好的彌補傳統的增長模型在探討群體異質性方面的不足,是縱向數據分析的有力工具。
隨著大數據時代的到來,醫學、心理學、社會學等領域的大型人群隊列研究越來越多,隊列研究中的數據是對每一個個體在不同時間點多次重復測量得到的追蹤數據,即縱向數據。縱向數據中同一個體的多次重復觀測之間往往具有相關性,不同時間點的觀測變量取值不獨立[1],如何處理這種個體內的相關性便成為縱向數據分析中必須要解決的問題。目前,縱向隨訪數據常用的分析方法有時間序列分析(time series analysis,TSA)、多水平模型(multilevel modeling,MLM)、廣義估計方程(generalized estimated equation,GEE)和潛變量增長曲線模型(latent growth curve modeling,LGCM)等,這些方法可以對所研究特征的總體發展趨勢進行分析,或者探討個體的特征隨時間變化的特點以及個體間發展變化趨勢是否存在差異。但不論哪種分析方法前提都假設全部研究對象的發展趨勢是相同的。越來越多的研究顯示研究總體中可能存在不可觀測的亞群[2],不同亞群擁有各自不同的增長參數,即不同的增長軌跡,傳統的縱向數據分析方法無法識別潛在亞群,這可能會導致研究結果的準確性和預測效果降低[3]。
Muthen等人[4]1999年提出潛變量增長混合模型(latent growth mixture modeling,LGMM),該模型是識別縱向數據變化趨勢的新的縱向數據分析方法。當研究的全部個體的發展趨勢不一致時,LGMM可以很好的彌補傳統的增長模型在探討群體異質性方面的不足。LGMM假設總體中存在多個潛在的增長軌跡,每個潛在的軌跡代表一個亞類,不同亞類的增長模式不同,即允許研究總體存在異質性。該模型的運用能夠對預防、臨床治療及病因探索等研究領域提供研究線索。本文介紹潛變量增長混合模型的基本原理,并通過實例來介紹該方法的實際應用。
方法介紹
1.模型的概念
潛變量增長混合模型將研究總體分成若干個不可觀測的亞群,并描述亞群的發展軌跡和亞群內個體隨時間變化的情況,該模型包含兩種潛變量:連續潛變量和分類潛變量。連續潛變量包含增長特征參數截距和斜率,分類潛變量把研究總體分成互斥的亞群來描述群體的異質性[5]。
潛變量增長混合模型的表達式如下:
(1)
(2)
(3)
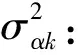
模型中也可以考慮協變量X對發展軌跡的影響,圖1是包含協變量的LGMM路徑圖,圖中有五次重復測量(Y1,Y2,Y3,Y4和Y5),分類潛變量C和連續潛變量(截距α和斜率β)。Li等人[7]研究發現協變量在確定模型潛在的類別個數上有重要的作用,故協變量的納入能夠提高模型識別不可觀測亞群的能力。
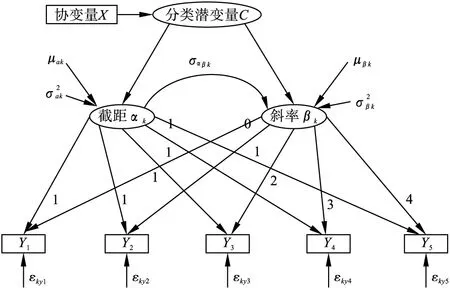
圖1 包含協變量的LGMM模型路徑圖
2.模型參數估計
潛變量增長混合模型的參數估計方法常用的有最大似然法(maximum likelihood,ML)和貝葉斯法,這兩種方法均是對數據進行多次迭代,獲得模型參數的估計值和后驗概率。目前,潛變量增長混合模型常在Mplus或Amos中擬合,兩種統計軟件進行參數估計時分別采用最大期望算法(expectation-maximization,EM)和馬爾科夫鏈蒙特卡洛法(markov chain monte carlo,MCMC)。當研究數據存在缺失值時,Mplus 7.4軟件會采用完全信息極大似然估計法(full information maximum likelihood estimator)對模型進行擬合[8]。
3.模型類別數的確定
確定LGMM模型的類別數是模型擬合的關鍵,一般根據信息指數與模型擬合檢驗結果來選擇模型類別個數。常用的信息指數有AIC,BIC和aBIC指標,Karen等人[9]研究指出aBIC是最好的信息指標,該指標越小說明模型的擬合效果越好。此外,Entropy值表示模型能夠將個體歸為相應類別的精確程度,取值在0~1之間,一般大于0.80可認為該模型的分類準確性較高[10]。常用的模型擬合檢驗有BLRT檢驗(bootstrapped likelihood ratio test)和VLRT檢驗(vuong-lo-mcndell-rubin likelihood ratio test),其中BLRT檢驗比較含C類的模型與C-1類模型擬合情況,若結果P<0.05,則提示含C個亞類的模型更優;反之,則C-1類模型擬合較優。VLRT檢驗也能夠評價C類模型與C-1類模型擬合情況,VLRT檢驗在確定類別數目時比BLRT檢驗更為敏感,故VLRT檢驗結果更加可靠。Tofight等人[11]研究認為aBIC和VLRT檢驗是正確選擇模型類別數的兩個最佳指標。
實例分析
1.資料來源
研究對象為山西醫科大學附屬醫院收集的符合DSM-Ⅳ(《診斷與統計手冊:精神障礙》)抑郁發作診斷的患者。納入標準為年齡在18~65歲,首次測量漢密頓抑郁量表(hamilton depression rating scale,HAMD)總分≥7分且整個隨訪調查中缺失次數<3次的患者。本研究共有453名患者滿足入選標準。
2.研究方法
每名患者接受抑郁治療后,每隔3周采用HAMD量表測量患者的抑郁狀況,該量表包含17個項目,共5個維度,大部分條目采用5級評分法,“0~4”分別表示無、輕度、中度、重度、很重;少數條目采用3級評分法,“0~2”分別為無、輕中度、重度,量表得分越高表明抑郁情況越嚴重[12]。本研究僅采用前5次的得分數據,并記錄患者的年齡、性別等人口學特征指標。研究探討患者抑郁癥狀隨時間的改善情況,將人口學特征指標作為協變量,5次重復測量的抑郁得分作為可測變量分別擬合線性、二次、自由估計三種類型增長混合模型。使用Epidata 3.1軟件進行錄入,使用SAS 9.4對人口學變量進行統計描述,Mplus 7.4軟件進行潛變量混合增長模型分析。
3.結果
納入研究的抑郁癥患者共453人,年齡為(32.49±11.78)歲。其中男性217人,占47.90%;女性236人,占52.10%。其他人口學特征指標見表1。
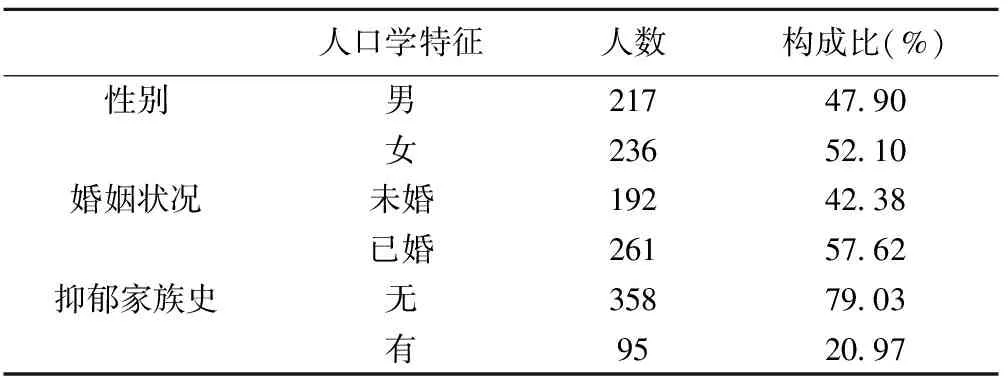
表1 抑郁癥患者人口學特征
將潛在類別數從1增加到3,分別擬合線性、二次、自由估計三種類型增長混合模型,結果見表2。除含3個潛類別自由估計的LGMM外,BLRT均大于0.05,且VLRT在3個潛類別時也大于0.05,自由估計時Entropy值最大(Entropy=0.812),結合信息指標提示含2個潛在類別自由估計的LGMM模型較優。
采用自由估計的含2個潛類別的模型參數估計結果和增長趨勢圖分別見表3和圖2。第一類截距和斜率的均值分別為18.935(P<0.05)和-6.607(P<0.05),該類起始抑郁得分較低,隨時間變化下降速率先加快后減緩,命名為“一般抑郁組”,該組380人,占83.89%。第一類截距和斜率的方差分別為16.187(P<0.05)和3.247(P<0.05),說明該類個體間抑郁水平初始值和抑郁下降率均存在差異。第二類截距和斜率的均值分別為23.081(P<0.05)和-1.814(P<0.05),該類起始抑郁得分較高,處于嚴重的抑郁水平,隨時間變化下降速率先緩慢后加快,命名為“重度抑郁組”,該組73人,占16.11%。第二類截距和斜率的方差為18.847(P<0.05)和1.415(P=0.072),說明該類個體間抑郁水平初始值存在差異,而抑郁下降率差異沒有統計學意義。第一類與第二類的截距與斜率間的協方差分別為-6.025(P<0.05)和-3.939(P<0.05),說明抑郁水平初始值與抑郁下降率之間存在關聯,抑郁水平初始值越高,抑郁下降率越小。
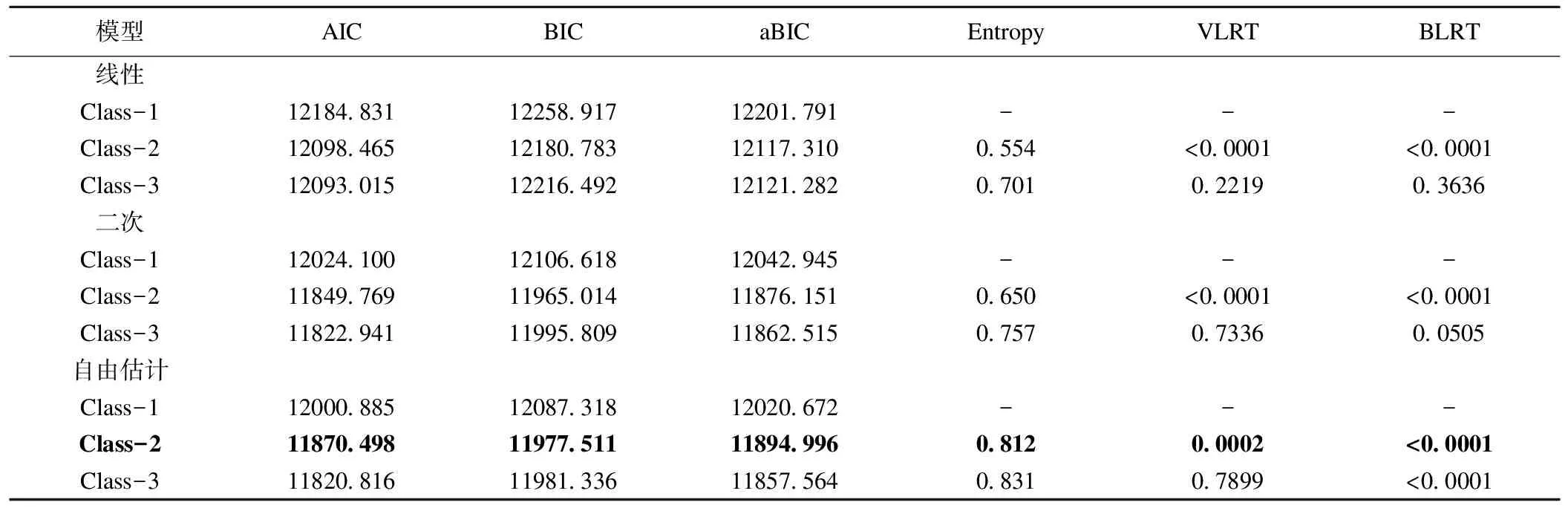
表2 增長混合模型擬合統計量結果
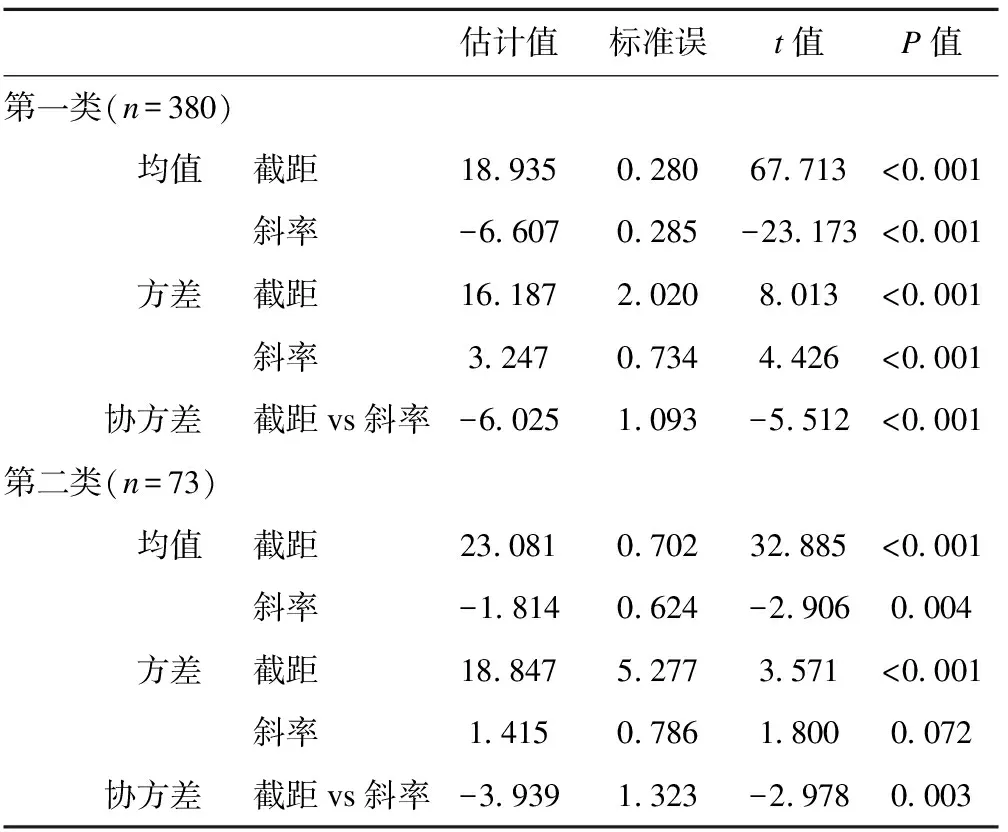
表3 抑郁癥發展趨勢的兩個類別模型參數估計結果
以亞類為因變量(以第二類為參照),人口學特征指標為自變量擬合logistic回歸,結果見表4,結果顯示僅年齡有統計學意義,其估計值為-0.051(P<0.05),說明年齡較小的患者,更容易分到第一類,即年輕患者出現一般抑郁的可能性大。

圖2 兩類別LGMM增長趨勢圖
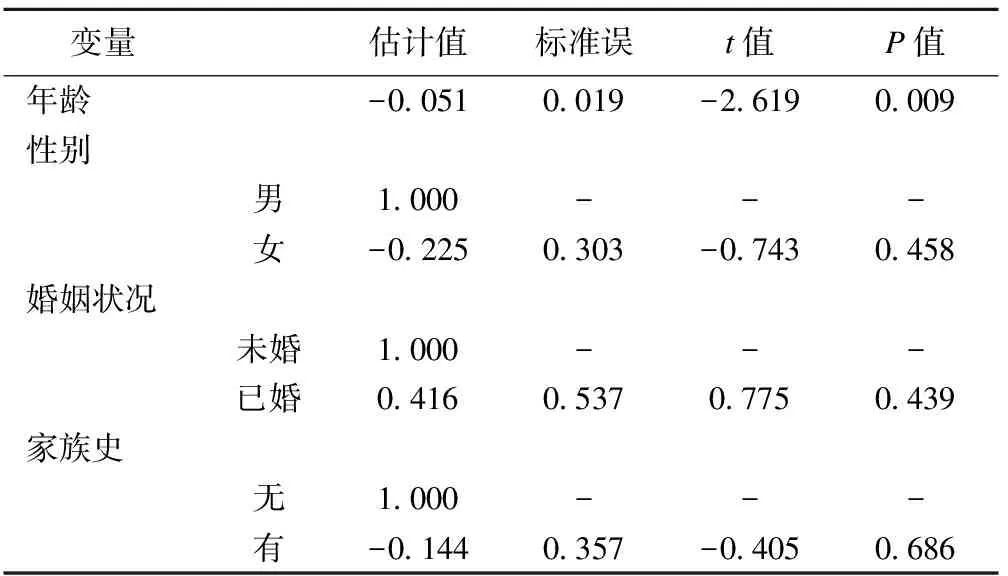
變量估計值標準誤t值P值年齡-0.0510.019-2.6190.009性別男1.000---女-0.2250.303-0.7430.458婚姻狀況未婚1.000---已婚0.4160.5370.7750.439家族史無1.000---有-0.1440.357-0.4050.686
討 論
傳統的縱向數據分析方法假設研究總體的增長軌跡是相同的,越來越多的縱向研究提示增長軌跡存在異質性的情況,許多研究結果已證實增長混合模型在公共衛生預防和臨床疾病病因探索等研究中都能很好地識別潛在的異質性亞群,這使得增長混合模型在縱向研究領域開始受到廣泛的關注。Ryan等人[13]在一項關于青少年抑郁癥研究中,構建LGMM模型發現抑郁的四種發展軌跡,認為校園暴力、網絡暴力和犯罪等是影響青少年抑郁發展的因素,建議學校管理者根據抑郁發展類型制定相應有針對性的預防措施進行干預。Yoo等人[14]將LGMM用于研究隨訪5年的慢阻肺病人生活質量變化情況,結果提示存在五種發展軌跡,發現年齡、睡眠質量、抑郁水平等因素對患者生活質量增長軌跡有影響,建議醫生根據慢阻肺患者具體情況提出個性化方案提高患者生活質量。本研究采用增長混合模型對抑郁患者隨時間抑郁發展情況進行分析,識別出“一般抑郁組”和“嚴重抑郁組”兩個不同增長軌跡的潛在亞群,為疾病治療方案的制定提供科學依據。
LGMM模型最大特點是將連續潛變量和分類潛變量結合起來,該模型通過分類潛變量將研究總體識別為不同亞群,并根據連續潛變量描述不同亞群發展趨勢以及個體間是否存在差異[15]。擬合LGMM模型時潛在類別數的確定至關重要,雖然根據信息指數等指標可以提供一定的信息,但潛在類別數的選擇仍存在一定的主觀性,建議結合專業知識為模型的構建提供理論支持。另外,LGMM模型雖然可以分析非正態分布的變量,但數據的非正態性可能存在多種原因:有可能是真實的非正態分布,亦或是多個不同分布類別的混合[16],故研究者可以把數據隨機分成兩組(訓練數據集和測試數據集)或使用新一批數據進行建模來比較結果是否一致來確認類別數選擇的正確性。LGMM模型需要足夠的樣本量,否則類別識別的準確率會降低,模型類別數的選擇可以參考與樣本量無關的Entropy值。
目前,LGMM模型已在多個研究領域有成功的應用,該模型在縱向數據分析中能夠識別不可觀測亞群的不同增長軌跡,進而深入剖析縱向數據中個體的發展情況,具有傳統增長模型所不具有的優勢,相信會在越來越多縱向數據分析中被采用,為相關學科研究者提供更加科學合理的建議。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
