融合交互信息和能量特征的三維復雜人體行為識別
2018-09-07 01:33:14王永雄張孫杰
小型微型計算機系統 2018年8期
王永雄,曾 艷,李 璇,尹 鐘,張孫杰,劉 麗
(上海理工大學 光電信息與計算機工程學院,上海 200093) E-mail:wyxiong@usst.edu.cn
1 引 言
識別和理解人的行為是智能服務機器人和智能輔助系統的主要任務之一,也是人機共融技術的主要難點和瓶頸.近年來,隨著3D設備(例如RGB-D攝像頭) 的普及,由于3D視覺具有較大優勢和表達能力,基于3D視覺的行為識別也得到了較大的發展.
首先,特征提取是基于圖像的行為識別最先考慮的問題.常見的特征主要有尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)[1]、方向梯度直方圖特征HOG[2](Histogram of Oriented Gradient)和人體姿態關節角等2D靜態特征[3],人體運動的速度、軌跡等3D動態特征[4]以及時空興趣點特征(Space-Time Interest Points,STIP[5])和改進密集軌跡特征(improved dense trajectories,IDT[6,7])等基于興趣點的特征.一般情況下,隨著特征維數的增加,識別準確率隨之提高,但是計算量隨之變大,而且難以從高層語義上進行理解,因此需要對特征數據進行降維,生成有利于識別的高層語義特征.Li FeiFei等人[8]提出了一種新的局部特征方法,通過使用局部的高層語義信息建立局部特征矩陣,然后使用聚類的方法建立BOW特征,實現了多種特征數據的融合和降維.近年來隨著深度學習理論的發展,將其應用于人體行為識別中,也取得了很好的效果[9,10].Ji等[11]將傳統卷積神經網絡擴展到具有時間信息的3DCNN,在視頻數據的時間維度和空間維度上進行特征計算.Ng等[12]使用長短時記憶型RNN對視頻進行建模,將底層CNN的輸出連接起來作為下一時刻的輸入,在UCF101數據庫上獲得了82.6%的識別率.從視覺顯著性和生物學觀點看,人總是關注人體運動的肢體和含有信息量的姿態.田國會等人[13]在三維關節點數據基礎上提取了向量角度與向量模的比值作為特征表征人體姿態,采用動態時間規整 (Dynamic Time Warping,DTW) 進行模板匹配,實現人體行為識別.我們認為:人體動作的差異不僅表現在位置信息上,還表現在肢體的基于能量特征表示的信息上.因此本文提取人體運動產生的關節點動能和姿態勢能作為全局運動特征[14],在此基礎上再加入描述性的局部特征,用于表示運動的形態變化,例如關節點關節角、關節點方向變化等,并采用BOW算法對特征降維,生成有利于識別的高層語義特征.
上述方法考慮了人體姿態的靜態和動態特征,但復雜的人體行為往往和物體、環境有交互作用.如果沒有融合人與物、人與環境、甚至人與人之間的交互信息,則無法消除或減少類似動作和復雜行為識別的不確定性和歧義性.例如奔跑和踢足球、喝水和打電話、手持刀和手持杯子等動作,人體姿態和運動過程相似,孤立地研究人的行為,而忽略了與人交互的物體或者場景信息,這無疑大大降低了推理的準確性.因此利用人與物、人與環境之間的交互信息,可以提高人體行為的識別率,減少行為識別的歧義性[15].常規的思路有兩個:一是分別識別人的行為和物體再融合;二是分別提取人的行為和物體的特征,組成組合特征再識別.Gupta和Davis提出了采用概率圖模型對人與物的交互作用進行建模,通過貝葉斯網絡同時對物體和行為進行分類和識別[16].Koppula等人[17]結合物品的“可操作性(affordances,例如杯子具有可移動性和可盛物性)”,采用結構化SVM方法進行復雜行為識別.Moore等人利用物體識別的結果提升行為識別的性能[18],或者利用行為識別的結果提升物體識別性能,然而上述的行為識別準確率依賴于物體分類的準確性.當物體分類出現錯誤時,其結果對行為識別往往有負面作用.在實際中,各式各樣的物體識別本身就很復雜,由于光線、角度,特別是手部的局部遮擋等原因,物體的準確定位、分割和識別都比較困難[19].因此本文提出了融合物體信息和能量特征的3D行為識別,具體步驟如下:在提取人體骨架特征的基礎上,采用Harris[20]算子檢測算法快速定位與人交互物體的關鍵點,然后在3D深度圖上利用區域生長法對物體進行分割,實現了從復雜背景中自動分割出待識別的物體,然后組合人體動能、勢能、其他局部特征和物體特征等多種特征,實現了融合人物交互信息的復雜行為識別.
本文的創新包括:
從能量的角度提取人體骨架動能、姿態勢能、關節點位置等特征構建局部特征矩陣,可以定量地表示人體行為的能量信息,并采用BOW算法對特征降維,生成有利于識別的高層語義特征.
在深度云圖中,采用Harris算子自動獲取區域生長法的種子,自動分割出與人體交互的手持物體,并提取交互物體的Hu矩特征融入最終的組合特征.
通過融合與人體產生交互的物體、環境信息,大幅度地提高類似動作或復雜行為的識別率.
2 特征提取和行為識別方法
3D人體行為常使用空間三維坐標、深度信息以及關節點角度等特征描述[21].本文使用Kinect獲得深度圖像和與之相對應的彩色圖像,利用Kinect SDK獲取人體三維骨架模型.本文采用的人體骨架模型由15個關節點組成,具體順序和編號如表1所示.
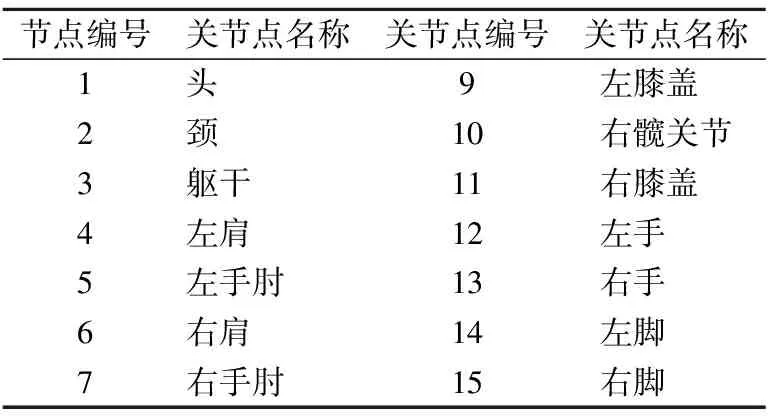
表1 關節點編號Table 1 Joint numbers
2.1 基于BOW特征的人體行為表示
根據人體生理學和運動學,我們首先提取關節點空間三維坐標、方向變化、關節點動能、姿態勢能和關節角等特征構建人體空間特征矩陣.Kinect可以識別15個關節點,因此每一幀圖像包含了一百多維特征數據.為了有效組合各種特征數據,降低特征向量維度,本文采用BOW模型構建特征向量.BOW構建過程如圖1.
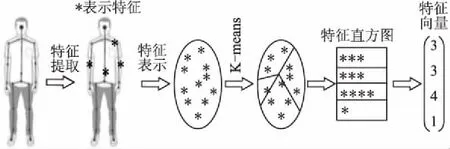
圖1 Bag Of Word構建過程Fig.1 Building process of Bag Of Word
根據提取的空間三維坐標、方向變化特征、關節點動能特征和人體姿態勢能特征等4類特征組成第Ft幀的特征矩陣Yt,它的每行對應一個關節點(n=15),按列依次存放以上4類特征,如(1)所示:
(1)
其中:Pn,t表示第n個關節點在Ft幀中的空間坐標.
φn,t=(xn,t-xn,t-1,yn,t-yn,t -1,zn,t-zn,t-1)
(2)
φn,t表示Ft幀中第n個關節點相對于Ft-1幀中第n個關節點的運動方向矢量.
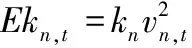
(3)
Ekn,t表示Ft幀中第n個關節點的動能,kn為第n個關節點的動能參數(為了簡單,實驗中kn取1),Δt表示相鄰兩幀之間的時間間隔,Ekn,t可以定量地表示人體骨架關節點的運動能量信息.
(4)
En,t表示人體姿態勢能,能夠定量地反映人體的姿態信息,L是勢能參數(實驗中選1),Pi,t為Ft幀中第i個關節點位置,P1,t表示Ft幀頭部關節點,即我們選定的零勢能參照點.
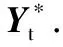
(5)
k-means中k值根據實驗選擇5為最佳,聚類迭代次數為100,n為15.聚類后得到5個聚類中心Ci(i=1,…,5),然后將所有特征向量映射到這5個聚類中心,得到第Ft幀的BOWt特征如下
BOWt=[bin1,…,bink]
(6)
BOW特征構建過程描述如下:
i.初始化:BOWt=[0,0,0,0,0],
ii.即bink=0(k=1,2,3,4,5)
iii.1)令
Yt=[vector1,vector2,vector3,…,vector15]T
(7)
2)利用K-means算法對vectori(i=1,2,…,15)聚類后得到5個聚類中C1、C2、C3、C4、C5即Ck(k=1,2,3,4,5)。
3)fori:15,
fork:5,
根據公式(8)計算所有vector與Ck的歐氏距離
Dk=‖vectori-Ck‖
(8)
end
如果D[index]是D中的最小值
binindex=binindex+1
end
關節角是人體骨架表示中常用的特征,在不同動作下,關節角的變化規律是不同的,例如刷牙洗臉時往往僅有上肢關節角變化幅度明顯,且呈現出有規律的變化,而人跑步或者行走時,四肢關節角都會發生明顯變化.因此四肢關節角作為一種識別特征是非常直觀有效的.我們根據人體運動學規律定義6個最具代表性的人體關節角,如圖2所示.
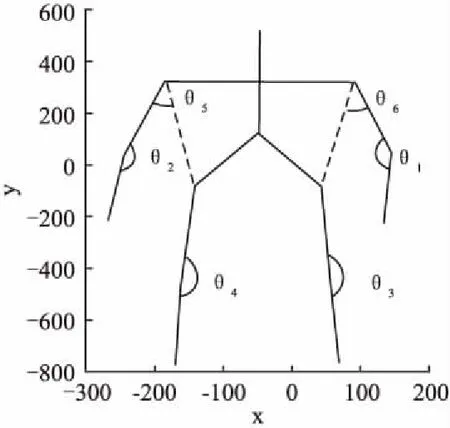
圖2 人體關節角示意圖Fig.2 Human joint angle
其中θ1和θ2表示左右手大臂與小臂形成的夾角,θ3和θ4分別表示左右腿大腿與小腿的夾角,θ5和θ6分別表示左右手大臂與軀干形成的夾角.然后對提取的6個關節角θi(i=1,2,…,6)歸一化處理,如下式,
(9)
由于本文提取的關節角特征個數較少不利于降維處理而且比較重要,因此關節角與BOWt一起構建特征向量,即構建一個k+6維的特征向量AFt(Activity Feature),
(10)
2.2 交互物體的檢測和分割
正確檢測與分割與人體產生交互的物體是有效提高人體行為識別的前提條件.一般來說手持物體是與人交互作用最多的物體,因此,我們這里只考慮人與物交互的手持物體.在復雜背景下,由于手持物體的大小不一、手對物體可能發生遮擋,手持物體的檢測和分割是比較困難.Harris算子就是一種局部特征提取算法,該算法可以獲得穩定、重復性高的角點,無論在哪個角度這些角點都可以很好地勾勒出物體的大致輪廓,基本不受手部遮擋的影響.
為了分割手持物體,Lv Xiong等人直接選取手部坐標作為區域生長法的生長種子點[22],該方法在實際應用中有一定局限性,例如很多時候手部中心位置 (關節點) 會稍微離開交互的物體區域,此時若以手部關節點為區域生長種子分割結果常常是不正確的.為了解決這個問題,降低誤分割率,本文提出了一種改進的區域生長種子定位方法,首先提取圖像中的Har-ris角點,將角點坐標(x,y)與對應深度圖的深度值depth構成Harris角點的三維坐標(x,y,depth),然后選取距離手部關節點最近的N個Harris角點,計算這N個點的中心作為區域生長種子(這里N=4,并確保種子與手部關節之間的距離小于閾值),具體流程如圖3.確定區域生長種子后,利用區域生長算法在深度圖像中實現復雜背景下手持物體的準確分割.
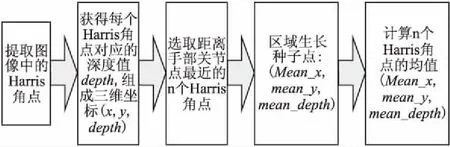
圖3 區域生長種子定位流程圖Fig.3 Flow chart of region growing seed location
2.3 融合交互物體特征的人體行為表示
幾何不變矩(Invariant Moments)是一種高效的圖像特征,具有平移、灰度、尺度、旋轉不變性.Hu提出把一副M*N的灰度分布圖像表示為函數f(x,y),(x,y)為圖像平面坐標,其p+q階幾何矩mqp和中心矩μqp定義如式(11)和式(12):
mpq=?xpyqf(x,y)
(11)
μpq=?(x-x0)p(y-y0)qf(x,y)
(12)
這里p,q=0,1,…;x0=m10/m00,y0=m01/m00,m10,m00,m01分別是p=1,q=0時的1階幾何矩、p=0,q=0時的0階幾何矩和p=0,q=1時的1階幾何矩.為了保證圖像特征具有平移不變性以及尺度不變性,如下公式定義歸一化中心不變矩.根據Hu的理論,利用歸一化中心矩作為特征能保證上述兩種不變性.
(13)
為了提高人體行為的識別率,減少行為識別的歧義性,通過加入物體特征信息可以有效避免因姿態相同而導致的誤識別,本文選擇Hu矩特征作為與人體產生交互物體的特征.Hu矩特征向量由7個矩特征組成,通常第一矩I1、和第二矩I2對識別貢獻較大,因此本文中只選取了I1和I2.
I1=y20+y02
(14)
(15)
融合物體特征的特征向量CFt(CombinedFeaturet)如下式
CFt=[AFtOFt]
(16)
2.4 分類方法介紹
基于核的SVM算法具有良好的泛化能力,且結構化風險小[23].其關鍵問題之一是選取合適的核函數和獲得最優的參數,選擇合適的核函數可使SVM發揮最好的分類能力,常用的核函數有線性核函數、多項式核函數、徑向基內核(Radial Basis Function,RBF Kernel)、sigmoid核函數.因為RBF核函數具有良好的性能且調節參數較少[24],本文采用基于RBF核函數的SVM分類器(RBF-SVM),RBF核函數公式如公式(17)所示:
(17)
其中xc為核函數中心,c為函數的寬度參數γ,為核參數.實驗發現RBF-SVM在實際分類問題中表現出了良好的性能由于實驗中涉及16組實驗動作的對比,而SVM算法最初是為二值分類問題設計的,當處理多類問題時,就需要構造合適的多類分類器.本實驗應用一對一法構建SVM多類分類器,其做法是在任意兩類樣本之間設計一個SVM,因此k個類別的樣本就需要設計k(k-1)/2個SVM.
3 實驗結果與分析
3.1 數據庫
為了驗證算法的有效性,本文分別在微軟公司的MSR Daily Activity 3D 數據庫[25,26]和康奈爾大學的CAD-60數據庫[27]進行實驗.這兩個數據庫都在計算機視覺領域尤其是人體行為識別領域應用非常廣泛.
MSR Daily Activity 3D數據庫包含了16個日常行為的短視頻:喝水、吃東西、閱讀書籍、打電話、寫字、使用筆記本、使用吸塵器、歡呼慶祝、站立不動、拋紙張、玩游戲、躺在沙發上、來回踱步、彈吉他、起來、坐下,如圖4.共有10位實驗者依次完成這16個動作,每個動作大概有120幀.
CAD-60數據庫包含了4個人12個日常行為的數據,具有較好的代表性.這12個動作分別為:漱口,刷牙,戴隱形眼鏡,打電話,喝水,打開藥盒,烹飪(切碎),烹飪(攪拌),在沙發上休息,黑板上寫字,用電腦工作,4 人中包含兩男兩女,男女中各有一個左撇子.每一位參與者在 5個不同的場景下:辦公室、廚房、臥室、洗漱間、客廳進行這12個日常動作.在本文實驗中為了驗證手持物體對行為識別的影響,只選取了打電話、黑板上寫字、喝水、刷牙、打開藥盒、用電腦工作這六個動作.

圖4 MSR Daily Activity 3D數據庫Fig.4 Date base of MSR Daily Activity 3D
這兩個數據庫都是由Kinect完成采集,其中包含深度圖像 (*.bin文件),人體關節點在三位空間中的坐標 (x,y,z)(*.txt文本)、關節點相對圖像的三維坐標(u,v,depth),其中u和v均做歸一化處理,depth表示對應像素點的深度值,以及RGB彩色視頻(*.avi文件).由于數據庫中絕大部分行為(動作)都包含了人—物交互關系,因此行為識別的難度比較大.
3.2 SVM分類器訓練
通過RBF-SVM訓練獲得分類器的兩個重要的參數:懲罰因子c和核參數γ[28],本實驗中采用的是臺灣大學林智仁教授開發的在matlab上的SVM工具包,其中包含交叉驗證方法的libsvm程序實現SVM算法,其中-c對應c,-g對應γ.參數訓練結果如圖5所示,圖中曲線表示識別率的等高線,標注的數值表示對應的識別率.通過反復交叉驗證選擇了一組最優參數c=32、g=24,星號標注的點為最優參數點.
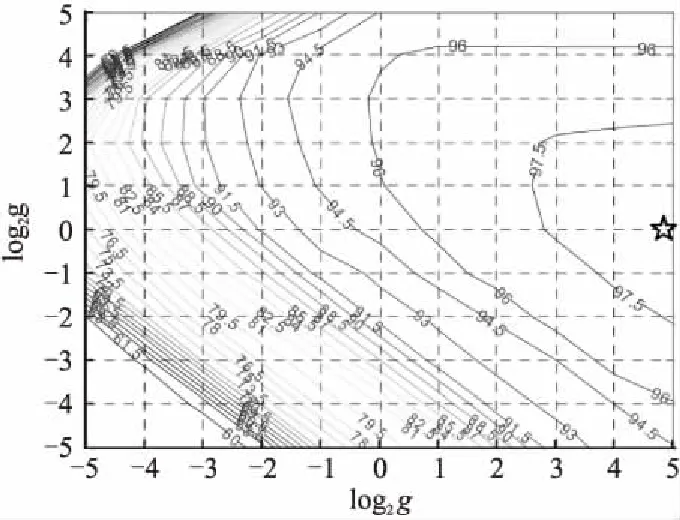
圖5 RBF-SVM參數c和g表示的識別率的等高線圖Fig.5 RBF-SVM recognition rate counter map of parameter c and g
3.3 實驗結果與分析
為了驗證物體自動分割效果和融合交互物體特征的復雜行為識別效果,分別進行了基于Harris角點檢測的物體自動分割實驗、基于人體特征AFt的行為識別和基于融合交互物體特征與人體行為特征CFt的行為識別實驗.
3.3.1 基于Harris算子的自動物體分割實驗
Harris算子可以有效地檢測出圖像中穩定、重復性高的角點,無論在哪個角度這些角點都可以很好地勾勒出物體的大致輪廓,并不受手部遮擋、光照變化的影響.因此我們選擇Harris角點自動提取區域生長算法的種子,然后在對應的深度圖像中,利用區域生長算法實現復雜背景下手持物體的自動分割,最后把分割出的物體結合原來的彩色圖顯現出來.
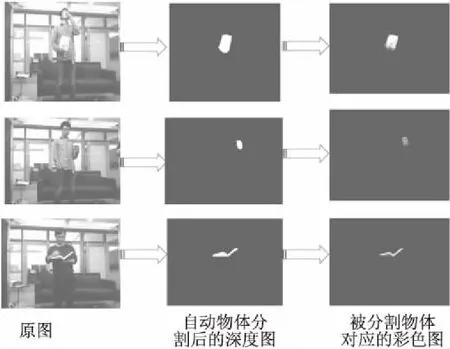
圖6 區域生長法自動物體分割圖Fig.6 Segmenting object automatically by region growing seed method
這里列出了“吃東西”,“喝水”,“看書”三個典型的具有手持物體的動作分割結果,實驗效果如圖6.從圖6第一列的彩色圖中可以看出第一個動作“吃東西”,其手持物體體積較大且正對鏡頭;第二個動作“喝水”,其手持物體“水杯”的體積較小且部分被手部遮擋;第三個動作“看書”,其手持物體“書本”沒有正對鏡頭只能看到側面.圖6的第2列是自動分割物體后的深度圖,可以看出實驗中3個動作中的物體沒有受到角度和大小的影響,都達到了很好的分割效果.圖6第3列是分割出的物體的對應彩色圖.
實驗結果顯示,基于Harris角點的區域生長法能夠較好地自動分割手持物體.
3.3.2 只采用人體特征AFt的行為識別實驗
我們分別在MSR Daily Activity 3D和CAD-60數據庫進行了實驗.實驗中,隨機提取該數據庫中每個動作的80%數據作為SVM的訓練集,將余下20%的數據作為測試集.重復實驗5次后,將實驗結果的平均值作為最終的實驗結果.
MSR Daily Activity 3D數據庫中每個動作的都存在手持物體,且許多動作之間有著較高的相似性.當只采用AFt作為特征而不考慮交互物體特征時,由姿態相同而導致的誤識別比較大,因此非常適合做對比實驗.圖7顯示了只采用AFt作為特征進行行為識別時MSR Daily Activity 3D數據庫中16個動作的混淆矩陣結果,從圖中可以看出實驗平均準確率僅為58.8%,如“喝水”、“吃東西”、“看書”、“打游戲”、“躺在沙發上”等動作的誤識別情況比較嚴重.
CAD-60數據庫數據量比較大,我們只選取了手持物體比較明顯的動作進行識別.從圖8中可以看出這六個動作的平均識別率已經高達88.0%,這說明這六個動作的人體姿態存在較大差異,應用人體特征識別可以取得比較滿意的識別效果.
3.3.3 基于組合交互物體特征與人體行為特征CFt的行為識別實驗
為了驗證交互物體信息對行為識別的有效性,這里采用組合的新特征CFt進行行為識別,其他的條件都與上一組實驗相同,行為識別的混淆矩陣如圖8、圖9.

圖7 只采用AFt特征在MSR數據庫上行為識別混淆矩陣Fig.7 Confusion matrix of activity recognition in MSR database based on AFt features
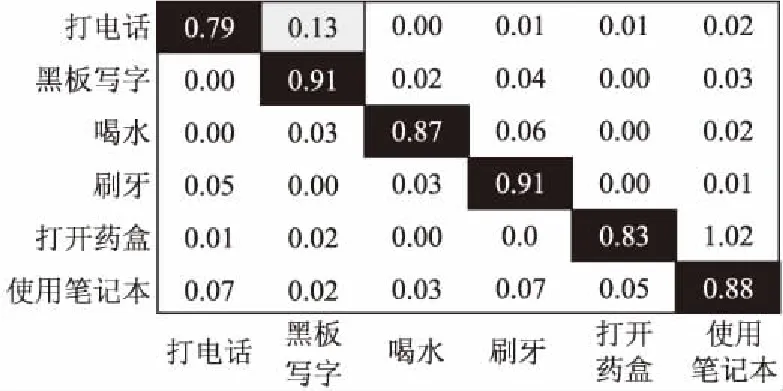
圖8 只采用AFt特征在CAD-60數據庫上的行為識別混淆矩陣Fig.8 Confusion matrix of activity recognition in CAD-60 database based on AFt features

圖9 基于CFt特征在MSR數據庫上的行為識別混淆矩陣Fig.9 Confusion matrix of activity recognitionin MSR database based on CFt features
從圖中可以看出融合手持物體特征之后,MSR Daily Activity 3D數據庫中的16個動作的準確率都有所提高,平均準確率從58.8%提高至82.9%.如“喝水”、“吃東西”、“看書”、“打電話”、“寫字”、“打游戲”、“扔紙團”、“彈吉他”等動作的識別率都很高,原因是這些動作中,準確地分割出了手持物體,準確地提取到物體特征,因此識別率得到大幅提升.CAD-60數據庫中6個動作的平均準確率也從88.0%提高至94.0%,可見這六個動作僅使用人體特征已經取得比較滿意的識別效果,加入物體特征后識別也更加準確了.
另外,從圖8中可以看出融合手持物體特征之后,“躺在沙發上” 、“站著不動”、“站立”、“走路”和“坐下”這5個動作的誤識率沒有明顯提高,主要原因是這五個行為中沒有手持物體.沒有手持物體的行為識別率偏低可能需要構建更復雜特征,針對這個問題,我們將做進一步研究.
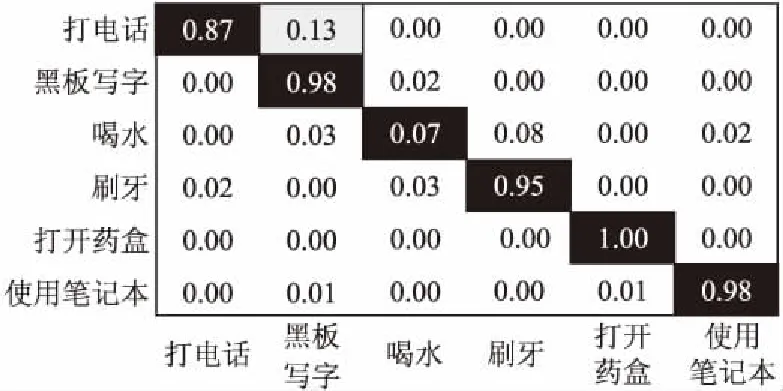
圖10 基于CFt特征在MSR數據庫上的行為識別混淆矩陣Fig.10 Confusion matrix of activity recognition in MSR database based on CFt features
在CAD-60數據庫上的實驗結果和MSR Daily Activity 3D數據庫中類似,對比圖8和圖10,我們可以看出6個動作的準確率都有了一定的提高平均準確率也從88.0%提高至94.0%,尤其是“打開藥盒”這個動作的準確率高達100%,可見這六個動作僅使用人體特征已經取得比較滿意的識別效果,加入物體特征后識別也更加準確了.
同時,為了驗證我們方法的總體性能,表2列舉了我們的方法和目前多種最新方法的實驗結果對比.

表2 不同特征和分類方法的對比結果Table 2 Comparison experiment results based on different features and methods
從表2中可以看出全部MSR Daily Activity 3D數據庫中16個行為的總的平均識別準確率為82.9%,處在中間水平,但我們的特征維數很低,只有13維,和別的方法相比計算量明顯減小.對比圖7和圖9,可以清楚地看出其中11個具有手持物體的復雜行為的識別率有明顯提高,比如喝水的識別率從69%提高到92%,其中喝水和吃東西的誤識別率從13%降到0,喝水和看書的誤識別率從7%降到0,這是由于喝水時的手持物體“杯子”與另兩個動作中的 “食物”、“書本”進行了有效的區分.特別地,如果去除沒有手持物體的5個行為,剩下的有手持物體的11個行為的平均識別率高達89.1%,超過其他所有方法的識別率.在CAD-60數據庫上的實驗結果顯示我們6個動作的準確率高達94.0%,在現有的方法上有了較大的提高.
因此,在兩個數據庫的實驗有效地驗證了融合手持物體特征可以大幅提高復雜行為的識別率,交互信息的引入對識別有很大的促進作用.
4 結束語
考慮到與人交互物體對人體行為識別的重要作用,本文提出了一種對交互物體信息和人體動作特征聯合建模的三維人體識別方法,該方法提取了人體骨架動能、關節點位置、姿態勢能等多種特征聚類為高層語義BOW特征,其中人體骨架動能和姿態勢能特征能夠定量地表示視頻中人體動作,區域生長法能夠較好地自動分割手持物體,融合交互物體的Hu矩特征對易混淆的人體行為有很好的補充作用,可以大幅度減少行為識別的歧義性,針對人與物體交互等復雜的人體行為識別率有較大的提高.在特征提取方面,例如與IDT方法結合是我們今后的研究方向之一,同時將考慮人體行為特征和交互物體的信息,進一步提高行為識別的準確性和適用性.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
