中文微博情感分析模型SR-CBOW
2018-09-07 01:23:18劉秋慧柴玉梅
小型微型計(jì)算機(jī)系統(tǒng) 2018年8期
劉秋慧,柴玉梅,劉 箴
1(鄭州大學(xué) 信息工程學(xué)院,鄭州 450001) 2(寧波大學(xué) 信息科學(xué)與工程學(xué)院,浙江 寧波 315211) E-mail:liuqhano@foxmail.com
1 引 言
微博作為一種開放的、發(fā)展迅速的社交媒體,越來越多的用戶將其作為分享和交流的平臺,人們不僅喜歡在微博上與朋友進(jìn)行交流、互動,更愿意對即時播出的影視劇和熱銷的產(chǎn)品及熱點(diǎn)事件發(fā)表自己的觀點(diǎn)和看法.龐大的微博用戶群,通過文本、聲音、圖片和視頻等方式,來發(fā)表自己對產(chǎn)品、事件和服務(wù)等實(shí)體對象的觀點(diǎn)和態(tài)度,產(chǎn)生的海量數(shù)據(jù)信息,隱藏著巨大的社會價值和商業(yè)價值,引發(fā)了很多學(xué)者積極參與到微博信息挖掘的研究工作中.
自2002年Bo Pang[1]提出情感分析以來,引起了國內(nèi)外學(xué)者的廣泛關(guān)注,隨著社交媒體的迅速發(fā)展,微博情感分析成為當(dāng)前研究的熱點(diǎn).從微博數(shù)據(jù)中分析和監(jiān)測到的用戶的信息,已經(jīng)被應(yīng)用到諸多領(lǐng)域中,例如商業(yè)部門通過分析微博數(shù)據(jù)中所包含的用戶對于某產(chǎn)品發(fā)表的觀點(diǎn)信息,預(yù)測產(chǎn)品的銷售狀況,幫助自動推薦系統(tǒng)更加準(zhǔn)確的判斷是否向用戶推送廣告;政府部門則通過監(jiān)測到的微博信息,來實(shí)時掌握民情、民意.
微博具有便捷性和原創(chuàng)性,內(nèi)容短小精悍一般限制在140字左右,融合了情感詞、網(wǎng)絡(luò)用語和表情符號等情感特征.構(gòu)建網(wǎng)絡(luò)用語詞典、情感詞表、表情符號向量空間和詞向量,是學(xué)習(xí)微博情感特征的有效方法之一.本文提出了半監(jiān)督的情感分析模型SR-CBOW(Softmax Regression-Continuous Bag-of-Words),利用詞向量學(xué)習(xí)微博短語的情感特征,可以同時進(jìn)行詞向量的訓(xùn)練和微博情感分析.本文的章節(jié)安排為:第2節(jié)介紹相關(guān)工作,第3節(jié)介紹本文提出的情感分析模型SR-CBOW,第4介紹實(shí)驗(yàn),第5節(jié)介紹工作總結(jié)與展望.
2 相關(guān)工作
微博情感分析方法歸納起來可以分為兩類,有監(jiān)督的學(xué)習(xí)方法和無監(jiān)督的學(xué)習(xí)方法.有監(jiān)督的學(xué)習(xí)方法,通過有標(biāo)簽的樣本來訓(xùn)練模型,并利用訓(xùn)練好的模型對未見文本進(jìn)行分類.起初,有監(jiān)督的機(jī)器學(xué)習(xí)方法樸素貝葉斯、最大熵和支持向量機(jī)被應(yīng)用于情感分類任務(wù)[2];近幾年,深度學(xué)習(xí)方法被推上了熱潮.無監(jiān)督的學(xué)習(xí)方法不需要人工標(biāo)注語料,省去了大量的人力勞動,因此,也得到了研究者的廣泛關(guān)注.基于主題模型的情感分類方法,是使用最為廣泛的無監(jiān)督情感分類方法[3],有代表性的一些算法有,Mei[4]等人提出的主題情感模型TSM,Lin[5]等人提出的基于LDA模型的JST模型.無監(jiān)督的學(xué)習(xí)方法雖然不需要付出高昂的代價來標(biāo)注數(shù)據(jù),但是其情感分析的結(jié)果往往略低于有監(jiān)督的學(xué)習(xí)方法.
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一種范式,近年來引起工業(yè)界和學(xué)術(shù)界的廣泛關(guān)注[6].深度學(xué)習(xí)常見的三種基本模型為多層感知機(jī)(MLP,Multi-layer Perceptron)、循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network)和卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network),被應(yīng)用于分詞、詞性標(biāo)注、情感分析和機(jī)器翻譯等諸多自然語言處理任務(wù)中.何[7]等人提出了增強(qiáng)情感語義的多通道卷積神經(jīng)網(wǎng)絡(luò)(EMCNN,Emotion-semantics enhanced Multi-channel Convolution Neural Network)模型,該模型利用表情符號的向量增強(qiáng)多通道卷積神經(jīng)網(wǎng)絡(luò)(MCNN,Multi-channel Convolution Neural Network)模型的情感語義,來提高微博情緒識別的準(zhǔn)確性.梁[8]等人在遞歸自編碼網(wǎng)絡(luò)的基礎(chǔ)上,構(gòu)建極性情感轉(zhuǎn)移模型,并將其應(yīng)用于微博情感傾向性分析任務(wù)中.深度學(xué)習(xí)的模型較復(fù)雜,導(dǎo)致模型對數(shù)據(jù)集的需求更大,模型訓(xùn)練需要的時間也更多.
微博數(shù)據(jù)中表情符號、網(wǎng)絡(luò)用語和無情感色彩字符的出現(xiàn),嚴(yán)重制約微博情感分析性能的提高.表情符號作為情感表達(dá)的方式之一,在微博文本中出現(xiàn)的概率超過7%,模型對于表情符號的理解是情感分析任務(wù)的難點(diǎn)之一,Jiang[9]等人提出表情符號空間模型(ESM,Emoticon Space Model),利用一維向量空間表示一個表情符號,將詞替換為與之相似度最高的表情符號,并用其進(jìn)一步構(gòu)建微博的向量表示,該方法通過將文字語言替換為更簡潔、直觀地表情達(dá)意的表情符號,巧妙的把高維的詞向量轉(zhuǎn)換為低維的表情符號向量,使之在少量手工標(biāo)注的數(shù)據(jù)上有更好的表現(xiàn);網(wǎng)絡(luò)用語的自主化、個性化、全息化、符號化、創(chuàng)新化等特性,使其信息傳遞的方式更形象、使用也越來越廣泛,按照其來源網(wǎng)絡(luò)用語被分為諧音詞、縮略詞、象形詞、轉(zhuǎn)義詞和新詞五大類[10],如諧音詞“厚厚”表達(dá)的涵義為“吼吼”表示開心,縮略詞“請?jiān)时睘椤罢堅(jiān)试S我做一個悲傷的表情”的簡寫,象形詞“orz”像一個人跪在那里,表示自己很無奈,新詞“我去”表示對于某事感到驚訝,而統(tǒng)計(jì)模型較難學(xué)習(xí)該類詞明確的語義信息,網(wǎng)絡(luò)詞匯詞典的構(gòu)建,為此問題的解決提供了幫助;微博文本中數(shù)字、URL等無情感色彩的字符的出現(xiàn),影響了分詞和詞性標(biāo)注等情感分析基礎(chǔ)任務(wù)的準(zhǔn)確性,通過刪除文本中的該類字符,降低噪聲的干擾以提高情感分析的準(zhǔn)確性.
針對微博數(shù)據(jù)的特點(diǎn)及中文微博情感分析任務(wù)中人工標(biāo)注數(shù)據(jù)相對較少的情況,本文提出了半監(jiān)督的情感分析模型SR-CBOW.與受限于具體語境的基于語料庫的方法相比,該模型對大規(guī)模無標(biāo)注的微博語料進(jìn)行學(xué)習(xí),利用自動獲取的語義信息,輔助完成情感分析任務(wù).對于不平衡的微博情感分析數(shù)據(jù)集,本文對語義相似度最高的微博進(jìn)行合并,通過減少所占比重較高的情感類的樣本數(shù)量,解決數(shù)據(jù)集的不平衡問題;為提高SR-CBOW模型情感分析的準(zhǔn)確性,采用否定擴(kuò)散的方法突出否定詞的重要性,利用對詞語添加的否定標(biāo)記,來獲取關(guān)鍵的詞序信息,協(xié)助SR-CBOW模型實(shí)現(xiàn)情感轉(zhuǎn)移.
3 情感分析模型SR-CBOW
SR-CBOW模型在對微博的向量表示進(jìn)行情感分類的同時,利用微博中詞語的上下文信息進(jìn)行詞向量的訓(xùn)練,從而使模型得以有效地利用包含在文本中的語言信息,更好地完成情感分類任務(wù).SR-CBOW模型進(jìn)行情感分析的主要流程,如圖1所示.
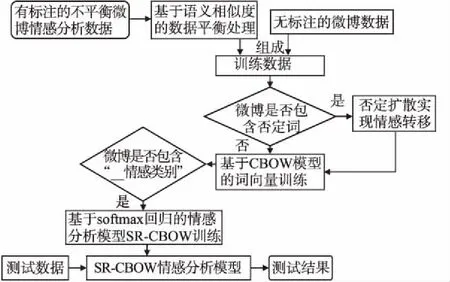
圖1 SR-CBOW模型流程圖Fig.1 SR-CBOW model flowchart
首先,通過基于語義相似度的數(shù)據(jù)集平衡方法,均衡微博情感分析數(shù)據(jù)集中不同情感類的樣本數(shù)量,將得到的均衡數(shù)據(jù)集和大量無標(biāo)注的微博數(shù)據(jù),作為模型的訓(xùn)練數(shù)據(jù);其次,對訓(xùn)練數(shù)據(jù)中包含否定詞的微博進(jìn)行否定擴(kuò)散,通過添加否定標(biāo)記,來標(biāo)識關(guān)鍵的詞序信息,緩解SR-CBOW模型構(gòu)建過程中,微博向量表示方式造成詞序信息丟失的問題,協(xié)助模型對包含否定詞的微博進(jìn)行情感轉(zhuǎn)移;最終,CBOW模型根據(jù)窗口內(nèi)的上下文信息預(yù)測當(dāng)前詞,進(jìn)行詞向量的訓(xùn)練和語義信息的獲取,通過查找向量表,得到微博中所有詞的向量表示,并對其進(jìn)行累加取平均,作為微博短語的向量表示,并通過 softmax回歸方法對微博的向量表示進(jìn)行情感分類.
為了提高詞向量的質(zhì)量,本文在訓(xùn)練語料中加入了大量未標(biāo)注的微博數(shù)據(jù),并以“__情感類別”區(qū)分有標(biāo)注的情感分析語料以及未標(biāo)注的純文本語料,在進(jìn)行詞向量訓(xùn)練之后,如果數(shù)據(jù)中包含“__情感類別”標(biāo)記,則對該微博進(jìn)行情感分析模型的訓(xùn)練.
3.1 基于語義相似度的數(shù)據(jù)平衡處理
不平衡數(shù)據(jù)集使SR-CBOW模型預(yù)測的結(jié)果往往傾向于樣本數(shù)量較多的情感類,嚴(yán)重影響了情感分析的結(jié)果.針對此問題,本文采用基于微博語義相似度的數(shù)據(jù)平衡方法,通過合并相似度最高的微博,緩解數(shù)據(jù)集的不平衡性.
定義1.本文將情感類別相同的微博twg和twh的相似度函數(shù)Sim(twg,twh)定義為:
(1)
其中,wgi與whj表示微博twg和twh中出現(xiàn)的動詞、形容詞或副詞,ng和nh分別代表上述三類詞語在微博twg和twh中總的數(shù)量,sim(wgi,whj)[11]表示基于知網(wǎng)的詞語wgi和whj的相似度計(jì)算.首先給定某一情感類別,然后遍歷數(shù)據(jù)集中該情感類的所有微博,并將相似度最高的兩條微博進(jìn)行合并,每進(jìn)行一輪,該情感類的微博樣本數(shù)減半.該方法在沒有數(shù)據(jù)損失的情況下,降低了訓(xùn)練數(shù)據(jù)集上所占比重最高的情感類的樣本數(shù)量,增加了低頻情感類別的權(quán)重,從而均衡模型預(yù)測結(jié)果的分布、提高情感分析的性能.
3.2 否定擴(kuò)散實(shí)現(xiàn)情感轉(zhuǎn)移
模型對于包含否定詞的微博短語,較難做出準(zhǔn)確的分類.針對此問題,采用否定擴(kuò)散的方法來突出否定詞的重要性,與傳統(tǒng)的TF-IDF[12]相比,該方法不僅可以突出重要詞語、抑制次要詞語,還可以利用添加的否定標(biāo)記,來獲取關(guān)鍵的詞序信息.
SR-CBOW模型的構(gòu)建過程中,通過向量累加來構(gòu)建微博向量表示的方式,會導(dǎo)致詞序信息的丟失,尤其是對于有否定詞出現(xiàn)的微博,關(guān)鍵的詞序信息決定了是否對該微博進(jìn)行情感極性轉(zhuǎn)移.例如微博“我/rr 送/v 的/ude1 禮物/n 你/rr 喜歡/vi 不/d”和“我/rr 送/v 的/ude1 禮物/n 你/rr 不/d 喜歡/vi”有相同的向量表示,如公式2和3所示,但要表達(dá)的情感信息卻截然不同.
(v我+v送+v的+v禮物+v你+v喜歡+v不)/ 7
(2)
(v我+v送+v的+v禮物+v你+v不+v喜歡)/ 7
(3)
針對上述問題,本文采用否定擴(kuò)散的方法,對出現(xiàn)在否定詞之后的詞語添加否定標(biāo)記,例如,原有的情感詞“喜歡”,添加否定標(biāo)記后得到新的詞“喜歡
(v我+v送+v的+v禮物+v你+v喜歡+v不)/ 7
(4)
(v我+v送+v的+v禮物+v你+v不+v喜歡< neg >)/ 7
(5)
從公式(4)和公式(5)中可以看出,否定擴(kuò)散的方法通過對微博中相應(yīng)的詞語添加否定標(biāo)記,來標(biāo)識動詞、形容詞和副詞與否定詞的前后位置,為SR-CBOW模型提供關(guān)鍵的詞序信息;同時通過添加否定標(biāo)記,將原有的情感詞“喜歡”改變?yōu)樾碌脑~“喜歡
本文收集建立的否定詞表,如表1所示.

表1 否定詞表Table 1 Privative words table
考慮到一個否定詞只能影響它所在的短句,而不是整條微博,因此,將否定擴(kuò)散的范圍限定到否定詞所在的短句中,例如,對于微博“不/d 舒服/a./wj 拉肚子/v./wj 還/d 低燒/n.”只需對第一個短句進(jìn)行否定擴(kuò)散.本文收集建立了標(biāo)點(diǎn)符號表,將否定擴(kuò)散限制在一定的范圍內(nèi),所包含的符號如表2所示.

表2 標(biāo)點(diǎn)符號表Table 2 Punctuation table
一個詞語之前可能存在多個否定詞,本文假定雙重否定表示肯定,當(dāng)已記錄否定詞的數(shù)量為奇數(shù),且當(dāng)前詞語屬于動詞、形容詞或副詞時,才對其添加否定標(biāo)記,進(jìn)行否定擴(kuò)散,具體實(shí)現(xiàn)過程如算法1所示.
算法1.否定擴(kuò)散
輸入:微博tw,否定詞表privative_table,標(biāo)點(diǎn)符號表Punctuation_table
輸出:否定擴(kuò)散后的微博
1. 首先使用NLPIR分詞工具進(jìn)行分詞和詞性標(biāo)注工作
2. 初始化否定標(biāo)志flag=False
3. forwintwdo
4. ifwinprivative_tablethen
flag=flag取反
5. else ifwinPunctuation_tablethen
flag=False
else
6. ifflagandw∈{verb,adjective,adverb} then
w=w+“
end if
end if
更新tw
end for
7. returntw
3.3 SR-CBOW模型實(shí)現(xiàn)情感分類
3.3.1 基于CBOW模型的詞向量訓(xùn)練
目前微博情感分析的語料較少,模型難以充分獲取低頻詞的語義信息,導(dǎo)致情感分析模型無法得到有效的訓(xùn)練.針對此問題,CBOW模型通過周圍的詞來預(yù)測當(dāng)前詞,有效地利用了包含在文本中的語言信息,協(xié)助SR-CBOW模型完成情感分析任務(wù);并采用欠采樣的方法,均衡數(shù)據(jù)中的高頻詞和低頻詞,提高詞語和微博向量表示的質(zhì)量,為情感分析奠定基礎(chǔ);為了提高模型的訓(xùn)練速度,采用了近似于-log softmax的噪聲對比估計(jì)方法.
CBOW模型通過上下文來預(yù)測當(dāng)前詞,共分為輸入層、投射層和輸出層三部分,CBOW模型的結(jié)構(gòu)如圖2所示.
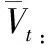
(6)
為了均衡微博文本中高頻詞語及低頻詞語的影響,使出現(xiàn)頻率較低的詞語仍然能夠得到充分的訓(xùn)練,在取上下文詞語時,對其進(jìn)行欠采樣處理,按照公式(7)所示的概率舍棄詞語wt+i:
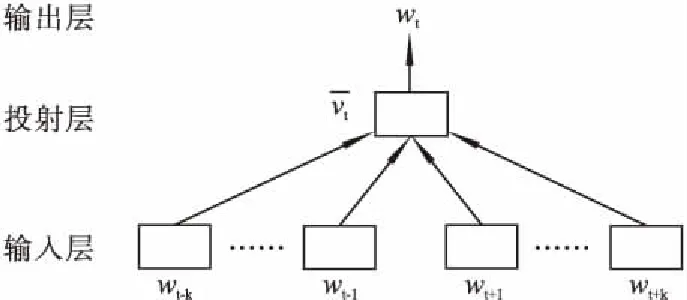
圖2 CBOW模型結(jié)構(gòu)圖Fig.2 CBOW model structure diagram
(7)
其中f(wt+i)表示詞語wt+i在訓(xùn)練語料中出現(xiàn)的頻率,λ為預(yù)設(shè)定的閾值,實(shí)驗(yàn)中使用10-5.
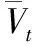
(8)
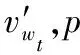
(9)
其中σ(·)為sigmoid函數(shù),負(fù)例集合N為:
N={wi|wi∈V&wi?{wt-k…wt+k}}
(10)
3.3.2 基于softmax回歸的情感分類
softmax回歸是邏輯回歸在多分類問題上的擴(kuò)展,是常用的有監(jiān)督的多分類方法.本文采用softmax回歸模型對微博的向量表示進(jìn)行情感分類,通過最優(yōu)化負(fù)對數(shù)似然懲罰函數(shù),對情感分析模型SR-CBOW進(jìn)行訓(xùn)練.
定義2.本文將微博短語的向量表示定義為,微博中所有詞語向量累加的均值,如公式(11)所示:
(11)
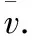
(12)
其中W2為權(quán)重矩陣,m表示情感類別數(shù),b為偏置,s的維度為m.微博屬于各個情感類的成績分別為s1,s2…sm,并利用softmax函數(shù)計(jì)算微博屬于每個情感類別的概率:
(13)
其中yi表示第i維是否為微博的目標(biāo)情感類別,如果第i維是微博的目標(biāo)情感類,yi為1,否則yi為0.p的每一維代表模型預(yù)測微博為相應(yīng)情感類別的概率,概率最大的情感類別為該微博情感分析的結(jié)果.模型訓(xùn)練的目標(biāo)是使目標(biāo)情感類別的概率盡可能的大,使用的懲罰函數(shù)為:
(14)
情感分析模型SR-CBOW在大量無標(biāo)注的微博數(shù)據(jù)和少量標(biāo)注的情感分析數(shù)據(jù)上進(jìn)行訓(xùn)練,其過程如算法2所示.
算法2.SR-CBOW模型的訓(xùn)練
輸入:微博訓(xùn)練數(shù)據(jù)集D,初始學(xué)習(xí)速率start_lr,無監(jiān)督訓(xùn)練周期cbow_epoch,詞向量矩陣M,系數(shù)矩陣W1,W2
輸出:訓(xùn)練好的情感分析模型SR-CBOW
1. 初始化訓(xùn)練周期epoch=1
2.D1=對D進(jìn)行基于語義相似度的數(shù)據(jù)平衡處理
3. while 誤差下降 do
lr=start_lr/ epoch
4. fortwinD1do
5.tw=對包含否定詞的tw進(jìn)行否定擴(kuò)散
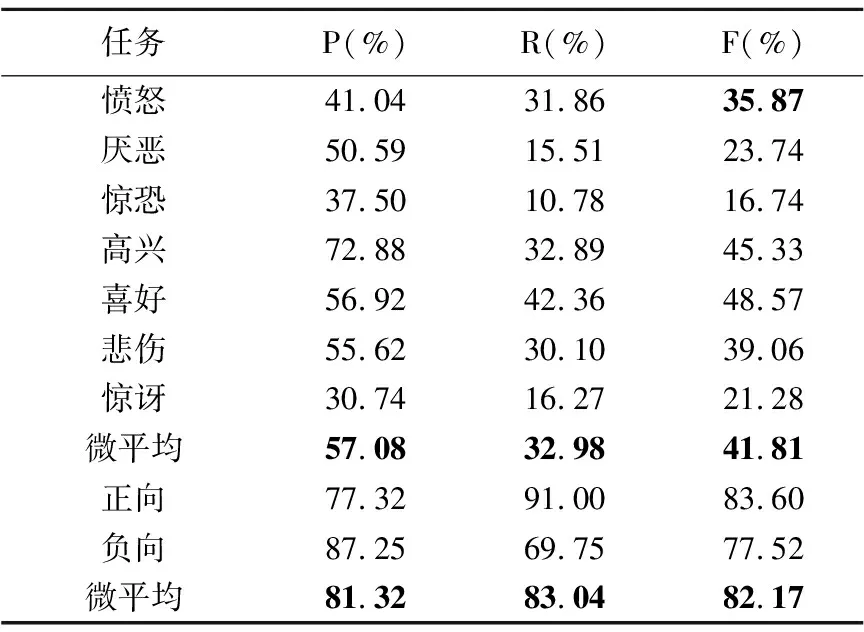
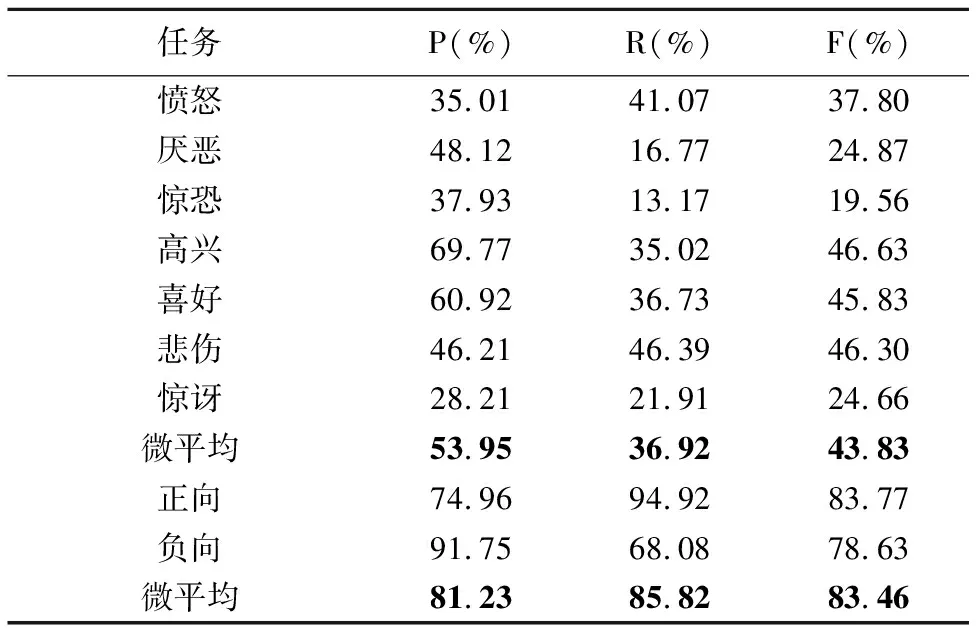
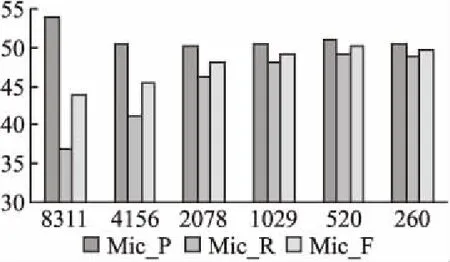
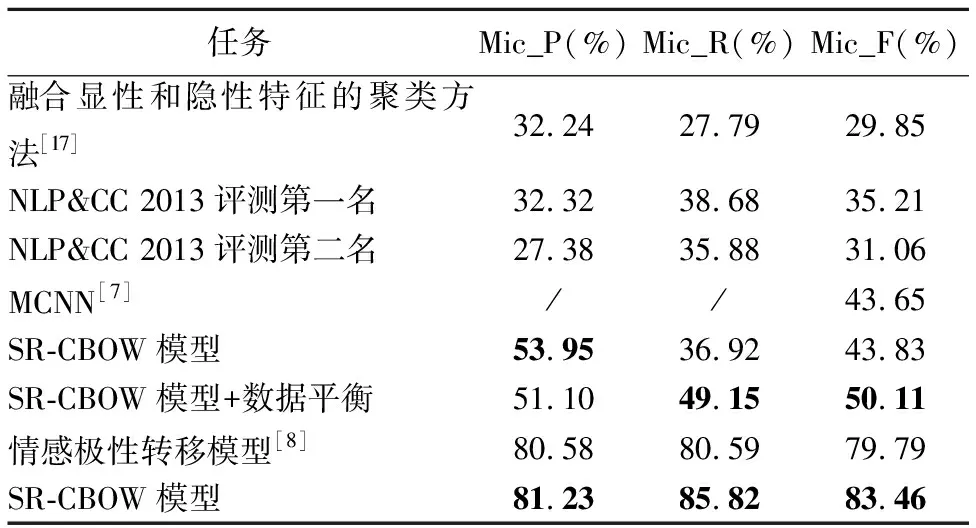
string_tag=獲取tw的第一個標(biāo)記
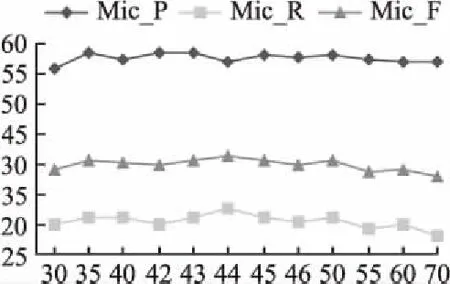
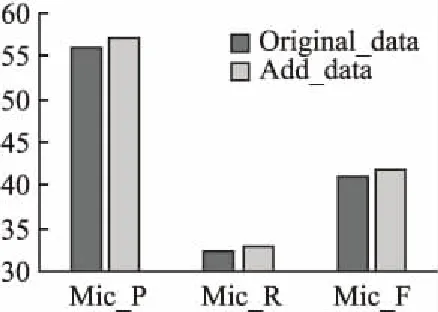
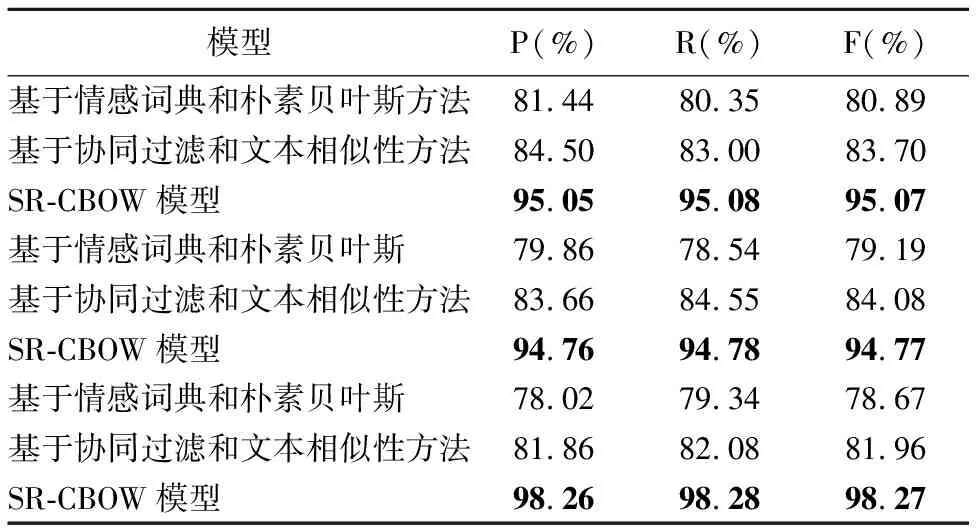
6. ifepoch 7. forwintwdo w左右各取k個詞作為CBOW模型的輸入,預(yù)測w,計(jì)算懲罰函數(shù)對M、W1的導(dǎo)數(shù)△M、△W1 M=M-lr* △M W1=W1-lr* △W1 end for end if 8. ifstring_tag==“__情感類別” then tw中所有詞向量通過情感分析模型預(yù)測情感類別,計(jì)算懲罰函數(shù)對M、W2的導(dǎo)數(shù)△M、△W2 M=M-lr* △M W2=W2-lr* △W2 end if end for epoch=epoch+1 end while 9. return SR-CBOW模型 本文實(shí)驗(yàn)所使用的數(shù)據(jù)是NLP&CC2013情緒識別任務(wù)和CCIR2014情感傾向性分析任務(wù)的評測數(shù)據(jù),無情感標(biāo)簽的微博語料來源于中國爬盟網(wǎng)站,共整理得到約30G的微博文本.情緒識別任務(wù)將情感分為7類,分別對應(yīng)憤怒(anger)、厭惡(disgust)、驚恐(fear)、高興(happiness)、喜好(like)、悲傷(sadness)和驚訝(surprise),情感傾向性分析任務(wù)將情感分為兩類正向和負(fù)向,訓(xùn)練集中每個情感類及對應(yīng)出現(xiàn)的頻次(樣本的數(shù)量)如表3所示. 本文使用準(zhǔn)確率P(Precesion)、召回率R(Recall)、F值(F-measure)和微平均評估情感分析模型SR-CBOW,微平均的計(jì)算公式為: 表3 情感類別及出現(xiàn)的頻次Table 3 Emotions and frequency of occurrence 其中sys_correct表示模型預(yù)測的結(jié)果和目標(biāo)值一致的數(shù)目,gold表示微博的目標(biāo)情感數(shù)目,sys_proposed表示模型標(biāo)注的數(shù)目,i的取值在情緒識別任務(wù)和情感傾向性分析任務(wù)中,分別對應(yīng)7類情感值和2類情感傾向值. 本文共分為5組實(shí)驗(yàn),第1組實(shí)驗(yàn)是對向量維度的選擇,以期得到能較好適應(yīng)模型的向量表示;第2組實(shí)驗(yàn)是在第1組實(shí)驗(yàn)的基礎(chǔ)上展開的,利用無標(biāo)注的微博數(shù)據(jù)協(xié)助模型訓(xùn)練;第3組實(shí)驗(yàn)驗(yàn)證本文提出的否定擴(kuò)散方法的有效性;第4組實(shí)驗(yàn)利用基于語義相似度的數(shù)據(jù)平衡方法,對沒有情感色彩的微博樣本進(jìn)行合并,來緩解數(shù)據(jù)集的不平衡性,從而提高情感分析的準(zhǔn)確率;第5組實(shí)驗(yàn)在電腦、酒店和書籍消費(fèi)評價的語料(平衡數(shù)據(jù)集)上進(jìn)行,來驗(yàn)證移除定制技巧后SR-CBOW模型的泛化能力和領(lǐng)域適應(yīng)能力. 向量的維度是需要調(diào)整的主要參數(shù),維度越高模型中的參數(shù)就越多,容易導(dǎo)致模型過擬合,維度過低則難以包含所需要的信息.本文以情緒識別任務(wù)為主,通過調(diào)整詞語向量的維度,選取適合數(shù)據(jù)集和模型的向量維度,參數(shù)調(diào)整的過程如圖3所示. 圖3 向量維度調(diào)整Fig.3 Vector dimension adjustment 從圖3可以看出,當(dāng)情感分析模型中詞向量的維度高于50時,其準(zhǔn)確率開始下降,在向量維度為44時,Mic_P、Mic_R和Mic_F的值分別為56.1%、32.37%、41.05%,此時的Mic_F值最高,接下來的實(shí)驗(yàn)中向量維度都設(shè)置為44. 在向量維度為44的基礎(chǔ)上,訓(xùn)練數(shù)據(jù)中加入大量無情感標(biāo)簽的微博數(shù)據(jù),模型的Mic_F值提高了0.76個百分點(diǎn),其結(jié)果如圖4所示. 圖4 加入無標(biāo)簽數(shù)據(jù)集的情感分析結(jié)果Fig.4 Emotion analysis results with unlabeled data set added 灰色的柱狀圖表示加入無情感標(biāo)簽微博數(shù)據(jù)后,情緒識別任務(wù)的結(jié)果.情緒識別任務(wù)和情感傾向性分析任務(wù),每個情感類的識別結(jié)果,如表4所示. 表4 情感分析結(jié)果Table 4 Emotion analysis results 其中情緒識別任務(wù)的情感分析結(jié)果,明顯低于情感傾向性分析任務(wù),從任務(wù)本身和任務(wù)的數(shù)據(jù)特點(diǎn)分析,情緒識別任務(wù)中每個情感類的樣本數(shù)量分布不均衡,尤其是標(biāo)簽為“none”的樣本,約占樣本總量的3/5,是導(dǎo)致情緒識別結(jié)果較低的主要原因. 加入否定擴(kuò)散之后,在情緒識別任務(wù)和情感傾向性分析任務(wù)中,Mic_F值分別提高了2.02和1.29個百分點(diǎn),幾乎每個情緒類別的召回率都得到提高.因?yàn)?微博短語往往較短,數(shù)據(jù)中包含否定詞語的情況也較少,所以,該方法對情感分析結(jié)果的提高程度有限.具體結(jié)果如表5所示. 從表4和表5可以看出情緒識別任務(wù)中模型的準(zhǔn)確率較高,而召回率卻很低.根據(jù)表3的統(tǒng)計(jì)信息可以發(fā)現(xiàn)訓(xùn)練樣例中包含大量沒有情感色彩的微博,數(shù)據(jù)集的極度不平衡是造成召回率低的主要原因.針對此問題,本文通過減少標(biāo)簽為“none”的樣本數(shù)量,來降低其頻率,以均衡模型的準(zhǔn)確率與召回率.數(shù)據(jù)平衡處理對結(jié)果的影響,如圖5所示. 表5 基于否定擴(kuò)散的情感分析結(jié)果Table 5 Emotion analysis results with negative spreading 圖5 數(shù)據(jù)平衡處理及對應(yīng)的情感分析結(jié)果Fig.5 Data balancing and emotion analysis results 其中縱軸表示情感分析結(jié)果的評估值,橫軸表示將沒有情感色彩的微博合并后,微博樣本的數(shù)量,當(dāng)執(zhí)行4輪數(shù)據(jù)集平衡處理時,情感分析的結(jié)果最好.隨著標(biāo)簽為“none”的微博樣本,在訓(xùn)練語料中比重的降低,情感分析模型的召回率快速上升,同時Mic_F值得到較為明顯的提高;當(dāng)該比重降低到一定程度后,情感分析的準(zhǔn)確性開始下降,本文只取得了局部最優(yōu)結(jié)果.選擇Mic_F值最高的結(jié)果,作為SR-CBOW模型的最終結(jié)果,其Mic_F值提高了6.28個百分點(diǎn),與其它模型的情感分析結(jié)果進(jìn)行比較,如表6所示. 表6 情感分析結(jié)果對比Table 6 Comparison of emotion analysis results 其中融合顯性和隱性特征的無監(jiān)督聚類方法的結(jié)果要略低于其它方法,基于深度學(xué)習(xí)的MCNN模型和情感極性轉(zhuǎn)移模型,雖然結(jié)果較無監(jiān)督的聚類方法好,但訓(xùn)練模型需要的時間較多,且F值略低于未進(jìn)行數(shù)據(jù)平衡的SR-CBOW模型.本文提出的半監(jiān)督情感分析模型SR-CBOW,結(jié)構(gòu)簡單、模型訓(xùn)練快,并且情感分析結(jié)果優(yōu)于已知模型. 由表6可以看出,在數(shù)據(jù)集不平衡的微博情緒識別任務(wù)中,通過平衡數(shù)據(jù)集,可以使SR-CBOW模型的情感分析結(jié)果得到進(jìn)一步的提升. 為了驗(yàn)證本文提出的SR-CBOW模型的魯棒性,本文在其它領(lǐng)域的平衡數(shù)據(jù)集上,使用移除定制技巧的情感分析模型SR-CBOW進(jìn)行實(shí)驗(yàn),來檢驗(yàn)?zāi)P偷姆夯芰吞幚砥渌I(lǐng)域數(shù)據(jù)的能力.該數(shù)據(jù)集為包含電腦、酒店和書籍3個領(lǐng)域消費(fèi)評價數(shù)據(jù)的中文情感挖掘語料-ChnSentiCorp[18].對應(yīng)的情感分析結(jié)果如表7所示. 表7 消費(fèi)評價語料的情感分析結(jié)果Table 7 Consumption evaluation data emotion analysis results 前兩種方法是文獻(xiàn)[18]中實(shí)驗(yàn)及對比實(shí)驗(yàn)的方法.通過表7可以看出,未使用數(shù)據(jù)平衡手段的SR-CBOW模型,在消費(fèi)評價數(shù)據(jù)的情感分析任務(wù)中,也可以取得理想的結(jié)果. 本文提出情感分析模型SR-CBOW,利用文本中包含的語言信息輔助模型的訓(xùn)練,并通過否定擴(kuò)散的方法,解決生成微博向量表示時語序信息丟失所帶來的問題,在情緒識別任務(wù)和情感傾向性分析任務(wù)中取得了目前已知的最好結(jié)果,并可以通過均衡數(shù)據(jù)集等手段進(jìn)一步提升. 不同的詞語蘊(yùn)含不同程度的情感信息,對情感分析結(jié)果的影響程度也不同;否定擴(kuò)散可以保留情感分析問題中較關(guān)鍵的語序信息,但仍會損失一些語序信息.針對這些問題,下一步將探究一種保留詞序信息的、加權(quán)的微博向量表示構(gòu)建方法,實(shí)現(xiàn)對微博向量表示的自動化學(xué)習(xí),以期獲得更好的微博情感分析結(jié)果.4 實(shí) 驗(yàn)
4.1 實(shí)驗(yàn)數(shù)據(jù)及評價指標(biāo)

4.2 實(shí)驗(yàn)及結(jié)果分析
5 總結(jié)與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(bào)(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
