DF-MAP:一種基于概率圖模型的案件判決路徑挖掘算法
2018-09-07 01:23:18彭敦陸
小型微型計算機系統 2018年8期
關鍵詞:規則
高 丹,彭敦陸
(上海理工大學 光電信息與計算機工程學院,上海 200093) E-mail:gaodan223@126.com
1 引 言
隨著計算機技術的發展以及互聯網技術的飛速普及,海量法律文書數據產生.截至2017年3月22日,中國裁判網的文書總量達到27,248,664篇.如何有效地利用這些海量文本數據產生有價值的信息,是信息抽取領域要解決的重要任務之一.
審判事務中,案由確定是人民法院正確審判案件的基礎和保障,案由的準確判斷直接關系到當事人法律關系的認定以及適用法律的正確選擇,一直以來備受社會各界關注.最高人民法院的司法數據表明法院新收、審執結案件數量持續上升:2015年,全國法院新收各類案件17,659,861件,同比上升22.81%,審執結案件16,713,793件,同比上升21.14%.同時,法院編制人員約34萬,其中法官人員僅僅19.6萬.各項數據意味著:
1)全國法院平均每天處理的案件高達4萬多件;
2)“案多人少”成為各國法院的突出矛盾.以上事實均為構建高效的審判服務體系,同時保證立案的準確性提出了巨大的挑戰.
針對上述挑戰,自然語言處理作為一門實現人機間自然語言通信的學科,為其提供了實現的途徑.文獻[1]中提出一種短文本自動分類模型,該模型挖掘已有的語義單元進行聚類,在此基礎上結合CNN的自動學習能力對短文本進行自動分類;文獻[2]中作者深度剖析Tweet網站的領域特征,基于斯坦福CoreNLP與POS工具,運用規則增強解析能力與語料庫,實現tweet的關鍵詞自動抽取.這些研究表明,人工智能與計算機技術的結合在文本信息自動挖掘方面具有重要的應用價值.受上述研究的啟發,論文試圖通過對海量歷史法律文書進行深入分析,提取案情描述關鍵詞與適用法律中隱藏的規則集合,并基于Rete算法構建Rete-PGM(Probability Graph Model Based on Rete Algorithm).在此基礎上,提出算法DF-MAP(Deep First Max A Posterior)對法律文書進行高效的判決路徑挖掘過程.
在提取規則集合時,本文試圖采用概率圖模型的相關理論來研究不同關鍵詞組合與適用法律同時出現的概率,并準確描述它們之間的邏輯關系.概率圖模型是一類用圖模式表達基于概率相關關系的模型總稱,包含概率圖模型表示理論,概率圖模型推理理論和概率圖模型學習理論三部分[8].目前,基于概率圖的推理模型主要有4種:貝葉斯網絡、馬爾科夫網絡、混合網絡、動態貝葉斯網.在此基礎上,論文提出了基于Rete算法的概率圖模型—Rete-PGM.Rete-PGM不僅反映了每條適用法律中包含的司法解釋與量刑標準,而且還描述了特定案件中隱含的判決路徑的概率分布.利用提出的DF-MAP算法對Rete-PGM進行最大可能路徑的挖掘,最終實現案件判決路徑的挖掘.
文章剩余部分組織如下:第二部分介紹Rete算法的相關研究工作;第三部分給出問題描述及法律文書數據的預處理過程;第四部分基于Rete算法構建概率圖模型Rete-PGM,并對案件判決路徑挖掘算法DF-MAP進行詳細描述;第五部分通過實驗對所提算法進行有效性驗證;第六部分是論文的結論.
2 相關工作
Rete算法與Treat算法是最好的兩個規則匹配算法[3],本文引用Rete算法的匹配原則對各項法律法規的規則進行抽取.1974年,Charles L Forgy在工作論文[4]中首次提及Rete算法,并相繼在1979年的博士論文[5]、1982年發表的論文[6]中詳細描述并部署Rete算法.除此之外,Forgy還提出Rete-II,Rete-III,Rete-NT等變種算法對Rete算法進行完善,不僅提升了Rete算法的匹配效率,而且被應用與各種推理引擎中.
作為針對基于規則知識表現的高效模式匹配算法之一,Rete算法是對一系列元組數據(Facts)匹配規則集(Rules)的過程描述.Rete算法的匹配過程由表示系統當前狀態的事實庫(Working Memory,WM)和表示一系列規則集合的規則庫(Production Memory,PM)組成.其中,WM中每一個工作單元被稱為Working Memory Element(WME),由一個三元組表示:(identfier^attributevalue),表示將要被處理的數據.例如,w1:(B1^onB2)中的B1為identfier,on為attribute,B2為value.PM的每一條規則由LHS(Left-Hand Side)與RHS(Right-Hand Side)兩部分構成:LHS:使用邏輯符號and或or連接多個條件(Conditions),表示一條規則的條件前提;RHS:由一系列動作(Actions)組成,表示一條規則的結論部分.
Rete算法的匹配過程就是決定系統中當前WM匹配哪一條規則,以及該WM中哪些WMEs匹配對應條件的過程.Rete算法利用一個由alpha網絡、beta網絡構成的數據流網絡對該匹配過程進行描述.alpha網絡的功能是利用alphamemories(AMs)存儲符合模板的所有WMEs,并根據規則對其進行過濾,篩選出符合這條規則的模式集合.其中,模板(Pattern)表示事實(Fact)的一個抽象模型,每一個WME都必須滿足模板庫中的一個模板.beta網絡則由Join Node和Beta Memory組成:Join Node對當前兩個WME進行匹配篩選操作,而Beta Memory則對當前完成匹配過程并滿足條件的WMEs進行存儲.
迄今,眾多學術研究都對Rete算法做出了不同程度的描述,并結合不同的技術應用于不同領域.譬如,在自然語言處理領域中,Rete算法針對特定的詞匯與語料庫產生了一系列監督式規則以提高提取關鍵詞等任務的速度[7].本文試圖基于Rete算法,引入概率圖模型的相關理論來解決案情特征多樣性問題,并完成法律文書的判決路徑挖掘任務.論文中,首先分析并求解案情描述的關鍵詞與適用法律規則同時出現的概率關系,并使用提出的Rete-PGM來描述這種關系.然后,針對Rete-PGM圖集合,論文結合最大后驗概率(Max A Posterior,MAP)[9]查詢思想,提出DF-MAP (Deep First Based on Max A Posterior)算法,對案件的判決路徑進行挖掘.最后,在真實的海量法律文書數據集上進行實驗,很好的驗證了所提算法的有效性.
3 數據預處理
本小節首先給出案件判決路徑挖掘任務的問題描述,再介紹法律文書數據的預處理過程,以便后續章節的模型計算.3.1節對問題進行描述,提出Rete-PGM的概念;3.2節基于Rete算法思想,對現有的各項法律法規進行規則集合進行抽取;3.3節提取法律文書數據中案情描述關鍵詞及適用法律集合.
3.1 問題描述
事實:在法律條規中,影響量刑范圍的事實、行為,被稱為“事實”,記為f.
動作:法律條規中的量刑結果被稱為“動作”,記為a.
例如,交通肇事罪中,“死亡一人以上,負事故主要責任的,處三年以下有期徒刑或者拘役”,其中“死亡一人”、“負同等責任”為事實,“三年以下有期徒刑”、“拘役”為動作.
定義1.法律規則是由若干事實f以及相應的動作a構成的序列,記為p=[f1,f2,…,fn,a].案件判決路徑挖掘過程被描述為求解最有可能的法律規則的過程.
通常,法律文書的正文部分包括:案件事實、證據;立案理由、依據兩部分.其中,立案理由及依據必須滿足以下條件:準確概括犯罪性質、認定罪名及犯罪情節;準確引用法律;準確闡明定罪處罰的傾向意見;程式化寫明起訴決定.案件事實應當根據具體案件情況敘寫,同時,分列相關證據.立案理由與依據則需要法官對案情描述進行分析,綜合考慮各項相關法律條文,給出準確的罪名及依據.通常,盡管海量歷史法律文書的案情描述細節存在差異性,但案件判決路徑卻相差無幾.因此,論文通過深入挖掘海量歷史法律文書的正文部分,基于Rete算法,引入概率圖模型,構建Rete-PGM.再結合所提算法DF-MAP,對特定的案件進行判決路徑進行挖掘.
基于Rete算法抽取的實體法與程序法中蘊涵的規則集合,構成一個由alpha網絡與beta網絡組成的有向圖;同時,從法律文書的案情描述中提取的關鍵詞直接影響到適用法律規則的選取,并且存在概率聯系.這里,用概率圖表示關鍵詞集合與規則集合的組合關系,稱之為Rete-PGM.
Rete-PGM:由網絡結構G=(WMES,E)與參數模型P兩部分構成.WMES為頂點集,由若干法律規則的事實、動作組成;E為有向邊集,表示兩個頂點之間的概率關系.P是網絡結構G的概率分布模型,通過計算海量歷史法律文書中案情描述關鍵詞集合中每一個關鍵詞分別與每一條規則中的事實、動作共同出現的概率關系解得.
在Rete-PGM中,若兩個WMEA和B之間存在一條通路,表示A和B是串行組合關系,遵循順序匹配原則,若不存在,則表示A和B之間是并行組合關系,不存在數據匹配過程.圖2是一個案件文本的Rete-PGM示例圖.在圖2的網絡結構G中,“死亡一人”和“重傷三人”為開始頂點,也是并行組合關系,而“死亡一人”、“主要責任”以及結束頂點“有期徒刑”之間則是串行組合關系,所有的節點組合在一起是混合組合關系,共同構成了一份法律文書的Rete-PGM的網絡結構G.為了使網絡結構G能夠更好地刻畫適用法律規則集合,經深入分析海量歷史案件文書發現Rete-PGM中網絡結構具有如下的特點:
1)頂點互異性:在同一個Rete-PGM中不會出現兩個完全相同的事實、動作.
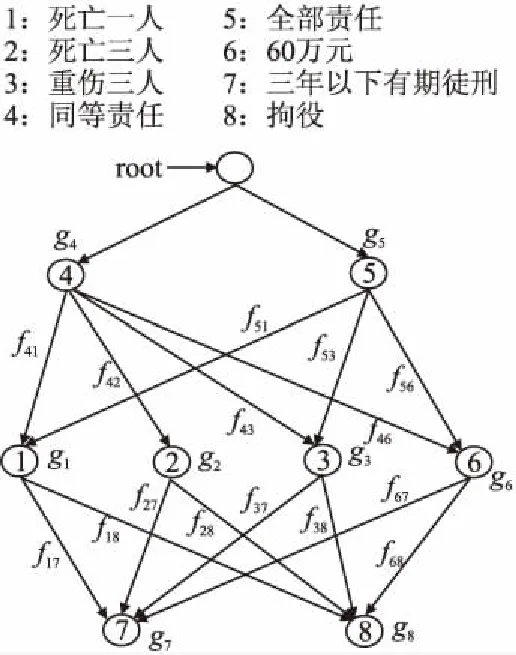
圖2 Rete-PGM示意圖Fig.2 Example of Rete-PGM
2)若干開始頂點和結束頂點:一個Rete-PGM的開始點是指入度為0的頂點,開始頂點對應于規則集中可以用于首個匹配的事實集合,由適用法律包含的量刑標準中變量個數決定.結束頂點是指出度為0的頂點,結束頂點對應整個規則集中的動作集合,由適用法律中包含的刑罰類別決定.
3)任意開始頂點到結束頂點之間必連通,即存在通路:一個Rete-PGM中,開始頂點與結束頂點之間必然存在一條通路,且這條通路對應法律規則庫中的一條規則.
3.2 法律規則提取
結合全國人民代表大會制定的刑法及全國人民代表大會常委會先后出臺的九個刑法修正案,至今刑法的罪名種類分為10大類,共468個.在實體法及程序法中,每條法律均可以被細分到款、項.在此,論文運用Rete算法抽取各項條款中的規則,形成規則庫,便于獲取單個案件文檔中適用法律規則.對468個罪名的所有相關法律以及司法解釋、量刑標準進行規則抽取,共獲得8603條規則,構成規則庫R={r1,r2,…,rn},n為規則庫中規則的數目.以《最高人民法院關于審理交通肇事刑事案件具體應用法律若干問題的解釋》第二條第一款第(一)項的具體內容:“死亡一人或者重傷三人以上,負事故全部或者主要責任的,處三年以下有期徒刑或者拘役”為例,抽取的規則使用Rete數據流網絡表示如圖1所示.圖1中,右圖給出上述法律條款的所有模板規則集合P1、P2,左圖則給出了P1的具體匹配過程.


圖3 法律文書預處理過程
Fig.3 Preprocess of law case filies
3.3 關鍵詞與適用法律抽取
利用關鍵詞提取技術,可以自動地選擇一個小特征項集對案情細節進行概括.目前,針對關鍵詞提取技術的研究已經取得較多的研究成果,如TF-IDF[10],LDA[11],Text-Rank[12],Rake[13].論文應用HanLP自然語言處理包對案情描述部分進行關鍵詞抽取,即Text-Rank方法.
算法1(圖3)詳細描述了法律文書中案情描述關鍵詞與適用法律集合的抽取過程.第1行建立空集合HK,HL分別用來存儲案情描述關鍵字、適用法律.2-9行依次遍歷所有文件抽取關鍵字及適用法律:第3行函數getDocContext()根據文件名獲取案件文書的內容,并存儲為字符串格式;第4-5行利用HandLP工具抽取案情描述關鍵字;6-7行運用準確的正則表達式對適用法律進行抽取;第8行將關鍵字與適用法律分別存入對應的HashMap集合中.
4 Rete-PGM與案件判決路徑挖掘算法DF-MAP
第3節詳細闡述了法律文書數據的預處理及適用法律規則庫生成過程,本小節重點討論案件判決路徑的挖掘過程.首先基于Rete算法、概率圖模型建立Rete-PGM;然后結合最大后驗概率(Max A Posterior,MAP)推理思想,提出算法DF-MAP對案件判決路徑進行挖掘.
4.1 Rete-PGM
概率圖模型利用網絡結構中變量的獨立性,將高維聯合概率分布為節點上低維概率分布的乘積.在此,論文首先分析法律規則庫,獲取事實、動作之間的條件概率分布,再結合案情描述關鍵詞與使用法律規則同時出現的概率,就可以解得Rete-PGM的參數模型.因此,Rete-PGM的參數模型包含兩種概率值:頂點WME本身具有的概率值,記為g;邊e∈E的概率值,記為f.

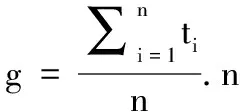



圖4 頂點結構
Fig.3 Structure of node
本文采用鄰接表結構對Rete-PGM進行存儲,如圖4所示.data存儲頂點;pro表示頂點本身的概率值g;next為指向第一個鄰接點的指針,默認值為null.f為指向該鄰接點的概率值,初始值為0.


圖5 Rete-PGM構建過程
Fig.5 Construction of Rete-PGM

圖6 DF-MAP算法
Fig.6 Algorithm of DF-MAP
算法2(圖5)詳細描述了構建一篇法律文書的Rete-PGM過程.算法前兩行完成初始化:第1行通HK,HL過獲取關鍵字與適用法律集合K,L,第2行初始化Rete-PGM的鄰接表G為空集.第3行利用createReteNetwork()函數將適用法律轉換成Rete網絡結構.4-15行依次遍歷Rete網絡的模板pattern,構建Rete-PGM的網絡結構:第5行completeMathes()進行匹配,得到WMEs與Actions列表;第8-13行判斷是否該WME存在于鄰接鏈表中,若不存在則創建頂點,并填充數據保存到鄰接表中;否則,第13行獲取頂點,并指向下一個WME.最后,16-18行根據定義5更新Rete-PGM中每條邊的概率.
4.2 DF-MAP算法
結合前文描述的Rete-PGM 的特點,運用MAP推理思想,提出適用于Rete-PGM的案件判決路徑挖掘算法—DF-MAP算法.在DF-MAP算法中,案件判決路徑挖掘的基本思想是查找開始頂點到結束頂點的關鍵路徑,即尋找一條概率值最大(最有可能)的通路.圖6給出了DF-MAP算法的描述.算法可分為兩部分:尋找Rete-PGM中開始節點到結束節點的所有連通路徑(2-5行)和應用MAP概率計算公式求解概率值最大的路徑(6-11行).
5 實驗與分析
5.1 數據采集
實驗在兩個數據集上進行:真實數據集和模擬數據集.真實數據集是來自中國裁判網的一審刑事法律文書,共計13,853,580個文件.模擬數據是根據Rete-PGM特征隨機產生的10,000個模擬的Rete-PGM,包含300種概率值最大的路徑模式,為了驗證所提算法對復雜的Rete-PGM查詢也有較好的計算效果,每個模擬Rete-PGM中開始頂點數和結束頂點數在4-11之間,中間結點在30-50之間,而真實數據集中的開始頂點數和結束頂點數一般在3-8個.同時,論文根據算法1對真實的法律文書數據集進行了預處理,剔除無關信息,只保留了案情描述與適用法律部分,以便于計算.

圖7 不同數據集規模下算法的運行時間比較Fig.7 Different algorithms runtime vs.data set

圖8 不同數據集規模下算法的F1-measure值比較Fig.8 F1-measure in different algorithms vs.data set
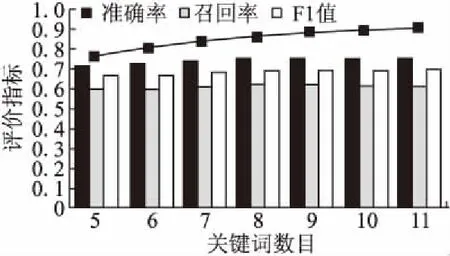
圖9 不同關鍵詞數目下的案件判決路徑的挖掘結果比較Fig.9 Case decision path mining in DF-MAP vs.key word number
5.2 實驗結果與分析
第1組:考察DF-MAP算法的計算性能
實驗1 驗證DF-MAP算法的運行效率.圖7中顯示了算法VE算法[14]、團樹算法[15]和DF-MAP在數據集規模不同的情況下,尋找最大概率值路徑所需要的運行時間.在數據集規模較小的情況下,相對其它兩種算法,算法DF-MAP在較短的時間內找到最優路徑.隨著數據的增加,每個算法運行時間的上升趨勢逐漸減緩,這是因為隨著數據集規模的增加,概率值最大的路徑模式增長減少,意味著需要的計算量也明顯減少.
實驗2 驗證DF-MAP算法的挖掘結果的有效性.圖8顯示了三個算法在數據集規模不同下尋找最大概率值路徑的結果.文獻[14,15]顯示,VE算法和團樹算法能夠求解變量集的最有可能取值,而算法DF-MAP發現的結果與它們近乎相同.由此,可以認為DF-MAP算法能夠有效地挖掘Rete-PGM中的最有可能的案件判決路徑.
第2組:在真實數據集上實現案件判決路徑的挖掘
上述兩個實驗結果表明,DF-MAP算法在保證挖掘結果有效性的基礎上,較其它兩個算法能夠更高效地實現對最有可能的案件判決路徑挖掘.下面,將所提算法運用到真實的法律文書數據集上進行案件判決路徑挖掘,并對挖掘結果進行分析.從下述兩個方面對所提算法DF-MAP進行考察:
實驗3考察在相同數據集規模下,案情描述的關鍵詞個數的變化對案件判決路徑挖掘結果的影響.已知在真實的法律文書數據集中,案情描述關鍵詞的選取對適用法律的選取具有決定性作用,關鍵詞數目太少無法完整而準確地總結案情描述的細節,而關鍵詞數目太多則降低算法的效率.實驗中對關鍵詞數目在5-11之間取不同的值進行測試.圖9中,折線圖和柱狀圖分別顯示了使用不同關鍵詞數目對案情進行描述的情況下,案件判決路徑挖掘過程的運行時間與挖掘結果的準確率、召回率、F1值.柱狀圖的結果顯示,關鍵詞數目從5-7變化時,三個指標值逐漸提升,而當其大于8后,三個指標值則趨于平緩,反映了8個或8個以上的關鍵詞對案情描述部分能夠較為充分的對案情進行描述.同時隨著關鍵詞數目的增加,算法DF-MAP的運行時間逐漸上升,但上升的趨勢逐漸緩慢.對比圖9,可以發現選取8個或8個以上關鍵詞時案件判決路徑挖掘效果較好,既能保證挖掘結果有較高的準確率、召回率,又能保證運行時間較低.在實際應用中,可結合實際需要來選擇關鍵詞數目.

圖10 不同類別法律文書的判決路徑挖掘結果比較Fig.10 Case decision path mining in different kind of case files
實驗4 考查在相同數據集規模下,算法DF-MAP挖掘不同類別的法律文書數據集的結果分布情況.圖11給出的實驗結果顯示,所提算法DF-MAP針對10個類別的法律文書數據集的案件判決路徑挖掘效果存在過大或過小的差異.其中,“破壞社會主義市場經濟秩序罪”、“瀆職罪”的三個評估值都較低,這反映了其成因的復雜性,導致DF-MAP的挖掘結果缺乏準確性.同時,“危害國家安全罪”、“侵犯財產罪”、“妨害社會管理秩序罪”等類別的法律文書的挖掘結果的準確度均接近74%,這反映了這些類別的案件具有明確、清晰的社會構成因素.由此可見DF-MAP算法的案件判決路徑挖掘具有良好的效果.
6 總 結
構建高效的案件判決路徑挖掘應用不僅能夠為法官提供可參考的法律文書,而且有利于解決法院“案多人少”的困境.基于Rete算法的概率圖模型Rete-PGM充分反映了適用法律規則模式,同時形象地描述了案情描述關鍵詞組合與適用法律之間的概率關系.在此基礎上,提出了案件判決路徑挖掘算法—DF-MAP算法,并將所提算法應用于真實的海量歷史法律文書數據集上,最終實現了對指定案情描述的案件判決路徑挖掘過程.此外,所提圖模型Rete-PGM還可以作為案情描述中關鍵詞選取的依據.因此,在下一步的工作中,將首先對法律規則集的自動化抽取方法進行研究;再結合Rete-PGM實現案情描述關鍵詞更加準確地提取過程.
猜你喜歡
作文周刊·小學一年級版(2022年28期)2022-05-30 10:48:04
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
法律方法(2019年3期)2019-09-11 06:26:16
中國外匯(2019年7期)2019-07-13 05:44:52
幸福(2018年33期)2018-12-05 05:22:42
環球飛行(2018年7期)2018-06-27 07:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
運動(2016年6期)2016-12-01 06:33:42
